Table of Contents
- 18.1 MySQL Cluster Overview
- 18.1.1 MySQL Cluster Core Concepts
- 18.1.2 MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- 18.1.3 MySQL Cluster Hardware, Software, and Networking Requirements
- 18.1.4 What is New in MySQL Cluster
- 18.1.5 MySQL Server Using InnoDB Compared with MySQL Cluster
- 18.1.6 Known Limitations of MySQL Cluster
- 18.2 MySQL Cluster Installation and Upgrades
- 18.2.1 Installing MySQL Cluster on Linux
- 18.2.2 Installing MySQL Cluster on Windows
- 18.2.3 Initial Configuration of MySQL Cluster
- 18.2.4 Initial Startup of MySQL Cluster
- 18.2.5 MySQL Cluster Example with Tables and Data
- 18.2.6 Safe Shutdown and Restart of MySQL Cluster
- 18.2.7 Upgrading and Downgrading MySQL Cluster NDB 7.2
- 18.3 Configuration of MySQL Cluster
- 18.4 MySQL Cluster Programs
- 18.4.1 ndbd — The MySQL Cluster Data Node Daemon
- 18.4.2 ndbinfo_select_all — Select From ndbinfo Tables
- 18.4.3 ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)
- 18.4.4 ndb_mgmd — The MySQL Cluster Management Server Daemon
- 18.4.5 ndb_mgm — The MySQL Cluster Management Client
- 18.4.6 ndb_blob_tool — Check and Repair BLOB and TEXT columns of MySQL Cluster Tables
- 18.4.7 ndb_config — Extract MySQL Cluster Configuration Information
- 18.4.8 ndb_cpcd — Automate Testing for NDB Development
- 18.4.9 ndb_delete_all — Delete All Rows from an NDB Table
- 18.4.10 ndb_desc — Describe NDB Tables
- 18.4.11 ndb_drop_index — Drop Index from an NDB Table
- 18.4.12 ndb_drop_table — Drop an NDB Table
- 18.4.13 ndb_error_reporter — NDB Error-Reporting Utility
- 18.4.14 ndb_index_stat — NDB Index Statistics Utility
- 18.4.15 ndb_print_backup_file — Print NDB Backup File Contents
- 18.4.16 ndb_print_file — Print NDB Disk Data File Contents
- 18.4.17 ndb_print_schema_file — Print NDB Schema File Contents
- 18.4.18 ndb_print_sys_file — Print NDB System File Contents
- 18.4.19 ndbd_redo_log_reader — Check and Print Content of Cluster Redo Log
- 18.4.20 ndb_restore — Restore a MySQL Cluster Backup
- 18.4.21 ndb_select_all — Print Rows from an NDB Table
- 18.4.22 ndb_select_count — Print Row Counts for NDB Tables
- 18.4.23 ndb_show_tables — Display List of NDB Tables
- 18.4.24 ndb_size.pl — NDBCLUSTER Size Requirement Estimator
- 18.4.25 ndb_waiter — Wait for MySQL Cluster to Reach a Given Status
- 18.4.26 Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs
- 18.5 Management of MySQL Cluster
- 18.5.1 Summary of MySQL Cluster Start Phases
- 18.5.2 Commands in the MySQL Cluster Management Client
- 18.5.3 Online Backup of MySQL Cluster
- 18.5.4 MySQL Server Usage for MySQL Cluster
- 18.5.5 Performing a Rolling Restart of a MySQL Cluster
- 18.5.6 Event Reports Generated in MySQL Cluster
- 18.5.7 MySQL Cluster Log Messages
- 18.5.8 MySQL Cluster Single User Mode
- 18.5.9 Quick Reference: MySQL Cluster SQL Statements
- 18.5.10 The ndbinfo MySQL Cluster Information Database
- 18.5.11 MySQL Cluster Security Issues
- 18.5.12 MySQL Cluster Disk Data Tables
- 18.5.13 Adding MySQL Cluster Data Nodes Online
- 18.5.14 Distributed MySQL Privileges for MySQL Cluster
- 18.5.15 NDB API Statistics Counters and Variables
- 18.6 MySQL Cluster Replication
- 18.6.1 MySQL Cluster Replication: Abbreviations and Symbols
- 18.6.2 General Requirements for MySQL Cluster Replication
- 18.6.3 Known Issues in MySQL Cluster Replication
- 18.6.4 MySQL Cluster Replication Schema and Tables
- 18.6.5 Preparing the MySQL Cluster for Replication
- 18.6.6 Starting MySQL Cluster Replication (Single Replication Channel)
- 18.6.7 Using Two Replication Channels for MySQL Cluster Replication
- 18.6.8 Implementing Failover with MySQL Cluster Replication
- 18.6.9 MySQL Cluster Backups With MySQL Cluster Replication
- 18.6.10 MySQL Cluster Replication: Multi-Master and Circular Replication
- 18.6.11 MySQL Cluster Replication Conflict Resolution
- 18.7 MySQL Cluster Release Notes
This chapter contains information about
MySQL Cluster, which is a
high-availability, high-redundancy version of MySQL adapted for the
distributed computing environment. Recent releases of MySQL Cluster
use version 7 of the NDBCLUSTER storage
engine (also known as NDB) to enable
running several computers with MySQL servers and other software in a
cluster; the latest releases available for production use
incorporate NDB version 7.2.
Support for the NDBCLUSTER storage
engine is not included in the standard MySQL Server 5.5 binaries
built by Oracle. Instead, users of MySQL Cluster binaries from
Oracle should upgrade to the most recent binary release of MySQL
Cluster for supported platforms—these include RPMs that should
work with most Linux distributions. MySQL Cluster users who build
from source should use the sources provided for MySQL Cluster.
(Locations where the sources can be obtained are listed later in
this section.)
This chapter contains information about MySQL Cluster NDB 7.2 releases through 5.5.48-ndb-7.2.24. Currently, the MySQL Cluster NDB 7.3 and MySQL Cluster NDB 7.4 release series are both Generally Available (GA). MySQL Cluster NDB 7.2 is a previous GA release series; although this series is still supported, we recommend that new deployments use MySQL Cluster NDB 7.4. For information about MySQL Cluster NDB 7.4, see MySQL Cluster NDB 7.3 and MySQL Cluster NDB 7.4, in the MySQL 5.6 Manual. MySQL Cluster NDB 7.5 is also available as a Developer Preview; see MySQL Cluster NDB 7.5.
Release notes for the changes in each release of MySQL Cluster are located at MySQL Cluster 7.2 Release Notes.
Supported Platforms. MySQL Cluster is currently available and supported on a number of platforms. For exact levels of support available for on specific combinations of operating system versions, operating system distributions, and hardware platforms, please refer to http://www.mysql.com/support/supportedplatforms/cluster.html.
Availability. MySQL Cluster binary and source packages are available for supported platforms from http://dev.mysql.com/downloads/cluster/.
MySQL Cluster release numbers.
MySQL Cluster follows a somewhat different release pattern from
the mainline MySQL Server 5.5 series of releases. In this
Manual and other MySQL documentation, we
identify these and later MySQL Cluster releases employing a
version number that begins with “NDB”. This version
number is that of the NDBCLUSTER
storage engine used in the release, and not of the MySQL server
version on which the MySQL Cluster release is based.
Version strings used in MySQL Cluster software. The version string displayed by MySQL Cluster programs uses this format:
mysql-mysql_server_version-ndb-ndb_engine_version
mysql_server_version represents the
version of the MySQL Server on which the MySQL Cluster release is
based. For all MySQL Cluster NDB 6.x and 7.x releases, this is
“5.1”. ndb_engine_version is
the version of the NDB storage engine
used by this release of the MySQL Cluster software. You can see this
format used in the mysql client, as shown here:
shell>mysqlWelcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2 Server version: 5.5.48-ndb-7.2.24 Source distribution Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>SELECT VERSION()\G*************************** 1. row *************************** VERSION(): 5.5.48-ndb-7.2.24 1 row in set (0.00 sec)
This version string is also displayed in the output of the
SHOW command in the ndb_mgm
client:
ndb_mgm> SHOW
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=1 @10.0.10.6 (5.5.48-ndb-7.2.24, Nodegroup: 0, *)
id=2 @10.0.10.8 (5.5.48-ndb-7.2.24, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=3 @10.0.10.2 (5.5.48-ndb-7.2.24)
[mysqld(API)] 2 node(s)
id=4 @10.0.10.10 (5.5.48-ndb-7.2.24)
id=5 (not connected, accepting connect from any host)
The version string identifies the mainline MySQL version from which
the MySQL Cluster release was branched and the version of the
NDBCLUSTER storage engine used. For
example, the full version string for MySQL Cluster NDB 7.2.4 (the
first MySQL Cluster production release based on MySQL Server 5.5) is
mysql-5.5.19-ndb-7.2.4. From this we can
determine the following:
Since the portion of the version string preceding “
-ndb-” is the base MySQL Server version, this means that MySQL Cluster NDB 7.2.4 derives from the MySQL 5.5.19, and contains all feature enhancements and bugfixes from MySQL 5.5 up to and including MySQL 5.5.19.Since the portion of the version string following “
-ndb-” represents the version number of theNDB(orNDBCLUSTER) storage engine, MySQL Cluster NDB 7.2.4 uses version 7.2.4 of theNDBCLUSTERstorage engine.
New MySQL Cluster releases are numbered according to updates in the
NDB storage engine, and do not necessarily
correspond in a one-to-one fashion with mainline MySQL Server
releases. For example, MySQL Cluster NDB 7.2.4 (as previously noted)
is based on MySQL 5.5.19, while MySQL Cluster NDB 7.2.0 was based on
MySQL 5.1.51 (version string:
mysql-5.1.51-ndb-7.2.0).
Compatibility with standard MySQL 5.5 releases.
While many standard MySQL schemas and applications can work using
MySQL Cluster, it is also true that unmodified applications and
database schemas may be slightly incompatible or have suboptimal
performance when run using MySQL Cluster (see
Section 18.1.6, “Known Limitations of MySQL Cluster”). Most of these issues
can be overcome, but this also means that you are very unlikely to
be able to switch an existing application datastore—that
currently uses, for example, MyISAM
or InnoDB—to use the
NDB storage engine without allowing
for the possibility of changes in schemas, queries, and
applications. In addition, the MySQL Server and MySQL Cluster
codebases diverge considerably, so that the standard
mysqld cannot function as a drop-in replacement
for the version of mysqld supplied with MySQL
Cluster.
MySQL Cluster development source trees. MySQL Cluster development trees can also be accessed from https://github.com/mysql/mysql-server.
The MySQL Cluster development sources maintained at https://github.com/mysql/mysql-server are licensed under the GPL. For information about obtaining MySQL sources using Bazaar and building them yourself, see Section 2.9.3, “Installing MySQL Using a Development Source Tree”.
As with MySQL Server 5.5, MySQL Cluster NDB 7.2 is built using CMake.
Currently, MySQL Cluster NDB 7.3 and MySQL Cluster NDB 7.4 releases are Generally Available (GA). We recommend that new deployments use MySQL Cluster NDB 7.4. MySQL Cluster NDB 7.1 and earlier versions are no longer in active development. For an overview of major features added in MySQL Cluster NDB 7.4, see What is New in MySQL Cluster NDB 7.4. For similar information about MySQL Cluster NDB 7.3, see What is New in MySQL Cluster NDB 7.3. For an overview of major features added in past MySQL Cluster releases, see MySQL Cluster Development History. MySQL Cluster NDB 7.5 is also available as a Developer Preview for testing of new features; for more information, see MySQL Cluster NDB 7.5.
This chapter represents a work in progress, and its contents are subject to revision as MySQL Cluster continues to evolve. Additional information regarding MySQL Cluster can be found on the MySQL Web site at http://www.mysql.com/products/cluster/.
Additional Resources. More information about MySQL Cluster can be found in the following places:
For answers to some commonly asked questions about MySQL Cluster, see Section A.10, “MySQL FAQ: MySQL 5.5 and MySQL Cluster”.
The MySQL Cluster mailing list: http://lists.mysql.com/cluster.
The MySQL Cluster Forum: http://forums.mysql.com/list.php?25.
Many MySQL Cluster users and developers blog about their experiences with MySQL Cluster, and make feeds of these available through PlanetMySQL.
- 18.1.1 MySQL Cluster Core Concepts
- 18.1.2 MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
- 18.1.3 MySQL Cluster Hardware, Software, and Networking Requirements
- 18.1.4 What is New in MySQL Cluster
- 18.1.5 MySQL Server Using InnoDB Compared with MySQL Cluster
- 18.1.6 Known Limitations of MySQL Cluster
MySQL Cluster is a technology that enables clustering of in-memory databases in a shared-nothing system. The shared-nothing architecture enables the system to work with very inexpensive hardware, and with a minimum of specific requirements for hardware or software.
MySQL Cluster is designed not to have any single point of failure. In a shared-nothing system, each component is expected to have its own memory and disk, and the use of shared storage mechanisms such as network shares, network file systems, and SANs is not recommended or supported.
MySQL Cluster integrates the standard MySQL server with an in-memory
clustered storage engine called NDB
(which stands for “Network
DataBase”). In our
documentation, the term NDB refers to
the part of the setup that is specific to the storage engine,
whereas “MySQL Cluster” refers to the combination of
one or more MySQL servers with the NDB
storage engine.
A MySQL Cluster consists of a set of computers, known as hosts, each running one or more processes. These processes, known as nodes, may include MySQL servers (for access to NDB data), data nodes (for storage of the data), one or more management servers, and possibly other specialized data access programs. The relationship of these components in a MySQL Cluster is shown here:
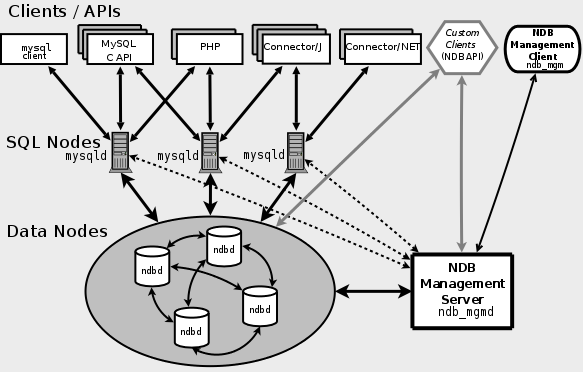
All these programs work together to form a MySQL Cluster (see
Section 18.4, “MySQL Cluster Programs”. When data is stored by the
NDB storage engine, the tables (and
table data) are stored in the data nodes. Such tables are directly
accessible from all other MySQL servers (SQL nodes) in the cluster.
Thus, in a payroll application storing data in a cluster, if one
application updates the salary of an employee, all other MySQL
servers that query this data can see this change immediately.
Although a MySQL Cluster SQL node uses the mysqld server daemon, it differs in a number of critical respects from the mysqld binary supplied with the MySQL 5.5 distributions, and the two versions of mysqld are not interchangeable.
In addition, a MySQL server that is not connected to a MySQL Cluster
cannot use the NDB storage engine and
cannot access any MySQL Cluster data.
The data stored in the data nodes for MySQL Cluster can be mirrored; the cluster can handle failures of individual data nodes with no other impact than that a small number of transactions are aborted due to losing the transaction state. Because transactional applications are expected to handle transaction failure, this should not be a source of problems.
Individual nodes can be stopped and restarted, and can then rejoin the system (cluster). Rolling restarts (in which all nodes are restarted in turn) are used in making configuration changes and software upgrades (see Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”). Rolling restarts are also used as part of the process of adding new data nodes online (see Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”). For more information about data nodes, how they are organized in a MySQL Cluster, and how they handle and store MySQL Cluster data, see Section 18.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”.
Backing up and restoring MySQL Cluster databases can be done using
the NDB-native functionality found in the MySQL
Cluster management client and the ndb_restore
program included in the MySQL Cluster distribution. For more
information, see Section 18.5.3, “Online Backup of MySQL Cluster”, and
Section 18.4.20, “ndb_restore — Restore a MySQL Cluster Backup”. You can also
use the standard MySQL functionality provided for this purpose in
mysqldump and the MySQL server. See
Section 4.5.4, “mysqldump — A Database Backup Program”, for more information.
MySQL Cluster nodes can use a number of different transport mechanisms for inter-node communications, including TCP/IP using standard 100 Mbps or faster Ethernet hardware. It is also possible to use the high-speed Scalable Coherent Interface (SCI) protocol with MySQL Cluster, although this is not required to use MySQL Cluster. SCI requires special hardware and software; see Section 18.3.4, “Using High-Speed Interconnects with MySQL Cluster”, for more about SCI and using it with MySQL Cluster.
NDBCLUSTER
(also known as NDB) is an in-memory
storage engine offering high-availability and data-persistence
features.
The NDBCLUSTER storage engine can be
configured with a range of failover and load-balancing options,
but it is easiest to start with the storage engine at the cluster
level. MySQL Cluster's NDB storage
engine contains a complete set of data, dependent only on other
data within the cluster itself.
The “Cluster” portion of MySQL Cluster is configured independently of the MySQL servers. In a MySQL Cluster, each part of the cluster is considered to be a node.
In many contexts, the term “node” is used to indicate a computer, but when discussing MySQL Cluster it means a process. It is possible to run multiple nodes on a single computer; for a computer on which one or more cluster nodes are being run we use the term cluster host.
There are three types of cluster nodes, and in a minimal MySQL Cluster configuration, there will be at least three nodes, one of each of these types:
Management node: The role of this type of node is to manage the other nodes within the MySQL Cluster, performing such functions as providing configuration data, starting and stopping nodes, running backup, and so forth. Because this node type manages the configuration of the other nodes, a node of this type should be started first, before any other node. An MGM node is started with the command ndb_mgmd.
Data node: This type of node stores cluster data. There are as many data nodes as there are replicas, times the number of fragments (see Section 18.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”). For example, with two replicas, each having two fragments, you need four data nodes. One replica is sufficient for data storage, but provides no redundancy; therefore, it is recommended to have 2 (or more) replicas to provide redundancy, and thus high availability. A data node is started with the command ndbd (see Section 18.4.1, “ndbd — The MySQL Cluster Data Node Daemon”) or ndbmtd (see Section 18.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”).
MySQL Cluster tables are normally stored completely in memory rather than on disk (this is why we refer to MySQL Cluster as an in-memory database). However, some MySQL Cluster data can be stored on disk; see Section 18.5.12, “MySQL Cluster Disk Data Tables”, for more information.
SQL node: This is a node that accesses the cluster data. In the case of MySQL Cluster, an SQL node is a traditional MySQL server that uses the
NDBCLUSTERstorage engine. An SQL node is a mysqld process started with the--ndbclusterand--ndb-connectstringoptions, which are explained elsewhere in this chapter, possibly with additional MySQL server options as well.An SQL node is actually just a specialized type of API node, which designates any application which accesses MySQL Cluster data. Another example of an API node is the ndb_restore utility that is used to restore a cluster backup. It is possible to write such applications using the NDB API. For basic information about the NDB API, see Getting Started with the NDB API.
It is not realistic to expect to employ a three-node setup in a production environment. Such a configuration provides no redundancy; to benefit from MySQL Cluster's high-availability features, you must use multiple data and SQL nodes. The use of multiple management nodes is also highly recommended.
For a brief introduction to the relationships between nodes, node groups, replicas, and partitions in MySQL Cluster, see Section 18.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”.
Configuration of a cluster involves configuring each individual node in the cluster and setting up individual communication links between nodes. MySQL Cluster is currently designed with the intention that data nodes are homogeneous in terms of processor power, memory space, and bandwidth. In addition, to provide a single point of configuration, all configuration data for the cluster as a whole is located in one configuration file.
The management server manages the cluster configuration file and the cluster log. Each node in the cluster retrieves the configuration data from the management server, and so requires a way to determine where the management server resides. When interesting events occur in the data nodes, the nodes transfer information about these events to the management server, which then writes the information to the cluster log.
In addition, there can be any number of cluster client processes
or applications. These include standard MySQL clients,
NDB-specific API programs, and management
clients. These are described in the next few paragraphs.
Standard MySQL clients. MySQL Cluster can be used with existing MySQL applications written in PHP, Perl, C, C++, Java, Python, Ruby, and so on. Such client applications send SQL statements to and receive responses from MySQL servers acting as MySQL Cluster SQL nodes in much the same way that they interact with standalone MySQL servers.
MySQL clients using a MySQL Cluster as a data source can be
modified to take advantage of the ability to connect with multiple
MySQL servers to achieve load balancing and failover. For example,
Java clients using Connector/J 5.0.6 and later can use
jdbc:mysql:loadbalance:// URLs (improved in
Connector/J 5.1.7) to achieve load balancing transparently; for
more information about using Connector/J with MySQL Cluster, see
Using Connector/J with MySQL Cluster.
NDB client programs.
Client programs can be written that access MySQL Cluster data
directly from the NDBCLUSTER storage engine,
bypassing any MySQL Servers that may be connected to the
cluster, using the NDB
API, a high-level C++ API. Such applications may be
useful for specialized purposes where an SQL interface to the
data is not needed. For more information, see
The NDB API.
NDB-specific Java applications can also be
written for MySQL Cluster using the
MySQL Cluster Connector for
Java. This MySQL Cluster Connector includes
ClusterJ, a high-level
database API similar to object-relational mapping persistence
frameworks such as Hibernate and JPA that connect directly to
NDBCLUSTER, and so does not require access to a
MySQL Server. Support is also provided in MySQL Cluster NDB 7.1
and later for ClusterJPA, an
OpenJPA implementation for MySQL Cluster that leverages the
strengths of ClusterJ and JDBC; ID lookups and other fast
operations are performed using ClusterJ (bypassing the MySQL
Server), while more complex queries that can benefit from
MySQL's query optimizer are sent through the MySQL Server,
using JDBC. See Java and MySQL Cluster, and
The ClusterJ API and Data Object Model, for more
information.
The Memcache API for MySQL Cluster, implemented as the loadable ndbmemcache storage engine for memcached version 1.6 and later, is available beginning with MySQL Cluster NDB 7.2.2. This API can be used to provide a persistent MySQL Cluster data store, accessed using the memcache protocol.
The standard memcached caching engine is included in the MySQL Cluster NDB 7.2 distribution (7.2.2 and later). Each memcached server has direct access to data stored in MySQL Cluster, but is also able to cache data locally and to serve (some) requests from this local cache.
For more information, see ndbmemcache—Memcache API for MySQL Cluster.
Management clients. These clients connect to the management server and provide commands for starting and stopping nodes gracefully, starting and stopping message tracing (debug versions only), showing node versions and status, starting and stopping backups, and so on. An example of this type of program is the ndb_mgm management client supplied with MySQL Cluster (see Section 18.4.5, “ndb_mgm — The MySQL Cluster Management Client”). Such applications can be written using the MGM API, a C-language API that communicates directly with one or more MySQL Cluster management servers. For more information, see The MGM API.
Oracle also makes available MySQL Cluster Manager, which provides an advanced command-line interface simplifying many complex MySQL Cluster management tasks, such restarting a MySQL Cluster with a large number of nodes. The MySQL Cluster Manager client also supports commands for getting and setting the values of most node configuration parameters as well as mysqld server options and variables relating to MySQL Cluster. See MySQL™ Cluster Manager 1.3.6 User Manual, for more information.
Event logs. MySQL Cluster logs events by category (startup, shutdown, errors, checkpoints, and so on), priority, and severity. A complete listing of all reportable events may be found in Section 18.5.6, “Event Reports Generated in MySQL Cluster”. Event logs are of the two types listed here:
Cluster log: Keeps a record of all desired reportable events for the cluster as a whole.
Node log: A separate log which is also kept for each individual node.
Under normal circumstances, it is necessary and sufficient to keep and examine only the cluster log. The node logs need be consulted only for application development and debugging purposes.
Checkpoint.
Generally speaking, when data is saved to disk, it is said that
a checkpoint has been
reached. More specific to MySQL Cluster, a checkpoint is a point
in time where all committed transactions are stored on disk.
With regard to the NDB storage
engine, there are two types of checkpoints which work together
to ensure that a consistent view of the cluster's data is
maintained. These are shown in the following list:
Local Checkpoint (LCP): This is a checkpoint that is specific to a single node; however, LCPs take place for all nodes in the cluster more or less concurrently. An LCP involves saving all of a node's data to disk, and so usually occurs every few minutes. The precise interval varies, and depends upon the amount of data stored by the node, the level of cluster activity, and other factors.
Global Checkpoint (GCP): A GCP occurs every few seconds, when transactions for all nodes are synchronized and the redo-log is flushed to disk.
For more information about the files and directories created by local checkpoints and global checkpoints, see MySQL Cluster Data Node File System Directory Files.
This section discusses the manner in which MySQL Cluster divides and duplicates data for storage.
A number of concepts central to an understanding of this topic are discussed in the next few paragraphs.
(Data) Node. An ndbd process, which stores a replica —that is, a copy of the partition (see below) assigned to the node group of which the node is a member.
Each data node should be located on a separate computer. While it is also possible to host multiple ndbd processes on a single computer, such a configuration is not supported.
It is common for the terms “node” and “data node” to be used interchangeably when referring to an ndbd process; where mentioned, management nodes (ndb_mgmd processes) and SQL nodes (mysqld processes) are specified as such in this discussion.
Node Group. A node group consists of one or more nodes, and stores partitions, or sets of replicas (see next item).
The number of node groups in a MySQL Cluster is not directly
configurable; it is a function of the number of data nodes and of
the number of replicas
(NoOfReplicas
configuration parameter), as shown here:
[number_of_node_groups] =number_of_data_nodes/NoOfReplicas
Thus, a MySQL Cluster with 4 data nodes has 4 node groups if
NoOfReplicas is set to 1
in the config.ini file, 2 node groups if
NoOfReplicas is set to 2,
and 1 node group if
NoOfReplicas is set to 4.
Replicas are discussed later in this section; for more information
about NoOfReplicas, see
Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”.
All node groups in a MySQL Cluster must have the same number of data nodes.
You can add new node groups (and thus new data nodes) online, to a running MySQL Cluster; see Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”, for more information.
Partition. This is a portion of the data stored by the cluster. There are as many cluster partitions as nodes participating in the cluster. Each node is responsible for keeping at least one copy of any partitions assigned to it (that is, at least one replica) available to the cluster.
A replica belongs entirely to a single node; a node can (and usually does) store several replicas.
NDB and user-defined partitioning.
MySQL Cluster normally partitions
NDBCLUSTER tables automatically.
However, it is also possible to employ user-defined partitioning
with NDBCLUSTER tables. This is
subject to the following limitations:
Only the
KEYandLINEAR KEYpartitioning schemes are supported in production withNDBtables.When using ndbd, the maximum number of partitions that may be defined explicitly for any
NDBtable is8 * [. (The number of node groups in a MySQL Cluster is determined as discussed previously in this section.)number of node groups]When using ndbmtd, this maximum is also affected by the number of local query handler threads, which is determined by the value of the
MaxNoOfExecutionThreadsconfiguration parameter. In such cases, the maximum number of partitions that may be defined explicitly for anNDBtable is equal to4 * MaxNoOfExecutionThreads * [.number of node groups]See Section 18.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”, for more information.
For more information relating to MySQL Cluster and user-defined partitioning, see Section 18.1.6, “Known Limitations of MySQL Cluster”, and Section 19.5.2, “Partitioning Limitations Relating to Storage Engines”.
Replica. This is a copy of a cluster partition. Each node in a node group stores a replica. Also sometimes known as a partition replica. The number of replicas is equal to the number of nodes per node group.
The following diagram illustrates a MySQL Cluster with four data nodes, arranged in two node groups of two nodes each; nodes 1 and 2 belong to node group 0, and nodes 3 and 4 belong to node group 1. Note that only data (ndbd) nodes are shown here; although a working cluster requires an ndb_mgm process for cluster management and at least one SQL node to access the data stored by the cluster, these have been omitted in the figure for clarity.
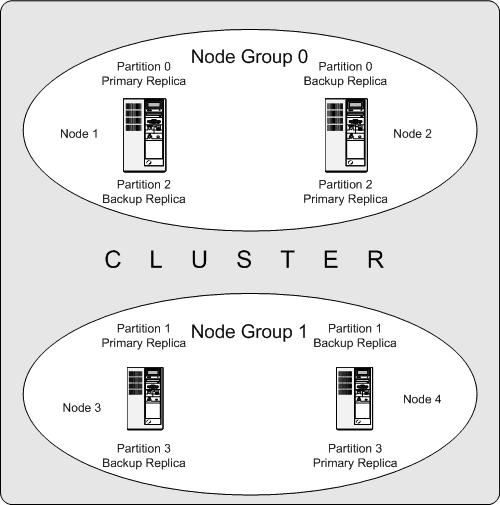
The data stored by the cluster is divided into four partitions, numbered 0, 1, 2, and 3. Each partition is stored—in multiple copies—on the same node group. Partitions are stored on alternate node groups as follows:
Partition 0 is stored on node group 0; a primary replica (primary copy) is stored on node 1, and a backup replica (backup copy of the partition) is stored on node 2.
Partition 1 is stored on the other node group (node group 1); this partition's primary replica is on node 3, and its backup replica is on node 4.
Partition 2 is stored on node group 0. However, the placing of its two replicas is reversed from that of Partition 0; for Partition 2, the primary replica is stored on node 2, and the backup on node 1.
Partition 3 is stored on node group 1, and the placement of its two replicas are reversed from those of partition 1. That is, its primary replica is located on node 4, with the backup on node 3.
What this means regarding the continued operation of a MySQL Cluster is this: so long as each node group participating in the cluster has at least one node operating, the cluster has a complete copy of all data and remains viable. This is illustrated in the next diagram.
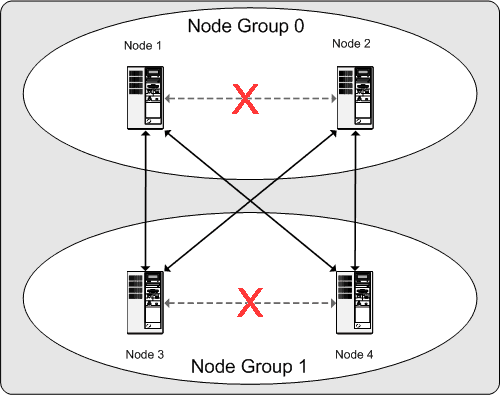
In this example, where the cluster consists of two node groups of two nodes each, any combination of at least one node in node group 0 and at least one node in node group 1 is sufficient to keep the cluster “alive” (indicated by arrows in the diagram). However, if both nodes from either node group fail, the remaining two nodes are not sufficient (shown by the arrows marked out with an X); in either case, the cluster has lost an entire partition and so can no longer provide access to a complete set of all cluster data.
One of the strengths of MySQL Cluster is that it can be run on commodity hardware and has no unusual requirements in this regard, other than for large amounts of RAM, due to the fact that all live data storage is done in memory. (It is possible to reduce this requirement using Disk Data tables—see Section 18.5.12, “MySQL Cluster Disk Data Tables”, for more information about these.) Naturally, multiple and faster CPUs can enhance performance. Memory requirements for other MySQL Cluster processes are relatively small.
The software requirements for MySQL Cluster are also modest. Host operating systems do not require any unusual modules, services, applications, or configuration to support MySQL Cluster. For supported operating systems, a standard installation should be sufficient. The MySQL software requirements are simple: all that is needed is a production release of MySQL Cluster. It is not strictly necessary to compile MySQL yourself merely to be able to use MySQL Cluster. We assume that you are using the binaries appropriate to your platform, available from the MySQL Cluster software downloads page at http://dev.mysql.com/downloads/cluster/.
For communication between nodes, MySQL Cluster supports TCP/IP networking in any standard topology, and the minimum expected for each host is a standard 100 Mbps Ethernet card, plus a switch, hub, or router to provide network connectivity for the cluster as a whole. We strongly recommend that a MySQL Cluster be run on its own subnet which is not shared with machines not forming part of the cluster for the following reasons:
Security. Communications between MySQL Cluster nodes are not encrypted or shielded in any way. The only means of protecting transmissions within a MySQL Cluster is to run your MySQL Cluster on a protected network. If you intend to use MySQL Cluster for Web applications, the cluster should definitely reside behind your firewall and not in your network's De-Militarized Zone (DMZ) or elsewhere.
See Section 18.5.11.1, “MySQL Cluster Security and Networking Issues”, for more information.
Efficiency. Setting up a MySQL Cluster on a private or protected network enables the cluster to make exclusive use of bandwidth between cluster hosts. Using a separate switch for your MySQL Cluster not only helps protect against unauthorized access to MySQL Cluster data, it also ensures that MySQL Cluster nodes are shielded from interference caused by transmissions between other computers on the network. For enhanced reliability, you can use dual switches and dual cards to remove the network as a single point of failure; many device drivers support failover for such communication links.
Network communication and latency. MySQL Cluster requires communication between data nodes and API nodes (including SQL nodes), as well as between data nodes and other data nodes, to execute queries and updates. Communication latency between these processes can directly affect the observed performance and latency of user queries. In addition, to maintain consistency and service despite the silent failure of nodes, MySQL Cluster uses heartbeating and timeout mechanisms which treat an extended loss of communication from a node as node failure. This can lead to reduced redundancy. Recall that, to maintain data consistency, a MySQL Cluster shuts down when the last node in a node group fails. Thus, to avoid increasing the risk of a forced shutdown, breaks in communication between nodes should be avoided wherever possible.
The failure of a data or API node results in the abort of all uncommitted transactions involving the failed node. Data node recovery requires synchronization of the failed node's data from a surviving data node, and re-establishment of disk-based redo and checkpoint logs, before the data node returns to service. This recovery can take some time, during which the Cluster operates with reduced redundancy.
Heartbeating relies on timely generation of heartbeat signals by all nodes. This may not be possible if the node is overloaded, has insufficient machine CPU due to sharing with other programs, or is experiencing delays due to swapping. If heartbeat generation is sufficiently delayed, other nodes treat the node that is slow to respond as failed.
This treatment of a slow node as a failed one may or may not be
desirable in some circumstances, depending on the impact of the
node's slowed operation on the rest of the cluster. When
setting timeout values such as
HeartbeatIntervalDbDb and
HeartbeatIntervalDbApi for
MySQL Cluster, care must be taken care to achieve quick detection,
failover, and return to service, while avoiding potentially
expensive false positives.
Where communication latencies between data nodes are expected to be higher than would be expected in a LAN environment (on the order of 100 µs), timeout parameters must be increased to ensure that any allowed periods of latency periods are well within configured timeouts. Increasing timeouts in this way has a corresponding effect on the worst-case time to detect failure and therefore time to service recovery.
LAN environments can typically be configured with stable low latency, and such that they can provide redundancy with fast failover. Individual link failures can be recovered from with minimal and controlled latency visible at the TCP level (where MySQL Cluster normally operates). WAN environments may offer a range of latencies, as well as redundancy with slower failover times. Individual link failures may require route changes to propagate before end-to-end connectivity is restored. At the TCP level this can appear as large latencies on individual channels. The worst-case observed TCP latency in these scenarios is related to the worst-case time for the IP layer to reroute around the failures.
SCI support. It is also possible to use the high-speed Scalable Coherent Interface (SCI) with MySQL Cluster, but this is not a requirement. See Section 18.3.4, “Using High-Speed Interconnects with MySQL Cluster”, for more about this protocol and its use with MySQL Cluster.
In this section, we discuss changes in the implementation of MySQL Cluster in MySQL MySQL Cluster NDB 7.2, as compared to MySQL Cluster NDB 7.1 and earlier releases. Changes and features most likely to be of interest are shown in the following table:
| MySQL Cluster NDB 7.2 |
|---|
| MySQL Cluster NDB 7.2.1 and later MySQL Cluster NDB 7.2 releases are based on MySQL 5.5. For more information about new features in MySQL Server 5.5, see Section 1.4, “What Is New in MySQL 5.5”. |
Version 2 binary log row events, to provide support for improvements in
MySQL Cluster Replication conflict detection (see next
item). A given mysqld can be made to
use Version 1 or Version 2 binary logging row events with
the
--log-bin-use-v1-row-events
option. |
Two new “primary wins” conflict detection and resolution
functions
NDB$EPOCH()
and
NDB$EPOCH_TRANS()
for use in replication setups with 2 MySQL Clusters. For
more information, see
Section 18.6, “MySQL Cluster Replication”. |
| Distribution of MySQL users and privileges across MySQL Cluster SQL nodes is now supported—see Section 18.5.14, “Distributed MySQL Privileges for MySQL Cluster”. |
| Improved support for distributed pushed-down joins, which greatly improve performance for many joins that can be executed in parallel on the data nodes. |
Default values for a number of data node configuration parameters such
as
HeartbeatIntervalDbDb
and
ArbitrationTimeout
have been improved. |
| Support for the Memcache API using the loadable ndbmemcache storage engine. See ndbmemcache—Memcache API for MySQL Cluster. |
This section contains information about MySQL Cluster NDB 7.2 releases through 5.5.48-ndb-7.2.24, which is currently available for use in production beginning with MySQL Cluster NDB 7.2.4. MySQL Cluster NDB 7.1, MySQL Cluster NDB 7.0, and MySQL Cluster NDB 6.3 are previous GA release series; although these are still supported, we recommend that new deployments use MySQL Cluster NDB 7.2. For information about MySQL Cluster NDB 7.1 and previous releases, see MySQL Cluster NDB 6.1 - 7.1, in the MySQL 5.1 Manual.
The following improvements to MySQL Cluster have been made in MySQL Cluster NDB 7.2:
Based on MySQL Server 5.5. Previous MySQL Cluster release series, including MySQL Cluster NDB 7.1, used MySQL 5.1 as a base. Beginning with MySQL Cluster NDB 7.2.1, MySQL Cluster NDB 7.2 is based on MySQL Server 5.5, so that MySQL Cluster users can benefit from MySQL 5.5's improvements in scalability and performance monitoring. As with MySQL 5.5, MySQL Cluster NDB 7.2.1 and later use CMake for configuring and building from source in place of GNU Autotools (used in MySQL 5.1 and MySQL Cluster releases based on MySQL 5.1). For more information about changes and improvements in MySQL 5.5, see Section 1.4, “What Is New in MySQL 5.5”.
Conflict detection using GCI Reflection. MySQL Cluster Replication implements a new “primary wins” conflict detection and resolution mechanism. GCI Reflection applies in two-cluster circulation “active-active” replication setups, tracking the order in which changes are applied on the MySQL Cluster designated as primary relative to changes originating on the other MySQL Cluster (referred to as the secondary). This relative ordering is used to determine whether changes originating on the slave are concurrent with any changes that originate locally, and are therefore potentially in conflict. Two new conflict detection functions are added: When using
NDB$EPOCH(), rows that are out of sync on the secondary are realigned with those on the primary; withNDB$EPOCH_TRANS(), this realignment is applied to transactions. For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.Version 2 binary log row events. A new format for binary log row events, known as Version 2 binary log row events, provides support for improvements in MySQL Cluster Replication conflict detection (see previous item) and is intended to facilitate further improvements in MySQL Replication. You can cause a given mysqld use Version 1 or Version 2 binary logging row events with the
--log-bin-use-v1-row-eventsoption. For backward compatibility, Version 2 binary log row events are also available in MySQL Cluster NDB 7.0 (7.0.27 and later) and MySQL Cluster NDB 7.1 (7.1.16 and later). However, MySQL Cluster NDB 7.0 and MySQL Cluster NDB 7.1 continue to use Version 1 binary log row events as the default, whereas the default in MySQL Cluster NDB 7.2.1 and later is use Version 2 row events for binary logging.Distribution of MySQL users and privileges. Automatic distribution of MySQL users and privileges across all SQL nodes in a given MySQL Cluster is now supported. To enable this support, you must first import an SQL script
share/mysql/ndb_dist_priv.sqlthat is included with the MySQL Cluster NDB 7.2 distribution. This script creates several stored procedures which you can use to enable privilege distribution and perform related tasks.When a new MySQL Server joins a MySQL Cluster where privilege distribution is in effect, it also participates in the privilege distribution automatically.
Once privilege distribution is enabled, all changes to the grant tables made on any mysqld attached to the cluster are immediately available on any other attached MySQL Servers. This is true whether the changes are made using
CREATE USER,GRANT, or any of the other statements described elsewhere in this Manual (see Section 13.7.1, “Account Management Statements”.) This includes privileges relating to stored routines and views; however, automatic distribution of the views or stored routines themselves is not currently supported.For more information, see Section 18.5.14, “Distributed MySQL Privileges for MySQL Cluster”.
Distributed pushed-down joins. Many joins can now be pushed down to the NDB kernel for processing on MySQL Cluster data nodes. Previously, a join was handled in MySQL Cluster by means of repeated accesses of
NDBby the SQL node; however, when pushed-down joins are enabled, a pushable join is sent in its entirety to the data nodes, where it can be distributed among the data nodes and executed in parallel on multiple copies of the data, with a single, merged result being returned to mysqld. This can reduce greatly the number of round trips between an SQL node and the data nodes required to handle such a join, leading to greatly improved performance of join processing.It is possible to determine when joins can be pushed down to the data nodes by examining the join with
EXPLAIN. A number of new system status variables (Ndb_pushed_queries_defined,Ndb_pushed_queries_dropped,Ndb_pushed_queries_executed, andNdb_pushed_reads) and additions to thecounterstable (in thendbinfoinformation database) can also be helpful in determining when and how well joins are being pushed down.More information and examples are available in the description of the
ndb_join_pushdownserver system variable. See also the description of the status variables referenced in the previous paragraph, as well as Section 18.5.10.7, “The ndbinfo counters Table”.Improved default values for data node configuration parameters. In order to provide more resiliency to environmental issues and better handling of some potential failure scenarios, and to perform more reliably with increases in memory and other resource requirements brought about by recent improvements in join handling by
NDB, the default values for a number of MySQL Cluster data node configuration parameters have been changed. The parameters and changes are described in the following list:HeartbeatIntervalDbDb: Default increased from 1500 ms to 5000 ms.ArbitrationTimeout: Default increased from 3000 ms to 7500 ms.TimeBetweenEpochsTimeout: Now effectively disabled by default (default changed from 4000 ms to 0).SharedGlobalMemory: Default increased from 20 MB to 128 MB.MaxParallelScansPerFragment: Default increased from 32 to 256.CrashOnCorruptedTuplechanged fromFALSEtoTRUE.Beginning with MySQL Cluster NDB 7.2.10,
DefaultOperationRedoProblemActionchanged fromABORTtoQUEUE.
In addition, the value computed for
MaxNoOfLocalScanswhen this parameter is not set inconfig.inihas been increased by a factor of 4.Fail-fast data nodes. Beginning with MySQL Cluster NDB 7.2.1, data nodes handle corrupted tuples in a fail-fast manner by default. This is a change from previous versions of MySQL Cluster where this behavior had to be enabled explicitly by enabling the
CrashOnCorruptedTupleconfiguration parameter. In MySQL Cluster NDB 7.2.1 and later, this parameter is enabled by default and must be explicitly disabled, in which case data nodes merely log a warning whenever they detect a corrupted tuple.Memcache API support (ndbmemcache). The Memcached server is a distributed in-memory caching server that uses a simple text-based protocol. It is often employed with key-value stores. The Memcache API for MySQL Cluster, available beginning with MySQL Cluster NDB 7.2.2, is implemented as a loadable storage engine for memcached version 1.6 and later. This API can be used to access a persistent MySQL Cluster data store employing the memcache protocol. It is also possible for the memcached server to provide a strictly defined interface to existing MySQL Cluster tables.
Each memcache server can both cache data locally and access data stored in MySQL Cluster directly. Caching policies are configurable. For more information, see ndbmemcache—Memcache API for MySQL Cluster, in the MySQL Cluster API Developers Guide.
Rows per partition limit removed. Previously it was possible to store a maximum of 46137488 rows in a single MySQL Cluster partition—that is, per data node. Beginning with MySQL Cluster NDB 7.2.9, this limitation has been lifted, and there is no longer any practical upper limit to this number. (Bug #13844405, Bug #14000373)
MySQL Cluster NDB 7.2 is also supported by MySQL Cluster Manager, which provides an advanced command-line interface that can simplify many complex MySQL Cluster management tasks. See MySQL™ Cluster Manager 1.3.6 User Manual, for more information.
MySQL Server offers a number of choices in storage engines. Since
both NDBCLUSTER and
InnoDB can serve as transactional
MySQL storage engines, users of MySQL Server sometimes become
interested in MySQL Cluster. They see
NDB as a possible alternative or
upgrade to the default InnoDB storage
engine in MySQL 5.5. While NDB and
InnoDB share common characteristics,
there are differences in architecture and implementation, so that
some existing MySQL Server applications and usage scenarios can be
a good fit for MySQL Cluster, but not all of them.
In this section, we discuss and compare some characteristics of
the NDB storage engine used by MySQL
Cluster NDB 7.2 with InnoDB used in
MySQL 5.5. The next few sections provide a technical comparison.
In many instances, decisions about when and where to use MySQL
Cluster must be made on a case-by-case basis, taking all factors
into consideration. While it is beyond the scope of this
documentation to provide specifics for every conceivable usage
scenario, we also attempt to offer some very general guidance on
the relative suitability of some common types of applications for
NDB as opposed to
InnoDB backends.
Recent MySQL Cluster NDB 7.2 releases use a
mysqld based on MySQL 5.5, including support
for InnoDB 1.1. While it is possible
to use InnoDB tables with MySQL Cluster, such
tables are not clustered. It is also not possible to use programs
or libraries from a MySQL Cluster NDB 7.2 distribution with MySQL
Server 5.5, or the reverse.
While it is also true that some types of common business
applications can be run either on MySQL Cluster or on MySQL Server
(most likely using the InnoDB storage
engine), there are some important architectural and implementation
differences. Section 18.1.5.1, “Differences Between the NDB and InnoDB Storage Engines”,
provides a summary of the these differences. Due to the
differences, some usage scenarios are clearly more suitable for
one engine or the other; see
Section 18.1.5.2, “NDB and InnoDB Workloads”. This in turn
has an impact on the types of applications that better suited for
use with NDB or
InnoDB. See
Section 18.1.5.3, “NDB and InnoDB Feature Usage Summary”, for a comparison
of the relative suitability of each for use in common types of
database applications.
For information about the relative characteristics of the
NDB and
MEMORY storage engines, see
When to Use MEMORY or MySQL Cluster.
See Chapter 15, Alternative Storage Engines, for additional information about MySQL storage engines.
The MySQL Cluster NDB storage
engine is implemented using a distributed, shared-nothing
architecture, which causes it to behave differently from
InnoDB in a number of ways. For
those unaccustomed to working with
NDB, unexpected behaviors can arise
due to its distributed nature with regard to transactions,
foreign keys, table limits, and other characteristics. These are
shown in the following table:
Feature |
|
MySQL Cluster |
|---|---|---|
MySQL Server Version | 5.5 | MySQL Cluster NDB 7.2: 5.5 MySQL Cluster NDB 7.3: 5.6 |
|
|
|
MySQL Cluster Version | N/A |
|
Storage Limits | 64TB | 3TB (Practical upper limit based on 48 data nodes with 64GB RAM each; can be increased with disk-based data and BLOBs) |
Foreign Keys | Yes | Available in MySQL Cluster NDB 7.3 and later.
(Prior to MySQL Cluster NDB 7.3: Ignored, as with
|
Transactions | All standard types | |
MVCC | Yes | No |
Data Compression | Yes | No (MySQL Cluster checkpoint and backup files can be compressed) |
Large Row Support (> 14K) |
Supported for (Using these types to store very large amounts of data can lower MySQL Cluster performance) | |
Replication Support | Asynchronous and semisynchronous replication using MySQL Replication | Automatic synchronous replication within a MySQL Cluster. Asynchronous replication between MySQL Clusters, using MySQL Replication |
Scaleout for Read Operations | Yes (MySQL Replication) | Yes (Automatic partitioning in MySQL Cluster; MySQL Replication) |
Scaleout for Write Operations | Requires application-level partitioning (sharding) | Yes (Automatic partitioning in MySQL Cluster is transparent to applications) |
High Availability (HA) | Requires additional software | Yes (Designed for 99.999% uptime) |
Node Failure Recovery and Failover | Requires additional software | Automatic (Key element in MySQL Cluster architecture) |
Time for Node Failure Recovery | 30 seconds or longer | Typically < 1 second |
Real-Time Performance | No | Yes |
In-Memory Tables | No | Yes (Some data can optionally be stored on disk; both in-memory and disk data storage are durable) |
NoSQL Access to Storage Engine | Native memcached interface in development (see the MySQL Dev Zone article MySQL Cluster 7.2 (DMR2): NoSQL, Key/Value, Memcached) | Yes Multiple APIs, including Memcached, Node.js/JavaScript, Java, JPA, C++, and HTTP/REST |
Concurrent and Parallel Writes | Not supported | Up to 48 writers, optimized for concurrent writes |
Conflict Detection and Resolution (Multiple Replication Masters) | No | Yes |
Hash Indexes | No | Yes |
Online Addition of Nodes | Read-only replicas using MySQL Replication | Yes (all node types) |
Online Upgrades | No | Yes |
Online Schema Modifications | No. | Yes. |
MySQL Cluster has a range of unique attributes that make it
ideal to serve applications requiring high availability, fast
failover, high throughput, and low latency. Due to its
distributed architecture and multi-node implementation, MySQL
Cluster also has specific constraints that may keep some
workloads from performing well. A number of major differences in
behavior between the NDB and
InnoDB storage engines with regard
to some common types of database-driven application workloads
are shown in the following table::
Workload |
MySQL Cluster ( | |
|---|---|---|
High-Volume OLTP Applications | Yes | Yes |
DSS Applications (data marts, analytics) | Yes | Limited (Join operations across OLTP datasets not exceeding 3TB in size) |
Custom Applications | Yes | Yes |
Packaged Applications | Yes | Limited (should be mostly primary key access).
Note
MySQL Cluster NDB 7.3 supports foreign keys. |
In-Network Telecoms Applications (HLR, HSS, SDP) | No | Yes |
Session Management and Caching | Yes | Yes |
E-Commerce Applications | Yes | Yes |
User Profile Management, AAA Protocol | Yes | Yes |
When comparing application feature requirements to the
capabilities of InnoDB with
NDB, some are clearly more
compatible with one storage engine than the other.
The following table lists supported application features according to the storage engine to which each feature is typically better suited.
Preferred application requirements for
|
Preferred application requirements for
|
|---|---|
|
|
- 18.1.6.1 Noncompliance with SQL Syntax in MySQL Cluster
- 18.1.6.2 Limits and Differences of MySQL Cluster from Standard MySQL Limits
- 18.1.6.3 Limits Relating to Transaction Handling in MySQL Cluster
- 18.1.6.4 MySQL Cluster Error Handling
- 18.1.6.5 Limits Associated with Database Objects in MySQL Cluster
- 18.1.6.6 Unsupported or Missing Features in MySQL Cluster
- 18.1.6.7 Limitations Relating to Performance in MySQL Cluster
- 18.1.6.8 Issues Exclusive to MySQL Cluster
- 18.1.6.9 Limitations Relating to MySQL Cluster Disk Data Storage
- 18.1.6.10 Limitations Relating to Multiple MySQL Cluster Nodes
- 18.1.6.11 Previous MySQL Cluster Issues Resolved in MySQL 5.1, MySQL Cluster NDB 6.x, and MySQL Cluster NDB 7.x
In the sections that follow, we discuss known limitations in
current releases of MySQL Cluster as compared with the features
available when using the MyISAM and
InnoDB storage engines. If you check the
“Cluster” category in the MySQL bugs database at
http://bugs.mysql.com, you can find known bugs in
the following categories under “MySQL Server:” in the
MySQL bugs database at http://bugs.mysql.com, which
we intend to correct in upcoming releases of MySQL Cluster:
MySQL Cluster
Cluster Direct API (NDBAPI)
Cluster Disk Data
Cluster Replication
ClusterJ
This information is intended to be complete with respect to the conditions just set forth. You can report any discrepancies that you encounter to the MySQL bugs database using the instructions given in Section 1.6, “How to Report Bugs or Problems”. If we do not plan to fix the problem in MySQL Cluster NDB 7.2, we will add it to the list.
See Section 18.1.6.11, “Previous MySQL Cluster Issues Resolved in MySQL 5.1, MySQL Cluster NDB 6.x, and MySQL Cluster NDB 7.x” for a list of issues in MySQL Cluster in MySQL 5.1 that have been resolved in the current version.
Limitations and other issues specific to MySQL Cluster Replication are described in Section 18.6.3, “Known Issues in MySQL Cluster Replication”.
Some SQL statements relating to certain MySQL features produce
errors when used with NDB tables,
as described in the following list:
Temporary tables. Temporary tables are not supported. Trying either to create a temporary table that uses the
NDBstorage engine or to alter an existing temporary table to useNDBfails with the error Table storage engine 'ndbcluster' does not support the create option 'TEMPORARY'.Indexes and keys in NDB tables. Keys and indexes on MySQL Cluster tables are subject to the following limitations:
Column width. Attempting to create an index on an
NDBtable column whose width is greater than 3072 bytes succeeds, but only the first 3072 bytes are actually used for the index. In such cases, a warning Specified key was too long; max key length is 3072 bytes is issued, and aSHOW CREATE TABLEstatement shows the length of the index as 3072.TEXT and BLOB columns. You cannot create indexes on
NDBtable columns that use any of theTEXTorBLOBdata types.FULLTEXT indexes. The
NDBstorage engine does not supportFULLTEXTindexes, which are possible forMyISAMtables only.However, you can create indexes on
VARCHARcolumns ofNDBtables.USING HASH keys and NULL. Using nullable columns in unique keys and primary keys means that queries using these columns are handled as full table scans. To work around this issue, make the column
NOT NULL, or re-create the index without theUSING HASHoption.Prefixes. There are no prefix indexes; only entire columns can be indexed. (The size of an
NDBcolumn index is always the same as the width of the column in bytes, up to and including 3072 bytes, as described earlier in this section. Also see Section 18.1.6.6, “Unsupported or Missing Features in MySQL Cluster”, for additional information.)BIT columns. A
BITcolumn cannot be a primary key, unique key, or index, nor can it be part of a composite primary key, unique key, or index.AUTO_INCREMENT columns. Like other MySQL storage engines, the
NDBstorage engine can handle a maximum of oneAUTO_INCREMENTcolumn per table, and this column must be indexed. However, in the case of a MySQL Cluster table with no explicit primary key, anAUTO_INCREMENTcolumn is automatically defined and used as a “hidden” primary key. For this reason, you cannot create anNDBtable having anAUTO_INCREMENTcolumn and no explicit primary key.
MySQL Cluster and geometry data types. Geometry data types (
WKTandWKB) are supported forNDBtables. However, spatial indexes are not supported.Character sets and binary log files. Currently, the
ndb_apply_statusandndb_binlog_indextables are created using thelatin1(ASCII) character set. Because names of binary logs are recorded in this table, binary log files named using non-Latin characters are not referenced correctly in these tables. This is a known issue, which we are working to fix. (Bug #50226)To work around this problem, use only Latin-1 characters when naming binary log files or setting any the
--basedir,--log-bin, or--log-bin-indexoptions.Creating NDB tables with user-defined partitioning. Support for user-defined partitioning in MySQL Cluster is restricted to [
LINEAR]KEYpartitioning. Using any other partitioning type withENGINE=NDBorENGINE=NDBCLUSTERin aCREATE TABLEstatement results in an error.It is possible to override this restriction, but doing so is not supported for use in production settings. For details, see User-defined partitioning and the NDB storage engine (MySQL Cluster).
Default partitioning scheme. All MySQL Cluster tables are by default partitioned by
KEYusing the table's primary key as the partitioning key. If no primary key is explicitly set for the table, the “hidden” primary key automatically created by theNDBstorage engine is used instead. For additional discussion of these and related issues, see Section 19.2.5, “KEY Partitioning”.CREATE TABLEandALTER TABLEstatements that would cause a user-partitionedNDBCLUSTERtable not to meet either or both of the following two requirements are not permitted, and fail with an error:The table must have an explicit primary key.
All columns listed in the table's partitioning expression must be part of the primary key.
Exception. If a user-partitioned
NDBCLUSTERtable is created using an empty column-list (that is, usingPARTITION BY [LINEAR] KEY()), then no explicit primary key is required.Maximum number of partitions for NDBCLUSTER tables. The maximum number of partitions that can defined for a
NDBCLUSTERtable when employing user-defined partitioning is 8 per node group. (See Section 18.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”, for more information about MySQL Cluster node groups.DROP PARTITION not supported. It is not possible to drop partitions from
NDBtables usingALTER TABLE ... DROP PARTITION. The other partitioning extensions toALTER TABLE—ADD PARTITION,REORGANIZE PARTITION, andCOALESCE PARTITION—are supported for Cluster tables, but use copying and so are not optimized. See Section 19.3.1, “Management of RANGE and LIST Partitions” and Section 13.1.7, “ALTER TABLE Syntax”.Row-based replication. When using row-based replication with MySQL Cluster, binary logging cannot be disabled. That is, the
NDBstorage engine ignores the value ofsql_log_bin. (Bug #16680)
In this section, we list limits found in MySQL Cluster that either differ from limits found in, or that are not found in, standard MySQL.
Memory usage and recovery.
Memory consumed when data is inserted into an
NDB table is not automatically
recovered when deleted, as it is with other storage engines.
Instead, the following rules hold true:
A
DELETEstatement on anNDBtable makes the memory formerly used by the deleted rows available for re-use by inserts on the same table only. However, this memory can be made available for general re-use by performingOPTIMIZE TABLE.A rolling restart of the cluster also frees any memory used by deleted rows. See Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”.
A
DROP TABLEorTRUNCATE TABLEoperation on anNDBtable frees the memory that was used by this table for re-use by anyNDBtable, either by the same table or by anotherNDBtable.NoteRecall that
TRUNCATE TABLEdrops and re-creates the table. See Section 13.1.33, “TRUNCATE TABLE Syntax”.Limits imposed by the cluster's configuration. A number of hard limits exist which are configurable, but available main memory in the cluster sets limits. See the complete list of configuration parameters in Section 18.3.3, “MySQL Cluster Configuration Files”. Most configuration parameters can be upgraded online. These hard limits include:
Database memory size and index memory size (
DataMemoryandIndexMemory, respectively).DataMemoryis allocated as 32KB pages. As eachDataMemorypage is used, it is assigned to a specific table; once allocated, this memory cannot be freed except by dropping the table.See Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”, for more information.
The maximum number of operations that can be performed per transaction is set using the configuration parameters
MaxNoOfConcurrentOperationsandMaxNoOfLocalOperations.NoteBulk loading,
TRUNCATE TABLE, andALTER TABLEare handled as special cases by running multiple transactions, and so are not subject to this limitation.Different limits related to tables and indexes. For example, the maximum number of ordered indexes in the cluster is determined by
MaxNoOfOrderedIndexes, and the maximum number of ordered indexes per table is 16.
Node and data object maximums. The following limits apply to numbers of cluster nodes and metadata objects:
The maximum number of data nodes is 48.
A data node must have a node ID in the range of 1 to 48, inclusive. (Management and API nodes may use node IDs in the range 1 to 255, inclusive.)
The total maximum number of nodes in a MySQL Cluster is 255. This number includes all SQL nodes (MySQL Servers), API nodes (applications accessing the cluster other than MySQL servers), data nodes, and management servers.
The maximum number of metadata objects in current versions of MySQL Cluster is 20320. This limit is hard-coded.
See Section 18.1.6.11, “Previous MySQL Cluster Issues Resolved in MySQL 5.1, MySQL Cluster NDB 6.x, and MySQL Cluster NDB 7.x”, for more information.
A number of limitations exist in MySQL Cluster with regard to the handling of transactions. These include the following:
Transaction isolation level. The
NDBCLUSTERstorage engine supports only theREAD COMMITTEDtransaction isolation level. (InnoDB, for example, supportsREAD COMMITTED,READ UNCOMMITTED,REPEATABLE READ, andSERIALIZABLE.) See Section 18.5.3.4, “MySQL Cluster Backup Troubleshooting”, for information on how this can affect backing up and restoring Cluster databases.)Transactions and BLOB or TEXT columns.
NDBCLUSTERstores only part of a column value that uses any of MySQL'sBLOBorTEXTdata types in the table visible to MySQL; the remainder of theBLOBorTEXTis stored in a separate internal table that is not accessible to MySQL. This gives rise to two related issues of which you should be aware whenever executingSELECTstatements on tables that contain columns of these types:For any
SELECTfrom a MySQL Cluster table: If theSELECTincludes aBLOBorTEXTcolumn, theREAD COMMITTEDtransaction isolation level is converted to a read with read lock. This is done to guarantee consistency.For any
SELECTwhich uses a unique key lookup to retrieve any columns that use any of theBLOBorTEXTdata types and that is executed within a transaction, a shared read lock is held on the table for the duration of the transaction—that is, until the transaction is either committed or aborted.This issue does not occur for queries that use index or table scans, even against
NDBtables havingBLOBorTEXTcolumns.For example, consider the table
tdefined by the followingCREATE TABLEstatement:CREATE TABLE t ( a INT NOT NULL AUTO_INCREMENT PRIMARY KEY, b INT NOT NULL, c INT NOT NULL, d TEXT, INDEX i(b), UNIQUE KEY u(c) ) ENGINE = NDB,Either of the following queries on
tcauses a shared read lock, because the first query uses a primary key lookup and the second uses a unique key lookup:SELECT * FROM t WHERE a = 1; SELECT * FROM t WHERE c = 1;
However, none of the four queries shown here causes a shared read lock:
SELECT * FROM t WHERE b = 1; SELECT * FROM t WHERE d = '1'; SELECT * FROM t; SELECT b,c WHERE a = 1;
This is because, of these four queries, the first uses an index scan, the second and third use table scans, and the fourth, while using a primary key lookup, does not retrieve the value of any
BLOBorTEXTcolumns.You can help minimize issues with shared read locks by avoiding queries that use unique key lookups that retrieve
BLOBorTEXTcolumns, or, in cases where such queries are not avoidable, by committing transactions as soon as possible afterward.
Rollbacks. There are no partial transactions, and no partial rollbacks of transactions. A duplicate key or similar error causes the entire transaction to be rolled back.
This behavior differs from that of other transactional storage engines such as
InnoDBthat may roll back individual statements.Transactions and memory usage. As noted elsewhere in this chapter, MySQL Cluster does not handle large transactions well; it is better to perform a number of small transactions with a few operations each than to attempt a single large transaction containing a great many operations. Among other considerations, large transactions require very large amounts of memory. Because of this, the transactional behavior of a number of MySQL statements is effected as described in the following list:
TRUNCATE TABLEis not transactional when used onNDBtables. If aTRUNCATE TABLEfails to empty the table, then it must be re-run until it is successful.DELETE FROM(even with noWHEREclause) is transactional. For tables containing a great many rows, you may find that performance is improved by using severalDELETE FROM ... LIMIT ...statements to “chunk” the delete operation. If your objective is to empty the table, then you may wish to useTRUNCATE TABLEinstead.LOAD DATA statements.
LOAD DATA INFILEis not transactional when used onNDBtables.ImportantWhen executing a
LOAD DATA INFILEstatement, theNDBengine performs commits at irregular intervals that enable better utilization of the communication network. It is not possible to know ahead of time when such commits take place.ALTER TABLE and transactions. When copying an
NDBtable as part of anALTER TABLE, the creation of the copy is nontransactional. (In any case, this operation is rolled back when the copy is deleted.)
Transactions and the COUNT() function. When using MySQL Cluster Replication, it is not possible to guarantee the transactional consistency of the
COUNT()function on the slave. In other words, when performing on the master a series of statements (INSERT,DELETE, or both) that changes the number of rows in a table within a single transaction, executingSELECT COUNT(*) FROMqueries on the slave may yield intermediate results. This is due to the fact thattableSELECT COUNT(...)may perform dirty reads, and is not a bug in theNDBstorage engine. (See Bug #31321 for more information.)
Starting, stopping, or restarting a node may give rise to temporary errors causing some transactions to fail. These include the following cases:
Temporary errors. When first starting a node, it is possible that you may see Error 1204 Temporary failure, distribution changed and similar temporary errors.
Errors due to node failure. The stopping or failure of any data node can result in a number of different node failure errors. (However, there should be no aborted transactions when performing a planned shutdown of the cluster.)
In either of these cases, any errors that are generated must be handled within the application. This should be done by retrying the transaction.
See also Section 18.1.6.2, “Limits and Differences of MySQL Cluster from Standard MySQL Limits”.
Some database objects such as tables and indexes have different
limitations when using the
NDBCLUSTER storage engine:
Database and table names. When using the
NDBstorage engine, the maximum allowed length both for database names and for table names is 63 characters.Number of database objects. The maximum number of all
NDBdatabase objects in a single MySQL Cluster—including databases, tables, and indexes—is limited to 20320.Attributes per table. The maximum number of attributes (that is, columns and indexes) that can belong to a given table is 512.
Attributes per key. The maximum number of attributes per key is 32.
Row size. The maximum permitted size of any one row is 14000 bytes (as of MySQL Cluster NDB 7.0). Each
BLOBorTEXTcolumn contributes 256 + 8 = 264 bytes to this total.BIT column storage per table. The maximum combined width for all
BITcolumns used in a givenNDBtable is 4096.
A number of features supported by other storage engines are not
supported for NDB tables. Trying to
use any of these features in MySQL Cluster does not cause errors
in or of itself; however, errors may occur in applications that
expects the features to be supported or enforced. Statements
referencing such features, even if effectively ignored by
NDB, must be syntactically and otherwise
valid.
Foreign key constraints. Prior to MySQL Cluster NDB 7.3, the foreign key construct is ignored, just as it is by
MyISAMtables. Foreign keys are supported in MySQL Cluster NDB 7.3 and later.Index prefixes. Prefixes on indexes are not supported for
NDBtables. If a prefix is used as part of an index specification in a statement such asCREATE TABLE,ALTER TABLE, orCREATE INDEX, the prefix is not created byNDB.A statement containing an index prefix, and creating or modifying an
NDBtable, must still be syntactically valid. For example, the following statement always fails with Error 1089 Incorrect prefix key; the used key part isn't a string, the used length is longer than the key part, or the storage engine doesn't support unique prefix keys, regardless of storage engine:CREATE TABLEt1 ( c1 INT NOT NULL, c2 VARCHAR(100), INDEX i1 (c2(500)) );This happens on account of the SQL syntax rule that no index may have a prefix larger than itself.
Savepoints and rollbacks. Savepoints and rollbacks to savepoints are ignored as in
MyISAM.Durability of commits. There are no durable commits on disk. Commits are replicated, but there is no guarantee that logs are flushed to disk on commit.
Replication. Statement-based replication is not supported. Use
--binlog-format=ROW(or--binlog-format=MIXED) when setting up cluster replication. See Section 18.6, “MySQL Cluster Replication”, for more information.
See Section 18.1.6.3, “Limits Relating to Transaction Handling in MySQL Cluster”,
for more information relating to limitations on transaction
handling in NDB.
