3.3字符型数据与整型数据
了解了变量与常量的关,再来看一看不同数据类型究竟有什么区别。前面程序中的延时
程序是这么写的:
void mDelay(unsigned int DelayTime)
{ unsigned int j=0;
for(;DelayTime>0;DelayTime--)
{ for(j=0;j<125;j++)
{;}
}
}
在main 函数中用mDelay(1000)的形式调用该函数时,延时时间约为1s。如果将该函数
中的unsigned int j 改为unsigned char j,其他任何地方都不作更改,重新编译、连接
后,可以发现延迟时间变为约0.38s。int 和char 是C 语言中的两种不同的数据类型,可见
程序中仅改变数据类型就会得到不同的结果。那么int 和char 型的数据究竟有什么区别呢?
3.3.1 整型数据
1.整型数据在内存中的存放形式
如果定义了一个 int 型变量i:
int i=10; /*定义i 为整型变量,并将10 赋给该变量*/
在Keil C 中规定使用二个字节表示int 型数据,因此,变量i 在内存中的实际占用情况
如下:
0000,0000,0000,1010
也就是整型数据总是用2 个字节存放,不足部分用0 补齐。
事实上,数据是以补码的形式存在的。一个正数的补码和其原码的形式是相同的。如果
数值是负的,补码的形式就不一样了。求负数的补码的方法是:将该数的绝对值的二进制形
式取反加1.例如,-10,第一步取-10 的绝对值10,其二进制编码是1010,由于是整型数占
2 个字节(16 位),所以其二进制形式实为0000,0000,0000,1010,取反,即变为1111,
1111,1111,0101,然后再加1 变成了1111,1111,1111,0110,这个就是数-10 在内存中
的存放形式。这里其实只要搞清一点,就是必须补足16 位,其它的都不难理解。
2.整型变量的分类
整型变量的基本类型是 int,可以加上有关数值范围的修饰符。这些修饰符分两类,一
类是short 和long,另一类是unsigned,这两类可以同时使用。下面就来看有关这些修饰符
的内容。
在 int 前加上short 或long 是表示数的大小的,对于keil C 来说,加short 和不加short
是一模一样的(在有一些C 语言编译系统中是不一样的),所以,short 就不加讨论了。如果
在int 前加上long 的修饰符,那么这个数就被称之为长整数,在keil C 中,长整数要用4个
字节来存放(基本的int 型是2个字节)。显然,长整数所能表达的范围比整数要大,一个
长整数表达的范围可以有:
-231<x<231-1
大概是在正负21 亿多。而不加long 修饰的int 型数据的范围是-32768~32767,可见,
二者相差很远。
第二类修饰符是 unsigned 即无符号的意思,如果加上了这样的一个修饰符,就说明其
后的数是一个无符号的数,无符号、有符号的差别还是数的范围不一样。对于unsigned int
而言,仍是用2 个字节(16 位)表示一个数,但其数的范围是0~65535,对于unsigned long
int 而言,仍是用4 个字节(32 位)表示一个数,但其数的范围是0~232-1。
3.3.2 字符型数据
1.字符型数据在内存中的存放形式
数据在内存中是以二进制形式存放的,如果定义了一个 char 型变量c:
char c=10; /*定义c 为字符型变量,并将10 赋给该变量*/
十进制数10 的二进制形式为1010,在Keil C 中规定使用一个字节表示char 型数据,
因此,变量c 在内存中的实际占用情如下:
0000,1010
弄明白了整型数据和字符型数据在内存中的存放,两者在前述程序中引起的差别就不难
主理解了,当使用int 型变量时,程序需要对16 位二进制码运算,而80C51 是8 位机,一
次只能处理8 位二进制码,所以就要分次处理,因此延迟时间就变长了。
2.字符型变量的分类
字符型变量只有一个修饰符 unsigned 即无符号的。对于一个字符型变量来说,其表达
的范围是-128~+127,而加上了unsigned 后,其表达的范围变为0~255。
加了 unsigned 和没有加究竟有何区别呢?其实对于二进制形式而言,char 型变量表达
