汇编语言数据类型以及数据定义详解
汇编器识别一组基本的内部数据类型(intrinsic data type),按照数据大小(字节、字、双字等等)、是否有符号、是整数还是实数来描述其类型。这些类型有相当程度的重叠,例如,DWORD 类型(32 位,无符号整数)就可以和 SDWORD 类型(32 位,有符号整数)相互交换。
可能有人会说,程序员用 SDWORD 告诉读程序的人,这个值是有符号的,但是,对于汇编器来说这不是强制性的。汇编器只评估操作数的大小。因此,举例来说,程序员只能将 32 位整数指定为 DWORD、SDWORD 或者 REAL4 类型。
下表给出了全部内部数据类型的列表,有些表项中的 IEEE 符号指的是 IEEE 计算机学会出版的标准实数格式。
数据定义语法如下所示:
其中:
数据定义中至少要有一个初始值,即使该值为 0。其他初始值,如果有的话,用逗号分隔。对整数数据类型而言,初始值(initializer)是整数常量或是与变量类型,如 BYTE 或 WORD 相匹配的整数表达式。
如果程序员希望不对变量进行初始化(随机分配数值),可以用符号 ? 作为初始值。所有初始值,不论其格式,都由汇编器转换为二进制数据。 初始值 0011 0010b、32h 和 50d 都具有相同的二进制数值。
并不是所有的数据定义都要用标号。比如,在 list 后面继续添加字节数组,就可以在下一行定义它们:
行连续字符(\)把两个源代码行连接成一条语句,它必须是一行的最后一个字符。下面的语句是等价的:
DUP 操作符提供了一种方便的方法来声明数组:
示例下表列出了正、负十进制数 1234 的十六进制存储字节,排列顺序从最低有效字节到最高有效字节:
MASM 使用 TBYTE 伪指令来定义压缩 BCD 变量。常数初始值必须是十六进制的,因为,汇编器不会自动将十进制初始值转换为 BCD 码。下面的两个例子展示了十进制 数 -1234 有效和无效的表达方式:
如果想要把一个实数编码为压缩 BCD 码,可以先用 FLD 指令将该实数加载到浮点寄存器堆栈,再用 FBSTP 指令将其转换为压缩 BCD 码,该指令会把数值舍入到最接近的整数:
DD、DQ 和 DT 伪指令也可以定义实数:
在调试会话过程中,如果想要变量显示为十六进制,则按下述步骤操作:鼠标在变量或寄存器上悬停 1 秒,直到一个灰色矩形框出现在鼠标下。右键点击该矩形框,在弹出菜单中选择 Hexadecimal Display。
其他有些计算机系统采用的是大端顺序(高到低)。 下图展示了 12345678h 从偏移量 0000 开始的大端顺序存放。
可能有人会说,程序员用 SDWORD 告诉读程序的人,这个值是有符号的,但是,对于汇编器来说这不是强制性的。汇编器只评估操作数的大小。因此,举例来说,程序员只能将 32 位整数指定为 DWORD、SDWORD 或者 REAL4 类型。
下表给出了全部内部数据类型的列表,有些表项中的 IEEE 符号指的是 IEEE 计算机学会出版的标准实数格式。
| 类型 | 用法 |
|---|---|
| BYTE | 8 位无符号整数,B 代表字节 |
| SBYTE | 8 位有符号整数,S 代表有符号 |
| WORD | 16 位无符号整数 |
| SWORD | 16 位有符号整数 |
| DWORD | 32 位无符号整数,D 代表双(字) |
| SDWORD | 32 位有符号整数,SD 代表有符号双(字) |
| FWORD | 48 位整数(保护模式中的远指针) |
| QWORD | 64 位整数,Q 代表四(字) |
| TBYTE | 80 位(10 字节)整数,T 代表 10 字节 |
| REAL4 | 32 位(4 字节)IEEE 短实数 |
| REAL8 | 64 位(8 字节)IEEE 长实数 |
| REAL10 | 80 位(10 字节)IEEE 扩展实数 |
数据定义语句
数据定义语句(data definition statement)在内存中为变量留岀存储空间,并赋予一个可选的名字。数据定义语句根据内部数据类型(上表)定义变量。数据定义语法如下所示:
[name] directive initializer [,initializer]...
