数组越界及其避免方法,C语言数组越界详解
所谓的数组越界,简单地讲就是指数组下标变量的取值超过了初始定义时的大小,导致对数组元素的访问出现在数组的范围之外,这类错误也是 C 语言程序中最常见的错误之一。
在 C 语言中,数组必须是静态的。换而言之,数组的大小必须在程序运行前就确定下来。由于 C 语言并不具有类似 Java 等语言中现有的静态分析工具的功能,可以对程序中数组下标取值范围进行严格检查,一旦发现数组上溢或下溢,都会因抛出异常而终止程序。也就是说,C 语言并不检验数组边界,数组的两端都有可能越界,从而使其他变量的数据甚至程序代码被破坏。
因此,数组下标的取值范围只能预先推断一个值来确定数组的维数,而检验数组的边界是程序员的职责。
一般情况下,数组的越界错误主要包括两种:数组下标取值越界与指向数组的指针的指向范围越界。
由于程序将用户输入的字符串原封不动地复制到 Test() 函数的数组 char buffer[7] 中。因此,当用户的输入大于 7 个字符的缓冲区尺寸时,就会发生数组越界错误,这也就是大家所谓的缓冲区溢出(Buffer overflow)漏洞。但是要注意,如果这个时候我们根据缓冲区溢出发生的具体情况填充缓冲区,不但可以避免程序崩溃,还会影响到程序的执行流程,甚至会让程序去执行缓冲区里的代码。示例运行结果为:
请输入密码:12345
密码错误!
请输入密码:123456
密码正确!
请输入密码:1234567
密码正确!
请输入密码:aaaaaaa
密码正确!
请输入密码:0123456
密码错误!
请输入密码:
在示例代码中,flag 变量实际上是一个标志变量,其值将决定着程序是进入“密码错误”的流程(非 0)还是“密码正确”的流程(0)。当我们输入错误的字符串“1234567”或者“aaaaaaa”,程序也都会输出“密码正确”。但在输入“0123456”的时候,程序却输出“密码错误”,这究竟是为什么呢?
其实,原因很简单。当调用 Test() 函数时,系统将会给它分配一片连续的内存空间,而变量 char buffer[7] 与 int flag 将会紧挨着进行存储,用户输入的字符串将会被复制进 buffer[7] 中。如果这个时候,我们输入的字符串数量超过 6 个(注意,有字符串截断符也算一个),那么超出的部分将破坏掉与它紧邻着的 flag 变量的内容。
当输入的密码不是宏定义的“123456”时,字符串比较将返回 1 或 -1。我们都知道,内存中的数据按照 4 字节(DWORD)逆序存储,所以当 flag 为 1 时,在内存中存储的是 0x01000000。如果我们输入包含 7 个字符的错误密码,如“aaaaaaa”,那么字符串截断符 0x00 将写入 flag 变量,这样溢出数组的一个字节 0x00 将恰好把逆序存放的 flag 变量改为 0x00000000。在函数返回后,一旦 main 函数的 flag 为 0,就会输出“密码正确”。这样,我们就用错误的密码得到了正确密码的运行效果。
而对于“0123456”,因为在进行字符串的大小比较时,它小于“123456”,flag的值是 -1,在内存中将按照补码存放负数,所以实际存储的不是 0x01000000 而是 0xffffffff。那么字符串截断后符 0x00 淹没后,变成 0x00ffffff,还是非 0,所以没有进入正确分支。
其实,本示例只是用一个字节淹没了邻接变量,导致程序进入密码正确的处理流程,使设计的验证功能失效。
要避免程序因数组越界所发生的错误,首先就需要从数组的边界定义开始。尽量显式地指定数组的边界,即使它已经由初始化值列表隐式指定。示例代码如下所示:
当然,也可以使用宏的形式来显式指定数组的边界(实际上,这也是最常用的指定方法),如下面的代码所示:
a[MAX]:
a[0]=1 a[1]=2 a[2]=3 a[3]=4 a[4]=5 a[5]=6 a[6]=7 a[7]=8 a[8]=9 a[9]=10
b[MAX1]:
b[0]=1 b[1]=2 b[2]=3 b[3]=4 b[4]=5 b[5]=0 b[6]=0 b[7]=0 b[8]=0 b[9]=0 b[10]=6 b[11]=7 b[12]=8 b[13]=9 b[14]=10
c[MAX2]:
c[0]=1 c[1]=6 c[2]=7 c[3]=8 c[4]=9 c[5]=10
来看下面一段代码示例:
但是,如果仔细检查,TestArray() 函数仍然还存在一个致命的问题,那就是没有检查数组的下界。由于这里的 num 参数类型是 int 类型,因此可能为负数。如果 num 参数所传递的值为负数,将导致在 arr 所引用的内存边界之外进行写入。
当然,你可以通过向“if(num<ARRAY_NUM)”语句里面再加一个条件进行测试,如下面的代码所示:
但需要注意的是,sizeof 操作符不能用于函数类型、不完全类型(指具有未知存储大小的数据类型,如未知存储大小的数组类型、未知内容的结构或联合类型、void 类型等)与位字段。例如,以下都是不正确形式:
是什么原因导致这个结果呢?
