C#/.NET编译原理和跨平台特性
任何编程语言要被计算机理解,都需要转化成机器码才行,而转化的过程分为两种主要的形式,即编译和解释。
编译(compile)是将一种语言转换为另一种语言的动作,而一般来说,"另一种语言”通常是机器码(machine code/native code),即全部由 0 和 1 组成的语言,或者某种公共语言,当然机器码可以看作所有语言的目标公共语言。
使用编译器读入一 个文件,将会产出一个由目标语言写成的另一个文件,例如,C# 编译器会产出扩展名为 exe 或 dll 的文件,目标语言是 IL。
而相对的,解释(interpret)虽然也会将代码翻译为机器码,但是,却不会产生目标文件。
因此,每次运行解释型语言时,都需要重新进行解释。
不太准确地讲,编译可以类比为做好一桌菜才开吃,而解释可以类比为吃火锅,边涮边吃。
.NET 框架语言和 C、C++ 都是编译型语言,而它们之间还有一点不同。
.NET 框架语言是通过两步编译变成机器码的,如下图所示。
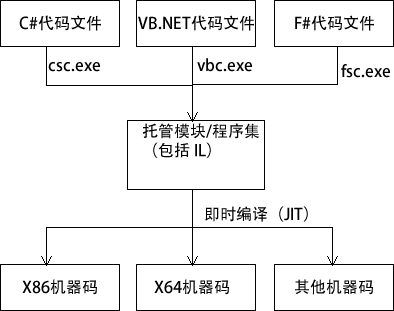
第一步编译使用 .NET 自带的编译器(例如 C# 会使用 csc.exe)并生成 IL 语言,它是一个基于栈的、面向对象的高级语言。
显然,高级语言是无法被机器直接执行的,在运行时(runtime), CLR 使用 JIT 来将 IL 转换为机器码,所以,CLR 是 .NET Framework 最重要的组件,没有之一。
Java 和 C# 类似,它的中间层叫做字节码(bytecode)。而 C 语言则是一步到位的,没有中间 IL 这一层。
在第二步将 IL 或字节码转化为机器码时,会使用对应机器的解释器来执行。
在解释器执行时,会采用即时编译的形式(一句句编译源代码,但是会将翻译过的代码缓存起来以降低性能损耗),因此,它的性能比普通的解释型语言(没有缓存功能)要快。
不过,运行完毕,程序退出之后,缓存的内容就消失了,每次运行时都需要重新编译。
跨平台最常见和最令人熟悉的定义是“一次编译,到处运行”。
这其中,一次编译指的就是第一步编译(转化为中间语言)。
C 语言不能跨平台,是因为它的编译目标是机器码(本地代码),而不同操作系统和处理器的机器码是不同的。
C#/Java 采用了一个中间层来解决这个问题。
C# 的编译器 csc.exe 将 C# 代码编译为 IL,而不是机器码。
拿到 IL 之后, 通过在特定平台的运行时程序(CLR 和 JRE),解释和编译 IL (即时编译 JIT)为机器码来执行。
而这么做的好处则是,仅需要较少的编译器就可以完成跨平台功能。
例如,上图中,为了使三个语言支持三种机器,需要六个编译器,例如,C# 编译器和 X86JIT 编译器等。
如果撤掉 IL 层,则需要九种编译器才行,因为每个语言都需要三个编译器:3x3=9。
编译(compile)是将一种语言转换为另一种语言的动作,而一般来说,"另一种语言”通常是机器码(machine code/native code),即全部由 0 和 1 组成的语言,或者某种公共语言,当然机器码可以看作所有语言的目标公共语言。
使用编译器读入一 个文件,将会产出一个由目标语言写成的另一个文件,例如,C# 编译器会产出扩展名为 exe 或 dll 的文件,目标语言是 IL。
而相对的,解释(interpret)虽然也会将代码翻译为机器码,但是,却不会产生目标文件。
因此,每次运行解释型语言时,都需要重新进行解释。
不太准确地讲,编译可以类比为做好一桌菜才开吃,而解释可以类比为吃火锅,边涮边吃。
.NET 框架语言和 C、C++ 都是编译型语言,而它们之间还有一点不同。
.NET 框架语言是通过两步编译变成机器码的,如下图所示。
第一步编译使用 .NET 自带的编译器(例如 C# 会使用 csc.exe)并生成 IL 语言,它是一个基于栈的、面向对象的高级语言。
显然,高级语言是无法被机器直接执行的,在运行时(runtime), CLR 使用 JIT 来将 IL 转换为机器码,所以,CLR 是 .NET Framework 最重要的组件,没有之一。
Java 和 C# 类似,它的中间层叫做字节码(bytecode)。而 C 语言则是一步到位的,没有中间 IL 这一层。
在第二步将 IL 或字节码转化为机器码时,会使用对应机器的解释器来执行。
在解释器执行时,会采用即时编译的形式(一句句编译源代码,但是会将翻译过的代码缓存起来以降低性能损耗),因此,它的性能比普通的解释型语言(没有缓存功能)要快。
不过,运行完毕,程序退出之后,缓存的内容就消失了,每次运行时都需要重新编译。
跨平台最常见和最令人熟悉的定义是“一次编译,到处运行”。
这其中,一次编译指的就是第一步编译(转化为中间语言)。
C 语言不能跨平台,是因为它的编译目标是机器码(本地代码),而不同操作系统和处理器的机器码是不同的。
C#/Java 采用了一个中间层来解决这个问题。
C# 的编译器 csc.exe 将 C# 代码编译为 IL,而不是机器码。
拿到 IL 之后, 通过在特定平台的运行时程序(CLR 和 JRE),解释和编译 IL (即时编译 JIT)为机器码来执行。
而这么做的好处则是,仅需要较少的编译器就可以完成跨平台功能。
例如,上图中,为了使三个语言支持三种机器,需要六个编译器,例如,C# 编译器和 X86JIT 编译器等。
如果撤掉 IL 层,则需要九种编译器才行,因为每个语言都需要三个编译器:3x3=9。
所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频