The following performance issues are specific to or especially pronounced in MySQL Cluster:
Range scans. There are query performance issues due to sequential access to the
NDBstorage engine; it is also relatively more expensive to do many range scans than it is with eitherMyISAMorInnoDB.Reliability of Records in range. The
Records in rangestatistic is available but is not completely tested or officially supported. This may result in nonoptimal query plans in some cases. If necessary, you can employUSE INDEXorFORCE INDEXto alter the execution plan. See Section 8.9.3, “Index Hints”, for more information on how to do this.Unique hash indexes. Unique hash indexes created with
USING HASHcannot be used for accessing a table ifNULLis given as part of the key.
The following are limitations specific to the
NDBCLUSTER storage engine:
Machine architecture. All machines used in the cluster must have the same architecture. That is, all machines hosting nodes must be either big-endian or little-endian, and you cannot use a mixture of both. For example, you cannot have a management node running on a PowerPC which directs a data node that is running on an x86 machine. This restriction does not apply to machines simply running mysql or other clients that may be accessing the cluster's SQL nodes.
Binary logging. MySQL Cluster has the following limitations or restrictions with regard to binary logging:
sql_log_binhas no effect on data operations; however, it is supported for schema operations.MySQL Cluster cannot produce a binary log for tables having
BLOBcolumns but no primary key.Only the following schema operations are logged in a cluster binary log which is not on the mysqld executing the statement:
See also Section 18.1.6.10, “Limitations Relating to Multiple MySQL Cluster Nodes”.
Disk Data object maximums and minimums. Disk data objects are subject to the following maximums and minimums:
Maximum number of tablespaces: 232 (4294967296)
Maximum number of data files per tablespace: 216 (65536)
Maximum data file size: The theoretical limit is 64G; however, the practical upper limit is 32G. This is equivalent to 32768 extents of 1M each.
Since a MySQL Cluster Disk Data table can use at most 1 tablespace, this means that the theoretical upper limit to the amount of data (in bytes) that can be stored on disk by a single
NDBtable is 32G * 65536 = 2251799813685248, or approximately 2 petabytes.The theoretical maximum number of extents per tablespace data file is 216 (65536); however, for practical purposes, the recommended maximum number of extents per data file is 215 (32768).
The minimum and maximum possible sizes of extents for tablespace data files are 32K and 2G, respectively. See Section 13.1.18, “CREATE TABLESPACE Syntax”, for more information.
Disk Data tables and diskless mode. Use of Disk Data tables is not supported when running the cluster in diskless mode. Beginning with MySQL 5.1.12, it is prohibited altogether. (Bug #20008)
Multiple SQL nodes.
The following are issues relating to the use of multiple MySQL
servers as MySQL Cluster SQL nodes, and are specific to the
NDBCLUSTER storage engine:
No distributed table locks. A
LOCK TABLESworks only for the SQL node on which the lock is issued; no other SQL node in the cluster “sees” this lock. This is also true for a lock issued by any statement that locks tables as part of its operations. (See next item for an example.)ALTER TABLE operations.
ALTER TABLEis not fully locking when running multiple MySQL servers (SQL nodes). (As discussed in the previous item, MySQL Cluster does not support distributed table locks.)
Multiple management nodes. When using multiple management servers:
If any of the management servers are running on the same host, you must give nodes explicit IDs in connection strings because automatic allocation of node IDs does not work across multiple management servers on the same host. This is not required if every management server resides on a different host.
When a management server starts, it first checks for any other management server in the same MySQL Cluster, and upon successful connection to the other management server uses its configuration data. This means that the management server
--reloadand--initialstartup options are ignored unless the management server is the only one running. It also means that, when performing a rolling restart of a MySQL Cluster with multiple management nodes, the management server reads its own configuration file if (and only if) it is the only management server running in this MySQL Cluster. See Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”, for more information.
Multiple network addresses. Multiple network addresses per data node are not supported. Use of these is liable to cause problems: In the event of a data node failure, an SQL node waits for confirmation that the data node went down but never receives it because another route to that data node remains open. This can effectively make the cluster inoperable.
It is possible to use multiple network hardware
interfaces (such as Ethernet cards) for a
single data node, but these must be bound to the same address.
This also means that it not possible to use more than one
[tcp] section per connection in the
config.ini file. See
Section 18.3.3.9, “MySQL Cluster TCP/IP Connections”, for more
information.
A number of limitations and related issues existing in earlier versions of MySQL Cluster have been resolved:
Variable-length column support. The
NDBCLUSTERstorage engine now supports variable-length column types for in-memory tables.Previously, for example, any Cluster table having one or more
VARCHARfields which contained only relatively small values, much more memory and disk space were required when using theNDBCLUSTERstorage engine than would have been the case for the same table and data using theMyISAMengine. In other words, in the case of aVARCHARcolumn, such a column required the same amount of storage as aCHARcolumn of the same size. In MySQL 5.1, this is no longer the case for in-memory tables, where storage requirements for variable-length column types such asVARCHARandBINARYare comparable to those for these column types when used inMyISAMtables (see Section 11.7, “Data Type Storage Requirements”).ImportantFor MySQL Cluster Disk Data tables, the fixed-width limitation continues to apply. See Section 18.5.12, “MySQL Cluster Disk Data Tables”.
Replication with MySQL Cluster. It is now possible to use MySQL replication with Cluster databases. For details, see Section 18.6, “MySQL Cluster Replication”.
Circular Replication. Circular replication is also supported with MySQL Cluster, beginning with MySQL 5.1.18. See Section 18.6.10, “MySQL Cluster Replication: Multi-Master and Circular Replication”.
auto_increment_increment and auto_increment_offset. The
auto_increment_incrementandauto_increment_offsetserver system variables are supported for MySQL Cluster Replication.Backup and restore between architectures. It is possible to perform a Cluster backup and restore between different architectures. Previously—for example—you could not back up a cluster running on a big-endian platform and then restore from that backup to a cluster running on a little-endian system. (Bug #19255)
Multiple data nodes, multi-threaded data nodes. MySQL Cluster NDB 7.2 supports multiple data node processes on a single host as well as multi-threaded data node processes. See Section 18.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”, for more information.
Identifiers. Formerly (in MySQL 5.0 and earlier), database names, table names and attribute names could not be as long for
NDBtables as tables using other storage engines, because attribute names were truncated internally. In MySQL 5.1 and later, names of MySQL Cluster databases, tables, and table columns follow the same rules regarding length as they do for any other storage engine.Length of CREATE TABLE statements.
CREATE TABLEstatements may be no more than 4096 characters in length. This limitation affects MySQL 5.1.6, 5.1.7, and 5.1.8 only. (See Bug #17813)IGNORE and REPLACE functionality. In MySQL 5.1.7 and earlier,
INSERT IGNORE,UPDATE IGNORE, andREPLACEwere supported only for primary keys, but not for unique keys. It was possible to work around this issue by removing the constraint, then dropping the unique index, performing any inserts, and then adding the unique index again.This limitation was removed for
INSERT IGNOREandREPLACEin MySQL 5.1.8. (See Bug #17431.)AUTO_INCREMENT columns. In MySQL 5.1.10 and earlier versions, the maximum number of tables having
AUTO_INCREMENTcolumns—including those belonging to hidden primary keys—was 2048.This limitation was lifted in MySQL 5.1.11.
Maximum number of cluster nodes. The total maximum number of nodes in a MySQL Cluster is 255, including all SQL nodes (MySQL Servers), API nodes (applications accessing the cluster other than MySQL servers), data nodes, and management servers. The total number of data nodes and management nodes is 63, of which up to 48 can be data nodes.
NoteA data node cannot have a node ID greater than 49.
Recovery of memory from deleted rows. Memory can be reclaimed from an
NDBtable for reuse with anyNDBtable by employingOPTIMIZE TABLE, subject to the following limitations:Only in-memory tables are supported; the
OPTIMIZE TABLEstatement has no effect on MySQL Cluster Disk Data tables.Only variable-length columns (such as those declared as
VARCHAR,TEXT, orBLOB) are supported.However, you can force columns defined using fixed-length data types (such as
CHAR) to be dynamic using theROW_FORMATorCOLUMN_FORMAToption with aCREATE TABLEorALTER TABLEstatement.See Section 13.1.17, “CREATE TABLE Syntax”, and Section 13.1.7, “ALTER TABLE Syntax”, for information on these options.
You can regulate the effects of
OPTIMIZEon performance by adjusting the value of the global system variablendb_optimization_delay, which sets the number of milliseconds to wait between batches of rows being processed byOPTIMIZE. The default value is 10 milliseconds. It is possible to set a lower value (to a minimum of0), but not recommended. The maximum is 100000 milliseconds (that is, 100 seconds).Number of tables. The maximum number of
NDBCLUSTERtables in a single MySQL Cluster is included in the total maximum number ofNDBCLUSTERdatabase objects (20320). (See Section 18.1.6.5, “Limits Associated with Database Objects in MySQL Cluster”.)Adding and dropping of data nodes. In MySQL Cluster NDB 7.2 (MySQL Cluster NDB 7.0 and later), it is possible to add new data nodes to a running MySQL Cluster by performing a rolling restart, so that the cluster and the data stored in it remain available to applications.
When planning to increase the number of data nodes in the cluster online, you should be aware of and take into account the following issues:
New data nodes can be added online to a MySQL Cluster only as part of a new node group.
New data nodes can be added online, but cannot be dropped online. Reducing the number of data nodes requires a system restart of the cluster.
As in previous MySQL Cluster releases, it is not possible to change online either the number of replicas (
NoOfReplicasconfiguration parameter) or the number of data nodes per node group. These changes require a system restart.Redistribution of existing cluster data using the new data nodes is not automatic; however, this can be accomplished using simple SQL statements in the mysql client or other MySQL client application once the nodes have been added. During this procedure, it is not possible to perform DDL operations, although DML operations can continue as normal.
The distribution of new cluster data (that is, data stored in the cluster after the new nodes have been added) uses the new nodes without manual intervention.
For more information, see Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”.
Native support for default column values. Starting with MySQL Cluster NDB 7.1.0, default values for table columns are stored by
NDBCLUSTER, rather than by the MySQL server as was previously the case. Because less data must be sent from an SQL node to the data nodes, inserts on tables having column value defaults can be performed more efficiently than before.Tables created using previous MySQL Cluster releases can still be used in MySQL Cluster 7.1.0 and later, although they do not support native default values and continue to use defaults supplied by the MySQL server until they are upgraded. This can be done by means of an offline
ALTER TABLEstatement.ImportantYou cannot set or change a table column's default value using an online
ALTER TABLEoperationDistribution of MySQL users and privileges. Previously, MySQL users and privileges created on one SQL node were unique to that SQL node, due to the fact that the MySQL grant tables were restricted to using the
MyISAMstorage engine. Beginning with MySQL Cluster NDB 7.2.0, it is possible, following installation of the MySQL Cluster software and setup of the desired users and privileges on one SQL node, to convert the grant tables to useNDBand thus to distribute the users and privileges across all SQL nodes connected to the cluster. You can do this by loading and making use of a set of stored procedures defined in an SQL script supplied with the MySQL Cluster distribution. For more information, see Section 18.5.14, “Distributed MySQL Privileges for MySQL Cluster”.Number of rows per partition. Previously, a single MySQL Cluster partition could hold a maximum of 46137488 rows. This limitation was removed in MySQL Cluster NDB 7.2.9. (Bug #13844405, Bug #14000373)
If you are still using a previous MySQL Cluster release, you can work around this limitation by taking advantage of the fact that the number of partitions is the same as the number of data nodes in the cluster (see Section 18.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”). This means that, by increasing the number of data nodes, you can increase the available space for storing data.
MySQL Cluster NDB 7.2 also supports increasing the number of data nodes in the cluster while the cluster remains in operation. See Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”, for more information.
It is also possible to increase the number of partitions for
NDBtables by using explicitKEYorLINEAR KEYpartitioning (see Section 19.2.5, “KEY Partitioning”).
- 18.2.1 Installing MySQL Cluster on Linux
- 18.2.2 Installing MySQL Cluster on Windows
- 18.2.3 Initial Configuration of MySQL Cluster
- 18.2.4 Initial Startup of MySQL Cluster
- 18.2.5 MySQL Cluster Example with Tables and Data
- 18.2.6 Safe Shutdown and Restart of MySQL Cluster
- 18.2.7 Upgrading and Downgrading MySQL Cluster NDB 7.2
This section describes the basics for planning, installing, configuring, and running a MySQL Cluster. Whereas the examples in Section 18.3, “Configuration of MySQL Cluster” provide more in-depth information on a variety of clustering options and configuration, the result of following the guidelines and procedures outlined here should be a usable MySQL Cluster which meets the minimum requirements for availability and safeguarding of data.
For information about upgrading or downgrading a MySQL Cluster between release versions, see Section 18.2.7, “Upgrading and Downgrading MySQL Cluster NDB 7.2”.
This section covers hardware and software requirements; networking issues; installation of MySQL Cluster; configuration issues; starting, stopping, and restarting the cluster; loading of a sample database; and performing queries.
Assumptions. The following sections make a number of assumptions regarding the cluster's physical and network configuration. These assumptions are discussed in the next few paragraphs.
Cluster nodes and host computers. The cluster consists of four nodes, each on a separate host computer, and each with a fixed network address on a typical Ethernet network as shown here:
| Node | IP Address |
|---|---|
| Management node (mgmd) | 192.168.0.10 |
| SQL node (mysqld) | 192.168.0.20 |
| Data node "A" (ndbd) | 192.168.0.30 |
| Data node "B" (ndbd) | 192.168.0.40 |
This may be made clearer by the following diagram:
Network addressing.
In the interest of simplicity (and reliability), this
How-To uses only numeric IP addresses.
However, if DNS resolution is available on your network, it is
possible to use host names in lieu of IP addresses in configuring
Cluster. Alternatively, you can use the hosts
file (typically /etc/hosts for Linux and
other Unix-like operating systems,
C:\WINDOWS\system32\drivers\etc\hosts on
Windows, or your operating system's equivalent) for providing
a means to do host lookup if such is available.
Potential hosts file issues.
A common problem when trying to use host names for Cluster nodes
arises because of the way in which some operating systems
(including some Linux distributions) set up the system's own
host name in the /etc/hosts during
installation. Consider two machines with the host names
ndb1 and ndb2, both in the
cluster network domain. Red Hat Linux
(including some derivatives such as CentOS and Fedora) places the
following entries in these machines'
/etc/hosts files:
# ndb1 /etc/hosts:
127.0.0.1 ndb1.cluster ndb1 localhost.localdomain localhost
# ndb2 /etc/hosts:
127.0.0.1 ndb2.cluster ndb2 localhost.localdomain localhost
SUSE Linux (including OpenSUSE) places these entries in the
machines' /etc/hosts files:
# ndb1 /etc/hosts:
127.0.0.1 localhost
127.0.0.2 ndb1.cluster ndb1
# ndb2 /etc/hosts:
127.0.0.1 localhost
127.0.0.2 ndb2.cluster ndb2
In both instances, ndb1 routes
ndb1.cluster to a loopback IP address, but gets a
public IP address from DNS for ndb2.cluster,
while ndb2 routes ndb2.cluster
to a loopback address and obtains a public address for
ndb1.cluster. The result is that each data node
connects to the management server, but cannot tell when any other
data nodes have connected, and so the data nodes appear to hang
while starting.
You cannot mix localhost and other host names
or IP addresses in config.ini. For these
reasons, the solution in such cases (other than to use IP
addresses for all
config.ini HostName
entries) is to remove the fully qualified host names from
/etc/hosts and use these in
config.ini for all cluster hosts.
Host computer type. Each host computer in our installation scenario is an Intel-based desktop PC running a supported operating system installed to disk in a standard configuration, and running no unnecessary services. The core operating system with standard TCP/IP networking capabilities should be sufficient. Also for the sake of simplicity, we also assume that the file systems on all hosts are set up identically. In the event that they are not, you should adapt these instructions accordingly.
Network hardware. Standard 100 Mbps or 1 gigabit Ethernet cards are installed on each machine, along with the proper drivers for the cards, and that all four hosts are connected through a standard-issue Ethernet networking appliance such as a switch. (All machines should use network cards with the same throughput. That is, all four machines in the cluster should have 100 Mbps cards or all four machines should have 1 Gbps cards.) MySQL Cluster works in a 100 Mbps network; however, gigabit Ethernet provides better performance.
MySQL Cluster is not intended for use in a network for which throughput is less than 100 Mbps or which experiences a high degree of latency. For this reason (among others), attempting to run a MySQL Cluster over a wide area network such as the Internet is not likely to be successful, and is not supported in production.
Sample data.
We use the world database which is available
for download from the MySQL Web site (see
http://dev.mysql.com/doc/index-other.html). We assume that
each machine has sufficient memory for running the operating
system, required MySQL Cluster processes, and (on the data nodes)
storing the database.
For general information about installing MySQL, see Chapter 2, Installing and Upgrading MySQL. For information about installation of MySQL Cluster on Linux and other Unix-like operating systems, see Section 18.2.1, “Installing MySQL Cluster on Linux”. For information about installation of MySQL Cluster on Windows operating systems, see Section 18.2.2, “Installing MySQL Cluster on Windows”.
For general information about MySQL Cluster hardware, software, and networking requirements, see Section 18.1.3, “MySQL Cluster Hardware, Software, and Networking Requirements”.
This section covers installation of MySQL Cluster on Linux and other Unix-like operating systems. While the next few sections refer to a Linux operating system, the instructions and procedures given there should be easily adaptable to other supported Unix-like platforms.
MySQL Cluster NDB 7.2 is also available for Windows operating systems; for installation and setup instructions specific to Windows, see Section 18.2.2, “Installing MySQL Cluster on Windows”.
Each MySQL Cluster host computer must have the correct executable programs installed. A host running an SQL node must have installed on it a MySQL Server binary (mysqld). Management nodes require the management server daemon (ndb_mgmd); data nodes require the data node daemon (ndbd or ndbmtd). It is not necessary to install the MySQL Server binary on management node hosts and data node hosts. It is recommended that you also install the management client (ndb_mgm) on the management server host.
Installation of MySQL Cluster on Linux can be done using precompiled binaries from Oracle (downloaded as a .tar.gz archive), with RPM packages (also available from Oracle), or from source code. All three of these installation methods are described in the section that follow.
Regardless of the method used, it is still necessary following installation of the MySQL Cluster binaries to create configuration files for all cluster nodes, before you can start the cluster. See Section 18.2.3, “Initial Configuration of MySQL Cluster”.
This section covers the steps necessary to install the correct executables for each type of Cluster node from precompiled binaries supplied by Oracle.
For setting up a cluster using precompiled binaries, the first
step in the installation process for each cluster host is to
download the latest MySQL Cluster NDB 7.2 binary archive
(mysql-cluster-gpl-7.2.24-linux-i686-glibc23.tar.gz)
from the MySQL Cluster
downloads area. We assume that you have placed this file
in each machine's /var/tmp directory.
(If you do require a custom binary, see
Section 2.9.3, “Installing MySQL Using a Development Source Tree”.)
After completing the installation, do not yet start any of the binaries. We show you how to do so following the configuration of the nodes (see Section 18.2.3, “Initial Configuration of MySQL Cluster”).
SQL nodes.
On each of the machines designated to host SQL nodes, perform
the following steps as the system root
user:
Check your
/etc/passwdand/etc/groupfiles (or use whatever tools are provided by your operating system for managing users and groups) to see whether there is already amysqlgroup andmysqluser on the system. Some OS distributions create these as part of the operating system installation process. If they are not already present, create a newmysqluser group, and then add amysqluser to this group:shell>
groupadd mysqlshell>useradd -g mysql -s /bin/false mysqlThe syntax for useradd and groupadd may differ slightly on different versions of Unix, or they may have different names such as adduser and addgroup.
Change location to the directory containing the downloaded file, unpack the archive, and create a symbolic link named
mysqlto themysqldirectory. Note that the actual file and directory names vary according to the MySQL Cluster version number.shell>
cd /var/tmpshell>tar -C /usr/local -xzvf mysql-cluster-gpl-7.2.24-linux2.6.tar.gzshell>ln -s /usr/local/mysql-cluster-gpl-7.2.24-linux2.6-i686 /usr/local/mysqlChange location to the
mysqldirectory and run the supplied script for creating the system databases:shell>
cd mysqlshell>scripts/mysql_install_db --user=mysqlSet the necessary permissions for the MySQL server and data directories:
shell>
chown -R root .shell>chown -R mysql datashell>chgrp -R mysql .Copy the MySQL startup script to the appropriate directory, make it executable, and set it to start when the operating system is booted up:
shell>
cp support-files/mysql.server /etc/rc.d/init.d/shell>chmod +x /etc/rc.d/init.d/mysql.servershell>chkconfig --add mysql.server(The startup scripts directory may vary depending on your operating system and version—for example, in some Linux distributions, it is
/etc/init.d.)Here we use Red Hat's chkconfig for creating links to the startup scripts; use whatever means is appropriate for this purpose on your platform, such as update-rc.d on Debian.
Remember that the preceding steps must be repeated on each machine where an SQL node is to reside.
Data nodes.
Installation of the data nodes does not require the
mysqld binary. Only the MySQL Cluster data
node executable ndbd (single-threaded) or
ndbmtd (multi-threaded) is required. These
binaries can also be found in the .tar.gz
archive. Again, we assume that you have placed this archive in
/var/tmp.
As system root (that is, after using
sudo, su root, or your
system's equivalent for temporarily assuming the system
administrator account's privileges), perform the following steps
to install the data node binaries on the data node hosts:
Change location to the
/var/tmpdirectory, and extract the ndbd and ndbmtd binaries from the archive into a suitable directory such as/usr/local/bin:shell>
cd /var/tmpshell>tar -zxvf mysql-5.5.48-ndb-7.2.24-linux-i686-glibc23.tar.gzshell>cd mysql-5.5.48-ndb-7.2.24-linux-i686-glibc23shell>cp bin/ndbd /usr/local/bin/ndbdshell>cp bin/ndbmtd /usr/local/bin/ndbmtd(You can safely delete the directory created by unpacking the downloaded archive, and the files it contains, from
/var/tmponce ndb_mgm and ndb_mgmd have been copied to the executables directory.)Change location to the directory into which you copied the files, and then make both of them executable:
shell>
cd /usr/local/binshell>chmod +x ndb*
The preceding steps should be repeated on each data node host.
Although only one of the data node executables is required to run a MySQL Cluster data node, we have shown you how to install both ndbd and ndbmtd in the preceding instructions. We recommend that you do this when installing or upgrading MySQL Cluster, even if you plan to use only one of them, since this will save time and trouble in the event that you later decide to change from one to the other.
The data directory on each machine hosting a data node is
/usr/local/mysql/data. This piece of
information is essential when configuring the management node.
(See Section 18.2.3, “Initial Configuration of MySQL Cluster”.)
Management nodes.
Installation of the management node does not require the
mysqld binary. Only the MySQL Cluster
management server (ndb_mgmd) is required;
you most likely want to install the management client
(ndb_mgm) as well. Both of these binaries
also be found in the .tar.gz archive.
Again, we assume that you have placed this archive in
/var/tmp.
As system root, perform the following steps
to install ndb_mgmd and
ndb_mgm on the management node host:
Change location to the
/var/tmpdirectory, and extract the ndb_mgm and ndb_mgmd from the archive into a suitable directory such as/usr/local/bin:shell>
cd /var/tmpshell>tar -zxvf mysql-5.5.48-ndb-7.2.24-linux2.6-i686.tar.gzshell>cd mysql-5.5.48-ndb-7.2.24-linux2.6-i686shell>cp bin/ndb_mgm* /usr/local/bin(You can safely delete the directory created by unpacking the downloaded archive, and the files it contains, from
/var/tmponce ndb_mgm and ndb_mgmd have been copied to the executables directory.)Change location to the directory into which you copied the files, and then make both of them executable:
shell>
cd /usr/local/binshell>chmod +x ndb_mgm*
In Section 18.2.3, “Initial Configuration of MySQL Cluster”, we create configuration files for all of the nodes in our example MySQL Cluster.
This section covers the steps necessary to install the correct executables for each type of MySQL Cluster node using RPM packages supplied by Oracle.
RPMs are available for both 32-bit and 64-bit Linux platforms. The filenames for these RPMs use the following pattern:
MySQL-Cluster-component-producttype-ndbversion.distribution.architecture.rpmcomponent:= {server | client [|other]}producttype:= {gpl | advanced}ndbversion:=major.minor.releasedistribution:= {sles10 | rhel5 | el6}architecture:= {i386 | x86_64}
The component can be
server or client. (Other
values are possible, but since only the
server and client
components are required for a working MySQL Cluster
installation, we do not discuss them here.) The
producttype for Community RPMs
downloaded from http://dev.mysql.com/downloads/cluster/ is
always gpl; advanced is
used to indicate commercial releases.
ndbversion represents the three-part
NDB storage engine version number in
7.2.x format. The
distribution can be one of
sles11 (SUSE Enterprise Linux 11),
rhel5 (Oracle Linux 5, Red Hat Enterprise
Linux 4 and 5), or el6 (Oracle Linux 6, Red
Hat Enterprise Linux 6) The
architecture is
i386 for 32-bit RPMs and
x86_64 for 64-bit versions.
For a MySQL Cluster, one and possibly two RPMs are required:
The
serverRPM (for example,MySQL-Cluster-server-gpl-7.2.24-1.sles11.i386.rpm), which supplies the core files needed to run a MySQL Server withNDBCLUSTERstorage engine support (that is, as a MySQL Cluster SQL node) as well as all MySQL Cluster executables, including the management node, data node, and ndb_mgm client binaries. This RPM is always required for installing MySQL Cluster NDB 7.2.If you do not have your own client application capable of administering a MySQL server, you should also obtain and install the
clientRPM (for example,MySQL-Cluster-client-gpl-7.2.24-1.sles11.i386.rpm), which supplies the mysql client
The MySQL Cluster version number in the RPM file names (shown
here as 7.2.24) can vary
according to the version which you are actually using.
It is very important that all of the Cluster RPMs to
be installed have the same version number. The
architecture designation should be
appropriate to the machine on which the RPM is to be installed;
in particular, you should keep in mind that 64-bit RPMs cannot
be used with 32-bit operating system.
Data nodes.
On a computer that is to host a cluster data node it is
necessary to install only the server RPM.
To do so, copy this RPM to the data node host, and run the
following command as the system root user, replacing the name
shown for the RPM as necessary to match that of the RPM
downloaded from the MySQL web site:
shell> rpm -Uhv MySQL-Cluster-server-gpl-7.2.24-1.sles11.i386.rpm
Although this installs all MySQL Cluster binaries, only the
program ndbd or ndbmtd
(both in /usr/sbin) is actually needed to
run a MySQL Cluster data node.
SQL nodes.
On each machine to be used for hosting a cluster SQL node,
install the server RPM by executing the
following command as the system root user, replacing the name
shown for the RPM as necessary to match the name of the RPM
downloaded from the MySQL web site:
shell> rpm -Uhv MySQL-Cluster-server-gpl-7.2.24-1.sles11.i386.rpm
This installs the MySQL server binary
(mysqld) with
NDB storage engine support in the
/usr/sbin directory, as well as all needed
MySQL Server support files. It also installs the
mysql.server and
mysqld_safe startup scripts (in
/usr/share/mysql and
/usr/bin, respectively). The RPM installer
should take care of general configuration issues (such as
creating the mysql user and group, if needed)
automatically.
To administer the SQL node (MySQL server), you should also
install the client RPM, as shown here:
shell> rpm -Uhv MySQL-Cluster-client-gpl-7.2.24-1.sles11.i386.rpm
This installs the mysql client program.
Management nodes.
To install the MySQL Cluster management server, it is
necessary only to use the server RPM. Copy
this RPM to the computer intended to host the management node,
and then install it by running the following command as the
system root user (replace the name shown for the RPM as
necessary to match that of the server RPM
downloaded from the MySQL web site):
shell> rpm -Uhv MySQL-Cluster-server-gpl-7.2.24-1.sles11.i386.rpm
Although this RPM installs many other files, only the management
server binary ndb_mgmd (in the
/usr/sbin directory) is actually required
for running a management node. The server RPM
also installs ndb_mgm, the
NDB management client.
See Section 2.5.1, “Installing MySQL on Linux Using RPM Packages”, for general information about installing MySQL using RPMs supplied by Oracle.
After installing from RPM, you still need to configure the cluster as discussed in Section 18.2.3, “Initial Configuration of MySQL Cluster”.
A number of RPMs used by MySQL Cluster NDB 7.1 were made
obsolete and discontinued in MySQL Cluster NDB 7.2. These
include the former MySQL-Cluster-clusterj,
MySQL-Cluster-extra,
MySQL-Cluster-management,
MySQL-Cluster-storage, and MySQL
Cluster-tools RPMs; all of these have been merged
into the MySQL-Cluster-server RPM. When
upgrading from a MySQL Cluster NDB 7.1 RPM installation to
MySQL Cluster NDB 7.2.3 or an earlier MySQL Cluster NDB 7.2
release, it was necessary to remove these packages manually
before installing the MySQL Cluster NDB 7.2
MySQL-Cluster-server RPM. This issue is
fixed in MySQL Cluster NDB 7.2.4 and later, where the
MySQL-Cluster-server package specifically
obsoletes the discontinued packages (BUG #13545589).
The section provides information about installing MySQL Cluster on Debian and related Linux distributions such Ubuntu using the .deb files supplied by Oracle for this purpose.
Oracle provides .deb installer files for
MySQL Cluster NDB 7.2 for 32-bit and 64-bit platforms. For a
Debian-based system, only a single installer file is necessary.
This file is named using the pattern shown here, according to
the applicable MySQL Cluster version, Debian version, and
architecture:
mysql-cluster-gpl-ndbver-debiandebianver-arch.deb
Here, ndbver is the 3-part
NDB engine version number,
debianver is the major version of
Debian (for MySQL Cluster NDB 7.2, this is always
6.0), and arch is
one of i686 or x86_64. In
the examples that follow, we assume you wish to install MySQL
Cluster NDB 7.2.21 on a 64-bit Debian 6 system; in this case,
the installer file is named
mysql-cluster-gpl-7.2.21-debian6.0-x86_64.deb.
Once you have downloaded the appropriate
.deb file, you can install it from the
command line using dpkg, like this:
shell> dpkg -i mysql-cluster-gpl-7.2.21-debian6.0-i686.deb
You can also remove it using dpkg as shown
here:
shell> dpkg -r mysql
The installer file should also be compatible with most graphical
package managers that work with .deb files,
such as GDebi for the Gnome desktop.
The .deb file installs MySQL Cluster under
/opt/mysql/server-,
where version/version is the 2-part release
series version for the included MySQL server. For MySQL Cluster
NDB 7.2, this is always 5.5. The directory
layout is the same as that for the generic Linux binary
distribution (see Table 2.3, “MySQL Installation Layout for Generic Unix/Linux Binary Package”),
with the exception that startup scripts and configuration files
are found in support-files instead of
share. All MySQL Cluster executables, such
as ndb_mgm, ndbd, and
ndb_mgmd, are placed in the
bin directory.
This section provides information about compiling MySQL Cluster on Linux and other Unix-like platforms. Building MySQL Cluster from source is similar to building the standard MySQL Server, although it differs in a few key respects discussed here. For general information about building MySQL from source, see Section 2.9, “Installing MySQL from Source”. For information about compiling MySQL Cluster on Windows platforms, see Section 18.2.2.2, “Compiling and Installing MySQL Cluster from Source on Windows”.
Building MySQL Cluster requires using the MySQL Cluster sources.
These are available from the MySQL Cluster downloads page at
http://dev.mysql.com/downloads/cluster/. The archived source
file should have a name similar to
mysql-cluster-gpl-7.2.24.tar.gz.
You can also obtain MySQL development sources from
launchpad.net. Attempting to build MySQL Cluster
from standard MySQL Server 5.5 sources is not
supported.
The WITH_NDBCLUSTER_STORAGE_ENGINE
option for CMake causes the binaries for the
management nodes, data nodes, and other MySQL Cluster programs
to be built; it also causes mysqld to be
compiled with NDB storage engine
support. This option (or its alias
WITH_NDBCLUSTER) is required when
building MySQL Cluster.
Beginning with MySQL Cluster NDB 7.2.9, the
WITH_NDB_JAVA option is enabled
by default. This means that, by default, if
CMake cannot find the location of Java on
your system, the configuration process fails; if you do not
wish to enable Java and ClusterJ support, you must indicate
this explicitly by configuring the build using
-DWITH_NDB_JAVA=OFF. (Bug #12379735) Use
WITH_CLASSPATH to provide the
Java classpath if needed.
For more information about CMake options specific to building MySQL Cluster, see Options for Compiling MySQL Cluster.
After you have run make && make install (or your system's equivalent), the result is similar to what is obtained by unpacking a precompiled binary to the same location.
Management nodes.
When building from source and running the default
make install, the management server and
management client binaries (ndb_mgmd and
ndb_mgm) can be found in
/usr/local/mysql/bin. Only
ndb_mgmd is required to be present on a
management node host; however, it is also a good idea to have
ndb_mgm present on the same host machine.
Neither of these executables requires a specific location on
the host machine's file system.
Data nodes.
The only executable required on a data node host is the data
node binary ndbd or
ndbmtd. (mysqld, for
example, does not have to be present on the host machine.) By
default, when building from source, this file is placed in the
directory /usr/local/mysql/bin. For
installing on multiple data node hosts, only
ndbd or ndbmtd need be
copied to the other host machine or machines. (This assumes
that all data node hosts use the same architecture and
operating system; otherwise you may need to compile separately
for each different platform.) The data node binary need not be
in any particular location on the host's file system, as long
as the location is known.
When compiling MySQL Cluster from source, no special options are
required for building multi-threaded data node binaries.
Configuring the build with NDB
storage engine support causes ndbmtd to be
built automatically; make install places the
ndbmtd binary in the installation
bin directory along with
mysqld, ndbd, and
ndb_mgm.
SQL nodes.
If you compile MySQL with clustering support, and perform the
default installation (using make install as
the system root user),
mysqld is placed in
/usr/local/mysql/bin. Follow the steps
given in Section 2.9, “Installing MySQL from Source” to make
mysqld ready for use. If you want to run
multiple SQL nodes, you can use a copy of the same
mysqld executable and its associated
support files on several machines. The easiest way to do this
is to copy the entire /usr/local/mysql
directory and all directories and files contained within it to
the other SQL node host or hosts, then repeat the steps from
Section 2.9, “Installing MySQL from Source” on each machine. If you
configure the build with a nondefault PREFIX
option, you must adjust the directory accordingly.
In Section 18.2.3, “Initial Configuration of MySQL Cluster”, we create configuration files for all of the nodes in our example MySQL Cluster.
MySQL Cluster NDB 7.2 binaries for Windows can be obtained from http://dev.mysql.com/downloads/cluster/. For information about installing MySQL Cluster on Windows from a binary release provided by Oracle, see Section 18.2.2.1, “Installing MySQL Cluster on Windows from a Binary Release”.
It is also possible to compile and install MySQL Cluster from source on Windows using Microsoft Visual Studio. For more information, see Section 18.2.2.2, “Compiling and Installing MySQL Cluster from Source on Windows”.
This section describes a basic installation of MySQL Cluster on
Windows using a binary no-install MySQL
Cluster release provided by Oracle, using the same 4-node setup
outlined in the beginning of this section (see
Section 18.2, “MySQL Cluster Installation and Upgrades”), as shown in the
following table:
| Node | IP Address |
|---|---|
| Management (MGMD) node | 192.168.0.10 |
| MySQL server (SQL) node | 192.168.0.20 |
| Data (NDBD) node "A" | 192.168.0.30 |
| Data (NDBD) node "B" | 192.168.0.40 |
As on other platforms, the MySQL Cluster host computer running an SQL node must have installed on it a MySQL Server binary (mysqld.exe). You should also have the MySQL client (mysql.exe) on this host. For management nodes and data nodes, it is not necessary to install the MySQL Server binary; however, each management node requires the management server daemon (ndb_mgmd.exe); each data node requires the data node daemon (ndbd.exe or ndbmtd.exe). For this example, we refer to ndbd.exe as the data node executable, but you can install ndbmtd.exe, the multi-threaded version of this program, instead, in exactly the same way. You should also install the management client (ndb_mgm.exe) on the management server host. This section covers the steps necessary to install the correct Windows binaries for each type of MySQL Cluster node.
As with other Windows programs, MySQL Cluster executables are
named with the .exe file extension.
However, it is not necessary to include the
.exe extension when invoking these
programs from the command line. Therefore, we often simply
refer to these programs in this documentation as
mysqld, mysql,
ndb_mgmd, and so on. You should understand
that, whether we refer (for example) to
mysqld or mysqld.exe,
either name means the same thing (the MySQL Server program).
For setting up a MySQL Cluster using Oracles's
no-install binaries, the first step in the
installation process is to download the latest MySQL Cluster
Windows binary archive from
http://dev.mysql.com/downloads/cluster/. This archive has a
filename of the form
mysql-cluster-gpl-noinstall-,
where ver-winarch.zipver is the
NDB storage engine version (such as
7.2.1), and arch
is the architecture (32 for 32-bit binaries,
and 64 for 64-bit binaries). For example, the
MySQL Cluster NDB 7.2.1 no-install archive
for 32-bit Windows systems is named
mysql-cluster-gpl-noinstall-7.2.1-win32.zip.
You can run 32-bit MySQL Cluster binaries on both 32-bit and 64-bit versions of Windows; however, 64-bit MySQL Cluster binaries can be used only on 64-bit versions of Windows. If you are using a 32-bit version of Windows on a computer that has a 64-bit CPU, then you must use the 32-bit MySQL Cluster binaries.
To minimize the number of files that need to be downloaded from the Internet or copied between machines, we start with the computer where you intend to run the SQL node.
SQL node.
We assume that you have placed a copy of the
no-install archive in the directory
C:\Documents and
Settings\ on the computer having the IP
address 192.168.0.20, where
username\My
Documents\Downloadsusername is the name of the current
user. (You can obtain this name using ECHO
%USERNAME% on the command line.) To install and run
MySQL Cluster executables as Windows services, this user
should be a member of the Administrators
group.
Extract all the files from the archive. The Extraction Wizard
integrated with Windows Explorer is adequate for this task. (If
you use a different archive program, be sure that it extracts
all files and directories from the archive, and that it
preserves the archive's directory structure.) When you are
asked for a destination directory, enter
C:\, which causes the Extraction Wizard to
extract the archive to the directory
C:\mysql-cluster-gpl-noinstall-.
Rename this directory to ver-winarchC:\mysql.
It is possible to install the MySQL Cluster binaries to
directories other than C:\mysql\bin;
however, if you do so, you must modify the paths shown in this
procedure accordingly. In particular, if the MySQL Server (SQL
node) binary is installed to a location other than
C:\mysql or C:\Program
Files\MySQL\MySQL Server 5.5, or if the
SQL node's data directory is in a location other than
C:\mysql\data or C:\Program
Files\MySQL\MySQL Server 5.5\data, extra
configuration options must be used on the command line or added
to the my.ini or
my.cnf file when starting the SQL node. For
more information about configuring a MySQL Server to run in a
nonstandard location, see
Section 2.3.7, “Installing MySQL on Microsoft Windows Using a noinstall Zip Archive”.
For a MySQL Server with MySQL Cluster support to run as part of
a MySQL Cluster, it must be started with the options
--ndbcluster and
--ndb-connectstring. While you
can specify these options on the command line, it is usually
more convenient to place them in an option file. To do this,
create a new text file in Notepad or another text editor. Enter
the following configuration information into this file:
[mysqld] # Options for mysqld process: ndbcluster # run NDB storage engine ndb-connectstring=192.168.0.10 # location of management server
You can add other options used by this MySQL Server if desired
(see Section 2.3.7.2, “Creating an Option File”), but the file
must contain the options shown, at a minimum. Save this file as
C:\mysql\my.ini. This completes the
installation and setup for the SQL node.
Data nodes.
A MySQL Cluster data node on a Windows host requires only a
single executable, one of either ndbd.exe
or ndbmtd.exe. For this example, we assume
that you are using ndbd.exe, but the same
instructions apply when using ndbmtd.exe.
On each computer where you wish to run a data node (the
computers having the IP addresses 192.168.0.30 and
192.168.0.40), create the directories
C:\mysql,
C:\mysql\bin, and
C:\mysql\cluster-data; then, on the
computer where you downloaded and extracted the
no-install archive, locate
ndbd.exe in the
C:\mysql\bin directory. Copy this file to
the C:\mysql\bin directory on each of the
two data node hosts.
To function as part of a MySQL Cluster, each data node must be
given the address or hostname of the management server. You can
supply this information on the command line using the
--ndb-connectstring or
-c option when starting each data node process.
However, it is usually preferable to put this information in an
option file. To do this, create a new text file in Notepad or
another text editor and enter the following text:
[mysql_cluster] # Options for data node process: ndb-connectstring=192.168.0.10 # location of management server
Save this file as C:\mysql\my.ini on the
data node host. Create another text file containing the same
information and save it on as
C:mysql\my.ini on the other data node host,
or copy the my.ini file from the first data node host to the
second one, making sure to place the copy in the second data
node's C:\mysql directory. Both data
node hosts are now ready to be used in the MySQL Cluster, which
leaves only the management node to be installed and configured.
Management node.
The only executable program required on a computer used for
hosting a MySQL Cluster management node is the management
server program ndb_mgmd.exe. However, in
order to administer the MySQL Cluster once it has been
started, you should also install the MySQL Cluster management
client program ndb_mgm.exe on the same
machine as the management server. Locate these two programs on
the machine where you downloaded and extracted the
no-install archive; this should be the
directory C:\mysql\bin on the SQL node
host. Create the directory C:\mysql\bin
on the computer having the IP address 192.168.0.10, then copy
both programs to this directory.
You should now create two configuration files for use by
ndb_mgmd.exe:
A local configuration file to supply configuration data specific to the management node itself. Typically, this file needs only to supply the location of the MySQL Cluster global configuration file (see item 2).
To create this file, start a new text file in Notepad or another text editor, and enter the following information:
[mysql_cluster] # Options for management node process config-file=C:/mysql/bin/config.ini
Save this file as the text file
C:\mysql\bin\my.ini.A global configuration file from which the management node can obtain configuration information governing the MySQL Cluster as a whole. At a minimum, this file must contain a section for each node in the MySQL Cluster, and the IP addresses or hostnames for the management node and all data nodes (
HostNameconfiguration parameter). It is also advisable to include the following additional information:The IP address or hostname of any SQL nodes
The data memory and index memory allocated to each data node (
DataMemoryandIndexMemoryconfiguration parameters)The number of replicas, using the
NoOfReplicasconfiguration parameter (see Section 18.1.2, “MySQL Cluster Nodes, Node Groups, Replicas, and Partitions”)The directory where each data node stores it data and log file, and the directory where the management node keeps its log files (in both cases, the
DataDirconfiguration parameter)
Create a new text file using a text editor such as Notepad, and input the following information:
[ndbd default] # Options affecting ndbd processes on all data nodes: NoOfReplicas=2 # Number of replicas DataDir=C:/mysql/cluster-data # Directory for each data node's data files # Forward slashes used in directory path, # rather than backslashes. This is correct; # see Important note in text DataMemory=80M # Memory allocated to data storage IndexMemory=18M # Memory allocated to index storage # For DataMemory and IndexMemory, we have used the # default values. Since the "world" database takes up # only about 500KB, this should be more than enough for # this example Cluster setup. [ndb_mgmd] # Management process options: HostName=192.168.0.10 # Hostname or IP address of management node DataDir=C:/mysql/bin/cluster-logs # Directory for management node log files [ndbd] # Options for data node "A": # (one [ndbd] section per data node) HostName=192.168.0.30 # Hostname or IP address [ndbd] # Options for data node "B": HostName=192.168.0.40 # Hostname or IP address [mysqld] # SQL node options: HostName=192.168.0.20 # Hostname or IP addressSave this file as the text file
C:\mysql\bin\config.ini.
A single backslash character (\) cannot be
used when specifying directory paths in program options or
configuration files used by MySQL Cluster on Windows. Instead,
you must either escape each backslash character with a second
backslash (\\), or replace the backslash
with a forward slash character (/). For
example, the following line from the
[ndb_mgmd] section of a MySQL Cluster
config.ini file does not work:
DataDir=C:\mysql\bin\cluster-logs
Instead, you may use either of the following:
DataDir=C:\\mysql\\bin\\cluster-logs # Escaped backslashes
DataDir=C:/mysql/bin/cluster-logs # Forward slashes
For reasons of brevity and legibility, we recommend that you use forward slashes in directory paths used in MySQL Cluster program options and configuration files on Windows.
Oracle provides precompiled MySQL Cluster binaries for Windows which should be adequate for most users. However, if you wish, it is also possible to compile MySQL Cluster for Windows from source code. The procedure for doing this is almost identical to the procedure used to compile the standard MySQL Server binaries for Windows, and uses the same tools. However, there are two major differences:
To build MySQL Cluster, you must use the MySQL Cluster sources, which you can obtain from http://dev.mysql.com/downloads/cluster/.
Attempting to build MySQL Cluster from the source code for the standard MySQL Server is likely not to be successful, and is not supported by Oracle.
You must configure the build using the
WITH_NDBCLUSTER_STORAGE_ENGINEorWITH_NDBCLUSTERoption in addition to any other build options you wish to use with CMake. (WITH_NDBCLUSTERis supported as an alias forWITH_NDBCLUSTER_STORAGE_ENGINE, and works in exactly the same way.)
Beginning with MySQL Cluster NDB 7.2.9, the
WITH_NDB_JAVA option is enabled
by default. This means that, by default, if
CMake cannot find the location of Java on
your system, the configuration process fails; if you do not
wish to enable Java and ClusterJ support, you must indicate
this explicitly by configuring the build using
-DWITH_NDB_JAVA=OFF. (Bug #12379735) Use
WITH_CLASSPATH to provide the
Java classpath if needed.
For more information about CMake options specific to building MySQL Cluster, see Options for Compiling MySQL Cluster.
Once the build process is complete, you can create a Zip archive
containing the compiled binaries;
Section 2.9.2, “Installing MySQL Using a Standard Source Distribution” provides the
commands needed to perform this task on Windows systems. The
MySQL Cluster binaries can be found in the
bin directory of the resulting archive,
which is equivalent to the no-install
archive, and which can be installed and configured in the same
manner. For more information, see
Section 18.2.2.1, “Installing MySQL Cluster on Windows from a Binary Release”.
Once the MySQL Cluster executables and needed configuration files are in place, performing an initial start of the cluster is simply a matter of starting the MySQL Cluster executables for all nodes in the cluster. Each cluster node process must be started separately, and on the host computer where it resides. The management node should be started first, followed by the data nodes, and then finally by any SQL nodes.
On the management node host, issue the following command from the command line to start the management node process:
C:\mysql\bin>
ndb_mgmd2010-06-23 07:53:34 [MgmtSrvr] INFO -- NDB Cluster Management Server. mysql-5.5.48-ndb-7.2.24 2010-06-23 07:53:34 [MgmtSrvr] INFO -- Reading cluster configuration from 'config.ini'The management node process continues to print logging output to the console. This is normal, because the management node is not running as a Windows service. (If you have used MySQL Cluster on a Unix-like platform such as Linux, you may notice that the management node's default behavior in this regard on Windows is effectively the opposite of its behavior on Unix systems, where it runs by default as a Unix daemon process. This behavior is also true of MySQL Cluster data node processes running on Windows.) For this reason, do not close the window in which ndb_mgmd.exe is running; doing so kills the management node process. (See Section 18.2.2.4, “Installing MySQL Cluster Processes as Windows Services”, where we show how to install and run MySQL Cluster processes as Windows services.)
The required
-foption tells the management node where to find the global configuration file (config.ini). The long form of this option is--config-file.ImportantA MySQL Cluster management node caches the configuration data that it reads from
config.ini; once it has created a configuration cache, it ignores theconfig.inifile on subsequent starts unless forced to do otherwise. This means that, if the management node fails to start due to an error in this file, you must make the management node re-readconfig.iniafter you have corrected any errors in it. You can do this by starting ndb_mgmd.exe with the--reloador--initialoption on the command line. Either of these options works to refresh the configuration cache.It is not necessary or advisable to use either of these options in the management node's
my.inifile.For additional information about options which can be used with ndb_mgmd, see Section 18.4.4, “ndb_mgmd — The MySQL Cluster Management Server Daemon”, as well as Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
On each of the data node hosts, run the command shown here to start the data node processes:
C:\mysql\bin>
ndbd2010-06-23 07:53:46 [ndbd] INFO -- Configuration fetched from 'localhost:1186', generation: 1In each case, the first line of output from the data node process should resemble what is shown in the preceding example, and is followed by additional lines of logging output. As with the management node process, this is normal, because the data node is not running as a Windows service. For this reason, do not close the console window in which the data node process is running; doing so kills ndbd.exe. (For more information, see Section 18.2.2.4, “Installing MySQL Cluster Processes as Windows Services”.)
Do not start the SQL node yet; it cannot connect to the cluster until the data nodes have finished starting, which may take some time. Instead, in a new console window on the management node host, start the MySQL Cluster management client ndb_mgm.exe, which should be in
C:\mysql\binon the management node host. (Do not try to re-use the console window where ndb_mgmd.exe is running by typing CTRL+C, as this kills the management node.) The resulting output should look like this:C:\mysql\bin>
ndb_mgm-- NDB Cluster -- Management Client -- ndb_mgm>When the prompt
ndb_mgm>appears, this indicates that the management client is ready to receive MySQL Cluster management commands. You can observe the status of the data nodes as they start by enteringALL STATUSat the management client prompt. This command causes a running report of the data nodes's startup sequence, which should look something like this:ndb_mgm>
ALL STATUSConnected to Management Server at: localhost:1186 Node 2: starting (Last completed phase 3) (mysql-5.5.48-ndb-7.2.24) Node 3: starting (Last completed phase 3) (mysql-5.5.48-ndb-7.2.24) Node 2: starting (Last completed phase 4) (mysql-5.5.48-ndb-7.2.24) Node 3: starting (Last completed phase 4) (mysql-5.5.48-ndb-7.2.24) Node 2: Started (version 7.2.24) Node 3: Started (version 7.2.24) ndb_mgm>NoteCommands issued in the management client are not case-sensitive; we use uppercase as the canonical form of these commands, but you are not required to observe this convention when inputting them into the ndb_mgm client. For more information, see Section 18.5.2, “Commands in the MySQL Cluster Management Client”.
The output produced by
ALL STATUSis likely to vary from what is shown here, according to the speed at which the data nodes are able to start, the release version number of the MySQL Cluster software you are using, and other factors. What is significant is that, when you see that both data nodes have started, you are ready to start the SQL node.You can leave ndb_mgm.exe running; it has no negative impact on the performance of the MySQL Cluster, and we use it in the next step to verify that the SQL node is connected to the cluster after you have started it.
On the computer designated as the SQL node host, open a console window and navigate to the directory where you unpacked the MySQL Cluster binaries (if you are following our example, this is
C:\mysql\bin).Start the SQL node by invoking mysqld.exe from the command line, as shown here:
C:\mysql\bin>
mysqld --consoleThe
--consoleoption causes logging information to be written to the console, which can be helpful in the event of problems. (Once you are satisfied that the SQL node is running in a satisfactory manner, you can stop it and restart it out without the--consoleoption, so that logging is performed normally.)In the console window where the management client (ndb_mgm.exe) is running on the management node host, enter the
SHOWcommand, which should produce output similar to what is shown here:ndb_mgm>
SHOWConnected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 5.5.48-ndb-7.2.24, Nodegroup: 0, *) id=3 @192.168.0.40 (Version: 5.5.48-ndb-7.2.24, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 5.5.48-ndb-7.2.24) [mysqld(API)] 1 node(s) id=4 @192.168.0.20 (Version: 5.5.48-ndb-7.2.24)You can also verify that the SQL node is connected to the MySQL Cluster in the mysql client (mysql.exe) using the
SHOW ENGINE NDB STATUSstatement.
You should now be ready to work with database objects and data
using MySQL Cluster's
NDBCLUSTER storage engine. See
Section 18.2.5, “MySQL Cluster Example with Tables and Data”, for more
information and examples.
You can also install ndb_mgmd.exe, ndbd.exe, and ndbmtd.exe as Windows services. For information on how to do this, see Section 18.2.2.4, “Installing MySQL Cluster Processes as Windows Services”).
Once you are satisfied that MySQL Cluster is running as desired, you can install the management nodes and data nodes as Windows services, so that these processes are started and stopped automatically whenever Windows is started or stopped. This also makes it possible to control these processes from the command line with the appropriate NET START or NET STOP command, or using the Windows graphical Services utility.
Installing programs as Windows services usually must be done using an account that has Administrator rights on the system.
To install the management node as a service on Windows, invoke
ndb_mgmd.exe from the command line on the
machine hosting the management node, using the
--install option, as shown
here:
C:\> C:\mysql\bin\ndb_mgmd.exe --install
Installing service 'MySQL Cluster Management Server'
as '"C:\mysql\bin\ndbd.exe" "--service=ndb_mgmd"'
Service successfully installed.
When installing a MySQL Cluster program as a Windows service, you should always specify the complete path; otherwise the service installation may fail with the error The system cannot find the file specified.
The --install option must be
used first, ahead of any other options that might be specified
for ndb_mgmd.exe. However, it is preferable
to specify such options in an options file instead. If your
options file is not in one of the default locations as shown in
the output of ndb_mgmd.exe
--help, you can specify the
location using the
--config-file option.
Now you should be able to start and stop the management server like this:
C:\>NET START ndb_mgmdThe MySQL Cluster Management Server service is starting. The MySQL Cluster Management Server service was started successfully. C:\>NET STOP ndb_mgmdThe MySQL Cluster Management Server service is stopping.. The MySQL Cluster Management Server service was stopped successfully.
You can also start or stop the management server as a Windows service using the descriptive name, as shown here:
C:\>NET START 'MySQL Cluster Management Server'The MySQL Cluster Management Server service is starting. The MySQL Cluster Management Server service was started successfully. C:\>NET STOP 'MySQL Cluster Management Server'The MySQL Cluster Management Server service is stopping.. The MySQL Cluster Management Server service was stopped successfully.
However, it is usually simpler to specify a short service name
or to permit the default service name to be used when installing
the service, and then reference that name when starting or
stopping the service. To specify a service name other than
ndb_mgmd, append it to the
--install option, as shown in
this example:
C:\> C:\mysql\bin\ndb_mgmd.exe --install=mgmd1
Installing service 'MySQL Cluster Management Server'
as '"C:\mysql\bin\ndb_mgmd.exe" "--service=mgmd1"'
Service successfully installed.
Now you should be able to start or stop the service using the name you have specified, like this:
C:\>NET START mgmd1The MySQL Cluster Management Server service is starting. The MySQL Cluster Management Server service was started successfully. C:\>NET STOP mgmd1The MySQL Cluster Management Server service is stopping.. The MySQL Cluster Management Server service was stopped successfully.
To remove the management node service, invoke
ndb_mgmd.exe with the
--remove option, as shown here:
C:\> C:\mysql\bin\ndb_mgmd.exe --remove
Removing service 'MySQL Cluster Management Server'
Service successfully removed.
If you installed the service using a service name other than the
default, you can remove the service by passing this name as the
value of the --remove option,
like this:
C:\> C:\mysql\bin\ndb_mgmd.exe --remove=mgmd1
Removing service 'mgmd1'
Service successfully removed.
Installation of a MySQL Cluster data node process as a Windows
service can be done in a similar fashion, using the
--install option for
ndbd.exe (or ndbmtd.exe),
as shown here:
C:\> C:\mysql\bin\ndbd.exe --install
Installing service 'MySQL Cluster Data Node Daemon' as '"C:\mysql\bin\ndbd.exe" "--service=ndbd"'
Service successfully installed.
Now you can start or stop the data node using either the default service name or the descriptive name with net start or net stop, as shown in the following example:
C:\>NET START ndbdThe MySQL Cluster Data Node Daemon service is starting. The MySQL Cluster Data Node Daemon service was started successfully. C:\>NET STOP ndbdThe MySQL Cluster Data Node Daemon service is stopping.. The MySQL Cluster Data Node Daemon service was stopped successfully. C:\>NET START 'MySQL Cluster Data Node Daemon'The MySQL Cluster Data Node Daemon service is starting. The MySQL Cluster Data Node Daemon service was started successfully. C:\>NET STOP 'MySQL Cluster Data Node Daemon'The MySQL Cluster Data Node Daemon service is stopping.. The MySQL Cluster Data Node Daemon service was stopped successfully.
To remove the data node service, invoke
ndbd.exe with the
--remove option, as shown here:
C:\> C:\mysql\bin\ndbd.exe --remove
Removing service 'MySQL Cluster Data Node Daemon'
Service successfully removed.
As with ndb_mgmd.exe (and
mysqld.exe), when installing
ndbd.exe as a Windows service, you can also
specify a name for the service as the value of
--install, and then use it when
starting or stopping the service, like this:
C:\>C:\mysql\bin\ndbd.exe --install=dnode1Installing service 'dnode1' as '"C:\mysql\bin\ndbd.exe" "--service=dnode1"' Service successfully installed. C:\>NET START dnode1The MySQL Cluster Data Node Daemon service is starting. The MySQL Cluster Data Node Daemon service was started successfully. C:\>NET STOP dnode1The MySQL Cluster Data Node Daemon service is stopping.. The MySQL Cluster Data Node Daemon service was stopped successfully.
If you specified a service name when installing the data node
service, you can use this name when removing it as well, by
passing it as the value of the
--remove option, as shown here:
C:\> C:\mysql\bin\ndbd.exe --remove=dnode1
Removing service 'dnode1'
Service successfully removed.
Installation of the SQL node as a Windows service, starting the
service, stopping the service, and removing the service are done
in a similar fashion, using mysqld
--install, NET START,
NET STOP, and mysqld
--remove. For additional
information, see Section 2.3.7.7, “Starting MySQL as a Windows Service”.
For our four-node, four-host MySQL Cluster, it is necessary to write four configuration files, one per node host.
Each data node or SQL node requires a
my.cnffile that provides two pieces of information: a connection string that tells the node where to find the management node, and a line telling the MySQL server on this host (the machine hosting the data node) to enable theNDBCLUSTERstorage engine.For more information on connection strings, see Section 18.3.3.3, “MySQL Cluster Connection Strings”.
The management node needs a
config.inifile telling it how many replicas to maintain, how much memory to allocate for data and indexes on each data node, where to find the data nodes, where to save data to disk on each data node, and where to find any SQL nodes.
Configuring the data nodes and SQL nodes.
The my.cnf file needed for the data nodes
is fairly simple. The configuration file should be located in
the /etc directory and can be edited using
any text editor. (Create the file if it does not exist.) For
example:
shell> vi /etc/my.cnf
We show vi being used here to create the file, but any text editor should work just as well.
For each data node and SQL node in our example setup,
my.cnf should look like this:
[mysqld] # Options for mysqld process: ndbcluster # run NDB storage engine [mysql_cluster] # Options for MySQL Cluster processes: ndb-connectstring=192.168.0.10 # location of management server
After entering the preceding information, save this file and exit the text editor. Do this for the machines hosting data node “A”, data node “B”, and the SQL node.
Once you have started a mysqld process with
the ndbcluster and
ndb-connectstring parameters in the
[mysqld] and
[mysql_cluster] sections of the
my.cnf file as shown previously, you cannot
execute any CREATE TABLE or
ALTER TABLE statements without
having actually started the cluster. Otherwise, these statements
will fail with an error. This is by design.
Configuring the management node.
The first step in configuring the management node is to create
the directory in which the configuration file can be found and
then to create the file itself. For example (running as
root):
shell>mkdir /var/lib/mysql-clustershell>cd /var/lib/mysql-clustershell>vi config.ini
For our representative setup, the config.ini
file should read as follows:
[ndbd default]
# Options affecting ndbd processes on all data nodes:
NoOfReplicas=2 # Number of replicas
DataMemory=80M # How much memory to allocate for data storage
IndexMemory=18M # How much memory to allocate for index storage
# For DataMemory and IndexMemory, we have used the
# default values. Since the "world" database takes up
# only about 500KB, this should be more than enough for
# this example Cluster setup.
[tcp default]
# TCP/IP options:
portnumber=2202 # This the default; however, you can use any
# port that is free for all the hosts in the cluster
# Note: It is recommended that you do not specify the port
# number at all and simply allow the default value to be used
# instead
[ndb_mgmd]
# Management process options:
hostname=192.168.0.10 # Hostname or IP address of MGM node
datadir=/var/lib/mysql-cluster # Directory for MGM node log files
[ndbd]
# Options for data node "A":
# (one [ndbd] section per data node)
hostname=192.168.0.30 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's data files
[ndbd]
# Options for data node "B":
hostname=192.168.0.40 # Hostname or IP address
datadir=/usr/local/mysql/data # Directory for this data node's data files
[mysqld]
# SQL node options:
hostname=192.168.0.20 # Hostname or IP address
# (additional mysqld connections can be
# specified for this node for various
# purposes such as running ndb_restore)
The world database can be downloaded from
http://dev.mysql.com/doc/, where it can be found listed
under “Examples”.
After all the configuration files have been created and these minimal options have been specified, you are ready to proceed with starting the cluster and verifying that all processes are running. We discuss how this is done in Section 18.2.4, “Initial Startup of MySQL Cluster”.
For more detailed information about the available MySQL Cluster configuration parameters and their uses, see Section 18.3.3, “MySQL Cluster Configuration Files”, and Section 18.3, “Configuration of MySQL Cluster”. For configuration of MySQL Cluster as relates to making backups, see Section 18.5.3.3, “Configuration for MySQL Cluster Backups”.
The default port for Cluster management nodes is 1186; the default port for data nodes is 2202. However, the cluster can automatically allocate ports for data nodes from those that are already free.
Starting the cluster is not very difficult after it has been configured. Each cluster node process must be started separately, and on the host where it resides. The management node should be started first, followed by the data nodes, and then finally by any SQL nodes:
On the management host, issue the following command from the system shell to start the management node process:
shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.iniThe first time that it is started, ndb_mgmd must be told where to find its configuration file, using the
-for--config-fileoption. (See Section 18.4.4, “ndb_mgmd — The MySQL Cluster Management Server Daemon”, for details.)For additional options which can be used with ndb_mgmd, see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
On each of the data node hosts, run this command to start the ndbd process:
shell>
ndbdIf you used RPM files to install MySQL on the cluster host where the SQL node is to reside, you can (and should) use the supplied startup script to start the MySQL server process on the SQL node.
If all has gone well, and the cluster has been set up correctly, the cluster should now be operational. You can test this by invoking the ndb_mgm management node client. The output should look like that shown here, although you might see some slight differences in the output depending upon the exact version of MySQL that you are using:
shell>ndb_mgm-- NDB Cluster -- Management Client -- ndb_mgm>SHOWConnected to Management Server at: localhost:1186 Cluster Configuration --------------------- [ndbd(NDB)] 2 node(s) id=2 @192.168.0.30 (Version: 5.5.48-ndb-7.2.24, Nodegroup: 0, *) id=3 @192.168.0.40 (Version: 5.5.48-ndb-7.2.24, Nodegroup: 0) [ndb_mgmd(MGM)] 1 node(s) id=1 @192.168.0.10 (Version: 5.5.48-ndb-7.2.24) [mysqld(API)] 1 node(s) id=4 @192.168.0.20 (Version: 5.5.48-ndb-7.2.24)
The SQL node is referenced here as
[mysqld(API)], which reflects the fact that the
mysqld process is acting as a MySQL Cluster API
node.
The IP address shown for a given MySQL Cluster SQL or other API
node in the output of SHOW
is the address used by the SQL or API node to connect to the
cluster data nodes, and not to any management node.
You should now be ready to work with databases, tables, and data in MySQL Cluster. See Section 18.2.5, “MySQL Cluster Example with Tables and Data”, for a brief discussion.
The information in this section applies to MySQL Cluster running on both Unix and Windows platforms.
Working with database tables and data in MySQL Cluster is not much different from doing so in standard MySQL. There are two key points to keep in mind:
For a table to be replicated in the cluster, it must use the
NDBCLUSTERstorage engine. To specify this, use theENGINE=NDBCLUSTERorENGINE=NDBoption when creating the table:CREATE TABLE
tbl_name(col_namecolumn_definitions) ENGINE=NDBCLUSTER;Alternatively, for an existing table that uses a different storage engine, use
ALTER TABLEto change the table to useNDBCLUSTER:ALTER TABLE
tbl_nameENGINE=NDBCLUSTER;Every
NDBCLUSTERtable has a primary key. If no primary key is defined by the user when a table is created, theNDBCLUSTERstorage engine automatically generates a hidden one. Such a key takes up space just as does any other table index. (It is not uncommon to encounter problems due to insufficient memory for accommodating these automatically created indexes.)
If you are importing tables from an existing database using the
output of mysqldump, you can open the SQL
script in a text editor and add the ENGINE
option to any table creation statements, or replace any existing
ENGINE options. Suppose that you have the
world sample database on another MySQL server
that does not support MySQL Cluster, and you want to export the
City table:
shell> mysqldump --add-drop-table world City > city_table.sql
The resulting city_table.sql file will
contain this table creation statement (and the
INSERT statements necessary to
import the table data):
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(remaining INSERT statements omitted)
You need to make sure that MySQL uses the
NDBCLUSTER storage engine for this
table. There are two ways that this can be accomplished. One of
these is to modify the table definition
before importing it into the Cluster
database. Using the City table as an example,
modify the ENGINE option of the definition as
follows:
DROP TABLE IF EXISTS `City`;
CREATE TABLE `City` (
`ID` int(11) NOT NULL auto_increment,
`Name` char(35) NOT NULL default '',
`CountryCode` char(3) NOT NULL default '',
`District` char(20) NOT NULL default '',
`Population` int(11) NOT NULL default '0',
PRIMARY KEY (`ID`)
) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
INSERT INTO `City` VALUES (1,'Kabul','AFG','Kabol',1780000);
INSERT INTO `City` VALUES (2,'Qandahar','AFG','Qandahar',237500);
INSERT INTO `City` VALUES (3,'Herat','AFG','Herat',186800);
(remaining INSERT statements omitted)
This must be done for the definition of each table that is to be
part of the clustered database. The easiest way to accomplish this
is to do a search-and-replace on the file that contains the
definitions and replace all instances of
TYPE= or
engine_nameENGINE=
with engine_nameENGINE=NDBCLUSTER. If you do not want to
modify the file, you can use the unmodified file to create the
tables, and then use ALTER TABLE to
change their storage engine. The particulars are given later in
this section.
Assuming that you have already created a database named
world on the SQL node of the cluster, you can
then use the mysql command-line client to read
city_table.sql, and create and populate the
corresponding table in the usual manner:
shell> mysql world < city_table.sql
It is very important to keep in mind that the preceding command
must be executed on the host where the SQL node is running (in
this case, on the machine with the IP address
192.168.0.20).
To create a copy of the entire world database
on the SQL node, use mysqldump on the
noncluster server to export the database to a file named
world.sql; for example, in the
/tmp directory. Then modify the table
definitions as just described and import the file into the SQL
node of the cluster like this:
shell> mysql world < /tmp/world.sql
If you save the file to a different location, adjust the preceding instructions accordingly.