很显然,上面的示例代码在“void Init(int arr[])”函数中接收了一个“int arr[]”类型的形参,并且在main函数中向它传递一个“a[10]”实参。同时,在 Init() 函数中通过“sizeof(arr)/sizeof(arr[0])”来确定这个数组元素的数量和初始化值。
在这里出现了一个很大问题:由于 arr 参数是一个形参,它是一个指针类型,其结果是“sizeof(arr)=sizeof(int*)”。在 IA-32 中,“sizeof(arr)/sizeof(arr[0])”的结果为 1。因此,最后的结果如图 1 所示。
对于上面的示例代码,我们可以通过传入数组的长度的方式来解决这个问题,示例代码如下:
在 C 语言中,数组必须是静态的。换而言之,数组的大小必须在程序运行前就确定下来。由于 C 语言并不具有类似 Java 等语言中现有的静态分析工具的功能,可以对程序中数组下标取值范围进行严格检查,一旦发现数组上溢或下溢,都会因抛出异常而终止程序。也就是说,C 语言并不检验数组边界,数组的两端都有可能越界,从而使其他变量的数据甚至程序代码被破坏。
因此,数组下标的取值范围只能预先推断一个值来确定数组的维数,而检验数组的边界是程序员的职责。
一般情况下,数组的越界错误主要包括两种:数组下标取值越界与指向数组的指针的指向范围越界。
数组下标取值越界
数组下标取值越界主要是指访问数组的时候,下标的取值不在已定义好的数组的取值范围内,而访问的是无法获取的内存地址。例如,对于数组 int a[3],它的下标取值范围是 [0,2](即 a[0]、a[1] 与 a[2])。如果我们的取值不在这个范围内(如 a[3]),就会发生越界错误。示例代码如下所示:
int a[3];
int i=0;
for(i=0;i<4;i++)
{
a[i] = i;
}
for(i=0;i<4;i++)
{
printf("a[%d]=%d\n",i,a[i]);
}
很显然,在上面的示例程序中,访问 a[3] 是非法的,将会发生越界错误。因此,我们应该将上面的代码修改成如下形式:
int a[3];
int i=0;
for(i=0;i<3;i++)
{
a[i] = i;
}
for(i=0;i<3;i++)
{
printf("a[%d]=%d\n",i,a[i]);
}
指向数组的指针的指向范围越界
指向数组的指针的指向范围越界是指定义数组时会返回一个指向第一个变量的头指针,对这个指针进行加减运算可以向前或向后移动这个指针,进而访问数组中所有的变量。但在移动指针时,如果不注意移动的次数和位置,会使指针指向数组以外的位置,导致数组发生越界错误。下面的示例代码就是移动指针时没有考虑到移动的次数和数组的范围,从而使程序访问了数组以外的存储单元。
int i;
int *p;
int a[5];
/*数组a的头指针赋值给指针p*/
p=a;
for(i=0;i<10;i++)
{
/*指针p指向的变量*/
*p=i+10;
/*指针p下一个变量*/
p++;
}
在上面的示例代码中,for 循环会使指针 p 向后移动 10 次,并且每次向指针指向的单元赋值。但是,这里数组 a 的下标取值范围是 [0,4](即 a[0]、a[1]、a[2]、a[3] 与 a[4])。因此,后 5 次的操作会对未知的内存区域赋值,而这种向内存未知区域赋值的操作会使系统发生错误。正确的操作应该是指针移动的次数与数组中的变量个数相同,如下面的代码所示:
int i;
int *p;
int a[5];
/*数组a的头指针赋值给指针p*/
p=a;
for(i=0;i<5;i++)
{
/*指针p指向的变量*/
*p=i+10;
/*指针p下一个变量*/
p++;
}
为了加深大家对数组越界的了解,下面通过一段完整的数组越界示例来演示编程中数组越界将会导致哪些问题。
#define PASSWORD "123456"
int Test(char *str)
{
int flag;
char buffer[7];
flag=strcmp(str,PASSWORD);
strcpy(buffer,str);
return flag;
}
int main(void)
{
int flag=0;
char str[1024];
while(1)
{
printf("请输入密码: ");
scanf("%s",str);
flag = Test(str);
if(flag)
{
printf("密码错误!\n");
}
else
{
printf("密码正确!\n");
}
}
return 0;
}
上面的示例代码模拟了一个密码验证的例子,它将用户输入的密码与宏定义中的密码“123456”进行比较。很显然,本示例中最大的设计漏洞就在于 Test() 函数中的 strcpy(buffer,str) 调用。由于程序将用户输入的字符串原封不动地复制到 Test() 函数的数组 char buffer[7] 中。因此,当用户的输入大于 7 个字符的缓冲区尺寸时,就会发生数组越界错误,这也就是大家所谓的缓冲区溢出(Buffer overflow)漏洞。但是要注意,如果这个时候我们根据缓冲区溢出发生的具体情况填充缓冲区,不但可以避免程序崩溃,还会影响到程序的执行流程,甚至会让程序去执行缓冲区里的代码。示例运行结果为:
请输入密码:12345
密码错误!
