你们要靠主常常喜乐;我再说,你们要喜乐。当叫众人知道你们谦让的心。主已经近了。应当一无挂虑,只要凡事藉着祷告、祈求和感谢,将你们所要的告诉神。神所赐出人意外的平安,比在基督耶稣里面保守你们的心怀意念。(PHILIPPIANS 4:4-7)
标准库(7)
xml
xml在软件领域用途非常广泛,有名人曰:
“当 XML(扩展标记语言)于 1998 年 2 月被引入软件工业界时,它给整个行业带来了一场风暴。有史以来第一次,这个世界拥有了一种用来结构化文档和数据的通用且适应性强的格式,它不仅仅可以用于 WEB,而且可以被用于任何地方。”
---《Designing With Web Standards Second Edition》, Jeffrey Zeldman
对于xml如果要做一个定义式的说明,就不得不引用w3school里面简洁而明快的说明:
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
如果读者要详细了解和学习有关xml,可以阅读w3school的教程
xml的重要,关键在于它是用来传输数据,因为传输数据,特别是在web编程中,经常要用到的。有了这样一种东西,就让数据传输变得简单了。对于这么重要的,python当然有支持。
一般来讲,一个引人关注的东西,总会有很多人从不同侧面去关注。在编程语言中也是如此,所以,对xml这个明星式的东西,python提供了多种模块来处理。
- xml.dom.* 模块:Document Object Model。适合用于处理 DOM API。它能够将xml数据在内存中解析成一个树,然后通过对树的操作来操作xml。但是,这种方式由于将xml数据映射到内存中的树,导致比较慢,且消耗更多内存。
- xml.sax.* 模块:simple API for XML。由于SAX以流式读取xml文件,从而速度较快,切少占用内存,但是操作上稍复杂,需要用户实现回调函数。
- xml.parser.expat:是一个直接的,低级一点的基于 C 的 expat 的语法分析器。 expat接口基于事件反馈,有点像 SAX 但又不太像,因为它的接口并不是完全规范于 expat 库的。
- xml.etree.ElementTree (以下简称 ET):元素树。它提供了轻量级的python式的API,相对于DOM,ET快了很多 ,而且有很多令人愉悦的API可以使用;相对于SAX,ET也有ET.iterparse提供了 “在空中” 的处理方式,没有必要加载整个文档到内存,节省内存。ET的性能的平均值和SAX差不多,但是API的效率更高一点而且使用起来很方便。
所以,我用xml.etree.ElementTree
ElementTree在标准库中有两种实现。一种是纯Python实现:xml.etree.ElementTree ,另外一种是速度快一点:xml.etree.cElementTree 。
如果读者使用的是python2.x,可以像这样引入模块:
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
如果是Python3.3以上,就没有这个必要了,只需要一句话import xml.etree.ElementTree as ET即可,然后由模块自动来寻找适合的方式。显然python3.x相对python2.x有了很大进步。但是,本教程碍于很多工程项目还没有升级换代,暂且忍受了。
遍历查询
先要搞一个xml文档。为了图省事,我就用w3school中的一个例子:
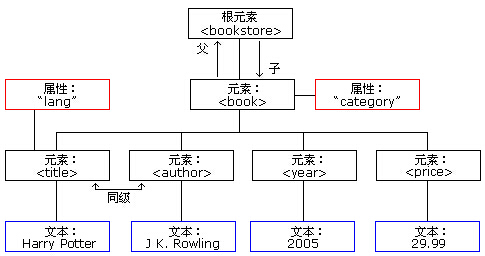
这是一个xml树,只不过是用图来表示的,还没有用ET解析呢。把这棵树写成xml文档格式:
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book>
<book category="CHILDREN">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book>
</bookstore>
将xml保存为名为22601.xml的文件,然后对其进行如下操作:
>>> import xml.etree.cElementTree as ET
为了简化,我用这种方式引入,如果在编程实践中,推荐读者使用try...except...方式。
>>> tree = ET.ElementTree(file="22601.xml")
>>> tree
<ElementTree object at 0xb724cc2c>
建立起xml解析树。然后可以通过根节点向下开始读取各个元素(element对象)。
在上述xml文档中,根元素是
>>> root = tree.getroot() #获得根
>>> root.tag
'bookstore'
>>> root.attrib
{}
要想将根下面的元素都读出来,可以:
>>> for child in root:
... print child.tag, child.attrib
...
