Go语言死锁、活锁和饥饿概述
前面的部分都是关于程序正确性的讨论,如果这些问题得到正确的处理,那我们的程序将永远不会给出错误的答案。不幸的是,即使成功处理了这些问题,还有另一类问题需要解决:死锁、活锁和饥饿。所有这些问题都与你的程序密切相关,它们保证了你的程序在任何时候都在做着一些真正有用的事。如果没有正确处理,程序可能会进入一种完全停止正常工作的状态。
这听起来很严峻,那是因为的确如此!Go语言的运行时会尽其所能,检测一些死锁(所有的 goroutine 必须被阻塞,或者“asleep”),但是这对于防止死锁并没有太多的帮助。
为了帮助理解死锁是什么,我们先来看一个例子。同样,忽略任何你不知道的类型,函数,方法或是你不知道的包,只理解什么是死锁即可。
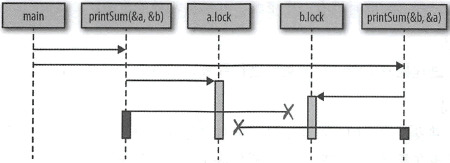
图 :一个因时间问题导致死锁的演示
本质上,我们创建了两个不能转动的齿轮:第一次调用 printSum 锁定 a,然后试图锁定 b ,但在此期间,第二次调用 printSum 己锁定 b 并试图锁定 a。这两个 goroutine 都无限地等待着。
以图形的方式展示为什么会出现死锁似乎很明确,但是更严格的定义会给我们带来更多的好处。事实证明,出现死锁有几个必要条件。1971 年,Edgar Coffman 在一篇论文中列举了这些条件。这些条件现在被称为 Coffman 条件,是帮助检测、防止和纠正死锁的技术依据。
Coffman 条件如下:
注意:我们实际上并不能保证 goroutines 的运行顺序,或者需妥多长时间才能启动。虽然不太可能,但是一个 goroutine 可以在另一个 goroutine 开始之前获得和释放锁,从而避免死锁,这是有道理的。
来看看我们设计的程序,并确定它是否符合所有四个条件:
是的,我们写出来的无疑是一个死锁了。
这些规则也帮助我们防止死锁。如果确保至少有一个条件不成立,我们可以防止发生死锁。不幸的是,实际上这些条件很难推理,因此很难预防。网络上散布着诸如你和我这样的开发者的疑问,他们想知道为什么一小段代码是死锁的。通常情况下,一旦有人指出,这是非常明显的,但往往需要另一双眼睛。
你曾经在走廊走向另一个人吗?她移动到一边让你通过,但你也做了同样的事情。所以你转到另一边,但她也是这样做的。想象一下这个情形永远持续下去,你就明白了活锁。
我们实际上编写一些代码来演示这种情况。首先,我们将设置一些辅助函数来简化示例。为了有一个可以工作的例子,这里的代码利用了我们尚未涉及的几个主题。不建议试图了解它的细节,直到有把握可以使用好 sync 包。相反,建议遵循代码标注来理解强调的部分,然后将注意力转向包含示例核心的第二个代码块。
这个例子横示了使用活锁的一个卡分常见的原因:两个或两个以上的并发进程试图在没有协调的情况下防止死锁。这就好比,如果走廊里的人都同意,只有一个人会移动,那就不会有活锁:一个人会站着不动,另一个人会移到另一边,他们就会继续移动。
在我看来,活锁要比死锁更复杂,因为它看起来程序好像在工作。如果一个活锁程序在你的机器上运行,那可以通过查看 CPU 利用率来确定它是否在做处理某些逻辑,大家可能会认为它确实是在工作。根据活锁的不同,它甚至可能发出其他信号,让大家认为它在工作。然而,程序将会一直上演“hallway-shuffle”的循环游戏。
活锁是一组被称为“饥饿”的更大问题的子集。
