Go语言Ratelimit服务流量限制
Web 系统打交道最多的是⽹络,⽆论是接收,解析⽤户请求,访问存储,还是把响应数据返回给⽤户,都是要⾛⽹络的。在没有 epoll/kqueue 之类的系统提供的 IO 多路复⽤接⼝之前,多个核⼼的现代计算机最头痛的是 C10k 问题,C10k 问题会导致计算机没有办法充分利⽤ CPU 来处理更多的⽤户连接,进⽽没有办法通过优化程序提升CPU利⽤率来处理更多的请求。
⾃从 Linux 实现了 epoll,FreeBSD 实现了 kqueue ,这个问题基本解决了,我们可以借助内核提供的 API 轻松解决当年的 C10k 问题,也就是说如今如果你的程序主要是和⽹络打交道,那么瓶颈⼀定在⽤户程序⽽不在操作系统内核。
随着时代的发展,编程语⾔对这些系统调⽤⼜进⼀步进⾏了封装,如今做应⽤层开发,⼏乎不会在程序中看到 epoll 之类的字眼,⼤多数时候我们就只要聚焦在业务逻辑上就好。
Go语言的 net 库针对不同平台封装了不同的 syscall API,http 库⼜是构建在 net 库之上,所以在 Go语⾔中我们可以借助标准库,很轻松地写出⾼性能的 http 服务,下⾯是⼀个简单的 hello world 服务的代码:
package main
import (
"io"
"log"
"net/http"
)
func sayhello(wr http.ResponseWriter, r *http.Request) {
wr.WriteHeader(200)
io.WriteString(wr, "hello world")
}
func main() {
http.HandleFunc("/", sayhello)
err := http.ListenAndServe(":9090", nil)
if err != nil {
log.Fatal("ListenAndServe:", err)
}
}
我们需要衡量⼀下这个 Web 服务的吞吐量,再具体⼀些,实际上就是接⼝的 QPS。借助 wrk,在家⽤电脑 Macbook Pro 上对这个 hello world 服务进⾏基准测试,Mac 的硬件情况如下:
CPU: Intel(R) Core(TM) i5-5257U CPU @ 2.70GHz
Core: 2
Threads: 4
Graphics/Displays:
Chipset Model: Intel Iris Graphics 6100
Resolution: 2560 x 1600 Retina
Memory Slots:
Size: 4 GB
Speed: 1867 MHz
Size: 4 GB
Speed: 1867 MHz
Storage:
Size: 250.14 GB (250,140,319,744 bytes)
Media Name: APPLE SSD SM0256G Media
Size: 250.14 GB (250,140,319,744 bytes)
Medium Type: SSD
~ ❯❯❯ wrk -c 10 -d 10s -t10 http://localhost:9090
Running 10s test @ http://localhost:9090
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 339.99us 1.28ms 44.43ms 98.29%
Req/Sec 4.49k 656.81 7.47k 73.36%
449588 requests in 10.10s, 54.88MB read
Requests/sec: 44513.22
Transfer/sec: 5.43MB
~ ❯❯❯ wrk -c 10 -d 10s -t10 http://localhost:9090
Running 10s test @ http://localhost:9090
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 334.76us 1.21ms 45.47ms 98.27%
Req/Sec 4.42k 633.62 6.90k 71.16%
443582 requests in 10.10s, 54.15MB read
Requests/sec: 43911.68
Transfer/sec: 5.36MB
~ ❯❯❯ wrk -c 10 -d 10s -t10 http://localhost:9090
Running 10s test @ http://localhost:9090
10 threads and 10 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 379.26us 1.34ms 44.28ms 97.62%
Req/Sec 4.55k 591.64 8.20k 76.37%
455710 requests in 10.10s, 55.63MB read
Requests/sec: 45118.57
Transfer/sec: 5.51MB
这还只是家⽤ PC,线上服务器⼤多都是 24 核⼼起,32G 内存 +,CPU 基本都是 Intel i7。所以同样的程序在服务器上运⾏会得到更好的结果。