book {'category': 'COOKING'}
book {'category': 'CHILDREN'}
book {'category': 'WEB'}
也可以这样读取指定元素的信息:
>>> root[0].tag
'book'
>>> root[0].attrib
{'category': 'COOKING'}
>>> root[0].text #无内容
'\n '
再深点,就有感觉了:
>>> root[0][0].tag
'title'
>>> root[0][0].attrib
{'lang': 'en'}
>>> root[0][0].text
'Everyday Italian'
对于ElementTree对象,有一个iter方法可以对指定名称的子节点进行深度优先遍历。例如:
>>> for ele in tree.iter(tag="book"): #遍历名称为book的节点
... print ele.tag, ele.attrib
...
book {'category': 'COOKING'}
book {'category': 'CHILDREN'}
book {'category': 'WEB'}
>>> for ele in tree.iter(tag="title"): #遍历名称为title的节点
... print ele.tag, ele.attrib, ele.text
...
title {'lang': 'en'} Everyday Italian
title {'lang': 'en'} Harry Potter
title {'lang': 'en'} Learning XML
如果不指定元素名称,就是将所有的元素遍历一边。
>>> for ele in tree.iter():
... print ele.tag, ele.attrib
...
bookstore {}
book {'category': 'COOKING'}
title {'lang': 'en'}
author {}
year {}
price {}
book {'category': 'CHILDREN'}
title {'lang': 'en'}
author {}
year {}
price {}
book {'category': 'WEB'}
title {'lang': 'en'}
author {}
year {}
price {}
除了上面的方法,还可以通过路径,搜索到指定的元素,读取其内容。这就是xpath。此处对xpath不详解,如果要了解可以到网上搜索有关信息。
>>> for ele in tree.iterfind("book/title"):
... print ele.text
...
Everyday Italian
Harry Potter
Learning XML
利用findall()方法,也可以是实现查找功能:
>>> for ele in tree.findall("book"):
... title = ele.find('title').text
... price = ele.find('price').text
... lang = ele.find('title').attrib
... print title, price, lang
...
Everyday Italian 30.00 {'lang': 'en'}
Harry Potter 29.99 {'lang': 'en'}
Learning XML 39.95 {'lang': 'en'}
编辑
除了读取有关数据之外,还能对xml进行编辑,即增删改查功能。还是以上面的xml文档为例:
>>> root[1].tag
'book'
>>> del root[1]
>>> for ele in root:
... print ele.tag
...
book
book
如此,成功删除了一个节点。原来有三个book节点,现在就还剩两个了。打开源文件再看看,是不是正好少了第二个节点呢?一定很让你失望,源文件居然没有变化。
的确如此,源文件没有变化,这就对了。因为至此的修改动作,还是停留在内存中,还没有将修改结果输出到文件。不要忘记,我们是在内存中建立的ElementTree对象。再这样做:
>>> import os
>>> outpath = os.getcwd()
>>> file = outpath + "/22601.xml"
把当前文件路径拼装好。然后:
>>> tree.write(file)
再看源文件,已经变成两个节点了。
除了删除,也能够修改:
>>> for price in root.iter("price"): #原来每本书的价格
... print price.text
...
30.00
39.95
>>> for price in root.iter("price"): #每本上涨7元,并且增加属性标记
... new_price = float(price.text) + 7
... price.text = str(new_price)
... price.set("updated","up")
...
>>> tree.write(file)
查看源文件:
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price updated="up">37.0</price>
</book>
<book category="WEB">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price updated="up">46.95</price>
</book>
</bookstore>
不仅价格修改了,而且在price标签里面增加了属性标记。干得不错。
上面用del来删除某个元素,其实,在编程中,这个用的不多,更喜欢用remove()方法。比如我要删除price > 40的书。可以这么做:
>>> for book in root.findall("book"):
... price = book.find("price").text
... if float(price) > 40.0:
... root.remove(book)
...
