Shell管道详解
管道pipe同样可以在标准输入输出和标准错误输出间做代替工作,这样一来,可以将某一个程序的输出送到另一个程序的输入,其语法如下:
command1| command2[| command3...]
也可以连同标准错误输出一起送入管道:
command1| &command2[|& command3...]
一、基本的管道过滤器:
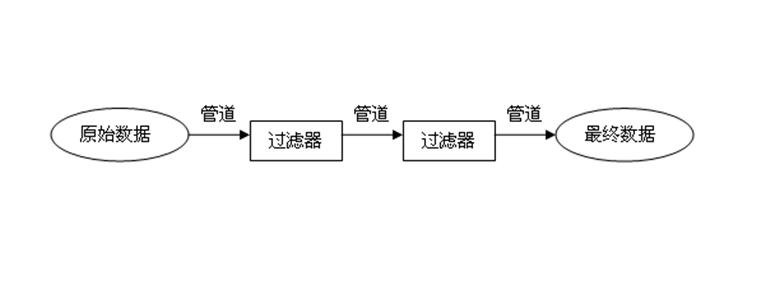
管道负责数据的传递,它把原始数据传递给第一个过滤器,把一个过滤器的输出传递给下一个过滤器,作为下一个过滤器的输入,重复这个过程直到处理结 束。要注意的是,管道只是对数据传输的抽象,它可能是管道,也可能是其它通信方式,甚至什么都没有(所有过滤器都在原始数据基础上进行处理)。
过滤器负责数据的处理,过滤器可以有多个,每个过滤器对数据做特定的处理,它们之间没有依赖关系,一个过滤器不必知道其它过滤器的存在。这种松耦合 的设计,使得过滤器只需要实现单一的功能,从而降低了系统的复杂度,也使得过滤器之间依赖最小,从而以更加灵活的组合来实现新的功能。
编译器就是基于管道过滤器模式设计的:
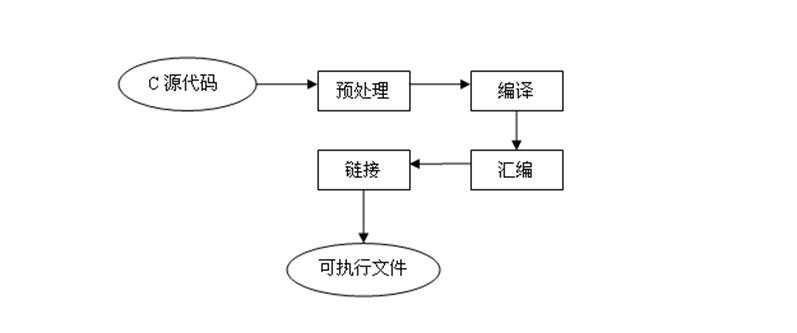
输入:源程序
预处理:负责宏展开和去掉注释等工作。
编译:进行词法分析、语法分析、语义分析、代码优化和代码产生。
汇编:负责把汇编代码转换成机器指令,生成目标文件。
链接:负责把多个目标文件、静态库和共享库链接成可执行文件/共享库。
输出:可执行文件/共享库。
二、复合过滤器
过滤器可以由多个其它过滤器组合起来的,比如上面的“编译”过程可以认为是一个复合过滤器:
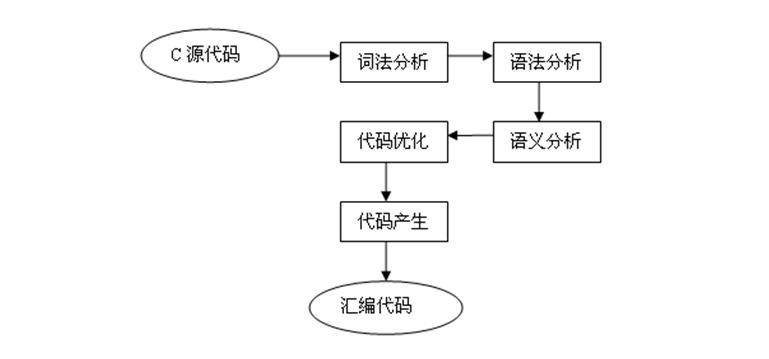 输入:预处理之后的源代码。
输入:预处理之后的源代码。
词法分析:负责将源程序分解成一个一个的token,这些token是组成源程序的基本单元。
语法分析:把词法分析得到的token解析成语法树。
语义分析:对语法树进行类型检查等语义分析。
代码优化:对语法树进行重组和修改,以优化代码的速度和大小。
代码产生:根据语法树产生汇编代码。
输出:汇编代码。
三、支持多个输入的过滤器
