小箱子有多大——取值范围
2015年05月20日,在纳斯达克上市的苹果公司市值达到了 7628.40 亿美元,是有史以来市值最高的公司,并且最有希望成为世界上第一个市值破万亿的公司。乔布斯辞世后,很多人质疑库克能不能再创辉煌,数据不会说谎,苹果公司市值已经翻倍,乔布斯没有选错接班人,iPhone 6 也顺应了大屏手机的趋势。
那么,我们不妨将苹果公司的市值输出一下,看看是多长的一串数字:
The market value of AAPL is 538082304 !
让人惊讶的是,市值瞬间蒸发,只剩下 5.38 亿美元,与达内的市值相当,刚刚够上市的体量。
这是因为,一般情况下 int 类型在内存中占用 4 个字节的空间,也就是32位,理论上所能表示的最大数是 2^32 - 1 = 0xFFFFFFFF = 4,294,967,296 ≈ 42.95 亿,7628.40 亿显然超出了它的范围,会发生溢出(Overflow)。就像水一样,多出的会流到木桶外面,如果数字超过32位,比如35位,那么就会有3位丢失,当然不能表示原来的值。
我们来验证一下 int 的最大值:
The maximum value of "int" is -1 .
这和我们期望的结果不一样:我们期望输出 4294967296,但实际输出的却是八竿子打不着的 -1。
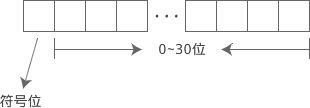
这是因为,整数有正负之分,我们需要在32位中选择一位用来标明到底是正数还是负数,这一位就是最高位。也就是说,0~30位表示数值,31 位表示正负号。如下图所示:
我们来验证一下上面的说法:
a=1234, a(u)=1234
a1=1234, a1(u)=1234
b=2147483647, b(u)=2147483647
c=-2147483648, c(u)=2147483648
d=-1, d(u)=4294967295
e=-1, e(u)=4294967295
我们发现,无论变量声明为 int 还是 unsigned,只有当以 %u 格式输出时,才会作为无符号数处理;如果声明为 unsigned,却以 d% 输出,那么也是有符号数。
为了更加灵活的表示数据,合理利用内存资源,C语言还使用另外两个关键字来表示整数,那就是 short 和long。short 表示短整型,long 表示长整型,这里的“长短”是针对 int 来说的。C语言规定,short 的长度不能大于 int,long 的长度不能小于 int。
现在的计算机已经甩开8086几条街,CPU、操作系统、编译器都已经支持到32位或者64位,所以 short 一般占2个字节,int 占 4 个字节,long 也占 4 个字节。
你看,C语言为了兼容硬件,追求效率,对数据类型的规定不是那么严谨,short 不一定真的“短”,long 也不一定真的“长”,这增加了我们学习和开发的成本。
char 的长度始终都是1个字节。
float 的长度为 4 个字节,是单精度浮点数。为了更加精确,表示更大或者更小的浮点数,可以使用 double。double 占用 8 个字节,是双精度浮点数。
最后,我们来总结一下现代计算机中各种数据类型的长度。
注意:unsigned 表示有无正负号,不会影响数据类型长度。
int = 4
float = 4
double = 8
A = 1
23 = 4
14.67 = 8
sizeof 的操作数既可以是变量、数据类型,还可以是某个具体的数据。细心的读者会发现,sizeof(14.67) 的结果是8,不错,因为小数默认的类型就是double。
那么,我们不妨将苹果公司的市值输出一下,看看是多长的一串数字:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int value=7628400000000;
// AAPL 是苹果公司的股票代码
printf("The market value of AAPL is %d !\n", value);
system("pause");
return 0;
}
输出结果:The market value of AAPL is 538082304 !
让人惊讶的是,市值瞬间蒸发,只剩下 5.38 亿美元,与达内的市值相当,刚刚够上市的体量。
这是因为,一般情况下 int 类型在内存中占用 4 个字节的空间,也就是32位,理论上所能表示的最大数是 2^32 - 1 = 0xFFFFFFFF = 4,294,967,296 ≈ 42.95 亿,7628.40 亿显然超出了它的范围,会发生溢出(Overflow)。就像水一样,多出的会流到木桶外面,如果数字超过32位,比如35位,那么就会有3位丢失,当然不能表示原来的值。
我们来验证一下 int 的最大值:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int value=0xffffffff;
printf("The maximum value of \"int\" is %d .\n", value);
system("pause");
return 0;
}
运行结果:The maximum value of "int" is -1 .