当我们讨论活锁时,每个 goroutine 的资源是一个共享锁。
活锁保证讨论与饥饿是无关的,因为在活锁中,所有并发进程都是相同的,并且没有完成工作。更广泛地说,饥饿通常意味着有一个或多个贪婪的并发进程,它们不公平地阻止一个或多个井发进程,以尽可能有效地完成工作,或者阻止全部并发进程。
这里有一个程序的例子,有一个贪婪的 goroutine 和一个平和的 goroutine:
假设两种 worker 都有同样大小的临界区,而不是认为贪婪的 worker 的算法更有效(或调用 Lock 和 Unlock 的时候,它们也不是缓慢的),我们得出这样的结论,贪婪的 worker 不必要地扩大其持有共享锁上的临界区,井阻止(通过饥饿)平和的 worker 的 goroutine 高效工作。
请注意,我们这里的技术用于识别饥饿:一个 metric。饥饿会为记录和取样提供一个很好的 metric。一个发现和解决饥饿的方曲是,通过记录来确定进程工作速度是否和你预期的一样高。
值得一提的是,前面的代码示例还可以作为内存访问同步的性能影响的示例。因为同步访问内存是昂贵的,所以将我们的锁扩展到临界段之外是有利的。另一方面,这样做我们将冒着饿死其他并发进程的风险。
如果使用了内存访问同步,将不得不在扭拉皮同步和细粒反同步之间找到一个平衡点。当需要对应用程序进行性能调优时,强烈建议只将内存访问同步限制在关键部分;如果同步成为性能问题,可以一直扩展范围。走另一条路妥难得多。
所以,饥饿会导致你的程序表现不佳或不正确。前面的示例演示了低效场景,但是如果你有一个非常贪婪的并发进程,以至于完全阻止另一个并发进程完成工作,那么你就会遇到一个更大的问题。
我们还应该考虑到来自于外部过程的饥饿。请记住,饥饿也可以应用于 CPU、内存、文件句柄、数据库连接:任何必须共享的资源都是饥饿的候选者。
死锁
死锁程序是所有并发进程彼此等待的程序。在这种情况下,如果没有外界的干预,这个程序将永远无法恢复。这听起来很严峻,那是因为的确如此!Go语言的运行时会尽其所能,检测一些死锁(所有的 goroutine 必须被阻塞,或者“asleep”),但是这对于防止死锁并没有太多的帮助。
为了帮助理解死锁是什么,我们先来看一个例子。同样,忽略任何你不知道的类型,函数,方法或是你不知道的包,只理解什么是死锁即可。
type value struct {
mu sync.Mutex
value int
}
var wg sync.WaitGroup
printSum := func(v1, v2 *value) {
defer wg.Done()
v1.mu.Lock() //在这里,我们尝试进入临界区来传入一个值。
defer v1.mu.Unlock() //在这里,我们使用defer语句在printSum返回之前退出临界区。
time.Sleep(2*time.Second) //在这里,我们休眠了一段时间来模拟一些工作(并触发死锁)
v2.mu.Lock()
defer v2.mu.Unlock()
fmt.Printf("sum=%v\n", v1.value + v2.value)
}
var a, b value
wg.Add(2)
go printSum(&a, &b)
go printSum(&b, &a)
wg.Wait()
如果尝试运行此代码,可能会看到:fatal error: all goroutines are asleep - deadlock!