过滤器可以有多个输入。比如上面“链接”,它接收多个输入:
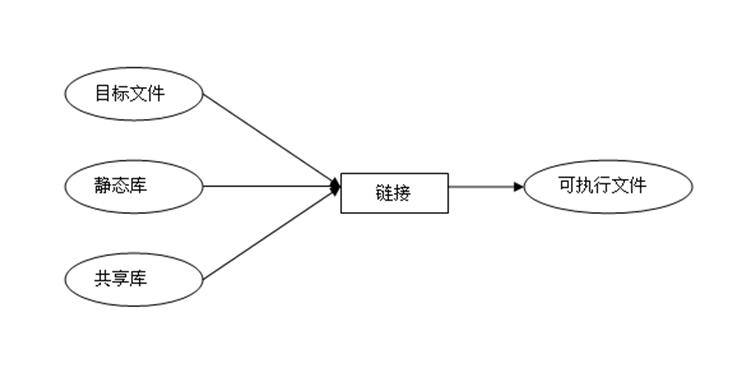 “链接”过滤器能接收多个数据源,如目标文件、静态库和共享库。
“链接”过滤器能接收多个数据源,如目标文件、静态库和共享库。
四、具有多个输出的过滤器
过滤器可以有多个输出。如多媒体播放器的解码过程:
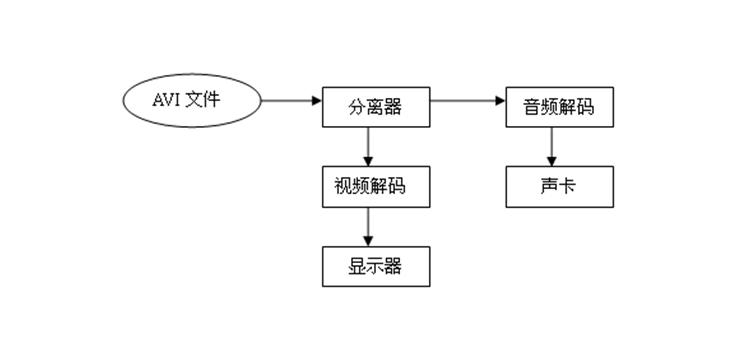 输入:AVI文件,包括音频和视频数据。
输入:AVI文件,包括音频和视频数据。
分离器:把音频和视频数据分离成两个流,音频数据传递给音频解码器,视频数据传递给视频解码器。
音频解码器:把压缩的音频数据解码成原始的音频数据。
视频解码器:把压缩的视频数据解码成原始的图像数据。
输出:音频数据传递给声卡,图像数据传递给显示器。
管道过滤器是最贴近程序员生活的模式,也是Unix-like系统的基本设计理念之一。作为Linux下的程序员,我们天天都使用这个模式。比如:
1、删除当前目录及子目录下的目标文件:
find -name \*.o|xargs rm –f
find是过滤器:它找出所有目标文件,它不需要关心查找文件的目的。
rm是过滤器:它删除找到目标文件,rm不需要关心文件名是如何得来的。
2、查看某个进程的栈的大小
grep stack /proc/2976/maps|sed -e “s/-/ /”|awk ‘{print strtonum(“0x”$2)-strtonum(“0x”$1)}’
/proc/2976/maps是进程2976内存映射表。内容可能如下:
bfe5e000-bfe73000 rw-p bffeb000 00:00 0 [stack]
sed是过滤器:它把‘-’替换成‘ ’,数据变成下面的内容。
bfe5e000 bfe73000 rw-p bffeb000 00:00 0 [stack]
awk是过滤器:它计算0xbfe73000和0x bfe5e000差值,并打印出来。
command1| command2[| command3...]
也可以连同标准错误输出一起送入管道:
command1| &command2[|& command3...]