Running SELECT queries on the SQL
node is no different from running them on any other instance of a
MySQL server. To run queries from the command line, you first need
to log in to the MySQL Monitor in the usual way (specify the
root password at the Enter
password: prompt):
shell> mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 1 to server version: 5.5.48-ndb-7.2.24
Type 'help;' or '\h' for help. Type '\c' to clear the buffer.
mysql>
We simply use the MySQL server's root
account and assume that you have followed the standard security
precautions for installing a MySQL server, including setting a
strong root password. For more information, see
Section 2.10.4, “Securing the Initial MySQL Accounts”.
It is worth taking into account that Cluster nodes do
not make use of the MySQL privilege system
when accessing one another. Setting or changing MySQL user
accounts (including the root account) effects
only applications that access the SQL node, not interaction
between nodes. See
Section 18.5.11.2, “MySQL Cluster and MySQL Privileges”, for
more information.
If you did not modify the ENGINE clauses in the
table definitions prior to importing the SQL script, you should
run the following statements at this point:
mysql>USE world;mysql>ALTER TABLE City ENGINE=NDBCLUSTER;mysql>ALTER TABLE Country ENGINE=NDBCLUSTER;mysql>ALTER TABLE CountryLanguage ENGINE=NDBCLUSTER;
Selecting a database and running a SELECT query against a table in that database is also accomplished in the usual manner, as is exiting the MySQL Monitor:
mysql>USE world;mysql>SELECT Name, Population FROM City ORDER BY Population DESC LIMIT 5;+-----------+------------+ | Name | Population | +-----------+------------+ | Bombay | 10500000 | | Seoul | 9981619 | | São Paulo | 9968485 | | Shanghai | 9696300 | | Jakarta | 9604900 | +-----------+------------+ 5 rows in set (0.34 sec) mysql>\qBye shell>
Applications that use MySQL can employ standard APIs to access
NDB tables. It is important to
remember that your application must access the SQL node, and not
the management or data nodes. This brief example shows how we
might execute the SELECT statement
just shown by using the PHP 5.X mysqli
extension running on a Web server elsewhere on the network:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type"
content="text/html; charset=iso-8859-1">
<title>SIMPLE mysqli SELECT</title>
</head>
<body>
<?php
# connect to SQL node:
$link = new mysqli('192.168.0.20', 'root', 'root_password', 'world');
# parameters for mysqli constructor are:
# host, user, password, database
if( mysqli_connect_errno() )
die("Connect failed: " . mysqli_connect_error());
$query = "SELECT Name, Population
FROM City
ORDER BY Population DESC
LIMIT 5";
# if no errors...
if( $result = $link->query($query) )
{
?>
<table border="1" width="40%" cellpadding="4" cellspacing ="1">
<tbody>
<tr>
<th width="10%">City</th>
<th>Population</th>
</tr>
<?
# then display the results...
while($row = $result->fetch_object())
printf("<tr>\n <td align=\"center\">%s</td><td>%d</td>\n</tr>\n",
$row->Name, $row->Population);
?>
</tbody
</table>
<?
# ...and verify the number of rows that were retrieved
printf("<p>Affected rows: %d</p>\n", $link->affected_rows);
}
else
# otherwise, tell us what went wrong
echo mysqli_error();
# free the result set and the mysqli connection object
$result->close();
$link->close();
?>
</body>
</html>
We assume that the process running on the Web server can reach the IP address of the SQL node.
In a similar fashion, you can use the MySQL C API, Perl-DBI, Python-mysql, or MySQL Connectors to perform the tasks of data definition and manipulation just as you would normally with MySQL.
To shut down the cluster, enter the following command in a shell on the machine hosting the management node:
shell> ndb_mgm -e shutdown
The -e option here is used to pass a command to
the ndb_mgm client from the shell. (See
Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”, for more
information about this option.) The command causes the
ndb_mgm, ndb_mgmd, and any
ndbd or ndbmtd processes to
terminate gracefully. Any SQL nodes can be terminated using
mysqladmin shutdown and other means. On Windows
platforms, assuming that you have installed the SQL node as a
Windows service, you can use NET STOP MYSQL.
To restart the cluster on Unix platforms, run these commands:
On the management host (
192.168.0.10in our example setup):shell>
ndb_mgmd -f /var/lib/mysql-cluster/config.iniOn each of the data node hosts (
192.168.0.30and192.168.0.40):shell>
ndbdUse the ndb_mgm client to verify that both data nodes have started successfully.
On the SQL host (
192.168.0.20):shell>
mysqld_safe &
On Windows platforms, assuming that you have installed all MySQL Cluster processes as Windows services using the default service names (see Section 18.2.2.4, “Installing MySQL Cluster Processes as Windows Services”), you can restart the cluster as follows:
On the management host (
192.168.0.10in our example setup), execute the following command:C:\>
NET START ndb_mgmdOn each of the data node hosts (
192.168.0.30and192.168.0.40), execute the following command:C:\>
NET START ndbdOn the management node host, use the ndb_mgm client to verify that the management node and both data nodes have started successfully (see Section 18.2.2.3, “Initial Startup of MySQL Cluster on Windows”).
On the SQL node host (
192.168.0.20), execute the following command:C:\>
NET START mysql
In a production setting, it is usually not desirable to shut down the cluster completely. In many cases, even when making configuration changes, or performing upgrades to the cluster hardware or software (or both), which require shutting down individual host machines, it is possible to do so without shutting down the cluster as a whole by performing a rolling restart of the cluster. For more information about doing this, see Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”.
This section provides information about MySQL Cluster software and table file compatibility between different MySQL Cluster NDB 7.2 releases with regard to performing upgrades and downgrades as well as compatibility matrices and notes. You are expected already to be familiar with installing and configuring a MySQL Cluster prior to attempting an upgrade or downgrade. See Section 18.3, “Configuration of MySQL Cluster”.
For information regarding the rolling restart procedure used to perform an online upgrade, see Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”.
Only compatibility between MySQL versions with regard to
NDBCLUSTER is taken into account in
this section, and there are likely other issues to be
considered. As with any other MySQL software upgrade
or downgrade, you are strongly encouraged to review the relevant
portions of the MySQL Manual for the MySQL versions from which
and to which you intend to migrate, before attempting an upgrade
or downgrade of the MySQL Cluster software. This is
especially true when planning a migration from MySQL Cluster NDB
7.1 (or earlier) to MySQL Cluster NDB 7.2, since the version of
the underlying MySQL Server also changes from MySQL 5.1 to MySQL
5.5. See Section 2.11.1, “Upgrading MySQL”.
The table shown here provides information on MySQL Cluster upgrade and downgrade compatibility among different releases of MySQL Cluster NDB 7.2. Additional notes about upgrades and downgrades to, from, or within the MySQL Cluster NDB 7.2 release series can be found immediately following the table.
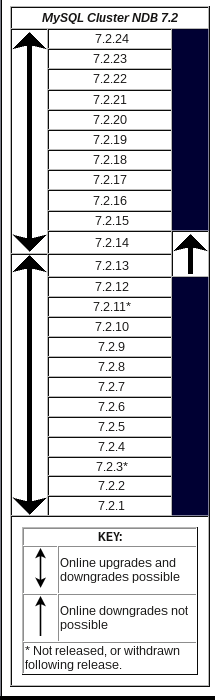
Notes: MySQL Cluster NDB 7.2
Versions supported. The following versions of MySQL Cluster are supported for upgrades to MySQL Cluster NDB 7.2 (7.2.4 and later):
MySQL Cluster NDB 7.1 GA releases (7.1.3 and later)
MySQL Cluster NDB 7.0 GA releases (7.0.5 and later)
MySQL Cluster NDB 6.3 GA releases (6.3.8 and later) that can be upgraded to MySQL Cluster NDB 7.1
For information about upgrades to and downgrades from MySQl Cluster NDB 7.3, see Upgrading and Downgrading MySQL Cluster. For information about upgrades and downgrades in previous MySQL Cluster release series, see Upgrade and Downgrade Compatibility: MySQL Cluster NDB 6.x, and Upgrade and downgrade compatibility: MySQL Cluster NDB 7.x.
NDB API, ClusterJ, and other applications used with recent releases of MySQL Cluster NDB 6.3 and later should continue to work with MySQL Cluster NDB 7.2.4 and later without rewriting or recompiling.
In MySQL Cluster NDB 7.2, the default values for a number of node configuration parameters have changed. See Improved default values for data node configuration parameters, for a listing of these.
Other known issues include the following:
In MySQL Cluster NDB 7.2.7 and later, the size of the hash map is 3840 LDM threads, an increase from 240 in previous versions. When upgrading a MySQL Cluster from MySQL Cluster NDB 7.2.6 and earlier to MySQL Cluster NDB 7.2.9 or later, you can modify existing tables online to take advantage of the new size: following the upgrade, increase the number of fragments by (for example) adding new data nodes to the cluster, and then execute
ALTER ONLINE TABLE ... REORGANIZE PARTITIONon any tables that were created in the older version. Following this, these tables can use the larger hash map size. (Bug #14645319)Due to this change, it was not possible to downgrade online to MySQL Cluster NDB 7.2.6 or earlier. This issue was resolved in MySQL Cluster NDB 7.2.11, where the size is made configurable using the
DefaultHashMapSizeparameter. (Bug #14800539) See the description of this parameter for more information.It is not possible to downgrade online to MySQL Cluster NDB 7.2.13 or earlier from MySQL Cluster NDB 7.2.14 or later. Online upgrades from MySQL Cluster NDB 7.2.13 to later MySQL Cluster NDB 7.2 releases are supported.
A MySQL server that is part of a MySQL Cluster differs in one chief
respect from a normal (nonclustered) MySQL server, in that it
employs the NDB storage engine. This
engine is also referred to sometimes as
NDBCLUSTER, although
NDB is preferred.
To avoid unnecessary allocation of resources, the server is
configured by default with the NDB
storage engine disabled. To enable NDB,
you must modify the server's my.cnf
configuration file, or start the server with the
--ndbcluster option.
This MySQL server is a part of the cluster, so it also must know how
to access a management node to obtain the cluster configuration
data. The default behavior is to look for the management node on
localhost. However, should you need to specify
that its location is elsewhere, this can be done in
my.cnf, or with the mysql
client. Before the NDB storage engine
can be used, at least one management node must be operational, as
well as any desired data nodes.
For more information about
--ndbcluster and other
mysqld options specific to MySQL Cluster, see
Section 18.3.3.8.1, “MySQL Server Options for MySQL Cluster”.
For information about installing MySQL Cluster, see Section 18.2, “MySQL Cluster Installation and Upgrades”.
To familiarize you with the basics, we will describe the simplest possible configuration for a functional MySQL Cluster. After this, you should be able to design your desired setup from the information provided in the other relevant sections of this chapter.
First, you need to create a configuration directory such as
/var/lib/mysql-cluster, by executing the
following command as the system root user:
shell> mkdir /var/lib/mysql-cluster
In this directory, create a file named
config.ini that contains the following
information. Substitute appropriate values for
HostName and DataDir as
necessary for your system.
# file "config.ini" - showing minimal setup consisting of 1 data node, # 1 management server, and 3 MySQL servers. # The empty default sections are not required, and are shown only for # the sake of completeness. # Data nodes must provide a hostname but MySQL Servers are not required # to do so. # If you don't know the hostname for your machine, use localhost. # The DataDir parameter also has a default value, but it is recommended to # set it explicitly. # Note: [db], [api], and [mgm] are aliases for [ndbd], [mysqld], and [ndb_mgmd], # respectively. [db] is deprecated and should not be used in new installations. [ndbd default] NoOfReplicas= 1 [mysqld default] [ndb_mgmd default] [tcp default] [ndb_mgmd] HostName= myhost.example.com [ndbd] HostName= myhost.example.com DataDir= /var/lib/mysql-cluster [mysqld] [mysqld] [mysqld]
You can now start the ndb_mgmd management
server. By default, it attempts to read the
config.ini file in its current working
directory, so change location into the directory where the file is
located and then invoke ndb_mgmd:
shell>cd /var/lib/mysql-clustershell>ndb_mgmd
Then start a single data node by running ndbd:
shell> ndbd
For command-line options which can be used when starting ndbd, see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
By default, ndbd looks for the management
server at localhost on port 1186.
If you have installed MySQL from a binary tarball, you will need
to specify the path of the ndb_mgmd and
ndbd servers explicitly. (Normally, these
will be found in /usr/local/mysql/bin.)
Finally, change location to the MySQL data directory (usually
/var/lib/mysql or
/usr/local/mysql/data), and make sure that
the my.cnf file contains the option necessary
to enable the NDB storage engine:
[mysqld] ndbcluster
You can now start the MySQL server as usual:
shell> mysqld_safe --user=mysql &
Wait a moment to make sure the MySQL server is running properly.
If you see the notice mysql ended, check the
server's .err file to find out what went
wrong.
If all has gone well so far, you now can start using the cluster.
Connect to the server and verify that the
NDBCLUSTER storage engine is enabled:
shell>mysqlWelcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 to server version: 5.5.50 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>SHOW ENGINES\G... *************************** 12. row *************************** Engine: NDBCLUSTER Support: YES Comment: Clustered, fault-tolerant, memory-based tables *************************** 13. row *************************** Engine: NDB Support: YES Comment: Alias for NDBCLUSTER ...
The row numbers shown in the preceding example output may be different from those shown on your system, depending upon how your server is configured.
Try to create an NDBCLUSTER table:
shell>mysqlmysql>USE test;Database changed mysql>CREATE TABLE ctest (i INT) ENGINE=NDBCLUSTER;Query OK, 0 rows affected (0.09 sec) mysql>SHOW CREATE TABLE ctest \G*************************** 1. row *************************** Table: ctest Create Table: CREATE TABLE `ctest` ( `i` int(11) default NULL ) ENGINE=ndbcluster DEFAULT CHARSET=latin1 1 row in set (0.00 sec)
To check that your nodes were set up properly, start the management client:
shell> ndb_mgm
Use the SHOW command from within the management client to obtain a report on the cluster's status:
ndb_mgm> SHOW
Cluster Configuration
---------------------
[ndbd(NDB)] 1 node(s)
id=2 @127.0.0.1 (Version: 5.5.48-ndb-7.2.24, Nodegroup: 0, *)
[ndb_mgmd(MGM)] 1 node(s)
id=1 @127.0.0.1 (Version: 5.5.48-ndb-7.2.24)
[mysqld(API)] 3 node(s)
id=3 @127.0.0.1 (Version: 5.5.48-ndb-7.2.24)
id=4 (not connected, accepting connect from any host)
id=5 (not connected, accepting connect from any host)
At this point, you have successfully set up a working MySQL
Cluster. You can now store data in the cluster by using any table
created with ENGINE=NDBCLUSTER or its alias
ENGINE=NDB.
- 18.3.2.1 MySQL Cluster Data Node Configuration Parameters
- 18.3.2.2 MySQL Cluster Management Node Configuration Parameters
- 18.3.2.3 MySQL Cluster SQL Node and API Node Configuration Parameters
- 18.3.2.4 Other MySQL Cluster Configuration Parameters
- 18.3.2.5 MySQL Cluster mysqld Option and Variable Reference
The next several sections provide summary tables of MySQL Cluster
node configuration parameters used in the
config.ini file to govern various aspects of
node behavior, as well as of options and variables read by
mysqld from a my.cnf file
or from the command line when run as a MySQL Cluster process. Each
of the node parameter tables lists the parameters for a given type
(ndbd, ndb_mgmd,
mysqld, computer,
tcp, shm, or
sci). All tables include the data type for the
parameter, option, or variable, as well as its default, mimimum,
and maximum values as applicable.
Considerations when restarting nodes.
For node parameters, these tables also indicate what type of
restart is required (node restart or system restart)—and
whether the restart must be done with
--initial—to change the value of a given
configuration parameter. When performing a node restart or an
initial node restart, all of the cluster's data nodes must
be restarted in turn (also referred to as a
rolling restart). It is
possible to update cluster configuration parameters marked as
node online—that is, without shutting
down the cluster—in this fashion. An initial node restart
requires restarting each ndbd process with
the --initial option.
A system restart requires a complete shutdown and restart of the entire cluster. An initial system restart requires taking a backup of the cluster, wiping the cluster file system after shutdown, and then restoring from the backup following the restart.
In any cluster restart, all of the cluster's management servers must be restarted for them to read the updated configuration parameter values.
Values for numeric cluster parameters can generally be increased without any problems, although it is advisable to do so progressively, making such adjustments in relatively small increments. Many of these can be increased online, using a rolling restart.
However, decreasing the values of such parameters—whether
this is done using a node restart, node initial restart, or even
a complete system restart of the cluster—is not to be
undertaken lightly; it is recommended that you do so only after
careful planning and testing. This is especially true with
regard to those parameters that relate to memory usage and disk
space, such as
MaxNoOfTables,
MaxNoOfOrderedIndexes,
and
MaxNoOfUniqueHashIndexes.
In addition, it is the generally the case that configuration
parameters relating to memory and disk usage can be raised using
a simple node restart, but they require an initial node restart
to be lowered.
Because some of these parameters can be used for configuring more than one type of cluster node, they may appear in more than one of the tables.
4294967039 often appears as a maximum value
in these tables. This value is defined in the
NDBCLUSTER sources as
MAX_INT_RNIL and is equal to
0xFFFFFEFF, or
232 −
28 − 1.
The summary table in this section provides information about
parameters used in the [ndbd] or
[ndbd default] sections of a
config.ini file for configuring MySQL
Cluster data nodes. For detailed descriptions and other
additional information about each of these parameters, see
Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”.
These parameters also apply to ndbmtd, the multi-threaded version of ndbd. For more information, see Section 18.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”.
Restart types. Changes in MySQL Cluster configuration parameters do not take effect until the cluster is restarted. The type of restart required to change a given parameter is indicated in the summary table as follows:
N—Node restart: The parameter can be updated using a rolling restart (see Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”).S—System restart: The cluster must be shut down completely, then restarted, to effect a change in this parameter.I—Initial restart: Data nodes must be restarted using the--initialoption.
For more information about restart types, see Section 18.3.2, “Overview of MySQL Cluster Configuration Parameters, Options, and Variables”.
MySQL Cluster NDB 7.2 supports the addition of new data node groups online, to a running cluster. For more information, see Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”.
Table 18.1 Data Node Configuration Parameters
| Parameter Name | Type or Units | Restart Type | In Version ... (and later) |
|---|---|---|---|
| Default Value | |||
| Minimum/Maximum or Permitted Values | |||
| enumeration | N | NDB 7.2.0 | |
| Default | |||
| Default, Disabled, WaitExternal | |||
| milliseconds | N | NDB 7.2.0 | |
| 7500 | |||
| 10 / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 16M | |||
| 512K / 4294967039 (0xFFFFFEFF) | |||
| path | IN | NDB 7.2.0 | |
| FileSystemPath | |||
| ... | |||
| bytes | N | NDB 7.2.0 | |
| 16M | |||
| 2M / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.1 | |
| 1M | |||
| 2K / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 32M | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| seconds | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 256K | |||
| 32K / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.1 | |
| 256 | |||
| 1 / 992 | |||
| numeric | S | NDB 7.2.0 | |
| 0 | |||
| 0 / 128 | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| milliseconds | N | NDB 7.2.1 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| boolean | S | NDB 7.2.1 | |
| true | |||
| true, false | |||
| path | IN | NDB 7.2.0 | |
| . | |||
| ... | |||
| bytes | N | NDB 7.2.0 | |
| 80M | |||
| 1M / 1024G | |||
| LDM threads | N | NDB 7.2.11 | |
| 3840 | |||
| 0 / 3840 | |||
| bytes | N | NDB 7.2.0 | |
| undefined | |||
| 0 / 100 | |||
| bytes | N | NDB 7.2.0 | |
| 10M | |||
| 1M / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 100M | |||
| 1M / 4294967039 (0xFFFFFEFF) | |||
| threads | N | NDB 7.2.0 | |
| 2 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| true|false (1|0) | IS | NDB 7.2.0 | |
| false | |||
| true, false | |||
| 32K pages | N | NDB 7.2.19 | |
| 10 | |||
| 1 / 1000 | |||
| bytes | N | NDB 7.2.0 | |
| 64M | |||
| 4M / 1T | |||
| bytes | N | NDB 7.2.0 | |
| 4M | |||
| 32K / 4294967039 (0xFFFFFEFF) | |||
| name | S | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| bytes | N | NDB 7.2.5 | |
| 0 | |||
| 0 / 32G | |||
| path | IN | NDB 7.2.0 | |
| DataDir | |||
| ... | |||
| filename | IN | NDB 7.2.0 | |
| [see text] | |||
| ... | |||
| filename | IN | NDB 7.2.0 | |
| FileSystemPath | |||
| ... | |||
| filename | IN | NDB 7.2.0 | |
| [see text] | |||
| ... | |||
| bytes | IN | NDB 7.2.0 | |
| 16M | |||
| 4M / 1G | |||
| milliseconds | N | NDB 7.2.0 | |
| 1500 | |||
| 100 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 5000 | |||
| 10 / 4294967039 (0xFFFFFEFF) | |||
| numeric | S | NDB 7.2.0 | |
| 0 | |||
| 0 / 65535 | |||
| name or IP address | N | NDB 7.2.0 | |
| localhost | |||
| ... | |||
| unsigned | IS | NDB 7.2.0 | |
| [none] | |||
| 1 / 48 | |||
| bytes | N | NDB 7.2.0 | |
| 18M | |||
| 1M / 1T | |||
| boolean | S | NDB 7.2.1 | |
| false | |||
| false, true | |||
| boolean | S | NDB 7.2.1 | |
| false | |||
| false, true | |||
| percentage | IN | NDB 7.2.1 | |
| 100 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| bytes | IN | NDB 7.2.1 | |
| 32768 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| percentage | IN | NDB 7.2.1 | |
| 100 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| percentage | IN | NDB 7.2.1 | |
| 100 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| seconds | IN | NDB 7.2.1 | |
| 60 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| [see values] | IN | NDB 7.2.0 | |
| SPARSE | |||
| SPARSE, FULL | |||
| string | S | NDB 7.2.0 | |
| [see text] | |||
| ... | |||
| files | N | NDB 7.2.0 | |
| 27 | |||
| 20 / 4294967039 (0xFFFFFEFF) | |||
| string | S | NDB 7.2.0 | |
| [see text] | |||
| ... | |||
| numeric | N | NDB 7.2.0 | |
| 1 | |||
| 0 / 1 | |||
| second | N | NDB 7.2.14 | |
| 60 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| CPU ID | N | NDB 7.2.0 | |
| 64K | |||
| 0 / 64K | |||
| CPU ID | N | NDB 7.2.0 | |
| [none] | |||
| 0 / 64K | |||
| numeric | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 2 | |||
| log level | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| levelr | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| integer | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| integer | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| integer | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| integer | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| integer | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| integer | N | NDB 7.2.0 | |
| 1 | |||
| 0 / 15 | |||
| integer | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 15 | |||
| bytes | N | NDB 7.2.16 | |
| 64M | |||
| 512K / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 32M | |||
| 1M / 1G | |||
| epochs | N | NDB 7.2.0 | |
| 100 | |||
| 0 / 100000 | |||
| bytes | N | NDB 7.2.13 | |
| 26214400 | |||
| 26214400 (0x01900000) / 4294967039 (0xFFFFFEFF) | |||
| operations (DML) | N | NDB 7.2.0 | |
| 4294967295 | |||
| 32 / 4294967295 | |||
| seconds | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 600 | |||
| integer | N | NDB 7.2.0 | |
| 1000 | |||
| 32 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 8K | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 32K | |||
| 32 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 256 | |||
| 2 / 500 | |||
| unsigned | N | NDB 7.2.0 | |
| 256 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 4096 | |||
| 32 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 4000 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| UNDEFINED | |||
| 32 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| [see text] | |||
| 32 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 20 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 128 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 25 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 128 | |||
| 8 / 20320 | |||
| integer | N | NDB 7.2.0 | |
| 768 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| integer | N | NDB 7.2.0 | |
| 64 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 256 | |||
| 1 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 3 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.3 | |
| 5 | |||
| 0 / 100 | |||
| IS | NDB 7.2.0 | ||
| [none] | |||
| 0 / 65536 | |||
| unsigned | IS | NDB 7.2.0 | |
| [none] | |||
| 1 / 48 | |||
| integer | IN | NDB 7.2.0 | |
| 16 | |||
| 3 / 4294967039 (0xFFFFFEFF) | |||
| integer | IS | NDB 7.2.0 | |
| 2 | |||
| 1 / 4 | |||
| boolean | N | NDB 7.2.0 | |
| 1 | |||
| ... | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| bytes | N | NDB 7.2.0 | |
| 32M | |||
| 1M / 4294967039 (0xFFFFFEFF) | |||
| numeric | N | NDB 7.2.0 | |
| 3 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| seconds | N | NDB 7.2.0 | |
| 20 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 256K | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| error code | N | NDB 7.2.0 | |
| 2 | |||
| 0 / 4 | |||
| µs | N | NDB 7.2.0 | |
| 50 | |||
| 0 / 11000 | |||
| µs | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 500 | |||
| unsigned | S | NDB 7.2.0 | |
| [none] | |||
| 1 / 64K | |||
| bytes | N | NDB 7.2.0 | |
| 128M | |||
| 0 / 64T | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 15000 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 30000 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 60000 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| seconds | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| boolean | N | NDB 7.2.0 | |
| 1 | |||
| 0, 1 | |||
| % or bytes | S | NDB 7.2.1 | |
| 25 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| milliseconds | N | NDB 7.2.0 | |
| 100 | |||
| 0 / 32000 | |||
| milliseconds | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 256000 | |||
| milliseconds | N | NDB 7.2.0 | |
| 2000 | |||
| 20 / 32000 | |||
| milliseconds | N | NDB 7.2.20 | |
| 120000 | |||
| 10 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 1000 | |||
| 1000 / 4294967039 (0xFFFFFEFF) | |||
| number of 4-byte words, as a base-2 logarithm | N | NDB 7.2.0 | |
| 20 | |||
| 0 / 31 | |||
| milliseconds | N | NDB 7.2.0 | |
| 6000 | |||
| 70 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 6000 | |||
| 70 / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 0 | |||
| 256K / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 1M | |||
| 1K / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| 1200 | |||
| 50 / 4294967039 (0xFFFFFEFF) | |||
| milliseconds | N | NDB 7.2.0 | |
| [see text] | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| unsigned | N | NDB 7.2.0 | |
| 16M | |||
| 1M / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 2M | |||
| 1M / 4294967039 (0xFFFFFEFF) |
Table 18.2 Multi-Threaded Data Node Configuration Parameters
| Parameter Name | Type or Units | Restart Type | In Version ... (and later) |
|---|---|---|---|
| Default Value | |||
| Minimum/Maximum or Permitted Values | |||
| integer | IS | NDB 7.2.5 | |
| 2 | |||
| 2 / 36 | |||
| numeric | IN | NDB 7.2.5 | |
| 4 | |||
| 4, 8, 12, 16 | |||
| string | IS | NDB 7.2.3 | |
| '' | |||
| ... |
The summary table in this section provides information about
parameters used in the [ndb_mgmd] or
[mgm] sections of a
config.ini file for configuring MySQL
Cluster management nodes. For detailed descriptions and other
additional information about each of these parameters, see
Section 18.3.3.5, “Defining a MySQL Cluster Management Server”.
Restart types. Changes in MySQL Cluster configuration parameters do not take effect until the cluster is restarted. The type of restart required to change a given parameter is indicated in the summary table as follows:
N—Node restart: The parameter can be updated using a rolling restart (see Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”).S—System restart: The cluster must be shut down completely, then restarted, to effect a change in this parameter.I—Initial restart: Data nodes must be restarted using the--initialoption.
For more information about restart types, see Section 18.3.2, “Overview of MySQL Cluster Configuration Parameters, Options, and Variables”.
Table 18.3 Management Node Configuration Parameters
| Parameter Name | Type or Units | Restart Type | In Version ... (and later) |
|---|---|---|---|
| Default Value | |||
| Minimum/Maximum or Permitted Values | |||
| milliseconds | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| 0-2 | N | NDB 7.2.0 | |
| 1 | |||
| 0 / 2 | |||
| path | N | NDB 7.2.0 | |
| . | |||
| ... | |||
| name | S | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| bytes | N | NDB 7.2.14 | |
| 0 | |||
| 0 / 32G | |||
| milliseconds | N | NDB 7.2.12 | |
| 1500 | |||
| 100 / 4294967039 (0xFFFFFEFF) | |||
| string | S | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| name or IP address | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| unsigned | IS | NDB 7.2.0 | |
| [none] | |||
| 1 / 255 | |||
| {CONSOLE|SYSLOG|FILE} | N | NDB 7.2.0 | |
| [see text] | |||
| ... | |||
| unsigned | N | NDB 7.2.0 |
| 100 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | IS | NDB 7.2.0 | |
| [none] | |||
| 1 / 255 | |||
| unsigned | S | NDB 7.2.0 | |
| 1186 | |||
| 0 / 64K | |||
| unsigned | N | NDB 7.2.0 | |
| [none] | |||
| 0 / 64K | |||
| bytes | N | NDB 7.2.0 | |
| 0 | |||
| 256K / 4294967039 (0xFFFFFEFF) | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false |
After making changes in a management node's configuration, it is necessary to perform a rolling restart of the cluster for the new configuration to take effect. See Section 18.3.3.5, “Defining a MySQL Cluster Management Server”, for more information.
To add new management servers to a running MySQL Cluster, it
is also necessary perform a rolling restart of all cluster
nodes after modifying any existing
config.ini files. For more information
about issues arising when using multiple management nodes, see
Section 18.1.6.10, “Limitations Relating to Multiple MySQL Cluster Nodes”.
The summary table in this section provides information about
parameters used in the [mysqld] and
[api] sections of a
config.ini file for configuring MySQL
Cluster SQL nodes and API nodes. For detailed descriptions and
other additional information about each of these parameters, see
Section 18.3.3.7, “Defining SQL and Other API Nodes in a MySQL Cluster”.
For a discussion of MySQL server options for MySQL Cluster, see Section 18.3.3.8.1, “MySQL Server Options for MySQL Cluster”; for information about MySQL server system variables relating to MySQL Cluster, see Section 18.3.3.8.2, “MySQL Cluster System Variables”.
Restart types. Changes in MySQL Cluster configuration parameters do not take effect until the cluster is restarted. The type of restart required to change a given parameter is indicated in the summary table as follows:
N—Node restart: The parameter can be updated using a rolling restart (see Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”).S—System restart: The cluster must be shut down completely, then restarted, to effect a change in this parameter.I—Initial restart: Data nodes must be restarted using the--initialoption.
For more information about restart types, see Section 18.3.2, “Overview of MySQL Cluster Configuration Parameters, Options, and Variables”.
Table 18.4 SQL Node / API Node Configuration Parameters
| Parameter Name | Type or Units | Restart Type | In Version ... (and later) |
|---|---|---|---|
| Default Value | |||
| Minimum/Maximum or Permitted Values | |||
| milliseconds | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| 0-2 | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 2 | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| bytes | N | NDB 7.2.1 | |
| 16K | |||
| 1024 / 1M | |||
| records | N | NDB 7.2.1 | |
| 256 | |||
| 1 / 992 | |||
| integer | N | NDB 7.2.18 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| string | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| buckets | N | NDB 7.2.11 | |
| 3840 | |||
| 0 / 3840 | |||
| enumeration | S | NDB 7.2.10 | |
| QUEUE | |||
| ABORT, QUEUE | |||
| bytes | S | NDB 7.2.0 | |
| 8192 | |||
| 0 / 64K | |||
| name | S | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| bytes | N | NDB 7.2.14 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| string | S | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| name or IP address | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| unsigned | IS | NDB 7.2.0 | |
| [none] | |||
| 1 / 255 | |||
| bytes | N | NDB 7.2.0 | |
| 256K | |||
| 32K / 16M | |||
| unsigned | IS | NDB 7.2.0 | |
| [none] | |||
| 1 / 255 | |||
| integer | N | NDB 7.2.18 | |
| 1500 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 0 | |||
| 256K / 4294967039 (0xFFFFFEFF) | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false |
To add new SQL or API nodes to the configuration of a running
MySQL Cluster, it is necessary to perform a rolling restart of
all cluster nodes after adding new [mysqld]
or [api] sections to the
config.ini file (or files, if you are
using more than one management server). This must be done
before the new SQL or API nodes can connect to the cluster.
It is not necessary to perform any restart of the cluster if new SQL or API nodes can employ previously unused API slots in the cluster configuration to connect to the cluster.
The summary tables in this section provide information about
parameters used in the [computer],
[tcp], [shm], and
[sci] sections of a
config.ini file for configuring MySQL
Cluster management nodes. For detailed descriptions and other
additional information about individual parameters, see
Section 18.3.3.9, “MySQL Cluster TCP/IP Connections”,
Section 18.3.3.11, “MySQL Cluster Shared-Memory Connections”, or
Section 18.3.3.12, “SCI Transport Connections in MySQL Cluster”, as appropriate.
Restart types. Changes in MySQL Cluster configuration parameters do not take effect until the cluster is restarted. The type of restart required to change a given parameter is indicated in the summary tables as follows:
N—Node restart: The parameter can be updated using a rolling restart (see Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”).S—System restart: The cluster must be shut down completely, then restarted, to effect a change in this parameter.I—Initial restart: Data nodes must be restarted using the--initialoption.
For more information about restart types, see Section 18.3.2, “Overview of MySQL Cluster Configuration Parameters, Options, and Variables”.
Table 18.6 TCP Configuration Parameters
| Parameter Name | Type or Units | Restart Type | In Version ... (and later) |
|---|---|---|---|
| Default Value | |||
| Minimum/Maximum or Permitted Values | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| unsigned | N | NDB 7.2.0 |
| 55 | |||
| 0 / 200 | |||
| numeric | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| numeric | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| numeric | N | NDB 7.2.0 |
| [none] | |||
| ... | |||
| bytes | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | S | NDB 7.2.0 | |
| [none] | |||
| 0 / 64K | |||
| string | N | NDB 7.2.0 |
| [none] | |||
| ... | |||
| bytes | N | NDB 7.2.0 | |
| 2M | |||
| 16K / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 2M | |||
| 256K / 4294967039 (0xFFFFFEFF) | |||
| boolean | N | NDB 7.2.0 | |
| [see text] | |||
| true, false | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 2G | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 2G | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 2G | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false |
Table 18.7 Shared Memory Configuration Parameters
| Parameter Name | Type or Units | Restart Type | In Version ... (and later) |
|---|---|---|---|
| Default Value | |||
| Minimum/Maximum or Permitted Values | |||
| boolean | N | NDB 7.2.0 | |
| true | |||
| true, false | |||
| unsigned | N | NDB 7.2.0 |
| 35 | |||
| 0 / 200 | |||
| numeric | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| numeric | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| numeric | N | NDB 7.2.0 |
| [none] | |||
| ... | |||
| bytes | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | S | NDB 7.2.0 |
| [none] | |||
| 0 / 64K | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| unsigned | N | NDB 7.2.0 | |
| [none] | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| bytes | N | NDB 7.2.0 | |
| 1M | |||
| 64K / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| [none] | |||
| 0 / 4294967039 (0xFFFFFEFF) |
Table 18.8 SCI Configuration Parameters
| Parameter Name | Type or Units | Restart Type | In Version ... (and later) |
|---|---|---|---|
| Default Value | |||
| Minimum/Maximum or Permitted Values | |||
| boolean | N | NDB 7.2.0 | |
| false | |||
| true, false | |||
| unsigned | N | NDB 7.2.0 |
| 15 | |||
| 0 / 200 | |||
| unsigned | N | NDB 7.2.0 | |
| [none] | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| [none] | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| numeric | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| numeric | N | NDB 7.2.0 | |
| [none] | |||
| ... | |||
| numeric | N | NDB 7.2.0 |
| [none] | |||
| ... | |||
| bytes | N | NDB 7.2.0 | |
| 0 | |||
| 0 / 4294967039 (0xFFFFFEFF) | |||
| unsigned | S | NDB 7.2.0 |
| [none] | |||
| 0 / 64K | |||
| unsigned | N | NDB 7.2.0 | |
| 8K | |||
| 128 / 32K | |||
| boolean | N | NDB 7.2.0 | |
| true | |||
| true, false | |||
| unsigned | N | NDB 7.2.0 | |
| 10M | |||
| 64K / 4294967039 (0xFFFFFEFF) |
The following table provides a list of the command-line options,
server and status variables applicable within
mysqld when it is running as an SQL node in a
MySQL Cluster. For a table showing all
command-line options, server and status variables available for
use with mysqld, see
Section 5.1.1, “Server Option and Variable Reference”.
Table 18.9 MySQL Server Options and Variables for MySQL Cluster: MySQL Cluster NDB 7.2
| Option or Variable Name | ||
|---|---|---|
| Command Line | System Variable | Status Variable |
| Option File | Scope | Dynamic |
| Notes | ||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of SHOW NDB STATUS statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Number of times that tables have been discovered |
||
| No | Yes | No |
| No | Global | No |
DESCRIPTION: Whether mysqld supports NDB Cluster tables (set by --ndbcluster option) |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Size (in bytes) to use for NDB transaction batches |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Specifies size in bytes that large BLOB reads should be batched into. 0 = no limit. |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Specifies size in bytes that large BLOB writes should be batched into. 0 = no limit. |
||
| Yes | Yes | Yes |
| Yes | Global | No |
DESCRIPTION: Number of connections to the cluster used by MySQL |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Point to the management server that distributes the cluster configuration |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Specifies that constraint checks on unique indexes (where these are supported) should be deferred until commit time. Not normally needed or used; for testing purposes only. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Default distribution for new tables in NDBCLUSTER (KEYHASH or LINHASH, default is KEYHASH) |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Cause a MySQL server acting as a slave to log mysql.ndb_apply_status updates received from its immediate master in its own binary log, using its own server ID. Effective only if the server is started with the --ndbcluster option. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: When enabled, causes epochs in which there were no changes to be written to the ndb_apply_status and ndb_binlog_index tables, even when --log-slave-updates is enabled. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Log originating server id and epoch in mysql.ndb_binlog_index table. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Write NDB transaction IDs in the binary log. Requires --log-bin-v1-events=OFF. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Toggles logging of updates on the master between updates (OFF) and writes (ON) |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Set the host (and port, if desired) for connecting to management server |
||
| Yes | No | Yes |
| Yes | Global | No |
DESCRIPTION: MySQL Cluster node ID for this MySQL server |
||
| Yes | No | No |
| No | No | |
DESCRIPTION: Enable or disable the ndb_transid_mysql_connection_map plugin; that is, enable or disable the INFORMATION_SCHEMA table having that name. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Time (in seconds) for the MySQL server to wait for connection to cluster management and data nodes before accepting MySQL client connections. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Time (in seconds) for the MySQL server to wait for NDB engine setup to complete. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Amount of data (in bytes) received from the data nodes by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Amount of data (in bytes) received from the data nodes in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Amount of data (in bytes) received from the data nodes by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Amount of data (in bytes) sent to the data nodes by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Amount of data (in bytes) sent to the data nodes in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Amount of data (in bytes) sent to the data nodes by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of bytes of events received by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of bytes of events received by the NDB binary log injector thread. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of row change events received by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of row change events received by the NDB binary log injector thread. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of events received, other than row change events, by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of events received, other than row change events, by the NDB binary log injector thread. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of operations based on or using primary keys by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of operations based on or using primary keys in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of operations based on or using primary keys by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of scans that have been pruned to a single partition by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of scans that have been pruned to a single partition in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of scans that have been pruned to a single partition by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of range scans that have been started by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of range scans that have been started in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of range scans that have been started by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Total number of rows that have been read by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Total number of rows that have been read in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Total number of rows that have been read by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of batches of rows received by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of batches of rows received in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of batches of rows received by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of table scans that have been started, including scans of internal tables, by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of table scans that have been started, including scans of internal tables, in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of table scans that have been started, including scans of internal tables, by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions aborted by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of transactions aborted in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions aborted by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions aborted (may be greater than the sum of TransCommitCount and TransAbortCount) by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of transactions aborted (may be greater than the sum of TransCommitCount and TransAbortCount) in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions aborted (may be greater than the sum of TransCommitCount and TransAbortCount) by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions committed by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of transactions committed in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions committed by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Total number of rows that have been read by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Total number of rows that have been read in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Total number of rows that have been read by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions started by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of transactions started in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions started by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of operations based on or using unique keys by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of operations based on or using unique keys in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of operations based on or using unique keys by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times thread has been blocked while waiting for execution of an operation to complete by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of times thread has been blocked while waiting for execution of an operation to complete in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times thread has been blocked while waiting for execution of an operation to complete by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times thread has been blocked waiting for a metadata-based signal by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of times thread has been blocked waiting for a metadata-based signal in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times thread has been blocked waiting for a metadata-based signal by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Total time (in nanoseconds) spent waiting for some type of signal from the data nodes by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Total time (in nanoseconds) spent waiting for some type of signal from the data nodes in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Total time (in nanoseconds) spent waiting for some type of signal from the data nodes by this slave. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times thread has been blocked while waiting for a scan-based signal by this MySQL Server (SQL node). |
||
| No | No | Yes |
| No | Session | No |
DESCRIPTION: Number of times thread has been blocked while waiting for a scan-based signal in this client session. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times thread has been blocked while waiting for a scan-based signal by this slave. |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: NDB auto-increment prefetch size |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Number of milliseconds between checks of cluster SQL nodes made by the MySQL query cache |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: If the server is acting as a MySQL Cluster node, then the value of this variable its node ID in the cluster |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: The host name or IP address of the Cluster management server. Formerly Ndb_connected_host |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: The port for connecting to Cluster management server. Formerly Ndb_connected_port |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of rows that have been found in conflict by the NDB$EPOCH() conflict detection function |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of rows that have been found in conflict by the NDB$EPOCH_TRANS() conflict detection function |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: If the server is part of a MySQL Cluster involved in cluster replication, the value of this variable indicates the number of times that conflict resolution based on "greater timestamp wins" has been applied |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: If the server is part of a MySQL Cluster involved in cluster replication, the value of this variable indicates the number of times that "same timestamp wins" conflict resolution has been applied |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of epoch transactions committed after requiring transactional conflict handling. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of internal iterations required to commit an epoch transaction. Should be (slightly) greater than or equal to Ndb_conflict_trans_conflict_commit_count. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions rejected after being found in conflict by a transactional conflict function. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Total number of rows realigned after being found in conflict by a transactional conflict function. Includes Ndb_conflict_trans_row_conflict_count and any rows included in or dependent on conflicting transactions. |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Specifies that constraint checks should be deferred (where these are supported). Not normally needed or used; for testing purposes only. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Default distribution for new tables in NDBCLUSTER (KEYHASH or LINHASH, default is KEYHASH) |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Maximum memory that can be allocated for buffering events by the NDB API. Defaults to 0 (no limit). |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Provides the number of round trips to the NDB kernel made by operations |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Controls logging of MySQL Cluster schema, connection, and data distribution events in the MySQL error log |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Forces sending of buffers to NDB immediately, without waiting for other threads |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Sets the granularity of the statistics by determining the number of starting and ending keys |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Use NDB index statistics in query optimization |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Comma-separated list of tunable options for NDB index statistics; the list should contain no spaces |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: How often to query data nodes instead of the statistics cache |
||
| No | Yes | No |
| No | Both | Yes |
DESCRIPTION: Enables pushing down of joins to data nodes |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Whether or not a MySQL server acting as a slave logs mysql.ndb_apply_status updates received from its immediate master in its own binary log, using its own server ID. |
||
| Yes | Yes | No |
| No | Both | Yes |
DESCRIPTION: Write updates to NDB tables in the binary log. Effective only if binary logging is enabled with --log-bin. |
||
| Yes | Yes | No |
| No | Global | Yes |
DESCRIPTION: Insert mapping between epochs and binary log positions into the ndb_binlog_index table. Defaults to ON. Effective only if binary logging is enabled on the server. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: When enabled, epochs in which there were no changes are written to the ndb_apply_status and ndb_binlog_index tables, even when log_slave_updates is enabled. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Whether the id and epoch of the originating server are recorded in the mysql.ndb_binlog_index table. Set using the --ndb-log-orig option when starting mysqld. |
||
| No | Yes | No |
| No | Global | No |
DESCRIPTION: Whether NDB transaction IDs are written into the binary log. (Read-only.) |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Log complete rows (ON) or updates only (OFF) |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: If the server is part of a MySQL Cluster, the value of this variable is the number of data nodes in the cluster |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Sets the number of milliseconds to wait between processing sets of rows by OPTIMIZE TABLE on NDB tables. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Determines how an SQL node chooses a cluster data node to use as transaction coordinator |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of scans executed by NDB since the cluster was last started where partition pruning could be used |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of joins that API nodes have attempted to push down to the data nodes |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of joins that API nodes have tried to push down, but failed |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of joins successfully pushed down and executed on the data nodes |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of reads executed on the data nodes by pushed-down joins |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: This is a threshold on the number of epochs to be behind before reporting binary log status |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: This is a threshold on the percentage of free memory remaining before reporting binary log status |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The total number of scans executed by NDB since the cluster was last started |
||
| No | Yes | No |
| No | Session | Yes |
DESCRIPTION: NDB tables created when this setting is enabled are not checkpointed to disk (although table schema files are created). The setting in effect when the table is created with or altered to use NDBCLUSTER persists for the lifetime of the table. |
||
| No | Yes | No |
| No | Session | Yes |
DESCRIPTION: NDB tables are not persistent on disk: no schema files are created and the tables are not logged |
||
| No | Yes | No |
| No | Both | Yes |
DESCRIPTION: Use exact row count when planning queries |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Forces NDB to use a count of records during SELECT COUNT(*) query planning to speed up this type of query |
||
| No | Yes | No |
| No | Global | No |
DESCRIPTION: Shows build and NDB engine version as an integer. |
||
| No | Yes | No |
| No | Global | No |
DESCRIPTION: Shows build information including NDB engine version in ndb-x.y.z format. |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Enable NDB Cluster (if this version of MySQL supports it)
Disabled by |
||
| No | Yes | No |
| No | Global | No |
DESCRIPTION: The name used for the NDB information database; read only. |
||
| Yes | Yes | No |
| No | Both | Yes |
DESCRIPTION: Used for debugging only. |
||
| Yes | Yes | No |
| No | Both | Yes |
DESCRIPTION: Used for debugging only. |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Put the ndbinfo database into offline mode, in which no rows are returned from tables or views. |
||
| Yes | Yes | No |
| No | Both | Yes |
DESCRIPTION: Whether to show ndbinfo internal base tables in the mysql client. The default is OFF. |
||
| Yes | Yes | No |
| No | Both | Yes |
DESCRIPTION: The prefix to use for naming ndbinfo internal base tables |
||
| No | Yes | No |
| No | Global | No |
DESCRIPTION: The version of the ndbinfo engine; read only. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Sets the number of least significant bits in the server_id actually used for identifying the server, permitting NDB API applications to store application data in the most significant bits. server_id must be less than 2 to the power of this value. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: The effective value of server_id if the server was started with the --server-id-bits option set to a nondefault value. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Turns update batching on and off for a replication slave |
||
| No | Yes | No |
| No | Session | Yes |
DESCRIPTION: Allows batching of statements within a transaction. Disable AUTOCOMMIT to use. |
||
- 18.3.3.1 MySQL Cluster Configuration: Basic Example
- 18.3.3.2 Recommended Starting Configuration for MySQL Cluster
- 18.3.3.3 MySQL Cluster Connection Strings
- 18.3.3.4 Defining Computers in a MySQL Cluster
- 18.3.3.5 Defining a MySQL Cluster Management Server
- 18.3.3.6 Defining MySQL Cluster Data Nodes
- 18.3.3.7 Defining SQL and Other API Nodes in a MySQL Cluster
- 18.3.3.8 MySQL Server Options and Variables for MySQL Cluster
- 18.3.3.9 MySQL Cluster TCP/IP Connections
- 18.3.3.10 MySQL Cluster TCP/IP Connections Using Direct Connections
- 18.3.3.11 MySQL Cluster Shared-Memory Connections
- 18.3.3.12 SCI Transport Connections in MySQL Cluster
- 18.3.3.13 Configuring MySQL Cluster Send Buffer Parameters
Configuring MySQL Cluster requires working with two files:
my.cnf: Specifies options for all MySQL Cluster executables. This file, with which you should be familiar with from previous work with MySQL, must be accessible by each executable running in the cluster.config.ini: This file, sometimes known as the global configuration file, is read only by the MySQL Cluster management server, which then distributes the information contained therein to all processes participating in the cluster.config.inicontains a description of each node involved in the cluster. This includes configuration parameters for data nodes and configuration parameters for connections between all nodes in the cluster. For a quick reference to the sections that can appear in this file, and what sorts of configuration parameters may be placed in each section, see Sections of theconfig.iniFile.
Caching of configuration data. In MySQL Cluster NDB 7.2, MySQL Cluster uses stateful configuration. Rather than reading the global configuration file every time the management server is restarted, the management server caches the configuration the first time it is started, and thereafter, the global configuration file is read only when one of the following conditions is true:
The management server is started using the --initial option. In this case, the global configuration file is re-read, any existing cache files are deleted, and the management server creates a new configuration cache.
The management server is started using the --reload option. In this case, the management server compares its cache with the global configuration file. If they differ, the management server creates a new configuration cache; any existing configuration cache is preserved, but not used. If the management server's cache and the global configuration file contain the same configuration data, then the existing cache is used, and no new cache is created.
The management server is started using a --config-cache option. This option can be used to force the management server to bypass configuration caching altogether. In this case, the management server ignores any configuration files that may be present, always reading its configuration data from the
config.inifile instead.No configuration cache is found. In this case, the management server reads the global configuration file and creates a cache containing the same configuration data as found in the file.
Configuration cache files.
The management server by default creates configuration cache
files in a directory named mysql-cluster in
the MySQL installation directory. (If you build MySQL Cluster
from source on a Unix system, the default location is
/usr/local/mysql-cluster.) This can be
overridden at runtime by starting the management server with the
--configdir option.
Configuration cache files are binary files named according to
the pattern
ndb_,
where node_id_config.bin.seq_idnode_id is the management
server's node ID in the cluster, and
seq_id is a cache idenitifer. Cache
files are numbered sequentially using
seq_id, in the order in which they
are created. The management server uses the latest cache file as
determined by the seq_id.
It is possible to roll back to a previous configuration by
deleting later configuration cache files, or by renaming an
earlier cache file so that it has a higher
seq_id. However, since configuration
cache files are written in a binary format, you should not
attempt to edit their contents by hand.
For more information about the
--configdir,
--config-cache,
--initial, and
--reload options for the MySQL
Cluster management server, see
Section 18.4.4, “ndb_mgmd — The MySQL Cluster Management Server Daemon”.
We are continuously making improvements in Cluster configuration and attempting to simplify this process. Although we strive to maintain backward compatibility, there may be times when introduce an incompatible change. In such cases we will try to let Cluster users know in advance if a change is not backward compatible. If you find such a change and we have not documented it, please report it in the MySQL bugs database using the instructions given in Section 1.6, “How to Report Bugs or Problems”.
To support MySQL Cluster, you will need to update
my.cnf as shown in the following example.
You may also specify these parameters on the command line when
invoking the executables.
The options shown here should not be confused with those that
are used in config.ini global
configuration files. Global configuration options are
discussed later in this section.
# my.cnf # example additions to my.cnf for MySQL Cluster # (valid in MySQL 5.5) # enable ndbcluster storage engine, and provide connection string for # management server host (default port is 1186) [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com # provide connection string for management server host (default port: 1186) [ndbd] connect-string=ndb_mgmd.mysql.com # provide connection string for management server host (default port: 1186) [ndb_mgm] connect-string=ndb_mgmd.mysql.com # provide location of cluster configuration file [ndb_mgmd] config-file=/etc/config.ini
(For more information on connection strings, see Section 18.3.3.3, “MySQL Cluster Connection Strings”.)
# my.cnf # example additions to my.cnf for MySQL Cluster # (will work on all versions) # enable ndbcluster storage engine, and provide connection string for management # server host to the default port 1186 [mysqld] ndbcluster ndb-connectstring=ndb_mgmd.mysql.com:1186
Once you have started a mysqld process with
the NDBCLUSTER and
ndb-connectstring parameters in the
[mysqld] in the my.cnf
file as shown previously, you cannot execute any
CREATE TABLE or
ALTER TABLE statements without
having actually started the cluster. Otherwise, these
statements will fail with an error. This is by
design.
You may also use a separate [mysql_cluster]
section in the cluster my.cnf file for
settings to be read and used by all executables:
# cluster-specific settings [mysql_cluster] ndb-connectstring=ndb_mgmd.mysql.com:1186
For additional NDB variables that
can be set in the my.cnf file, see
Section 18.3.3.8.2, “MySQL Cluster System Variables”.
The MySQL Cluster global configuration file is by convention
named config.ini (but this is not
required). If needed, it is read by ndb_mgmd
at startup and can be placed in any location that can be read by
it. The location and name of the configuration are specified
using
--config-file=
with ndb_mgmd on the command line. This
option has no default value, and is ignored if
ndb_mgmd uses the configuration cache.
path_name
The global configuration file for MySQL Cluster uses INI format,
which consists of sections preceded by section headings
(surrounded by square brackets), followed by the appropriate
parameter names and values. One deviation from the standard INI
format is that the parameter name and value can be separated by
a colon (“:”) as well as the
equal sign (“=”); however, the
equal sign is preferred. Another deviation is that sections are
not uniquely identified by section name. Instead, unique
sections (such as two different nodes of the same type) are
identified by a unique ID specified as a parameter within the
section.
Default values are defined for most parameters, and can also be
specified in config.ini. To create a
default value section, simply add the word
default to the section name. For example, an
[ndbd] section contains parameters that apply
to a particular data node, whereas an [ndbd
default] section contains parameters that apply to all
data nodes. Suppose that all data nodes should use the same data
memory size. To configure them all, create an [ndbd
default] section that contains a
DataMemory line to
specify the data memory size.
In some older releases of MySQL Cluster, there was no default
value for
NoOfReplicas, which
always had to be specified explicitly in the [ndbd
default] section. Although this parameter now has a
default value of 2, which is the recommended setting in most
common usage scenarios, it is still recommended practice to
set this parameter explicitly.
The global configuration file must define the computers and nodes involved in the cluster and on which computers these nodes are located. An example of a simple configuration file for a cluster consisting of one management server, two data nodes and two MySQL servers is shown here:
# file "config.ini" - 2 data nodes and 2 SQL nodes # This file is placed in the startup directory of ndb_mgmd (the # management server) # The first MySQL Server can be started from any host. The second # can be started only on the host mysqld_5.mysql.com [ndbd default] NoOfReplicas= 2 DataDir= /var/lib/mysql-cluster [ndb_mgmd] Hostname= ndb_mgmd.mysql.com DataDir= /var/lib/mysql-cluster [ndbd] HostName= ndbd_2.mysql.com [ndbd] HostName= ndbd_3.mysql.com [mysqld] [mysqld] HostName= mysqld_5.mysql.com
The preceding example is intended as a minimal starting configuration for purposes of familiarization with MySQL Cluster, and is almost certain not to be sufficient for production settings. See Section 18.3.3.2, “Recommended Starting Configuration for MySQL Cluster”, which provides a more complete example starting configuration.
Each node has its own section in the
config.ini file. For example, this cluster
has two data nodes, so the preceding configuration file contains
two [ndbd] sections defining these nodes.
Do not place comments on the same line as a section heading in
the config.ini file; this causes the
management server not to start because it cannot parse the
configuration file in such cases.
Sections of the config.ini File
There are six different sections that you can use in the
config.ini configuration file, as described
in the following list:
[computer]: Defines cluster hosts. This is not required to configure a viable MySQL Cluster, but be may used as a convenience when setting up a large cluster. See Section 18.3.3.4, “Defining Computers in a MySQL Cluster”, for more information.[ndbd]: Defines a cluster data node (ndbd process). See Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”, for details.[mysqld]: Defines the cluster's MySQL server nodes (also called SQL or API nodes). For a discussion of SQL node configuration, see Section 18.3.3.7, “Defining SQL and Other API Nodes in a MySQL Cluster”.[mgm]or[ndb_mgmd]: Defines a cluster management server (MGM) node. For information concerning the configuration of management nodes, see Section 18.3.3.5, “Defining a MySQL Cluster Management Server”.[tcp]: Defines a TCP/IP connection between cluster nodes, with TCP/IP being the default connection protocol. Normally,[tcp]or[tcp default]sections are not required to set up a MySQL Cluster, as the cluster handles this automatically; however, it may be necessary in some situations to override the defaults provided by the cluster. See Section 18.3.3.9, “MySQL Cluster TCP/IP Connections”, for information about available TCP/IP configuration parameters and how to use them. (You may also find Section 18.3.3.10, “MySQL Cluster TCP/IP Connections Using Direct Connections” to be of interest in some cases.)[shm]: Defines shared-memory connections between nodes. In MySQL 5.5, it is enabled by default, but should still be considered experimental. For a discussion of SHM interconnects, see Section 18.3.3.11, “MySQL Cluster Shared-Memory Connections”.[sci]:Defines Scalable Coherent Interface connections between cluster data nodes. Such connections require software which, while freely available, is not part of the MySQL Cluster distribution, as well as specialized hardware. See Section 18.3.3.12, “SCI Transport Connections in MySQL Cluster” for detailed information about SCI interconnects.
You can define default values for each
section. All Cluster parameter names are case-insensitive, which
differs from parameters specified in my.cnf
or my.ini files.
Achieving the best performance from a MySQL Cluster depends on a number of factors including the following:
MySQL Cluster software version
Numbers of data nodes and SQL nodes
Hardware
Operating system
Amount of data to be stored
Size and type of load under which the cluster is to operate
Therefore, obtaining an optimum configuration is likely to be an iterative process, the outcome of which can vary widely with the specifics of each MySQL Cluster deployment. Changes in configuration are also likely to be indicated when changes are made in the platform on which the cluster is run, or in applications that use the MySQL Cluster's data. For these reasons, it is not possible to offer a single configuration that is ideal for all usage scenarios. However, in this section, we provide a recommended base configuration.
Starting config.ini file.
The following config.ini file is a
recommended starting point for configuring a cluster running
MySQL Cluster NDB 7.2:
# TCP PARAMETERS [tcp default]SendBufferMemory=2MReceiveBufferMemory=2M # Increasing the sizes of these 2 buffers beyond the default values # helps prevent bottlenecks due to slow disk I/O. # MANAGEMENT NODE PARAMETERS [ndb_mgmd default]DataDir=path/to/management/server/data/directory# It is possible to use a different data directory for each management # server, but for ease of administration it is preferable to be # consistent. [ndb_mgmd]HostName=management-server-A-hostname#NodeId=management-server-A-nodeid[ndb_mgmd]HostName=management-server-B-hostname#NodeId=management-server-B-nodeid# Using 2 management servers helps guarantee that there is always an # arbitrator in the event of network partitioning, and so is # recommended for high availability. Each management server must be # identified by a HostName. You may for the sake of convenience specify # a NodeId for any management server, although one will be allocated # for it automatically; if you do so, it must be in the range 1-255 # inclusive and must be unique among all IDs specified for cluster # nodes. # DATA NODE PARAMETERS [ndbd default]NoOfReplicas=2 # Using 2 replicas is recommended to guarantee availability of data; # using only 1 replica does not provide any redundancy, which means # that the failure of a single data node causes the entire cluster to # shut down. We do not recommend using more than 2 replicas, since 2 is # sufficient to provide high availability, and we do not currently test # with greater values for this parameter.LockPagesInMainMemory=1 # On Linux and Solaris systems, setting this parameter locks data node # processes into memory. Doing so prevents them from swapping to disk, # which can severely degrade cluster performance.DataMemory=3072MIndexMemory=384M # The values provided for DataMemory and IndexMemory assume 4 GB RAM # per data node. However, for best results, you should first calculate # the memory that would be used based on the data you actually plan to # store (you may find the ndb_size.pl utility helpful in estimating # this), then allow an extra 20% over the calculated values. Naturally, # you should ensure that each data node host has at least as much # physical memory as the sum of these two values. #ODirect=1 # Enabling this parameter causes NDBCLUSTER to try using O_DIRECT # writes for local checkpoints and redo logs; this can reduce load on # CPUs. We recommend doing so when using MySQL Cluster on systems running # Linux kernel 2.6 or later.NoOfFragmentLogFiles=300DataDir=path/to/data/node/data/directoryMaxNoOfConcurrentOperations=100000SchedulerSpinTimer=400SchedulerExecutionTimer=100RealTimeScheduler=1 # Setting these parameters allows you to take advantage of real-time scheduling # of NDB threads to achieve increased throughput when using ndbd. They # are not needed when using ndbmtd; in particular, you should not set #RealTimeSchedulerfor ndbmtd data nodes.TimeBetweenGlobalCheckpoints=1000TimeBetweenEpochs=200DiskCheckpointSpeed=10MDiskCheckpointSpeedInRestart=100MRedoBuffer=32M #CompressedLCP=1 #CompressedBackup=1 # Enabling CompressedLCP and CompressedBackup causes, respectively, local checkpoint files and backup files to be compressed, which can result in a space savings of up to 50% over noncompressed LCPs and backups. #MaxNoOfLocalScans=64MaxNoOfTables=1024MaxNoOfOrderedIndexes=256 [ndbd]HostName=data-node-A-hostname#NodeId=data-node-A-nodeidLockExecuteThreadToCPU=1LockMaintThreadsToCPU=0 # On systems with multiple CPUs, these parameters can be used to lock NDBCLUSTER # threads to specific CPUs [ndbd]HostName=data-node-B-hostname#NodeId=data-node-B-nodeidLockExecuteThreadToCPU=1LockMaintThreadsToCPU=0 # You must have an [ndbd] section for every data node in the cluster; # each of these sections must include a HostName. Each section may # optionally include a NodeId for convenience, but in most cases, it is # sufficient to allow the cluster to allocate node IDs dynamically. If # you do specify the node ID for a data node, it must be in the range 1 # to 48 inclusive and must be unique among all IDs specified for # cluster nodes. # SQL NODE / API NODE PARAMETERS [mysqld] #HostName=sql-node-A-hostname#NodeId=sql-node-A-nodeid[mysqld] [mysqld] # Each API or SQL node that connects to the cluster requires a [mysqld] # or [api] section of its own. Each such section defines a connection # “slot”; you should have at least as many of these sections in the # config.ini file as the total number of API nodes and SQL nodes that # you wish to have connected to the cluster at any given time. There is # no performance or other penalty for having extra slots available in # case you find later that you want or need more API or SQL nodes to # connect to the cluster at the same time. # If no HostName is specified for a given [mysqld] or [api] section, # then any API or SQL node may use that slot to connect to the # cluster. You may wish to use an explicit HostName for one connection slot # to guarantee that an API or SQL node from that host can always # connect to the cluster. If you wish to prevent API or SQL nodes from # connecting from other than a desired host or hosts, then use a # HostName for every [mysqld] or [api] section in the config.ini file. # You can if you wish define a node ID (NodeId parameter) for any API or # SQL node, but this is not necessary; if you do so, it must be in the # range 1 to 255 inclusive and must be unique among all IDs specified # for cluster nodes.
Recommended my.cnf options for SQL nodes.
MySQL Servers acting as MySQL Cluster SQL nodes must always be
started with the --ndbcluster
and --ndb-connectstring options, either on
the command line or in my.cnf. In
addition, set the following options for all
mysqld processes in the cluster, unless
your setup requires otherwise:
--ndb-use-exact-count=0--ndb-index-stat-enable=0--ndb-force-send=1--engine-condition-pushdown=1
With the exception of the MySQL Cluster management server (ndb_mgmd), each node that is part of a MySQL Cluster requires a connection string that points to the management server's location. This connection string is used in establishing a connection to the management server as well as in performing other tasks depending on the node's role in the cluster. The syntax for a connection string is as follows:
[nodeid=node_id, ]host-definition[,host-definition[, ...]]host-definition:host_name[:port_number]
node_id is an integer greater than or equal
to 1 which identifies a node in config.ini.
host_name is a string representing a
valid Internet host name or IP address.
port_number is an integer referring
to a TCP/IP port number.
example 1 (long): "nodeid=2,myhost1:1100,myhost2:1100,192.168.0.3:1200" example 2 (short): "myhost1"
localhost:1186 is used as the default
connection string value if none is provided. If
port_num is omitted from the
connection string, the default port is 1186. This port should
always be available on the network because it has been assigned
by IANA for this purpose (see
http://www.iana.org/assignments/port-numbers for
details).
By listing multiple host definitions, it is possible to designate several redundant management servers. A MySQL Cluster data or API node attempts to contact successive management servers on each host in the order specified, until a successful connection has been established.
It is also possible to specify in a connection string one or more bind addresses to be used by nodes having multiple network interfaces for connecting to management servers. A bind address consists of a hostname or network address and an optional port number. This enhanced syntax for connection strings is shown here:
[nodeid=node_id, ] [bind-address=host-definition, ]host-definition[; bind-address=host-definition]host-definition[; bind-address=host-definition] [, ...]]host-definition:host_name[:port_number]
If a single bind address is used in the connection string
prior to specifying any management hosts,
then this address is used as the default for connecting to any
of them (unless overridden for a given management server; see
later in this section for an example). For example, the
following connection string causes the node to use
192.168.178.242 regardless of the management
server to which it connects:
bind-address=192.168.178.242, poseidon:1186, perch:1186
If a bind address is specified following a management host definition, then it is used only for connecting to that management node. Consider the following connection string:
poseidon:1186;bind-address=localhost, perch:1186;bind-address=192.168.178.242
In this case, the node uses localhost to
connect to the management server running on the host named
poseidon and
192.168.178.242 to connect to the management
server running on the host named perch.
You can specify a default bind address and then override this
default for one or more specific management hosts. In the
following example, localhost is used for
connecting to the management server running on host
poseidon; since
192.168.178.242 is specified first (before
any management server definitions), it is the default bind
address and so is used for connecting to the management servers
on hosts perch and orca:
bind-address=192.168.178.242,poseidon:1186;bind-address=localhost,perch:1186,orca:2200
There are a number of different ways to specify the connection string:
Each executable has its own command-line option which enables specifying the management server at startup. (See the documentation for the respective executable.)
It is also possible to set the connection string for all nodes in the cluster at once by placing it in a
[mysql_cluster]section in the management server'smy.cnffile.For backward compatibility, two other options are available, using the same syntax:
Set the
NDB_CONNECTSTRINGenvironment variable to contain the connection string.Write the connection string for each executable into a text file named
Ndb.cfgand place this file in the executable's startup directory.
However, these are now deprecated and should not be used for new installations.
The recommended method for specifying the connection string is
to set it on the command line or in the
my.cnf file for each executable.
The [computer] section has no real
significance other than serving as a way to avoid the need of
defining host names for each node in the system. All parameters
mentioned here are required.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 string [none] ... IS This is a unique identifier, used to refer to the host computer elsewhere in the configuration file.