的范围都是0000,0000~1111,1111 , 而int 型变量表达的范围都是
0000,0000,0000,0000~1111,1111,1111,1111,只是我们对这些二进制数的理解不一样而已。
使用 keil C 时,不论是char 型还是int 型,我们都非常喜欢用unsigned 型的数据,这是
因为在处理有符号的数时,程序要对符号进行判断和处理,运算的速度会减慢。
对单片机而言,速度比不上PC 机,又工作于实时状态,任何提高效率的手段都要考虑。
3.字符的处理
在一般的 C 语言中,字符型变量常用处理字符,如:
char c=’a’;
之类等,即是定义一个字符型的变量c,然后将字符a 赋给该变量。进行这一操作时,
实际是将字符a 的ASCII 码值赋给变量c,因此,做完这一操作之后,c 的值是97。
既然字符最终也是以数值来存储的,那么和以下的语句:
int i=97;
究竟有多大的区别呢?实际上它们是非常类似的,区别仅仅在于i 是16 位的,而c 是8
位的,当i 的值不超过255 时,两者完全可以互换。C 语言对定符型数据作这样的处理使用
得程序设计时增大了自由度。典型地,在C 语言中要将一个大写字母转化为一个小写字母,
只要简单地将该变量加上32 即可(查ASCII 码表可以看到任意一个大写字母比小写字母小
32)。由于这一点,我们在单片机中往往是把字符型变量当成一个“8 位的整型变量”来用。
4.数的溢出
一个字符型数的最大值是 127,一个整型数的最大值是32767,如果再加1,会出现什
么情况呢?下面我们用一个例子来说明。
例:演示字符型数据和整型数据溢出的例子
#includee “reg51.h”
void main()
{ unsigned char a,b;
int c,d;
a=255;
c=32767;
b=a+1;
d=a+1;
}
输入该文件,命名为exam23.c,建立工程,加
入该文件,在C 优化页将优化级别设为0,避免C
编译器认为这种程序无意义而自动优化使我们不能
得到想要的结果。编译、连接后,运行,查看变量,
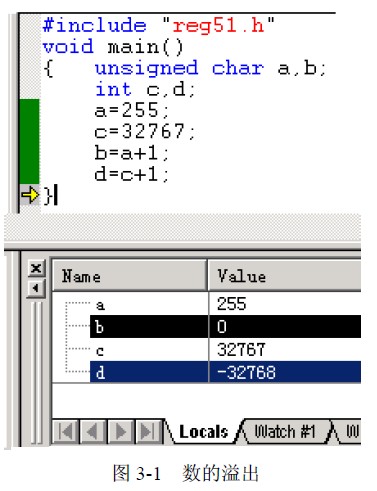
如图3-1 所示。
可见,b 和d 在加1 之后分别变成了0 和-32768,
这是为什么呢?这与我们的数学计算显然不同。其实
只要我们从数字在内存中的二进制存放形式分析,就
不难理解。
首先看变量 a,该变量的值是255,类型是无符
号字符型,因此,该变量在内存中以8 位(一个字节)
来存放,将255 转化为二进制即1111,1111,如果将
该值加1,结果是1,0000,0000,由于该变量只能存放
8 位,所以最高位的1 丢失,于是该数字就变也了
0000,0000,自然就是十进制的0 了。其实这不难理
解,录音机上有磁带计数器,共有3 位,当转到999 后,再转一圈,本应是1000,但实际
看到的是000,除非你借助于其他方法,否则你是无法判断其是转了1000 转还是根本没有
动。
在理解了无符号的字符型数据的溢出后,整型变量的溢出也不难理解。32767 在内存中
存放的形式是0111,1111,1111,1111,当其加1 后就变成了1000,0000,0000,0000,而这个二进
制数正是-32768 在内存中的存放形式,所以c 加1 后就变成了-32768。
可见,在出现这样的问题时C 编译系统不会给出提示(其他语言中BASIC 等会报告出
错),这有利于编出灵活的程序来,但也会引起一些副作用,这就要求C 程序员对硬件知识
有较多的了解,对于数在内存中的存放等基本知识必须清楚。
程序是这么写的:
void mDelay(unsigned int DelayTime)
{ unsigned int j=0;
for(;DelayTime>0;DelayTime--)
{ for(j=0;j<125;j++)
{;}
}
}
在main 函数中用mDelay(1000)的形式调用该函数时,延时时间约为1s。如果将该函数
中的unsigned int j 改为unsigned char j,其他任何地方都不作更改,重新编译、连接
后,可以发现延迟时间变为约0.38s。int 和char 是C 语言中的两种不同的数据类型,可见
程序中仅改变数据类型就会得到不同的结果。那么int 和char 型的数据究竟有什么区别呢?