管道过滤器(Pipe-And-Filter)模式
按照《POSA(面向模式的软件架构)》里的说法,管道过滤器(Pipe-And-Filter)应该属于架构模式,因为它通常决定了一个系统的基 本架构。管道过滤器和生产流水线类似,在生产流水线上,原材料在流水线上经一道一道的工序,最后形成某种有用的产品。在管道过滤器中,数据经过一个一个的 过滤器,最后得到需要的数据。一、基本的管道过滤器:
管道负责数据的传递,它把原始数据传递给第一个过滤器,把一个过滤器的输出传递给下一个过滤器,作为下一个过滤器的输入,重复这个过程直到处理结 束。要注意的是,管道只是对数据传输的抽象,它可能是管道,也可能是其它通信方式,甚至什么都没有(所有过滤器都在原始数据基础上进行处理)。
过滤器负责数据的处理,过滤器可以有多个,每个过滤器对数据做特定的处理,它们之间没有依赖关系,一个过滤器不必知道其它过滤器的存在。这种松耦合 的设计,使得过滤器只需要实现单一的功能,从而降低了系统的复杂度,也使得过滤器之间依赖最小,从而以更加灵活的组合来实现新的功能。
编译器就是基于管道过滤器模式设计的:
输入:源程序
预处理:负责宏展开和去掉注释等工作。
编译:进行词法分析、语法分析、语义分析、代码优化和代码产生。
汇编:负责把汇编代码转换成机器指令,生成目标文件。
链接:负责把多个目标文件、静态库和共享库链接成可执行文件/共享库。
输出:可执行文件/共享库。
二、复合过滤器
过滤器可以由多个其它过滤器组合起来的,比如上面的“编译”过程可以认为是一个复合过滤器:
词法分析:负责将源程序分解成一个一个的token,这些token是组成源程序的基本单元。
语法分析:把词法分析得到的token解析成语法树。
语义分析:对语法树进行类型检查等语义分析。
代码优化:对语法树进行重组和修改,以优化代码的速度和大小。
代码产生:根据语法树产生汇编代码。
输出:汇编代码。
三、支持多个输入的过滤器
过滤器可以有多个输入。比如上面“链接”,它接收多个输入:
四、具有多个输出的过滤器
过滤器可以有多个输出。如多媒体播放器的解码过程:
分离器:把音频和视频数据分离成两个流,音频数据传递给音频解码器,视频数据传递给视频解码器。
音频解码器:把压缩的音频数据解码成原始的音频数据。
视频解码器:把压缩的视频数据解码成原始的图像数据。
输出:音频数据传递给声卡,图像数据传递给显示器。
管道过滤器是最贴近程序员生活的模式,也是Unix-like系统的基本设计理念之一。作为Linux下的程序员,我们天天都使用这个模式。比如:
1、删除当前目录及子目录下的目标文件:
find -name \*.o|xargs rm –f
find是过滤器:它找出所有目标文件,它不需要关心查找文件的目的。
rm是过滤器:它删除找到目标文件,rm不需要关心文件名是如何得来的。
2、查看某个进程的栈的大小
grep stack /proc/2976/maps|sed -e “s/-/ /”|awk ‘{print strtonum(“0x”$2)-strtonum(“0x”$1)}’
/proc/2976/maps是进程2976内存映射表。内容可能如下:
00110000-00111000 r-xp 00110000 00:00 0 [vdso] 00111000-0011b000 r-xp 00000000 08:01 154857 /lib/libnss_files-2.8.so 0011b000-0011c000 r--p 0000a000 08:01 154857 /lib/libnss_files-2.8.so 0011c000-0011d000 rw-p 0000b000 08:01 154857 /lib/libnss_files-2.8.so 00907000-00923000 r-xp 00000000 08:01 157280 /lib/ld-2.8.so 00923000-00924000 r--p 0001c000 08:01 157280 /lib/ld-2.8.so 00924000-00925000 rw-p 0001d000 08:01 157280 /lib/ld-2.8.so 00927000-00a8a000 r-xp 00000000 08:01 157281 /lib/libc-2.8.so 00a8a000-00a8c000 r--p 00163000 08:01 157281 /lib/libc-2.8.so 00a8c000-00a8d000 rw-p 00165000 08:01 157281 /lib/libc-2.8.so 00a8d000-00a90000 rw-p 00a8d000 00:00 0 00abd000-00ac0000 r-xp 00000000 08:01 157284 /lib/libdl-2.8.so 00ac0000-00ac1000 r--p 00002000 08:01 157284 /lib/libdl-2.8.so 00ac1000-00ac2000 rw-p 00003000 08:01 157284 /lib/libdl-2.8.so 0383f000-03855000 r-xp 00000000 08:01 157307 /lib/libtinfo.so.5.6 03855000-03858000 rw-p 00015000 08:01 157307 /lib/libtinfo.so.5.6 08047000-080fa000 r-xp 00000000 08:01 1180910 /bin/bash 080fa000-080ff000 rw-p 000b3000 08:01 1180910 /bin/bash 080ff000-08104000 rw-p 080ff000 00:00 0 088bd000-088ff000 rw-p 088bd000 00:00 0 [heap] b7bfb000-b7bfd000 rw-p b7bfb000 00:00 0 b7bfd000-b7c04000 r--s 00000000 08:01 237138 /usr/lib/gconv/gconv-modules.cache b7c04000-b7d1e000 r--p 047d3000 08:01 237437 /usr/lib/locale/locale-archive b7d1e000-b7d5e000 r--p 0236e000 08:01 237437 /usr/lib/locale/locale-archive b7d5e000-b7f5e000 r--p 00000000 08:01 237437 /usr/lib/locale/locale-archive b7f5e000-b7f60000 rw-p b7f5e000 00:00 0 bfe5e000-bfe73000 rw-p bffeb000 00:00 0 [stack]grep是过滤器:它从文件/proc/2976/maps里找到下面这行数据。
bfe5e000-bfe73000 rw-p bffeb000 00:00 0 [stack]
sed是过滤器:它把‘-’替换成‘ ’,数据变成下面的内容。
bfe5e000 bfe73000 rw-p bffeb000 00:00 0 [stack]
awk是过滤器:它计算0xbfe73000和0x bfe5e000差值,并打印出来。