ImportantThe computer ID is not the same as the node ID used for a management, API, or data node. Unlike the case with node IDs, you cannot use
NodeIdin place ofIdin the[computer]section of theconfig.inifile. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N This is the computer's hostname or IP address.
The [ndb_mgmd] section is used to configure
the behavior of the management server. If multiple management
servers are employed, you can specify parameters common to all
of them in an [ndb_mgmd default] section.
[mgm] and [mgm default]
are older aliases for these, supported for backward
compatibility.
All parameters in the following list are optional and assume their default values if omitted.
If neither the ExecuteOnComputer nor the
HostName parameter is present, the default
value localhost will be assumed for both.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 1 - 255 IS Each node in the cluster has a unique identity. For a management node, this is represented by an integer value in the range 1 to 255, inclusive. This ID is used by all internal cluster messages for addressing the node, and so must be unique for each MySQL Cluster node, regardless of the type of node.
NoteData node IDs must be less than 49. If you plan to deploy a large number of data nodes, it is a good idea to limit the node IDs for management nodes (and API nodes) to values greater than 48.
The use of the
Idparameter for identifying management nodes is deprecated in favor ofNodeId. AlthoughIdcontinues to be supported for backward compatibility, it now generates a warning and is subject to removal in a future version of MySQL Cluster. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 1 - 255 IS Each node in the cluster has a unique identity. For a management node, this is represented by an integer value in the range 1 to 255 inclusive. This ID is used by all internal cluster messages for addressing the node, and so must be unique for each MySQL Cluster node, regardless of the type of node.
NoteData node IDs must be less than 49. If you plan to deploy a large number of data nodes, it is a good idea to limit the node IDs for management nodes (and API nodes) to values greater than 48.
NodeIdis the preferred parameter name to use when identifying management nodes. Although the olderIdcontinues to be supported for backward compatibility, it is now deprecated and generates a warning when used; it is also subject to removal in a future MySQL Cluster release. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name [none] ... S This refers to the
Idset for one of the computers defined in a[computer]section of theconfig.inifile. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 1186 0 - 64K S This is the port number on which the management server listens for configuration requests and management commands.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N Specifying this parameter defines the hostname of the computer on which the management node is to reside. To specify a hostname other than
localhost, either this parameter orExecuteOnComputeris required. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 {CONSOLE|SYSLOG|FILE} [see text] ... N This parameter specifies where to send cluster logging information. There are three options in this regard—
CONSOLE,SYSLOG, andFILE—withFILEbeing the default:CONSOLEoutputs the log tostdout:CONSOLE
SYSLOGsends the log to asyslogfacility, possible values being one ofauth,authpriv,cron,daemon,ftp,kern,lpr,mail,news,syslog,user,uucp,local0,local1,local2,local3,local4,local5,local6, orlocal7.NoteNot every facility is necessarily supported by every operating system.
SYSLOG:facility=syslog
FILEpipes the cluster log output to a regular file on the same machine. The following values can be specified:filename: The name of the log file.In MySQL Cluster NDB 7.2.6 and earlier, the log file's default name, used if
FILEwas specified without also settingfilename, waslogger.log. Beginning with MySQL Cluster NDB 7.2.7, the default log file name used in such cases isndb_.nodeid_cluster.logmaxsize: The maximum size (in bytes) to which the file can grow before logging rolls over to a new file. When this occurs, the old log file is renamed by appending.Nto the file name, whereNis the next number not yet used with this name.maxfiles: The maximum number of log files.
FILE:filename=cluster.log,maxsize=1000000,maxfiles=6
The default value for the
FILEparameter isFILE:filename=ndb_, wherenode_id_cluster.log,maxsize=1000000,maxfiles=6node_idis the ID of the node.
It is possible to specify multiple log destinations separated by semicolons as shown here:
CONSOLE;SYSLOG:facility=local0;FILE:filename=/var/log/mgmd
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 0-2 1 0 - 2 N This parameter is used to define which nodes can act as arbitrators. Only management nodes and SQL nodes can be arbitrators.
ArbitrationRankcan take one of the following values:0: The node will never be used as an arbitrator.1: The node has high priority; that is, it will be preferred as an arbitrator over low-priority nodes.2: Indicates a low-priority node which be used as an arbitrator only if a node with a higher priority is not available for that purpose.
Normally, the management server should be configured as an arbitrator by setting its
ArbitrationRankto 1 (the default for management nodes) and those for all SQL nodes to 0 (the default for SQL nodes).You can disable arbitration completely either by setting
ArbitrationRankto 0 on all management and SQL nodes, or by setting theArbitrationparameter in the[ndbd default]section of theconfig.iniglobal configuration file. SettingArbitrationcauses any settings forArbitrationRankto be disregarded. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 0 0 - 4294967039 (0xFFFFFEFF) N An integer value which causes the management server's responses to arbitration requests to be delayed by that number of milliseconds. By default, this value is 0; it is normally not necessary to change it.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 path . ... N This specifies the directory where output files from the management server will be placed. These files include cluster log files, process output files, and the daemon's process ID (PID) file. (For log files, this location can be overridden by setting the
FILEparameter forLogDestinationas discussed previously in this section.)The default value for this parameter is the directory in which ndb_mgmd is located.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 0 - 64K N This parameter specifies the port number used to obtain statistical information from a MySQL Cluster management server. It has no default value.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N Use WAN TCP setting as default.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 string [none] ... S Set the scheduling policy and priority of heartbeat threads for management and API nodes.
The syntax for setting this parameter is shown here:
HeartbeatThreadPriority =
policy[,priority]policy: {FIFO | RR}When setting this parameter, you must specify a policy. This is one of
FIFO(first in, first out) orRR(round robin). The policy value is followed optionally by the priority (an integer). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.14 bytes 0 0 - 32G N This parameter specifies the amount of transporter send buffer memory to allocate in addition to any that has been set using
TotalSendBufferMemory,SendBufferMemory, or both.This parameter was added in MySQL Cluster NDB 7.2.14. (Bug #14555359)
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 0 256K - 4294967039 (0xFFFFFEFF) N This parameter is used to determine the total amount of memory to allocate on this node for shared send buffer memory among all configured transporters.
If this parameter is set, its minimum permitted value is 256KB; 0 indicates that the parameter has not been set. For more detailed information, see Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.12 milliseconds 1500 100 - 4294967039 (0xFFFFFEFF) N Specify the interval between heartbeat messages used to determine whether another management node is on contact with this one. The management node waits after 3 of these intervals to declare the connection dead; thus, the default setting of 1500 milliseconds causes the management node to wait for approximately 1600 ms before timing out.
This parameter was added in MySQL Cluster NDB 7.2.12. (Bug #16426805, Bug #17807768)
After making changes in a management node's configuration, it is necessary to perform a rolling restart of the cluster for the new configuration to take effect.
To add new management servers to a running MySQL Cluster, it
is also necessary to perform a rolling restart of all cluster
nodes after modifying any existing
config.ini files. For more information
about issues arising when using multiple management nodes, see
Section 18.1.6.10, “Limitations Relating to Multiple MySQL Cluster Nodes”.
The [ndbd] and [ndbd
default] sections are used to configure the behavior
of the cluster's data nodes.
[ndbd] and [ndbd default]
are always used as the section names whether you are using
ndbd or ndbmtd binaries
for the data node processes.
There are many parameters which control buffer sizes, pool
sizes, timeouts, and so forth. The only mandatory parameter is
either one of ExecuteOnComputer or
HostName; this must be defined in the local
[ndbd] section.
The parameter
NoOfReplicas should be
defined in the [ndbd default] section, as it
is common to all Cluster data nodes. It is not strictly
necessary to set
NoOfReplicas, but it is
good practice to set it explicitly.
Most data node parameters are set in the [ndbd
default] section. Only those parameters explicitly
stated as being able to set local values are permitted to be
changed in the [ndbd] section. Where present,
HostName, NodeId and
ExecuteOnComputer must
be defined in the local [ndbd] section, and
not in any other section of config.ini. In
other words, settings for these parameters are specific to one
data node.
For those parameters affecting memory usage or buffer sizes, it
is possible to use K, M,
or G as a suffix to indicate units of 1024,
1024×1024, or 1024×1024×1024. (For example,
100K means 100 × 1024 = 102400.)
Parameter names and values are currently case-sensitive.
Information about configuration parameters specific to MySQL Cluster Disk Data tables can be found later in this section (see Disk Data Configuration Parameters).
All of these parameters also apply to ndbmtd
(the multi-threaded version of ndbd). Three
additional data node configuration
parameters—MaxNoOfExecutionThreads,
ThreadConfig, and
NoOfFragmentLogParts—apply
to ndbmtd only; these have no effect when
used with ndbd. For more information, see
Multi-Threading Configuration Parameters (ndbmtd).
See also Section 18.4.3, “ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)”.
Identifying data nodes.
The NodeId or Id value
(that is, the data node identifier) can be allocated on the
command line when the node is started or in the configuration
file.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 1 - 48 IS A unique node ID is used as the node's address for all cluster internal messages. For data nodes, this is an integer in the range 1 to 48 inclusive. Each node in the cluster must have a unique identifier.
NodeIdis the preferred parameter name to use when identifying data nodes. Although the olderIdis still supported for backward compatibility, it is now deprecated, and generates a warning when used.Idis also subject to removal in a future MySQL Cluster release. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 1 - 48 IS A unique node ID is used as the node's address for all cluster internal messages. For data nodes, this is an integer in the range 1 to 48 inclusive. Each node in the cluster must have a unique identifier.
NodeIdis the preferred parameter name to use when identifying data nodes. AlthoughIdcontinues to be supported for backward compatibility, it is now deprecated, generates a warning when used, and is subject to removal in a future version of MySQL Cluster. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name [none] ... S This refers to the
Idset for one of the computers defined in a[computer]section. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address localhost ... N Specifying this parameter defines the hostname of the computer on which the data node is to reside. To specify a hostname other than
localhost, either this parameter orExecuteOnComputeris required. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 1 - 64K S Each node in the cluster uses a port to connect to other nodes. By default, this port is allocated dynamically in such a way as to ensure that no two nodes on the same host computer receive the same port number, so it should normally not be necessary to specify a value for this parameter.
However, if you need to be able to open specific ports in a firewall to permit communication between data nodes and API nodes (including SQL nodes), you can set this parameter to the number of the desired port in an
[ndbd]section or (if you need to do this for multiple data nodes) the[ndbd default]section of theconfig.inifile, and then open the port having that number for incoming connections from SQL nodes, API nodes, or both.NoteConnections from data nodes to management nodes is done using the ndb_mgmd management port (the management server's
PortNumber; see Section 18.3.3.5, “Defining a MySQL Cluster Management Server”) so outgoing connections to that port from any data nodes should always be permitted. Setting this parameter to
TRUEor1bindsIP_ADDR_ANYso that connections can be made from anywhere (for autogenerated connections). The default isFALSE(0).-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 [none] 0 - 65536 IS This parameter can be used to assign a data node to a specific node group. It is read only when the cluster is started for the first time, and cannot be used to reassign a data node to a different node group online. It is generally not desirable to use this parameter in the
[ndbd default]section of theconfig.inifile, and care must be taken not to assign nodes to node groups in such a way that an invalid numbers of nodes are assigned to any node groups.The
NodeGroupparameter is chiefly intended for use in adding a new node group to a running MySQL Cluster without having to perform a rolling restart. For this purpose, you should set it to 65536 (the maximum value). You are not required to set aNodeGroupvalue for all cluster data nodes, only for those nodes which are to be started and added to the cluster as a new node group at a later time. For more information, see Section 18.5.13.3, “Adding MySQL Cluster Data Nodes Online: Detailed Example”. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 2 1 - 4 IS This global parameter can be set only in the
[ndbd default]section, and defines the number of replicas for each table stored in the cluster. This parameter also specifies the size of node groups. A node group is a set of nodes all storing the same information.Node groups are formed implicitly. The first node group is formed by the set of data nodes with the lowest node IDs, the next node group by the set of the next lowest node identities, and so on. By way of example, assume that we have 4 data nodes and that
NoOfReplicasis set to 2. The four data nodes have node IDs 2, 3, 4 and 5. Then the first node group is formed from nodes 2 and 3, and the second node group by nodes 4 and 5. It is important to configure the cluster in such a manner that nodes in the same node groups are not placed on the same computer because a single hardware failure would cause the entire cluster to fail.If no node IDs are provided, the order of the data nodes will be the determining factor for the node group. Whether or not explicit assignments are made, they can be viewed in the output of the management client's
SHOWcommand.The default value for
NoOfReplicasis 2, which is the recommended setting in most common usage scenarios.The maximum possible value is 4; currently, only the values 1 and 2 are actually supported.
ImportantSetting
NoOfReplicasto 1 means that there is only a single copy of all Cluster data; in this case, the loss of a single data node causes the cluster to fail because there are no additional copies of the data stored by that node.The value for this parameter must divide evenly into the number of data nodes in the cluster. For example, if there are two data nodes, then
NoOfReplicasmust be equal to either 1 or 2, since 2/3 and 2/4 both yield fractional values; if there are four data nodes, thenNoOfReplicasmust be equal to 1, 2, or 4. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 path . ... IN This parameter specifies the directory where trace files, log files, pid files and error logs are placed.
The default is the data node process working directory.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 path DataDir ... IN This parameter specifies the directory where all files created for metadata, REDO logs, UNDO logs (for Disk Data tables), and data files are placed. The default is the directory specified by
DataDir.NoteThis directory must exist before the ndbd process is initiated.
The recommended directory hierarchy for MySQL Cluster includes
/var/lib/mysql-cluster, under which a directory for the node's file system is created. The name of this subdirectory contains the node ID. For example, if the node ID is 2, this subdirectory is namedndb_2_fs. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 path [see text] ... IN This parameter specifies the directory in which backups are placed.
ImportantThe string '
/BACKUP' is always appended to this value. For example, if you set the value ofBackupDataDirto/var/lib/cluster-data, then all backups are stored under/var/lib/cluster-data/BACKUP. This also means that the effective default backup location is the directory namedBACKUPunder the location specified by theFileSystemPathparameter.
Data Memory, Index Memory, and String Memory
DataMemory and
IndexMemory are
[ndbd] parameters specifying the size of
memory segments used to store the actual records and their
indexes. In setting values for these, it is important to
understand how
DataMemory and
IndexMemory are used, as
they usually need to be updated to reflect actual usage by the
cluster:
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 80M 1M - 1024G N This parameter defines the amount of space (in bytes) available for storing database records. The entire amount specified by this value is allocated in memory, so it is extremely important that the machine has sufficient physical memory to accommodate it.
The memory allocated by
DataMemoryis used to store both the actual records and indexes. There is a 16-byte overhead on each record; an additional amount for each record is incurred because it is stored in a 32KB page with 128 byte page overhead (see below). There is also a small amount wasted per page due to the fact that each record is stored in only one page.For variable-size table attributes, the data is stored on separate data pages, allocated from
DataMemory. Variable-length records use a fixed-size part with an extra overhead of 4 bytes to reference the variable-size part. The variable-size part has 2 bytes overhead plus 2 bytes per attribute.The maximum record size is 14000 bytes.
The memory space defined by
DataMemoryis also used to store ordered indexes, which use about 10 bytes per record. Each table row is represented in the ordered index. A common error among users is to assume that all indexes are stored in the memory allocated byIndexMemory, but this is not the case: Only primary key and unique hash indexes use this memory; ordered indexes use the memory allocated byDataMemory. However, creating a primary key or unique hash index also creates an ordered index on the same keys, unless you specifyUSING HASHin the index creation statement. This can be verified by running ndb_desc -ddb_nametable_namein the management client.MySQL Cluster can use a maximum of 512 MB for hash indexes per partition, which means in some cases it is possible to get Table is full errors in MySQL client applications even when ndb_mgm -e "ALL REPORT MEMORYUSAGE" shows significant free
DataMemory. This can also pose a problem with data node restarts on nodes that are heavily loaded with data. You can forceNDBto create extra partitions for MySQL Cluster tables and thus have more memory available for hash indexes by using theMAX_ROWSoption forCREATE TABLE. In general, settingMAX_ROWSto twice the number of rows that you expect to store in the table should be sufficient. In MySQL Cluster 7.2.3 and later, you can also use theMinFreePctconfiguration parameter to help avoid problems with node restarts. (Bug #13436216)The memory space allocated by
DataMemoryconsists of 32KB pages, which are allocated to table fragments. Each table is normally partitioned into the same number of fragments as there are data nodes in the cluster. Thus, for each node, there are the same number of fragments as are set inNoOfReplicas.Once a page has been allocated, it is currently not possible to return it to the pool of free pages, except by deleting the table. (This also means that
DataMemorypages, once allocated to a given table, cannot be used by other tables.) Performing a data node recovery also compresses the partition because all records are inserted into empty partitions from other live nodes.The
DataMemorymemory space also contains UNDO information: For each update, a copy of the unaltered record is allocated in theDataMemory. There is also a reference to each copy in the ordered table indexes. Unique hash indexes are updated only when the unique index columns are updated, in which case a new entry in the index table is inserted and the old entry is deleted upon commit. For this reason, it is also necessary to allocate enough memory to handle the largest transactions performed by applications using the cluster. In any case, performing a few large transactions holds no advantage over using many smaller ones, for the following reasons:Large transactions are not any faster than smaller ones
Large transactions increase the number of operations that are lost and must be repeated in event of transaction failure
Large transactions use more memory
The default value for
DataMemoryis 80MB; the minimum is 1MB. There is no maximum size, but in reality the maximum size has to be adapted so that the process does not start swapping when the limit is reached. This limit is determined by the amount of physical RAM available on the machine and by the amount of memory that the operating system may commit to any one process. 32-bit operating systems are generally limited to 2−4GB per process; 64-bit operating systems can use more. For large databases, it may be preferable to use a 64-bit operating system for this reason. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 18M 1M - 1T N This parameter controls the amount of storage used for hash indexes in MySQL Cluster. Hash indexes are always used for primary key indexes, unique indexes, and unique constraints. When defining a primary key or a unique index, two indexes are created, one of which is a hash index used for all tuple accesses as well as lock handling. This index is also used to enforce unique constraints.
You can estimate the size of a hash index using this formula:
size = ( (
fragments* 32K) + (rows* 18) ) *replicasfragmentsis the number of fragments,replicasis the number of replicas (normally 2), androwsis the number of rows. If a table has one million rows, 8 fragments, and 2 replicas, the expected index memory usage is calculated as shown here:((8 * 32K) + (1000000 * 18)) * 2 = ((8 * 32768) + (1000000 * 18)) * 2 = (262144 + 18000000) * 2 = 18262144 * 2 = 36524288 bytes = ~35MB
In MySQL Cluster NDB 7.2 and later, index statistics (when enabled) for ordered indexes are stored in the
mysql.ndb_index_stat_sampletable. Since this table has a hash index, this adds to index memory usage. An upper bound to the number of rows for a given ordered index can be calculated as follows:sample_size= key_size + ((key_attributes + 1) * 4) sample_rows =
IndexStatSaveSize* ((0.01 *IndexStatSaveScale* log2(rows * sample_size)) + 1) / sample_sizeIn the preceding formula,
key_sizeis the size of the ordered index key in bytes,key_attributesis the number ot attributes in the ordered index key, androwsis the number of rows in the base table.Assume that table
t1has 1 million rows and an ordered index namedix1on two four-byte integers. Assume in addition thatIndexStatSaveSizeandIndexStatSaveScaleare set to their default values (32K and 100, respectively). Using the previous 2 formulas, we can calculate as follows:sample_size = 8 + ((1 + 2) * 4) = 20 bytes sample_rows = 32K * ((0.01 * 100 * log2(1000000*20)) + 1) / 20 = 32768 * ( (1 * ~16.811) +1) / 20 = 32768 * ~17.811 / 20 = ~29182 rowsThe expected index memory usage is thus 2 * 18 * 29182 = ~1050550 bytes.
The default value for
IndexMemoryis 18MB. The minimum is 1MB. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 % or bytes 25 0 - 4294967039 (0xFFFFFEFF) S NDB 7.2.1 % or bytes 25 0 - 4294967039 (0xFFFFFEFF) S This parameter determines how much memory is allocated for strings such as table names, and is specified in an
[ndbd]or[ndbd default]section of theconfig.inifile. A value between0and100inclusive is interpreted as a percent of the maximum default value, which is calculated based on a number of factors including the number of tables, maximum table name size, maximum size of.FRMfiles,MaxNoOfTriggers, maximum column name size, and maximum default column value.A value greater than
100is interpreted as a number of bytes.The default value is 25—that is, 25 percent of the default maximum.
Under most circumstances, the default value should be sufficient, but when you have a great many Cluster tables (1000 or more), it is possible to get Error 773 Out of string memory, please modify StringMemory config parameter: Permanent error: Schema error, in which case you should increase this value.
25(25 percent) is not excessive, and should prevent this error from recurring in all but the most extreme conditions.
The following example illustrates how memory is used for a table. Consider this table definition:
CREATE TABLE example ( a INT NOT NULL, b INT NOT NULL, c INT NOT NULL, PRIMARY KEY(a), UNIQUE(b) ) ENGINE=NDBCLUSTER;
For each record, there are 12 bytes of data plus 12 bytes
overhead. Having no nullable columns saves 4 bytes of overhead.
In addition, we have two ordered indexes on columns
a and b consuming roughly
10 bytes each per record. There is a primary key hash index on
the base table using roughly 29 bytes per record. The unique
constraint is implemented by a separate table with
b as primary key and a as
a column. This other table consumes an additional 29 bytes of
index memory per record in the example table
as well 8 bytes of record data plus 12 bytes of overhead.
Thus, for one million records, we need 58MB for index memory to handle the hash indexes for the primary key and the unique constraint. We also need 64MB for the records of the base table and the unique index table, plus the two ordered index tables.
You can see that hash indexes takes up a fair amount of memory space; however, they provide very fast access to the data in return. They are also used in MySQL Cluster to handle uniqueness constraints.
The only partitioning algorithm is hashing and ordered indexes are local to each node. Thus, ordered indexes cannot be used to handle uniqueness constraints in the general case.
An important point for both
IndexMemory and
DataMemory is that the
total database size is the sum of all data memory and all index
memory for each node group. Each node group is used to store
replicated information, so if there are four nodes with two
replicas, there will be two node groups. Thus, the total data
memory available is 2 ×
DataMemory for each data
node.
It is highly recommended that
DataMemory and
IndexMemory be set to
the same values for all nodes. Data distribution is even over
all nodes in the cluster, so the maximum amount of space
available for any node can be no greater than that of the
smallest node in the cluster.
DataMemory and
IndexMemory can be
changed, but decreasing either of these can be risky; doing so
can easily lead to a node or even an entire MySQL Cluster that
is unable to restart due to there being insufficient memory
space. Increasing these values should be acceptable, but it is
recommended that such upgrades are performed in the same manner
as a software upgrade, beginning with an update of the
configuration file, and then restarting the management server
followed by restarting each data node in turn.
MinFreePct.
Beginning with MySQL Cluster NDB 7.2.3, a proportion (5% by
default) of data node resources including
DataMemory and
IndexMemory is kept in
reserve to insure that the data node does not exhaust its
memory when performing a restart. This can be adjusted using
the MinFreePct data
node configuration parameter (default 5) introduced in the
same version of MySQL Cluster.
| Effective Version | Type/Units | Default | Range/Values | Restart Type |
|---|---|---|---|---|
| NDB 7.2.3 | unsigned | 5 | 0 - 100 | N |
Updates do not increase the amount of index memory used. Inserts take effect immediately; however, rows are not actually deleted until the transaction is committed.
Transaction parameters.
The next few [ndbd] parameters that we
discuss are important because they affect the number of
parallel transactions and the sizes of transactions that can
be handled by the system.
MaxNoOfConcurrentTransactions
sets the number of parallel transactions possible in a node.
MaxNoOfConcurrentOperations
sets the number of records that can be in update phase or
locked simultaneously.
Both of these parameters (especially
MaxNoOfConcurrentOperations)
are likely targets for users setting specific values and not
using the default value. The default value is set for systems
using small transactions, to ensure that these do not use
excessive memory.
MaxDMLOperationsPerTransaction
sets the maximum number of DML operations that can be performed
in a given transaction.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 4096 32 - 4294967039 (0xFFFFFEFF) N Each cluster data node requires a transaction record for each active transaction in the cluster. The task of coordinating transactions is distributed among all of the data nodes. The total number of transaction records in the cluster is the number of transactions in any given node times the number of nodes in the cluster.
Transaction records are allocated to individual MySQL servers. Each connection to a MySQL server requires at least one transaction record, plus an additional transaction object per table accessed by that connection. This means that a reasonable minimum for the total number of transactions in the cluster can be expressed as
TotalNoOfConcurrentTransactions = (maximum number of tables accessed in any single transaction + 1) * number of cluster SQL nodesSuppose that there are 10 SQL nodes using the cluster. A single join involving 10 tables requires 11 transaction records; if there are 10 such joins in a transaction, then 10 * 11 = 110 transaction records are required for this transaction, per MySQL server, or 110 * 10 = 1100 transaction records total. Each data node can be expected to handle TotalNoOfConcurrentTransactions / number of data nodes. For a MySQL Cluster having 4 data nodes, this would mean setting
MaxNoOfConcurrentTransactionson each data node to 1100 / 4 = 275. In addition, you should provide for failure recovery by ensuring that a single node group can accommodate all concurrent transactions; in other words, that each data node's MaxNoOfConcurrentTransactions is sufficient to cover a number of transaction equal to TotalNoOfConcurrentTransactions / number of node groups. If this cluster has a single node group, thenMaxNoOfConcurrentTransactionsshould be set to 1100 (the same as the total number of concurrent transactions for the entire cluster).In addition, each transaction involves at least one operation; for this reason, the value set for
MaxNoOfConcurrentTransactionsshould always be no more than the value ofMaxNoOfConcurrentOperations.This parameter must be set to the same value for all cluster data nodes. This is due to the fact that, when a data node fails, the oldest surviving node re-creates the transaction state of all transactions that were ongoing in the failed node.
It is possible to change this value using a rolling restart, but the amount of traffic on the cluster must be such that no more transactions occur than the lower of the old and new levels while this is taking place.
The default value is 4096.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 32K 32 - 4294967039 (0xFFFFFEFF) N It is a good idea to adjust the value of this parameter according to the size and number of transactions. When performing transactions which involve only a few operations and records, the default value for this parameter is usually sufficient. Performing large transactions involving many records usually requires that you increase its value.
Records are kept for each transaction updating cluster data, both in the transaction coordinator and in the nodes where the actual updates are performed. These records contain state information needed to find UNDO records for rollback, lock queues, and other purposes.
This parameter should be set at a minimum to the number of records to be updated simultaneously in transactions, divided by the number of cluster data nodes. For example, in a cluster which has four data nodes and which is expected to handle one million concurrent updates using transactions, you should set this value to 1000000 / 4 = 250000. To help provide resiliency against failures, it is suggested that you set this parameter to a value that is high enough to permit an individual data node to handle the load for its node group. In other words, you should set the value equal to
total number of concurrent operations / number of node groups. (In the case where there is a single node group, this is the same as the total number of concurrent operations for the entire cluster.)Because each transaction always involves at least one operation, the value of
MaxNoOfConcurrentOperationsshould always be greater than or equal to the value ofMaxNoOfConcurrentTransactions.Read queries which set locks also cause operation records to be created. Some extra space is allocated within individual nodes to accommodate cases where the distribution is not perfect over the nodes.
When queries make use of the unique hash index, there are actually two operation records used per record in the transaction. The first record represents the read in the index table and the second handles the operation on the base table.
The default value is 32768.
This parameter actually handles two values that can be configured separately. The first of these specifies how many operation records are to be placed with the transaction coordinator. The second part specifies how many operation records are to be local to the database.
A very large transaction performed on an eight-node cluster requires as many operation records in the transaction coordinator as there are reads, updates, and deletes involved in the transaction. However, the operation records of the are spread over all eight nodes. Thus, if it is necessary to configure the system for one very large transaction, it is a good idea to configure the two parts separately.
MaxNoOfConcurrentOperationswill always be used to calculate the number of operation records in the transaction coordinator portion of the node.It is also important to have an idea of the memory requirements for operation records. These consume about 1KB per record.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer UNDEFINED 32 - 4294967039 (0xFFFFFEFF) N By default, this parameter is calculated as 1.1 ×
MaxNoOfConcurrentOperations. This fits systems with many simultaneous transactions, none of them being very large. If there is a need to handle one very large transaction at a time and there are many nodes, it is a good idea to override the default value by explicitly specifying this parameter. MaxDMLOperationsPerTransactionEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 operations (DML) 4294967295 32 - 4294967295 N This parameter limits the size of a transaction. The transaction is aborted if it requires more than this many DML operations. The minimum number of operations per transaction is 32; however, you can set
MaxDMLOperationsPerTransactionto 0 to disable any limitation on the number of DML operations per transaction. The maximum (and default) is 4294967295.
Transaction temporary storage.
The next set of [ndbd] parameters is used
to determine temporary storage when executing a statement that
is part of a Cluster transaction. All records are released
when the statement is completed and the cluster is waiting for
the commit or rollback.
The default values for these parameters are adequate for most situations. However, users with a need to support transactions involving large numbers of rows or operations may need to increase these values to enable better parallelism in the system, whereas users whose applications require relatively small transactions can decrease the values to save memory.
MaxNoOfConcurrentIndexOperationsEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 8K 0 - 4294967039 (0xFFFFFEFF) N For queries using a unique hash index, another temporary set of operation records is used during a query's execution phase. This parameter sets the size of that pool of records. Thus, this record is allocated only while executing a part of a query. As soon as this part has been executed, the record is released. The state needed to handle aborts and commits is handled by the normal operation records, where the pool size is set by the parameter
MaxNoOfConcurrentOperations.The default value of this parameter is 8192. Only in rare cases of extremely high parallelism using unique hash indexes should it be necessary to increase this value. Using a smaller value is possible and can save memory if the DBA is certain that a high degree of parallelism is not required for the cluster.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 4000 0 - 4294967039 (0xFFFFFEFF) N The default value of
MaxNoOfFiredTriggersis 4000, which is sufficient for most situations. In some cases it can even be decreased if the DBA feels certain the need for parallelism in the cluster is not high.A record is created when an operation is performed that affects a unique hash index. Inserting or deleting a record in a table with unique hash indexes or updating a column that is part of a unique hash index fires an insert or a delete in the index table. The resulting record is used to represent this index table operation while waiting for the original operation that fired it to complete. This operation is short-lived but can still require a large number of records in its pool for situations with many parallel write operations on a base table containing a set of unique hash indexes.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 1M 1K - 4294967039 (0xFFFFFEFF) N The memory affected by this parameter is used for tracking operations fired when updating index tables and reading unique indexes. This memory is used to store the key and column information for these operations. It is only very rarely that the value for this parameter needs to be altered from the default.
The default value for
TransactionBufferMemoryis 1MB.Normal read and write operations use a similar buffer, whose usage is even more short-lived. The compile-time parameter
ZATTRBUF_FILESIZE(found inndb/src/kernel/blocks/Dbtc/Dbtc.hpp) set to 4000 × 128 bytes (500KB). A similar buffer for key information,ZDATABUF_FILESIZE(also inDbtc.hpp) contains 4000 × 16 = 62.5KB of buffer space.Dbtcis the module that handles transaction coordination.
Scans and buffering.
There are additional [ndbd] parameters in
the Dblqh module (in
ndb/src/kernel/blocks/Dblqh/Dblqh.hpp)
that affect reads and updates. These include
ZATTRINBUF_FILESIZE, set by default to
10000 × 128 bytes (1250KB) and
ZDATABUF_FILE_SIZE, set by default to
10000*16 bytes (roughly 156KB) of buffer space. To date, there
have been neither any reports from users nor any results from
our own extensive tests suggesting that either of these
compile-time limits should be increased.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 256 2 - 500 N This parameter is used to control the number of parallel scans that can be performed in the cluster. Each transaction coordinator can handle the number of parallel scans defined for this parameter. Each scan query is performed by scanning all partitions in parallel. Each partition scan uses a scan record in the node where the partition is located, the number of records being the value of this parameter times the number of nodes. The cluster should be able to sustain
MaxNoOfConcurrentScansscans concurrently from all nodes in the cluster.Scans are actually performed in two cases. The first of these cases occurs when no hash or ordered indexes exists to handle the query, in which case the query is executed by performing a full table scan. The second case is encountered when there is no hash index to support the query but there is an ordered index. Using the ordered index means executing a parallel range scan. The order is kept on the local partitions only, so it is necessary to perform the index scan on all partitions.
The default value of
MaxNoOfConcurrentScansis 256. The maximum value is 500. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer [see text] 32 - 4294967039 (0xFFFFFEFF) N Specifies the number of local scan records if many scans are not fully parallelized. In MySQL Cluster NDB 7.2.0 and later, when the number of local scan records is not provided, it is calculated as shown here:
4 *
MaxNoOfConcurrentScans* [# data nodes] + 2The minimum value is 32.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 64 1 - 992 N NDB 7.2.1 integer 256 1 - 992 N This parameter is used to calculate the number of lock records used to handle concurrent scan operations.
BatchSizePerLocalScanhas a strong connection to theBatchSizedefined in the SQL nodes. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 4M 512K - 4294967039 (0xFFFFFEFF) N NDB 7.2.16 bytes 64M 512K - 4294967039 (0xFFFFFEFF) N This is an internal buffer used for passing messages within individual nodes and between nodes. The default is 64MB. (Prior to MySQL Cluster NDB 7.2.16, this was 4MB.)
This parameter seldom needs to be changed from the default.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 256 1 - 4294967039 (0xFFFFFEFF) N It is possible to configure the maximum number of parallel scans (
TUPscans andTUXscans) allowed before they begin queuing for serial handling. You can increase this to take advantage of any unused CPU when performing large number of scans in parallel and improve their performance.Beginning with MySQL Cluster NDB 7.2.0, the default value for this parameter was increased from 32 to 256.
Memory Allocation
| Effective Version | Type/Units | Default | Range/Values | Restart Type |
|---|---|---|---|---|
| NDB 7.2.0 | unsigned | 32M | 1M - 1G | N |
This is the maximum size of the memory unit to use when
allocating memory for tables. In cases where
NDB gives Out of
memory errors, but it is evident by examining the
cluster logs or the output of DUMP 1000 (see
DUMP 1000) that all
available memory has not yet been used, you can increase the
value of this parameter (or
MaxNoOfTables, or both)
to cause NDB to make sufficient
memory available.
Hash Map Size
| Effective Version | Type/Units | Default | Range/Values | Restart Type |
|---|---|---|---|---|
| NDB 7.2.11 | LDM threads | 3840 | 0 - 3840 | N |
MySQL Cluster NDB 7.2.7 and later use a larger default table
hash map size (3840) than in previous releases (240). Beginning
with MySQL Cluster NDB 7.2.11, the size of the table hash maps
used by NDB is configurable using
this parameter; previously this value was hard-coded.
DefaultHashMapSize can take any of three
possible values (0, 240, 3840). These values and their effects
are described in the following table:
| Value | Description / Effect |
|---|---|
0 | Use the lowest value set, if any, for this parameter among all data nodes and API nodes in the cluster; if it is not set on any data or API node, use the default value. |
240 | Original hash map size, used by default in all MySQL Cluster releases prior to MySQL Cluster NDB 7.2.7. |
3840 | Larger hash map size as used by default in MySQL Cluster NDB 7.2.7 and later |
The primary intended use for this parameter is to facilitate
upgrades and especially downgrades between MySQL Cluster NDB
7.2.7 and later MySQL Cluster versions, in which the larger hash
map size (3840) is the default, and earlier releases (in which
the default was 240), due to the fact that this change is not
otherwise backward compatible (Bug #14800539). By setting this
parameter to 240 prior to performing an upgrade from an older
version where this value is in use, you can cause the cluster to
continue using the smaller size for table hash maps, in which
case the tables remain compatible with earlier versions
following the upgrade. DefaultHashMapSize can
be set for individual data nodes, API nodes, or both, but
setting it once only, in the [ndbd default]
section of the config.ini file, is the
recommended practice.
After increasing this parameter, to have existing tables to take
advantage of the new size, you can run
ALTER
TABLE ... REORGANIZE PARTITION on them, after which
they can use the larger hash map size. This is in addition to
performing a rolling restart, which makes the larger hash maps
available to new tables, but does not enable existing tables to
use them.
Decreasing this parameter online after any tables have been
created or modified with DefaultHashMapSize
equal to 3840 is not currently supported.
Logging and checkpointing.
The following [ndbd] parameters control log
and checkpoint behavior.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 16 3 - 4294967039 (0xFFFFFEFF) IN This parameter sets the number of REDO log files for the node, and thus the amount of space allocated to REDO logging. Because the REDO log files are organized in a ring, it is extremely important that the first and last log files in the set (sometimes referred to as the “head” and “tail” log files, respectively) do not meet. When these approach one another too closely, the node begins aborting all transactions encompassing updates due to a lack of room for new log records.
A
REDOlog record is not removed until the required number of local checkpoints has been completed since that log record was inserted. (In MySQL Cluster NDB 7.2, only 2 local checkpoints are necessary). Checkpointing frequency is determined by its own set of configuration parameters discussed elsewhere in this chapter.The default parameter value is 16, which by default means 16 sets of 4 16MB files for a total of 1024MB. The size of the individual log files is configurable using the
FragmentLogFileSizeparameter. In scenarios requiring a great many updates, the value forNoOfFragmentLogFilesmay need to be set as high as 300 or even higher to provide sufficient space for REDO logs.If the checkpointing is slow and there are so many writes to the database that the log files are full and the log tail cannot be cut without jeopardizing recovery, all updating transactions are aborted with internal error code 410 (
Out of log file space temporarily). This condition prevails until a checkpoint has completed and the log tail can be moved forward.ImportantThis parameter cannot be changed “on the fly”; you must restart the node using
--initial. If you wish to change this value for all data nodes in a running cluster, you can do so using a rolling node restart (using--initialwhen starting each data node). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 16M 4M - 1G IN Setting this parameter enables you to control directly the size of redo log files. This can be useful in situations when MySQL Cluster is operating under a high load and it is unable to close fragment log files quickly enough before attempting to open new ones (only 2 fragment log files can be open at one time); increasing the size of the fragment log files gives the cluster more time before having to open each new fragment log file. The default value for this parameter is 16M.
For more information about fragment log files, see the description for
NoOfFragmentLogFiles. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 [see values] SPARSE SPARSE, FULL IN By default, fragment log files are created sparsely when performing an initial start of a data node—that is, depending on the operating system and file system in use, not all bytes are necessarily written to disk. However, it is possible to override this behavior and force all bytes to be written, regardless of the platform and file system type being used, by means of this parameter.
InitFragmentLogFilestakes either of two values:SPARSE. Fragment log files are created sparsely. This is the default value.FULL. Force all bytes of the fragment log file to be written to disk.
Depending on your operating system and file system, setting
InitFragmentLogFiles=FULLmay help eliminate I/O errors on writes to the REDO log. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 20 - 4294967039 (0xFFFFFEFF) N This parameter sets a ceiling on how many internal threads to allocate for open files. Any situation requiring a change in this parameter should be reported as a bug.
The default value is 0. However, the minimum value to which this parameter can be set is 20.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 files 27 20 - 4294967039 (0xFFFFFEFF) N This parameter sets the initial number of internal threads to allocate for open files.
The default value is 27.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 25 0 - 4294967039 (0xFFFFFEFF) N This parameter sets the maximum number of trace files that are kept before overwriting old ones. Trace files are generated when, for whatever reason, the node crashes.
The default is 25 trace files.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 seconds 0 0 - 600 N In parallel data node recovery, only table data is actually copied and synchronized in parallel; synchronization of metadata such as dictionary and checkpoint information is done in a serial fashion. In addition, recovery of dictionary and checkpoint information cannot be executed in parallel with performing of local checkpoints. This means that, when starting or restarting many data nodes concurrently, data nodes may be forced to wait while a local checkpoint is performed, which can result in longer node recovery times.
It is possible to force a delay in the local checkpoint to permit more (and possibly all) data nodes to complete metadata synchronization; once each data node's metadata synchronization is complete, all of the data nodes can recover table data in parallel, even while the local checkpoint is being executed. To force such a delay, set
MaxLCPStartDelay, which determines the number of seconds the cluster can wait to begin a local checkpoint while data nodes continue to synchronize metadata. This parameter should be set in the[ndbd default]section of theconfig.inifile, so that it is the same for all data nodes. The maximum value is 600; the default is 0. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.14 second 60 0 - 4294967039 (0xFFFFFEFF) N A local checkpoint fragment scan watchdog checks periodically for no progress in each fragment scan performed as part of a local checkpoint, and shuts down the node if there is no progress after a given amount of time has elapsed. Prior to MySQL Cluster NDB 7.2.14, this interval is always 60 seconds (Bug #16630410). In MySQL Cluster NDB 7.2.14 and later, this interval can be set using the
LcpScanProgressTimeoutdata node configuration parameter, which sets the maximum time for which the local checkpoint can be stalled before the LCP fragment scan watchdog shuts down the node.The default value is 60 seconds (providing compatibility with previous releases). Setting this parameter to 0 disables the LCP fragment scan watchdog altogether.
Metadata objects.
The next set of [ndbd] parameters defines
pool sizes for metadata objects, used to define the maximum
number of attributes, tables, indexes, and trigger objects
used by indexes, events, and replication between clusters.
Note that these act merely as “suggestions” to
the cluster, and any that are not specified revert to the
default values shown.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 1000 32 - 4294967039 (0xFFFFFEFF) N This parameter sets a suggested maximum number of attributes that can be defined in the cluster; like
MaxNoOfTables, it is not intended to function as a hard upper limit.(In older MySQL Cluster releases, this parameter was sometimes treated as a hard limit for certain operations. This caused problems with MySQL Cluster Replication, when it was possible to create more tables than could be replicated, and sometimes led to confusion when it was possible [or not possible, depending on the circumstances] to create more than
MaxNoOfAttributesattributes.)The default value is 1000, with the minimum possible value being 32. The maximum is 4294967039. Each attribute consumes around 200 bytes of storage per node due to the fact that all metadata is fully replicated on the servers.
When setting
MaxNoOfAttributes, it is important to prepare in advance for anyALTER TABLEstatements that you might want to perform in the future. This is due to the fact, during the execution ofALTER TABLEon a Cluster table, 3 times the number of attributes as in the original table are used, and a good practice is to permit double this amount. For example, if the MySQL Cluster table having the greatest number of attributes (greatest_number_of_attributes) has 100 attributes, a good starting point for the value ofMaxNoOfAttributeswould be6 *.greatest_number_of_attributes= 600You should also estimate the average number of attributes per table and multiply this by
MaxNoOfTables. If this value is larger than the value obtained in the previous paragraph, you should use the larger value instead.Assuming that you can create all desired tables without any problems, you should also verify that this number is sufficient by trying an actual
ALTER TABLEafter configuring the parameter. If this is not successful, increaseMaxNoOfAttributesby another multiple ofMaxNoOfTablesand test it again. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 128 8 - 20320 N A table object is allocated for each table and for each unique hash index in the cluster. This parameter sets a suggested maximum number of table objects for the cluster as a whole; like
MaxNoOfAttributes, it is not intended to function as a hard upper limit.(In older MySQL Cluster releases, this parameter was sometimes treated as a hard limit for certain operations. This caused problems with MySQL Cluster Replication, when it was possible to create more tables than could be replicated, and sometimes led to confusion when it was possible [or not possible, depending on the circumstances] to create more than
MaxNoOfTablestables.)For each attribute that has a
BLOBdata type an extra table is used to store most of theBLOBdata. These tables also must be taken into account when defining the total number of tables.The default value of this parameter is 128. The minimum is 8 and the maximum is 20320. Each table object consumes approximately 20KB per node.
NoteThe sum of
MaxNoOfTables,MaxNoOfOrderedIndexes, andMaxNoOfUniqueHashIndexesmust not exceed232 − 2(4294967294). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 128 0 - 4294967039 (0xFFFFFEFF) N For each ordered index in the cluster, an object is allocated describing what is being indexed and its storage segments. By default, each index so defined also defines an ordered index. Each unique index and primary key has both an ordered index and a hash index.
MaxNoOfOrderedIndexessets the total number of ordered indexes that can be in use in the system at any one time.The default value of this parameter is 128. Each index object consumes approximately 10KB of data per node.
NoteThe sum of
MaxNoOfTables,MaxNoOfOrderedIndexes, andMaxNoOfUniqueHashIndexesmust not exceed232 − 2(4294967294). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 64 0 - 4294967039 (0xFFFFFEFF) N For each unique index that is not a primary key, a special table is allocated that maps the unique key to the primary key of the indexed table. By default, an ordered index is also defined for each unique index. To prevent this, you must specify the
USING HASHoption when defining the unique index.The default value is 64. Each index consumes approximately 15KB per node.
NoteThe sum of
MaxNoOfTables,MaxNoOfOrderedIndexes, andMaxNoOfUniqueHashIndexesmust not exceed232 − 2(4294967294). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 768 0 - 4294967039 (0xFFFFFEFF) N Internal update, insert, and delete triggers are allocated for each unique hash index. (This means that three triggers are created for each unique hash index.) However, an ordered index requires only a single trigger object. Backups also use three trigger objects for each normal table in the cluster.
Replication between clusters also makes use of internal triggers.
This parameter sets the maximum number of trigger objects in the cluster.
The default value is 768.
This parameter is deprecated and subject to removal in a future version of MySQL Cluster. You should use
MaxNoOfOrderedIndexesandMaxNoOfUniqueHashIndexesinstead.This parameter is used only by unique hash indexes. There needs to be one record in this pool for each unique hash index defined in the cluster.
The default value of this parameter is 128.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 0 - 4294967039 (0xFFFFFEFF) N Each
NDBtable in a MySQL Cluster requires a subscription in the NDB kernel. For some NDB API applications, it may be necessary or desirable to change this parameter. However, for normal usage with MySQL servers acting as SQL nodes, there is not any need to do so.The default value for
MaxNoOfSubscriptionsis 0, which is treated as equal toMaxNoOfTables. Each subscription consumes 108 bytes. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 0 - 4294967039 (0xFFFFFEFF) N This parameter is of interest only when using MySQL Cluster Replication. The default value is 0, which is treated as
2 * MaxNoOfTables; that is, there is one subscription perNDBtable for each of two MySQL servers (one acting as the replication master and the other as the slave). Each subscriber uses 16 bytes of memory.When using circular replication, multi-master replication, and other replication setups involving more than 2 MySQL servers, you should increase this parameter to the number of mysqld processes included in replication (this is often, but not always, the same as the number of clusters). For example, if you have a circular replication setup using three MySQL Clusters, with one mysqld attached to each cluster, and each of these mysqld processes acts as a master and as a slave, you should set
MaxNoOfSubscribersequal to3 * MaxNoOfTables.For more information, see Section 18.6, “MySQL Cluster Replication”.
MaxNoOfConcurrentSubOperationsEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 256 0 - 4294967039 (0xFFFFFEFF) N This parameter sets a ceiling on the number of operations that can be performed by all API nodes in the cluster at one time. The default value (256) is sufficient for normal operations, and might need to be adjusted only in scenarios where there are a great many API nodes each performing a high volume of operations concurrently.
Boolean parameters.
The behavior of data nodes is also affected by a set of
[ndbd] parameters taking on boolean values.
These parameters can each be specified as
TRUE by setting them equal to
1 or Y, and as
FALSE by setting them equal to
0 or N.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric 1 0 - 1 N Allocate memory for this data node after a connection to the management server has been established. Enabled by default.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric 0 0 - 2 N For a number of operating systems, including Solaris and Linux, it is possible to lock a process into memory and so avoid any swapping to disk. This can be used to help guarantee the cluster's real-time characteristics.
This parameter takes one of the integer values
0,1, or2, which act as shown in the following list:0: Disables locking. This is the default value.1: Performs the lock after allocating memory for the process.2: Performs the lock before memory for the process is allocated.
If the operating system is not configured to permit unprivileged users to lock pages, then the data node process making use of this parameter may have to be run as system root. (
LockPagesInMainMemoryuses themlockallfunction. From Linux kernel 2.6.9, unprivileged users can lock memory as limited bymax locked memory. For more information, see ulimit -l and http://linux.die.net/man/2/mlock).NoteIn older MySQL Cluster releases, this parameter was a Boolean.
0orfalsewas the default setting, and disabled locking.1ortrueenabled locking of the process after its memory was allocated. In MySQL Cluster NDB 7.2, usingtrueorfalseas the value of this parameter causes an error.ImportantBeginning with
glibc2.10,glibcuses per-thread arenas to reduce lock contention on a shared pool, which consumes real memory. In general, a data node process does not need per-thread arenas, since it does not perform any memory allocation after startup. (This difference in allocators does not appear to affect performance significantly.)The
glibcbehavior is intended to be configurable via theMALLOC_ARENA_MAXenvironment variable, but a bug in this mechanism prior toglibc2.16 meant that this variable could not be set to less than 8, so that the wasted memory could not be reclaimed. (Bug #15907219; see also http://sourceware.org/bugzilla/show_bug.cgi?id=13137 for more information concerning this issue.)One possible workaround for this problem is to use the
LD_PRELOADenvironment variable to preload ajemallocmemory allocation library to take the place of that supplied withglibc. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean 1 0, 1 N This parameter specifies whether a data node process should exit or perform an automatic restart when an error condition is encountered.
This parameter's default value is
1; this means that, by default, an error causes the data node process to halt.Users of MySQL Cluster Manager should note that, when
StopOnErrorequals 1, this prevents the MySQL Cluster Manager agent from restarting any data nodes after it has performed its own restart and recovery. See Starting and Stopping the Agent on Linux, for more information. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 boolean true true, false S When this parameter is enabled, it forces a data node to shut down whenever it encounters a corrupted tuple. In MySQL Cluster NDB 7.2.1 and later, it is enabled by default. This is a change from MySQL Cluster NDB 7.0 and MySQL Cluster NDB 7.1, where it was disabled by default.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 true|false (1|0) false true, false IS It is possible to specify MySQL Cluster tables as diskless, meaning that tables are not checkpointed to disk and that no logging occurs. Such tables exist only in main memory. A consequence of using diskless tables is that neither the tables nor the records in those tables survive a crash. However, when operating in diskless mode, it is possible to run ndbd on a diskless computer.
ImportantThis feature causes the entire cluster to operate in diskless mode.
When this feature is enabled, Cluster online backup is disabled. In addition, a partial start of the cluster is not possible.
Disklessis disabled by default. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N Enabling this parameter causes
NDBto attempt usingO_DIRECTwrites for LCP, backups, and redo logs, often lowering kswapd and CPU usage. When using MySQL Cluster on Linux, enableODirectif you are using a 2.6 or later kernel.ODirectis disabled by default. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 error code 2 0 - 4 N This feature is accessible only when building the debug version where it is possible to insert errors in the execution of individual blocks of code as part of testing.
This feature is disabled by default.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N Setting this parameter to
1causes backup files to be compressed. The compression used is equivalent to gzip --fast, and can save 50% or more of the space required on the data node to store uncompressed backup files. Compressed backups can be enabled for individual data nodes, or for all data nodes (by setting this parameter in the[ndbd default]section of theconfig.inifile).ImportantYou cannot restore a compressed backup to a cluster running a MySQL version that does not support this feature.
The default value is
0(disabled). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N Setting this parameter to
1causes local checkpoint files to be compressed. The compression used is equivalent to gzip --fast, and can save 50% or more of the space required on the data node to store uncompressed checkpoint files. Compressed LCPs can be enabled for individual data nodes, or for all data nodes (by setting this parameter in the[ndbd default]section of theconfig.inifile).ImportantYou cannot restore a compressed local checkpoint to a cluster running a MySQL version that does not support this feature.
The default value is
0(disabled).
Controlling Timeouts, Intervals, and Disk Paging
There are a number of [ndbd] parameters
specifying timeouts and intervals between various actions in
Cluster data nodes. Most of the timeout values are specified in
milliseconds. Any exceptions to this are mentioned where
applicable.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 6000 70 - 4294967039 (0xFFFFFEFF) N To prevent the main thread from getting stuck in an endless loop at some point, a “watchdog” thread checks the main thread. This parameter specifies the number of milliseconds between checks. If the process remains in the same state after three checks, the watchdog thread terminates it.
This parameter can easily be changed for purposes of experimentation or to adapt to local conditions. It can be specified on a per-node basis although there seems to be little reason for doing so.
The default timeout is 6000 milliseconds (6 seconds).
TimeBetweenWatchDogCheckInitialEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 6000 70 - 4294967039 (0xFFFFFEFF) N This is similar to the
TimeBetweenWatchDogCheckparameter, except thatTimeBetweenWatchDogCheckInitialcontrols the amount of time that passes between execution checks inside a database node in the early start phases during which memory is allocated.The default timeout is 6000 milliseconds (6 seconds).
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 30000 0 - 4294967039 (0xFFFFFEFF) N This parameter specifies how long the Cluster waits for all data nodes to come up before the cluster initialization routine is invoked. This timeout is used to avoid a partial Cluster startup whenever possible.
This parameter is overridden when performing an initial start or initial restart of the cluster.
The default value is 30000 milliseconds (30 seconds). 0 disables the timeout, in which case the cluster may start only if all nodes are available.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 60000 0 - 4294967039 (0xFFFFFEFF) N If the cluster is ready to start after waiting for
StartPartialTimeoutmilliseconds but is still possibly in a partitioned state, the cluster waits until this timeout has also passed. IfStartPartitionedTimeoutis set to 0, the cluster waits indefinitely.This parameter is overridden when performing an initial start or initial restart of the cluster.
The default timeout is 60000 milliseconds (60 seconds).
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 0 0 - 4294967039 (0xFFFFFEFF) N If a data node has not completed its startup sequence within the time specified by this parameter, the node startup fails. Setting this parameter to 0 (the default value) means that no data node timeout is applied.
For nonzero values, this parameter is measured in milliseconds. For data nodes containing extremely large amounts of data, this parameter should be increased. For example, in the case of a data node containing several gigabytes of data, a period as long as 10−15 minutes (that is, 600000 to 1000000 milliseconds) might be required to perform a node restart.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 15000 0 - 4294967039 (0xFFFFFEFF) N When a data node is configured with
Nodegroup = 65536, is regarded as not being assigned to any node group. When that is done, the cluster waitsStartNoNodegroupTimeoutmilliseconds, then treats such nodes as though they had been added to the list passed to the--nowait-nodesoption, and starts. The default value is15000(that is, the management server waits 15 seconds). Setting this parameter equal to0means that the cluster waits indefinitely.StartNoNodegroupTimeoutmust be the same for all data nodes in the cluster; for this reason, you should always set it in the[ndbd default]section of theconfig.inifile, rather than for individual data nodes.See Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”, for more information.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 5000 10 - 4294967039 (0xFFFFFEFF) N One of the primary methods of discovering failed nodes is by the use of heartbeats. This parameter states how often heartbeat signals are sent and how often to expect to receive them. After missing three heartbeat intervals in a row, the node is declared dead. Thus, the maximum time for discovering a failure through the heartbeat mechanism is four times the heartbeat interval.
In MySQL Cluster NDB 7.2.0 and later, the default heartbeat interval is 5000 milliseconds (5 seconds). (Previously, the default was 1500 milliseconds [1.5 seconds]). This parameter must not be changed drastically and should not vary widely between nodes. If one node uses 5000 milliseconds and the node watching it uses 1000 milliseconds, obviously the node will be declared dead very quickly. This parameter can be changed during an online software upgrade, but only in small increments.
See also Network communication and latency.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 1500 100 - 4294967039 (0xFFFFFEFF) N Each data node sends heartbeat signals to each MySQL server (SQL node) to ensure that it remains in contact. If a MySQL server fails to send a heartbeat in time it is declared “dead,” in which case all ongoing transactions are completed and all resources released. The SQL node cannot reconnect until all activities initiated by the previous MySQL instance have been completed. The three-heartbeat criteria for this determination are the same as described for
HeartbeatIntervalDbDb.The default interval is 1500 milliseconds (1.5 seconds). This interval can vary between individual data nodes because each data node watches the MySQL servers connected to it, independently of all other data nodes.
For more information, see Network communication and latency.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric 0 0 - 65535 S Data nodes send heartbeats to one another in a circular fashion whereby each data node monitors the previous one. If a heartbeat is not detected by a given data node, this node declares the previous data node in the circle “dead” (that is, no longer accessible by the cluster). The determination that a data node is dead is done globally; in other words; once a data node is declared dead, it is regarded as such by all nodes in the cluster.
It is possible for heartbeats between data nodes residing on different hosts to be too slow compared to heartbeats between other pairs of nodes (for example, due to a very low heartbeat interval or temporary connection problem), such that a data node is declared dead, even though the node can still function as part of the cluster. .
In this type of situation, it may be that the order in which heartbeats are transmitted between data nodes makes a difference as to whether or not a particular data node is declared dead. If this declaration occurs unnecessarily, this can in turn lead to the unnecessary loss of a node group and as thus to a failure of the cluster.
Consider a setup where there are 4 data nodes A, B, C, and D running on 2 host computers
host1andhost2, and that these data nodes make up 2 node groups, as shown in the following table:Node Group
Nodes Running on
host1Nodes Running on host2Node Group 0:
Node A
Node B Node Group 1:
Node C
Node D Suppose the heartbeats are transmitted in the order A->B->C->D->A. In this case, the loss of the heartbeat between the hosts causes node B to declare node A dead and node C to declare node B dead. This results in loss of Node Group 0, and so the cluster fails. On the other hand, if the order of transmission is A->B->D->C->A (and all other conditions remain as previously stated), the loss of the heartbeat causes nodes A and D to be declared dead; in this case, each node group has one surviving node, and the cluster survives.
The
HeartbeatOrderconfiguration parameter makes the order of heartbeat transmission user-configurable. The default value forHeartbeatOrderis zero; allowing the default value to be used on all data nodes causes the order of heartbeat transmission to be determined byNDB. If this parameter is used, it must be set to a nonzero value (maximum 65535) for every data node in the cluster, and this value must be unique for each data node; this causes the heartbeat transmission to proceed from data node to data node in the order of theirHeartbeatOrdervalues from lowest to highest (and then directly from the data node having the highestHeartbeatOrderto the data node having the lowest value, to complete the circle). The values need not be consecutive; for example, to force the heartbeat transmission order A->B->D->C->A in the scenario outlined previously, you could set theHeartbeatOrdervalues as shown here:Node HeartbeatOrderA 10 B 20 C 30 D 25 To use this parameter to change the heartbeat transmission order in a running MySQL Cluster, you must first set
HeartbeatOrderfor each data node in the cluster in the global configuration (config.ini) file (or files). To cause the change to take effect, you must perform either of the following:A complete shutdown and restart of the entire cluster.
2 rolling restarts of the cluster in succession. All nodes must be restarted in the same order in both rolling restarts.
You can use
DUMP 908to observe the effect of this parameter in the data node logs. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 1500 0 - 4294967039 (0xFFFFFEFF) N NDB 7.2.1 milliseconds 0 0 - 4294967039 (0xFFFFFEFF) N This parameter enables connection checking between data nodes. A data node that fails to respond within an interval of
ConnectCheckIntervalDelaymilliseconds is considered suspect, and is considered dead after two such intervals.The default value for this parameter is 0; this is a change from MySQL Cluster NDB 7.1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 number of 4-byte words, as a base-2 logarithm 20 0 - 31 N This parameter is an exception in that it does not specify a time to wait before starting a new local checkpoint; rather, it is used to ensure that local checkpoints are not performed in a cluster where relatively few updates are taking place. In most clusters with high update rates, it is likely that a new local checkpoint is started immediately after the previous one has been completed.
The size of all write operations executed since the start of the previous local checkpoints is added. This parameter is also exceptional in that it is specified as the base-2 logarithm of the number of 4-byte words, so that the default value 20 means 4MB (4 × 220) of write operations, 21 would mean 8MB, and so on up to a maximum value of 31, which equates to 8GB of write operations.
All the write operations in the cluster are added together. Setting
TimeBetweenLocalCheckpointsto 6 or less means that local checkpoints will be executed continuously without pause, independent of the cluster's workload. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 2000 20 - 32000 N When a transaction is committed, it is committed in main memory in all nodes on which the data is mirrored. However, transaction log records are not flushed to disk as part of the commit. The reasoning behind this behavior is that having the transaction safely committed on at least two autonomous host machines should meet reasonable standards for durability.
It is also important to ensure that even the worst of cases—a complete crash of the cluster—is handled properly. To guarantee that this happens, all transactions taking place within a given interval are put into a global checkpoint, which can be thought of as a set of committed transactions that has been flushed to disk. In other words, as part of the commit process, a transaction is placed in a global checkpoint group. Later, this group's log records are flushed to disk, and then the entire group of transactions is safely committed to disk on all computers in the cluster.
This parameter defines the interval between global checkpoints. The default is 2000 milliseconds.
TimeBetweenGlobalCheckpointsTimeoutEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.20 milliseconds 120000 10 - 4294967039 (0xFFFFFEFF) N This parameter defines the minimum timeout between global checkpoints. The default is 120000 milliseconds.
This parameter was added in MySQL Cluster NDB 7.2.20. (Bug #20069617)
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 100 0 - 32000 N This parameter defines the interval between synchronization epochs for MySQL Cluster Replication. The default value is 100 milliseconds.
TimeBetweenEpochsis part of the implementation of “micro-GCPs”, which can be used to improve the performance of MySQL Cluster Replication. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 0 0 - 256000 N This parameter defines a timeout for synchronization epochs for MySQL Cluster Replication. If a node fails to participate in a global checkpoint within the time determined by this parameter, the node is shut down. In MySQL Cluster NDB 7.2.0 and later, the default value is 0; in other words, the timeout is disabled. This represents a change from previous versions of MySQL Cluster, in which the default value was 4000 milliseconds (4 seconds).
TimeBetweenEpochsTimeoutis part of the implementation of “micro-GCPs”, which can be used to improve the performance of MySQL Cluster Replication.The current value of this parameter and a warning are written to the cluster log whenever a GCP save takes longer than 1 minute or a GCP save takes longer than 10 seconds.
Setting this parameter to zero has the effect of disabling GCP stops caused by save timeouts, commit timeouts, or both. The maximum possible value for this parameter is 256000 milliseconds.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 epochs 100 0 - 100000 N The number of unprocessed epochs by which a subscribing node can lag behind. Exceeding this number causes a lagging subscriber to be disconnected.
The default value of 100 is sufficient for most normal operations. If a subscribing node does lag enough to cause disconnections, it is usually due to network or scheduling issues with regard to processes or threads. (In rare circumstances, the problem may be due to a bug in the
NDBclient.) It may be desirable to set the value lower than the default when epochs are longer.Disconnection prevents client issues from affecting the data node service, running out of memory to buffer data, and eventually shutting down. Instead, only the client is affected as a result of the disconnect (by, for example gap events in the binary log), forcing the client to reconnect or restart the process.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.13 bytes 26214400 26214400 (0x01900000) - 4294967039 (0xFFFFFEFF) N The total number of bytes allocated for buffering epochs by this node.
This parameter was introduced in MySQL Cluster NDB 7.2.13. (Bug #16203623)
TimeBetweenInactiveTransactionAbortCheckEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 1000 1000 - 4294967039 (0xFFFFFEFF) N Timeout handling is performed by checking a timer on each transaction once for every interval specified by this parameter. Thus, if this parameter is set to 1000 milliseconds, every transaction will be checked for timing out once per second.
The default value is 1000 milliseconds (1 second).
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds [see text] 0 - 4294967039 (0xFFFFFEFF) N This parameter states the maximum time that is permitted to lapse between operations in the same transaction before the transaction is aborted.
The default for this parameter is
4G(also the maximum). For a real-time database that needs to ensure that no transaction keeps locks for too long, this parameter should be set to a relatively small value. The unit is milliseconds. TransactionDeadlockDetectionTimeoutEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 1200 50 - 4294967039 (0xFFFFFEFF) N When a node executes a query involving a transaction, the node waits for the other nodes in the cluster to respond before continuing. A failure to respond can occur for any of the following reasons:
The node is “dead”
The operation has entered a lock queue
The node requested to perform the action could be heavily overloaded.
This timeout parameter states how long the transaction coordinator waits for query execution by another node before aborting the transaction, and is important for both node failure handling and deadlock detection.
The default timeout value is 1200 milliseconds (1.2 seconds).
The minimum for this parameter is 50 milliseconds.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 4M 32K - 4294967039 (0xFFFFFEFF) N This is the maximum number of bytes to store before flushing data to a local checkpoint file. This is done to prevent write buffering, which can impede performance significantly. This parameter is not intended to take the place of
TimeBetweenLocalCheckpoints.NoteWhen
ODirectis enabled, it is not necessary to setDiskSyncSize; in fact, in such cases its value is simply ignored.The default value is 4M (4 megabytes).
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 10M 1M - 4294967039 (0xFFFFFEFF) N The amount of data,in bytes per second, that is sent to disk during a local checkpoint. This allocation is shared by DML operations and backups (but not backup logging), which means that backups started during times of intensive DML may be impaired by flooding of the redo log buffer and may fail altogether if the contention is sufficiently severe.
The default value is 10M (10 megabytes per second).
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 100M 1M - 4294967039 (0xFFFFFEFF) N The amount of data,in bytes per second, that is sent to disk during a local checkpoint as part of a restart operation.
The default value is 100M (100 megabytes per second).
NoOfDiskPagesToDiskAfterRestartTUPThis parameter is deprecated and subject to removal in a future version of MySQL Cluster. Use
DiskCheckpointSpeedInRestartandDiskSyncSizeinstead.NoOfDiskPagesToDiskAfterRestartACCThis parameter is deprecated and subject to removal in a future version of MySQL Cluster. Use
DiskCheckpointSpeedInRestartandDiskSyncSizeinstead.NoOfDiskPagesToDiskDuringRestartTUP(DEPRECATED)This parameter is deprecated and subject to removal in a future version of MySQL Cluster. Use
DiskCheckpointSpeedInRestartandDiskSyncSizeinstead.NoOfDiskPagesToDiskDuringRestartACC(DEPRECATED)This parameter is deprecated and subject to removal in a future version of MySQL Cluster. Use
DiskCheckpointSpeedInRestartandDiskSyncSizeinstead.-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 7500 10 - 4294967039 (0xFFFFFEFF) N This parameter specifies how long data nodes wait for a response from the arbitrator to an arbitration message. If this is exceeded, the network is assumed to have split.
In MySQL Cluster NDB 7.2.0 and later, the default value is 7500 milliseconds (7.5 seconds). Previously, this was 3000 milliseconds (3 seconds).