这和我们期望的结果不一样:我们期望输出 4294967296,但实际输出的却是八竿子打不着的 -1。
这是因为,整数有正负之分,我们需要在32位中选择一位用来标明到底是正数还是负数,这一位就是最高位。也就是说,0~30位表示数值,31 位表示正负号。如下图所示:
注意:在编程语言中,计数往往是从0开始,例如字符串 "abc123",我们称第 0 个字符是 a,第 1 个字符是 b,第 5 个字符是 3。这和我们平时从 1 开始计数的习惯不一样,大家要慢慢适应,培养编程思维。如果我们希望能表示更大些的数值,也可以不使用符号位,而用关键字
unsigned来声明变量,例如:
// 下面的两种写法都是正确的,使用 unsigned 时可以不写 int unsigned int a=100; unsigned a=999;这样,就只能表示正数了。unsigned 类型的整数需要用
%u来输出。我们来验证一下上面的说法:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int a=1234;
unsigned a1=1234;
int b=0x7fffffff;
int c=0x80000000; // 0x80000000 = 0x7fffffff + 0x1
int d=0xffffffff;
unsigned e=0xffffffff;
printf("a=%d, a(u)=%u\n", a, a);
printf("a1=%d, a1(u)=%u\n", a1, a1);
printf("b=%d, b(u)=%u\n", b, b);
printf("c=%d, c(u)=%u\n", c, c);
printf("d=%d, d(u)=%u\n", d, d);
printf("e=%d, e(u)=%u\n", e, e);
system("pause");
return 0;
}
输出结果:a=1234, a(u)=1234
a1=1234, a1(u)=1234
b=2147483647, b(u)=2147483647
c=-2147483648, c(u)=2147483648
d=-1, d(u)=4294967295
e=-1, e(u)=4294967295
我们发现,无论变量声明为 int 还是 unsigned,只有当以 %u 格式输出时,才会作为无符号数处理;如果声明为 unsigned,却以 d% 输出,那么也是有符号数。
为了更加灵活的表示数据,合理利用内存资源,C语言还使用另外两个关键字来表示整数,那就是 short 和long。short 表示短整型,long 表示长整型,这里的“长短”是针对 int 来说的。C语言规定,short 的长度不能大于 int,long 的长度不能小于 int。
unsigned表示有无符号位,short、int、long表示所占内存的大小,不要混淆,请看下面的例子:
long int a=1234; long b=299; unsigned long int c=999; unsigned long d=98720; short int m=222; short n=2094; unsigned short int p=3099; unsigned int q=68893;值得一提的是:C语言是70年代的产物,那个时候以及后面的十几年,是8086的天下,计算机的软硬件都是16位的,按照C语言的规定,short 一般占2个字节,int 也占2个字节,long 占4个字节。
现在的计算机已经甩开8086几条街,CPU、操作系统、编译器都已经支持到32位或者64位,所以 short 一般占2个字节,int 占 4 个字节,long 也占 4 个字节。
你看,C语言为了兼容硬件,追求效率,对数据类型的规定不是那么严谨,short 不一定真的“短”,long 也不一定真的“长”,这增加了我们学习和开发的成本。
在Java中不存在这样的情况,数据类型的长度是板上钉钉的,short 一定是 2 个字节,int 是 4 个字节,long 是 8 个字节,多么简单。但这是以牺牲效率为代价的。在编程语言中,简单和效率一直是相互矛盾的,几个语句搞定的代码往往效率不高,追求高效的代码往往需要自己实现,可能要几百行。
其他数据类型的长度
现在的计算机软硬件配置都已经支持到32位或者64位,这里以及后面提到的数据类型长度,都只考虑现代计算机,不再关心古董机器——16位机。char 的长度始终都是1个字节。
float 的长度为 4 个字节,是单精度浮点数。为了更加精确,表示更大或者更小的浮点数,可以使用 double。double 占用 8 个字节,是双精度浮点数。
最后,我们来总结一下现代计算机中各种数据类型的长度。
| 说 明 | 字符型 | 短整型 | 整型 | 长整型 | 单精度浮点型 | 双精度浮点型 |
|---|---|---|---|---|---|---|
| 数据类型 | char | short | int | long | float | double |
| 所占字节 | 1 | 2 | 4 | 4 | 4 | 8 |
注意:unsigned 表示有无正负号,不会影响数据类型长度。
sizeof
sizeof 用来计算数据所占用的内存空间,以字节计。如果你忘记了某个数据类型的长度,可以用 sizeof 求得,请看下面的代码:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int m=290;
float n=23;
printf("int = %d\n", sizeof(m));
printf("float = %d\n", sizeof(n));
printf("double = %d\n", sizeof(double));
printf("A = %d\n", sizeof('A'));
printf("23 = %d\n", sizeof(23));
printf("14.67 = %d\n", sizeof(14.67));
system("pause");
return 0;
}
输出结果:int = 4
float = 4
double = 8
A = 1
23 = 4
14.67 = 8
sizeof 的操作数既可以是变量、数据类型,还可以是某个具体的数据。细心的读者会发现,sizeof(14.67) 的结果是8,不错,因为小数默认的类型就是double。