深入内存模型和函数调用机制,理解析构函数的执行顺序
上一节的例子中,我们通过 Student 类依次创建了3个对象,分别是 stu1、stu2、stu3,但它们对应的析构函数的执行顺序却是相反的,这是为什么呢?
要搞清楚这个问题,首先要明白C++内存模型,也就是C++的代码和数据在内存中是如何存储的。C++内存模型和C语言类似(有部分细节不同),你可以参照C语言内存模型来理解。
在内存模型中有一块区域叫做栈区,它是由系统维护的(程序员无法操作),用来存储函数的参数、局部变量等,类似于数据结构中的栈,也是先进后出。
当遇到函数调用时,首先将下一条指令的地址压入栈区,然后将函数参数压入栈区,随着函数的执行,再将局部变量(或对象)按顺序压入栈区。
栈区是先进后出的结构,当函数执行结束后,先把最后压入的变量(或对象)弹出,以此类推,最后把第一个压入的变量弹出。接下来,再按照先进后出的规则弹出函数参数,弹出下一条指令地址。有了下一条指令的地址,函数调用结束后才能够继续执行后面的代码。
所谓弹出变量,就是销毁变量,清空变量所占用的资源。如果这个变量是一个对象,那么就会执行析构函数。
上节例子中,三个对象入栈的顺序依次是 stu1、stu2、stu3,出栈(销毁)的顺序依次是 stu3、stu2、stu1,如下图所示:
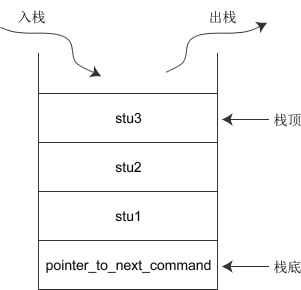
它们对应的析构函数的执行顺序也就一目了然了。
要搞清楚这个问题,首先要明白C++内存模型,也就是C++的代码和数据在内存中是如何存储的。C++内存模型和C语言类似(有部分细节不同),你可以参照C语言内存模型来理解。
在内存模型中有一块区域叫做栈区,它是由系统维护的(程序员无法操作),用来存储函数的参数、局部变量等,类似于数据结构中的栈,也是先进后出。
当遇到函数调用时,首先将下一条指令的地址压入栈区,然后将函数参数压入栈区,随着函数的执行,再将局部变量(或对象)按顺序压入栈区。
栈区是先进后出的结构,当函数执行结束后,先把最后压入的变量(或对象)弹出,以此类推,最后把第一个压入的变量弹出。接下来,再按照先进后出的规则弹出函数参数,弹出下一条指令地址。有了下一条指令的地址,函数调用结束后才能够继续执行后面的代码。
所谓弹出变量,就是销毁变量,清空变量所占用的资源。如果这个变量是一个对象,那么就会执行析构函数。
上节例子中,三个对象入栈的顺序依次是 stu1、stu2、stu3,出栈(销毁)的顺序依次是 stu3、stu2、stu1,如下图所示:
它们对应的析构函数的执行顺序也就一目了然了。
main() 函数没有参数,所以只有下一条指令的地址和局部变量入栈。