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 enumeration Default Default, Disabled, WaitExternal N The
Arbitrationparameter enables a choice of arbitration schemes, corresponding to one of 3 possible values for this parameter:Default. This enables arbitration to proceed normally, as determined by the
ArbitrationRanksettings for the management and API nodes. This is the default value.Disabled. Setting
Arbitration = Disabledin the[ndbd default]section of theconfig.inifile to accomplishes the same task as settingArbitrationRankto 0 on all management and API nodes. WhenArbitrationis set in this way, anyArbitrationRanksettings are ignored.WaitExternal. The
Arbitrationparameter also makes it possible to configure arbitration in such a way that the cluster waits until after the time determined byArbitrationTimeouthas passed for an external cluster manager application to perform arbitration instead of handling arbitration internally. This can be done by settingArbitration = WaitExternalin the[ndbd default]section of theconfig.inifile. For best results with theWaitExternalsetting, it is recommended thatArbitrationTimeoutbe 2 times as long as the interval required by the external cluster manager to perform arbitration.
ImportantThis parameter should be used only in the
[ndbd default]section of the cluster configuration file. The behavior of the cluster is unspecified whenArbitrationis set to different values for individual data nodes. RestartSubscriberConnectTimeoutEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.17 ms 12000 0 - 4294967039 (0xFFFFFEFF) S This parameter determines the time that a data node waits for subscribing API nodes to connect. Once this timeout expires, any “missing” API nodes are disconnected from the cluster. To disable this timeout, set
RestartSubscriberConnectTimeoutto 0.While this parameter is specified in milliseconds, the timeout itself is resolved to the next-greatest whole second.
RestartSubscriberConnectTimeoutwas added in MySQL Cluster NDB 7.2.17.
Buffering and logging.
Several [ndbd] configuration parameters
enable the advanced user to have more control over the
resources used by node processes and to adjust various buffer
sizes at need.
These buffers are used as front ends to the file system when
writing log records to disk. If the node is running in diskless
mode, these parameters can be set to their minimum values
without penalty due to the fact that disk writes are
“faked” by the NDB
storage engine's file system abstraction layer.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 2M 1M - 4294967039 (0xFFFFFEFF) N The UNDO index buffer, whose size is set by this parameter, is used during local checkpoints. The
NDBstorage engine uses a recovery scheme based on checkpoint consistency in conjunction with an operational REDO log. To produce a consistent checkpoint without blocking the entire system for writes, UNDO logging is done while performing the local checkpoint. UNDO logging is activated on a single table fragment at a time. This optimization is possible because tables are stored entirely in main memory.The UNDO index buffer is used for the updates on the primary key hash index. Inserts and deletes rearrange the hash index; the NDB storage engine writes UNDO log records that map all physical changes to an index page so that they can be undone at system restart. It also logs all active insert operations for each fragment at the start of a local checkpoint.
Reads and updates set lock bits and update a header in the hash index entry. These changes are handled by the page-writing algorithm to ensure that these operations need no UNDO logging.
This buffer is 2MB by default. The minimum value is 1MB, which is sufficient for most applications. For applications doing extremely large or numerous inserts and deletes together with large transactions and large primary keys, it may be necessary to increase the size of this buffer. If this buffer is too small, the NDB storage engine issues internal error code 677 (
Index UNDO buffers overloaded).ImportantIt is not safe to decrease the value of this parameter during a rolling restart.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 16M 1M - 4294967039 (0xFFFFFEFF) N This parameter sets the size of the UNDO data buffer, which performs a function similar to that of the UNDO index buffer, except the UNDO data buffer is used with regard to data memory rather than index memory. This buffer is used during the local checkpoint phase of a fragment for inserts, deletes, and updates.
Because UNDO log entries tend to grow larger as more operations are logged, this buffer is also larger than its index memory counterpart, with a default value of 16MB.
This amount of memory may be unnecessarily large for some applications. In such cases, it is possible to decrease this size to a minimum of 1MB.
It is rarely necessary to increase the size of this buffer. If there is such a need, it is a good idea to check whether the disks can actually handle the load caused by database update activity. A lack of sufficient disk space cannot be overcome by increasing the size of this buffer.
If this buffer is too small and gets congested, the NDB storage engine issues internal error code 891 (Data UNDO buffers overloaded).
ImportantIt is not safe to decrease the value of this parameter during a rolling restart.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 32M 1M - 4294967039 (0xFFFFFEFF) N All update activities also need to be logged. The REDO log makes it possible to replay these updates whenever the system is restarted. The NDB recovery algorithm uses a “fuzzy” checkpoint of the data together with the UNDO log, and then applies the REDO log to play back all changes up to the restoration point.
RedoBuffersets the size of the buffer in which the REDO log is written. The default value is 32MB; the minimum value is 1MB.If this buffer is too small, the
NDBstorage engine issues error code 1221 (REDO log buffers overloaded). For this reason, you should exercise care if you attempt to decrease the value ofRedoBufferas part of an online change in the cluster's configuration.ndbmtd allocates a separate buffer for each LDM thread (see
ThreadConfig). For example, with 4 LDM threads, an ndbmtd data node actually has 4 buffers and allocatesRedoBufferbytes to each one, for a total of4 * RedoBufferbytes. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 8192 0 - 64K S Controls the size of the circular buffer used for NDB log events within data nodes.
Controlling log messages.
In managing the cluster, it is very important to be able to
control the number of log messages sent for various event
types to stdout. For each event category,
there are 16 possible event levels (numbered 0 through 15).
Setting event reporting for a given event category to level 15
means all event reports in that category are sent to
stdout; setting it to 0 means that there
will be no event reports made in that category.
By default, only the startup message is sent to
stdout, with the remaining event reporting
level defaults being set to 0. The reason for this is that these
messages are also sent to the management server's cluster log.
An analogous set of levels can be set for the management client to determine which event levels to record in the cluster log.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 1 0 - 15 N The reporting level for events generated during startup of the process.
The default level is 1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 0 0 - 15 N The reporting level for events generated as part of graceful shutdown of a node.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 0 0 - 15 N The reporting level for statistical events such as number of primary key reads, number of updates, number of inserts, information relating to buffer usage, and so on.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 log level 0 0 - 15 N The reporting level for events generated by local and global checkpoints.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 0 0 - 15 N The reporting level for events generated during node restart.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 0 0 - 15 N The reporting level for events generated by connections between cluster nodes.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 0 0 - 15 N The reporting level for events generated by errors and warnings by the cluster as a whole. These errors do not cause any node failure but are still considered worth reporting.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 levelr 0 0 - 15 N The reporting level for events generated by congestion. These errors do not cause node failure but are still considered worth reporting.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 0 0 - 15 N The reporting level for events generated for information about the general state of the cluster.
The default level is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 0 - 4294967039 (0xFFFFFEFF) N This parameter controls how often data node memory usage reports are recorded in the cluster log; it is an integer value representing the number of seconds between reports.
Each data node's data memory and index memory usage is logged as both a percentage and a number of 32 KB pages of the
DataMemoryandIndexMemory, respectively, set in theconfig.inifile. For example, ifDataMemoryis equal to 100 MB, and a given data node is using 50 MB for data memory storage, the corresponding line in the cluster log might look like this:2006-12-24 01:18:16 [MgmSrvr] INFO -- Node 2: Data usage is 50%(1280 32K pages of total 2560)
MemReportFrequencyis not a required parameter. If used, it can be set for all cluster data nodes in the[ndbd default]section ofconfig.ini, and can also be set or overridden for individual data nodes in the corresponding[ndbd]sections of the configuration file. The minimum value—which is also the default value—is 0, in which case memory reports are logged only when memory usage reaches certain percentages (80%, 90%, and 100%), as mentioned in the discussion of statistics events in Section 18.5.6.2, “MySQL Cluster Log Events”. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 seconds 0 0 - 4294967039 (0xFFFFFEFF) N When a data node is started with the
--initial, it initializes the redo log file during Start Phase 4 (see Section 18.5.1, “Summary of MySQL Cluster Start Phases”). When very large values are set forNoOfFragmentLogFiles,FragmentLogFileSize, or both, this initialization can take a long time.You can force reports on the progress of this process to be logged periodically, by means of theStartupStatusReportFrequencyconfiguration parameter. In this case, progress is reported in the cluster log, in terms of both the number of files and the amount of space that have been initialized, as shown here:2009-06-20 16:39:23 [MgmSrvr] INFO -- Node 1: Local redo log file initialization status: #Total files: 80, Completed: 60 #Total MBytes: 20480, Completed: 15557 2009-06-20 16:39:23 [MgmSrvr] INFO -- Node 2: Local redo log file initialization status: #Total files: 80, Completed: 60 #Total MBytes: 20480, Completed: 15570
These reports are logged each
StartupStatusReportFrequencyseconds during Start Phase 4. IfStartupStatusReportFrequencyis 0 (the default), then reports are written to the cluster log only when at the beginning and at the completion of the redo log file initialization process.
Debugging Parameters.
In MySQL Cluster NDB 7.2, it is possible to cause logging of
traces for events generated by creating and dropping tables
using DictTrace. This
parameter is useful only in debugging NDB kernel code.
DictTrace takes an
integer value; currently, 0 (default - no logging) and 1
(logging enabled) are the only supported values.
Backup parameters.
The [ndbd] parameters discussed in this
section define memory buffers set aside for execution of
online backups.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 16M 0 - 4294967039 (0xFFFFFEFF) N In creating a backup, there are two buffers used for sending data to the disk. The backup data buffer is used to fill in data recorded by scanning a node's tables. Once this buffer has been filled to the level specified as
BackupWriteSize, the pages are sent to disk. While flushing data to disk, the backup process can continue filling this buffer until it runs out of space. When this happens, the backup process pauses the scan and waits until some disk writes have completed freeing up memory so that scanning may continue.The default value for this parameter is 16MB.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 16M 0 - 4294967039 (0xFFFFFEFF) N The backup log buffer fulfills a role similar to that played by the backup data buffer, except that it is used for generating a log of all table writes made during execution of the backup. The same principles apply for writing these pages as with the backup data buffer, except that when there is no more space in the backup log buffer, the backup fails. For that reason, the size of the backup log buffer must be large enough to handle the load caused by write activities while the backup is being made. See Section 18.5.3.3, “Configuration for MySQL Cluster Backups”.
The default value for this parameter should be sufficient for most applications. In fact, it is more likely for a backup failure to be caused by insufficient disk write speed than it is for the backup log buffer to become full. If the disk subsystem is not configured for the write load caused by applications, the cluster is unlikely to be able to perform the desired operations.
It is preferable to configure cluster nodes in such a manner that the processor becomes the bottleneck rather than the disks or the network connections.
The default value for this parameter is 16MB.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 32M 0 - 4294967039 (0xFFFFFEFF) N This parameter is simply the sum of
BackupDataBufferSizeandBackupLogBufferSize.The default value of this parameter in MySQL Cluster NDB 7.2 is 16MB + 16MB = 32MB.
ImportantIf
BackupDataBufferSizeandBackupLogBufferSizetaken together exceed the default value forBackupMemory, then this parameter must be set explicitly in theconfig.inifile to their sum. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 seconds 0 0 - 4294967039 (0xFFFFFEFF) N This parameter controls how often backup status reports are issued in the management client during a backup, as well as how often such reports are written to the cluster log (provided cluster event logging is configured to permit it—see Logging and checkpointing).
BackupReportFrequencyrepresents the time in seconds between backup status reports.The default value is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 256K 2K - 4294967039 (0xFFFFFEFF) N This parameter specifies the default size of messages written to disk by the backup log and backup data buffers.
The default value for this parameter is 256KB.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 1M 2K - 4294967039 (0xFFFFFEFF) N NDB 7.2.1 bytes 1M 2K - 4294967039 (0xFFFFFEFF) N This parameter specifies the maximum size of messages written to disk by the backup log and backup data buffers.
The default value for this parameter is 1MB.
When specifying these parameters, the following relationships must hold true. Otherwise, the data node will be unable to start.
BackupDataBufferSize >= BackupWriteSize + 188KBBackupLogBufferSize >= BackupWriteSize + 16KBBackupMaxWriteSize >= BackupWriteSize
MySQL Cluster Realtime Performance Parameters
The [ndbd] parameters discussed in this
section are used in scheduling and locking of threads to
specific CPUs on multiprocessor data node hosts.
To make use of these parameters, the data node process must be run as system root.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 CPU ID 64K 0 - 64K N When used with ndbd, this parameter (now a string) specifies the ID of the CPU assigned to handle the
NDBCLUSTERexecution thread. When used with ndbmtd, the value of this parameter is a comma-separated list of CPU IDs assigned to handle execution threads. Each CPU ID in the list should be an integer in the range 0 to 65535 (inclusive).The number of IDs specified should match the number of execution threads determined by
MaxNoOfExecutionThreads. However, there is no guarantee that threads are assigned to CPUs in any given order when using this parameter; beginning with in MySQL Cluster NDB 7.2.5, you can obtain more finely-grained control of this type usingThreadConfig.LockExecuteThreadToCPUhas no default value. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 CPU ID [none] 0 - 64K N This parameter specifies the ID of the CPU assigned to handle
NDBCLUSTERmaintenance threads.The value of this parameter is an integer in the range 0 to 65535 (inclusive). In MySQL Cluster NDB 7.2, there is no default value.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N Setting this parameter to 1 enables real-time scheduling of data node threads.
Prior to MySQL Cluster NDB 7.2.14, this parameter did not work correctly with data nodes running ndbmtd. (Bug #16961971)
The default is 0 (scheduling disabled).
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 µs 50 0 - 11000 N This parameter specifies the time in microseconds for threads to be executed in the scheduler before being sent. Setting it to 0 minimizes the response time; to achieve higher throughput, you can increase the value at the expense of longer response times.
The default is 50 μsec, which our testing shows to increase throughput slightly in high-load cases without materially delaying requests.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 µs 0 0 - 500 N This parameter specifies the time in microseconds for threads to be executed in the scheduler before sleeping.
The default value is 0.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric 0 0 - 128 S This parameter determines the number of threads to create when rebuilding ordered indexes during a system or node start, as well as when running ndb_restore
--rebuild-indexes. It is supported only when there is more than one fragment for the table per data node (for example, when theMAX_ROWSoption has been used withCREATE TABLE).Setting this parameter to 0 (the default) disables multi-threaded building of ordered indexes.
This parameter is supported when using ndbd or ndbmtd.
You can enable multi-threaded builds during data node initial restarts by setting the
TwoPassInitialNodeRestartCopydata node configuration parameter toTRUE. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N Multi-threaded building of ordered indexes can be enabled for initial restarts of data nodes by setting this configuration parameter to
TRUE, which enables two-pass copying of data during initial node restarts.You must also set
BuildIndexThreadsto a nonzero value. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean 1 ... N This parameter determines whether Non-Uniform Memory Access (NUMA) is controlled by the operating or by the data node process, whether the data node uses ndbd or ndbmtd. By default,
NDBattempts to use an interleaved NUMA memory allocation policy on any data node where the host operating system provides NUMA support.Setting
Numa = 0means that the datanode process does not itself attempt to set a policy for memory allocation, and permits this behavior to be determined by the operating system, which may be further guided by the separate numactl tool. That is,Numa = 0yields the system default behavior, which can be customised by numactl. For many Linux systems, the system default behavior is to allocate socket-local memory to any given process at allocation time. This can be problematic when using ndbmtd; this is because nbdmtd allocates all memory at startup, leading to an imbalance, giving different access speeds for different sockets, especially when locking pages in main memory.Setting
Numa = 1means that the data node process useslibnumato request interleaved memory allocation. (This can also be accomplished manually, on the operating system level, using numactl.) Using interleaved allocation in effect tells the data node process to ignore non-uniform memory access but does not attempt to take any advantage of fast local memory; instead, the data node process tries to avoid imbalances due to slow remote memory. If interleaved allocation is not desired, setNumato 0 so that the desired behavior can be determined on the operating system level.The
Numaconfiguration parameter is supported only on Linux systems wherelibnuma.sois available.
Multi-Threading Configuration Parameters (ndbmtd).
ndbmtd runs by default as a single-threaded
process and must be configured to use multiple threads, using
either of two methods, both of which require setting
configuration parameters in the
config.ini file. The first method is
simply to set an appropriate value for the
MaxNoOfExecutionThreads
configuration parameter. In MySQL Cluster NDB 7.2.3 and later,
a second method is also supported, whereby it is possible to
set up more complex rules for ndbmtd
multi-threading using
ThreadConfig. The
next few paragraphs provide information about these parameters
and their use with multi-threaded data nodes.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 integer 2 2 - 8 IS NDB 7.2.5 integer 2 2 - 36 IS Starting with MySQL Cluster NDB 7.2.5, this parameter directly controls the number of execution threads used by ndbmtd, up to a maximum of 36. Although this parameter is set in
[ndbd]or[ndbd default]sections of theconfig.inifile, it is exclusive to ndbmtd and does not apply to ndbd.Setting
MaxNoOfExecutionThreadssets the number of threads by type as determined in the following table:MaxNoOfExecutionThreadsValueLDM Threads TC Threads Send Threads Receive Threads 0 .. 3 1 1 0 1 4 .. 6 2 1 0 1 7 .. 8 4 1 0 1 9 4 2 0 1 10 4 2 1 1 11 4 3 1 1 12 4 3 1 2 13 4 3 2 2 14 4 4 2 2 15 4 5 2 2 16 8 3 1 2 17 8 4 1 2 18 8 4 2 2 19 8 5 2 2 20 8 5 2 3 21 8 5 3 3 22 8 6 3 3 23 8 7 3 3 24 12 5 2 3 25 12 6 2 3 26 12 6 3 3 27 12 7 3 3 28 12 7 3 4 29 12 8 3 4 30 12 8 4 4 31 12 9 4 4 32 16 8 3 3 33 16 8 3 4 34 16 8 4 4 35 16 9 4 4 36 16 10 4 4 The number of LDM threads must not exceed
NoOfFragmentLogParts. If this parameter's value is the default (4), this means that you must increase it as well, when settingMaxNoOfExecutionThreadsto 16 or greater; that is, you should setNoOfFragmentLogPartsto the corresponding number of LDM threads value shown for that value ofMaxNoOfExecutionThreadsin the preceding table.There is always one SUMA (replication) thread. There was no separate send thread in MySQL Cluster NDB 7.2.4 and earlier, as well as no means of changing the number of TC threads.
The thread types are described later in this section (see
ThreadConfig).Setting this parameter outside the permitted range of values causes the management server to abort on startup with the error Error line
number: Illegal valuevaluefor parameter MaxNoOfExecutionThreads.For
MaxNoOfExecutionThreads, a value of 0 or 1 is rounded up internally byNDBto 2, so that 2 is considered this parameter's default and minimum value.MaxNoOfExecutionThreadsis generally intended to be set equal to the number of CPU threads available, and to allocate a number of threads of each type suitable to typical workloads. It does not assign particular threads to specified CPUs. For cases where it is desirable to vary from the settings provided, or to bind threads to CPUs, you should useThreadConfiginstead, which allows you to allocate each thread directly to a desired type, CPU, or both.In MySQL Cluster NDB 7.2.5 and later, the multi-threaded data node process always spawns, at a minimum, the threads listed here:
1 local query handler (LDM) thread
1 transaction coordinator (TC) thread
1 receive thread
1 subscription manager (SUMA or replication) thread
Changing the number of LDM threads always requires a system restart, whether it is changed using this parameter or
ThreadConfig. If the cluster'sIndexMemoryusage is greater than 50%, changing this requires an initial restart of the cluster. (A maximum of 30-35%IndexMemoryusage is recommended in such cases.) Otherwise, resource usage and LDM thread allocation cannot be balanced between nodes, which can result in underutilized and overutilized LDM threads, and ultimately data node failures.In MySQL Cluster NDB 7.2.4 and earlier, there were only 4 thread types, with LDM threads being responsible for their own sends. In addition, it was not possible to cause ndbmtd to use more than 1 TC thread.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.5 numeric 4 4, 8, 12, 16 IN Set the number of log file groups for redo logs belonging to this ndbmtd. The value must be an even multiple of 4 between 4 and 16, inclusive.
Note that the number of LQH threads used by ndbmtd must not exceed
NoOfFragmentLogParts, and that this number may increase when increasingMaxNoOfExecutionThreads; see the description of this parameter for more information. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.3 string '' ... IS This parameter is used with ndbmtd to assign threads of different types to different CPUs. Its value is a string whose format has the following syntax:
ThreadConfig :=
entry[,entry[,...]]entry:=type={param[,param[,...]]}type:= ldm | main | recv | send | rep | ioparam:= count=number| cpubind=cpu_list| cpuset=cpu_list| spintime=number| realtime={0|1}The curly braces (
{...}) surrounding the list of parameters is required, even if there is only one parameter in the list.A
param(parameter) specifies any or all of the following information:The number of threads of the given type (
count)The CPUs to which the threads of the given type are to be bound (either one of
cpubindorcpuset)Wait time during which the CPU is busy (
spintime) and whether or not to set realtime priority to the specified thread or threads (realtime)Notespintimedoes not apply to I/O threads or watchdog threads and so cannot be set for these thread types.
The
typeattribute represents an NDB thread type. The thread types supported in MySQL Cluster NDB 7.2 and the range of permittedcountvalues for each are provided in the following list:ldm: Local query handler (DBLQHkernel block) that handles data. The more LDM threads that are used, the more highly partitioned the data becomes. Each LDM thread maintains its own sets of data and index partitions, as well as its own redo log. The value set forldmmust be one of one of the values 1, 2, 4, 6, 8, 12, or 16.ImportantChanging the number of LDM threads requires a system restart to be effective and safe for cluster operations. (This is also true when this is done using
MaxNoOfExecutionThreads.) IfIndexMemoryusage is in excess of 50%, an initial restart of the cluster is required; a maximum of 30-35%IndexMemoryusage is recommended in such cases. Otherwise,IndexMemoryandDataMemoryusage as well as the allocation of LDM threads cannot be balanced between nodes, which can ultimately lead to data node failures.tc: Transaction coordinator thread (DBTCkernel block) containing the state of an ongoing transaction. In MySQL Cluster NDB 7.2.5 and later, the number of TC threads is configurable, with a total of 16 possible.Optimally, every new transaction can be assigned to a new TC thread. In most cases 1 TC thread per 2 LDM threads is sufficient to guarantee that this can happen. In cases where the number of writes is relatively small when compared to the number of reads, it is possible that only 1 TC thread per 4 LQH threads is required to maintain transaction states. Conversely, in applications that perform a great many updates, it may be necessary for the ratio of TC threads to LDM threads to approach 1 (for example, 3 TC threads to 4 LDM threads).
Range: 1 - 16 (always 1 prior to MySQL Cluster 7.2.5).
main: Data dictionary and transaction coordinator (DBDIHandDBTCkernel blocks), providing schema management. This is always handled by a single dedicated thread.Range: 1 only.
recv: Receive thread (CMVMIkernel block). Each receive thread handles one or more sockets for communicating with other nodes in a MySQL Cluster, with one socket per node. Previously, this was limited to a single thread, but MySQL Cluster 7.2 implements multiple receive threads (up to 8).Range: 1 - 8.
send: Send thread (CMVMIkernel block). Added in MySQL Cluster NDB 7.2.5. To increase throughput, it is possible in MySQL Cluster NDB 7.2.5 and later to perform sends from one or more separate, dedicated threads (maximum 8).Previously, all threads handled their own sending directly; this can still be made to happen by setting the number of send threads to 0 (this also happens when
MaxNoOfExecutionThreadsis set less than 10). While doing so can have an adeverse impact on throughput, it can also in some cases provide decreased latency.Range: 0 - 8.
rep: Replication thread (SUMAkernel block). Asynchronous replication operations are always handled by a single, dedicated thread.Range: 1 only.
io: File system and other miscellaneous operations. These are not demanding tasks, and are always handled as a group by a single, dedicated I/O thread.Range: 1 only.
Simple examples:
# Example 1.
ThreadConfig=ldm={count=2,cpubind=1,2},main={cpubind=12},rep={cpubind=11}
# Example 2.
Threadconfig=main={cpubind=0},ldm={count=4,cpubind=1,2,5,6},io={cpubind=3}
It is usually desirable when configuring thread usage for a data
node host to reserve one or more number of CPUs for operating
system and other tasks. Thus, for a host machine with 24 CPUs,
you might want to use 20 CPU threads (leaving 4 for other uses),
with 8 LDM threads, 4 TC threads (half the number of LDM
threads), 3 send threads, 3 receive threads, and 1 thread each
for schema management, asynchronous replication, and I/O
operations. (This is almost the same distribution of threads
used when
MaxNoOfExecutionThreads
is set equal to 20.) The following
ThreadConfig setting performs these
assignments, additionally binding all of these threads to
specific CPUs:
ThreadConfig=ldm{count=8,cpubind=1,2,3,4,5,6,7,8},main={cpubind=9},io={cpubind=9}, \
rep={cpubind=10},tc{count=4,cpubind=11,12,13,14},recv={count=3,cpubind=15,16,17}, \
send{count=3,cpubind=18,19,20}
It should be possible in most cases to bind the main (schema management) thread and the I/O thread to the same CPU, as we have done in the example just shown.
In order to take advantage of the enhanced stability that the
use of ThreadConfig offers, it is necessary
to insure that CPUs are isolated, and that they not subject to
interrupts, or to being scheduled for other tasks by the
operating system. On many Linux systems, you can do this by
setting IRQBALANCE_BANNED_CPUS in
/etc/sysconfig/irqbalance to
0xFFFFF0, and by using the
isolcpus boot option in
grub.conf. For specific information, see
your operating system or platform documentation.
Disk Data Configuration Parameters. Configuration parameters affecting Disk Data behavior include the following:
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.19 32K pages 10 1 - 1000 N This is the number of page entries (page references) to allocate. It is specified as a number of 32K pages in
DiskPageBufferMemory. The default is sufficient for most cases but you may need to increase the value of this parameter if you encounter problems with very large transactions on Disk Data tables. Each page entry requires approximately 100 bytes. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 64M 4M - 1T N This determines the amount of space used for caching pages on disk, and is set in the
[ndbd]or[ndbd default]section of theconfig.inifile. It is measured in bytes. Each page takes up 32 KB. This means that MySQL Cluster Disk Data storage always usesN* 32 KB memory whereNis some nonnegative integer.The default value for this parameter is
64M(2000 pages of 32 KB each).You can query the
ndbinfo.diskpagebuffertable to help determine whether the value for this parameter should be increased to minimize unnecessary disk seeks. See Section 18.5.10.8, “The ndbinfo diskpagebuffer Table”, for more information. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 128M 0 - 64T N This parameter determines the amount of memory that is used for log buffers, disk operations (such as page requests and wait queues), and metadata for tablespaces, log file groups,
UNDOfiles, and data files. The shared global memory pool also provides memory used for satisfying the memory requirements of theUNDO_BUFFER_SIZEoption used withCREATE LOGFILE GROUPandALTER LOGFILE GROUPstatements, including any default value implied for this options by the setting of theInitialLogFileGroupdata node configuration parameter.SharedGlobalMemorycan be set in the[ndbd]or[ndbd default]section of theconfig.iniconfiguration file, and is measured in bytes.As of MySQL Cluster NDB 7.2.0, the default value is
128M. (Previously, this was20M.) -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 threads 2 0 - 4294967039 (0xFFFFFEFF) N This parameter determines the number of unbound threads used for Disk Data file access. Before
DiskIOThreadPoolwas introduced, exactly one thread was spawned for each Disk Data file, which could lead to performance issues, particularly when using very large data files. WithDiskIOThreadPool, you can—for example—access a single large data file using several threads working in parallel.This parameter applies to Disk Data I/O threads only.
The optimum value for this parameter depends on your hardware and configuration, and includes these factors:
Physical distribution of Disk Data files. You can obtain better performance by placing data files, undo log files, and the data node file system on separate physical disks. If you do this with some or all of these sets of files, then you can set
DiskIOThreadPoolhigher to enable separate threads to handle the files on each disk.Disk performance and types. The number of threads that can be accommodated for Disk Data file handling is also dependent on the speed and throughput of the disks. Faster disks and higher throughput allow for more disk I/O threads. Our test results indicate that solid-state disk drives can handle many more disk I/O threads than conventional disks, and thus higher values for
DiskIOThreadPool.
In MySQL Cluster NDB 7.2, the default value for this parameter is 2.
Disk Data file system parameters. The parameters in the following list make it possible to place MySQL Cluster Disk Data files in specific directories without the need for using symbolic links.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 filename [see text] ... IN If this parameter is specified, then MySQL Cluster Disk Data data files and undo log files are placed in the indicated directory. This can be overridden for data files, undo log files, or both, by specifying values for
FileSystemPathDataFiles,FileSystemPathUndoFiles, or both, as explained for these parameters. It can also be overridden for data files by specifying a path in theADD DATAFILEclause of aCREATE TABLESPACEorALTER TABLESPACEstatement, and for undo log files by specifying a path in theADD UNDOFILEclause of aCREATE LOGFILE GROUPorALTER LOGFILE GROUPstatement. IfFileSystemPathDDis not specified, thenFileSystemPathis used.If a
FileSystemPathDDdirectory is specified for a given data node (including the case where the parameter is specified in the[ndbd default]section of theconfig.inifile), then starting that data node with--initialcauses all files in the directory to be deleted. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 filename [see text] ... IN If this parameter is specified, then MySQL Cluster Disk Data data files are placed in the indicated directory. This overrides any value set for
FileSystemPathDD. This parameter can be overridden for a given data file by specifying a path in theADD DATAFILEclause of aCREATE TABLESPACEorALTER TABLESPACEstatement used to create that data file. IfFileSystemPathDataFilesis not specified, thenFileSystemPathDDis used (orFileSystemPath, ifFileSystemPathDDhas also not been set).If a
FileSystemPathDataFilesdirectory is specified for a given data node (including the case where the parameter is specified in the[ndbd default]section of theconfig.inifile), then starting that data node with--initialcauses all files in the directory to be deleted. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 filename [see text] ... IN If this parameter is specified, then MySQL Cluster Disk Data undo log files are placed in the indicated directory. This overrides any value set for
FileSystemPathDD. This parameter can be overridden for a given data file by specifying a path in theADD UNDOclause of aCREATE LOGFILE GROUPorALTER LOGFILE GROUPstatement used to create that data file. IfFileSystemPathUndoFilesis not specified, thenFileSystemPathDDis used (orFileSystemPath, ifFileSystemPathDDhas also not been set).If a
FileSystemPathUndoFilesdirectory is specified for a given data node (including the case where the parameter is specified in the[ndbd default]section of theconfig.inifile), then starting that data node with--initialcauses all files in the directory to be deleted.
For more information, see Section 18.5.12.1, “MySQL Cluster Disk Data Objects”.
-
Disk Data object creation parameters. The next two parameters enable you—when starting the cluster for the first time—to cause a Disk Data log file group, tablespace, or both, to be created without the use of SQL statements.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 string [see text] ... S This parameter can be used to specify a log file group that is created when performing an initial start of the cluster.
InitialLogFileGroupis specified as shown here:InitialLogFileGroup = [name=
name;] [undo_buffer_size=size;]file-specification-listfile-specification-list:file-specification[;file-specification[; ...]]file-specification:filename:sizeThe
nameof the log file group is optional and defaults toDEFAULT-LG. Theundo_buffer_sizeis also optional; if omitted, it defaults to64M. Eachfile-specificationcorresponds to an undo log file, and at least one must be specified in thefile-specification-list. Undo log files are placed according to any values that have been set forFileSystemPath,FileSystemPathDD, andFileSystemPathUndoFiles, just as if they had been created as the result of aCREATE LOGFILE GROUPorALTER LOGFILE GROUPstatement.Consider the following:
InitialLogFileGroup = name=LG1; undo_buffer_size=128M; undo1.log:250M; undo2.log:150M
This is equivalent to the following SQL statements:
CREATE LOGFILE GROUP LG1 ADD UNDOFILE 'undo1.log' INITIAL_SIZE 250M UNDO_BUFFER_SIZE 128M ENGINE NDBCLUSTER; ALTER LOGFILE GROUP LG1 ADD UNDOFILE 'undo2.log' INITIAL_SIZE 150M ENGINE NDBCLUSTER;This logfile group is created when the data nodes are started with
--initial.Resources for the initial log file group are taken from the global memory pool whose size is determined by the value of the
SharedGlobalMemorydata node configuration parameter; if this parameter is set too low and the values set inInitialLogFileGroupfor the logfile group's initial size or undo buffer size are too high, the cluster may fail to create the default log file group when starting, or fail to start altogether.This parameter, if used, should always be set in the
[ndbd default]section of theconfig.inifile. The behavior of a MySQL Cluster when different values are set on different data nodes is not defined. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 string [see text] ... S This parameter can be used to specify a MySQL Cluster Disk Data tablespace that is created when performing an initial start of the cluster.
InitialTablespaceis specified as shown here:InitialTablespace = [name=
name;] [extent_size=size;]file-specification-listThe
nameof the tablespace is optional and defaults toDEFAULT-TS. Theextent_sizeis also optional; it defaults to1M. Thefile-specification-listuses the same syntax as shown with theInitialLogfileGroupparameter, the only difference being that eachfile-specificationused withInitialTablespacecorresponds to a data file. At least one must be specified in thefile-specification-list. Data files are placed according to any values that have been set forFileSystemPath,FileSystemPathDD, andFileSystemPathDataFiles, just as if they had been created as the result of aCREATE TABLESPACEorALTER TABLESPACEstatement.For example, consider the following line specifying
InitialTablespacein the[ndbd default]section of theconfig.inifile (as withInitialLogfileGroup, this parameter should always be set in the[ndbd default]section, as the behavior of a MySQL Cluster when different values are set on different data nodes is not defined):InitialTablespace = name=TS1; extent_size=8M; data1.dat:2G; data2.dat:4G
This is equivalent to the following SQL statements:
CREATE TABLESPACE TS1 ADD DATAFILE 'data1.dat' EXTENT_SIZE 8M INITIAL_SIZE 2G ENGINE NDBCLUSTER; ALTER TABLESPACE TS1 ADD DATAFILE 'data2.dat' INITIAL_SIZE 4G ENGINE NDBCLUSTER;This tablespace is created when the data nodes are started with
--initial, and can be used whenever creating MySQL Cluster Disk Data tables thereafter.
-
Disk Data and GCP Stop errors.
Errors encountered when using Disk Data tables such as
Node nodeid killed this
node because GCP stop was detected (error 2303)
are often referred to as “GCP stop errors”. Such
errors occur when the redo log is not flushed to disk quickly
enough; this is usually due to slow disks and insufficient
disk throughput.
You can help prevent these errors from occurring by using faster
disks, and by placing Disk Data files on a separate disk from
the data node file system. Reducing the value of
TimeBetweenGlobalCheckpoints
tends to decrease the amount of data to be written for each
global checkpoint, and so may provide some protection against
redo log buffer overflows when trying to write a global
checkpoint; however, reducing this value also permits less time
in which to write the GCP, so this must be done with caution.
In addition to the considerations given for
DiskPageBufferMemory as
explained previously, it is also very important that the
DiskIOThreadPool
configuration parameter be set correctly; having
DiskIOThreadPool set too
high is very likely to cause GCP stop errors (Bug #37227).
GCP stops can be caused by save or commit timeouts; the
TimeBetweenEpochsTimeout
data node configuration parameter determines the timeout for
commits. However, it is possible to disable both types of
timeouts by setting this parameter to 0.
Parameters for configuring send buffer memory allocation.
Send buffer memory is allocated dynamically from a memory pool
shared between all transporters, which means that the size of
the send buffer can be adjusted as necessary. (Previously, the
NDB kernel used a fixed-size send buffer for every node in the
cluster, which was allocated when the node started and could
not be changed while the node was running.) The
TotalSendBufferMemory
and OverLoadLimit data
node configuration parameters permit the setting of limits on
this memory allocation. For more information about the use of
these parameters (as well as
SendBufferMemory), see
Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”.
This parameter specifies the amount of transporter send buffer memory to allocate in addition to any set using
TotalSendBufferMemory,SendBufferMemory, or both.This parameter was added in MySQL Cluster NDB 7.2.5. (Bug #11760629, Bug #53053)
This parameter is used to determine the total amount of memory to allocate on this node for shared send buffer memory among all configured transporters.
Prior to MySQL Cluster NDB 7.2.5, this parameter did not work correctly with ndbmtd. (Bug #13633845)
If this parameter is set, its minimum permitted value is 256KB; 0 indicates that the parameter has not been set. For more detailed information, see Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”.
This parameter is present in
NDBCLUSTERsource code beginning with MySQL Cluster NDB 6.4.0. However, it is not currently enabled.As of MySQL Cluster NDB 7.2.5, this parameter is deprecated, and is subject to removal in a future release of MySQL Cluster (Bug #11760629, Bug #53053).
For more detailed information about the behavior and use of
TotalSendBufferMemory
and
ReservedSendBufferMemory,
and about configuring send buffer memory parameters in MySQL
Cluster, see
Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”.
See also Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”.
Redo log over-commit handling.
It is possible to control a data node's handling of
operations when too much time is taken flushing redo logs to
disk. This occurs when a given redo log flush takes longer
than
RedoOverCommitLimit
seconds, more than
RedoOverCommitCounter
times, causing any pending transactions to be aborted. When
this happens, the API node that sent the transaction can
handle the operations that should have been committed either
by queuing the operations and re-trying them, or by aborting
them, as determined by
DefaultOperationRedoProblemAction.
The data node configuration parameters for setting the timeout
and number of times it may be exceeded before the API node
takes this action are described in the following list:
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric 3 0 - 4294967039 (0xFFFFFEFF) N When
RedoOverCommitLimitis exceeded when trying to write a given redo log to disk this many times or more, any transactions that were not committed as a result are aborted, and an API node where any of these transactions originated handles the operations making up those transactions according to its value forDefaultOperationRedoProblemAction(by either queuing the operations to be re-tried, or aborting them).RedoOverCommitCounterdefaults to 3. Set it to 0 to disable the limit. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 seconds 20 0 - 4294967039 (0xFFFFFEFF) N This parameter sets an upper limit in seconds for trying to write a given redo log to disk before timing out. The number of times the data node tries to flush this redo log, but takes longer than
RedoOverCommitLimit, is kept and compared withRedoOverCommitCounter, and when flushing takes too long more times than the value of that parameter, any transactions that were not committed as a result of the flush timeout are aborted. When this occurs, the API node where any of these transactions originated handles the operations making up those transactions according to itsDefaultOperationRedoProblemActionsetting (it either queues the operations to be re-tried, or aborts them).By default,
RedoOverCommitLimitis 20 seconds. Set to 0 to disable checking for redo log flush timeouts. This parameter was added in MySQL Cluster NDB 7.1.10.
Controlling restart attempts.
It is possible to exercise finely-grained control over restart
attempts by data nodes when they fail to start using the
MaxStartFailRetries
and
StartFailRetryDelay
data node configuration parameters.
MaxStartFailRetries
limits the total number of retries made before giving up on
starting the data node,
StartFailRetryDelay sets
the number of seconds between retry attempts. These parameters
are listed here:
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 0 - 4294967039 (0xFFFFFEFF) N Use this parameter to set the number of seconds between restart attempts by the data node in the event on failure on startup. The default is 0 (no delay).
Both this parameter and
MaxStartFailRetriesare ignored unlessStopOnErroris equal to 0. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 3 0 - 4294967039 (0xFFFFFEFF) N Use this parameter to limit the number restart attempts made by the data node in the event that it fails on startup. The default is 3 attempts.
Both this parameter and
StartFailRetryDelayare ignored unlessStopOnErroris equal to 0.
NDB index statistics parameters. The parameters in the following list relate to NDB index statistics generation, which was introduced in MySQL Cluster NDB 7.2.1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 boolean false false, true S Enable or disable automatic statistics collection when indexes are created. Disabled by default.
This parameter was added in MySQL Cluster NDB 7.2.1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 boolean false false, true S Enable or disable monitoring of indexes for changes and trigger automatic statistics updates these are detected. The amount and degree of change needed to trigger the updates are determined by the settings for the
IndexStatTriggerPctandIndexStatTriggerScaleoptions.This parameter was added in MySQL Cluster NDB 7.2.1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 bytes 32768 0 - 4294967039 (0xFFFFFEFF) IN Maximum space in bytes allowed for the saved statistics of any given index in the
NDBsystem tables and in the mysqld memory cache. This consumesIndexMemory.At least one sample is always produced, regardless of any size limit. Note that this size is scaled by
IndexStatSaveScale.This parameter was added in MySQL Cluster NDB 7.2.1.
The size specified by
IndexStatSaveSizeis scaled by the value ofIndexStatTriggerPctfor a large index, times 0.01. Note that this is further multiplied by the logarithm to the base 2 of the index size. SettingIndexStatTriggerPctequal to 0 disables the scaling effect. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 percentage 100 0 - 4294967039 (0xFFFFFEFF) IN The size specified by
IndexStatSaveSizeis scaled by the value ofIndexStatTriggerPctfor a large index, times 0.01. Note that this is further multiplied by the logarithm to the base 2 of the index size. SettingIndexStatTriggerPctequal to 0 disables the scaling effect.This parameter was added in MySQL Cluster NDB 7.2.1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 percentage 100 0 - 4294967039 (0xFFFFFEFF) IN Percentage change in updates that triggers an index statistics update. The value is scaled by
IndexStatTriggerScale. You can disable this trigger altogether by settingIndexStatTriggerPctto 0.This parameter was added in MySQL Cluster NDB 7.2.1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 percentage 100 0 - 4294967039 (0xFFFFFEFF) IN Scale
IndexStatTriggerPctby this amount times 0.01 for a large index. A value of 0 disables scaling.This parameter was added in MySQL Cluster NDB 7.2.1.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.1 seconds 60 0 - 4294967039 (0xFFFFFEFF) IN Minimum delay in seconds between automatic index statistics updates for a given index. Setting this variable to 0 disables any delay. The default is 60 seconds.
This parameter was added in MySQL Cluster NDB 7.2.1.
The [mysqld] and [api]
sections in the config.ini file define the
behavior of the MySQL servers (SQL nodes) and other applications
(API nodes) used to access cluster data. None of the parameters
shown is required. If no computer or host name is provided, any
host can use this SQL or API node.
Generally speaking, a [mysqld] section is
used to indicate a MySQL server providing an SQL interface to
the cluster, and an [api] section is used for
applications other than mysqld processes
accessing cluster data, but the two designations are actually
synonymous; you can, for instance, list parameters for a MySQL
server acting as an SQL node in an [api]
section.
For a discussion of MySQL server options for MySQL Cluster, see Section 18.3.3.8.1, “MySQL Server Options for MySQL Cluster”; for information about MySQL server system variables relating to MySQL Cluster, see Section 18.3.3.8.2, “MySQL Cluster System Variables”.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 1 - 255 IS The
Idis an integer value used to identify the node in all cluster internal messages. The permitted range of values is 1 to 255 inclusive. This value must be unique for each node in the cluster, regardless of the type of node.NoteData node IDs must be less than 49, regardless of the MySQL Cluster version used. If you plan to deploy a large number of data nodes, it is a good idea to limit the node IDs for API nodes (and management nodes) to values greater than 48.
NodeIdis the preferred parameter name to use when identifying API nodes. (Idcontinues to be supported for backward compatibility, but is now deprecated and generates a warning when used. It is also subject to future removal.) -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 string [none] ... N Specifies which data nodes to connect.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 1 - 255 IS The
NodeIdis an integer value used to identify the node in all cluster internal messages. The permitted range of values is 1 to 255 inclusive. This value must be unique for each node in the cluster, regardless of the type of node.NoteData node IDs must be less than 49, regardless of the MySQL Cluster version used. If you plan to deploy a large number of data nodes, it is a good idea to limit the node IDs for API nodes (and management nodes) to values greater than 48.
NodeIdis the preferred parameter name to use when identifying management nodes in MySQL Cluster NDB 7.2 and later. Previously,Idwas used for this purpose and this continues to be supported for backward compatibility.Idis now deprecated and generates a warning when used; it is subject to removal in a future release of MySQL Cluster. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name [none] ... S This refers to the
Idset for one of the computers (hosts) defined in a[computer]section of the configuration file. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N Specifying this parameter defines the hostname of the computer on which the SQL node (API node) is to reside. To specify a hostname, either this parameter or
ExecuteOnComputeris required.If no
HostNameorExecuteOnComputeris specified in a given[mysql]or[api]section of theconfig.inifile, then an SQL or API node may connect using the corresponding “slot” from any host which can establish a network connection to the management server host machine. This differs from the default behavior for data nodes, wherelocalhostis assumed forHostNameunless otherwise specified. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 0-2 0 0 - 2 N This parameter defines which nodes can act as arbitrators. Both management nodes and SQL nodes can be arbitrators. A value of 0 means that the given node is never used as an arbitrator, a value of 1 gives the node high priority as an arbitrator, and a value of 2 gives it low priority. A normal configuration uses the management server as arbitrator, setting its
ArbitrationRankto 1 (the default for management nodes) and those for all SQL nodes to 0 (the default for SQL nodes).By setting
ArbitrationRankto 0 on all management and SQL nodes, you can disable arbitration completely. You can also control arbitration by overriding this parameter; to do so, set theArbitrationparameter in the[ndbd default]section of theconfig.iniglobal configuration file. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 milliseconds 0 0 - 4294967039 (0xFFFFFEFF) N Setting this parameter to any other value than 0 (the default) means that responses by the arbitrator to arbitration requests will be delayed by the stated number of milliseconds. It is usually not necessary to change this value.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 32K 1024 - 1M N NDB 7.2.1 bytes 16K 1024 - 1M N For queries that are translated into full table scans or range scans on indexes, it is important for best performance to fetch records in properly sized batches. It is possible to set the proper size both in terms of number of records (
BatchSize) and in terms of bytes (BatchByteSize). The actual batch size is limited by both parameters.The speed at which queries are performed can vary by more than 40% depending upon how this parameter is set.
This parameter is measured in bytes. The default value prior to MySQL Cluster NDB 7.2.1 was 32K; in MySQL Cluster NDB 7.2.1 and later, the default is 16K.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 records 64 1 - 992 N NDB 7.2.1 records 256 1 - 992 N This parameter is measured in number of records and is by default set to 256 (MySQL Cluster NDB 7.2.1 and later; previously, the default was 64). The maximum size is 992.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.14 bytes 0 0 - 4294967039 (0xFFFFFEFF) N This parameter specifies the amount of transporter send buffer memory to allocate in addition to any that has been set using
TotalSendBufferMemory,SendBufferMemory, or both.This parameter was added in MySQL Cluster NDB 7.2.14. (Bug #14555359)
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 string [none] ... S Use this parameter to set the scheduling policy and priority of heartbeat threads for management and API nodes. The syntax for setting this parameter is shown here:
HeartbeatThreadPriority =
policy[,priority]policy: {FIFO | RR}When setting this parameter, you must specify a policy. This is one of
FIFO(first in, first in) orRR(round robin). This followed optionally by the priority (an integer). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 256K 32K - 16M N The batch size is the size of each batch sent from each data node. Most scans are performed in parallel to protect the MySQL Server from receiving too much data from many nodes in parallel; this parameter sets a limit to the total batch size over all nodes.
The default value of this parameter is set to 256KB. Its maximum size is 16MB.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 0 256K - 4294967039 (0xFFFFFEFF) N This parameter is available beginning with MySQL Cluster NDB 6.4.0. It is used to determine the total amount of memory to allocate on this node for shared send buffer memory among all configured transporters.
If this parameter is set, its minimum permitted value is 256KB; 0 indicates that the parameter has not been set. For more detailed information, see Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N This parameter is
falseby default. This forces disconnected API nodes (including MySQL Servers acting as SQL nodes) to use a new connection to the cluster rather than attempting to re-use an existing one, as re-use of connections can cause problems when using dynamically-allocated node IDs. (Bug #45921)NoteThis parameter can be overridden using the NDB API. For more information, see Ndb_cluster_connection::set_auto_reconnect(), and Ndb_cluster_connection::get_auto_reconnect().
DefaultOperationRedoProblemActionEffective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 enumeration ABORT ABORT, QUEUE S NDB 7.2.1 enumeration ABORT ABORT, QUEUE S NDB 7.2.10 enumeration QUEUE ABORT, QUEUE S This parameter (along with
RedoOverCommitLimitandRedoOverCommitCounter) controls the data node's handling of operations when too much time is taken flushing redo logs to disk. This occurs when a given redo log flush takes longer thanRedoOverCommitLimitseconds, more thanRedoOverCommitCountertimes, causing any pending transactions to be aborted.When this happens, the node can respond in either of two ways, according to the value of
DefaultOperationRedoProblemAction, listed here:ABORT: Any pending operations from aborted transactions are also aborted.QUEUE: Pending operations from transactions that were aborted are queued up to be re-tried. This the default in MySQL Cluster NDB 7.2 and later. In MySQL Cluster NDB 7.2.21 and later, pending operations are still aborted when the redo log runs out of space—that is, when P_TAIL_PROBLEM errors occur. (Bug #20782580)
Prior to MySQL Cluster NDB 7.2.10, setting this parameter did not have any effect. (Bug #15855588)
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.11 buckets 3840 0 - 3840 N MySQL Cluster NDB 7.2.7 and later use a larger default table hash map size (3840) than in previous releases (240). Beginning with MySQL Cluster NDB 7.2.11, the size of the table hash maps used by
NDBis configurable using this parameter; previously this value was hard-coded.DefaultHashMapSizecan take any of three possible values (0, 240, 3840). These values and their effects are described in the following table.Value Description / Effect 0Use the lowest value set, if any, for this parameter among all data nodes and API nodes in the cluster; if it is not set on any data or API node, use the default value. 240Original hash map size, used by default in all MySQL Cluster releases prior to MySQL Cluster NDB 7.2.7. 3840Larger hash map size as used by default in MySQL Cluster NDB 7.2.7 and later The primary intended use for this parameter is to facilitate upgrades and especially downgrades between MySQL Cluster NDB 7.2.7 and later MySQL Cluster versions, in which the larger hash map size (3840) is the default, and earlier releases (in which the default was 240), due to the fact that this change is not otherwise backward compatible (Bug #14800539). By setting this parameter to 240 prior to performing an upgrade from an older version where this value is in use, you can cause the cluster to continue using the smaller size for table hash maps, in which case the tables remain compatible with earlier versions following the upgrade.
DefaultHashMapSizecan be set for individual data nodes, API nodes, or both, but setting it once only, in the[ndbd default]section of theconfig.inifile, is the recommended practice.After increasing this parameter, to have existing tables to take advantage of the new size, you can run
ALTER TABLE ... REORGANIZE PARTITIONon them, after which they can use the larger hash map size. This is in addition to performing a rolling restart, which makes the larger hash maps available to new tables, but does not enable existing tables to use them.Decreasing this parameter online after any tables have been created or modified with
DefaultHashMapSizeequal to 3840 is not currently supported. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N Use WAN TCP setting as default.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.18 integer 0 0 - 4294967039 (0xFFFFFEFF) N Starting with MySQL Cluster NDB 7.2.18, in a MySQL Cluster with many unstarted data nodes, the value of this parameter can be raised to circumvent connection attempts to data nodes which have not yet begun to function in the cluster, as well as moderate high traffic to management nodes. As long as the API node is not connected to any new data nodes, the value of the
StartConnectBackoffMaxTimeparameter is applied; otherwise,ConnectBackoffMaxTimeis used to determine the length of time in milliseconds to wait between connection attempts.Time elapsed during node connection attempts is not taken into account when calculating elapsed time for this parameter. The timeout is applied with approximately 100 ms resolution, starting with a 100 ms delay; for each subsequent attempt, the length of this period is doubled until it reaches
ConnectBackoffMaxTimemilliseconds, up to a maximum of 100000 ms (100s).Once the API node is connected to a data node and that node reports (in a heartbeat message) that it has connected to other data nodes, connection attempts to those data nodes are no longer affected by this parameter, and are made every 100 ms thereafter until connected. Note that, once a data node has started, it can take up
HeartbeatIntervalDbApifor the API node to be notified that this has occurred. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.18 integer 1500 0 - 4294967039 (0xFFFFFEFF) N Starting with MySQL Cluster NDB 7.2.18, in a MySQL Cluster with many unstarted data nodes, the value of this parameter can be raised to circumvent connection attempts to data nodes which have not yet begun to function in the cluster, as well as moderate high traffic to management nodes. As long as the API node is not connected to any new data nodes, the value of the
StartConnectBackoffMaxTimeparameter is applied; otherwise,ConnectBackoffMaxTimeis used to determine the length of time in milliseconds to wait between connection attempts.Time elapsed during node connection attempts is not taken into account when calculating elapsed time for this parameter. The timeout is applied with approximately 100 ms resolution, starting with a 100 ms delay; for each subsequent attempt, the length of this period is doubled until it reaches
StartConnectBackoffMaxTimemilliseconds, up to a maximum of 100000 ms (100s).Once the API node is connected to a data node and that node reports (in a heartbeat message) that it has connected to other data nodes, connection attempts to those data nodes are no longer affected by this parameter, and are made every 100 ms thereafter until connected. Note that, once a data node has started, it can take up
HeartbeatIntervalDbApifor the API node to be notified that this has occurred.
You can also obtain information from a MySQL server running as a
MySQL Cluster SQL node using SHOW
STATUS in the mysql client, as
shown here:
mysql> SHOW STATUS LIKE 'ndb%';
+-----------------------------+---------------+
| Variable_name | Value |
+-----------------------------+---------------+
| Ndb_cluster_node_id | 5 |
| Ndb_config_from_host | 192.168.0.112 |
| Ndb_config_from_port | 1186 |
| Ndb_number_of_storage_nodes | 4 |
+-----------------------------+---------------+
4 rows in set (0.02 sec)
For information about the status variables appearing in the output from this statement, see Section 18.3.3.8.3, “MySQL Cluster Status Variables”.
To add new SQL or API nodes to the configuration of a running
MySQL Cluster, it is necessary to perform a rolling restart of
all cluster nodes after adding new [mysqld]
or [api] sections to the
config.ini file (or files, if you are
using more than one management server). This must be done
before the new SQL or API nodes can connect to the cluster.
It is not necessary to perform any restart of the cluster if new SQL or API nodes can employ previously unused API slots in the cluster configuration to connect to the cluster.
This section provides information about MySQL server options, server and status variables that are specific to MySQL Cluster. For general information on using these, and for other options and variables not specific to MySQL Cluster, see Section 5.1, “The MySQL Server”.
For MySQL Cluster configuration parameters used in the cluster
configuration file (usually named
config.ini), see
Section 18.3, “Configuration of MySQL Cluster”.
This section provides descriptions of mysqld server options relating to MySQL Cluster. For information about mysqld options not specific to MySQL Cluster, and for general information about the use of options with mysqld, see Section 5.1.3, “Server Command Options”.
For information about command-line options used with other
MySQL Cluster processes (ndbd,
ndb_mgmd, and ndb_mgm),
see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
For information about command-line options used with
NDB utility programs (such as
ndb_desc, ndb_size.pl,
and ndb_show_tables), see
Section 18.4, “MySQL Cluster Programs”.
-
Table 18.10 Type and value information for ndb-batch-size
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 integer 32768 / 0 - 31536000 DESCRIPTION: Size (in bytes) to use for NDB transaction batches
This sets the size in bytes that is used for NDB transaction batches.
--ndb-cluster-connection-pool=#Table 18.11 Type and value information for ndb-cluster-connection-pool
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes Yes Yes Global No NDB 7.2 integer 1 / 1 - 63 DESCRIPTION: Number of connections to the cluster used by MySQL
By setting this option to a value greater than 1 (the default), a mysqld process can use multiple connections to the cluster, effectively mimicking several SQL nodes. Each connection requires its own
[api]or[mysqld]section in the cluster configuration (config.ini) file, and counts against the maximum number of API connections supported by the cluster.Suppose that you have 2 cluster host computers, each running an SQL node whose mysqld process was started with
--ndb-cluster-connection-pool=4; this means that the cluster must have 8 API slots available for these connections (instead of 2). All of these connections are set up when the SQL node connects to the cluster, and are allocated to threads in a round-robin fashion.This option is useful only when running mysqld on host machines having multiple CPUs, multiple cores, or both. For best results, the value should be smaller than the total number of cores available on the host machine. Setting it to a value greater than this is likely to degrade performance severely.
ImportantBecause each SQL node using connection pooling occupies multiple API node slots—each slot having its own node ID in the cluster—you must not use a node ID as part of the cluster connection string when starting any mysqld process that employs connection pooling.
Setting a node ID in the connection string when using the
--ndb-cluster-connection-pooloption causes node ID allocation errors when the SQL node attempts to connect to the cluster.NoteIn some older releases of MySQL Cluster prior to MySQL Cluster NDB 7.2, there was also a separate status variable corresponding to this option; however, the status variable was removed as redundant as of these versions. (Bug #60119)
--ndb-blob-read-batch-bytes=bytesTable 18.12 Type and value information for ndb-blob-read-batch-bytes
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 integer 65536 / 0 - 4294967295 DESCRIPTION: Specifies size in bytes that large BLOB reads should be batched into. 0 = no limit.
This option can be used to set the size (in bytes) for batching of
BLOBdata reads in MySQL Cluster applications. When this batch size is exceeded by the amount ofBLOBdata to be read within the current transaction, any pendingBLOBread operations are immediately executed.The maximum value for this option is 4294967295; the default is 65536. Setting it to 0 has the effect of disabling
BLOBread batching.NoteIn NDB API applications, you can control
BLOBwrite batching with thesetMaxPendingBlobReadBytes()andgetMaxPendingBlobReadBytes()methods.--ndb-blob-write-batch-bytes=bytesTable 18.13 Type and value information for ndb-blob-write-batch-bytes
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 integer 65536 / 0 - 4294967295 DESCRIPTION: Specifies size in bytes that large BLOB writes should be batched into. 0 = no limit.
This option can be used to set the size (in bytes) for batching of
BLOBdata writes in MySQL Cluster applications. When this batch size is exceeded by the amount ofBLOBdata to be written within the current transaction, any pendingBLOBwrite operations are immediately executed.The maximum value for this option is 4294967295; the default is 65536. Setting it to 0 has the effect of disabling
BLOBwrite batching.NoteIn NDB API applications, you can control
BLOBwrite batching with thesetMaxPendingBlobWriteBytes()andgetMaxPendingBlobWriteBytes()methods.--ndb-connectstring=connection_stringTable 18.14 Type and value information for ndb-connectstring
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No No Yes No NDB 7.2 string DESCRIPTION: Point to the management server that distributes the cluster configuration
When using the
NDBCLUSTERstorage engine, this option specifies the management server that distributes cluster configuration data. See Section 18.3.3.3, “MySQL Cluster Connection Strings”, for syntax.--ndb-deferred-constraints=[0|1]Table 18.15 Type and value information for ndb-deferred-constraints
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 integer 0 / 0 - 1 DESCRIPTION: Specifies that constraint checks on unique indexes (where these are supported) should be deferred until commit time. Not normally needed or used; for testing purposes only.
Controls whether or not constraint checks on unique indexes are deferred until commit time, where such checks are supported.
0is the default.This option is not normally needed for operation of MySQL Cluster or MySQL Cluster Replication, and is intended primarily for use in testing.
--ndb-distribution=[KEYHASH|LINHASH]Table 18.16 Type and value information for ndb-distribution
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 enumeration KEYHASH / LINHASH, KEYHASH DESCRIPTION: Default distribution for new tables in NDBCLUSTER (KEYHASH or LINHASH, default is KEYHASH)
Controls the default distribution method for
NDBtables. Can be set to either ofKEYHASH(key hashing) orLINHASH(linear hashing).KEYHASHis the default.-
Table 18.17 Type and value information for ndb-mgmd-host
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No No Yes No NDB 7.2 string localhost:1186 DESCRIPTION: Set the host (and port, if desired) for connecting to management server
Can be used to set the host and port number of a single management server for the program to connect to. If the program requires node IDs or references to multiple management servers (or both) in its connection information, use the
--ndb-connectstringoption instead. -
Table 18.18 Type and value information for ndbcluster
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No No Yes No NDB 7.2 boolean FALSE DESCRIPTION: Enable NDB Cluster (if this version of MySQL supports it)
Disabled by
--skip-ndbclusterThe
NDBCLUSTERstorage engine is necessary for using MySQL Cluster. If a mysqld binary includes support for theNDBCLUSTERstorage engine, the engine is disabled by default. Use the--ndbclusteroption to enable it. Use--skip-ndbclusterto explicitly disable the engine. -
Table 18.19 Type and value information for ndb-log-apply-status
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 boolean OFF DESCRIPTION: Cause a MySQL server acting as a slave to log mysql.ndb_apply_status updates received from its immediate master in its own binary log, using its own server ID. Effective only if the server is started with the --ndbcluster option.
Causes a slave mysqld to log any updates received from its immediate master to the
mysql.ndb_apply_statustable in its own binary log using its own server ID rather than the server ID of the master. In a circular or chain replication setting, this allows such updates to propagate to themysql.ndb_apply_statustables of any MySQL servers configured as slaves of the current mysqld.In a chain replication setup, using this option allows downstream (slave) clusters to be aware of their positions relative to all of their upstream contributors (masters).
In a circular replication setup, this option causes changes to
ndb_apply_statustables to complete the entire circuit, eventually propagating back to the originating MySQL Cluster. This also allows a cluster acting as a master to see when its changes (epochs) have been applied to the other clusters in the circle.This option has no effect unless the MySQL server is started with the
--ndbclusteroption. -
Table 18.20 Type and value information for ndb-log-empty-epochs
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 boolean OFF DESCRIPTION: When enabled, causes epochs in which there were no changes to be written to the ndb_apply_status and ndb_binlog_index tables, even when --log-slave-updates is enabled.
Causes epochs during which there were no changes to be written to the
ndb_apply_statusandndb_binlog_indextables, even when--log-slave-updatesis enabled.By default this option is disabled. Disabling
--ndb-log-empty-epochscauses epoch transactions with no changes not to be written to the binary log, although a row is still written even for an empty epoch inndb_binlog_index.Because
--ndb-log-empty-epochs=1causes the size ofndb_binlog_indextable to increase independently of the size of the binary log, users should be prepared to manage the growth of this table, even if they expect the cluster to be idle a large part of the time. -
Table 18.21 Type and value information for ndb-log-orig
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 boolean OFF DESCRIPTION: Log originating server id and epoch in mysql.ndb_binlog_index table.
Log the originating server ID and epoch in the
ndb_binlog_indextable.Note that this makes it possible for a given epoch to have multiple rows in
ndb_binlog_index, one for each originating epoch.For more information, see Section 18.6.4, “MySQL Cluster Replication Schema and Tables”.
-
Table 18.22 Type and value information for ndb-log-transaction-id
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 boolean OFF DESCRIPTION: Write NDB transaction IDs in the binary log. Requires --log-bin-v1-events=OFF.
Causes a slave mysqld to write the NDB transaction ID in each row of the binary log. Such logging requires the use of the Version 2 event format for the binary log; thus,
--log-bin-use-v1-row-eventsmust be set toFALSEin order to use this option.This option is available beginning with MySQL Cluster NDB 7.2.1 (and is not supported in mainline MySQL Server 5.5). It is required to enable MySQL Cluster Replication conflict detection and resolution using the
NDB$EPOCH_TRANS()function introduced in the same MySQL Cluster release.The default value is
FALSE.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
-
Table 18.23 Type and value information for ndb-nodeid
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No Yes Yes Global No 5.0.45 integer / 1 - 63 5.1.5 integer / 1 - 255 DESCRIPTION: MySQL Cluster node ID for this MySQL server
Set this MySQL server's node ID in a MySQL Cluster.
The
--ndb-nodeidoption overrides any node ID set with--ndb-connectstring, regardless of the order in which the two options are used.In addition, if
--ndb-nodeidis used, then either a matching node ID must be found in a[mysqld]or[api]section ofconfig.ini, or there must be an “open”[mysqld]or[api]section in the file (that is, a section without aNodeIdorIdparameter specified). This is also true if the node ID is specified as part of the connection string.Regardless of how the node ID is determined, its is shown as the value of the global status variable
Ndb_cluster_node_idin the output ofSHOW STATUS, and ascluster_node_idin theconnectionrow of the output ofSHOW ENGINE NDBCLUSTER STATUS.For more information about node IDs for MySQL Cluster SQL nodes, see Section 18.3.3.7, “Defining SQL and Other API Nodes in a MySQL Cluster”.
--ndb_optimization_delay=millisecondsTable 18.24 Type and value information for ndb_optimization_delay
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global Yes NDB 7.2 integer 10 / 0 - 100000 DESCRIPTION: Sets the number of milliseconds to wait between processing sets of rows by OPTIMIZE TABLE on NDB tables.
Set the number of milliseconds to wait between sets of rows by
OPTIMIZE TABLEstatements onNDBtables. The default is 10.ndb-transid-mysql-connection-map=stateTable 18.25 Type and value information for ndb-transid-mysql-connection-map
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No No No No NDB 7.2 enumeration ON / ON, OFF, FORCE DESCRIPTION: Enable or disable the ndb_transid_mysql_connection_map plugin; that is, enable or disable the INFORMATION_SCHEMA table having that name.
Enables or disables the plugin that handles the
ndb_transid_mysql_connection_maptable in theINFORMATION_SCHEMAdatabase. Takes one of the valuesON,OFF, orFORCE.ON(the default) enables the plugin.OFFdisables the plugin, which makesndb_transid_mysql_connection_mapinaccessible.FORCEkeeps the MySQL Server from starting if the plugin fails to load and start.You can see whether the
ndb_transid_mysql_connection_maptable plugin is running by checking the output ofSHOW PLUGINS.This option was added in MySQL Cluster NDB 7.2.2.
-
Table 18.26 Type and value information for ndb-wait-connected
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 integer 0 / 0 - 31536000 5.1.56-ndb-7.1.16, 5.1.56-ndb-7.0.27 integer 30 / 0 - 31536000 DESCRIPTION: Time (in seconds) for the MySQL server to wait for connection to cluster management and data nodes before accepting MySQL client connections.
This option sets the period of time that the MySQL server waits for connections to MySQL Cluster management and data nodes to be established before accepting MySQL client connections. The time is specified in seconds. The default value is
30. -
Table 18.27 Type and value information for ndb-wait-setup
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 integer 15 / 0 - 31536000 5.1.56-ndb-7.0.27, 5.1.56-ndb-7.1.16 integer 30 / 0 - 31536000 DESCRIPTION: Time (in seconds) for the MySQL server to wait for NDB engine setup to complete.
This variable shows the period of time that the MySQL server waits for the
NDBstorage engine to complete setup before timing out and treatingNDBas unavailable. The time is specified in seconds. The default value is30. -
Table 18.28 Type and value information for server-id-bits
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 integer 32 / 7 - 32 DESCRIPTION: Sets the number of least significant bits in the server_id actually used for identifying the server, permitting NDB API applications to store application data in the most significant bits. server_id must be less than 2 to the power of this value.
This option indicates the number of least significant bits within the 32-bit
server_idwhich actually identify the server. Indicating that the server is actually identified by fewer than 32 bits makes it possible for some of the remaining bits to be used for other purposes, such as storing user data generated by applications using the NDB API's Event API within theAnyValueof anOperationOptionsstructure (MySQL Cluster uses theAnyValueto store the server ID).When extracting the effective server ID from
server_idfor purposes such as detection of replication loops, the server ignores the remaining bits. The--server-id-bitsoption is used to mask out any irrelevant bits ofserver_idin the IO and SQL threads when deciding whether an event should be ignored based on the server ID.This data can be read from the binary log by mysqlbinlog, provided that it is run with its own
--server-id-bitsoption set to 32 (the default).The value of
server_idmust be less than 2 ^server_id_bits; otherwise, mysqld refuses to start.This system variable is supported only by MySQL Cluster. It is not supported in the standard MySQL 5.5 Server.