这⾥的 hello world 服务没有任何业务逻辑。真实环境的程序要复杂得多,有些程序偏⽹络 IO 瓶颈,例如⼀些 CDN 服务、Proxy 服务;有些程序偏 CPU/GPU 瓶颈,例如登陆校验服务、图像处理服务;有些程序瓶颈偏磁盘,例如专⻔的存储系统,数据库。
不同的程序瓶颈会体现在不同的地⽅,这⾥提到的这些功能单⼀的服务相对来说还算容易分析。如果碰到业务逻辑复杂代码量巨⼤的模块,其瓶颈并不是三下五除⼆可以推测出来的,还是需要从压⼒测试中得到更为精确的结论。
对于 IO/Network 瓶颈类的程序,其表现是⽹卡 / 磁盘 IO 会先于 CPU 打满,这种情况即使优化 CPU 的使⽤也不能提⾼整个系统的吞吐量,只能提⾼磁盘的读写速度,增加内存⼤⼩,提升⽹卡的带宽来提升整体性能。
⽽ CPU 瓶颈类的程序,则是在存储和⽹卡未打满之前 CPU 占⽤率提前到达 100%,CPU 忙于各种计算任务,IO 设备相对则较闲。
⽆论哪种类型的服务,在资源使⽤到极限的时候都会导致请求堆积,超时,系统 hang 死,最终伤害到终端⽤户。对于分布式的 Web 服务来说,瓶颈还不⼀定总在系统内部,也有可能在外部。
⾮计算密集型的系统往往会在关系型数据库环节失守,⽽这时候 Web 模块本身还远远未达到瓶颈。不管我们的服务瓶颈在哪⾥,最终要做的事情都是⼀样的,那就是流量限制。
常⻅的流量限制⼿段
流量限制的⼿段有很多,最常⻅的:漏桶、令牌桶两种:- 漏桶是指我们有⼀个⼀直装满了⽔的桶,每过固定的⼀段时间即向外漏⼀滴⽔。如果你接到了这滴⽔,那么你就可以继续服务请求,如果没有接到,那么就需要等待下⼀滴⽔。
- 令牌桶则是指匀速向桶中添加令牌,服务请求时需要从桶中获取令牌,令牌的数⽬可以按照需要消耗的资源进⾏相应的调整。如果没有令牌,可以选择等待,或者放弃。
这两种⽅法看起来很像,不过还是有区别的。漏桶流出的速率固定,⽽令牌桶只要在桶中有令牌,那就可以拿。也就是说令牌桶是允许⼀定程度的并发的,⽐如同⼀个时刻,有 100 个⽤户请求,只要令牌桶中有 100 个令牌,那么这 100 个请求全都会放过去。令牌桶在桶中没有令牌的情况下也会退化为漏桶模型。
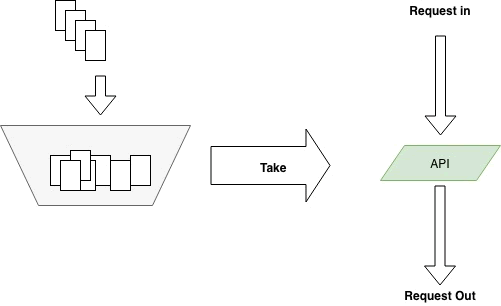
图:令牌桶
实际应⽤中令牌桶应⽤较为⼴泛,开源界流⾏的限流器⼤多数都是基于令牌桶思想的。并且在此基础上进⾏了⼀定程度的扩充,⽐如 github.com/juju/ratelimit 提供了⼏种不同特⾊的令牌桶填充⽅式:
func NewBucket(fillInterval time.Duration, capacity int64) *Bucket
默认的令牌桶,fillInterval 指每过多⻓时间向桶⾥放⼀个令牌,capacity 是桶的容量,超过桶容量的部分会被直接丢弃。桶初始是满的。func NewBucketWithQuantum(fillInterval time.Duration, capacity, quantum int64) *Bucket
和普通的 NewBucket() 的区别是,每次向桶中放令牌时,是放 quantum 个令牌,⽽不是⼀个令牌。func NewBucketWithRate(rate float64, capacity int64) *Bucket
这个就有点特殊了,会按照提供的⽐例,每秒钟填充令牌数。例如 capacity 是 100,⽽ rate 是 0.1,那么每秒会填充 10 个令牌。从桶中获取令牌也提供了⼏个 API:
func (tb *Bucket) Take(count int64) time.Duration {}
func (tb *Bucket) TakeAvailable(count int64) int64 {}
func (tb *Bucket) TakeMaxDuration(count int64, maxWait time.Duration) (
time.Duration, bool,
) {}
func (tb *Bucket) Wait(count int64) {}
func (tb *Bucket) WaitMaxDuration(count int64, maxWait time.Duration) bool {}
但在明⽩令牌桶的基本原理之后,如果没办法满⾜需求,相信大家也可以很快对其进⾏修改并⽀持⾃⼰的业务场景。
原理
从功能上来看,令牌桶模型实际上就是对全局计数的加减法操作过程,但使⽤计数需要我们⾃⼰加读写锁,有⼩⼩的思想负担。如果我们对 Go语⾔已经⽐较熟悉的话,很容易想到可以⽤ buffered channel 来完成简单的加令牌取令牌操作:var tokenBucket = make(chan struct{}, capacity)
每过⼀段时间向 tokenBucket 中添加 token,如果 bucket 已经满了,那么直接放弃:
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
}
package main
import (
"fmt"
"time"
)
func main() {
var fillInterval = time.Millisecond * 10
var capacity = 100