下面是数据定义语句的一个例子:count DWORD 12345
其中:
- 名字:分配给变量的可选名字必须遵守标识符规范。
- 伪指令:数据定义语句中的伪指令可以是 BYTE、WORD、DWORD、SBTYE、SWORD 或其他在上表中列出的类型。此外,它还可以是传统数据定义伪指令,如下表所示。
| 伪指令 | 用法 | 伪指令 | 用法 |
|---|---|---|---|
| DB | 8位整数 | DQ | 64 位整数或实数 |
| DW | 16 位整数 | DT | 定义 80 位(10 字节)整数 |
| DD | 32 位整数或实数 |
数据定义中至少要有一个初始值,即使该值为 0。其他初始值,如果有的话,用逗号分隔。对整数数据类型而言,初始值(initializer)是整数常量或是与变量类型,如 BYTE 或 WORD 相匹配的整数表达式。
如果程序员希望不对变量进行初始化(随机分配数值),可以用符号 ? 作为初始值。所有初始值,不论其格式,都由汇编器转换为二进制数据。 初始值 0011 0010b、32h 和 50d 都具有相同的二进制数值。
向 AddTwo 程序添加一个变量
前面《整数加减法》一节中介绍了 AddTwo 程序,现在创建它的一个新版本,并称为 AddTwoSum。这个版本引入了变量 sum,它出现在完整的程序清单中:
;AddTowSum.asm
.386
.model flat,stdcall
.stack 4096
ExitProcess PROTO, dwExitCode:DWORD
.data
sum DWORD 0
.code
main PROC
mov eax,5
add eax,6
mov sum,eax
INVOKE ExitProcess,0
main ENDP
END main
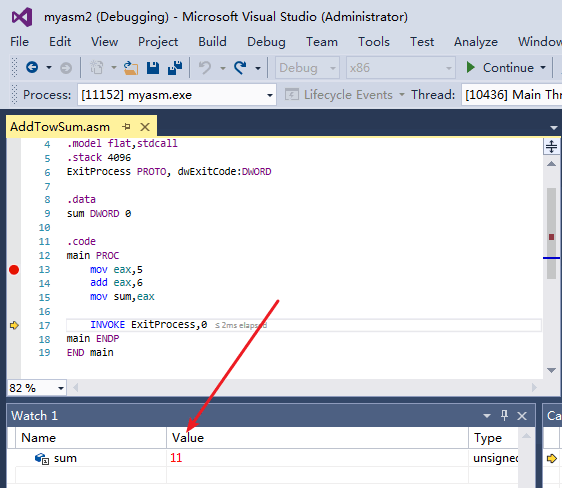
可以在第 13 行设置断点,每次执行一行,在调试器中单步执行该程序。执行完第 15 行后,将鼠标悬停在变量 sum 上,查看其值。或者打开一个 Watch 窗口,打开过程如下:在 Debug 菜单中选择 Windows(在调试会话中),选择 Watch,并在四个可用选项(Watch1,Watch2,Watch3 或 Watch4)中选择一个。然后,用鼠标高亮显示 sum 变量,将其拖拉到 Watch 窗口中。下图展示了一个例子,其中用大箭头指出了执行第 15 行后,sum 的当前值。定义 BYTE 和 SBYTE 数据
BYTE(定义字节)和 SBYTE(定义有符号字节)为一个或多个无符号或有符号数值分配存储空间。每个初始值在存储时,都必须是 8 位的。例如:value1 BYTE 'A' ;字符常量 value2 BYTE 0 ;最小无符号字节 value3 BYTE 255 ;最大无符号字节 value4 SBYTE -128 ;最小有符号字节 value5 SBYTE +127 ;最大有符号字节问号(?)初始值使得变量未初始化,这意味着在运行时分配数值到该变量:
value6 BYTE ?