-
Table 18.29 Type and value information for skip-ndbcluster
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No No Yes No DESCRIPTION: Disable the NDB Cluster storage engine
Disable the
NDBCLUSTERstorage engine. This is the default for binaries that were built withNDBCLUSTERstorage engine support; the server allocates memory and other resources for this storage engine only if the--ndbclusteroption is given explicitly. See Section 18.3.1, “Quick Test Setup of MySQL Cluster”, for an example.
This section provides detailed information about MySQL server
system variables that are specific to MySQL Cluster and the
NDB storage engine. For system
variables not specific to MySQL Cluster, see
Section 5.1.4, “Server System Variables”. For general
information on using system variables, see
Section 5.1.5, “Using System Variables”.
-
Table 18.30 Type and value information for have_ndbcluster
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global No NDB 7.2 boolean DESCRIPTION: Whether mysqld supports NDB Cluster tables (set by --ndbcluster option)
YESif mysqld supportsNDBCLUSTERtables.DISABLEDif--skip-ndbclusteris used.This variable is deprecated and is removed in MySQL 5.6. Use
SHOW ENGINESinstead. -
Table 18.31 Type and value information for ndb_autoincrement_prefetch_sz
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 integer 32 / 1 - 256 5.0.56 integer 1 / 1 - 256 5.1.1 integer 32 / 1 - 256 5.1.23 integer 1 / 1 - 256 5.1.16-ndb-6.2.0 integer 32 / 1 - 256 5.1.23-ndb-6.2.10 integer 1 / 1 - 256 5.1.19-ndb-6.3.0 integer 32 / 1 - 256 5.1.23-ndb-6.3.7 integer 1 / 1 - 256 5.1.41-ndb-6.3.31 integer 1 / 1 - 65536 5.1.30-ndb-6.4.0 integer 32 / 1 - 256 5.1.41-ndb-7.0.11 integer 1 / 1 - 65536 5.5.15-ndb-7.2.1 integer 1 / 1 - 65536 DESCRIPTION: NDB auto-increment prefetch size
Determines the probability of gaps in an autoincremented column. Set it to
1to minimize this. Setting it to a high value for optimization makes inserts faster, but decreases the likelihood that consecutive autoincrement numbers will be used in a batch of inserts. The mininum and default value is 1. The maximum value forndb_autoincrement_prefetch_szis 65536.This variable affects only the number of
AUTO_INCREMENTIDs that are fetched between statements; within a given statement, at least 32 IDs are obtained at a time. The default value is 1.ImportantThis variable does not affect inserts performed using
INSERT ... SELECT. -
Table 18.32 Type and value information for ndb_cache_check_time
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 integer 0 / - DESCRIPTION: Number of milliseconds between checks of cluster SQL nodes made by the MySQL query cache
The number of milliseconds that elapse between checks of MySQL Cluster SQL nodes by the MySQL query cache. Setting this to 0 (the default and minimum value) means that the query cache checks for validation on every query.
The recommended maximum value for this variable is 1000, which means that the check is performed once per second. A larger value means that the check is performed and possibly invalidated due to updates on different SQL nodes less often. It is generally not desirable to set this to a value greater than 2000.
-
Table 18.33 Type and value information for ndb_deferred_constraints
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 integer 0 / 0 - 1 DESCRIPTION: Specifies that constraint checks should be deferred (where these are supported). Not normally needed or used; for testing purposes only.
Controls whether or not constraint checks are deferred, where these are supported.
0is the default.This variable is not normally needed for operation of MySQL Cluster or MySQL Cluster Replication, and is intended primarily for use in testing.
-
Table 18.34 Type and value information for ndb_distribution
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 enumeration KEYHASH / LINHASH, KEYHASH DESCRIPTION: Default distribution for new tables in NDBCLUSTER (KEYHASH or LINHASH, default is KEYHASH)
Controls the default distribution method for
NDBtables. Can be set to either ofKEYHASH(key hashing) orLINHASH(linear hashing).KEYHASHis the default. -
Table 18.35 Type and value information for ndb_eventbuffer_max_alloc
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 integer 0 / 0 - 4294967295 DESCRIPTION: Maximum memory that can be allocated for buffering events by the NDB API. Defaults to 0 (no limit).
Sets the maximum amount memory (in bytes) that can be allocated for buffering events by the NDB API. 0 means that no limit is imposed, and is the default.
This variable was added in MySQL Cluster NDB 7.2.14.
-
Table 18.36 Type and value information for ndb_extra_logging
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 integer 0 / - 5.1.19-ndb-6.3.0 integer 1 / - DESCRIPTION: Controls logging of MySQL Cluster schema, connection, and data distribution events in the MySQL error log
This variable enables recording in the MySQL error log of information specific to the
NDBstorage engine.When this variable is set to 0, the only information specific to
NDBthat is written to the MySQL error log relates to transaction handling. If it set to a value greater than 0 but less than 10,NDBtable schema and connection events are also logged, as well as whether or not conflict resolution is in use, and otherNDBerrors and information. If the value is set to 10 or more, information aboutNDBinternals, such as the progress of data distribution among cluster nodes, is also written to the MySQL error log. The default is 1. -
Table 18.37 Type and value information for ndb_force_send
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 boolean TRUE DESCRIPTION: Forces sending of buffers to NDB immediately, without waiting for other threads
Forces sending of buffers to
NDBimmediately, without waiting for other threads. Defaults toON. -
Table 18.38 Type and value information for ndb_index_stat_cache_entries
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 integer 32 / 0 - 4294967295 DESCRIPTION: Sets the granularity of the statistics by determining the number of starting and ending keys
Sets the granularity of the statistics by determining the number of starting and ending keys to store in the statistics memory cache. Zero means no caching takes place; in this case, the data nodes are always queried directly. Default value:
32.NoteIf
ndb_index_stat_enableisOFF, then setting this variable has no effect.This variable was deprecated in MySQL 5.1, and is removed from MySQL Cluster NDB 7.2.16 and later.
-
Table 18.39 Type and value information for ndb_index_stat_enable
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 boolean OFF 5.5.15-ndb-7.2.1 boolean ON DESCRIPTION: Use NDB index statistics in query optimization
Use
NDBindex statistics in query optimization.ONis the default in MySQL Cluster NDB 7.2 and later. -
Table 18.40 Type and value information for ndb_index_stat_option
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 string loop_enable=1000ms,loop_idle=1000ms,loop_busy=100ms, update_batch=1,read_batch=4,idle_batch=32,check_batch=8, check_delay=10m,delete_batch=8, clean_delay=1m,error_batch=4, error_delay=1m,evict_batch=8,evict_delay=1m,cache_limit=32M, cache_lowpct=90,zero_total=0 5.1.56-ndb-7.1.17 string loop_checkon=1000ms,loop_idle=1000ms,loop_busy=100ms, update_batch=1,read_batch=4,idle_batch=32,check_batch=32, check_delay=1m,delete_batch=8,clean_delay=0,error_batch=4, error_delay=1m,evict_batch=8,evict_delay=1m,cache_limit=32M, cache_lowpct=90 DESCRIPTION: Comma-separated list of tunable options for NDB index statistics; the list should contain no spaces
This variable is used for providing tuning options for NDB index statistics generation. The list consist of comma-separated name-value pairs of option names and values. Note that this list must not contain any space characters.
Options not used when setting
ndb_index_stat_optionare not changed from their default values. For example, you can setndb_index_stat_option = 'loop_idle=1000ms,cache_limit=32M'.Time values can be optionally suffixed with
h(hours),m(minutes), ors(seconds). Millisecond values can optionally be specified usingms; millisecond values cannot be specified usingh,m, ors.) Integer values can be suffixed withK,M, orG.The names of the options that can be set using this variable are shown in the table that follows. The table also provides brief descriptions of the options, their default values, and (where applicable) their minimum and maximum values.
Name Description Default/Units Minimum/Maximum loop_enable1000 ms 0/4G loop_idleTime to sleep when idle 1000 ms 0/4G loop_busyTime to sleep when more work is waiting 100 ms 0/4G update_batch1 0/4G read_batch4 1/4G idle_batch32 1/4G check_batch8 1/4G check_delayHow often to check for new statistics 10 m 1/4G delete_batch8 0/4G clean_delay1 m 0/4G error_batch4 1/4G error_delay1 m 1/4G evict_batch8 1/4G evict_delayClean LRU cache, from read time 1 m 0/4G cache_limitMaximum amount of memory in bytes used for cached index statistics by this mysqld; clean up the cache when this is exceeded. 32 M 0/4G cache_lowpct90 0/100 zero_totalSetting this to 1 causes all accumulating counters in ndb_index_stat_statusto be reset to 0. Note that the option value is also reset to 0 when this is done.0 0/1 ndb_index_stat_optionwas added in MySQL Cluster NDB 7.2.1. -
Table 18.41 Type and value information for ndb_index_stat_update_freq
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 integer 20 / 0 - 4294967295 DESCRIPTION: How often to query data nodes instead of the statistics cache
How often to query data nodes instead of the statistics cache. For example, a value of
20(the default) means to direct every 20th query to the data nodes.NoteIf
ndb_index_stat_cache_entriesis0, then setting this variable has no effect; in this case, every query is sent directly to the data nodes.This variable was deprecated in MySQL 5.1, and is removed from MySQL Cluster NDB 7.2.16 and later.
-
Table 18.42 Type and value information for ndb_join_pushdown
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Both Yes 5.1.51-ndb-7.2.0 boolean TRUE DESCRIPTION: Enables pushing down of joins to data nodes
Added in MySQL Cluster NDB 7.2.0, this variable controls whether joins on
NDBtables are pushed down to the NDB kernel (data nodes). Previously, a join was handled using multiple accesses ofNDBby the SQL node; however, whenndb_join_pushdownis enabled, a pushable join is sent in its entirety to the data nodes, where it can be distributed among the data nodes and executed in parallel on multiple copies of the data, with a single, merged result being returned to mysqld. This can reduce greatly the number of round trips between an SQL node and the data nodes required to handle such a join.By default,
ndb_join_pushdownis enabled.Conditions for NDB pushdown joins. In order for a join to be pushable, it must meet the following conditions:
Only columns can be compared, and all columns to be joined must use exactly the same data type.
This means that expressions such as
t1.a = t2.a +cannot be pushed down, and that (for example) a join on anconstantINTcolumn and aBIGINTcolumn also cannot be pushed down.Explicit locking is not supported; however, the
NDBstorage engine's characteristic implicit row-based locking is enforced.This means that a join using
FOR UPDATEcannot be pushed down.In order for a join to be pushed down, child tables in the join must be accessed using one of the
ref,eq_ref, orconstaccess methods, or some combination of these methods.Outer joined child tables can only be pushed using
eq_ref.If the root of the pushed join is an
eq_reforconst, only child tables joined byeq_refcan be appended. (A table joined byrefis likely to become the root of another pushed join.)If the query optimizer decides on
Using join cachefor a candidate child table, that table cannot be pushed as a child. However, it may be the root of another set of pushed tables.Joins referencing tables explicitly partitioned by
[LINEAR] HASH,LIST, orRANGEcurrently cannot be pushed down.
You can see whether a given join can be pushed down by checking it with
EXPLAIN; when the join can be pushed down, you can see references to thepushed joinin theExtracolumn of the output, as shown in this example:mysql>
EXPLAIN->SELECT e.first_name, e.last_name, t.title, d.dept_name->FROM employees e->JOIN dept_emp de ON e.emp_no=de.emp_no->JOIN departments d ON d.dept_no=de.dept_no->JOIN titles t ON e.emp_no=t.emp_no\G*************************** 1. row *************************** id: 1 select_type: SIMPLE table: d type: ALL possible_keys: PRIMARY key: NULL key_len: NULL ref: NULL rows: 9 Extra: Parent of 4 pushed join@1 *************************** 2. row *************************** id: 1 select_type: SIMPLE table: de type: ref possible_keys: PRIMARY,emp_no,dept_no key: dept_no key_len: 4 ref: employees.d.dept_no rows: 5305 Extra: Child of 'd' in pushed join@1 *************************** 3. row *************************** id: 1 select_type: SIMPLE table: e type: eq_ref possible_keys: PRIMARY key: PRIMARY key_len: 4 ref: employees.de.emp_no rows: 1 Extra: Child of 'de' in pushed join@1 *************************** 4. row *************************** id: 1 select_type: SIMPLE table: t type: ref possible_keys: PRIMARY,emp_no key: emp_no key_len: 4 ref: employees.de.emp_no rows: 19 Extra: Child of 'e' in pushed join@1 4 rows in set (0.00 sec)NoteIf inner joined child tables are joined by
ref, and the result is ordered or grouped by a sorted index, this index cannot provide sorted rows, which forces writing to a sorted tempfile.Two additional sources of information about pushed join performance are available:
The status variables
Ndb_pushed_queries_defined,Ndb_pushed_queries_dropped,Ndb_pushed_queries_executed, andNdb_pushed_reads(all introduced in MySQL Cluster NDB 7.2.0).The counters in the
ndbinfo.counterstable that belong to theDBSPJkernel block. (These counters and theDBSPJblock were also introduced in MySQL Cluster NDB 7.2.0). See Section 18.5.10.7, “The ndbinfo counters Table”, for information about these counters. See also The DBSPJ Block, in the MySQL Cluster API Developer Guide.
-
Table 18.43 Type and value information for ndb_log_apply_status
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 boolean OFF DESCRIPTION: Whether or not a MySQL server acting as a slave logs mysql.ndb_apply_status updates received from its immediate master in its own binary log, using its own server ID.
A read-only variable which shows whether the server was started with the
--ndb-log-apply-statusoption. -
Table 18.44 Type and value information for ndb_log_bin
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No No Both Yes NDB 7.2 boolean ON DESCRIPTION: Write updates to NDB tables in the binary log. Effective only if binary logging is enabled with --log-bin.
Causes updates to
NDBtables to be written to the binary log. Setting this variable has no effect if binary logging is not already enabled for the server usinglog_bin.ndb_log_bindefaults to 1 (ON); normally, there is never any need to change this value in a production environment. -
Table 18.45 Type and value information for ndb_log_binlog_index
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No No Global Yes NDB 7.2 boolean ON DESCRIPTION: Insert mapping between epochs and binary log positions into the ndb_binlog_index table. Defaults to ON. Effective only if binary logging is enabled on the server.
Causes a mapping of epochs to positions in the binary log to be inserted into the
ndb_binlog_indextable. Setting this variable has no effect if binary logging is not already enabled for the server usinglog_bin. (In addition,ndb_log_binmust not be disabled.)ndb_log_binlog_indexdefaults to1(ON); normally, there is never any need to change this value in a production environment. -
Table 18.46 Type and value information for ndb_log_empty_epochs
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 boolean OFF DESCRIPTION: When enabled, epochs in which there were no changes are written to the ndb_apply_status and ndb_binlog_index tables, even when log_slave_updates is enabled.
When this variable is set to 0, epoch transactions with no changes are not written to the binary log, although a row is still written even for an empty epoch in
ndb_binlog_index. -
Table 18.47 Type and value information for ndb_log_orig
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 boolean OFF DESCRIPTION: Whether the id and epoch of the originating server are recorded in the mysql.ndb_binlog_index table. Set using the --ndb-log-orig option when starting mysqld.
Shows whether the originating server ID and epoch are logged in the
ndb_binlog_indextable. Set using the--ndb-log-origserver option. -
Table 18.48 Type and value information for ndb_log_transaction_id
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global No NDB 7.2 boolean OFF DESCRIPTION: Whether NDB transaction IDs are written into the binary log. (Read-only.)
This read-only, Boolean system variable shows whether a slave mysqld writes NDB transaction IDs in the binary log (required to use “active-active” MySQL Cluster Replication with
NDB$EPOCH_TRANS()conflict detection). To change the setting, use the--ndb-log-transaction-idoption.ndb_log_transaction_idis available in MySQL Cluster NDB 7.2.1 and later. It is not supported in mainline MySQL Server 5.5.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
-
Table 18.49 Type and value information for ndb_optimized_node_selection
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 boolean ON 5.1.22-ndb-6.3.4 integer 3 / 0 - 3 DESCRIPTION: Determines how an SQL node chooses a cluster data node to use as transaction coordinator
There are two forms of optimized node selection, described here:
The SQL node uses promixity to determine the transaction coordinator; that is, the “closest” data node to the SQL node is chosen as the transaction coordinator. For this purpose, a data node having a shared memory connection with the SQL node is considered to be “closest” to the SQL node; the next closest (in order of decreasing proximity) are: TCP connection to
localhost; SCI connection; TCP connection from a host other thanlocalhost.The SQL thread uses distribution awareness to select the data node. That is, the data node housing the cluster partition accessed by the first statement of a given transaction is used as the transaction coordinator for the entire transaction. (This is effective only if the first statement of the transaction accesses no more than one cluster partition.)
This option takes one of the integer values
0,1,2, or3.3is the default. These values affect node selection as follows:0: Node selection is not optimized. Each data node is employed as the transaction coordinator 8 times before the SQL thread proceeds to the next data node.1: Proximity to the SQL node is used to determine the transaction coordinator.2: Distribution awareness is used to select the transaction coordinator. However, if the first statement of the transaction accesses more than one cluster partition, the SQL node reverts to the round-robin behavior seen when this option is set to0.3: If distribution awareness can be employed to determine the transaction coordinator, then it is used; otherwise proximity is used to select the transaction coordinator. (This is the default behavior.)
ndb_report_thresh_binlog_epoch_slipTable 18.50 Type and value information for ndb_report_thresh_binlog_epoch_slip
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No No Yes No NDB 7.2 integer 3 / 0 - 256 DESCRIPTION: This is a threshold on the number of epochs to be behind before reporting binary log status
This is a threshold on the number of epochs to be behind before reporting binary log status. For example, a value of
3(the default) means that if the difference between which epoch has been received from the storage nodes and which epoch has been applied to the binary log is 3 or more, a status message will be sent to the cluster log.ndb_report_thresh_binlog_mem_usageTable 18.51 Type and value information for ndb_report_thresh_binlog_mem_usage
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes No No Yes No NDB 7.2 integer 10 / 0 - 10 DESCRIPTION: This is a threshold on the percentage of free memory remaining before reporting binary log status
This is a threshold on the percentage of free memory remaining before reporting binary log status. For example, a value of
10(the default) means that if the amount of available memory for receiving binary log data from the data nodes falls below 10%, a status message will be sent to the cluster log.-
Table 18.52 Type and value information for slave_allow_batching
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global Yes NDB 7.2 boolean off DESCRIPTION: Turns update batching on and off for a replication slave
Whether or not batched updates are enabled on MySQL Cluster replication slaves.
This variable is available for mysqld only as supplied with MySQL Cluster or built from the MySQL Cluster sources. For more information, see Section 18.6.6, “Starting MySQL Cluster Replication (Single Replication Channel)”.
Setting this variable had no effect in MySQL Cluster NDB 7.2 prior to MySQL Cluster NDB 7.2.10. (Bug #15953730)
-
Table 18.53 Type and value information for ndb_table_no_logging
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Session Yes NDB 7.2 boolean FALSE DESCRIPTION: NDB tables created when this setting is enabled are not checkpointed to disk (although table schema files are created). The setting in effect when the table is created with or altered to use NDBCLUSTER persists for the lifetime of the table.
When this variable is set to
ONor1, it causesNDBtables not to be checkpointed to disk. More specifically, this setting applies to tables which are created or altered usingENGINE NDBwhenndb_table_no_loggingis enabled, and continues to apply for the lifetime of the table, even ifndb_table_no_loggingis later changed. Suppose thatA,B,C, andDare tables that we create (and perhaps also alter), and that we also change the setting forndb_table_no_loggingas shown here:SET @@ndb_table_no_logging = 1; CREATE TABLE A ... ENGINE NDB; CREATE TABLE B ... ENGINE MYISAM; CREATE TABLE C ... ENGINE MYISAM; ALTER TABLE B ENGINE NDB; SET @@ndb_table_no_logging = 0; CREATE TABLE D ... ENGINE NDB; ALTER TABLE C ENGINE NDB; SET @@ndb_table_no_logging = 1;
After the previous sequence of events, tables
AandBare not checkpointed;Awas created withENGINE NDBand B was altered to useNDB, both whilendb_table_no_loggingwas enabled. However, tablesCandDare logged;Cwas altered to useNDBandDwas created usingENGINE NDB, both whilendb_table_no_loggingwas disabled. Settingndb_table_no_loggingback to1orONdoes not cause tableCorDto be checkpointed.Notendb_table_no_logginghas no effect on the creation ofNDBtable schema files; to suppress these, usendb_table_temporaryinstead. -
Table 18.54 Type and value information for ndb_table_temporary
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Session Yes NDB 7.2 boolean FALSE DESCRIPTION: NDB tables are not persistent on disk: no schema files are created and the tables are not logged
When set to
ONor1, this variable causesNDBtables not to be written to disk: This means that no table schema files are created, and that the tables are not logged.NoteSetting this variable currently has no effect in MySQL Cluster NDB 7.0 and later. This is a known issue; see Bug #34036.
-
Table 18.55 Type and value information for ndb_use_copying_alter_table
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Both No DESCRIPTION: Use copying ALTER TABLE operations in MySQL Cluster
Forces
NDBto use copying of tables in the event of problems with onlineALTER TABLEoperations. The default value isOFF. -
Table 18.56 Type and value information for ndb_use_exact_count
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Both Yes NDB 7.2 boolean ON 5.1.47-ndb-7.1.8 boolean OFF DESCRIPTION: Use exact row count when planning queries
Forces
NDBto use a count of records duringSELECT COUNT(*)query planning to speed up this type of query. The default value isOFF, which allows for faster queries overall. -
Table 18.57 Type and value information for ndb_use_transactions
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Both Yes NDB 7.2 boolean ON DESCRIPTION: Forces NDB to use a count of records during SELECT COUNT(*) query planning to speed up this type of query
You can disable
NDBtransaction support by setting this variable's values toOFF(not recommended). The default isON. -
Table 18.58 Type and value information for ndb_version
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global No NDB 7.2 string DESCRIPTION: Shows build and NDB engine version as an integer.
NDBengine version, as a composite integer. -
Table 18.59 Type and value information for ndb_version_string
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global No NDB 7.2 string DESCRIPTION: Shows build information including NDB engine version in ndb-x.y.z format.
NDBengine version inndb-format.x.y.z -
Table 18.60 Type and value information for server_id_bits
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No Yes Global No NDB 7.2 integer 32 / 7 - 32 DESCRIPTION: The effective value of server_id if the server was started with the --server-id-bits option set to a nondefault value.
The effective value of
server_idif the server was started with the--server-id-bitsoption set to a nondefault value.If the value of
server_idgreater than or equal to 2 to the power ofserver_id_bits, mysqld refuses to start.This system variable is supported only by MySQL Cluster.
server_id_bitsis not supported by the standard MySQL Server. -
Table 18.61 Type and value information for transaction_allow_batching
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Session Yes NDB 7.2 boolean FALSE DESCRIPTION: Allows batching of statements within a transaction. Disable AUTOCOMMIT to use.
When set to
1orON, this variable enables batching of statements within the same transaction. To use this variable,autocommitmust first be disabled by setting it to0orOFF; otherwise, settingtransaction_allow_batchinghas no effect.It is safe to use this variable with transactions that performs writes only, as having it enabled can lead to reads from the “before” image. You should ensure that any pending transactions are committed (using an explicit
COMMITif desired) before issuing aSELECT.Importanttransaction_allow_batchingshould not be used whenever there is the possibility that the effects of a given statement depend on the outcome of a previous statement within the same transaction.This variable is currently supported for MySQL Cluster only.
ImportantDue an issue in the MySQL Cluster NDB 7.2 codebase (Bug #64697) prior to General Availability, this variable is not available prior to MySQL Cluster NDB 7.2.6.
The system variables in the following list all relate to the
ndbinfo information
database.
-
Table 18.62 Type and value information for ndbinfo_database
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global No NDB 7.2 string ndbinfo DESCRIPTION: The name used for the NDB information database; read only.
Shows the name used for the
NDBinformation database; the default isndbinfo. This is a read-only variable whose value is determined at compile time; you can set it by starting the server using--ndbinfo-database=, which sets the value shown for this variable but does not actually change the name used for the NDB information database.name -
Table 18.63 Type and value information for ndbinfo_max_bytes
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No No Both Yes NDB 7.2 integer 0 / - DESCRIPTION: Used for debugging only.
Used in testing and debugging only.
-
Table 18.64 Type and value information for ndbinfo_max_rows
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No No Both Yes NDB 7.2 integer 10 / - DESCRIPTION: Used for debugging only.
Used in testing and debugging only.
-
Table 18.65 Type and value information for ndbinfo_offline
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global Yes NDB 7.2 boolean OFF DESCRIPTION: Put the ndbinfo database into offline mode, in which no rows are returned from tables or views.
Place the
ndbinfodatabase into offline mode, in which tables and views can be opened even when they do not actually exist, or when they exist but have different definitions inNDB. No rows are returned from such tables (or views). -
Whether or not the
ndbinfodatabase's underlying internal tables are shown in themysqlclient. The default isOFF. -
Table 18.67 Type and value information for ndbinfo_table_prefix
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes Yes Yes No No Both Yes NDB 7.2 string ndb$ DESCRIPTION: The prefix to use for naming ndbinfo internal base tables
The prefix used in naming the ndbinfo database's base tables (normally hidden, unless exposed by setting
ndbinfo_show_hidden). This is a read-only variable whose default value is “ndb$”. You can start the server with the--ndbinfo-table-prefixoption, but this merely sets the variable and does not change the actual prefix used to name the hidden base tables; the prefix itself is determined at compile time. -
Table 18.68 Type and value information for ndbinfo_version
Command Line System Variable Status Variable Option File Scope Dynamic From Version Type Default, Range Notes No Yes No No Global No NDB 7.2 string DESCRIPTION: The version of the ndbinfo engine; read only.
Shows the version of the
ndbinfoengine in use; read-only.
This section provides detailed information about MySQL server
status variables that relate to MySQL Cluster and the
NDB storage engine. For status
variables not specific to MySQL Cluster, and for general
information on using status variables, see
Section 5.1.6, “Server Status Variables”.
The MySQL server can ask the
NDBCLUSTERstorage engine if it knows about a table with a given name. This is called discovery.Handler_discoverindicates the number of times that tables have been discovered using this mechanism.Ndb_api_bytes_sent_count_sessionAmount of data (in bytes) sent to the data nodes in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_bytes_sent_count_slaveAmount of data (in bytes) sent to the data nodes by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Amount of data (in bytes) sent to the data nodes by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_bytes_received_count_sessionAmount of data (in bytes) received from the data nodes in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_bytes_received_count_slaveAmount of data (in bytes) received from the data nodes by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Amount of data (in bytes) received from the data nodes by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_event_data_count_injectorThe number of row change events received by the NDB binlog injector thread.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of row change events received by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_event_nondata_count_injectorThe number of events received, other than row change events, by the NDB binary log injector thread.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of events received, other than row change events, by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_event_bytes_count_injectorThe number of bytes of events received by the NDB binlog injector thread.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of bytes of events received by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of operations in this client session based on or using primary keys. This includes operations on blob tables, implicit unlock operations, and auto-increment operations, as well as user-visible primary key operations.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of operations by this slave based on or using primary keys. This includes operations on blob tables, implicit unlock operations, and auto-increment operations, as well as user-visible primary key operations.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of operations by this MySQL Server (SQL node) based on or using primary keys. This includes operations on blob tables, implicit unlock operations, and auto-increment operations, as well as user-visible primary key operations.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_pruned_scan_count_sessionThe number of scans in this client session that have been pruned to a single partition.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_pruned_scan_count_slaveThe number of scans by this slave that have been pruned to a single partition.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of scans by this MySQL Server (SQL node) that have been pruned to a single partition.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_range_scan_count_sessionThe number of range scans that have been started in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_range_scan_count_slaveThe number of range scans that have been started by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of range scans that have been started by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_read_row_count_sessionThe total number of rows that have been read in this client session. This includes all rows read by any primary key, unique key, or scan operation made in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The total number of rows that have been read by this slave. This includes all rows read by any primary key, unique key, or scan operation made by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The total number of rows that have been read by this MySQL Server (SQL node). This includes all rows read by any primary key, unique key, or scan operation made by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_scan_batch_count_sessionThe number of batches of rows received in this client session. 1 batch is defined as 1 set of scan results from a single fragment.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_scan_batch_count_slaveThe number of batches of rows received by this slave. 1 batch is defined as 1 set of scan results from a single fragment.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of batches of rows received by this MySQL Server (SQL node). 1 batch is defined as 1 set of scan results from a single fragment.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_table_scan_count_sessionThe number of table scans that have been started in this client session, including scans of internal tables,.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_table_scan_count_slaveThe number of table scans that have been started by this slave, including scans of internal tables,.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of table scans that have been started by this MySQL Server (SQL node), including scans of internal tables,.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_abort_count_sessionThe number of transactions aborted in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_abort_count_slaveThe number of transactions aborted by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of transactions aborted by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_close_count_sessionThe number of transactions closed in this client session. This value may be greater than the sum of
Ndb_api_trans_commit_count_sessionandNdb_api_trans_abort_count_session, since some transactions may have been rolled back.Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_close_count_slaveThe number of transactions closed by this slave. This value may be greater than the sum of
Ndb_api_trans_commit_count_slaveandNdb_api_trans_abort_count_slave, since some transactions may have been rolled back.Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of transactions closed by this MySQL Server (SQL node). This value may be greater than the sum of
Ndb_api_trans_commit_countandNdb_api_trans_abort_count, since some transactions may have been rolled back.Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_commit_count_sessionThe number of transactions committed in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_commit_count_slaveThe number of transactions committed by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of transactions committed by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_local_read_row_count_sessionThe total number of rows that have been read in this client session. This includes all rows read by any primary key, unique key, or scan operation made in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_local_read_row_count_slaveThe total number of rows that have been read by this slave. This includes all rows read by any primary key, unique key, or scan operation made by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_local_read_row_countThe total number of rows that have been read by this MySQL Server (SQL node). This includes all rows read by any primary key, unique key, or scan operation made by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_start_count_sessionThe number of transactions started in this client session.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_trans_start_count_slaveThe number of transactions started by this slave.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of transactions started by this MySQL Server (SQL node).
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of operations in this client session based on or using unique keys.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of operations by this slave based on or using unique keys.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
The number of operations by this MySQL Server (SQL node) based on or using unique keys.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_exec_complete_count_sessionThe number of times a thread has been blocked in this client session while waiting for execution of an operation to complete. This includes all
execute()calls as well as implicit implicit executes for blob and auto-increment operations not visible to clients.Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_exec_complete_count_slaveThe number of times a thread has been blocked by this slave while waiting for execution of an operation to complete. This includes all
execute()calls as well as implicit implicit executes for blob and auto-increment operations not visible to clients.Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_exec_complete_countThe number of times a thread has been blocked by this MySQL Server (SQL node) while waiting for execution of an operation to complete. This includes all
execute()calls as well as implicit implicit executes for blob and auto-increment operations not visible to clients.Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_meta_request_count_sessionThe number of times a thread has been blocked in this client session waiting for a metadata-based signal, such as is expected for DDL requests, new epochs, and seizure of transaction records.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_meta_request_count_slaveThe number of times a thread has been blocked by this slave waiting for a metadata-based signal, such as is expected for DDL requests, new epochs, and seizure of transaction records.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_meta_request_countThe number of times a thread has been blocked by this MySQL Server (SQL node) waiting for a metadata-based signal, such as is expected for DDL requests, new epochs, and seizure of transaction records.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_nanos_count_sessionTotal time (in nanoseconds) spent in this client session waiting for any type of signal from the data nodes.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_nanos_count_slaveTotal time (in nanoseconds) spent by this slave waiting for any type of signal from the data nodes.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Total time (in nanoseconds) spent by this MySQL Server (SQL node) waiting for any type of signal from the data nodes.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_scan_result_count_sessionThe number of times a thread has been blocked in this client session while waiting for a scan-based signal, such as when waiting for more results from a scan, or when waiting for a scan to close.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it relates to the current session only, and is not affected by any other clients of this mysqld.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_scan_result_count_slaveThe number of times a thread has been blocked by this slave while waiting for a scan-based signal, such as when waiting for more results from a scan, or when waiting for a scan to close.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope. If this MySQL server does not act as a replication slave, or does not use NDB tables, this value is always 0.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
Ndb_api_wait_scan_result_countThe number of times a thread has been blocked by this MySQL Server (SQL node) while waiting for a scan-based signal, such as when waiting for more results from a scan, or when waiting for a scan to close.
Although this variable can be read using either
SHOW GLOBAL STATUSorSHOW SESSION STATUS, it is effectively global in scope.For more information, see Section 18.5.15, “NDB API Statistics Counters and Variables”.
If the server is acting as a MySQL Cluster node, then the value of this variable its node ID in the cluster.
If the server is not part of a MySQL Cluster, then the value of this variable is 0.
If the server is part of a MySQL Cluster, the value of this variable is the host name or IP address of the Cluster management server from which it gets its configuration data.
If the server is not part of a MySQL Cluster, then the value of this variable is an empty string.
If the server is part of a MySQL Cluster, the value of this variable is the number of the port through which it is connected to the Cluster management server from which it gets its configuration data.
If the server is not part of a MySQL Cluster, then the value of this variable is 0.
Used in MySQL Cluster Replication conflict resolution, this variable shows the number of times that a row was not applied on the current SQL node due to “greatest timestamp wins” conflict resolution since the last time that this mysqld was started.
For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Used in MySQL Cluster Replication conflict resolution, this variable shows the number of times that a row was not applied as the result of “same timestamp wins” conflict resolution on a given mysqld since the last time it was restarted.
For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Used in MySQL Cluster Replication conflict resolution, this variable shows the number of rows found to be in conflict using
NDB$EPOCH()conflict resolution on a given mysqld since the last time it was restarted.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Used in MySQL Cluster Replication conflict resolution, this variable shows the number of rows found to be in conflict using
NDB$EPOCH_TRANS()conflict resolution on a given mysqld since the last time it was restarted.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Ndb_conflict_trans_row_conflict_countUsed in MySQL Cluster Replication conflict resolution, this status variable shows the number of rows found to be directly in-conflict by a transactional conflict function on a given mysqld since the last time it was restarted.
Currently, the only transactional conflict detection function supported by MySQL Cluster is NDB$EPOCH_TRANS(), so this status variable is effectively the same as
Ndb_conflict_fn_epoch_trans.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Ndb_conflict_trans_row_reject_countUsed in MySQL Cluster Replication conflict resolution, this status variable shows the total number of rows realigned due to being determined as conflicting by a transactional conflict detection function. This includes not only
Ndb_conflict_trans_row_conflict_count, but any rows in or dependent on conflicting transactions.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Ndb_conflict_trans_reject_countUsed in MySQL Cluster Replication conflict resolution, this status variable shows the number of transactions found to be in conflict by a transactional conflict detection function.
For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Ndb_conflict_trans_detect_iter_countUsed in MySQL Cluster Replication conflict resolution, this shows the number of internal iterations required to commit an epoch transaction. Should be (slightly) greater than or equal to
Ndb_conflict_trans_conflict_commit_count.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Ndb_conflict_trans_conflict_commit_countUsed in MySQL Cluster Replication conflict resolution, this shows the number of epoch transactions committed after they required transactional conflict handling.
For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Provides the number of round trips to the
NDBkernel made by operations.If the server is part of a MySQL Cluster, the value of this variable is the number of data nodes in the cluster.
If the server is not part of a MySQL Cluster, then the value of this variable is 0.
The total number of joins pushed down to the NDB kernel for distributed handling on the data nodes. Note that joins tested using
EXPLAINthat can be pushed down contribute to this number. Added in MySQL Cluster NDB 7.2.0.The number of joins that were pushed down to the NDB kernel but that could not be handled there. Added in MySQL Cluster NDB 7.2.0.
The number of joins successfully pushed down to
NDBand executed there. Added in MySQL Cluster NDB 7.2.0.The number of rows returned to mysqld from the NDB kernel by joins that were pushed down. Note that executing
EXPLAINon joins that can be pushed down toNDBdoes not add to this number. Added in MySQL Cluster NDB 7.2.0.This variable holds a count of the number of scans executed by
NDBCLUSTERsince the MySQL Cluster was last started whereNDBCLUSTERwas able to use partition pruning.Using this variable together with
Ndb_scan_countcan be helpful in schema design to maximize the ability of the server to prune scans to a single table partition, thereby involving only a single data node.This variable holds a count of the total number of scans executed by
NDBCLUSTERsince the MySQL Cluster was last started.
TCP/IP is the default transport mechanism for all connections between nodes in a MySQL Cluster. Normally it is not necessary to define TCP/IP connections; MySQL Cluster automatically sets up such connections for all data nodes, management nodes, and SQL or API nodes.
For an exception to this rule, see Section 18.3.3.10, “MySQL Cluster TCP/IP Connections Using Direct Connections”.
To override the default connection parameters, it is necessary
to define a connection using one or more
[tcp] sections in the
config.ini file. Each
[tcp] section explicitly defines a TCP/IP
connection between two MySQL Cluster nodes, and must contain at
a minimum the parameters
NodeId1 and
NodeId2, as well as any
connection parameters to override.
It is also possible to change the default values for these
parameters by setting them in the [tcp
default] section.
Any [tcp] sections in the
config.ini file should be listed
last, following all other sections in the
file. However, this is not required for a [tcp
default] section. This requirement is a known issue
with the way in which the config.ini file
is read by the MySQL Cluster management server.
Connection parameters which can be set in
[tcp] and [tcp default]
sections of the config.ini file are listed
here:
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric [none] ... N To identify a connection between two nodes it is necessary to provide their node IDs in the
[tcp]section of the configuration file as the values ofNodeId1andNodeId2. These are the same uniqueIdvalues for each of these nodes as described in Section 18.3.3.7, “Defining SQL and Other API Nodes in a MySQL Cluster”. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric [none] ... N To identify a connection between two nodes it is necessary to provide their node IDs in the
[tcp]section of the configuration file as the values ofNodeId1andNodeId2. These are the same uniqueIdvalues for each of these nodes as described in Section 18.3.3.7, “Defining SQL and Other API Nodes in a MySQL Cluster”. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N The
HostName1andHostName2parameters can be used to specify specific network interfaces to be used for a given TCP connection between two nodes. The values used for these parameters can be host names or IP addresses. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N The
HostName1andHostName2parameters can be used to specify specific network interfaces to be used for a given TCP connection between two nodes. The values used for these parameters can be host names or IP addresses. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 0 0 - 4294967039 (0xFFFFFEFF) N When more than this many unsent bytes are in the send buffer, the connection is considered overloaded.
This parameter can be used to determine the amount of unsent data that must be present in the send buffer before the connection is considered overloaded. See Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”, for more information.
In some older releases, the effective value of this parameter was limited by the size of
SendBufferMemory; in MySQL Cluster NDB 7.2, the actual value forOverloadLimit(up to the stated maximum of 4G) is used instead. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 2M 256K - 4294967039 (0xFFFFFEFF) N TCP transporters use a buffer to store all messages before performing the send call to the operating system. When this buffer reaches 64KB its contents are sent; these are also sent when a round of messages have been executed. To handle temporary overload situations it is also possible to define a bigger send buffer.
If this parameter is set explicitly, then the memory is not dedicated to each transporter; instead, the value used denotes the hard limit for how much memory (out of the total available memory—that is,
TotalSendBufferMemory) that may be used by a single transporter. For more information about configuring dynamic transporter send buffer memory allocation in MySQL Cluster, see Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”.The default size of the send buffer in MySQL Cluster NDB 7.2 is 2MB, which is the size recommended in most situations. The minimum size is 64 KB; the theoretical maximum is 4 GB.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean [see text] true, false N To be able to retrace a distributed message datagram, it is necessary to identify each message. When this parameter is set to
Y, message IDs are transported over the network. This feature is disabled by default in production builds, and enabled in-debugbuilds. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N This parameter is a boolean parameter (enabled by setting it to
Yor1, disabled by setting it toNor0). It is disabled by default. When it is enabled, checksums for all messages are calculated before they placed in the send buffer. This feature ensures that messages are not corrupted while waiting in the send buffer, or by the transport mechanism. This formerly specified the port number to be used for listening for connections from other nodes. This parameter is deprecated and should no longer be used; use the
ServerPortdata node configuration parameter for this purpose instead.-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 2M 16K - 4294967039 (0xFFFFFEFF) N Specifies the size of the buffer used when receiving data from the TCP/IP socket.
The default value of this parameter is 2MB. The minimum possible value is 16KB; the theoretical maximum is 4GB.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 70080 1 - 2G N Determines the size of the receive buffer set during TCP transporter initialization. The default is recommended for most common usage cases.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 71540 1 - 2G N Determines the size of the send buffer set during TCP transporter initialization. The default is recommended for most common usage cases.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 0 - 2G N Determines the size of the memory set during TCP transporter initialization. The default is recommended for most common usage cases.
Setting this parameter to
TRUEor1bindsIP_ADDR_ANYso that connections can be made from anywhere (for autogenerated connections). The default isFALSE(0).
Setting up a cluster using direct connections between data nodes
requires specifying explicitly the crossover IP addresses of the
data nodes so connected in the [tcp] section
of the cluster config.ini file.
In the following example, we envision a cluster with at least
four hosts, one each for a management server, an SQL node, and
two data nodes. The cluster as a whole resides on the
172.23.72.* subnet of a LAN. In addition to
the usual network connections, the two data nodes are connected
directly using a standard crossover cable, and communicate with
one another directly using IP addresses in the
1.1.0.* address range as shown:
# Management Server [ndb_mgmd] Id=1 HostName=172.23.72.20 # SQL Node [mysqld] Id=2 HostName=172.23.72.21 # Data Nodes [ndbd] Id=3 HostName=172.23.72.22 [ndbd] Id=4 HostName=172.23.72.23 # TCP/IP Connections [tcp] NodeId1=3 NodeId2=4 HostName1=1.1.0.1 HostName2=1.1.0.2
The HostName1 and
HostName2 parameters are
used only when specifying direct connections.
The use of direct TCP connections between data nodes can improve the cluster's overall efficiency by enabling the data nodes to bypass an Ethernet device such as a switch, hub, or router, thus cutting down on the cluster's latency. It is important to note that to take the best advantage of direct connections in this fashion with more than two data nodes, you must have a direct connection between each data node and every other data node in the same node group.
MySQL Cluster attempts to use the shared memory transporter and
configure it automatically where possible.
[shm] sections in the
config.ini file explicitly define
shared-memory connections between nodes in the cluster. When
explicitly defining shared memory as the connection method, it
is necessary to define at least
NodeId1,
NodeId2, and
ShmKey. All other
parameters have default values that should work well in most
cases.
SHM functionality is considered experimental only. It is not officially supported in any current MySQL Cluster release, and testing results indicate that SHM performance is not appreciably greater than when using TCP/IP for the transporter.
For these reasons, you must determine for yourself or by using our free resources (forums, mailing lists) whether SHM can be made to work correctly in your specific case.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric [none] ... N To identify a connection between two nodes it is necessary to provide node identifiers for each of them, as
NodeId1andNodeId2. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric [none] ... N To identify a connection between two nodes it is necessary to provide node identifiers for each of them, as
NodeId1andNodeId2. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N The
HostName1andHostName2parameters can be used to specify specific network interfaces to be used for a given SHM connection between two nodes. The values used for these parameters can be host names or IP addresses. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N The
HostName1andHostName2parameters can be used to specify specific network interfaces to be used for a given SHM connection between two nodes. The values used for these parameters can be host names or IP addresses. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 0 0 - 4294967039 (0xFFFFFEFF) N When more than this many unsent bytes are in the send buffer, the connection is considered overloaded.
This parameter can be used to determine the amount of unsent data that must be present in the send buffer before the connection is considered overloaded. See Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”, for more information.
In some older releases, the effective value of this parameter was limited by the size of
SendBufferMemory; in MySQL Cluster NDB 7.2, the actual value forOverloadLimit(up to the stated maximum of 4G) is used instead. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 0 - 4294967039 (0xFFFFFEFF) N When setting up shared memory segments, a node ID, expressed as an integer, is used to identify uniquely the shared memory segment to use for the communication. There is no default value.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 1M 64K - 4294967039 (0xFFFFFEFF) N Each SHM connection has a shared memory segment where messages between nodes are placed by the sender and read by the reader. The size of this segment is defined by
ShmSize. The default value is 1MB. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N To retrace the path of a distributed message, it is necessary to provide each message with a unique identifier. Setting this parameter to
Ycauses these message IDs to be transported over the network as well. This feature is disabled by default in production builds, and enabled in-debugbuilds. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean true true, false N This parameter is a boolean (
Y/N) parameter which is disabled by default. When it is enabled, checksums for all messages are calculated before being placed in the send buffer.This feature prevents messages from being corrupted while waiting in the send buffer. It also serves as a check against data being corrupted during transport.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 0 - 4294967039 (0xFFFFFEFF) N When using the shared memory transporter, a process sends an operating system signal to the other process when there is new data available in the shared memory. Should that signal conflict with an existing signal, this parameter can be used to change it. This is a possibility when using SHM due to the fact that different operating systems use different signal numbers.
The default value of
SigNumis 0; therefore, it must be set to avoid errors in the cluster log when using the shared memory transporter. Typically, this parameter is set to 10 in the[shm default]section of theconfig.inifile.
[sci] sections in the
config.ini file explicitly define SCI
(Scalable Coherent Interface) connections between cluster nodes.
Using SCI transporters in MySQL Cluster is supported only when
the MySQL binaries are built using
--with-ndb-sci=.
The /your/path/to/SCIpath should point to a directory
that contains at a minimum lib and
include directories containing SISCI
libraries and header files. (See
Section 18.3.4, “Using High-Speed Interconnects with MySQL Cluster” for more
information about SCI.)
In addition, SCI requires specialized hardware.
It is strongly recommended to use SCI Transporters only for communication between ndbd processes. Note also that using SCI Transporters means that the ndbd processes never sleep. For this reason, SCI Transporters should be used only on machines having at least two CPUs dedicated for use by ndbd processes. There should be at least one CPU per ndbd process, with at least one CPU left in reserve to handle operating system activities.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric [none] ... N To identify a connection between two nodes it is necessary to provide node identifiers for each of them, as
NodeId1andNodeId2. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 numeric [none] ... N To identify a connection between two nodes it is necessary to provide node identifiers for each of them, as
NodeId1andNodeId2. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 0 - 4294967039 (0xFFFFFEFF) N This identifies the SCI node ID on the first Cluster node (identified by
NodeId1). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 0 - 4294967039 (0xFFFFFEFF) N It is possible to set up SCI Transporters for failover between two SCI cards which then should use separate networks between the nodes. This identifies the node ID and the second SCI card to be used on the first node.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned [none] 0 - 4294967039 (0xFFFFFEFF) N This identifies the SCI node ID on the second Cluster node (identified by
NodeId2). -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 0 0 - 4294967039 (0xFFFFFEFF) N When using two SCI cards to provide failover, this parameter identifies the second SCI card to be used on the second node.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N The
HostName1andHostName2parameters can be used to specify specific network interfaces to be used for a given SCI connection between two nodes. The values used for these parameters can be host names or IP addresses. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 name or IP address [none] ... N The
HostName1andHostName2parameters can be used to specify specific network interfaces to be used for a given SCI connection between two nodes. The values used for these parameters can be host names or IP addresses. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 10M 64K - 4294967039 (0xFFFFFEFF) N Each SCI transporter has a shared memory segment used for communication between the two nodes. Setting the size of this segment to the default value of 1MB should be sufficient for most applications. Using a smaller value can lead to problems when performing many parallel inserts; if the shared buffer is too small, this can also result in a crash of the ndbd process.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 unsigned 8K 128 - 32K N A small buffer in front of the SCI media stores messages before transmitting them over the SCI network. By default, this is set to 8KB. Our benchmarks show that performance is best at 64KB but 16KB reaches within a few percent of this, and there was little if any advantage to increasing it beyond 8KB.
-
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean true true, false N To trace a distributed message it is necessary to identify each message uniquely. When this parameter is set to
Y, message IDs are transported over the network. This feature is disabled by default in production builds, and enabled in-debugbuilds. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 boolean false true, false N This parameter is a boolean value, and is disabled by default. When
Checksumis enabled, checksums are calculated for all messages before they are placed in the send buffer. This feature prevents messages from being corrupted while waiting in the send buffer. It also serves as a check against data being corrupted during transport. -
Effective Version Type/Units Default Range/Values Restart Type NDB 7.2.0 bytes 0 0 - 4294967039 (0xFFFFFEFF) N When more than this many unsent bytes are in the send buffer, the connection is considered overloaded. See Section 18.3.3.13, “Configuring MySQL Cluster Send Buffer Parameters”, for more information.
Formerly, the NDB kernel employed a send buffer whose size was fixed at 2MB for each node in the cluster, this buffer being allocated when the node started. Because the size of this buffer could not be changed after the cluster was started, it was necessary to make it large enough in advance to accommodate the maximum possible load on any transporter socket. However, this was an inefficient use of memory, since much of it often went unused, and could result in large amounts of resources being wasted when scaling up to many API nodes.
This problem was eventually solved (in MySQL Cluster NDB 7.0) by employing a unified send buffer whose memory is allocated dynamically from a pool shared by all transporters. This means that the size of the send buffer can be adjusted as necessary. Configuration of the unified send buffer can accomplished by setting the following parameters:
TotalSendBufferMemory. This parameter can be set for all types of MySQL Cluster nodes—that is, it can be set in the
[ndbd],[mgm], and[api](or[mysql]) sections of theconfig.inifile. It represents the total amount of memory (in bytes) to be allocated by each node for which it is set for use among all configured transporters. If set, its minimum is 256KB; the maximum is 4294967039.To be backward-compatible with existing configurations, this parameter takes as its default value the sum of the maximum send buffer sizes of all configured transporters, plus an additional 32KB (one page) per transporter. The maximum depends on the type of transporter, as shown in the following table:
Transporter Maximum Send Buffer Size (bytes) TCP SendBufferMemory(default = 2M)SCI SendLimit(default = 8K) plus 16KSHM 20K This enables existing configurations to function in close to the same way as they did with MySQL Cluster NDB 6.3 and earlier, with the same amount of memory and send buffer space available to each transporter. However, memory that is unused by one transporter is not available to other transporters.
OverloadLimit. This parameter is used in the
config.inifile[tcp]section, and denotes the amount of unsent data (in bytes) that must be present in the send buffer before the connection is considered overloaded. When such an overload condition occurs, transactions that affect the overloaded connection fail with NDB API Error 1218 (Send Buffers overloaded in NDB kernel) until the overload status passes. The default value is 0, in which case the effective overload limit is calculated asSendBufferMemory * 0.8for a given connection. The maximum value for this parameter is 4G.SendBufferMemory. This value denotes a hard limit for the amount of memory that may be used by a single transporter out of the entire pool specified by
TotalSendBufferMemory. However, the sum ofSendBufferMemoryfor all configured transporters may be greater than theTotalSendBufferMemorythat is set for a given node. This is a way to save memory when many nodes are in use, as long as the maximum amount of memory is never required by all transporters at the same time.ReservedSendBufferMemory. This optional data node parameter, if set, gives an amount of memory (in bytes) that is reserved for connections between data nodes; this memory is not allocated to send buffers used for communications with management servers or API nodes. This provides a way to protect the cluster against misbehaving API nodes that use excess send memory and thus cause failures in communications internally in the NDB kernel. If set, its the minimum permitted value for this parameters is 256KB; the maximum is 4294967039.
Even before design of NDBCLUSTER
began in 1996, it was evident that one of the major problems to be
encountered in building parallel databases would be communication
between the nodes in the network. For this reason,
NDBCLUSTER was designed from the very
beginning to permit the use of a number of different data
transport mechanisms. In this Manual, we use the term
transporter for these.
The MySQL Cluster codebase provides for four different transporters:
TCP/IP using 100 Mbps or gigabit Ethernet, as discussed in Section 18.3.3.9, “MySQL Cluster TCP/IP Connections”.
Direct (machine-to-machine) TCP/IP; although this transporter uses the same TCP/IP protocol as mentioned in the previous item, it requires setting up the hardware differently and is configured differently as well. For this reason, it is considered a separate transport mechanism for MySQL Cluster. See Section 18.3.3.10, “MySQL Cluster TCP/IP Connections Using Direct Connections”, for details.
Shared memory (SHM). For more information about SHM, see Section 18.3.3.11, “MySQL Cluster Shared-Memory Connections”.
NoteSHM is considered experimental only, and is not officially supported.
Scalable Coherent Interface (SCI), as described in the next section of this chapter, Section 18.3.3.12, “SCI Transport Connections in MySQL Cluster”.
Most users today employ TCP/IP over Ethernet because it is ubiquitous. TCP/IP is also by far the best-tested transporter for use with MySQL Cluster.
We are working to make sure that communication with the ndbd process is made in “chunks” that are as large as possible because this benefits all types of data transmission.
For users who desire it, it is also possible to use cluster interconnects to enhance performance even further. There are two ways to achieve this: Either a custom transporter can be designed to handle this case, or you can use socket implementations that bypass the TCP/IP stack to one extent or another. We have experimented with both of these techniques using the SCI (Scalable Coherent Interface) technology developed by Dolphin Interconnect Solutions.
It is possible employing Scalable Coherent Interface (SCI) technology to achieve a significant increase in connection speeds and throughput between MySQL Cluster data and SQL nodes. To use SCI, it is necessary to obtain and install Dolphin SCI network cards and to use the drivers and other software supplied by Dolphin. You can get information on obtaining these, from Dolphin Interconnect Solutions. SCI SuperSocket or SCI Transporter support is available for 32-bit and 64-bit Linux, Solaris, Windows, and other platforms. See the Dolphin documentation referenced later in this section for more detailed information regarding platforms supported for SCI.
Once you have acquired the required Dolphin hardware and software, you can obtain detailed information on how to adapt a MySQL Cluster configured for normal TCP/IP communication to use SCI from the from the Dolphin SCI online documentation.
The ndbd process has a number of simple constructs which are used to access the data in a MySQL Cluster. We have created a very simple benchmark to check the performance of each of these and the effects which various interconnects have on their performance.
There are four access methods:
Primary key access. This is access of a record through its primary key. In the simplest case, only one record is accessed at a time, which means that the full cost of setting up a number of TCP/IP messages and a number of costs for context switching are borne by this single request. In the case where multiple primary key accesses are sent in one batch, those accesses share the cost of setting up the necessary TCP/IP messages and context switches. If the TCP/IP messages are for different destinations, additional TCP/IP messages need to be set up.
Unique key access. Unique key accesses are similar to primary key accesses, except that a unique key access is executed as a read on an index table followed by a primary key access on the table. However, only one request is sent from the MySQL Server, and the read of the index table is handled by ndbd. Such requests also benefit from batching.
Full table scan. When no indexes exist for a lookup on a table, a full table scan is performed. This is sent as a single request to the ndbd process, which then divides the table scan into a set of parallel scans on all cluster ndbd processes. In future versions of MySQL Cluster, an SQL node will be able to filter some of these scans.
Range scan using ordered index. When an ordered index is used, it performs a scan in the same manner as the full table scan, except that it scans only those records which are in the range used by the query transmitted by the MySQL server (SQL node). All partitions are scanned in parallel when all bound index attributes include all attributes in the partitioning key.
With benchmarks developed internally by MySQL for testing simple and batched primary and unique key accesses, we have found that using SCI sockets improves performance by approximately 100% over TCP/IP, except in rare instances when communication performance is not an issue. This can occur when scan filters make up most of processing time or when very large batches of primary key accesses are achieved. In that case, the CPU processing in the ndbd processes becomes a fairly large part of the overhead.
Using the SCI transporter instead of SCI Sockets is only of interest in communicating between ndbd processes. Using the SCI transporter is also only of interest if a CPU can be dedicated to the ndbd process because the SCI transporter ensures that this process will never go to sleep. It is also important to ensure that the ndbd process priority is set in such a way that the process does not lose priority due to running for an extended period of time, as can be done by locking processes to CPUs in Linux 2.6. If such a configuration is possible, the ndbd process will benefit by 10−70% as compared with using SCI sockets. (The larger figures will be seen when performing updates and probably on parallel scan operations as well.)
There are several other optimized socket implementations for computer clusters, including Myrinet, Gigabit Ethernet, Infiniband and the VIA interface. However, we have tested MySQL Cluster so far only with SCI sockets. See Section 18.3.4.1, “Configuring MySQL Cluster to use SCI Sockets”, for information on how to set up SCI sockets using ordinary TCP/IP for MySQL Cluster.
- 18.4.1 ndbd — The MySQL Cluster Data Node Daemon
- 18.4.2 ndbinfo_select_all — Select From ndbinfo Tables
- 18.4.3 ndbmtd — The MySQL Cluster Data Node Daemon (Multi-Threaded)
- 18.4.4 ndb_mgmd — The MySQL Cluster Management Server Daemon
- 18.4.5 ndb_mgm — The MySQL Cluster Management Client
- 18.4.6 ndb_blob_tool — Check and Repair BLOB and TEXT columns of MySQL Cluster Tables
- 18.4.7 ndb_config — Extract MySQL Cluster Configuration Information
- 18.4.8 ndb_cpcd — Automate Testing for NDB Development
- 18.4.9 ndb_delete_all — Delete All Rows from an NDB Table
- 18.4.10 ndb_desc — Describe NDB Tables
- 18.4.11 ndb_drop_index — Drop Index from an NDB Table
- 18.4.12 ndb_drop_table — Drop an NDB Table
- 18.4.13 ndb_error_reporter — NDB Error-Reporting Utility
- 18.4.14 ndb_index_stat — NDB Index Statistics Utility
- 18.4.15 ndb_print_backup_file — Print NDB Backup File Contents
- 18.4.16 ndb_print_file — Print NDB Disk Data File Contents
- 18.4.17 ndb_print_schema_file — Print NDB Schema File Contents
- 18.4.18 ndb_print_sys_file — Print NDB System File Contents
- 18.4.19 ndbd_redo_log_reader — Check and Print Content of Cluster Redo Log
- 18.4.20 ndb_restore — Restore a MySQL Cluster Backup
- 18.4.21 ndb_select_all — Print Rows from an NDB Table
- 18.4.22 ndb_select_count — Print Row Counts for NDB Tables
- 18.4.23 ndb_show_tables — Display List of NDB Tables
- 18.4.24 ndb_size.pl — NDBCLUSTER Size Requirement Estimator
- 18.4.25 ndb_waiter — Wait for MySQL Cluster to Reach a Given Status
- 18.4.26 Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs
Using and managing a MySQL Cluster requires several specialized programs, which we describe in this chapter. We discuss the purposes of these programs in a MySQL Cluster, how to use the programs, and what startup options are available for each of them.
These programs include the MySQL Cluster data, management, and SQL node processes (ndbd, ndbmtd, ndb_mgmd, and mysqld) and the management client (ndb_mgm).
For information about using mysqld as a MySQL Cluster process, see Section 18.5.4, “MySQL Server Usage for MySQL Cluster”.
Other NDB utility, diagnostic, and
example programs are included with the MySQL Cluster distribution.
These include ndb_restore,
ndb_show_tables, and
ndb_config. These programs are also covered in
this section.
The final portion of this section contains tables of options that are common to all the various MySQL Cluster programs.
ndbd is the process that is used to handle all the data in tables using the NDB Cluster storage engine. This is the process that empowers a data node to accomplish distributed transaction handling, node recovery, checkpointing to disk, online backup, and related tasks.
In a MySQL Cluster, a set of ndbd processes cooperate in handling data. These processes can execute on the same computer (host) or on different computers. The correspondences between data nodes and Cluster hosts is completely configurable.
The following table includes command options specific to the MySQL Cluster data node program ndbd. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndbd), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.69 This table describes command-line options for the ndbd program
| Format | Description | Added or Removed |
|---|---|---|
| Perform initial start of ndbd, including cleaning the file system. Consult the documentation before using this option | All MySQL 5.5 based releases |
|
| Don't start ndbd immediately; ndbd waits for command to start from ndb_mgmd | All MySQL 5.5 based releases |
|
| Start ndbd as daemon (default); override with --nodaemon | All MySQL 5.5 based releases |
|
| Do not start ndbd as daemon; provided for testing purposes | All MySQL 5.5 based releases |
|
| Run ndbd in foreground, provided for debugging purposes (implies --nodaemon) | All MySQL 5.5 based releases |
|
| Do not wait for these data nodes to start (takes comma-separated list of node IDs). Also requires --ndb-nodeid to be used. | All MySQL 5.5 based releases |
|
| Perform partial initial start (requires --nowait-nodes) | All MySQL 5.5 based releases |
|
| Local bind address | All MySQL 5.5 based releases |
|
| Used to install the data node process as a Windows service. Does not apply on non-Windows platforms. | All MySQL 5.5 based releases |
|
| Used to remove a data node process that was previously installed as a Windows service. Does not apply on non-Windows platforms. | All MySQL 5.5 based releases |
|
| Set the number of times to retry a connection before giving up; 0 means 1 attempt only (and no retries) | ADDED: NDB 7.2.9 |
|
| Time to wait between attempts to contact a management server, in seconds; 0 means do not wait between attempts | ADDED: NDB 7.2.9 |
All of these options also apply to the multi-threaded version of this program (ndbmtd) and you may substitute “ndbmtd” for “ndbd” wherever the latter occurs in this section.
-
Command-Line Format --bind-address=namePermitted Values Type stringDefault Causes ndbd to bind to a specific network interface (host name or IP address). This option has no default value.
-
Command-Line Format --daemonPermitted Values Type booleanDefault TRUEInstructs ndbd or ndbmtd to execute as a daemon process. This is the default behavior.
--nodaemoncan be used to prevent the process from running as a daemon.This option has no effect when running ndbd or ndbmtd on Windows platforms.
-
Command-Line Format --nodaemonPermitted Values Type booleanDefault FALSEPrevents ndbd or ndbmtd from executing as a daemon process. This option overrides the
--daemonoption. This is useful for redirecting output to the screen when debugging the binary.The default behavior for ndbd and ndbmtd on Windows is to run in the foreground, making this option unnecessary on Windows platforms, where it has no effect.
-
Command-Line Format --foregroundPermitted Values Type booleanDefault FALSECauses ndbd or ndbmtd to execute as a foreground process, primarily for debugging purposes. This option implies the
--nodaemonoption.This option has no effect when running ndbd or ndbmtd on Windows platforms.
-
Command-Line Format --initialPermitted Values Type booleanDefault FALSEInstructs ndbd to perform an initial start. An initial start erases any files created for recovery purposes by earlier instances of ndbd. It also re-creates recovery log files. Note that on some operating systems this process can take a substantial amount of time.
An
--initialstart is to be used only when starting the ndbd process under very special circumstances; this is because this option causes all files to be removed from the MySQL Cluster file system and all redo log files to be re-created. These circumstances are listed here:When performing a software upgrade which has changed the contents of any files.
When restarting the node with a new version of ndbd.
As a measure of last resort when for some reason the node restart or system restart repeatedly fails. In this case, be aware that this node can no longer be used to restore data due to the destruction of the data files.
Use of this option prevents the
StartPartialTimeoutandStartPartitionedTimeoutconfiguration parameters from having any effect.ImportantThis option does not affect either of the following types of files:
Backup files that have already been created by the affected node
MySQL Cluster Disk Data files (see Section 18.5.12, “MySQL Cluster Disk Data Tables”).
This option also has no effect on recovery of data by a data node that is just starting (or restarting) from data nodes that are already running. This recovery of data occurs automatically, and requires no user intervention in a MySQL Cluster that is running normally.
It is permissible to use this option when starting the cluster for the very first time (that is, before any data node files have been created); however, it is not necessary to do so.
-
Command-Line Format --initial-startPermitted Values Type booleanDefault FALSEThis option is used when performing a partial initial start of the cluster. Each node should be started with this option, as well as
--nowait-nodes.Suppose that you have a 4-node cluster whose data nodes have the IDs 2, 3, 4, and 5, and you wish to perform a partial initial start using only nodes 2, 4, and 5—that is, omitting node 3:
shell>
ndbd --ndb-nodeid=2 --nowait-nodes=3 --initial-startshell>ndbd --ndb-nodeid=4 --nowait-nodes=3 --initial-startshell>ndbd --ndb-nodeid=5 --nowait-nodes=3 --initial-startWhen using this option, you must also specify the node ID for the data node being started with the
--ndb-nodeidoption.ImportantDo not confuse this option with the
--nowait-nodesoption for ndb_mgmd, which can be used to enable a cluster configured with multiple management servers to be started without all management servers being online. --nowait-nodes=node_id_1[,node_id_2[, ...]]Command-Line Format --nowait-nodes=listPermitted Values Type stringDefault This option takes a list of data nodes which for which the cluster will not wait for before starting.
This can be used to start the cluster in a partitioned state. For example, to start the cluster with only half of the data nodes (nodes 2, 3, 4, and 5) running in a 4-node cluster, you can start each ndbd process with
--nowait-nodes=3,5. In this case, the cluster starts as soon as nodes 2 and 4 connect, and does not waitStartPartitionedTimeoutmilliseconds for nodes 3 and 5 to connect as it would otherwise.If you wanted to start up the same cluster as in the previous example without one ndbd (say, for example, that the host machine for node 3 has suffered a hardware failure) then start nodes 2, 4, and 5 with
--nowait-nodes=3. Then the cluster will start as soon as nodes 2, 4, and 5 connect and will not wait for node 3 to start.-
Command-Line Format --nostartPermitted Values Type booleanDefault FALSEInstructs ndbd not to start automatically. When this option is used, ndbd connects to the management server, obtains configuration data from it, and initializes communication objects. However, it does not actually start the execution engine until specifically requested to do so by the management server. This can be accomplished by issuing the proper
STARTcommand in the management client (see Section 18.5.2, “Commands in the MySQL Cluster Management Client”). -
Command-Line Format --install[=name]Platform Specific Windows Permitted Values Type stringDefault ndbdCauses ndbd to be installed as a Windows service. Optionally, you can specify a name for the service; if not set, the service name defaults to
ndbd. Although it is preferable to specify other ndbd program options in amy.iniormy.cnfconfiguration file, it is possible to use together with--install. However, in such cases, the--installoption must be specified first, before any other options are given, for the Windows service installation to succeed.It is generally not advisable to use this option together with the
--initialoption, since this causes the data node file system to be wiped and rebuilt every time the service is stopped and started. Extreme care should also be taken if you intend to use any of the other ndbd options that affect the starting of data nodes—including--initial-start,--nostart, and--nowait-nodes—together with--install, and you should make absolutely certain you fully understand and allow for any possible consequences of doing so.The
--installoption has no effect on non-Windows platforms. -
Command-Line Format --remove[=name]Platform Specific Windows Permitted Values Type stringDefault ndbdCauses an ndbd process that was previously installed as a Windows service to be removed. Optionally, you can specify a name for the service to be uninstalled; if not set, the service name defaults to
ndbd.The
--removeoption has no effect on non-Windows platforms. -
Introduced 5.5.28-ndb-7.2.9 Command-Line Format --connect-retries=#Permitted Values Type numericDefault 12Min Value 0Max Value 65535Determines the number of times that the data node attempts to contact a management server when starting. Setting this option to -1 causes the data node to keep trying to make contact indefinitely. The default is 12 attempts. The time to wait between attempts is controlled by the
--connect-delayoption.This option was added in MySQL Cluster NDB 7.2.9.
