用图片搜索图片是怎么回事?

如果你去问同学或者同事,估计没人知道,因为她不是什么明星,也不是什么网红,更不是王思聪的第99个女盆友。
你手里只有一张图片,没有其他信息,但是你又非常想认识这位小姐姐,怎么办呢?
你可以去请教老司机,他会让你使用搜索引擎(百度、谷歌、搜狗等)的“以图搜图”功能,也就是上传一张图片,找到图片的相关信息,或者找到更多类似的图片。
在百度的“图片搜索”里上传这张图片,经过图像识别后,会得到以下的信息:
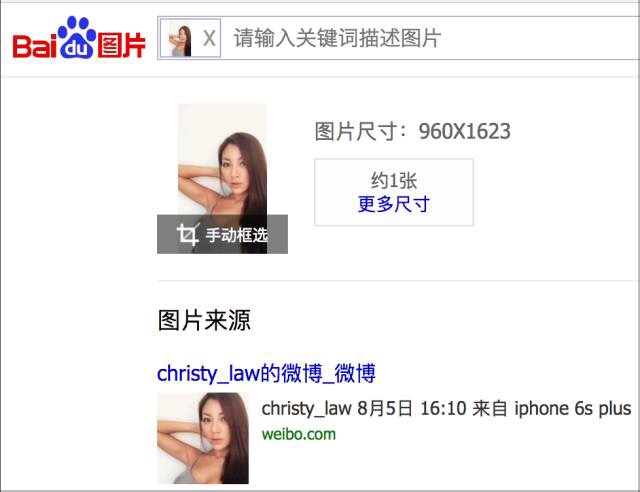
各位男同胞们可以看一下小姐姐的微博,相信会惊爆你的眼球。互联网就是这么强大,只要你有一点点线索,就能把一个人的老底翻个遍。
好了,言归正传,作为一个科普技术的公众号,今天我要向大家介绍的是“以图搜图”的实现原理。
说起搜索技术,其实是一个匹配的过程。我们最常用的是文本搜索,在百度里输入几个关键字,就能找到与此相关的网页。
站在编程的角度,判断两段文本是不是一样很容易,直接比较字符串就可以。对于搜索引擎,当然要复杂一些,会涉及到“倒排索引”“PR值”等算法,它们主要用来加快搜索速度,确定网页排名。
文本很容易作比较,但是换成图片就不一样了。“以图搜图”面临的首要问题,就是如何判断两张图片是相似的。
图片本身是二进制数据,最简单的办法,就是通过对比二进制数据来判断。但是图片的体积往往比较大,小的有几十KB,大的几十MB,等你对比完了,小姐姐的微博可能都关闭了。
另外,图片的格式不一样,尺寸不一样,精度不一样,相应的二进制数据也会有天壤之别,所以直接比较二进制数据几乎是不可行的。
“以图搜图”使用的是一种快速的、模糊的匹配算法。它仿照人眼对图片相似度的判断,只要两张图片的整体轮廓和大致颜色一样,就可以认为两张图片是相似的,至于图片是什么格式,大小和精度如何,都不再重要了。
“感知哈希算法”可以做到这一点,它的作用是对每张图片生成一段文本,当用户搜索时,比较的是不同图片的文本。文本越接近,图片就越相似。这又回到了刚才的文本匹配技术,这就简单了。
“感知哈希算法”大致分为以下几个步骤:
1) 缩小尺寸
将图片缩小到8*8的尺寸,总共64个像素。这一步的作用是去除图片的细节,只保留整体轮廓、明暗等基本信息,摒弃不同尺寸、比例带来的图片差异。缩小的结果就是整个图片变得模糊了,但是基本的结构还在。
2) 简化色彩
将彩色图片转换成黑白图片,去除颜色的影响。
3) 计算灰度平均值
定义了“灰度”以后,就可以用 1~64 中的某个数字来表示像素的颜色;也就是说,每个像素都对应 1~64 中的一个值。缩小后的图片有64个像素,也就有64个值,我们可以计算出这64个值的平均值,得到64个像素的平均灰度。
4) 得到哈希值
将每个像素的灰度与平均值相比较,大于或等于平均值记作 1,小于平均值记作 0,这样就能够得到64个0和1的组合,例如:1100 0000 1111 1010 1100 0101 0011 1000 0001 1011 1001 0100 0110 0001 1000 1010我们将这一串0和1的组合称为图片的哈希值(hash),它就是一段文本。
5) 对比哈希值
对比两张图片的时候,可以直接对比它们的哈希值,64个0和1里面,相同的越多就越相似。这就回到了传统的文本匹配技术,问题就简单了。总起来说,“感知哈希算法”就是忽略图片的格式、大小、精度等因素,把图片的整体轮廓和大致颜色提取出来,生成一段由0和1组成的文本,从而加快比较速度。
我们可以拓展一下思路,微信摇一摇里的“听歌识曲”、公安局的“人脸识别”也是类似的原理,都是提取二进制数据的主要特征,形成一段文本,最终转换成文本匹配的问题。