请输入密码:123456
密码正确!
请输入密码:1234567
密码正确!
请输入密码:aaaaaaa
密码正确!
请输入密码:0123456
密码错误!
请输入密码:
在示例代码中,flag 变量实际上是一个标志变量,其值将决定着程序是进入“密码错误”的流程(非 0)还是“密码正确”的流程(0)。当我们输入错误的字符串“1234567”或者“aaaaaaa”,程序也都会输出“密码正确”。但在输入“0123456”的时候,程序却输出“密码错误”,这究竟是为什么呢?
其实,原因很简单。当调用 Test() 函数时,系统将会给它分配一片连续的内存空间,而变量 char buffer[7] 与 int flag 将会紧挨着进行存储,用户输入的字符串将会被复制进 buffer[7] 中。如果这个时候,我们输入的字符串数量超过 6 个(注意,有字符串截断符也算一个),那么超出的部分将破坏掉与它紧邻着的 flag 变量的内容。
当输入的密码不是宏定义的“123456”时,字符串比较将返回 1 或 -1。我们都知道,内存中的数据按照 4 字节(DWORD)逆序存储,所以当 flag 为 1 时,在内存中存储的是 0x01000000。如果我们输入包含 7 个字符的错误密码,如“aaaaaaa”,那么字符串截断符 0x00 将写入 flag 变量,这样溢出数组的一个字节 0x00 将恰好把逆序存放的 flag 变量改为 0x00000000。在函数返回后,一旦 main 函数的 flag 为 0,就会输出“密码正确”。这样,我们就用错误的密码得到了正确密码的运行效果。
而对于“0123456”,因为在进行字符串的大小比较时,它小于“123456”,flag的值是 -1,在内存中将按照补码存放负数,所以实际存储的不是 0x01000000 而是 0xffffffff。那么字符串截断后符 0x00 淹没后,变成 0x00ffffff,还是非 0,所以没有进入正确分支。
其实,本示例只是用一个字节淹没了邻接变量,导致程序进入密码正确的处理流程,使设计的验证功能失效。
尽量显式地指定数组的边界
在 C 语言中,为了提高运行效率,给程序员更大的空间,为指针操作带来更多的方便,C 语言内部本身不检查数组下标表达式的取值是否在合法范围内,也不检查指向数组元素的指针是不是移出了数组的合法区域。因此,在编程中使用数组时就必须格外谨慎,在对数组进行读写操作时都应当进行相应的检查,以免对数组的操作超过数组的边界,从而发生缓冲区溢出漏洞。要避免程序因数组越界所发生的错误,首先就需要从数组的边界定义开始。尽量显式地指定数组的边界,即使它已经由初始化值列表隐式指定。示例代码如下所示:
int a[]={1,2,3,4,5,6,7,8,9,10};
很显然,对于上面的数组 a[],虽然编译器可以根据始化值列表来计算出数组的长度。但是,如果我们显式地指定该数组的长度,例如:
int a[10]={1,2,3,4,5,6,7,8,9,10};
它不仅使程序具有更好的可读性,并且大多数编译器在数组长度小于初始化值列表的长度时还会发生相应警告。当然,也可以使用宏的形式来显式指定数组的边界(实际上,这也是最常用的指定方法),如下面的代码所示:
#define MAX 10
…
int a[MAX]={1,2,3,4,5,6,7,8,9,10};
除此之外,在 C99 标准中,还允许我们使用单个指示符为数组的两段“分配”空间,如下面的代码所示:
int a[MAX]={1,2,3,4,5,[MAX-5]=6,7,8,9,10};
在上面的 a[MAX] 数组中,如果 MAX 大于 10,数组中间将用 0 值元素进行填充(填充的个数为 MAX-10,并从 a[5] 开始进行 0 值填充);如果 MAX 小于 10,“[MAX-5]”之前的 5 个元素(1,2,3,4,5)中将有几个被“[MAX-5]”之后的 5 个元素(6,7,8,9,10)所覆盖,示例代码如下所示:
#define MAX 10
#define MAX1 15
#define MAX2 6
int main(void)
{
int a[MAX]={1,2,3,4,5,[MAX-5]=6,7,8,9,10};
int b[MAX1]={1,2,3,4,5,[MAX1-5]=6,7,8,9,10};
int c[MAX2]={1,2,3,4,5,[MAX2-5]=6,7,8,9,10};