可选名字是一个标号,标识从变量包含段的开始到该变量的偏移量。比如,如果 value1 在数据段偏移量为 0000 处,并在内存中占一个字节,则 value2 就自动处于偏移量为 0001 处:
value1 BYTE 10h
value2 BYTE 20h
val1 DB 255 ;无符号字节
val2 DB -128 ;有符号字节
1) 多初始值
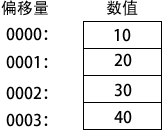
如果同一个数据定义中使用了多个初始值,那么它的标号只指出第一个初始值的偏移量。在下面的例子中,假设 list 的偏移量为 0000。那么,数值 10 的偏移量就为 0000, 20 的偏移量为 0001,30 的偏移量为 0002,40 的偏移量为 0003:list BYTE 10,20,30,40
下图给出了字节序列 list,显示了每个字节及其偏移量。并不是所有的数据定义都要用标号。比如,在 list 后面继续添加字节数组,就可以在下一行定义它们:
list BYTE 10,20,30,40
BYTE 50,60,70,80
BYTE 81,82,83,84
在单个数据定义中,其初始值可以使用不同的基数。字符和字符串常量也可以自由组合。在下面的例子中,list1 和 list2 有相同的内容:list1 BYTE 10, 32, 41h, 00100010b list2 BYTE 0Ah, 20h, 'A', 22h
2) 定义字符串
定义一个字符串,要用单引号或双引号将其括起来。最常见的字符串类型是用一个空字节(值为0)作为结束标记,称为以空字节结束的字符串,很多编程语言中都使用这种类型的字符串:greeting1 BYTE "Good afternoon",0 greeting2 BYTE 'Good night',0每个字符占一个字节的存储空间。对于字节数值必须用逗号分隔的规则而言,字符串是一个例外。如果没有这种例外,greeting1 就会被定义为:
greeting1 BYTE 'G', 'o', 'o', 'd'....etc.
这就显得很冗长。一个字符串可以分为多行,并且不用为每一行都添加标号:
greeting1 BYTE "Welcome to the Encryption Demo program "
BYTE "created by Kip Irvine.",0dh, 0ah
BYTE "If you wish to modify this program, please "
BYTE "send me a copy.",0dh,0ah,0
十六进制代码 0Dh 和 0Ah 也被称为 CR/LF (回车换行符)或行结束字符。在编写标准输出时,它们将光标移动到当前行的下一行的左侧。行连续字符(\)把两个源代码行连接成一条语句,它必须是一行的最后一个字符。下面的语句是等价的:
greeting1 BYTE "Welcome to the Encryption Demo program "
和
greeting1 \
BYTE "Welcome to the Encryption Demo program "
3) DUP 操作符
DUP 操作符使用一个整数表达式作为计数器,为多个数据项分配存储空间。在为字符串或数组分配存储空间时,这个操作符非常有用,它可以使用初始化或非初始化数据:BYTE 20 DUP ( 0 ) ;20 个字节,值都为 0 BYTE 20 DUP ( ? ) ;20 个字节,非初始化 BYTE 4 DUP ( "STACK" ) ; 20 个字节:
定义 WORD 和 SWORD 数据
WORD(定义字)和 SWORD(定义有符号字)伪指令为一个或多个 16 位整数分配存储空间:word1 WORD 65535 ;最大无符号数 word2 SWORD -32768 ;最小有符号数 word3 WORD ? ;未初始化,无符号也可以使用传统的 DW 伪指令:
val1 DW 65535 ;无符号 val2 DW -32768 ;有符号16 位字数组通过列举元素或使用 DUP 操作符来创建字数组。下面的数组包含了一组数值:
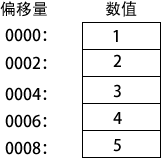
myList WORD 1,2,3,4,5