var tokenBucket = make(chan struct{}, capacity)
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
}
go fillToken()
time.Sleep(time.Hour)
}
看看运⾏结果:
current token cnt: 98 2019-08-30 17:34:31.44304 +0800 CST m=+1.007173201
current token cnt: 99 2019-08-30 17:34:31.4530154 +0800 CST m=+1.017148601
current token cnt: 100 2019-08-30 17:34:31.462987 +0800 CST m=+1.027120201
current token cnt: 100 2019-08-30 17:34:31.4729601 +0800 CST m=+1.037093301
current token cnt: 100 2019-08-30 17:34:31.4829352 +0800 CST m=+1.047068401
current token cnt: 100 2019-08-30 17:34:31.4939354 +0800 CST m=+1.058068601
current token cnt: 100 2019-08-30 17:34:31.5028803 +0800 CST m=+1.067013501
current token cnt: 100 2019-08-30 17:34:31.5128549 +0800 CST m=+1.076988101
current token cnt: 100 2019-08-30 17:34:31.5248539 +0800 CST m=+1.088987101
current token cnt: 100 2019-08-30 17:34:31.5348291 +0800 CST m=+1.098962301
current token cnt: 100 2019-08-30 17:34:31.5437705 +0800 CST m=+1.107903701
current token cnt: 100 2019-08-30 17:34:31.5537455 +0800 CST m=+1.117878701
上⾯的令牌桶的取令牌操作实现起来也⽐较简单,简化问题,我们这⾥只取⼀个令牌:
func TakeAvailable(block bool) bool{
var takenResult bool
if block {
select {
case <-tokenBucket:
takenResult = true
}
} else {
select {
case <-tokenBucket:
takenResult = true
default:
takenResult = false
}
}
return takenResult
}
我们来思考⼀下,令牌桶每隔⼀段固定的时间向桶中放令牌,如果我们记下上⼀次放令牌的时间为 t1,和当时的令牌数 k1,放令牌的时间间隔为 ti,每次向令牌桶中放 x 个令牌,令牌桶容量为 cap。现在如果有⼈来调⽤ TakeAvailable 来取 n 个令牌,我们将这个时刻记为 t2。在 t2 时刻,令牌桶中理论上应该有多少令牌呢?伪代码如下:
cur = k1 + ((t2 - t1)/ti) * x
cur = cur > cap ? cap : cur
只要在每次 Take 的时候,再对令牌桶中的 token 数进⾏简单计算,就可以得到正确的令牌数。是不是很像惰性求值的感觉?
在得到正确的令牌数之后,再进⾏实际的 Take 操作就好,这个 Take 操作只需要对令牌数进⾏简单的减法即可,记得加锁以保证并发安全。github.com/juju/ratelimit 这个库就是这样做的。
服务瓶颈和 QoS
前⾯我们说了很多 CPU 瓶颈、IO 瓶颈之类的概念,这种性能瓶颈从⼤多数公司都有的监控系统中可以⽐较快速地定位出来,如果⼀个系统遇到了性能问题,那监控图的反应⼀般都是最快的。虽然性能指标很重要,但对⽤户提供服务时还应考虑服务整体的 QoS。QoS 全称是 Quality of Service,顾名思义是服务质量。QoS 包含有可⽤性、吞吐量、时延、时延变化和丢失等指标。⼀般来讲我们可以通过优化系统,来提⾼ Web 服务的 CPU 利⽤率,从⽽提⾼整个系统的吞吐量。但吞吐量提⾼的同时,⽤户体验是有可能变差的。
⽤户⻆度⽐较敏感的除了可⽤性之外,还有时延。虽然你的系统吞吐量⾼,但半天刷不开⻚⾯,想必会造成⼤量的⽤户流失。所以在⼤公司的Web服务性能指标中,除了平均响应时延之外,还会把响应时间的 95 分位,99 分位也拿出来作为性能标准。
平均响应在提⾼ CPU 利⽤率没受到太⼤影响时,可能 95 分位、99 分位的响应时间⼤幅度攀升了,那么这时候就要考虑提⾼这些 CPU 利⽤率所付出的代价是否值得了。在线系统的机器⼀般都会保持 CPU 有⼀定的余裕。
所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频