int i=0;
int j=0;
int z=0;
printf("a[MAX]:\n");
for(i=0;i<MAX;i++)
{
printf("a[%d]=%d ",i,a[i]);
}
printf("\nb[MAX1]:\n");
for(j=0;j<MAX1;j++)
{
printf("b[%d]=%d ",j,b[j]);
}
printf("\nc[MAX2]:\n");
for(z=0;z<MAX2;z++)
{
printf("c[%d]=%d ",z,c[z]);
}
printf("\n");
return 0;
}
运行结果为:a[MAX]:
a[0]=1 a[1]=2 a[2]=3 a[3]=4 a[4]=5 a[5]=6 a[6]=7 a[7]=8 a[8]=9 a[9]=10
b[MAX1]:
b[0]=1 b[1]=2 b[2]=3 b[3]=4 b[4]=5 b[5]=0 b[6]=0 b[7]=0 b[8]=0 b[9]=0 b[10]=6 b[11]=7 b[12]=8 b[13]=9 b[14]=10
c[MAX2]:
c[0]=1 c[1]=6 c[2]=7 c[3]=8 c[4]=9 c[5]=10
对数组做越界检查,确保索引值位于合法的范围之内
要避免数组越界,除了上面所阐述的显式指定数组的边界之外,还可以在数组使用之前进行越界检查,检查数组的界限和字符串(也以数组的方式存放)的结束,以保证数组索引值位于合法的范围之内。例如,在写处理数组的函数时,一般应该有一个范围参数;在处理字符串时总检查是否遇到空字符‘\0’。来看下面一段代码示例:
#define ARRAY_NUM 10
int *TestArray(int num,int value)
{
int *arr=NULL;
arr=(int *)malloc(sizeof(int)*ARRAY_NUM);
if(arr!=NULL)
{
arr[num]=value;
}
else
{
/*处理arr==NULL*/
}
return arr;
}
从上面的“int*TestArray(int num,int value)”函数中不难看出,其中存在着一个很明显的问题,那就是无法保证 num 参数是否越界(即当 num>=ARRAY_NUM 的情况)。因此,应该对 num 参数进行越界检查,示例代码如下所示:
int *TestArray(int num,int value)
{
int *arr=NULL;
/*越界检查(越上界)*/
if(num<ARRAY_NUM)
{
arr=(int *)malloc(sizeof(int)*ARRAY_NUM);
if(arr!=NULL)
{
arr[num]=value;
}
else
{
/*处理arr==NULL*/
}
}
return arr;
}
这样通过“if(num<ARRAY_NUM)”语句进行越界检查,从而保证 num 参数没有越过这个数组的上界。现在看起来,TestArray() 函数应该没什么问题,也不会发生什么越界错误。但是,如果仔细检查,TestArray() 函数仍然还存在一个致命的问题,那就是没有检查数组的下界。由于这里的 num 参数类型是 int 类型,因此可能为负数。如果 num 参数所传递的值为负数,将导致在 arr 所引用的内存边界之外进行写入。
当然,你可以通过向“if(num<ARRAY_NUM)”语句里面再加一个条件进行测试,如下面的代码所示:
if(num>=0&&num<ARRAY_NUM)
{
}
但是,这样的函数形式对调用者来说是不友好的(由于 int 类型的原因,对调用者来说仍然可以传递负数,至于在函数中怎么处理那是另外一件事情),因此,最佳的解决方案是将 num 参数声明为 size_t 类型,从根本上防止它传递负数,示例代码如下所示:
int *TestArray(size_t num,int value)
{
int *arr=NULL;
/*越界检查(越上界)*/
if(num<ARRAY_NUM)
{
arr=(int *)malloc(sizeof(int)*ARRAY_NUM);
if(arr!=NULL)
{
arr[num]=value;
}
else
{
/*处理arr==NULL*/
}
}
return arr;
}