>>> tree.write(file)
于是就这样了:
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price updated="up">37.0</price>
</book>
</bookstore>
接下来就要增加元素了。
>>> import xml.etree.cElementTree as ET
>>> tree = ET.ElementTree(file="22601.xml")
>>> root = tree.getroot()
>>> ET.SubElement(root, "book") #在root里面添加book节点
<Element 'book' at 0xb71c7578>
>>> for ele in root:
... print ele.tag
...
book
book
>>> b2 = root[1] #得到新增的book节点
>>> b2.text = "python" #添加内容
>>> tree.write("22601.xml")
查看源文件:
<bookstore>
<book category="COOKING">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price updated="up">37.0</price>
</book>
<book>python</book>
</bookstore>
常用属性和方法总结
ET里面的属性和方法不少,这里列出常用的,供使用中备查。
Element对象
常用属性:
- tag:string,元素数据种类
- text:string,元素的内容
- attrib:dictionary,元素的属性字典
- tail:string,元素的尾形
针对属性的操作
- clear():清空元素的后代、属性、text和tail也设置为None
- get(key, default=None):获取key对应的属性值,如该属性不存在则返回default值
- items():根据属性字典返回一个列表,列表元素为(key, value)
- keys():返回包含所有元素属性键的列表
- set(key, value):设置新的属性键与值
针对后代的操作
- append(subelement):添加直系子元素
- extend(subelements):增加一串元素对象作为子元素
- find(match):寻找第一个匹配子元素,匹配对象可以为tag或path
- findall(match):寻找所有匹配子元素,匹配对象可以为tag或path
- findtext(match):寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path
- insert(index, element):在指定位置插入子元素
- iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器
- iterfind(match):根据tag或path查找所有的后代
- itertext():遍历所有后代并返回text值
- remove(subelement):删除子元素
ElementTree对象
- find(match)
- findall(match)
- findtext(match, default=None)
- getroot():获取根节点.
- iter(tag=None)
- iterfind(match)
- parse(source, parser=None):装载xml对象,source可以为文件名或文件类型对象.
- write(file, encoding="us-ascii", xml_declaration=None, default_namespace=None,method="xml")
一个实例
最后,提供一个参考,这是一篇来自网络的文章:Python xml属性、节点、文本的增删改,本文的源码我也复制到下面,请读者参考:
实现思想:
使用ElementTree,先将文件读入,解析成树,之后,根据路径,可以定位到树的每个节点,再对节点进行修改,最后直接将其输出.
#!/usr/bin/python
# -*- coding=utf-8 -*-
# author : wklken@yeah.net
# date: 2012-05-25
# version: 0.1
from xml.etree.ElementTree import ElementTree,Element
def read_xml(in_path):
'''
读取并解析xml文件
in_path: xml路径
return: ElementTree
'''
tree = ElementTree()
tree.parse(in_path)
return tree
def write_xml(tree, out_path):
'''
将xml文件写出
tree: xml树
out_path: 写出路径
'''
tree.write(out_path, encoding="utf-8",xml_declaration=True)
def if_match(node, kv_map):
'''
判断某个节点是否包含所有传入参数属性
node: 节点
kv_map: 属性及属性值组成的map
'''
for key in kv_map:
if node.get(key) != kv_map.get(key):
return False
return True
#---------------search -----
def find_nodes(tree, path):
'''
查找某个路径匹配的所有节点
tree: xml树
path: 节点路径
'''
return tree.findall(path)
def get_node_by_keyvalue(nodelist, kv_map):
'''
根据属性及属性值定位符合的节点,返回节点
nodelist: 节点列表
kv_map: 匹配属性及属性值map
'''
result_nodes = []
for node in nodelist:
if if_match(node, kv_map):
result_nodes.append(node)
return result_nodes
#---------------change -----
def change_node_properties(nodelist, kv_map, is_delete=False):
'''
修改/增加 /删除 节点的属性及属性值
nodelist: 节点列表
kv_map:属性及属性值map
'''
for node in nodelist:
for key in kv_map:
if is_delete:
if key in node.attrib:
del node.attrib[key]
else:
node.set(key, kv_map.get(key))
