Linux RAID磁盘列阵完全攻略
LVM 最大的优势在于可以在不卸载分区和不损坏数据的情况下进行分区容量的调整,但是万一硬盘损坏了,那么数据一定会丟失。 本节讲的 RAID(磁盘阵列)的优势在于硬盘读写性能更好,而且有一定的数据冗余功能。
那什么是数据冗余呢?从字面上理解,冗余就是多余的、重复的。在磁盘阵列中,冗余是指由多块硬盘组成一个磁盘组,在这个磁盘组中,数据存储在多块硬盘的不同地方,这样即使某块硬盘出现问题,数据也不会丟失,也就是磁盘数据具有了保护功能。
读者也可以这样理解,RAID 用于在多个硬盘上分散存储数据,并且能够“恰当”地重复存储数据,从而保证其中某块硬盘发生故障后,不至于影响整个系统的运转。RAID 将几块独立的硬盘组合在一起,形成一个逻辑上的 RAID 硬盘,这块“硬盘”在外界(用户、LVM 等)看来,和真实的硬盘一样,没有任何区别。
这种模式下会先把硬盘分隔出大小相等的区块,当有数据需要写入硬盘时,会把数据也切割成相同大小的区块,然后分别写入各块硬盘。这样就相当于把一个文件分成几个部分同时向不同的硬盘中写入,数据的读/写速度当然就会非常快。
从理论上讲,由几块硬盘组成 RAID 0,比如由 3 块硬盘组成 RAID 0,数据的写入速度就是同样的数据向一块硬盘中写入速度的3倍。我们画一张 RAID 0 的示意图,如图 1 所示。
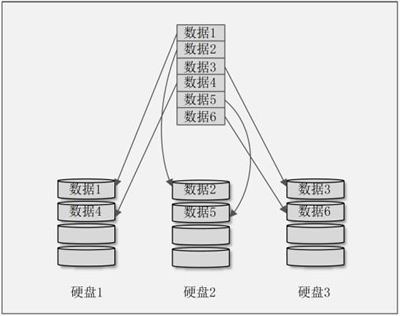
图 1 RAID 0 示意图
解释一下这张示意图。我们准备了 3 块硬盘组成了 RAID 0,每块硬盘都划分了相等的区块。当有数据要写入 RAID 0 时,首先把数据按照区块大小进行分割,然后再把数据依次写入不同的硬盘。每块硬盘负责的数据写入量都是整体数据的 1/3,当然写入时间也只有原始时间的 1/3。所以,从理论上讲,由几块硬盘组成 RAID 0,数据的写入速度就是数据只写入一块硬盘速度的几倍。
RAID 0 的优点如下:
RAID 0 有一个明显的缺点,那就是没有数据冗余功能,RAID 0 中的任何一块硬盘损坏,RAID 0 中所有的数据都将丟失。也就是说,由几块硬盘组成 RAID 0,数据的损毁概率就是只写入一块硬盘的几倍。
我们刚刚说了,组成 RAID 0 的硬盘的大小最好都是一样的。那有人说我只有两块不一样大小的硬盘,难道就不能组成 RAID 0 吗?