-
Introduced 5.5.28-ndb-7.2.9 Command-Line Format --connect-delay=#Permitted Values Type numericDefault 5Min Value 0Max Value 3600Determines the time to wait between attempts to contact a management server when starting (the time between attempts is controlled by the
--connect-retriesoption). The default is 5 attempts.This option was added in MySQL Cluster NDB 7.2.9.
ndbd generates a set of log files which are
placed in the directory specified by
DataDir in the
config.ini configuration file.
These log files are listed below.
node_id is the node's unique
identifier. Note that node_id
represents the node's unique identifier. For example,
ndb_2_error.log is the error log generated
by the data node whose node ID is 2.
ndb_is a file containing records of all crashes which the referenced ndbd process has encountered. Each record in this file contains a brief error string and a reference to a trace file for this crash. A typical entry in this file might appear as shown here:node_id_error.logDate/Time: Saturday 30 July 2004 - 00:20:01 Type of error: error Message: Internal program error (failed ndbrequire) Fault ID: 2341 Problem data: DbtupFixAlloc.cpp Object of reference: DBTUP (Line: 173) ProgramName: NDB Kernel ProcessID: 14909 TraceFile: ndb_2_trace.log.2 ***EOM***
Listings of possible ndbd exit codes and messages generated when a data node process shuts down prematurely can be found in ndbd Error Messages.
ImportantThe last entry in the error log file is not necessarily the newest one (nor is it likely to be). Entries in the error log are not listed in chronological order; rather, they correspond to the order of the trace files as determined in the
ndb_file (see below). Error log entries are thus overwritten in a cyclical and not sequential fashion.node_id_trace.log.nextndb_is a trace file describing exactly what happened just before the error occurred. This information is useful for analysis by the MySQL Cluster development team.node_id_trace.log.trace_idIt is possible to configure the number of these trace files that will be created before old files are overwritten.
trace_idis a number which is incremented for each successive trace file.ndb_is the file that keeps track of the next trace file number to be assigned.node_id_trace.log.nextndb_is a file containing any data output by the ndbd process. This file is created only if ndbd is started as a daemon, which is the default behavior.node_id_out.logndb_is a file containing the process ID of the ndbd process when started as a daemon. It also functions as a lock file to avoid the starting of nodes with the same identifier.node_id.pidndb_is a file used only in debug versions of ndbd, where it is possible to trace all incoming, outgoing, and internal messages with their data in the ndbd process.node_id_signal.log
It is recommended not to use a directory mounted through NFS
because in some environments this can cause problems whereby the
lock on the .pid file remains in effect
even after the process has terminated.
To start ndbd, it may also be necessary to specify the host name of the management server and the port on which it is listening. Optionally, one may also specify the node ID that the process is to use.
shell> ndbd --connect-string="nodeid=2;host=ndb_mgmd.mysql.com:1186"
See Section 18.3.3.3, “MySQL Cluster Connection Strings”, for additional information about this issue. Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”, describes other command-line options which can be used with ndbd. For information about data node configuration parameters, see Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”.
When ndbd starts, it actually initiates two processes. The first of these is called the “angel process”; its only job is to discover when the execution process has been completed, and then to restart the ndbd process if it is configured to do so. Thus, if you attempt to kill ndbd using the Unix kill command, it is necessary to kill both processes, beginning with the angel process. The preferred method of terminating an ndbd process is to use the management client and stop the process from there.
The execution process uses one thread for reading, writing, and scanning data, as well as all other activities. This thread is implemented asynchronously so that it can easily handle thousands of concurrent actions. In addition, a watch-dog thread supervises the execution thread to make sure that it does not hang in an endless loop. A pool of threads handles file I/O, with each thread able to handle one open file. Threads can also be used for transporter connections by the transporters in the ndbd process. In a multi-processor system performing a large number of operations (including updates), the ndbd process can consume up to 2 CPUs if permitted to do so.
For a machine with many CPUs it is possible to use several ndbd processes which belong to different node groups; however, such a configuration is still considered experimental and is not supported for MySQL 5.5 in a production setting. See Section 18.1.6, “Known Limitations of MySQL Cluster”.
ndbinfo_select_all is a client program that
selects all rows and columns from one or more tables in the
ndbinfo database. It is
included with the MySQL Cluster distribution beginning with
MySQL Cluster NDB 7.2.2.
Not all ndbinfo tables available in the
mysql client can be read by this program. In
addition, ndbinfo_select_all can show
information about some tables internal to
ndbinfo which cannot be accessed using SQL,
including the tables and
columns metadata tables.
To select from one or more ndbinfo tables
using ndbinfo_select_all, it is necessary to
supply the names of the tables when invoking the program as
shown here:
shell> ndbinfo_select_all table_name1 [table_name2] [...]
For example:
shell> ndbinfo_select_all logbuffers logspaces
== logbuffers ==
node_id log_type log_id log_part total used high
5 0 0 0 33554432 262144 0
6 0 0 0 33554432 262144 0
7 0 0 0 33554432 262144 0
8 0 0 0 33554432 262144 0
== logspaces ==
node_id log_type log_id log_part total used high
5 0 0 0 268435456 0 0
5 0 0 1 268435456 0 0
5 0 0 2 268435456 0 0
5 0 0 3 268435456 0 0
6 0 0 0 268435456 0 0
6 0 0 1 268435456 0 0
6 0 0 2 268435456 0 0
6 0 0 3 268435456 0 0
7 0 0 0 268435456 0 0
7 0 0 1 268435456 0 0
7 0 0 2 268435456 0 0
7 0 0 3 268435456 0 0
8 0 0 0 268435456 0 0
8 0 0 1 268435456 0 0
8 0 0 2 268435456 0 0
8 0 0 3 268435456 0 0
shell>
The following table includes options that are specific to ndbinfo_select_all. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndbinfo_select_all), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.70 This table describes command-line options for the ndbinfo_select_all program
| Format | Description | Added or Removed |
|---|---|---|
| Set the delay in seconds between loops. Default is 5. | All MySQL 5.5 based releases |
|
| Set the number of times to perform the select. Default is 1. | All MySQL 5.5 based releases |
|
| Name of the database where the table located. | All MySQL 5.5 based releases |
|
| Set the degree of parallelism. | All MySQL 5.5 based releases |
-
Command-Line Format --delay=#Permitted Values Type numericDefault 5Min Value 0Max Value MAX_INTThis option sets the number of seconds to wait between executing loops. Has no effect if
--loopsis set to 0 or 1. -
Command-Line Format --loops=#Permitted Values Type numericDefault 1Min Value 0Max Value MAX_INTThis option sets the number of times to execute the select. Use
--delayto set the time between loops.
ndbmtd is a multi-threaded version of
ndbd, the process that is used to handle all
the data in tables using the
NDBCLUSTER storage engine.
ndbmtd is intended for use on host computers
having multiple CPU cores. Except where otherwise noted,
ndbmtd functions in the same way as
ndbd; therefore, in this section, we
concentrate on the ways in which ndbmtd
differs from ndbd, and you should consult
Section 18.4.1, “ndbd — The MySQL Cluster Data Node Daemon”, for additional
information about running MySQL Cluster data nodes that apply to
both the single-threaded and multi-threaded versions of the data
node process.
Command-line options and configuration parameters used with ndbd also apply to ndbmtd. For more information about these options and parameters, see Section 18.4.1, “ndbd — The MySQL Cluster Data Node Daemon”, and Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”, respectively.
ndbmtd is also file system-compatible with
ndbd. In other words, a data node running
ndbd can be stopped, the binary replaced with
ndbmtd, and then restarted without any loss
of data. (However, when doing this, you must make sure that
MaxNoOfExecutionThreads
is set to an apppriate value before restarting the node if you
wish for ndbmtd to run in multi-threaded
fashion.) Similarly, an ndbmtd binary can be
replaced with ndbd simply by stopping the
node and then starting ndbd in place of the
multi-threaded binary. It is not necessary when switching
between the two to start the data node binary using
--initial.
Using ndbmtd differs from using ndbd in two key respects:
Because ndbmtd runs by default in single-threaded mode (that is, it behaves like ndbd), you must configure it to use multiple threads. This can be done by setting an appropriate value in the
config.inifile for theMaxNoOfExecutionThreadsconfiguration parameter or (in MySQL Cluster NDB 7.2.3 and later) theThreadConfigconfiguration parameter. UsingMaxNoOfExecutionThreadsis simpler, butThreadConfigoffers more flexibility. For more information about these configuration parameters and their use, see Multi-Threading Configuration Parameters (ndbmtd).Trace files are generated by critical errors in ndbmtd processes in a somewhat different fashion from how these are generated by ndbd failures. These differences are discussed in more detail in the next few paragraphs.
Like ndbd, ndbmtd
generates a set of log files which are placed in the directory
specified by DataDir in
the config.ini configuration file. Except
for trace files, these are generated in the same way and have
the same names as those generated by ndbd.
In the event of a critical error, ndbmtd
generates trace files describing what happened just prior to the
error' occurrence. These files, which can be found in the
data node's
DataDir, are useful for
analysis of problems by the MySQL Cluster Development and
Support teams. One trace file is generated for each
ndbmtd thread. The names of these files have
the following pattern:
ndb_node_id_trace.log.trace_id_tthread_id,
In this pattern, node_id stands for
the data node's unique node ID in the cluster,
trace_id is a trace sequence number,
and thread_id is the thread ID. For
example, in the event of the failure of an
ndbmtd process running as a MySQL Cluster
data node having the node ID 3 and with
MaxNoOfExecutionThreads
equal to 4, four trace files are generated in the data
node's data directory. If the is the first time this node
has failed, then these files are named
ndb_3_trace.log.1_t1,
ndb_3_trace.log.1_t2,
ndb_3_trace.log.1_t3, and
ndb_3_trace.log.1_t4. Internally, these
trace files follow the same format as ndbd
trace files.
The ndbd exit codes and messages that are generated when a data node process shuts down prematurely are also used by ndbmtd. See ndbd Error Messages, for a listing of these.
The management server is the process that reads the cluster configuration file and distributes this information to all nodes in the cluster that request it. It also maintains a log of cluster activities. Management clients can connect to the management server and check the cluster's status.
The following table includes options that are specific to the MySQL Cluster management server program ndb_mgmd. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_mgmd), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.71 This table describes command-line options for the ndb_mgmd program
| Format | Description | Added or Removed |
|---|---|---|
| Specify the cluster configuration file; in NDB-6.4.0 and later, needs --reload or --initial to override configuration cache if present | All MySQL 5.5 based releases |
|
| Specify the cluster management server's configuration cache directory | All MySQL 5.5 based releases |
|
| Local bind address | All MySQL 5.5 based releases |
|
| Print full configuration and exit | All MySQL 5.5 based releases |
|
| Run ndb_mgmd in daemon mode (default) | All MySQL 5.5 based releases |
|
| Do not run ndb_mgmd as a daemon | All MySQL 5.5 based releases |
|
| Run ndb_mgmd in interactive mode (not officially supported in production; for testing purposes only) | All MySQL 5.5 based releases |
|
| A name to use when writing messages applying to this node in the cluster log. | All MySQL 5.5 based releases |
|
| Do not provide any node id checks | All MySQL 5.5 based releases |
|
| Read cluster configuration data from the my.cnf file | All MySQL 5.5 based releases |
|
| Causes the management server to compare the configuration file with its configuration cache | All MySQL 5.5 based releases |
|
| Causes the management server reload its configuration data from the configuration file, bypassing the configuration cache | All MySQL 5.5 based releases |
|
| Do not wait for these management nodes when starting this management server. Also requires --ndb-nodeid to be used. | All MySQL 5.5 based releases |
|
| Enable the management server configuration cache; TRUE by default. | All MySQL 5.5 based releases |
|
| Used to install the management server process as a Windows service. Does not apply on non-Windows platforms. | All MySQL 5.5 based releases |
|
| Used to remove a management server process that was previously installed as a Windows service, optionally specifying the name of the service to be removed. Does not apply on non-Windows platforms. | All MySQL 5.5 based releases |
-
Command-Line Format --bind-address=ip_addressPermitted Values Type stringDefault [none]When specified, this option limits management server connections by management clients to clients at the specified host name or IP address (and possibly port, if this is also specified). In such cases, a management client attempting to connect to the management server from any other address fails with the error Unable to setup port:
host:port!If the
portis not specified, the management client attempts to use port 1186. -
Command-Line Format --no-nodeid-checksPermitted Values Type booleanDefault FALSEDo not perform any checks of node IDs.
-
Command-Line Format --configdir=directory--config-dir=directoryPermitted Values Type file nameDefault $INSTALLDIR/mysql-clusterSpecifies the cluster management server's configuration cache directory.
--config-diris an alias for this option. -
Command-Line Format --config-cache[=TRUE|FALSE]Permitted Values Type booleanDefault TRUEThis option, whose default value is
1(orTRUE, orON), can be used to disable the management server's configuration cache, so that it reads its configuration fromconfig.inievery time it starts (see Section 18.3.3, “MySQL Cluster Configuration Files”). You can do this by starting the ndb_mgmd process with any one of the following options:Using one of the options just listed is effective only if the management server has no stored configuration at the time it is started. If the management server finds any configuration cache files, then the
--config-cacheoption or the--skip-config-cacheoption is ignored. Therefore, to disable configuration caching, the option should be used the first time that the management server is started. Otherwise—that is, if you wish to disable configuration caching for a management server that has already created a configuration cache—you must stop the management server, delete any existing configuration cache files manually, then restart the management server with--skip-config-cache(or with--config-cacheset equal to 0,OFF, orFALSE).Configuration cache files are normally created in a directory named
mysql-clusterunder the installation directory (unless this location has been overridden using the--configdiroption). Each time the management server updates its configuration data, it writes a new cache file. The files are named sequentially in order of creation using the following format:ndb_
node-id_config.bin.seq-numbernode-idis the management server's node ID;seq-numberis a sequence number, beginning with 1. For example, if the management server's node ID is 5, then the first three configuration cache files would, when they are created, be namedndb_5_config.bin.1,ndb_5_config.bin.2, andndb_5_config.bin.3.If your intent is to purge or reload the configuration cache without actually disabling caching, you should start ndb_mgmd with one of the options
--reloador--initialinstead of--skip-config-cache.To re-enable the configuration cache, simply restart the management server, but without the
--config-cacheor--skip-config-cacheoption that was used previously to disable the configuration cache.Beginning with MySQL Cluster NDB 7.2.5, ndb_mgmd no longer checks for the configuration directory (
--configdir) or attempts to create one when--skip-config-cacheis used. (Bug #13428853) --config-file=,filename-ffilenameCommand-Line Format --config-file=filePermitted Values Type file nameDefault [none]Instructs the management server as to which file it should use for its configuration file. By default, the management server looks for a file named
config.iniin the same directory as the ndb_mgmd executable; otherwise the file name and location must be specified explicitly.This option has no default value, and is ignored unless the management server is forced to read the configuration file, either because ndb_mgmd was started with the
--reloador--initialoption, or because the management server could not find any configuration cache. This option is also read if ndb_mgmd was started with--config-cache=OFF. See Section 18.3.3, “MySQL Cluster Configuration Files”, for more information.Formerly, using this option together with
--initialcaused removal of the configuration cache even if the file was not found. This issue was resolved in MySQL Cluster NDB 7.2.13. (Bug #1299289)-
Command-Line Format --mycnfPermitted Values Type booleanDefault FALSERead configuration data from the
my.cnffile. -
Command-Line Format --daemonPermitted Values Type booleanDefault TRUEInstructs ndb_mgmd to start as a daemon process. This is the default behavior.
This option has no effect when running ndb_mgmd on Windows platforms.
-
Command-Line Format --interactivePermitted Values Type booleanDefault FALSEStarts ndb_mgmd in interactive mode; that is, an ndb_mgm client session is started as soon as the management server is running. This option does not start any other MySQL Cluster nodes.
-
Command-Line Format --initialPermitted Values Type booleanDefault FALSEConfiguration data is cached internally, rather than being read from the cluster global configuration file each time the management server is started (see Section 18.3.3, “MySQL Cluster Configuration Files”). Using the
--initialoption overrides this behavior, by forcing the management server to delete any existing cache files, and then to re-read the configuration data from the cluster configuration file and to build a new cache.This differs in two ways from the
--reloadoption. First,--reloadforces the server to check the configuration file against the cache and reload its data only if the contents of the file are different from the cache. Second,--reloaddoes not delete any existing cache files.If ndb_mgmd is invoked with
--initialbut cannot find a global configuration file, the management server cannot start.When a management server starts, it checks for another management server in the same MySQL Cluster and tries to use the other management server's configuration data; ndb_mgmd ignores
--initialunless it is the only management server running. This behavior also has implications when performing a rolling restart of a MySQL Cluster with multiple management nodes. See Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”, for more information.Formerly, using this option together with the
--config-fileoption caused removal of the configuration cache even if the file was not found. Starting with MySQL Cluster NDB 7.2.13, the cache is cleared in such cases only if the configuration file is actually found. (Bug #1299289) -
Command-Line Format --log-name=namePermitted Values Type stringDefault MgmtSrvrProvides a name to be used for this node in the cluster log.
-
Command-Line Format --nodaemonPermitted Values Type booleanDefault FALSEInstructs ndb_mgmd not to start as a daemon process.
The default behavior for ndb_mgmd on Windows is to run in the foreground, making this option unnecessary on Windows platforms.
-
Command-Line Format --print-full-configPermitted Values Type booleanDefault FALSEShows extended information regarding the configuration of the cluster. With this option on the command line the ndb_mgmd process prints information about the cluster setup including an extensive list of the cluster configuration sections as well as parameters and their values. Normally used together with the
--config-file(-f) option. -
Command-Line Format --reloadPermitted Values Type booleanDefault FALSEIn MySQL Cluster NDB 7.2, configuration data is stored internally rather than being read from the cluster global configuration file each time the management server is started (see Section 18.3.3, “MySQL Cluster Configuration Files”). Using this option forces the management server to check its internal data store against the cluster configuration file and to reload the configuration if it finds that the configuration file does not match the cache. Existing configuration cache files are preserved, but not used.
This differs in two ways from the
--initialoption. First,--initialcauses all cache files to be deleted. Second,--initialforces the management server to re-read the global configuration file and construct a new cache.If the management server cannot find a global configuration file, then the
--reloadoption is ignored.When a management server starts, it checks for another management server in the same MySQL Cluster and tries to use the other management server's configuration data; ndb_mgmd ignores
--reloadunless it is the only management server running. This behavior also has implications when performing a rolling restart of a MySQL Cluster with multiple management nodes. See Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”, for more information. -
Command-Line Format --nowait-nodes=listPermitted Values Type numericDefault Min Value 1Max Value 255When starting a MySQL Cluster is configured with two management nodes, each management server normally checks to see whether the other ndb_mgmd is also operational and whether the other management server's configuration is identical to its own. However, it is sometimes desirable to start the cluster with only one management node (and perhaps to allow the other ndb_mgmd to be started later). This option causes the management node to bypass any checks for any other management nodes whose node IDs are passed to this option, permitting the cluster to start as though configured to use only the management node that was started.
For purposes of illustration, consider the following portion of a
config.inifile (where we have omitted most of the configuration parameters that are not relevant to this example):[ndbd] NodeId = 1 HostName = 192.168.0.101 [ndbd] NodeId = 2 HostName = 192.168.0.102 [ndbd] NodeId = 3 HostName = 192.168.0.103 [ndbd] NodeId = 4 HostName = 192.168.0.104 [ndb_mgmd] NodeId = 10 HostName = 192.168.0.150 [ndb_mgmd] NodeId = 11 HostName = 192.168.0.151 [api] NodeId = 20 HostName = 192.168.0.200 [api] NodeId = 21 HostName = 192.168.0.201
Assume that you wish to start this cluster using only the management server having node ID
10and running on the host having the IP address 192.168.0.150. (Suppose, for example, that the host computer on which you intend to the other management server is temporarily unavailable due to a hardware failure, and you are waiting for it to be repaired.) To start the cluster in this way, use a command line on the machine at 192.168.0.150 to enter the following command:shell>
ndb_mgmd --ndb-nodeid=10 --nowait-nodes=11As shown in the preceding example, when using
--nowait-nodes, you must also use the--ndb-nodeidoption to specify the node ID of this ndb_mgmd process.You can then start each of the cluster's data nodes in the usual way. If you wish to start and use the second management server in addition to the first management server at a later time without restarting the data nodes, you must start each data node with a connection string that references both management servers, like this:
shell>
ndbd -c 192.168.0.150,192.168.0.151The same is true with regard to the connection string used with any mysqld processes that you wish to start as MySQL Cluster SQL nodes connected to this cluster. See Section 18.3.3.3, “MySQL Cluster Connection Strings”, for more information.
When used with ndb_mgmd, this option affects the behavior of the management node with regard to other management nodes only. Do not confuse it with the
--nowait-nodesoption used with ndbd or ndbmtd to permit a cluster to start with fewer than its full complement of data nodes; when used with data nodes, this option affects their behavior only with regard to other data nodes.Multiple management node IDs may be passed to this option as a comma-separated list. Each node ID must be no less than 1 and no greater than 255. In practice, it is quite rare to use more than two management servers for the same MySQL Cluster (or to have any need for doing so); in most cases you need to pass to this option only the single node ID for the one management server that you do not wish to use when starting the cluster.
NoteWhen you later start the “missing” management server, its configuration must match that of the management server that is already in use by the cluster. Otherwise, it fails the configuration check performed by the existing management server, and does not start.
It is not strictly necessary to specify a connection string when starting the management server. However, if you are using more than one management server, a connection string should be provided and each node in the cluster should specify its node ID explicitly.
See Section 18.3.3.3, “MySQL Cluster Connection Strings”, for information about using connection strings. Section 18.4.4, “ndb_mgmd — The MySQL Cluster Management Server Daemon”, describes other options for ndb_mgmd.
The following files are created or used by
ndb_mgmd in its starting directory, and are
placed in the DataDir as
specified in the config.ini configuration
file. In the list that follows,
node_id is the unique node
identifier.
config.iniis the configuration file for the cluster as a whole. This file is created by the user and read by the management server. Section 18.3, “Configuration of MySQL Cluster”, discusses how to set up this file.ndb_is the cluster events log file. Examples of such events include checkpoint startup and completion, node startup events, node failures, and levels of memory usage. A complete listing of cluster events with descriptions may be found in Section 18.5, “Management of MySQL Cluster”.node_id_cluster.logBy default, when the size of the cluster log reaches one million bytes, the file is renamed to
ndb_, wherenode_id_cluster.log.seq_idseq_idis the sequence number of the cluster log file. (For example: If files with the sequence numbers 1, 2, and 3 already exist, the next log file is named using the number4.) You can change the size and number of files, and other characteristics of the cluster log, using theLogDestinationconfiguration parameter.ndb_is the file used fornode_id_out.logstdoutandstderrwhen running the management server as a daemon.ndb_is the process ID file used when running the management server as a daemon.node_id.pid-
Command-Line Format --install[=name]Platform Specific Windows Permitted Values Type stringDefault ndb_mgmdCauses ndb_mgmd to be installed as a Windows service. Optionally, you can specify a name for the service; if not set, the service name defaults to
ndb_mgmd. Although it is preferable to specify other ndb_mgmd program options in amy.iniormy.cnfconfiguration file, it is possible to use them together with--install. However, in such cases, the--installoption must be specified first, before any other options are given, for the Windows service installation to succeed.It is generally not advisable to use this option together with the
--initialoption, since this causes the configuration cache to be wiped and rebuilt every time the service is stopped and started. Care should also be taken if you intend to use any other ndb_mgmd options that affect the starting of the management server, and you should make absolutely certain you fully understand and allow for any possible consequences of doing so.The
--installoption has no effect on non-Windows platforms. -
Command-Line Format --remove[=name]Platform Specific Windows Permitted Values Type stringDefault ndb_mgmdCauses an ndb_mgmd process that was previously installed as a Windows service to be removed. Optionally, you can specify a name for the service to be uninstalled; if not set, the service name defaults to
ndb_mgmd.The
--removeoption has no effect on non-Windows platforms.
The ndb_mgm management client process is actually not needed to run the cluster. Its value lies in providing a set of commands for checking the cluster's status, starting backups, and performing other administrative functions. The management client accesses the management server using a C API. Advanced users can also employ this API for programming dedicated management processes to perform tasks similar to those performed by ndb_mgm.
To start the management client, it is necessary to supply the host name and port number of the management server:
shell> ndb_mgm [host_name [port_num]]
For example:
shell> ndb_mgm ndb_mgmd.mysql.com 1186
The default host name and port number are
localhost and 1186, respectively.
The following table includes options that are specific to the MySQL Cluster management client program ndb_mgm. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_mgm), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.72 This table describes command-line options for the ndb_mgm program
| Format | Description | Added or Removed |
|---|---|---|
| Set the number of times to retry a connection before giving up; synonym for --connect-retries | All MySQL 5.5 based releases |
|
| Execute command and exit | All MySQL 5.5 based releases |
-
Command-Line Format --execute=nameThis option can be used to send a command to the MySQL Cluster management client from the system shell. For example, either of the following is equivalent to executing
SHOWin the management client:shell>
ndb_mgm -e "SHOW"shell>ndb_mgm --execute="SHOW"This is analogous to how the
--executeor-eoption works with the mysql command-line client. See Section 4.2.4, “Using Options on the Command Line”.NoteIf the management client command to be passed using this option contains any space characters, then the command must be enclosed in quotation marks. Either single or double quotation marks may be used. If the management client command contains no space characters, the quotation marks are optional.
-
Command-Line Format --try-reconnect=#Permitted Values Type integerDefault 3Min Value 0Max Value 4294967295If the connection to the management server is broken, the node tries to reconnect to it every 5 seconds until it succeeds. By using this option, it is possible to limit the number of attempts to
numberbefore giving up and reporting an error instead.
Additional information about using ndb_mgm can be found in Section 18.5.2, “Commands in the MySQL Cluster Management Client”.
This tool can be used to check for and remove orphaned BLOB
column parts from NDB tables, as
well as to generate a file listing any orphaned parts. It is
sometimes useful in diagnosing and repairing corrupted or
damaged NDB tables containing
BLOB or
TEXT columns.
The basic syntax for ndb_blob_tool is shown here:
ndb_blob_tool [options]table[column, ...]
Unless you use the --help
option, you must specify an action to be performed by including
one or more of the options
--check-orphans,
--delete-orphans, or
--dump-file. These options
cause ndb_blob_tool to check for orphaned
BLOB parts, remove any orphaned BLOB parts, and generate a dump
file listing orphaned BLOB parts, respectively, and are
described in more detail later in this section.
You must also specify the name of a table when invoking
ndb_blob_tool. In addition, you can
optionally follow the table name with the (comma-separated)
names of one or more BLOB or
TEXT columns from that table. If
no columns are listed, the tool works on all of the table's
BLOB and
TEXT columns. If you need to
specify a database, use the
--database
(-d) option.
The --verbose option
provides additional information in the output about the
tool's progress.
The following table includes options that are specific to ndb_blob_tool. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_blob_tool), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.73 This table describes command-line options for the ndb_blob_tool program
| Format | Description | Added or Removed |
|---|---|---|
| Check for orphan blob parts | All MySQL 5.5 based releases |
|
| Database to find the table in. | All MySQL 5.5 based releases |
|
| Delete orphan blob parts | All MySQL 5.5 based releases |
|
| Write orphan keys to specified file | All MySQL 5.5 based releases |
|
| Verbose output | All MySQL 5.5 based releases |
-
Command-Line Format --check-orphansPermitted Values Type booleanDefault FALSECheck for orphaned BLOB parts in MySQL Cluster tables.
-
Command-Line Format --database=db_namePermitted Values Type stringDefault [none]Specify the database to find the table in.
-
Command-Line Format --delete-orphansPermitted Values Type booleanDefault FALSERemove orphaned BLOB parts from MySQL Cluster tables.
-
Command-Line Format --dump-file=filePermitted Values Type file nameDefault [none]Writes a list of orphaned BLOB column parts to
file. The information written to the file includes the table key and BLOB part number for each orphaned BLOB part. -
Command-Line Format --verbosePermitted Values Type booleanDefault FALSEProvide extra information in the tool's output regarding its progress.
Example
First we create an NDB table in the
test database, using the
CREATE TABLE statement shown
here:
USE test;
CREATE TABLE btest (
c0 BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
c1 TEXT,
c2 BLOB
) ENGINE=NDB;
Then we insert a few rows into this table, using a series of statements similar to this one:
INSERT INTO btest VALUES (NULL, 'x', REPEAT('x', 1000));
When run with
--check-orphans against
this table, ndb_blob_tool generates the
following output:
shell> ndb_blob_tool --check-orphans --verbose -d test btest
connected
processing 2 blobs
processing blob #0 c1 NDB$BLOB_19_1
NDB$BLOB_19_1: nextResult: res=1
total parts: 0
orphan parts: 0
processing blob #1 c2 NDB$BLOB_19_2
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=0
NDB$BLOB_19_2: nextResult: res=1
total parts: 10
orphan parts: 0
disconnected
NDBT_ProgramExit: 0 - OK
The tool reports that there are no NDB BLOB
column parts associated with column c1, even
though c1 is a
TEXT column. This is due to the
fact that, in an NDB table, only
the first 256 bytes of a BLOB or
TEXT column value are stored
inline, and only the excess, if any, is stored separately; thus,
if there are no values using more than 256 bytes in a given
column of one of these types, no BLOB column
parts are created by NDB for this column. See
Section 11.7, “Data Type Storage Requirements”, for more information.
This tool extracts current configuration information for data
nodes, SQL nodes, and API nodes from one of a number of sources:
a MySQL Cluster management node, or its
config.ini or my.cnf
file. By default, the management node is the source for the
configuration data; to override the default, execute ndb_config
with the --config-file or
--mycnf option. It is also
possible to use a data node as the source by specifying its node
ID with
--config_from_node=.
node_id
ndb_config can also provide an offline dump
of all configuration parameters which can be used, along with
their default, maximum, and minimum values and other
information. The dump can be produced in either text or XML
format; for more information, see the discussion of the
--configinfo and
--xml options later in this
section).
You can filter the results by section (DB,
SYSTEM, or CONNECTIONS)
using one of the options
--nodes,
--system, or
--connections.
The following table includes options that are specific to ndb_config. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_config), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.74 This table describes command-line options for the ndb_config program
| Format | Description | Added or Removed |
|---|---|---|
| Print node information ([ndbd] or [ndbd default] section of cluster configuration file) only. Cannot be used with --system or --connections. | All MySQL 5.5 based releases |
|
| Print connections information ([tcp], [tcp default], [sci], [sci default], [shm], or [shm default] sections of cluster configuration file) only. Cannot be used with --system or --nodes. | All MySQL 5.5 based releases |
|
| One or more query options (attributes) | All MySQL 5.5 based releases |
|
| Specify host | All MySQL 5.5 based releases |
|
| Specify node type | All MySQL 5.5 based releases |
|
| Get configuration of node with this ID | All MySQL 5.5 based releases |
|
| Field separator | All MySQL 5.5 based releases |
|
| Row separator | All MySQL 5.5 based releases |
|
| Set the path to config.ini file | All MySQL 5.5 based releases |
|
| Read configuration data from my.cnf file | All MySQL 5.5 based releases |
|
| Short form for --ndb-connectstring | All MySQL 5.5 based releases |
|
| Dumps information about all NDB configuration parameters in text format with default, maximum, and minimum values. Use with --xml to obtain XML output. | All MySQL 5.5 based releases |
|
| Use --xml with --configinfo to obtain a dump of all NDB configuration parameters in XML format with default, maximum, and minimum values. | All MySQL 5.5 based releases |
|
| Print SYSTEM section information only (see ndb_config --configinfo output). Cannot be used with --nodes or --connections. | All MySQL 5.5 based releases |
|
| Obtain configuration data from the node having this ID (must be a data node). | All MySQL 5.5 based releases |
-
Command-Line Format --help--usageCauses ndb_config to print a list of available options, and then exit.
-
Command-Line Format --config_from_node=#Permitted Values Type numericDefault noneMin Value 1Max Value 48Obtain the cluster's configuration data from the data node that has this ID.
If the node having this ID is not a data node, ndb_config fails with an error. (To obtain configuration data from the management node instead, simply omit this option.)
-
Command-Line Format --versionCauses ndb_config to print a version information string, and then exit.
--ndb-connectstring=,connection_string-cconnection_stringCommand-Line Format --ndb-connectstring=connectstring--connect-string=connectstringPermitted Values Type stringDefault localhost:1186Specifies the connection string to use in connecting to the management server. The format for the connection string is the same as described in Section 18.3.3.3, “MySQL Cluster Connection Strings”, and defaults to
localhost:1186.-
Command-Line Format --config-file=file_namePermitted Values Type file nameDefault Gives the path to the management server's configuration file (
config.ini). This may be a relative or absolute path. If the management node resides on a different host from the one on which ndb_config is invoked, then an absolute path must be used. -
Command-Line Format --mycnfPermitted Values Type booleanDefault FALSERead configuration data from the
my.cnffile. --query=,query-options-qquery-optionsCommand-Line Format --query=stringPermitted Values Type stringDefault This is a comma-delimited list of query options—that is, a list of one or more node attributes to be returned. These include
id(node ID), type (node type—that is,ndbd,mysqld, orndb_mgmd), and any configuration parameters whose values are to be obtained.For example,
--query=id,type,indexmemory,datamemoryreturns the node ID, node type,DataMemory, andIndexMemoryfor each node.NoteIf a given parameter is not applicable to a certain type of node, than an empty string is returned for the corresponding value. See the examples later in this section for more information.
-
Command-Line Format --host=namePermitted Values Type stringDefault Specifies the host name of the node for which configuration information is to be obtained.
NoteWhile the hostname
localhostusually resolves to the IP address127.0.0.1, this may not necessarily be true for all operating platforms and configurations. This means that it is possible, whenlocalhostis used inconfig.ini, for ndb_config--host=localhostto fail if ndb_config is run on a different host wherelocalhostresolves to a different address (for example, on some versions of SUSE Linux, this is127.0.0.2). In general, for best results, you should use numeric IP addresses for all MySQL Cluster configuration values relating to hosts, or verify that all MySQL Cluster hosts handlelocalhostin the same fashion. -
Command-Line Format --ndb-nodeid=#Permitted Values Type numericDefault 0Either of these options can be used to specify the node ID of the node for which configuration information is to be obtained.
--nodeidis the preferred form. -
Command-Line Format --nodesPermitted Values Type booleanDefault FALSETells ndb_config to print information relating only to parameters defined in an
[ndbd]or[ndbd default]section of the cluster configuration file (see Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”).This option is mutually exclusive with
--connectionsand--system; only one of these 3 options can be used. -
Command-Line Format --connectionsPermitted Values Type booleanDefault FALSETells ndb_config to print
CONNECTIONSinformation only—that is, information about parameters found in the[tcp],[tcp default],[sci],[sci default],[shm], or[shm default]sections of the cluster configuration file (see Section 18.3.3.9, “MySQL Cluster TCP/IP Connections”, Section 18.3.3.12, “SCI Transport Connections in MySQL Cluster”, and Section 18.3.3.11, “MySQL Cluster Shared-Memory Connections”, for more information).This option is mutually exclusive with
--nodesand--system; only one of these 3 options can be used. -
Command-Line Format --systemPermitted Values Type booleanDefault FALSETells ndb_config to print
SYSTEMinformation only. This consists of system variables that cannot be changed at run time; thus, there is no corresponding section of the cluster configuration file for them. They can be seen (prefixed with****** SYSTEM ******) in the output of ndb_config--configinfo.This option is mutually exclusive with
--nodesand--connections; only one of these 3 options can be used. -
Command-Line Format --type=namePermitted Values Type enumerationDefault [none]Valid Values ndbdmysqldndb_mgmdFilters results so that only configuration values applying to nodes of the specified
node_type(ndbd,mysqld, orndb_mgmd) are returned. --fields=,delimiter-fdelimiterCommand-Line Format --fields=stringPermitted Values Type stringDefault Specifies a
delimiterstring used to separate the fields in the result. The default is “,” (the comma character).NoteIf the
delimitercontains spaces or escapes (such as\nfor the linefeed character), then it must be quoted.--rows=,separator-rseparatorCommand-Line Format --rows=stringPermitted Values Type stringDefault Specifies a
separatorstring used to separate the rows in the result. The default is a space character.NoteIf the
separatorcontains spaces or escapes (such as\nfor the linefeed character), then it must be quoted.The
--configinfooption causes ndb_config to dump a list of each MySQL Cluster configuration parameter supported by the MySQL Cluster distribution of which ndb_config is a part, including the following information:A brief description of each parameter's purpose, effects, and usage
The section of the
config.inifile where the parameter may be usedThe parameter's data type or unit of measurement
Where applicable, the parameter's default, minimum, and maximum values
MySQL Cluster release version and build information
By default, this output is in text format. Part of this output is shown here:
shell>
ndb_config --configinfo****** SYSTEM ****** Name (String) Name of system (NDB Cluster) MANDATORY PrimaryMGMNode (Non-negative Integer) Node id of Primary ndb_mgmd(MGM) node Default: 0 (Min: 0, Max: 4294967039) ConfigGenerationNumber (Non-negative Integer) Configuration generation number Default: 0 (Min: 0, Max: 4294967039) ****** DB ****** MaxNoOfSubscriptions (Non-negative Integer) Max no of subscriptions (default 0 == MaxNoOfTables) Default: 0 (Min: 0, Max: 4294967039) MaxNoOfSubscribers (Non-negative Integer) Max no of subscribers (default 0 == 2 * MaxNoOfTables) Default: 0 (Min: 0, Max: 4294967039) …Command-Line Format --configinfo --xmlPermitted Values Type booleanDefault falseYou can obtain the output of ndb_config
--configinfoas XML by adding the--xmloption. A portion of the resulting output is shown in this example:shell>
ndb_config --configinfo --xml<configvariables protocolversion="1" ndbversionstring="5.5.48-ndb-7.2.24" ndbversion="458758" ndbversionmajor="7" ndbversionminor="0" ndbversionbuild="6"> <section name="SYSTEM"> <param name="Name" comment="Name of system (NDB Cluster)" type="string" mandatory="true"/> <param name="PrimaryMGMNode" comment="Node id of Primary ndb_mgmd(MGM) node" type="unsigned" default="0" min="0" max="4294967039"/> <param name="ConfigGenerationNumber" comment="Configuration generation number" type="unsigned" default="0" min="0" max="4294967039"/> </section> <section name="NDBD"> <param name="MaxNoOfSubscriptions" comment="Max no of subscriptions (default 0 == MaxNoOfTables)" type="unsigned" default="0" min="0" max="4294967039"/> <param name="MaxNoOfSubscribers" comment="Max no of subscribers (default 0 == 2 * MaxNoOfTables)" type="unsigned" default="0" min="0" max="4294967039"/> … </section> … </configvariables>NoteNormally, the XML output produced by ndb_config
--configinfo--xmlis formatted using one line per element; we have added extra whitespace in the previous example, as well as the next one, for reasons of legibility. This should not make any difference to applications using this output, since most XML processors either ignore nonessential whitespace as a matter of course, or can be instructed to do so.The XML output also indicates when changing a given parameter requires that data nodes be restarted using the
--initialoption. This is shown by the presence of aninitial="true"attribute in the corresponding<param>element. In addition, the restart type (systemornode) is also shown; if a given parameter requires a system restart, this is indicated by the presence of arestart="system"attribute in the corresponding<param>element. For example, changing the value set for theDisklessparameter requires a system initial restart, as shown here (with therestartandinitialattributes highlighted for visibility):<param name="Diskless" comment="Run wo/ disk" type="bool" default="false" restart="system" initial="true"/>Currently, no
initialattribute is included in the XML output for<param>elements corresponding to parameters which do not require initial restarts; in other words,initial="false"is the default, and the valuefalseshould be assumed if the attribute is not present. Similarly, the default restart type isnode(that is, an online or “rolling” restart of the cluster), but therestartattribute is included only if the restart type issystem(meaning that all cluster nodes must be shut down at the same time, then restarted).ImportantThe
--xmloption can be used only with the--configinfooption. Using--xmlwithout--configinfofails with an error.Unlike the options used with this program to obtain current configuration data,
--configinfoand--xmluse information obtained from the MySQL Cluster sources when ndb_config was compiled. For this reason, no connection to a running MySQL Cluster or access to aconfig.iniormy.cnffile is required for these two options.Combining other ndb_config options (such as
--queryor--type) with--configinfoor--xmlis not supported. Currently, if you attempt to do so, the usual result is that all other options besides--configinfoor--xmlare simply ignored. However, this behavior is not guaranteed and is subject to change at any time. In addition, since ndb_config, when used with the--configinfooption, does not access the MySQL Cluster or read any files, trying to specify additional options such as--ndb-connectstringor--config-filewith--configinfoserves no purpose.
Examples
To obtain the node ID and type of each node in the cluster:
shell>
./ndb_config --query=id,type --fields=':' --rows='\n'1:ndbd 2:ndbd 3:ndbd 4:ndbd 5:ndb_mgmd 6:mysqld 7:mysqld 8:mysqld 9:mysqldIn this example, we used the
--fieldsoptions to separate the ID and type of each node with a colon character (:), and the--rowsoptions to place the values for each node on a new line in the output.To produce a connection string that can be used by data, SQL, and API nodes to connect to the management server:
shell>
./ndb_config --config-file=usr/local/mysql/cluster-data/config.ini \ --query=hostname,portnumber --fields=: --rows=, --type=ndb_mgmd192.168.0.179:1186This invocation of ndb_config checks only data nodes (using the
--typeoption), and shows the values for each node's ID and host name, as well as the values set for itsDataMemory,IndexMemory, andDataDirparameters:shell>
./ndb_config --type=ndbd --query=id,host,datamemory,indexmemory,datadir -f ' : ' -r '\n'1 : 192.168.0.193 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 2 : 192.168.0.112 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 3 : 192.168.0.176 : 83886080 : 18874368 : /usr/local/mysql/cluster-data 4 : 192.168.0.119 : 83886080 : 18874368 : /usr/local/mysql/cluster-dataIn this example, we used the short options
-fand-rfor setting the field delimiter and row separator, respectively.To exclude results from any host except one in particular, use the
--hostoption:shell>
./ndb_config --host=192.168.0.176 -f : -r '\n' -q id,type3:ndbd 5:ndb_mgmdIn this example, we also used the short form
-qto determine the attributes to be queried.Similarly, you can limit results to a node with a specific ID using the
--idor--nodeidoption.
A utility having this name was formerly part of an internal automated test framework used in testing and debugging MySQL Cluster. It was deprecated in MySQL Cluster NDB 7.0, and removed from MySQL Cluster distributions provided by Oracle beginning with MySQL Cluster NDB 7.2.1.
ndb_delete_all deletes all rows from the
given NDB table. In some cases,
this can be much faster than
DELETE or even
TRUNCATE TABLE.
Usage
ndb_delete_all -cconnection_stringtbl_name-ddb_name
This deletes all rows from the table named
tbl_name in the database named
db_name. It is exactly equivalent to
executing TRUNCATE
in MySQL.
db_name.tbl_name
The following table includes options that are specific to ndb_delete_all. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_delete_all), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.75 This table describes command-line options for the ndb_delete_all program
| Format | Description | Added or Removed |
|---|---|---|
|
Name of the database in which the table is found | All MySQL 5.5 based releases |
| Perform the delete in a single transaction (may run out of operations) | All MySQL 5.5 based releases |
|
|
Run tup scan | All MySQL 5.5 based releases |
|
Run disk scan | All MySQL 5.5 based releases |
ndb_desc provides a detailed description of
one or more NDB tables.
Usage
ndb_desc -cconnection_stringtbl_name-ddb_name[options]
(MySQL Cluster NDB 7.2.9 and later:)
ndb_desc -cconnection_stringindex_name-ddb_name-ttbl_name
Additional options that can be used with ndb_desc are listed later in this section.
Sample Output
MySQL table creation and population statements:
USE test;
CREATE TABLE fish (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
length_mm INT(11) NOT NULL,
weight_gm INT(11) NOT NULL,
PRIMARY KEY pk (id),
UNIQUE KEY uk (name)
) ENGINE=NDB;
INSERT INTO fish VALUES
('','guppy', 35, 2), ('','tuna', 2500, 150000),
('','shark', 3000, 110000), ('','manta ray', 1500, 50000),
('','grouper', 900, 125000), ('','puffer', 250, 2500);
Output from ndb_desc:
shell> ./ndb_desc -c localhost fish -d test -p
-- fish --
Version: 2
Fragment type: 9
K Value: 6
Min load factor: 78
Max load factor: 80
Temporary table: no
Number of attributes: 4
Number of primary keys: 1
Length of frm data: 311
Row Checksum: 1
Row GCI: 1
SingleUserMode: 0
ForceVarPart: 1
FragmentCount: 2
TableStatus: Retrieved
-- Attributes --
id Int PRIMARY KEY DISTRIBUTION KEY AT=FIXED ST=MEMORY AUTO_INCR
name Varchar(20;latin1_swedish_ci) NOT NULL AT=SHORT_VAR ST=MEMORY
length_mm Int NOT NULL AT=FIXED ST=MEMORY
weight_gm Int NOT NULL AT=FIXED ST=MEMORY
-- Indexes --
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
uk$unique(name) - UniqueHashIndex
uk(name) - OrderedIndex
-- Per partition info --
Partition Row count Commit count Frag fixed memory ...
0 2 2 32768 ...
1 4 4 32768 ...
... Frag varsized memory Extent_space Free extent_space
... 32768 0 0
... 32768 0 0
NDBT_ProgramExit: 0 - OK
Information about multiple tables can be obtained in a single invocation of ndb_desc by using their names, separated by spaces. All of the tables must be in the same database.
Beginning with MySQL Cluster NDB 7.2.9, it is possible to obtain
additional information about a specific index using the
--table (short form: -t)
option introduced in this version and supplying the name of the
index as the first argument to ndb_desc, as
shown here:
shell> ./ndb_desc uk -d test -t fish
-- uk --
Version: 3
Base table: fish
Number of attributes: 1
Logging: 0
Index type: OrderedIndex
Index status: Retrieved
-- Attributes --
name Varchar(20;latin1_swedish_ci) NOT NULL AT=SHORT_VAR ST=MEMORY
-- IndexTable 10/uk --
Version: 3
Fragment type: FragUndefined
K Value: 6
Min load factor: 78
Max load factor: 80
Temporary table: yes
Number of attributes: 2
Number of primary keys: 1
Length of frm data: 0
Row Checksum: 1
Row GCI: 1
SingleUserMode: 2
ForceVarPart: 0
FragmentCount: 4
ExtraRowGciBits: 0
ExtraRowAuthorBits: 0
TableStatus: Retrieved
-- Attributes --
name Varchar(20;latin1_swedish_ci) NOT NULL AT=SHORT_VAR ST=MEMORY
NDB$TNODE Unsigned [64] PRIMARY KEY DISTRIBUTION KEY AT=FIXED ST=MEMORY
-- Indexes --
PRIMARY KEY(NDB$TNODE) - UniqueHashIndex
NDBT_ProgramExit: 0 - OK
When an index is specified in this way, the
--extra-partition-info and
--extra-node-info options have
no effect.
The Version column in the output contains the
table's schema object version. For information about
interpreting this value, see
NDB Schema Object Versions.
The Extent_space and Free
extent_space columns are applicable only to
NDB tables having columns on disk; for tables
having only in-memory columns, these columns always contain the
value 0.
To illustrate their use, we modify the previous example. First, we must create the necessary Disk Data objects, as shown here:
CREATE LOGFILE GROUP lg_1
ADD UNDOFILE 'undo_1.log'
INITIAL_SIZE 16M
UNDO_BUFFER_SIZE 2M
ENGINE NDB;
ALTER LOGFILE GROUP lg_1
ADD UNDOFILE 'undo_2.log'
INITIAL_SIZE 12M
ENGINE NDB;
CREATE TABLESPACE ts_1
ADD DATAFILE 'data_1.dat'
USE LOGFILE GROUP lg_1
INITIAL_SIZE 32M
ENGINE NDB;
ALTER TABLESPACE ts_1
ADD DATAFILE 'data_2.dat'
INITIAL_SIZE 48M
ENGINE NDB;
(For more information on the statements just shown and the objects created by them, see Section 18.5.12.1, “MySQL Cluster Disk Data Objects”, as well as Section 13.1.14, “CREATE LOGFILE GROUP Syntax”, and Section 13.1.18, “CREATE TABLESPACE Syntax”.)
Now we can create and populate a version of the
fish table that stores 2 of its columns on
disk (deleting the previous version of the table first, if it
already exists):
CREATE TABLE fish (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(20) NOT NULL,
length_mm INT(11) NOT NULL,
weight_gm INT(11) NOT NULL,
PRIMARY KEY pk (id),
UNIQUE KEY uk (name)
) TABLESPACE ts_1 STORAGE DISK
ENGINE=NDB;
INSERT INTO fish VALUES
('','guppy', 35, 2), ('','tuna', 2500, 150000),
('','shark', 3000, 110000), ('','manta ray', 1500, 50000),
('','grouper', 900, 125000), ('','puffer', 250, 2500);
When run against this version of the table, ndb_desc displays the following output:
shell> ./ndb_desc -c localhost fish -d test -p
-- fish --
Version: 3
Fragment type: 9
K Value: 6
Min load factor: 78
Max load factor: 80
Temporary table: no
Number of attributes: 4
Number of primary keys: 1
Length of frm data: 321
Row Checksum: 1
Row GCI: 1
SingleUserMode: 0
ForceVarPart: 1
FragmentCount: 2
TableStatus: Retrieved
-- Attributes --
id Int PRIMARY KEY DISTRIBUTION KEY AT=FIXED ST=MEMORY AUTO_INCR
name Varchar(20;latin1_swedish_ci) NOT NULL AT=SHORT_VAR ST=MEMORY
length_mm Int NOT NULL AT=FIXED ST=DISK
weight_gm Int NOT NULL AT=FIXED ST=DISK
-- Indexes --
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
uk$unique(name) - UniqueHashIndex
uk(name) - OrderedIndex
-- Per partition info --
Partition Row count Commit count Frag fixed memory ...
0 2 2 32768 ...
1 4 4 32768 ...
... Frag varsized memory Extent_space Free extent_space
... 32768 0 0
... 32768 0 0
NDBT_ProgramExit: 0 - OK
This means that 1048576 bytes are allocated from the tablespace
for this table on each partition, of which 1044440 bytes remain
free for additional storage. In other words, 1048576 - 1044440 =
4136 bytes per partition is currently being used to store the
data from this table's disk-based columns. The number of
bytes shown as Free extent_space is available
for storing on-disk column data from the fish
table only; for this reason, it is not visible when selecting
from the INFORMATION_SCHEMA.FILES
table.
The following table includes options that are specific to ndb_desc. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_desc), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.76 This table describes command-line options for the ndb_desc program
| Format | Description | Added or Removed |
|---|---|---|
| Include partition information for BLOB tables in output. Requires that the -p option also be used | All MySQL 5.5 based releases |
|
| Name of database containing table | All MySQL 5.5 based releases |
|
| Include partition-to-data-node mappings in output. Requires that the -p option also be used | All MySQL 5.5 based releases |
|
| Display information about partitions | All MySQL 5.5 based releases |
|
| Number of times to retry the connection (once per second) | All MySQL 5.5 based releases |
|
| Specify the table in which to find an index. When this option is used, -p and -n have no effect and are ignored. | ADDED: NDB 7.2.9 |
|
| Use unqualified table names | All MySQL 5.5 based releases |
Include information about subordinate
BLOBandTEXTcolumns.Use of this option also requires the use of the
--extra-partition-info(-p) option.Specify the database in which the table should be found.
Include information about the mappings between table partitions and the data nodes upon which they reside. This information can be useful for verifying distribution awareness mechanisms and supporting more efficient application access to the data stored in MySQL Cluster.
Use of this option also requires the use of the
--extra-partition-info(-p) option.Print additional information about the table's partitions.
Try to connect this many times before giving up. One connect attempt is made per second.
Specify the table in which to look for an index.
This option was added in MySQL Cluster NDB 7.2.9.
Use unqualified table names.
ndb_drop_index drops the specified index from
an NDB table. It is
recommended that you use this utility only as an example for
writing NDB API applications—see the Warning
later in this section for details.
Usage
ndb_drop_index -cconnection_stringtable_nameindex-ddb_name
The statement shown above drops the index named
index from the
table in the
database.
The following table includes options that are specific to ndb_drop_index. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_drop_index), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.77 This table describes command-line options for the ndb_drop_index program
| Format | Description | Added or Removed |
|---|---|---|
|
Name of the database in which the table is found | All MySQL 5.5 based releases |
Operations performed on Cluster table indexes using the NDB API are not visible to MySQL and make the table unusable by a MySQL server. If you use this program to drop an index, then try to access the table from an SQL node, an error results, as shown here:
shell>./ndb_drop_index -c localhost dogs ix -d ctest1Dropping index dogs/idx...OK NDBT_ProgramExit: 0 - OK shell>./mysql -u jon -p ctest1Enter password: ******* Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 7 to server version: 5.5.48-ndb-7.2.24 Type 'help;' or '\h' for help. Type '\c' to clear the buffer. mysql>SHOW TABLES;+------------------+ | Tables_in_ctest1 | +------------------+ | a | | bt1 | | bt2 | | dogs | | employees | | fish | +------------------+ 6 rows in set (0.00 sec) mysql>SELECT * FROM dogs;ERROR 1296 (HY000): Got error 4243 'Index not found' from NDBCLUSTER
In such a case, your only option for making
the table available to MySQL again is to drop the table and
re-create it. You can use either the SQL
statementDROP TABLE or the
ndb_drop_table utility (see
Section 18.4.12, “ndb_drop_table — Drop an NDB Table”) to drop
the table.
ndb_drop_table drops the specified
NDB table. (If you try to use this
on a table created with a storage engine other than
NDB, the attempt fails with the
error 723: No such table exists.) This
operation is extremely fast; in some cases, it can be an order
of magnitude faster than using a MySQL DROP
TABLE statement on an NDB
table.
Usage
ndb_drop_table -cconnection_stringtbl_name-ddb_name
The following table includes options that are specific to ndb_drop_table. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_drop_table), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.78 This table describes command-line options for the ndb_drop_table program
| Format | Description | Added or Removed |
|---|---|---|
|
Name of the database in which the table is found | All MySQL 5.5 based releases |
ndb_error_reporter creates an archive from data node and management node log files that can be used to help diagnose bugs or other problems with a cluster. It is highly recommended that you make use of this utility when filing reports of bugs in MySQL Cluster.
The following table includes command options specific to the MySQL Cluster program ndb_error_reporter. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_error_reporter), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
ndb_error_reporter did not support the
--help option prior to MySQL
Cluster NDB 7.2.14 (Bug #11756666, Bug #48606). The
--connection-timeout
--dry-scp, and
--skip-nodegroup
options were also added in this release (Bug #16602002).
Table 18.79 This table describes command-line options for the ndb_error_reporter program
| Format | Description | Added or Removed |
|---|---|---|
| Number of seconds to wait when connecting to nodes before timing out. | ADDED: NDB 7.2.14 |
|
| Disable scp with remote hosts; used only for testing. | ADDED: NDB 7.2.14 |
|
| Include file system data in error report; can use a large amount of disk space | All MySQL 5.5 based releases |
|
| Skip all nodes in the node group having this ID. | ADDED: NDB 7.2.14 |
Usage
ndb_error_reporterpath/to/config-file[username] [options]
This utility is intended for use on a management node host, and
requires the path to the management host configuration file
(usually named config.ini). Optionally, you
can supply the name of a user that is able to access the
cluster's data nodes using SSH, to copy the data node log files.
ndb_error_reporter then includes all of these
files in archive that is created in the same directory in which
it is run. The archive is named
ndb_error_report_,
where YYYYMMDDHHMMSS.tar.bz2YYYYMMDDHHMMSS is a datetime
string.
ndb_error_reporter also accepts the options listed here:
-
Introduced 5.5.34-ndb-7.2.14 Command-Line Format --connection-timeout=timeoutPermitted Values Type integerDefault 0Wait this many seconds when trying to connect to nodes before timing out.
-
Introduced 5.5.34-ndb-7.2.14 Command-Line Format --dry-scpPermitted Values Type booleanDefault TRUERun ndb_error_reporter without using scp from remote hosts. Used for testing only.
-
Command-Line Format --fsPermitted Values Type booleanDefault FALSECopy the data node file systems to the management host and include them in the archive.
Because data node file systems can be extremely large, even after being compressed, we ask that you please do not send archives created using this option to Oracle unless you are specifically requested to do so.
-
Introduced 5.5.34-ndb-7.2.14 Command-Line Format --connection-timeout=timeoutPermitted Values Type integerDefault 0Skip all nodes belong to the node group having the supplied node group ID.
ndb_index_stat provides per-fragment
statistical information about indexes on NDB
tables. This includes cache version and age, number of index
entries per partition, and memory consumption by indexes.
Usage
To obtain basic index statistics about a given
NDB table, invoke
ndb_index_stat as shown here, with the name
of the table as the first argument and the name of the database
containing this table specified immediately following it, using
the --database
(-d) option:
ndb_index_stattable-ddatabase
In this example, we use ndb_index_stat to
obtain such information about an NDB table
named mytable in the test
database:
shell> ndb_index_stat -d test mytable
table:City index:PRIMARY fragCount:2
sampleVersion:3 loadTime:1399585986 sampleCount:1994 keyBytes:7976
query cache: valid:1 sampleCount:1994 totalBytes:27916
times in ms: save: 7.133 sort: 1.974 sort per sample: 0.000
NDBT_ProgramExit: 0 - OK
sampleVersion is the version number of the
cache from which the statistics data is taken. Running
ndb_index_stat with the
--update option causes
sampleVersion to be incremented.
loadTime shows when the cache was last
updated. This is expressed as seconds since the Unix Epoch.
sampleCount is the number of index entries
found per partition. You can estimate the total number of
entries by multiplying this by the number of fragments (shown as
fragCount).
sampleCount can be compared with the
cardinality of SHOW INDEX or
INFORMATION_SCHEMA.STATISTICS,
although the latter two provide a view of the table as a whole,
while ndb_index_stat provides a per-fragment
average.
keyBytes is the number of bytes used by the
index. In this example, the primary key is an integer, which
requires four bytes for each index, so
keyBytes can be calculated in this case as
shown here:
keyBytes = sampleCount * (4 bytes per index) = 1994 * 4 = 7976
This information can also be obtained using the corresponding
column definitions from
INFORMATION_SCHEMA.COLUMNS (this
requires a MySQL Server and a MySQL client application).
totalBytes is the total memory consumed by
all indexes on the table, in bytes.
Timings shown in the preceding examples are specific to each invocation of ndb_index_stat.
The --verbose option
provides some additional output, as shown here:
shell> ndb_index_stat -d test mytable --verbose
random seed 1337010518
connected
loop 1 of 1
table:mytable index:PRIMARY fragCount:4
sampleVersion:2 loadTime:1336751773 sampleCount:0 keyBytes:0
read stats
query cache created
query cache: valid:1 sampleCount:0 totalBytes:0
times in ms: save: 20.766 sort: 0.001
disconnected
NDBT_ProgramExit: 0 - OK
shell>
Options
The following table includes options that are specific to the MySQL Cluster ndb_index_stat utility. Additional descriptions are listed following the table. For options common to most MySQL Cluster programs (including ndb_index_stat), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.80 This table describes command-line options for the ndb_index_stat program
| Format | Description | Added or Removed |
|---|---|---|
| Name of the database containing the table. | All MySQL 5.5 based releases |
|
| Delete index statistics for the given table, stopping any auto-update previously configured. | All MySQL 5.5 based releases |
|
| Update index statistics for the given table, restarting any auto-update previously configured. | All MySQL 5.5 based releases |
|
| Print the query cache. | All MySQL 5.5 based releases |
|
| Perform a number of random range queries on first key attr (must be int unsigned). | All MySQL 5.5 based releases |
|
| Drop any statistics tables and events in NDB kernel (all statistics are lost) | All MySQL 5.5 based releases |
|
| Create all statistics tables and events in NDB kernel, if none of them already exist | All MySQL 5.5 based releases |
|
| Create any statistics tables and events in NDB kernel that do not already exist. | All MySQL 5.5 based releases |
|
| Create any statistics tables or events that do not already exist in the NDB kernel. after dropping any that are invalid. | All MySQL 5.5 based releases |
|
| Verify that NDB system index statistics and event tables exist. | All MySQL 5.5 based releases |
|
| Do not apply sys-* options to tables. | All MySQL 5.5 based releases |
|
| Do not apply sys-* options to events. | All MySQL 5.5 based releases |
|
| Turn on verbose output | All MySQL 5.5 based releases |
|
| Set the number of times to perform a given command. Default is 0. | All MySQL 5.5 based releases |
ndb_index_stat statistics options. The following options are used to generate index statistics. They work with a given table and database. They cannot be mixed with system options (see ndb_index_stat system options).
-
Command-Line Format --database=namePermitted Values Type stringDefault [none]Min Value Max Value The name of the database that contains the table being queried.
-
Command-Line Format --deletePermitted Values Type booleanDefault falseMin Value Max Value Delete the index statistics for the given table, stopping any auto-update that was previously configured.
-
Command-Line Format --updatePermitted Values Type booleanDefault falseMin Value Max Value Update the index statistics for the given table, and restart any auto-update that was previously configured.
-
Command-Line Format --dumpPermitted Values Type booleanDefault falseMin Value Max Value Dump the contents of the query cache.
-
Command-Line Format --query=#Permitted Values Type numericDefault 0Min Value 0Max Value MAX_INTPerform random range queries on first key attribute (must be int unsigned).
ndb_index_stat system options. The following options are used to generate and update the statistics tables in the NDB kernel. None of these options can be mixed with statistics options (see ndb_index_stat statistics options).
-
Command-Line Format --sys-dropPermitted Values Type booleanDefault falseMin Value Max Value Drop all statistics tables and events in the NDB kernel. This causes all statistics to be lost.
-
Command-Line Format --sys-createPermitted Values Type booleanDefault falseMin Value Max Value Create all statistics tables and events in the NDB kernel. This works only if none of them exist previously.
-
Command-Line Format --sys-create-if-not-existPermitted Values Type booleanDefault falseMin Value Max Value Create any NDB system statistics tables or events (or both) that do not already exist when the program is invoked.
-
Command-Line Format --sys-create-if-not-validPermitted Values Type booleanDefault falseMin Value Max Value Create any NDB system statistics tables or events that do not already exist, after dropping any that are invalid.
-
Command-Line Format --sys-checkPermitted Values Type booleanDefault falseMin Value Max Value Verify that all required system statistics tables and events exist in the NDB kernel.
-
Command-Line Format --sys-skip-tablesPermitted Values Type booleanDefault falseMin Value Max Value Do not apply any
--sys-*options to any statistics tables. -
Command-Line Format --sys-skip-eventsPermitted Values Type booleanDefault falseMin Value Max Value Do not apply any
--sys-*options to any events. -
Command-Line Format --verbosePermitted Values Type booleanDefault falseMin Value Max Value Turn on verbose output.
-
Command-Line Format --loops=#Permitted Values Type numericDefault 0Min Value 0Max Value MAX_INTRepeat commands this number of times (for use in testing).
ndb_print_backup_file obtains diagnostic information from a cluster backup file.
Usage
ndb_print_backup_file file_name
file_name is the name of a cluster
backup file. This can be any of the files
(.Data, .ctl, or
.log file) found in a cluster backup
directory. These files are found in the data node's backup
directory under the subdirectory
BACKUP-, where
## is the sequence number for the
backup. For more information about cluster backup files and
their contents, see
Section 18.5.3.1, “MySQL Cluster Backup Concepts”.
Like ndb_print_schema_file and
ndb_print_sys_file (and unlike most of the
other NDB utilities that are
intended to be run on a management server host or to connect to
a management server) ndb_print_backup_file
must be run on a cluster data node, since it accesses the data
node file system directly. Because it does not make use of the
management server, this utility can be used when the management
server is not running, and even when the cluster has been
completely shut down.
Additional Options
None.
ndb_print_file obtains information from a MySQL Cluster Disk Data file.
Usage
ndb_print_file [-v] [-q] file_name+
file_name is the name of a MySQL
Cluster Disk Data file. Multiple filenames are accepted,
separated by spaces.
Like ndb_print_schema_file and
ndb_print_sys_file (and unlike most of the
other NDB utilities that are
intended to be run on a management server host or to connect to
a management server) ndb_print_file must be
run on a MySQL Cluster data node, since it accesses the data
node file system directly. Because it does not make use of the
management server, this utility can be used when the management
server is not running, and even when the cluster has been
completely shut down.
Additional Options
ndb_print_file supports the following options:
-v: Make output verbose.-q: Suppress output (quiet mode).--help,-h,-?: Print help message.This option did not work correctly prior to MySQL Cluster NDB 7.2.18. (Bug #17069285)
For more information, see Section 18.5.12, “MySQL Cluster Disk Data Tables”.
ndb_print_schema_file obtains diagnostic information from a cluster schema file.
Usage
ndb_print_schema_file file_name
file_name is the name of a cluster
schema file. For more information about cluster schema files,
see MySQL Cluster Data Node File System Directory Files.
Like ndb_print_backup_file and
ndb_print_sys_file (and unlike most of the
other NDB utilities that are
intended to be run on a management server host or to connect to
a management server) ndb_schema_backup_file
must be run on a cluster data node, since it accesses the data
node file system directly. Because it does not make use of the
management server, this utility can be used when the management
server is not running, and even when the cluster has been
completely shut down.
Additional Options
None.
ndb_print_sys_file obtains diagnostic information from a MySQL Cluster system file.
Usage
ndb_print_sys_file file_name
file_name is the name of a cluster
system file (sysfile). Cluster system files are located in a
data node's data directory
(DataDir); the path
under this directory to system files matches the pattern
ndb_.
In each case, the #_fs/D#/DBDIH/P#.sysfile# represents a
number (not necessarily the same number). For more information,
see MySQL Cluster Data Node File System Directory Files.
Like ndb_print_backup_file and
ndb_print_schema_file (and unlike most of the
other NDB utilities that are
intended to be run on a management server host or to connect to
a management server) ndb_print_backup_file
must be run on a cluster data node, since it accesses the data
node file system directly. Because it does not make use of the
management server, this utility can be used when the management
server is not running, and even when the cluster has been
completely shut down.
Additional Options
None.