3.3.1 整型数据
1.整型数据在内存中的存放形式
如果定义了一个 int 型变量i:
int i=10; /*定义i 为整型变量,并将10 赋给该变量*/
在Keil C 中规定使用二个字节表示int 型数据,因此,变量i 在内存中的实际占用情况
如下:
0000,0000,0000,1010
也就是整型数据总是用2 个字节存放,不足部分用0 补齐。
事实上,数据是以补码的形式存在的。一个正数的补码和其原码的形式是相同的。如果
数值是负的,补码的形式就不一样了。求负数的补码的方法是:将该数的绝对值的二进制形
式取反加1.例如,-10,第一步取-10 的绝对值10,其二进制编码是1010,由于是整型数占
2 个字节(16 位),所以其二进制形式实为0000,0000,0000,1010,取反,即变为1111,
1111,1111,0101,然后再加1 变成了1111,1111,1111,0110,这个就是数-10 在内存中
的存放形式。这里其实只要搞清一点,就是必须补足16 位,其它的都不难理解。
2.整型变量的分类
整型变量的基本类型是 int,可以加上有关数值范围的修饰符。这些修饰符分两类,一
类是short 和long,另一类是unsigned,这两类可以同时使用。下面就来看有关这些修饰符
的内容。
在 int 前加上short 或long 是表示数的大小的,对于keil C 来说,加short 和不加short
是一模一样的(在有一些C 语言编译系统中是不一样的),所以,short 就不加讨论了。如果
在int 前加上long 的修饰符,那么这个数就被称之为长整数,在keil C 中,长整数要用4个
字节来存放(基本的int 型是2个字节)。显然,长整数所能表达的范围比整数要大,一个
长整数表达的范围可以有:
-231<x<231-1
大概是在正负21 亿多。而不加long 修饰的int 型数据的范围是-32768~32767,可见,
二者相差很远。
第二类修饰符是 unsigned 即无符号的意思,如果加上了这样的一个修饰符,就说明其
后的数是一个无符号的数,无符号、有符号的差别还是数的范围不一样。对于unsigned int
而言,仍是用2 个字节(16 位)表示一个数,但其数的范围是0~65535,对于unsigned long
int 而言,仍是用4 个字节(32 位)表示一个数,但其数的范围是0~232-1。
3.3.2 字符型数据
1.字符型数据在内存中的存放形式
数据在内存中是以二进制形式存放的,如果定义了一个 char 型变量c:
char c=10; /*定义c 为字符型变量,并将10 赋给该变量*/
十进制数10 的二进制形式为1010,在Keil C 中规定使用一个字节表示char 型数据,
因此,变量c 在内存中的实际占用情如下:
0000,1010
弄明白了整型数据和字符型数据在内存中的存放,两者在前述程序中引起的差别就不难
主理解了,当使用int 型变量时,程序需要对16 位二进制码运算,而80C51 是8 位机,一
次只能处理8 位二进制码,所以就要分次处理,因此延迟时间就变长了。
2.字符型变量的分类
字符型变量只有一个修饰符 unsigned 即无符号的。对于一个字符型变量来说,其表达
的范围是-128~+127,而加上了unsigned 后,其表达的范围变为0~255。
加了 unsigned 和没有加究竟有何区别呢?其实对于二进制形式而言,char 型变量表达