答案是可以的。假设有两块硬盘,一块大小是 100GB,另一块大小是 200GB。由这两块硬盘组成 RAID 0,那么当最初的 200G 数据写入时,是分别存放在两块硬盘当中的;但是当数据大于 200GB 之后,第一块硬盘就写满了,以后的数据就只能写入第二块硬盘中,读/写性能也就随之下降了。
一般不建议企业用户使用 RAID 0,因为数据损毁的概率更高。如果对数据的读/写性能要求非常高,但对数据安全要求不高时,RAID 0 就非常合适了。
比如有两块硬盘,组成了 RAID 1,当有数据写入时,相同的数据既写入硬盘 1,也写入硬盘 2。这样相当于给数据做了备份,所以任何一块硬盘损坏,数据都可以在另一块硬盘中找回。RAID 1 的示意图如图 2 所示。
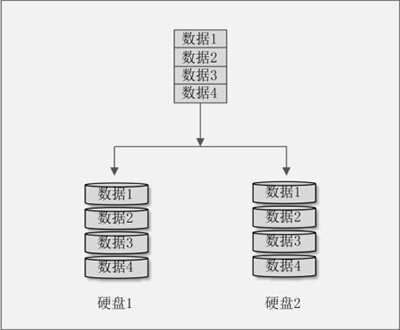
图 2 RAID 1 示意图
RAID 1 具有了数据冗余功能,但是硬盘的容量却减少了 50%,因为两块硬盘当中保存的数据是一样的,所以两块硬盘际上只保存了一块硬盘那么多的数据,这也是我们把 RAID 1 称作镜像卷的原因。
RAID 1 的优点如下:
RAID 1 的缺点也同样明显:
那么,我们能不能把 RAID 0 和 RAID 1 组合起来使用?当然可以,这样我们就即拥有了 RAID 0 的性能,又拥有了 RAID 1 的数据冗余功能。
我们先用两块硬盘组成 RAID 1,再用两块硬盘组成另一个 RAID 1,最后把这两个 RAID 1组成 RAID 0,这种 RAID 方法称作 RAID 10。那先组成 RAID 0,再组成 RAID 1 的方法我们作 RAID 01。我们通过示意图 3 来看看 RAID 10。
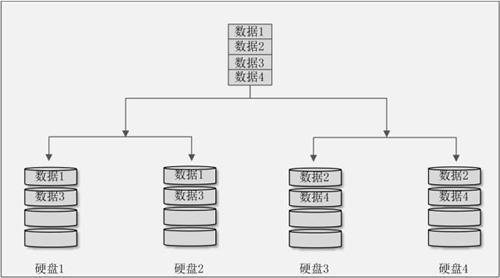
图 3 RAID 10 示意图
我们把硬盘 1 和硬盘 2 组成了第一个 RAID 1,把硬盘 3 和硬盘 4 组成了第二个 RAID 1,这两个 RAID 1组成了 RAID 0。因为先组成 RAID 1,再组成 RAID 0,所以这个 RAID 是 RAID 10。
当有数据写入时,首先写入的是 RAID 0(RAID 0 后组成,所以数据先写入),所以数据 1 和数据 3 写入了第一个 RAID 1,而数据 2 和数据 4 写入了第二个 RAID 1。当数据 1 和数据 3 写入第一个 RAID 1 时,
因为写入的是 RAID 1,所以在硬盘 1 和硬盘 2 中各写入了一份。数据 2 和数据 4 也一样。
这样的组成方式,既有了 RAID 0 的性能优点,也有了 RAID 1 的数据冗余优点。但是大家要注意,虽然我们有了 4 块硬盘,但是由于 RAID 1 的缺点,所以真正的容量只有 4 块硬盘的 50%,另外的一半是用来备份的。
每次循环写入数据的过程中,在其中一块硬盘中加入一个奇偶校验值(Parity),这个奇偶校验值的内容是这次循环写入时其他硬盘数据的备份。当有一块硬盘损坏时,采用这个奇偶校验值进行数据恢复。通过示意图来看看 RAID 5 的存储过程,如图 4 所示。
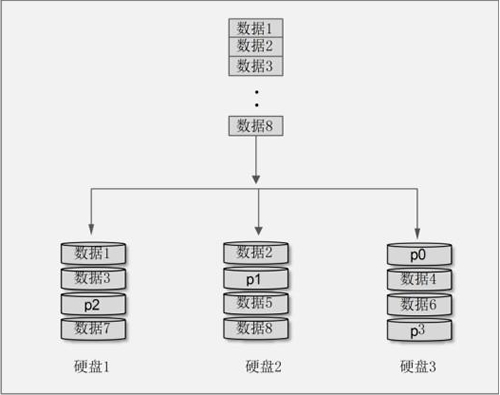
图 4 RAID 5 示意图
在这张示意图中,我们使用三块硬盘组成了 RAID 5。当有数据循环写入时,每次循环都会写入一个奇偶校验值(Parity),并且每次奇偶校验值都会写入不同的硬盘。这个奇偶校验值就是其他两块硬盘中的数据经过换算之后产生的。因为每次奇偶校验值都会写入不同的硬盘,所以任何一块硬盘损坏之后,都可以依赖其他两块硬盘中保存的数据恢复这块损坏的硬盘中的数据。
需要注意的是,每次数据循环写入时,都会有一块硬盘用来保存奇偶校验值,所以在 RAID 5 中可以使用的总容量是硬盘总数减去一块的容量之和。
比如,在这张示意图中,由三块硬盘组成了 RAID 5,但是真正可用的容量是两块硬盘的容量之和,也就是说,越多的硬盘组成 RAID 5,损失的容量占比越小,因为不管由多少块硬盘组成 RAID 5,奇偶校验值加起来只占用一块硬盘。而且还要注意,RAID 5 不管是由几块硬盘组成的,只有损坏一块硬盘的情况才能恢复数据,因为奇偶校验值加起来只占用了一块硬盘,如果损坏的硬盘超过一块,那么数据就不能再恢复了。