下图是一个数组在内存中的示意图,假设 myList 起始位置偏移量为0000。由于每个数值占两个字节,因此其地址递增量为 2。DUP 操作符提供了一种方便的方法来声明数组:
array WORD 5 DUP (?) ; 5 个数值,未初始化
定义 DWORD 和 SDWORD 数据
DWORD(定义双字)和 SDWORD(定义有符号双字)伪指令为一个或多个 32 位整数分配存储空间:val1 DWORD 12345678h ;无符号 val2 SDWORD -2147483648 ;有符号 val3 DWORD 20 DUP (?) ;无符号数组传统的 DD 伪指令也可以用来定义双字数据:
val1 DD 12345678h ;无符号 val2 DD -2147483648 ;有符号DWORD 还可以用于声明一种变量,这种变量包含的是另一个变量的 32 位偏移量。如下所示,pVal 包含的就是 val3 的偏移量:
pVal DWORD val3
32 位双字数组
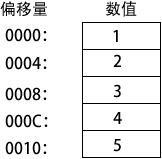
现在定义一个双字数组,并显式初始化它的每 一个值:myList DWORD 1,2,3,4,5
下图给岀了这个数组在内存中的示意图,假设 myList 起始位置偏移量为 0000,偏移量增量为 4。定义 QWORD 数据
QWORD(定义四字)伪指令为 64 位(8 字节)数值分配存储空间:quad1 QWORD 1234567812345678h
传统的 DQ 伪指令也可以用来定义四字数据:quad1 DQ 1234567812345678h
定义压缩 BCD(TBYTE)数据
Intel 把一个压缩的二进制编码的十进制(BCD, Binary Coded Decimal)整数存放在一个 10 字节的包中。每个字节(除了最高字节之外)包含两个十进制数字。在低 9 个存储字节中,每半个字节都存放了一个十进制数字。最高字节中,最高位表示该数的符号位。如果最高字节为 80h,该数就是负数;如果最高字节为 00h,该数就是正数。整数的范围是 -999 999 999 999 999 999 到 +999 999 999 999 999 999。示例下表列出了正、负十进制数 1234 的十六进制存储字节,排列顺序从最低有效字节到最高有效字节:
| 十进制数值 | 存储字节 |
|---|---|
| +1234 | 34 12 00 00 00 00 00 00 00 00 |
| -1234 | 34 12 00 00 00 00 00 00 00 80 |
MASM 使用 TBYTE 伪指令来定义压缩 BCD 变量。常数初始值必须是十六进制的,因为,汇编器不会自动将十进制初始值转换为 BCD 码。下面的两个例子展示了十进制 数 -1234 有效和无效的表达方式:
intVal TBYTE 800000000000001234h ;有效 intVal TBYTE -1234 ;无效第二个例子无效的原因是 MASM 将常数编码为二进制整数,而不是压缩 BCD 整数。
如果想要把一个实数编码为压缩 BCD 码,可以先用 FLD 指令将该实数加载到浮点寄存器堆栈,再用 FBSTP 指令将其转换为压缩 BCD 码,该指令会把数值舍入到最接近的整数:
.data posVal REAL8 1.5 bcdVal TBYTE ? .code fid posVal ;加载到浮点堆栈 fbstp bcdVal ;向上舍入到 2,压缩 BCD 码值如果 posVal 等于 1.5,结果 BCD 值就是 2。
定义浮点类型
REAL4 定义 4 字节单精度浮点变量。REAL8 定义 8 字节双精度数值,REAL10 定义 10 字节扩展精度数值。每个伪指令都需要一个或多个实常数初始值:rVal1 REAL4 -1.2 rVal2 REAL8 3.2E-260 rVal3 REAL10 4.6E+4096 ShortArray REAL4 20 DUP(0.0)下表描述了标准实类型的最少有效数字个数和近似范围:
| 数据类型 | 有效数字 | 近似范围 |
|---|---|---|
| 短实数 | 6 | 1.18x 10-38 to 3.40 x 1038 |
| 长实数 | 15 | 2.23 x 10-308 to 1.79 x 10308 |
| 扩展精度实数 | 19 | 3.37 x 10-4932 to 1.18 x 104932 |