获取数组的长度时不要对指针应用 sizeof 操作符
在 C 语言中,sizeof 这个其貌不扬的家伙经常会让无数程序员叫苦连连。同时,它也是各大公司争相选用的面试必备题目。简单地讲,sizeof 是一个单目操作符,不是函数。其作用就是返回一个操作数所占的内存字节数。其中,操作数可以是一个表达式或括在括号内的类型名,操作数的存储大小由操作数的类型来决定。例如,对于数组 int a[5],可以使用“sizeof(a)”来获取数组的长度,使用“sizeof(a[0])”来获取数组元素的长度。但需要注意的是,sizeof 操作符不能用于函数类型、不完全类型(指具有未知存储大小的数据类型,如未知存储大小的数组类型、未知内容的结构或联合类型、void 类型等)与位字段。例如,以下都是不正确形式:
/*若此时max定义为intmax();*/
sizeof(max)
/*若此时arr定义为char arr[MAX],且MAX未知*/
sizeof(arr)
/*不能够用于void类型*/
sizeof(void)
/*不能够用于位字段*/
struct S
{
unsigned int f1 : 1;
unsigned int f2 : 5;
unsigned int f3 : 12;
};
sizeof(S.f1);
了解 sizeof 操作符之后,现在来看下面的示例代码:
void Init(int arr[])
{
size_t i=0;
for(i=0;i<sizeof(arr)/sizeof(arr[0]);i++)
{
arr[i]=i;
}
}
int main(void)
{
int i=0;
int a[10];
Init(a);
for(i=0;i<10;i++)
{
printf("%d\n",a[i]);
}
return 0;
}
从表面看,上面代码的输出结果应该是“0,1,2,3,4,5,6,7,8,9”,但实际结果却出乎我们的意料,如图 1 所示。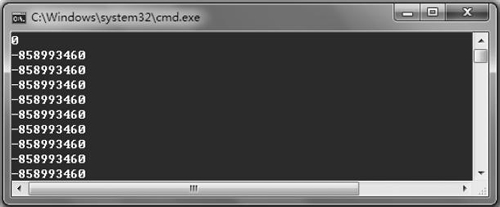
是什么原因导致这个结果呢?
很显然,上面的示例代码在“void Init(int arr[])”函数中接收了一个“int arr[]”类型的形参,并且在main函数中向它传递一个“a[10]”实参。同时,在 Init() 函数中通过“sizeof(arr)/sizeof(arr[0])”来确定这个数组元素的数量和初始化值。
在这里出现了一个很大问题:由于 arr 参数是一个形参,它是一个指针类型,其结果是“sizeof(arr)=sizeof(int*)”。在 IA-32 中,“sizeof(arr)/sizeof(arr[0])”的结果为 1。因此,最后的结果如图 1 所示。
对于上面的示例代码,我们可以通过传入数组的长度的方式来解决这个问题,示例代码如下:
void Init(int arr[],size_t arr_len)
{
size_t i=0;
for(i=0;i<arr_len;i++)
{
arr[i]=i;
}
}
int main(void)
{
int i=0;
int a[10];
Init(a,10);
for(i=0;i<10;i++)
{
printf("%d\n",a[i]);
}
return 0;
}
除此之外,我们还可以通过指针的方式来解决上面的问题,示例代码如下所示:
void Init(int (*arr)[10])
{
size_t i=0;
for(i=0;i< sizeof(*arr)/sizeof(int);i++)
{
(*arr)[i]=i;
}
}
int main(void)
{
int i=0;
int a[10];
Init(&a);
for(i=0;i<10;i++)
{
printf("%d\n",a[i]);
}
return 0;
}
现在,Init() 函数中的 arr 参数是一个指向“arr[10]”类型的指针。需要特别注意的是,这里绝对不能够使用“void Init(int(*arr)[])”来声明函数,而是必须指明要传入的数组的大小,否则“sizeof(*arr)”无法计算。但是在这种情况下,再通过 sizeof 来计算数组大小已经没有意义了,因为此时数组大小已经指定为 10 了。所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频