RAID 5 的优点如下:
RAID 5 的缺点如下:
从总体上来说,RAID 5 更像 RAID 0 和 RAID 1 的折中,性能比 RAID 1 好,但是不如 RAID 0;数据冗余比 RAID 0 好,而且不像 RAID 1 那样浪费了 50% 的硬盘容量。
如果我们既不想花钱又想使用 RAID,那就只能使用软 RAID 了。软 RAID 是指通过软件实现 RAID 功能,没有多余的费用,但是更加耗费服务器系统性能,而数据的写入速度比硬 RAID 慢。
RAID 功能已经内置在 Linux 2.0及以后的内核中,为了使用这项功能,还需要特定的工具来管理 RAID,在绝对多数 Linux 发行版本中,更多的是使用 mdadm,读者可以自行下载并安装这个工具。
RAID 简介
RAID(Redundant Arrays of Inexpensive Disks,磁盘阵列),翻译过来就是廉价的、具有冗余功能的磁盘阵列。其原理是通过软件或硬件将多块较小的分区组合成一个容量较大的磁盘组。这个较大的磁盘组读写性能更好,更重要的是具有数据冗余功能。那什么是数据冗余呢?从字面上理解,冗余就是多余的、重复的。在磁盘阵列中,冗余是指由多块硬盘组成一个磁盘组,在这个磁盘组中,数据存储在多块硬盘的不同地方,这样即使某块硬盘出现问题,数据也不会丟失,也就是磁盘数据具有了保护功能。
读者也可以这样理解,RAID 用于在多个硬盘上分散存储数据,并且能够“恰当”地重复存储数据,从而保证其中某块硬盘发生故障后,不至于影响整个系统的运转。RAID 将几块独立的硬盘组合在一起,形成一个逻辑上的 RAID 硬盘,这块“硬盘”在外界(用户、LVM 等)看来,和真实的硬盘一样,没有任何区别。
RAID 的组成可以是几块硬盘,所以我们在讲解原理时使用硬盘举例,但是大家要知道不同的分区也可以组成 RAID。
RAID 根据组合方式的不同,有多种设计解决方案,以下介绍几种常见的 RAID 方案(RAID级别)。RAID 0
RAID 0 也叫 Stripe 或 Striping(带区卷),是 RAID 级别中存储性能最好的一个。RAID 0 最好由相同容量的两块或两块以上的硬盘组成。如果组成 RAID 0 的两块硬盘大小不一致,则会影响 RAID 0 的性能。这种模式下会先把硬盘分隔出大小相等的区块,当有数据需要写入硬盘时,会把数据也切割成相同大小的区块,然后分别写入各块硬盘。这样就相当于把一个文件分成几个部分同时向不同的硬盘中写入,数据的读/写速度当然就会非常快。
从理论上讲,由几块硬盘组成 RAID 0,比如由 3 块硬盘组成 RAID 0,数据的写入速度就是同样的数据向一块硬盘中写入速度的3倍。我们画一张 RAID 0 的示意图,如图 1 所示。
图 1 RAID 0 示意图
解释一下这张示意图。我们准备了 3 块硬盘组成了 RAID 0,每块硬盘都划分了相等的区块。当有数据要写入 RAID 0 时,首先把数据按照区块大小进行分割,然后再把数据依次写入不同的硬盘。每块硬盘负责的数据写入量都是整体数据的 1/3,当然写入时间也只有原始时间的 1/3。所以,从理论上讲,由几块硬盘组成 RAID 0,数据的写入速度就是数据只写入一块硬盘速度的几倍。
RAID 0 的优点如下:
- 通过把多块硬盘合并成一块大的逻辑硬盘,实现了数据跨硬盘存储。
- 通过把数据分割成等大小的区块,分别存入不同的硬盘,加快了数据的读写速度。数据的读/写性能是几种 RAID 中最好的。
- 多块硬盘合并成 RAID 0,几块小硬盘组成了更大容量的硬盘,而且没有容量损失。RAID 0 的总容量就是几块硬盘的容量之和。
RAID 0 有一个明显的缺点,那就是没有数据冗余功能,RAID 0 中的任何一块硬盘损坏,RAID 0 中所有的数据都将丟失。也就是说,由几块硬盘组成 RAID 0,数据的损毁概率就是只写入一块硬盘的几倍。
我们刚刚说了,组成 RAID 0 的硬盘的大小最好都是一样的。那有人说我只有两块不一样大小的硬盘,难道就不能组成 RAID 0 吗?