为什么呢?如果仔细观察,就可以在此代码中看到时机问题。以下是运行时的图形表示。这些框表示函数,水平线表示调用这些函数,竖线表示图形头部的函数生存时间,如下图所示。图 :一个因时间问题导致死锁的演示
本质上,我们创建了两个不能转动的齿轮:第一次调用 printSum 锁定 a,然后试图锁定 b ,但在此期间,第二次调用 printSum 己锁定 b 并试图锁定 a。这两个 goroutine 都无限地等待着。
以图形的方式展示为什么会出现死锁似乎很明确,但是更严格的定义会给我们带来更多的好处。事实证明,出现死锁有几个必要条件。1971 年,Edgar Coffman 在一篇论文中列举了这些条件。这些条件现在被称为 Coffman 条件,是帮助检测、防止和纠正死锁的技术依据。
Coffman 条件如下:
- 相互排斥:井发进程同时拥有资源的独占权。
- 等待条件:并发进程必须同时拥有一个资源,并等待额外的资源。
- 没有抢占:并发进程拥有的资掘只能被该进程释放,即可满足这个条件。
- 循环等待:一个并发进程(P1)必须等待一系列其他井发进程(P2),这些并发进程同时也在等待进程(P2),这样便满足了这个最终条件。
注意:我们实际上并不能保证 goroutines 的运行顺序,或者需妥多长时间才能启动。虽然不太可能,但是一个 goroutine 可以在另一个 goroutine 开始之前获得和释放锁,从而避免死锁,这是有道理的。
来看看我们设计的程序,并确定它是否符合所有四个条件:
- printSum 函数确实需要 a 和 b 的独占权,所以它满足了这个条件。
- 因为 printSum 持有 a 或 b 并正在等待另一个,所以它满足这个条件。
- 我们没有任何办怯让我们的 goroutine 被抢占。
- 我们第一次调用 printSum 正在等待我们的第二次调用;反之亦然。
是的,我们写出来的无疑是一个死锁了。
这些规则也帮助我们防止死锁。如果确保至少有一个条件不成立,我们可以防止发生死锁。不幸的是,实际上这些条件很难推理,因此很难预防。网络上散布着诸如你和我这样的开发者的疑问,他们想知道为什么一小段代码是死锁的。通常情况下,一旦有人指出,这是非常明显的,但往往需要另一双眼睛。
活锁
店锁是正在主动执行并发操作的程序,但是这些操作无战向前推进程序的状态。你曾经在走廊走向另一个人吗?她移动到一边让你通过,但你也做了同样的事情。所以你转到另一边,但她也是这样做的。想象一下这个情形永远持续下去,你就明白了活锁。
我们实际上编写一些代码来演示这种情况。首先,我们将设置一些辅助函数来简化示例。为了有一个可以工作的例子,这里的代码利用了我们尚未涉及的几个主题。不建议试图了解它的细节,直到有把握可以使用好 sync 包。相反,建议遵循代码标注来理解强调的部分,然后将注意力转向包含示例核心的第二个代码块。
cadence := sync.NewCond(&sync.Mutex{})
go func () {
for range time.Tick(1*time.Millisecond) {
cadence.Broadcast()
}
}()
takeStep := func() {
cadence.L.Lock()
cadence.Wait()
cadence.L.Unlock()
}
//tryDir 允许一个人尝试向一个方向移动,并返回是否成功。dir,每个方向都表示为试图朝这个方向移动的人数。
tryDir := func(dirName string, dir *int32, out *bytes.Buffer) bool {
fmt.Fprintf(out, " %v", dirName)
//首先,我们宣布将要向这个方向移动一个距离。现在,只需要知道这个包的操作是原子操作。
atomic.Addint32(dir, 1)
//为了演示活锁,每个人都必须以相同的速度或节奏移动。takeStep 模拟所有对象之间的一个不变的节奏。
takeStep()
if atomic.LoadInt32(dir) == 1 {
fmt.Fprint(out, ". Success!")
return true
}
takeStep()
//这里的人意识到他们不能向这个方向走而放弃。我们通过把这个方向减 1 来表示。
atomic.AddInt32(dir, -1)
return false
}
var left, right int32
tryLeft := func(out *bytes.Buffer) bool { return tryDir("left", &left, out)}
tryRight := func(out *bytes.Buffer) bool { return tryDir("right", &right, out)}
walk := func(walking *sync.WaitGroup, name string) {
var out bytes.Buffer
defer func() {fmt.Println(out.String()) }()
defer walking.Done()
fmt.Fprintf(&out, "%v is trying to scoot:", name)
//对尝试次数进行了人为限制,以便此程序能结束。在一个有活锁的程序中,可能没有这个限制,这就是为什么它是一个问题!
for i:=O; i<5; i++{
//首先,这个人会试图向左走,如果失败了,他们会尝试向右走
if tryLeft(&out) || tryRight(&out) {
return
}
}
fmt.Fprintf(&out, "\n%v tosses her hands up in exasperation!", name)
}
//这个变量为程序提供了一个等待直到两个人都能够相互通过或放弃的方式
var peopleInHallway sync.WaitGroup
peopleInHallway.Add(2)
go walk(&peopleInHallway, "Alice")
go walk(&peopleInHallway, "Barbara")
peopleInHallway.Wait()
输出如下:
Alice is trying to scoot: left right left right left right left right left right
Alice tosses her hands up in exasperation!