的范围都是0000,0000~1111,1111 , 而int 型变量表达的范围都是
0000,0000,0000,0000~1111,1111,1111,1111,只是我们对这些二进制数的理解不一样而已。
使用 keil C 时,不论是char 型还是int 型,我们都非常喜欢用unsigned 型的数据,这是
因为在处理有符号的数时,程序要对符号进行判断和处理,运算的速度会减慢。
对单片机而言,速度比不上PC 机,又工作于实时状态,任何提高效率的手段都要考虑。
3.字符的处理
在一般的 C 语言中,字符型变量常用处理字符,如:
char c=’a’;
之类等,即是定义一个字符型的变量c,然后将字符a 赋给该变量。进行这一操作时,
实际是将字符a 的ASCII 码值赋给变量c,因此,做完这一操作之后,c 的值是97。
既然字符最终也是以数值来存储的,那么和以下的语句:
int i=97;
究竟有多大的区别呢?实际上它们是非常类似的,区别仅仅在于i 是16 位的,而c 是8
位的,当i 的值不超过255 时,两者完全可以互换。C 语言对定符型数据作这样的处理使用
得程序设计时增大了自由度。典型地,在C 语言中要将一个大写字母转化为一个小写字母,
只要简单地将该变量加上32 即可(查ASCII 码表可以看到任意一个大写字母比小写字母小
32)。由于这一点,我们在单片机中往往是把字符型变量当成一个“8 位的整型变量”来用。
4.数的溢出
一个字符型数的最大值是 127,一个整型数的最大值是32767,如果再加1,会出现什
么情况呢?下面我们用一个例子来说明。
例:演示字符型数据和整型数据溢出的例子
#includee “reg51.h”
void main()
{ unsigned char a,b;
int c,d;
a=255;
c=32767;
b=a+1;
d=a+1;
}
输入该文件,命名为exam23.c,建立工程,加
入该文件,在C 优化页将优化级别设为0,避免C
编译器认为这种程序无意义而自动优化使我们不能
得到想要的结果。编译、连接后,运行,查看变量,
如图3-1 所示。
可见,b 和d 在加1 之后分别变成了0 和-32768,
这是为什么呢?这与我们的数学计算显然不同。其实
只要我们从数字在内存中的二进制存放形式分析,就
不难理解。
首先看变量 a,该变量的值是255,类型是无符
号字符型,因此,该变量在内存中以8 位(一个字节)
来存放,将255 转化为二进制即1111,1111,如果将
该值加1,结果是1,0000,0000,由于该变量只能存放
8 位,所以最高位的1 丢失,于是该数字就变也了
0000,0000,自然就是十进制的0 了。其实这不难理
解,录音机上有磁带计数器,共有3 位,当转到999 后,再转一圈,本应是1000,但实际
看到的是000,除非你借助于其他方法,否则你是无法判断其是转了1000 转还是根本没有
动。
在理解了无符号的字符型数据的溢出后,整型变量的溢出也不难理解。32767 在内存中
存放的形式是0111,1111,1111,1111,当其加1 后就变成了1000,0000,0000,0000,而这个二进
制数正是-32768 在内存中的存放形式,所以c 加1 后就变成了-32768。
可见,在出现这样的问题时C 编译系统不会给出提示(其他语言中BASIC 等会报告出
错),这有利于编出灵活的程序来,但也会引起一些副作用,这就要求C 程序员对硬件知识
有较多的了解,对于数在内存中的存放等基本知识必须清楚。