答案是可以的。假设有两块硬盘,一块大小是 100GB,另一块大小是 200GB。由这两块硬盘组成 RAID 0,那么当最初的 200G 数据写入时,是分别存放在两块硬盘当中的;但是当数据大于 200GB 之后,第一块硬盘就写满了,以后的数据就只能写入第二块硬盘中,读/写性能也就随之下降了。
一般不建议企业用户使用 RAID 0,因为数据损毁的概率更高。如果对数据的读/写性能要求非常高,但对数据安全要求不高时,RAID 0 就非常合适了。
RAID 1
RAID 1也叫 Mirror 或 Mirroring(镜像卷),由两块硬盘组成。两块硬盘的大小最好一致,否则总容量以容量小的那块硬盘为主。RAID 1 就具备了数据冗余功能,因为这种模式是把同一份数据同时写入两块硬盘。比如有两块硬盘,组成了 RAID 1,当有数据写入时,相同的数据既写入硬盘 1,也写入硬盘 2。这样相当于给数据做了备份,所以任何一块硬盘损坏,数据都可以在另一块硬盘中找回。RAID 1 的示意图如图 2 所示。
图 2 RAID 1 示意图
RAID 1 具有了数据冗余功能,但是硬盘的容量却减少了 50%,因为两块硬盘当中保存的数据是一样的,所以两块硬盘际上只保存了一块硬盘那么多的数据,这也是我们把 RAID 1 称作镜像卷的原因。
RAID 1 的优点如下:
- 具备了数据冗余功能,任何一块硬盘出现故障,数据都不会丟失。
- 数据的读取性能虽然不如RAID 0,但是比单一硬盘要好,因为数据有两份备份在不同的硬盘上,当多个进程读取同一数据时,RAID会自动分配读取进程。
RAID 1 的缺点也同样明显:
- RAID 1 的容量只有两块硬盘容量的 50%,因为每块硬盘中保存的数据都一样。
- 数据写入性能较差,因为相同的数据会写入两块硬盘当中,相当于写入数据的总容量变大了。虽然 CPU 的速度足够快,但是负责数据写入的芯片只有一个。
RAID 10 或 RAID 01
我们发现,RAID 0 虽然数据读/写性能非常好,但是没有数据冗余功能;而 RAID 1 虽然具有了数据冗余功能,但是数据写入速度实在是太慢了(尤其是软 RAID)。那么,我们能不能把 RAID 0 和 RAID 1 组合起来使用?当然可以,这样我们就即拥有了 RAID 0 的性能,又拥有了 RAID 1 的数据冗余功能。
我们先用两块硬盘组成 RAID 1,再用两块硬盘组成另一个 RAID 1,最后把这两个 RAID 1组成 RAID 0,这种 RAID 方法称作 RAID 10。那先组成 RAID 0,再组成 RAID 1 的方法我们作 RAID 01。我们通过示意图 3 来看看 RAID 10。
图 3 RAID 10 示意图
我们把硬盘 1 和硬盘 2 组成了第一个 RAID 1,把硬盘 3 和硬盘 4 组成了第二个 RAID 1,这两个 RAID 1组成了 RAID 0。因为先组成 RAID 1,再组成 RAID 0,所以这个 RAID 是 RAID 10。
当有数据写入时,首先写入的是 RAID 0(RAID 0 后组成,所以数据先写入),所以数据 1 和数据 3 写入了第一个 RAID 1,而数据 2 和数据 4 写入了第二个 RAID 1。当数据 1 和数据 3 写入第一个 RAID 1 时,
因为写入的是 RAID 1,所以在硬盘 1 和硬盘 2 中各写入了一份。数据 2 和数据 4 也一样。