def change_node_text(nodelist, text, is_add=False, is_delete=False):
'''
改变/增加/删除一个节点的文本
nodelist:节点列表
text : 更新后的文本
'''
for node in nodelist:
if is_add:
node.text += text
elif is_delete:
node.text = ""
else:
node.text = text
def create_node(tag, property_map, content):
'''
新造一个节点
tag:节点标签
property_map:属性及属性值map
content: 节点闭合标签里的文本内容
return 新节点
'''
element = Element(tag, property_map)
element.text = content
return element
def add_child_node(nodelist, element):
'''
给一个节点添加子节点
nodelist: 节点列表
element: 子节点
'''
for node in nodelist:
node.append(element)
def del_node_by_tagkeyvalue(nodelist, tag, kv_map):
'''
同过属性及属性值定位一个节点,并删除之
nodelist: 父节点列表
tag:子节点标签
kv_map: 属性及属性值列表
'''
for parent_node in nodelist:
children = parent_node.getchildren()
for child in children:
if child.tag == tag and if_match(child, kv_map):
parent_node.remove(child)
if __name__ == "__main__":
#1. 读取xml文件
tree = read_xml("./test.xml")
#2. 属性修改
#A. 找到父节点
nodes = find_nodes(tree, "processers/processer")
#B. 通过属性准确定位子节点
result_nodes = get_node_by_keyvalue(nodes, {"name":"BProcesser"})
#C. 修改节点属性
change_node_properties(result_nodes, {"age": "1"})
#D. 删除节点属性
change_node_properties(result_nodes, {"value":""}, True)
#3. 节点修改
#A.新建节点
a = create_node("person", {"age":"15","money":"200000"}, "this is the firest content")
#B.插入到父节点之下
add_child_node(result_nodes, a)
#4. 删除节点
#定位父节点
del_parent_nodes = find_nodes(tree, "processers/services/service")
#准确定位子节点并删除之
target_del_node = del_node_by_tagkeyvalue(del_parent_nodes, "chain", {"sequency" : "chain1"})
#5. 修改节点文本
#定位节点
text_nodes = get_node_by_keyvalue(find_nodes(tree, "processers/services/service/chain"), {"sequency":"chain3"})
change_node_text(text_nodes, "new text")
#6. 输出到结果文件
write_xml(tree, "./out.xml")
操作对象(原始xml文件):
<?xml version="1.0" encoding="UTF-8"?>
<framework>
<processers>
<processer name="AProcesser" file="lib64/A.so"
path="/tmp">
</processer>
<processer name="BProcesser" file="lib64/B.so" value="fordelete">
</processer>
<processer name="BProcesser" file="lib64/B.so2222222"/>
<services>
<service name="search" prefix="/bin/search?"
output_formatter="OutPutFormatter:service_inc">
<chain sequency="chain1"/>
<chain sequency="chain2"></chain>
</service>
<service name="update" prefix="/bin/update?">
<chain sequency="chain3" value="fordelete"/>
</service>
</services>
</processers>
</framework>
执行程序之后,得到的结果文件:
<?xml version='1.0' encoding='utf-8'?>
<framework>
<processers>
<processer file="lib64/A.so" name="AProcesser" path="/tmp">
</processer>
<processer age="1" file="lib64/B.so" name="BProcesser">
<person age="15" money="200000">this is the firest content</person>
</processer>
<processer age="1" file="lib64/B.so2222222" name="BProcesser">
<person age="15" money="200000">this is the firest content</person>
</processer>
<services>
<service name="search" output_formatter="OutPutFormatter:service_inc"
prefix="/bin/search?">
<chain sequency="chain2" />
</service>
<service name="update" prefix="/bin/update?">
<chain sequency="chain3" value="fordelete">new text</chain>
</service>
</services>
</processers>
</framework>
如有疑问,请到Python论坛提问