Barbara is trying to scoot: left right left right left right left right
left right
Barbara tosses her hands up in exasperation!
这个例子横示了使用活锁的一个卡分常见的原因:两个或两个以上的并发进程试图在没有协调的情况下防止死锁。这就好比,如果走廊里的人都同意,只有一个人会移动,那就不会有活锁:一个人会站着不动,另一个人会移到另一边,他们就会继续移动。
在我看来,活锁要比死锁更复杂,因为它看起来程序好像在工作。如果一个活锁程序在你的机器上运行,那可以通过查看 CPU 利用率来确定它是否在做处理某些逻辑,大家可能会认为它确实是在工作。根据活锁的不同,它甚至可能发出其他信号,让大家认为它在工作。然而,程序将会一直上演“hallway-shuffle”的循环游戏。
活锁是一组被称为“饥饿”的更大问题的子集。
饥饿
饥饿是在任何情况下,并发进程都无法获得执行工作所需的所有资源。当我们讨论活锁时,每个 goroutine 的资源是一个共享锁。
活锁保证讨论与饥饿是无关的,因为在活锁中,所有并发进程都是相同的,并且没有完成工作。更广泛地说,饥饿通常意味着有一个或多个贪婪的并发进程,它们不公平地阻止一个或多个井发进程,以尽可能有效地完成工作,或者阻止全部并发进程。
这里有一个程序的例子,有一个贪婪的 goroutine 和一个平和的 goroutine:
var wg sync.WaitGroup
var sharedLock sync.Mutex
const runtime = 1*time.Second
greedyWorker := func() {
defer wg.Done()
var count int
for begin := time.Now(); time.Since(begin) <= runtime; {
sharedLock.Lock()
time.Sleep(3*time.Nanosecond)
sharedLock.Unlock()
count++
}
fmt.Printf("Greedy worker was able to execute %v work loops\n", count)
}
politeWorker := func() {
defer wg .Done ()
var count int
for begin := time.Now(); time.Since(begin) <= runtime; {
sharedLock.Lock()
time.Sleep(1*time.Nanosecond)
sharedLock.Unlock()
sharedLock.Lock()
time.Sleep(1*time.Nanosecond)
sharedLock.Unlock()
sharedLock.Lock()
time.Sleep(1*time.Nanosecond)
sharedLock.Unlock()
count++
}
fmt.Printf ("Polite worker was able to execute %v work loops.\n", count)
}
wg.Add(2)
go greedyWorker()
go politeWorker()
wg.Wait()
输出如下:
Polite worker was able to execute 289777 work loops.
Greedy worker was able to execute 471287 work loops.
假设两种 worker 都有同样大小的临界区,而不是认为贪婪的 worker 的算法更有效(或调用 Lock 和 Unlock 的时候,它们也不是缓慢的),我们得出这样的结论,贪婪的 worker 不必要地扩大其持有共享锁上的临界区,井阻止(通过饥饿)平和的 worker 的 goroutine 高效工作。
请注意,我们这里的技术用于识别饥饿:一个 metric。饥饿会为记录和取样提供一个很好的 metric。一个发现和解决饥饿的方曲是,通过记录来确定进程工作速度是否和你预期的一样高。
值得一提的是,前面的代码示例还可以作为内存访问同步的性能影响的示例。因为同步访问内存是昂贵的,所以将我们的锁扩展到临界段之外是有利的。另一方面,这样做我们将冒着饿死其他并发进程的风险。
如果使用了内存访问同步,将不得不在扭拉皮同步和细粒反同步之间找到一个平衡点。当需要对应用程序进行性能调优时,强烈建议只将内存访问同步限制在关键部分;如果同步成为性能问题,可以一直扩展范围。走另一条路妥难得多。
所以,饥饿会导致你的程序表现不佳或不正确。前面的示例演示了低效场景,但是如果你有一个非常贪婪的并发进程,以至于完全阻止另一个并发进程完成工作,那么你就会遇到一个更大的问题。
我们还应该考虑到来自于外部过程的饥饿。请记住,饥饿也可以应用于 CPU、内存、文件句柄、数据库连接:任何必须共享的资源都是饥饿的候选者。
所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频