DD、DQ 和 DT 伪指令也可以定义实数:
rVal1 DD -1.2 ;短实数 rVal2 DQ 3.2E-260 ;长实数 rVal3 DT 4.6E+4096 ;扩展精度实数MASM 汇编器包含了诸如 wal4 和 real8 的数据类型,这些类型表明数值是实数。更准确地说,这些数值是浮点数,其精度和范围都是有限的。从数学的角度来看,实数的精度和大小是无限的。
变量加法程序
到目前为止,本节的示例程序实现了存储在寄存器中的整数加法。现在已经对如何定义数据有了一些了解,那么可以对同样的程序进行修改,使之实现三个整数变量相加,并将和数存放到第四个变量中。
;AddTowSum.asm
.386
.model flat,stdcall
.stack 4096
ExitProcess PROTO, dwExitCode:DWORD
.data
firstval DWORD 20002000h
secondval DWORD 11111111h
thirdval DWORD 22222222h
sum DWORD 0
.code
main PROC
mov eax,firstval
add eax,secondval
add eax,thirdval
mov sum,eax
INVOKE ExitProcess,0
main ENDP
END main
注意,已经用非零数值对三个变量进行了初始化(9〜11 行)。16〜18 行进行变量相加。x86 指令集不允许将一个变量直接与另一个变量相加,但是允许一个变量与一个寄存器相加。这就是为什么 16〜17 行用 EAX 作累加器的原因:
mov eax,firstval
add eax,secondval
add eax,thirdval
最后,在第 19 行,和数被复制到名称为 sum 的变量中:mov sum,eax
作为练习,鼓励大家在调试会话中运行本程序,并在每条指令执行后检查每个寄存器。最终和数应为十六进制的 53335333。在调试会话过程中,如果想要变量显示为十六进制,则按下述步骤操作:鼠标在变量或寄存器上悬停 1 秒,直到一个灰色矩形框出现在鼠标下。右键点击该矩形框,在弹出菜单中选择 Hexadecimal Display。
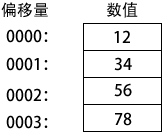
小端顺序
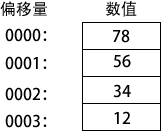
x86 处理器在内存中按小端(little-endian)顺序(低到高)存放和检索数据。最低有效字节存放在分配给该数据的第一个内存地址中,剩余字节存放在随后的连续内存位置中。考虑一个双字 12345678h。如果将其存放在偏移量为 0000 的位置,则 78h 存放在第一个字节,56h 存放在第二个字节,余下的字节存放地址偏移量为 0002 和 0003,如下图所示。其他有些计算机系统采用的是大端顺序(高到低)。 下图展示了 12345678h 从偏移量 0000 开始的大端顺序存放。
声明未初始化数据
.DATA ? 伪指令声明未初始化数据。当定义大量未初始化数据时,.DATA ? 伪指令减少了编译程序的大小。例如,下述代码是有效声明:.data smallArray DWORD 10 DUP (0) ;40 个字节 .data? bigArray DWORD 5000 DUP ( ? ) ;20 000 个字节,未初始化而另一方面,下述代码生成的编译程序将会多岀 20 000 个字节:
.data smallArray DWORD 10 DUP ( 0 ) ; 40 个字节 bigArray DWORD 5000 DUP ( ? ) ; 20 000 个字节代码与数据混合汇编器允许在程序中进行代码和数据的来回切换。比如,想要声明一个变量,使其只能在程序的局部区域中使用。下述示例在两个代码语句之间插入了一个名为 temp 的变量:
.code mov eax,ebx .data temp DWORD ? .code mov temp,eax尽管 temp 声明的出现打断了可执行指令流,MASM 还是会把 temp 放在数据段中,并与保持编译的代码段分隔开。然而同时,混用 .code 和 .data 伪指令会使得程序变得难以阅读。
所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频