这样的组成方式,既有了 RAID 0 的性能优点,也有了 RAID 1 的数据冗余优点。但是大家要注意,虽然我们有了 4 块硬盘,但是由于 RAID 1 的缺点,所以真正的容量只有 4 块硬盘的 50%,另外的一半是用来备份的。
RAID 5
RAID 5 最少需要由 3 块硬盘组成,当然硬盘的容量也应当一致。当组成 RAID 5 时,同样需要把硬盘分隔成大小相同的区块。当有数据写入时,数据也被划分成等大小的区块,然后循环向 RAID 5 中写入。每次循环写入数据的过程中,在其中一块硬盘中加入一个奇偶校验值(Parity),这个奇偶校验值的内容是这次循环写入时其他硬盘数据的备份。当有一块硬盘损坏时,采用这个奇偶校验值进行数据恢复。通过示意图来看看 RAID 5 的存储过程,如图 4 所示。
图 4 RAID 5 示意图
在这张示意图中,我们使用三块硬盘组成了 RAID 5。当有数据循环写入时,每次循环都会写入一个奇偶校验值(Parity),并且每次奇偶校验值都会写入不同的硬盘。这个奇偶校验值就是其他两块硬盘中的数据经过换算之后产生的。因为每次奇偶校验值都会写入不同的硬盘,所以任何一块硬盘损坏之后,都可以依赖其他两块硬盘中保存的数据恢复这块损坏的硬盘中的数据。
需要注意的是,每次数据循环写入时,都会有一块硬盘用来保存奇偶校验值,所以在 RAID 5 中可以使用的总容量是硬盘总数减去一块的容量之和。
比如,在这张示意图中,由三块硬盘组成了 RAID 5,但是真正可用的容量是两块硬盘的容量之和,也就是说,越多的硬盘组成 RAID 5,损失的容量占比越小,因为不管由多少块硬盘组成 RAID 5,奇偶校验值加起来只占用一块硬盘。而且还要注意,RAID 5 不管是由几块硬盘组成的,只有损坏一块硬盘的情况才能恢复数据,因为奇偶校验值加起来只占用了一块硬盘,如果损坏的硬盘超过一块,那么数据就不能再恢复了。
RAID 5 的优点如下:
- 因为奇偶校验值的存在,RAID 5 具有了数据冗余功能。
- 硬盘容量损失比 RAID 1 小,而且组成 RAID 5 的硬盘数量越多,容量损失占比越小。
- RAID 5的数据读/写性能要比 RAID 1 更好,但是在数据写入性能上比 RAID 0 差。
RAID 5 的缺点如下:
- 不管由多少块硬盘组成 RAID 5,只支持一块硬盘损坏之后的数据恢复。
- RAID 5 的实际容量是组成 RAID 5 的硬盘总数减去一块的容量之和。也就是有一块硬盘用来保存奇偶校验值,但不能保存数据。
从总体上来说,RAID 5 更像 RAID 0 和 RAID 1 的折中,性能比 RAID 1 好,但是不如 RAID 0;数据冗余比 RAID 0 好,而且不像 RAID 1 那样浪费了 50% 的硬盘容量。
软 RAID 和硬 RAID
我们要想在服务器上实现 RAID,可以采用磁盘阵列卡(RAID 卡)来组成 RAID,也就是硬 RAID。RAID 卡上有专门的芯片负责 RAID 任务,因此性能要好得多,而且不占用系统性能,缺点是 RAID 卡比较昂贵。如果我们既不想花钱又想使用 RAID,那就只能使用软 RAID 了。软 RAID 是指通过软件实现 RAID 功能,没有多余的费用,但是更加耗费服务器系统性能,而数据的写入速度比硬 RAID 慢。
所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频