Reads a redo log file, checking it for errors, printing its contents in a human-readable format, or both. ndbd_redo_log_reader is intended for use primarily by MySQL Cluster developers and Support personnel in debugging and diagnosing problems.
This utility remains under development, and its syntax and behavior are subject to change in future MySQL Cluster releases.
The C++ source files for ndbd_redo_log_reader
can be found in the directory
/storage/ndb/src/kernel/blocks/dblqh/redoLogReader.
The following table includes options that are specific to the MySQL Cluster program ndbd_redo_log_reader. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndbd_redo_log_reader), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Usage
ndbd_redo_log_readerfile_name[options]
file_name is the name of a cluster
redo log file. redo log files are located in the numbered
directories under the data node's data directory
(DataDir); the path
under this directory to the redo log files matches the pattern
ndb_.
In each case, the #_fs/D#/LCP/#/T#F#.Data# represents a
number (not necessarily the same number). For more information,
see MySQL Cluster Data Node File System Directory Files.
The name of the file to be read may be followed by one or more of the options listed here:
Like ndb_print_backup_file and
ndb_print_schema_file (and unlike most of the
NDB utilities that are intended to
be run on a management server host or to connect to a management
server) ndbd_redo_log_reader must be run on a
cluster data node, since it accesses the data node file system
directly. Because it does not make use of the management server,
this utility can be used when the management server is not
running, and even when the cluster has been completely shut
down.
The cluster restoration program is implemented as a separate
command-line utility ndb_restore, which can
normally be found in the MySQL bin
directory. This program reads the files created as a result of
the backup and inserts the stored information into the database.
ndb_restore must be executed once for each of
the backup files that were created by the START
BACKUP command used to create the backup (see
Section 18.5.3.2, “Using The MySQL Cluster Management Client to Create a Backup”).
This is equal to the number of data nodes in the cluster at the
time that the backup was created.
Before using ndb_restore, it is recommended that the cluster be running in single user mode, unless you are restoring multiple data nodes in parallel. See Section 18.5.8, “MySQL Cluster Single User Mode”, for more information.
The following table includes options that are specific to the MySQL Cluster native backup restoration program ndb_restore. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_restore), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.82 This table describes command-line options for the ndb_restore program
| Format | Description | Added or Removed |
|---|---|---|
| Alias for --connectstring. | All MySQL 5.5 based releases |
|
| Restore backup files to node with this ID | All MySQL 5.5 based releases |
|
| Restore from the backup with the given ID | All MySQL 5.5 based releases |
|
| Restore table data and logs into NDB Cluster using the NDB API | All MySQL 5.5 based releases |
|
| Restore metadata to NDB Cluster using the NDB API | All MySQL 5.5 based releases |
|
| Do not upgrade array type for varsize attributes which do not already resize VAR data, and do not change column attributes | All MySQL 5.5 based releases |
|
| Allow attributes to be promoted when restoring data from backup | All MySQL 5.5 based releases |
|
| Allow preservation of trailing spaces (including padding) when promoting fixed-width string types to variable-width types | All MySQL 5.5 based releases |
|
| Do not restore objects relating to Disk Data | All MySQL 5.5 based releases |
|
| Restore epoch info into the status table. Convenient on a MySQL Cluster replication slave for starting replication. The row in mysql.ndb_apply_status with id 0 will be updated/inserted. | All MySQL 5.5 based releases |
|
| Skip table structure check during restoring of data | All MySQL 5.5 based releases |
|
| Number of parallel transactions to use while restoring data | All MySQL 5.5 based releases |
|
| Print metadata, data and log to stdout (equivalent to --print_meta --print_data --print_log) | All MySQL 5.5 based releases |
|
| Print metadata to stdout | All MySQL 5.5 based releases |
|
| Print data to stdout | All MySQL 5.5 based releases |
|
| Print to stdout | All MySQL 5.5 based releases |
|
| Path to backup files directory | All MySQL 5.5 based releases |
|
| Do not ignore system table during restore. Experimental only; not for production use | All MySQL 5.5 based releases |
|
| Nodegroup map for NDBCLUSTER storage engine. Syntax: list of (source_nodegroup, destination_nodegroup) | All MySQL 5.5 based releases |
|
| Fields are enclosed with the indicated character | All MySQL 5.5 based releases |
|
| Fields are terminated by the indicated character | All MySQL 5.5 based releases |
|
| Fields are optionally enclosed with the indicated character | All MySQL 5.5 based releases |
|
| Lines are terminated by the indicated character | All MySQL 5.5 based releases |
|
| Print binary types in hexadecimal format | All MySQL 5.5 based releases |
|
| Creates a tab-separated .txt file for each table in the given path | All MySQL 5.5 based releases |
|
| Append data to a tab-delimited file | All MySQL 5.5 based releases |
|
| Print status of restoration each given number of seconds | All MySQL 5.5 based releases |
|
| If a mysqld is connected and using binary logging, do not log the restored data | All MySQL 5.5 based releases |
|
| Level of verbosity in output | All MySQL 5.5 based releases |
|
| List of one or more databases to restore (excludes those not named) | All MySQL 5.5 based releases |
|
| List of one or more databases to exclude (includes those not named) | All MySQL 5.5 based releases |
|
| List of one or more tables to restore (excludes those in same database that are not named); each table reference must include the database name | All MySQL 5.5 based releases |
|
| List of one or more tables to exclude (includes those in the same database that are not named); each table reference must include the database name | All MySQL 5.5 based releases |
|
| Causes columns from the backup version of a table that are missing from the version of the table in the database to be ignored. | All MySQL 5.5 based releases |
|
| Causes tables from the backup that are missing from the database to be ignored. | ADDED: NDB 7.2.18 |
|
| Causes indexes from a backup to be ignored; may decrease time needed to restore data. | All MySQL 5.5 based releases |
|
| Causes multi-threaded rebuilding of ordered indexes found in the backup. Number of threads used is determined by setting BuildIndexThreads parameter. | All MySQL 5.5 based releases |
|
| Causes missing blob tables in the backup file to be ignored. | All MySQL 5.5 based releases |
|
| Causes schema objects not recognized by ndb_restore to be ignored when restoring a backup made from a newer MySQL Cluster version to an older version. | All MySQL 5.5 based releases |
|
| Restores to a database with a different name than the original | All MySQL 5.5 based releases |
|
| Allow lossy conversions of column values (type demotions or changes in sign) when restoring data from backup | All MySQL 5.5 based releases |
|
| Restore MySQL privilege tables that were previously moved to NDB. | All MySQL 5.5 based releases |
|
| If TRUE (the default), do not restore any intermediate tables (having names prefixed with '#sql-') that were left over from copying ALTER TABLE operations. | ADDED: NDB 7.2.17 |
Typical options for this utility are shown here:
ndb_restore [-cconnection_string] -nnode_id-bbackup_id\ [-m] -r --backup_path=/path/to/backup/files
Normally, when restoring from a MySQL Cluster backup,
ndb_restore requires at a minimum the
--nodeid (short form:
-n),
--backupid (short form:
-b), and
--backup_path options.
The -c option is used to specify a connection
string which tells ndb_restore where to
locate the cluster management server. (See
Section 18.3.3.3, “MySQL Cluster Connection Strings”, for
information on connection strings.) If this option is not used,
then ndb_restore attempts to connect to a
management server on localhost:1186. This
utility acts as a cluster API node, and so requires a free
connection “slot” to connect to the cluster
management server. This means that there must be at least one
[api] or [mysqld] section
that can be used by it in the cluster
config.ini file. It is a good idea to keep
at least one empty [api] or
[mysqld] section in
config.ini that is not being used for a
MySQL server or other application for this reason (see
Section 18.3.3.7, “Defining SQL and Other API Nodes in a MySQL Cluster”).
You can verify that ndb_restore is connected to the cluster by using the SHOW command in the ndb_mgm management client. You can also accomplish this from a system shell, as shown here:
shell> ndb_mgm -e "SHOW"
The --nodeid or -n is used to
specify the node ID of the data node on which the backup should
be restored.
The first time you run the ndb_restore
restoration program, you also need to restore the metadata. In
other words, you must re-create the database tables—this
can be done by running it with the
--restore_meta (-m) option.
Restoring the metdata need be done only on a single data node;
this is sufficient to restore it to the entire cluster. Note
that the cluster should have an empty database when starting to
restore a backup. (In other words, you should start
ndbd with --initial prior to
performing the restore.)
It is possible to restore data without restoring table metadata.
The default behavior when doing this is for
ndb_restore to fail with an error if table
data do not match the table schema; this can be overridden using
the --skip-table-check or -s
option.
Some of the restrictions on mismatches in column definitions
when restoring data using ndb_restore are
relaxed; when one of these types of mismatches is encountered,
ndb_restore does not stop with an error as it
did previously, but rather accepts the data and inserts it into
the target table while issuing a warning to the user that this
is being done. This behavior occurs whether or not either of the
options --skip-table-check or
--promote-attributes is in
use. These differences in column definitions are of the
following types:
Different
COLUMN_FORMATsettings (FIXED,DYNAMIC,DEFAULT)Different
STORAGEsettings (MEMORY,DISK)Different default values
Different distribution key settings
ndb_restore supports limited
attribute promotion in
much the same way that it is supported by MySQL replication;
that is, data backed up from a column of a given type can
generally be restored to a column using a “larger,
similar” type. For example, data from a
CHAR(20) column can be restored to a column
declared as VARCHAR(20),
VARCHAR(30), or CHAR(30);
data from a MEDIUMINT column can
be restored to a column of type
INT or
BIGINT. See
Section 17.4.1.10.2, “Replication of Columns Having Different Data Types”, for
a table of type conversions currently supported by attribute
promotion.
Attribute promotion by ndb_restore must be enabled explicitly, as follows:
Prepare the table to which the backup is to be restored. ndb_restore cannot be used to re-create the table with a different definition from the original; this means that you must either create the table manually, or alter the columns which you wish to promote using
ALTER TABLEafter restoring the table metadata but before restoring the data.Invoke ndb_restore with the
--promote-attributesoption (short form-A) when restoring the table data. Attribute promotion does not occur if this option is not used; instead, the restore operation fails with an error.
Prior to MySQL Cluster NDB 7.2.14, conversions between character
data types and TEXT or
BLOB were not handled correctly (Bug
#17325051).
Prior to MySQL Cluster NDB 7.2.18, demotion of
TEXT to
TINYTEXT was not handled
correctly (Bug #18875137).
When converting between character data types and
TEXT or BLOB, only
conversions between character types
(CHAR and
VARCHAR) and binary types
(BINARY and
VARBINARY) can be performed at
the same time. For example, you cannot promote an
INT column to
BIGINT while promoting a
VARCHAR column to TEXT in
the same invocation of ndb_restore.
Converting between TEXT columns
using different character sets is not supported. Beginning with
MySQL Cluster NDB 7.2.18, it is expressly disallowed (Bug
#18875137).
When performing conversions of character or binary types to
TEXT or BLOB with
ndb_restore, you may notice that it creates
and uses one or more staging tables named
table_name$STnode_id
| Command-Line Format | --lossy-conversions | ||
| Permitted Values | Type | boolean | |
| Default | FALSE | ||
This option is intended to complement the
--promote-attributes option.
Using --lossy-conversions allows lossy
conversions of column values (type demotions or changes in sign)
when restoring data from backup. With some exceptions, the rules
governing demotion are the same as for MySQL replication; see
Section 17.4.1.10.2, “Replication of Columns Having Different Data Types”, for
information about specific type conversions currently supported
by attribute demotion.
ndb_restore reports any truncation of data that it performs during lossy conversions once per attribute and column.
The --preserve-trailing-spaces option (short
form -R) causes trailing spaces to be preserved
when promoting a fixed-width character data type to its
variable-width equivalent—that is, when promoting a
CHAR column value to
VARCHAR or a
BINARY column value to
VARBINARY. Otherwise, any
trailing spaces are dropped from such column values when they
are inserted into the new columns.
Although you can promote CHAR
columns to VARCHAR and
BINARY columns to
VARBINARY, you cannot promote
VARCHAR columns to
CHAR or
VARBINARY columns to
BINARY.
The -b option is used to specify the ID or
sequence number of the backup, and is the same number shown by
the management client in the Backup
message
displayed upon completion of a backup. (See
Section 18.5.3.2, “Using The MySQL Cluster Management Client to Create a Backup”.)
backup_id completed
When restoring cluster backups, you must be sure to restore all data nodes from backups having the same backup ID. Using files from different backups will at best result in restoring the cluster to an inconsistent state, and may fail altogether.
--restore_epoch (short form:
-e) adds (or restores) epoch information to the
cluster replication status table. This is useful for starting
replication on a MySQL Cluster replication slave. When this
option is used, the row in the
mysql.ndb_apply_status having
0 in the id column is
updated if it already exists; such a row is inserted if it does
not already exist. (See
Section 18.6.9, “MySQL Cluster Backups With MySQL Cluster Replication”.)
This option causes ndb_restore to output
NDB table data and logs.
This option causes ndb_restore to print
NDB table metadata. Generally, you
need only use this option when restoring the first data node of
a cluster; additional data nodes can obtain the metadata from
the first one.
ndb_restore does not by default restore distributed MySQL privilege tables (MySQL Cluster NDB 7.2.0 and later). This option causes ndb_restore to restore the privilege tables.
This works only if the privilege tables were converted to
NDB before the backup was taken.
For more information, see
Section 18.5.14, “Distributed MySQL Privileges for MySQL Cluster”.
The path to the backup directory is required; this is supplied
to ndb_restore using the
--backup_path option, and must include the
subdirectory corresponding to the ID backup of the backup to be
restored. For example, if the data node's
DataDir is
/var/lib/mysql-cluster, then the backup
directory is /var/lib/mysql-cluster/BACKUP,
and the backup files for the backup with the ID 3 can be found
in /var/lib/mysql-cluster/BACKUP/BACKUP-3.
The path may be absolute or relative to the directory in which
the ndb_restore executable is located, and
may be optionally prefixed with backup_path=.
It is possible to restore a backup to a database with a
different configuration than it was created from. For example,
suppose that a backup with backup ID 12,
created in a cluster with two database nodes having the node IDs
2 and 3, is to be restored
to a cluster with four nodes. Then
ndb_restore must be run twice—once for
each database node in the cluster where the backup was taken.
However, ndb_restore cannot always restore
backups made from a cluster running one version of MySQL to a
cluster running a different MySQL version. See
Section 18.2.7, “Upgrading and Downgrading MySQL Cluster NDB 7.2”, for more
information.
It is not possible to restore a backup made from a newer version of MySQL Cluster using an older version of ndb_restore. You can restore a backup made from a newer version of MySQL to an older cluster, but you must use a copy of ndb_restore from the newer MySQL Cluster version to do so.
For example, to restore a cluster backup taken from a cluster running MySQL Cluster NDB 7.2.5 to a cluster running MySQL Cluster NDB 7.1.21, you must use the ndb_restore that comes with the MySQL Cluster NDB 7.2.5 distribution.
For more rapid restoration, the data may be restored in
parallel, provided that there is a sufficient number of cluster
connections available. That is, when restoring to multiple nodes
in parallel, you must have an [api] or
[mysqld] section in the cluster
config.ini file available for each
concurrent ndb_restore process. However, the
data files must always be applied before the logs.
When using ndb_restore to restore a backup,
VARCHAR columns created using the
old fixed format are resized and recreated using the
variable-width format now employed. This behavior can be
overridden using the
--no-upgrade option (short
form: -u) when running
ndb_restore.
The --print_data option causes
ndb_restore to direct its output to
stdout.
TEXT and
BLOB column values are always
truncated. In MySQL Cluster NDB 7.2.18 and earlier, such values
are truncated to the first 240 bytes in the output; in MySQL
Cluster NDB 7.2.19 and later, they are truncated to 256 bytes.
(Bug #14571512, Bug #65467) This cannot currently be overridden
when using --print_data.
Several additional options are available for use with the
--print_data option in generating data dumps,
either to stdout, or to a file. These are
similar to some of the options used with
mysqldump, and are shown in the following
list:
-
Command-Line Format --tab=dir_namePermitted Values Type directory nameThis option causes
--print_datato create dump files, one per table, each namedtbl_name.txt.for the current directory. -
Command-Line Format --fields-enclosed-by=charPermitted Values Type stringDefault Each column values are enclosed by the string passed to this option (regardless of data type; see next item).
--fields-optionally-enclosed-by=stringCommand-Line Format --fields-optionally-enclosed-byPermitted Values Type stringDefault The string passed to this option is used to enclose column values containing character data (such as
CHAR,VARCHAR,BINARY,TEXT, orENUM).-
Command-Line Format --fields-terminated-by=charPermitted Values Type stringDefault \t (tab)The string passed to this option is used to separate column values. The default value is a tab character (
\t). -
Command-Line Format --hexIf this option is used, all binary values are output in hexadecimal format.
-
Command-Line Format --fields-terminated-by=charPermitted Values Type stringDefault \t (tab)This option specifies the string used to end each line of output. The default is a linefeed character (
\n). -
Command-Line Format --appendWhen used with the
--taband--print_dataoptions, this causes the data to be appended to any existing files having the same names.
If a table has no explicit primary key, then the output
generated when using the
--print_data option
includes the table's hidden primary key.
This option causes ndb_restore to print all
metadata to stdout.
The --print_log option causes
ndb_restore to output its log to
stdout.
Causes ndb_restore to print all data,
metadata, and logs to stdout. Equivalent to
using the --print_data,
--print_meta, and
--print_log options
together.
Use of --print or any of the
--print_* options is in effect performing a
dry run. Including one or more of these options causes any
output to be redirected to stdout; in such
cases, ndb_restore makes no attempt to
restore data or metadata to a MySQL Cluster.
Normally, when restoring table data and metadata,
ndb_restore ignores the copy of the
NDB system table that is present in
the backup. --dont_ignore_systab_0 causes the
system table to be restored. This option is intended
for experimental and development use only, and is not
recommended in a production environment.
This option can be used to restore a backup taken from one node
group to a different node group. Its argument is a list of the
form source_node_group,
target_node_group
This option prevents any connected SQL nodes from writing data restored by ndb_restore to their binary logs.
This option stops ndb_restore from restoring any MySQL Cluster Disk Data objects, such as tablespaces and log file groups; see Section 18.5.12, “MySQL Cluster Disk Data Tables”, for more information about these.
Determines the maximum number of parallel transactions that ndb_restore tries to use. By default, this is 128; the minimum is 1, and the maximum is 1024.
Print a status report each N seconds
while the backup is in progress. 0 (the default) causes no
status reports to be printed. The maximum is 65535.
Sets the level for the verbosity of the output. The minimum is 0; the maximum is 255. The default value is 1.
It is possible to restore only selected databases, or selected tables from a single database, using the syntax shown here:
ndb_restoreother_optionsdb_name,[db_name[,...] |tbl_name[,tbl_name][,...]]
In other words, you can specify either of the following to be restored:
All tables from one or more databases
One or more tables from a single database
--include-databases=
db_name[,db_name][,...]
| Command-Line Format | --include-databases=db-list | ||
| Permitted Values | Type | string | |
| Default | | ||
--include-tables=
db_name.tbl_name[,db_name.tbl_name][,...]
| Command-Line Format | --include-tables=table-list | ||
| Permitted Values | Type | string | |
| Default | | ||
Use the --include-databases
option or the --include-tables option for
restoring only specific databases or tables, respectively.
--include-databases takes a comma-delimited
list of databases to be restored.
--include-tables takes a comma-delimited list
of tables (in
database.table
When --include-databases or
--include-tables is used, only those databases
or tables named by the option are restored; all other databases
and tables are excluded by ndb_restore, and
are not restored.
The following table shows several invocations of
ndb_restore using
--include-* options (other options possibly
required have been omitted for clarity), and the effects these
have on restoring from a MySQL Cluster backup:
| Option Used | Result |
|---|---|
--include-databases=db1 | Only tables in database db1 are restored; all tables
in all other databases are ignored |
--include-databases=db1,db2 (or
--include-databases=db1
--include-databases=db2) | Only tables in databases db1 and
db2 are restored; all tables in all
other databases are ignored |
--include-tables=db1.t1 | Only table t1 in database db1 is
restored; no other tables in db1 or
in any other database are restored |
--include-tables=db1.t2,db2.t1 (or
--include-tables=db1.t2
--include-tables=db2.t1) | Only the table t2 in database db1
and the table t1 in database
db2 are restored; no other tables in
db1, db2, or any
other database are restored |
You can also use these two options together. For example, the
following causes all tables in databases db1
and db2, together with the tables
t1 and t2 in database
db3, to be restored (and no other databases
or tables):
shell> ndb_restore [...] --include-databases=db1,db2 --include-tables=db3.t1,db3.t2
(Again we have omitted other, possibly required, options in the example just shown.)
--exclude-databases=
db_name[,db_name][,...]
| Command-Line Format | --exclude-databases=db-list | ||
| Permitted Values | Type | string | |
| Default | | ||
--exclude-tables=
db_name.tbl_name[,db_name.tbl_name][,...]
| Command-Line Format | --exclude-tables=table-list | ||
| Permitted Values | Type | string | |
| Default | | ||
It is possible to prevent one or more databases or tables from
being restored using the ndb_restore options
--exclude-databases and
--exclude-tables.
--exclude-databases takes a comma-delimited
list of one or more databases which should not be restored.
--exclude-tables takes a comma-delimited list
of one or more tables (using
database.table
When --exclude-databases or
--exclude-tables is used, only those databases
or tables named by the option are excluded; all other databases
and tables are restored by ndb_restore.
This table shows several invocations of
ndb_restore usng --exclude-*
options (other options possibly required have been omitted for
clarity), and the effects these options have on restoring from a
MySQL Cluster backup:
| Option Used | Result |
|---|---|
--exclude-databases=db1 | All tables in all databases except db1 are restored;
no tables in db1 are restored |
--exclude-databases=db1,db2 (or
--exclude-databases=db1
--exclude-databases=db2) | All tables in all databases except db1 and
db2 are restored; no tables in
db1 or db2 are
restored |
--exclude-tables=db1.t1 | All tables except t1 in database
db1 are restored; all other tables in
db1 are restored; all tables in all
other databases are restored |
--exclude-tables=db1.t2,db2.t1 (or
--exclude-tables=db1.t2
--exclude-tables=db2.t1) | All tables in database db1 except for
t2 and all tables in database
db2 except for table
t1 are restored; no other tables in
db1 or db2 are
restored; all tables in all other databases are restored |
You can use these two options together. For example, the
following causes all tables in all databases except
for databases db1 and
db2, and tables t1 and
t2 in database db3, to be
restored:
shell> ndb_restore [...] --exclude-databases=db1,db2 --exclude-tables=db3.t1,db3.t2
(Again, we have omitted other possibly necessary options in the interest of clarity and brevity from the example just shown.)
You can use --include-* and
--exclude-* options together, subject to the
following rules:
The actions of all
--include-*and--exclude-*options are cumulative.All
--include-*and--exclude-*options are evaluated in the order passed to ndb_restore, from right to left.In the event of conflicting options, the first (rightmost) option takes precedence. In other words, the first option (going from right to left) that matches against a given database or table “wins”.
For example, the following set of options causes
ndb_restore to restore all tables from
database db1 except
db1.t1, while restoring no other tables from
any other databases:
--include-databases=db1 --exclude-tables=db1.t1
However, reversing the order of the options just given simply
causes all tables from database db1 to be
restored (including db1.t1, but no tables
from any other database), because the
--include-databases option,
being farthest to the right, is the first match against database
db1 and thus takes precedence over any other
option that matches db1 or any tables in
db1:
--exclude-tables=db1.t1 --include-databases=db1
| Command-Line Format | --exclude-missing-columns | ||
It is also possible to restore only selected table columns using
the --exclude-missing-columns option. When this
option is used, ndb_restore ignores any
columns missing from tables being restored as compared to the
versions of those tables found in the backup. This option
applies to all tables being restored. If you wish to apply this
option only to selected tables or databases, you can use it in
combination with one or more of the options described in the
previous paragraph to do so, then restore data to the remaining
tables using a complementary set of these options.
| Introduced | 5.5.40-ndb-7.2.18 | ||
| Command-Line Format | --exclude-missing-tables | ||
Beginning with MySQL Cluster NDB 7.2.17, it is also possible to restore only selected tables columns using this option, which causes ndb_restore to ignore any tables from the backup that are not found in the target database.
| Command-Line Format | --disable-indexes | ||
Disable restoration of indexes during restoration of the data
from a native NDB backup. Afterwards, you can restore indexes
for all tables at once with multi-threaded building of indexes
using --rebuild-indexes,
which should be faster than rebuilding indexes concurrently for
very large tables.
| Command-Line Format | --rebuild-indexes | ||
You can use this option with ndb_restore to
cause multi-threaded rebuilding of the ordered indexes while
restoring a native NDB backup. The number of
threads used for building ordered indexes by
ndb_restore with this option is controlled by
the BuildIndexThreads
data node configuration parameter (MySQL Cluster NDB 6.3.30 and
later; MySQL Cluster NDB 7.0.11 and later).
It is necessary to use this option only for the first run of
ndb_restore; this causes all ordered indexes
to be rebuilt without using --rebuild-indexes
again when restoring subsequent nodes. You should use this
option prior to inserting new rows into the database; otherwise,
it is possible for a row to be inserted that later causes a
unique constraint violation when trying to rebuild the indexes.
Rebuilding of unique indexes uses disk write bandwidth for redo
logging and local checkpointing. An insufficient amount of this
bandwith can lead to redo buffer overload or log overload
errors. In such cases you can run ndb_restore
--rebuild-indexes again; the process resumes at
the point where the error occurred. You can also do this when
you have encountered temporarary errors. You can repeat
execution of ndb_restore
--rebuild-indexes indefinitely; you may be able
to stop such errors by reducing the value of
DiskCheckpointSpeed to
provide additional disk bandwidth to redo logging.
| Command-Line Format | --skip-broken-objects | ||
This option causes ndb_restore to ignore
corrupt tables while reading a native
NDB backup, and to continue
restoring any remaining tables (that are not also corrupted).
Currently, the --skip-broken-objects option
works only in the case of missing blob parts tables.
| Command-Line Format | --skip-unknown-objects | ||
This option causes ndb_restore to ignore any
schema objects it does not recognize while reading a native
NDB backup. This can be used for
restoring a backup made from a cluster running MySQL Cluster NDB
7.2 to a cluster running MySQL Cluster NDB 7.1.
--rewrite-database=
old_dbname,new_dbname
| Command-Line Format | --rewrite-database=olddb,newdb | ||
| Permitted Values | Type | string | |
| Default | none | ||
This option makes it possible to restore to a database having a
different name from that used in the backup. For example, if a
backup is made of a database named products,
you can restore the data it contains to a database named
inventory, use this option as shown here
(omitting any other options that might be required):
shell> ndb_restore --rewrite-database=product,inventory
The option can be employed multiple times in a single invocation
of ndb_restore. Thus it is possible to
restore simultaneously from a database named
db1 to a database named
db2 and from a database named
db3 to one named db4 using
--rewrite-database=db1,db2
--rewrite-database=db3,db4. Other
ndb_restore options may be used between
multiple occurrences of --rewrite-database.
In the event of conflicts between multiple
--rewrite-database options, the last
--rewrite-database option used, reading from
left to right, is the one that takes effect. For example, if
--rewrite-database=db1,db2
--rewrite-database=db1,db3 is used, only
--rewrite-database=db1,db3 is honored, and
--rewrite-database=db1,db2 is ignored. It is
also possible to restore from multiple databases to a single
database, so that --rewrite-database=db1,db3
--rewrite-database=db2,db3 restores all tables and data
from databases db1 and db2
into database db3.
When restoring from multiple backup databases into a single
target database using --rewrite-database, no
check is made for collisions between table or other object
names, and the order in which rows are restored is not
guaranteed. This means that it is possible in such cases for
rows to be overwritten and updates to be lost.
--exclude-intermediate-sql-tables[=TRUE|FALSE]
| Introduced | 5.5.37-ndb-7.2.17 | ||
| Command-Line Format | --exclude-intermediate-sql-tables[=TRUE|FALSE] | ||
| Permitted Values | Type | boolean | |
| Default | TRUE | ||
When performing copying ALTER
TABLE operations, mysqld creates
intermediate tables (whose names are prefixed with
#sql-). When TRUE, the
--exclude-intermediate-sql-tables option keeps
ndb_restore from restoring such tables that
may have been left over from such operations. This option is
TRUE by default.
The --exclude-intermediate-sql-tables option
was introduced in MySQL Cluster NDB 7.2.17. (Bug #17882305)
Error reporting.
ndb_restore reports both temporary and
permanent errors. In the case of temporary errors, it may able
to recover from them, and reports Restore successful,
but encountered temporary error, please look at
configuration in such cases.
After using ndb_restore to initialize a
MySQL Cluster for use in circular replication, binary logs on
the SQL node acting as the replication slave are not
automatically created, and you must cause them to be created
manually. To cause the binary logs to be created, issue a
SHOW TABLES statement on that
SQL node before running START
SLAVE. This is a known issue in MySQL Cluster.
ndb_select_all prints all rows from an
NDB table to
stdout.
Usage
ndb_select_all -cconnection_stringtbl_name-ddb_name[>file_name]
The following table includes options that are specific to the MySQL Cluster native backup restoration program ndb_select_all. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_select_all), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.83 This table describes command-line options for the ndb_select_all program
| Format | Description | Added or Removed |
|---|---|---|
| Name of the database in which the table is found | All MySQL 5.5 based releases |
|
| Degree of parallelism | All MySQL 5.5 based releases |
|
| Lock type | All MySQL 5.5 based releases |
|
| Sort resultset according to index whose name is supplied | All MySQL 5.5 based releases |
|
| Sort resultset in descending order (requires order flag) | All MySQL 5.5 based releases |
|
| Print header (set to 0|FALSE to disable headers in output) | All MySQL 5.5 based releases |
|
| Output numbers in hexadecimal format | All MySQL 5.5 based releases |
|
| Set a column delimiter | All MySQL 5.5 based releases |
|
| Print disk references (useful only for Disk Data tables having nonindexed columns) | All MySQL 5.5 based releases |
|
| Print rowid | All MySQL 5.5 based releases |
|
| Include GCI in output | All MySQL 5.5 based releases |
|
| Include GCI and row epoch in output | All MySQL 5.5 based releases |
|
| Scan in tup order | All MySQL 5.5 based releases |
|
| Do not print table column data | All MySQL 5.5 based releases |
Name of the database in which the table is found. The default value is
TEST_DB.Specifies the degree of parallelism.
--lock=,lock_type-llock_typeEmploys a lock when reading the table. Possible values for
lock_typeare:0: Read lock1: Read lock with hold2: Exclusive read lock
There is no default value for this option.
--order=,index_name-oindex_nameOrders the output according to the index named
index_name. Note that this is the name of an index, not of a column, and that the index must have been explicitly named when created.Sorts the output in descending order. This option can be used only in conjunction with the
-o(--order) option.Excludes column headers from the output.
Causes all numeric values to be displayed in hexadecimal format. This does not affect the output of numerals contained in strings or datetime values.
--delimiter=,character-DcharacterCauses the
characterto be used as a column delimiter. Only table data columns are separated by this delimiter.The default delimiter is the tab character.
Adds a disk reference column to the output. The column is nonempty only for Disk Data tables having nonindexed columns.
Adds a
ROWIDcolumn providing information about the fragments in which rows are stored.Adds a
GCIcolumn to the output showing the global checkpoint at which each row was last updated. See Section 18.1, “MySQL Cluster Overview”, and Section 18.5.6.2, “MySQL Cluster Log Events”, for more information about checkpoints.Adds a
ROW$GCI64column to the output showing the global checkpoint at which each row was last updated, as well as the number of the epoch in which this update occurred.Scan the table in the order of the tuples.
Causes any table data to be omitted.
Sample Output
Output from a MySQL SELECT
statement:
mysql> SELECT * FROM ctest1.fish;
+----+-----------+
| id | name |
+----+-----------+
| 3 | shark |
| 6 | puffer |
| 2 | tuna |
| 4 | manta ray |
| 5 | grouper |
| 1 | guppy |
+----+-----------+
6 rows in set (0.04 sec)
Output from the equivalent invocation of ndb_select_all:
shell> ./ndb_select_all -c localhost fish -d ctest1
id name
3 [shark]
6 [puffer]
2 [tuna]
4 [manta ray]
5 [grouper]
1 [guppy]
6 rows returned
NDBT_ProgramExit: 0 - OK
Note that all string values are enclosed by square brackets
(“[...]”) in
the output of ndb_select_all. For a further
example, consider the table created and populated as shown here:
CREATE TABLE dogs (
id INT(11) NOT NULL AUTO_INCREMENT,
name VARCHAR(25) NOT NULL,
breed VARCHAR(50) NOT NULL,
PRIMARY KEY pk (id),
KEY ix (name)
)
TABLESPACE ts STORAGE DISK
ENGINE=NDBCLUSTER;
INSERT INTO dogs VALUES
('', 'Lassie', 'collie'),
('', 'Scooby-Doo', 'Great Dane'),
('', 'Rin-Tin-Tin', 'Alsatian'),
('', 'Rosscoe', 'Mutt');
This demonstrates the use of several additional ndb_select_all options:
shell> ./ndb_select_all -d ctest1 dogs -o ix -z --gci --disk
GCI id name breed DISK_REF
834461 2 [Scooby-Doo] [Great Dane] [ m_file_no: 0 m_page: 98 m_page_idx: 0 ]
834878 4 [Rosscoe] [Mutt] [ m_file_no: 0 m_page: 98 m_page_idx: 16 ]
834463 3 [Rin-Tin-Tin] [Alsatian] [ m_file_no: 0 m_page: 34 m_page_idx: 0 ]
835657 1 [Lassie] [Collie] [ m_file_no: 0 m_page: 66 m_page_idx: 0 ]
4 rows returned
NDBT_ProgramExit: 0 - OK
ndb_select_count prints the number of rows in
one or more NDB tables. With a
single table, the result is equivalent to that obtained by using
the MySQL statement SELECT COUNT(*) FROM
.
tbl_name
Usage
ndb_select_count [-cconnection_string] -ddb_nametbl_name[,tbl_name2[, ...]]
The following table includes options that are specific to the MySQL Cluster native backup restoration program ndb_select_count. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_select_count), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.84 This table describes command-line options for the ndb_select_count program
| Format | Description | Added or Removed |
|---|---|---|
|
Name of the database in which the table is found | All MySQL 5.5 based releases |
|
Degree of parallelism | All MySQL 5.5 based releases |
|
Lock type | All MySQL 5.5 based releases |
You can obtain row counts from multiple tables in the same database by listing the table names separated by spaces when invoking this command, as shown under Sample Output.
Sample Output
shell> ./ndb_select_count -c localhost -d ctest1 fish dogs
6 records in table fish
4 records in table dogs
NDBT_ProgramExit: 0 - OK
ndb_show_tables displays a list of all
NDB database objects in the
cluster. By default, this includes not only both user-created
tables and NDB system tables, but
NDB-specific indexes, internal
triggers, and MySQL Cluster Disk Data objects as well.
The following table includes options that are specific to the MySQL Cluster native backup restoration program ndb_show_tables. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_show_tables), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.85 This table describes command-line options for the ndb_show_tables program
| Format | Description | Added or Removed |
|---|---|---|
| Specifies the database in which the table is found | All MySQL 5.5 based releases |
|
| Number of times to repeat output | All MySQL 5.5 based releases |
|
| Limit output to objects of this type | All MySQL 5.5 based releases |
|
| Do not qualify table names | All MySQL 5.5 based releases |
|
| Return output suitable for MySQL LOAD DATA INFILE statement | All MySQL 5.5 based releases |
|
| Show table temporary flag | All MySQL 5.5 based releases |
Usage
ndb_show_tables [-c connection_string]
Specifies the name of the database in which the tables are found.
Specifies the number of times the utility should execute. This is 1 when this option is not specified, but if you do use the option, you must supply an integer argument for it.
Using this option causes the output to be in a format suitable for use with
LOAD DATA INFILE.If specified, this causes temporary tables to be displayed.
Can be used to restrict the output to one type of object, specified by an integer type code as shown here:
1: System table2: User-created table3: Unique hash index
Any other value causes all
NDBdatabase objects to be listed (the default).If specified, this causes unqualified object names to be displayed.
Only user-created MySQL Cluster tables may be accessed from
MySQL; system tables such as SYSTAB_0 are
not visible to mysqld. However, you can
examine the contents of system tables using
NDB API applications such as
ndb_select_all (see
Section 18.4.21, “ndb_select_all — Print Rows from an NDB Table”).
This is a Perl script that can be used to estimate the amount of
space that would be required by a MySQL database if it were
converted to use the NDBCLUSTER
storage engine. Unlike the other utilities discussed in this
section, it does not require access to a MySQL Cluster (in fact,
there is no reason for it to do so). However, it does need to
access the MySQL server on which the database to be tested
resides.
Requirements
A running MySQL server. The server instance does not have to provide support for MySQL Cluster.
A working installation of Perl.
The
DBImodule, which can be obtained from CPAN if it is not already part of your Perl installation. (Many Linux and other operating system distributions provide their own packages for this library.)A MySQL user account having the necessary privileges. If you do not wish to use an existing account, then creating one using
GRANT USAGE ON—wheredb_name.*db_nameis the name of the database to be examined—is sufficient for this purpose.
ndb_size.pl can also be found in the MySQL
sources in storage/ndb/tools.
The following table includes options that are specific to the MySQL Cluster program ndb_size.pl. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_size.pl), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.86 This table describes command-line options for the ndb_size.pl program
| Format | Description | Added or Removed |
|---|---|---|
| The database or databases to examine; accepts a comma-delimited list; the default is ALL (use all databases found on the server) | All MySQL 5.5 based releases |
|
| Specify host and optional port as host[:port] | All MySQL 5.5 based releases |
|
| Specify a socket to connect to | All MySQL 5.5 based releases |
|
| Specify a MySQL user name | All MySQL 5.5 based releases |
|
| Specify a MySQL user password | All MySQL 5.5 based releases |
|
| Set output format (text or HTML) | All MySQL 5.5 based releases |
|
| Skip any tables in a comma-separated list of tables | All MySQL 5.5 based releases |
|
| Skip any databases in a comma-separated list of databases | All MySQL 5.5 based releases |
|
| Saves all queries to the database into the file specified | All MySQL 5.5 based releases |
|
| Loads all queries from the file specified; does not connect to a database | All MySQL 5.5 based releases |
|
| Designates a table to handle unique index size calculations | All MySQL 5.5 based releases |
Usage
perl ndb_size.pl [--database={db_name|ALL}] [--hostname=host[:port]] [--socket=socket] \
[--user=user] [--password=password] \
[--help|-h] [--format={html|text}] \
[--loadqueries=file_name] [--savequeries=file_name]
By default, this utility attempts to analyze all databases on
the server. You can specify a single database using the
--database option; the default behavior can be
made explicit by using ALL for the name of
the database. You can also exclude one or more databases by
using the --excludedbs option with a
comma-separated list of the names of the databases to be
skipped. Similarly, you can cause specific tables to be skipped
by listing their names, separated by commas, following the
optional --excludetables option. A host name
can be specified using --hostname; the default
is localhost. In MySQL Cluster NDB 7.2.6 and
later, you can specify a port in addition to the host using
host:port
format for the value of --hostname. The default
port number is 3306. If necessary, you can also specify a
socket; the default is /var/lib/mysql.sock.
A MySQL user name and password can be specified the
corresponding options shown. It also possible to control the
format of the output using the --format option;
this can take either of the values html or
text, with text being the
default. An example of the text output is shown here:
shell> ndb_size.pl --database=test --socket=/tmp/mysql.sock
ndb_size.pl report for database: 'test' (1 tables)
--------------------------------------------------
Connected to: DBI:mysql:host=localhost;mysql_socket=/tmp/mysql.sock
Including information for versions: 4.1, 5.0, 5.1
test.t1
-------
DataMemory for Columns (* means varsized DataMemory):
Column Name Type Varsized Key 4.1 5.0 5.1
HIDDEN_NDB_PKEY bigint PRI 8 8 8
c2 varchar(50) Y 52 52 4*
c1 int(11) 4 4 4
-- -- --
Fixed Size Columns DM/Row 64 64 12
Varsize Columns DM/Row 0 0 4
DataMemory for Indexes:
Index Name Type 4.1 5.0 5.1
PRIMARY BTREE 16 16 16
-- -- --
Total Index DM/Row 16 16 16
IndexMemory for Indexes:
Index Name 4.1 5.0 5.1
PRIMARY 33 16 16
-- -- --
Indexes IM/Row 33 16 16
Summary (for THIS table):
4.1 5.0 5.1
Fixed Overhead DM/Row 12 12 16
NULL Bytes/Row 4 4 4
DataMemory/Row 96 96 48
(Includes overhead, bitmap and indexes)
Varsize Overhead DM/Row 0 0 8
Varsize NULL Bytes/Row 0 0 4
Avg Varside DM/Row 0 0 16
No. Rows 0 0 0
Rows/32kb DM Page 340 340 680
Fixedsize DataMemory (KB) 0 0 0
Rows/32kb Varsize DM Page 0 0 2040
Varsize DataMemory (KB) 0 0 0
Rows/8kb IM Page 248 512 512
IndexMemory (KB) 0 0 0
Parameter Minimum Requirements
------------------------------
* indicates greater than default
Parameter Default 4.1 5.0 5.1
DataMemory (KB) 81920 0 0 0
NoOfOrderedIndexes 128 1 1 1
NoOfTables 128 1 1 1
IndexMemory (KB) 18432 0 0 0
NoOfUniqueHashIndexes 64 0 0 0
NoOfAttributes 1000 3 3 3
NoOfTriggers 768 5 5 5
For debugging purposes, the Perl arrays containing the queries
run by this script can be read from the file specified using can
be saved to a file using --savequeries; a file
containing such arrays to be read in during script execution can
be specified using --loadqueries. Neither of
these options has a default value.
To produce output in HTML format, use the
--format option and redirect the output to a
file, as shown here:
shell> ndb_size.pl --database=test --socket=/tmp/mysql.sock --format=html > ndb_size.html
(Without the redirection, the output is sent to
stdout.)
The output from this script includes the following information:
Minimum values for the
DataMemory,IndexMemory,MaxNoOfTables,MaxNoOfAttributes,MaxNoOfOrderedIndexes,MaxNoOfUniqueHashIndexes, andMaxNoOfTriggersconfiguration parameters required to accommodate the tables analyzed.Memory requirements for all of the tables, attributes, ordered indexes, and unique hash indexes defined in the database.
The
IndexMemoryandDataMemoryrequired per table and table row.
ndb_waiter repeatedly (each 100 milliseconds)
prints out the status of all cluster data nodes until either the
cluster reaches a given status or the
--timeout limit is exceeded,
then exits. By default, it waits for the cluster to achieve
STARTED status, in which all nodes have
started and connected to the cluster. This can be overridden
using the --no-contact and
--not-started options.
The node states reported by this utility are as follows:
NO_CONTACT: The node cannot be contacted.UNKNOWN: The node can be contacted, but its status is not yet known. Usually, this means that the node has received aSTARTorRESTARTcommand from the management server, but has not yet acted on it.NOT_STARTED: The node has stopped, but remains in contact with the cluster. This is seen when restarting the node using the management client'sRESTARTcommand.STARTING: The node's ndbd process has started, but the node has not yet joined the cluster.STARTED: The node is operational, and has joined the cluster.SHUTTING_DOWN: The node is shutting down.SINGLE USER MODE: This is shown for all cluster data nodes when the cluster is in single user mode.
The following table includes options that are specific to the MySQL Cluster native backup restoration program ndb_waiter. Additional descriptions follow the table. For options common to most MySQL Cluster programs (including ndb_waiter), see Section 18.4.26, “Options Common to MySQL Cluster Programs — Options Common to MySQL Cluster Programs”.
Table 18.87 This table describes command-line options for the ndb_waiter program
| Format | Description | Added or Removed |
|---|---|---|
| Wait for cluster to reach NO CONTACT state | All MySQL 5.5 based releases |
|
| Wait for cluster to reach NOT STARTED state | All MySQL 5.5 based releases |
|
| Wait for cluster to enter single user mode | All MySQL 5.5 based releases |
|
| Wait this many seconds, then exit whether or not cluster has reached desired state; default is 2 minutes (120 seconds) | All MySQL 5.5 based releases |
|
| List of nodes not to be waited for. | All MySQL 5.5 based releases |
|
| List of nodes to be waited for. | All MySQL 5.5 based releases |
Usage
ndb_waiter [-c connection_string]
Additional Options
Instead of waiting for the
STARTEDstate, ndb_waiter continues running until the cluster reachesNO_CONTACTstatus before exiting.Instead of waiting for the
STARTEDstate, ndb_waiter continues running until the cluster reachesNOT_STARTEDstatus before exiting.Time to wait. The program exits if the desired state is not achieved within this number of seconds. The default is 120 seconds (1200 reporting cycles).
The program waits for the cluster to enter single user mode.
When this option is used, ndb_waiter does not wait for the nodes whose IDs are listed. The list is comma-delimited; ranges can be indicated by dashes, as shown here:
shell>
ndb_waiter --nowait-nodes=1,3,7-9ImportantDo not use this option together with the
--wait-nodesoption.When this option is used, ndb_waiter waits only for the nodes whose IDs are listed. The list is comma-delimited; ranges can be indicated by dashes, as shown here:
shell>
ndb_waiter --wait-nodes=2,4-6,10ImportantDo not use this option together with the
--nowait-nodesoption.
Sample Output.
Shown here is the output from ndb_waiter
when run against a 4-node cluster in which two nodes have been
shut down and then started again manually. Duplicate reports
(indicated by “...”) are
omitted.
shell> ./ndb_waiter -c localhost
Connecting to mgmsrv at (localhost)
State node 1 STARTED
State node 2 NO_CONTACT
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 UNKNOWN
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 NO_CONTACT
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 UNKNOWN
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTING
State node 3 STARTED
State node 4 STARTING
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTED
State node 3 STARTED
State node 4 STARTING
Waiting for cluster enter state STARTED
...
State node 1 STARTED
State node 2 STARTED
State node 3 STARTED
State node 4 STARTED
Waiting for cluster enter state STARTED
NDBT_ProgramExit: 0 - OK
If no connection string is specified, then
ndb_waiter tries to connect to a management
on localhost, and reports
Connecting to mgmsrv at (null).
All MySQL Cluster programs accept the options described in this section, with the following exceptions:
Users of earlier MySQL Cluster versions should note that some of
these options have been changed to make them consistent with one
another as well as with mysqld. You can use
the --help option with any MySQL Cluster
program—with the exception of
ndb_print_backup_file,
ndb_print_schema_file, and
ndb_print_sys_file—to view a list of
the options which the program supports.
The options in the following table are common to all MySQL Cluster executables (except those noted previously in this section).
Table 18.88 This table describes command-line options common to all MySQL Cluster programs
| Format | Description | Added or Removed |
|---|---|---|
| Display help message and exit | All MySQL 5.5 based releases |
|
| Directory where character sets are installed | All MySQL 5.5 based releases |
|
| Write core on errors (defaults to TRUE in debug builds) | All MySQL 5.5 based releases |
|
| Enable output from debug calls. Can be used only for versions compiled with debugging enabled | All MySQL 5.5 based releases |
|
|
Set connection string for connecting to ndb_mgmd. Syntax: [nodeid=<id>;][host=]<hostname>[:<port>]. Overrides entries specified in NDB_CONNECTSTRING or my.cnf. | All MySQL 5.5 based releases |
| Set the host (and port, if desired) for connecting to management server | All MySQL 5.5 based releases |
|
| Set node id for this node | All MySQL 5.5 based releases |
|
| Select nodes for transactions in a more optimal way | All MySQL 5.5 based releases |
|
| Output version information and exit | All MySQL 5.5 based releases |
For options specific to individual MySQL Cluster programs, see Section 18.4, “MySQL Cluster Programs”.
See Section 18.3.3.8.1, “MySQL Server Options for MySQL Cluster”, for mysqld options relating to MySQL Cluster.
-
Command-Line Format --help--usagePrints a short list with descriptions of the available command options.
-
Command-Line Format --character-sets-dir=dir_namePermitted Values Type directory nameDefault Tells the program where to find character set information.
--ndb-connectstring=,connection_string--connect-string=,connection_string-cconnection_stringCommand-Line Format --ndb-connectstring=connectstring--connect-string=connectstringPermitted Values Type stringDefault localhost:1186This option takes a MySQL Cluster connection string that specifies the management server for the application to connect to, as shown here:
shell>
ndbd --ndb-connectstring="nodeid=2;host=ndb_mgmd.mysql.com:1186"For more information, see Section 18.3.3.3, “MySQL Cluster Connection Strings”.
-
Command-Line Format --core-filePermitted Values Type booleanDefault FALSEWrite a core file if the program dies. The name and location of the core file are system-dependent. (For MySQL Cluster programs nodes running on Linux, the default location is the program's working directory—for a data node, this is the node's
DataDir.) For some systems, there may be restrictions or limitations; for example, it might be necessary to execute ulimit -c unlimited before starting the server. Consult your system documentation for detailed information.If MySQL Cluster was built using the
--debugoption for configure, then--core-fileis enabled by default. For regular builds,--core-fileis disabled by default. -
Command-Line Format --debug=optionsPermitted Values Type stringDefault d:t:O,/tmp/ndb_restore.traceThis option can be used only for versions compiled with debugging enabled. It is used to enable output from debug calls in the same manner as for the mysqld process.
-
Command-Line Format --ndb-mgmd-host=host[:port]Permitted Values Type stringDefault localhost:1186Can be used to set the host and port number of a single management server for the program to connect to. If the program requires node IDs or references to multiple management servers (or both) in its connection information, use the
--ndb-connectstringoption instead. -
Command-Line Format --ndb-nodeid=#Permitted Values Type numericDefault 0Sets this node's MySQL Cluster node ID. The range of permitted values depends on the node's type (data, management, or API) and the MySQL Cluster software version. See Section 18.1.6.2, “Limits and Differences of MySQL Cluster from Standard MySQL Limits”, for more information.
--ndb-optimized-node-selectionCommand-Line Format --ndb-optimized-node-selectionPermitted Values Type booleanDefault TRUEOptimize selection of nodes for transactions. Enabled by default.
-
Command-Line Format --versionPrints the MySQL Cluster version number of the executable. The version number is relevant because not all versions can be used together, and the MySQL Cluster startup process verifies that the versions of the binaries being used can co-exist in the same cluster. This is also important when performing an online (rolling) software upgrade or downgrade of MySQL Cluster.
See Section 18.5.5, “Performing a Rolling Restart of a MySQL Cluster”), for more information.
- 18.5.1 Summary of MySQL Cluster Start Phases
- 18.5.2 Commands in the MySQL Cluster Management Client
- 18.5.3 Online Backup of MySQL Cluster
- 18.5.4 MySQL Server Usage for MySQL Cluster
- 18.5.5 Performing a Rolling Restart of a MySQL Cluster
- 18.5.6 Event Reports Generated in MySQL Cluster
- 18.5.7 MySQL Cluster Log Messages
- 18.5.8 MySQL Cluster Single User Mode
- 18.5.9 Quick Reference: MySQL Cluster SQL Statements
- 18.5.10 The ndbinfo MySQL Cluster Information Database
- 18.5.11 MySQL Cluster Security Issues
- 18.5.12 MySQL Cluster Disk Data Tables
- 18.5.13 Adding MySQL Cluster Data Nodes Online
- 18.5.14 Distributed MySQL Privileges for MySQL Cluster
- 18.5.15 NDB API Statistics Counters and Variables
Managing a MySQL Cluster involves a number of tasks, the first of which is to configure and start MySQL Cluster. This is covered in Section 18.3, “Configuration of MySQL Cluster”, and Section 18.4, “MySQL Cluster Programs”.
The next few sections cover the management of a running MySQL Cluster.
For information about security issues relating to management and deployment of a MySQL Cluster, see Section 18.5.11, “MySQL Cluster Security Issues”.
There are essentially two methods of actively managing a running
MySQL Cluster. The first of these is through the use of commands
entered into the management client whereby cluster status can be
checked, log levels changed, backups started and stopped, and nodes
stopped and started. The second method involves studying the
contents of the cluster log
ndb_;
this is usually found in the management server's
node_id_cluster.logDataDir directory, but this
location can be overridden using the
LogDestination option.
(Recall that node_id represents the
unique identifier of the node whose activity is being logged.) The
cluster log contains event reports generated by
ndbd. It is also possible to send cluster log
entries to a Unix system log.
Some aspects of the cluster's operation can be also be monitored
from an SQL node using the
SHOW ENGINE NDB
STATUS statement.
More detailed information about MySQL Cluster operations is
available in real time through an SQL interface using the
ndbinfo database. For more
information, see Section 18.5.10, “The ndbinfo MySQL Cluster Information Database”.
NDB statistics counters provide improved monitoring using the
mysql client. These counters, implemented in the
NDB kernel, relate to operations performed by or affecting
Ndb objects, such as starting,
closing, and aborting transactions; primary key and unique key
operations; table, range, and pruned scans; blocked threads waiting
for various operations to complete; and data and events sent and
received by MySQL Cluster. The counters are incremented by the NDB
kernel whenever NDB API calls are made or data is sent to or
received by the data nodes.
mysqld exposes the NDB API statistics counters as
system status variables, which can be identified from the prefix
common to all of their names (Ndb_api_). The
values of these variables can be read in the
mysql client from the output of a
SHOW STATUS statement, or by querying
either the
SESSION_STATUS table
or the GLOBAL_STATUS
table (in the INFORMATION_SCHEMA database). By
comparing the values of the status variables before and after the
execution of an SQL statement that acts on
NDB tables, you can observe the actions
taken on the NDB API level that correspond to this statement, which
can be beneficial for monitoring and performance tuning of MySQL
Cluster.
MySQL Cluster Manager provides an advanced command-line interface that simplifies many otherwise complex MySQL Cluster management tasks, such as starting, stopping, or restarting a MySQL Cluster with a large number of nodes. The MySQL Cluster Manager client also supports commands for getting and setting the values of most node configuration parameters as well as mysqld server options and variables relating to MySQL Cluster. See MySQL™ Cluster Manager 1.3.6 User Manual, for more information.
This section provides a simplified outline of the steps involved
when MySQL Cluster data nodes are started. More complete
information can be found in
MySQL Cluster Start Phases, in the
NDB Internals Guide.
These phases are the same as those reported in the output from the
node_id STATUSstart_phase
column of the ndbinfo.nodes
table.
Start types. There are several different startup types and modes, as shown in the following list:
Initial start. The cluster starts with a clean file system on all data nodes. This occurs either when the cluster started for the very first time, or when all data nodes are restarted using the
--initialoption.NoteDisk Data files are not removed when restarting a node using
--initial.System restart. The cluster starts and reads data stored in the data nodes. This occurs when the cluster has been shut down after having been in use, when it is desired for the cluster to resume operations from the point where it left off.
Node restart. This is the online restart of a cluster node while the cluster itself is running.
Initial node restart. This is the same as a node restart, except that the node is reinitialized and started with a clean file system.
Setup and initialization (phase -1). Prior to startup, each data node (ndbd process) must be initialized. Initialization consists of the following steps:
Obtain a node ID
Fetch configuration data
Allocate ports to be used for inter-node communications
Allocate memory according to settings obtained from the configuration file
When a data node or SQL node first connects to the management node, it reserves a cluster node ID. To make sure that no other node allocates the same node ID, this ID is retained until the node has managed to connect to the cluster and at least one ndbd reports that this node is connected. This retention of the node ID is guarded by the connection between the node in question and ndb_mgmd.
After each data node has been initialized, the cluster startup process can proceed. The stages which the cluster goes through during this process are listed here:
Phase 0. The
NDBFSandNDBCNTRblocks start (see NDB Kernel Blocks). Data node file systems are cleared on those data nodes that were started with--initialoption.Phase 1. In this stage, all remaining
NDBkernel blocks are started. MySQL Cluster connections are set up, inter-block communications are established, and heartbeats are started. In the case of a node restart, API node connections are also checked.NoteWhen one or more nodes hang in Phase 1 while the remaining node or nodes hang in Phase 2, this often indicates network problems. One possible cause of such issues is one or more cluster hosts having multiple network interfaces. Another common source of problems causing this condition is the blocking of TCP/IP ports needed for communications between cluster nodes. In the latter case, this is often due to a misconfigured firewall.
Phase 2. The
NDBCNTRkernel block checks the states of all existing nodes. The master node is chosen, and the cluster schema file is initialized.Phase 3. The
DBLQHandDBTCkernel blocks set up communications between them. The startup type is determined; if this is a restart, theDBDIHblock obtains permission to perform the restart.Phase 4. For an initial start or initial node restart, the redo log files are created. The number of these files is equal to
NoOfFragmentLogFiles.For a system restart:
Read schema or schemas.
Read data from the local checkpoint.
Apply all redo information until the latest restorable global checkpoint has been reached.
For a node restart, find the tail of the redo log.
Phase 5. Most of the database-related portion of a data node start is performed during this phase. For an initial start or system restart, a local checkpoint is executed, followed by a global checkpoint. Periodic checks of memory usage begin during this phase, and any required node takeovers are performed.
Phase 6. In this phase, node groups are defined and set up.
Phase 7. The arbitrator node is selected and begins to function. The next backup ID is set, as is the backup disk write speed. Nodes reaching this start phase are marked as
Started. It is now possible for API nodes (including SQL nodes) to connect to the cluster.Phase 8. If this is a system restart, all indexes are rebuilt (by
DBDIH).Phase 9. The node internal startup variables are reset.
Phase 100 (OBSOLETE). Formerly, it was at this point during a node restart or initial node restart that API nodes could connect to the node and begin to receive events. Currently, this phase is empty.
Phase 101. At this point in a node restart or initial node restart, event delivery is handed over to the node joining the cluster. The newly-joined node takes over responsibility for delivering its primary data to subscribers. This phase is also referred to as
SUMAhandover phase.
After this process is completed for an initial start or system restart, transaction handling is enabled. For a node restart or initial node restart, completion of the startup process means that the node may now act as a transaction coordinator.
In addition to the central configuration file, a cluster may also be controlled through a command-line interface available through the management client ndb_mgm. This is the primary administrative interface to a running cluster.
Commands for the event logs are given in Section 18.5.6, “Event Reports Generated in MySQL Cluster”; commands for creating backups and restoring from them are provided in Section 18.5.3, “Online Backup of MySQL Cluster”.
Using ndb_mgm with MySQL Cluster Manager.
MySQL Cluster Manager handles starting and stopping processes and tracks their
states internally, so it is not necessary to use
ndb_mgm for these tasks for a MySQL Cluster
that is under MySQL Cluster Manager control. it is recommended
not to use the ndb_mgm
command-line client that comes with the MySQL Cluster
distribution to perform operations that involve starting or
stopping nodes. These include but are not limited to the
START, STOP,
RESTART, and SHUTDOWN
commands. For more information, see
MySQL Cluster Manager Process Commands.
The management client has the following basic commands. In the
listing that follows, node_id denotes
either a database node ID or the keyword ALL,
which indicates that the command should be applied to all of the
cluster's data nodes.
Displays information on all available commands.
Displays information on the cluster's status. Possible node status values include
UNKNOWN,NO_CONTACT,NOT_STARTED,STARTING,STARTED,SHUTTING_DOWN, andRESTARTING. The output from this command also indicates when the cluster is in single user mode (statusSINGLE USER MODE).Brings online the data node identified by
node_id(or all data nodes).ALL STARTworks on all data nodes only, and does not affect management nodes.ImportantTo use this command to bring a data node online, the data node must have been started using ndbd
--nostartor ndbd-n.Stops the data or management node identified by
node_id. Note thatALL STOPworks to stop all data nodes only, and does not affect management nodes.A node affected by this command disconnects from the cluster, and its associated ndbd or ndb_mgmd process terminates.
The
-aoption causes the node to be stopped immediately, without waiting for the completion of any pending transactions.Normally,
STOPfails if the result would cause an incomplete cluster. The-foption forces the node to shut down without checking for this. If this option is used and the result is an incomplete cluster, the cluster immediately shuts down.WarningUse of the
-aoption also disables the safety check otherwise performed whenSTOPis invoked to insure that stopping the node does not cause an incomplete cluster. In other words, you should exercise extreme care when using the-aoption with theSTOPcommand, due to the fact that this option makes it possible for the cluster to undergo a forced shutdown because it no longer has a complete copy of all data stored inNDB.node_idRESTART [-n] [-i] [-a] [-f]Restarts the data node identified by
node_id(or all data nodes).Using the
-ioption withRESTARTcauses the data node to perform an initial restart; that is, the node's file system is deleted and recreated. The effect is the same as that obtained from stopping the data node process and then starting it again using ndbd--initialfrom the system shell. Note that backup files and Disk Data files are not removed when this option is used.Using the
-noption causes the data node process to be restarted, but the data node is not actually brought online until the appropriateSTARTcommand is issued. The effect of this option is the same as that obtained from stopping the data node and then starting it again using ndbd--nostartor ndbd-nfrom the system shell.Using the
-acauses all current transactions relying on this node to be aborted. No GCP check is done when the node rejoins the cluster.Normally,
RESTARTfails if taking the node offline would result in an incomplete cluster. The-foption forces the node to restart without checking for this. If this option is used and the result is an incomplete cluster, the entire cluster is restarted.Displays status information for the data node identified by
node_id(or for all data nodes).The output from this command also indicates when the cluster is in single user mode.
Displays a report of type
report-typefor the data node identified bynode_id, or for all data nodes usingALL.Currently, there are three accepted values for
report-type:BackupStatusprovides a status report on a cluster backup in progressMemoryUsagedisplays how much data memory and index memory is being used by each data node as shown in this example:ndb_mgm>
ALL REPORT MEMORYNode 1: Data usage is 5%(177 32K pages of total 3200) Node 1: Index usage is 0%(108 8K pages of total 12832) Node 2: Data usage is 5%(177 32K pages of total 3200) Node 2: Index usage is 0%(108 8K pages of total 12832)This information is also available from the
ndbinfo.memoryusagetable.EventLogreports events from the event log buffers of one or more data nodes.
report-typeis case-insensitive and “fuzzy”; forMemoryUsage, you can useMEMORY(as shown in the prior example),memory, or even simplyMEM(ormem). You can abbreviateBackupStatusin a similar fashion.Prior to MySQL Cluster NDB 7.2.10,
ALL REPORT BackupStatusdid not work correctly with multi-threaded data nodes. (Bug #15908907)ENTER SINGLE USER MODEnode_idEnters single user mode, whereby only the MySQL server identified by the node ID
node_idis permitted to access the database.Currently, it is not possible for data nodes to join a MySQL Cluster while it is running in single user mode. (Bug #20395)
Exits single user mode, enabling all SQL nodes (that is, all running mysqld processes) to access the database.
NoteIt is possible to use
EXIT SINGLE USER MODEeven when not in single user mode, although the command has no effect in this case.Terminates the management client.
This command does not affect any nodes connected to the cluster.
Shuts down all cluster data nodes and management nodes. To exit the management client after this has been done, use
EXITorQUIT.This command does not shut down any SQL nodes or API nodes that are connected to the cluster.
CREATE NODEGROUPnodeid[,nodeid, ...]Creates a new MySQL Cluster node group and causes data nodes to join it.
This command is used after adding new data nodes online to a MySQL Cluster, and causes them to join a new node group and thus to begin participating fully in the cluster. The command takes as its sole parameter a comma-separated list of node IDs—these are the IDs of the nodes just added and started that are to join the new node group. The number of nodes must be the same as the number of nodes in each node group that is already part of the cluster (each MySQL Cluster node group must have the same number of nodes). In other words, if the MySQL Cluster has 2 node groups of 2 data nodes each, then the new node group must also have 2 data nodes.
The node group ID of the new node group created by this command is determined automatically, and always the next highest unused node group ID in the cluster; it is not possible to set it manually.
For more information, see Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”.
Drops the MySQL Cluster node group with the given
nodegroup_id.This command can be used to drop a node group from a MySQL Cluster.
DROP NODEGROUPtakes as its sole argument the node group ID of the node group to be dropped.DROP NODEGROUPacts only to remove the data nodes in the effected node group from that node group. It does not stop data nodes, assign them to a different node group, or remove them from the cluster's configuration. A data node that does not belong to a node group is indicated in the output of the management clientSHOWcommand withno nodegroupin place of the node group ID, like this (indicated using bold text):id=3 @10.100.2.67 (5.5.48-ndb-7.2.24, no nodegroup)Prior to MySQL Cluster NDB 7.0.4, the
SHOWoutput was not updated correctly followingDROP NODEGROUP. (Bug #43413)DROP NODEGROUPworks only when all data nodes in the node group to be dropped are completely empty of any table data and table definitions. Since there is currently no way using ndb_mgm or the mysql client to remove all data from a specific data node or node group, this means that the command succeeds only in the two following cases:After issuing
CREATE NODEGROUPin the ndb_mgm client, but before issuing anyALTER ONLINE TABLE ... REORGANIZE PARTITIONstatements in the mysql client.After dropping all
NDBCLUSTERtables usingDROP TABLE.TRUNCATE TABLEdoes not work for this purpose because this removes only the table data; the data nodes continue to store anNDBCLUSTERtable's definition until aDROP TABLEstatement is issued that causes the table metadata to be dropped.
For more information about
DROP NODEGROUP, see Section 18.5.13, “Adding MySQL Cluster Data Nodes Online”.
The next few sections describe how to prepare for and then to create a MySQL Cluster backup using the functionality for this purpose found in the ndb_mgm management client. To distinguish this type of backup from a backup made using mysqldump, we sometimes refer to it as a “native” MySQL Cluster backup. (For information about the creation of backups with mysqldump, see Section 4.5.4, “mysqldump — A Database Backup Program”.) Restoration of MySQL Cluster backups is done using the ndb_restore utility provided with the MySQL Cluster distribution; for information about ndb_restore and its use in restoring MySQL Cluster backups, see Section 18.4.20, “ndb_restore — Restore a MySQL Cluster Backup”.
A backup is a snapshot of the database at a given time. The backup consists of three main parts:
Metadata. The names and definitions of all database tables
Table records. The data actually stored in the database tables at the time that the backup was made
Transaction log. A sequential record telling how and when data was stored in the database
Each of these parts is saved on all nodes participating in the backup. During backup, each node saves these three parts into three files on disk:
BACKUP-backup_id.node_id.ctlA control file containing control information and metadata. Each node saves the same table definitions (for all tables in the cluster) to its own version of this file.
BACKUP-backup_id-0.node_id.dataA data file containing the table records, which are saved on a per-fragment basis. That is, different nodes save different fragments during the backup. The file saved by each node starts with a header that states the tables to which the records belong. Following the list of records there is a footer containing a checksum for all records.
BACKUP-backup_id.node_id.logA log file containing records of committed transactions. Only transactions on tables stored in the backup are stored in the log. Nodes involved in the backup save different records because different nodes host different database fragments.
In the listing above, backup_id
stands for the backup identifier and
node_id is the unique identifier for
the node creating the file.
Before starting a backup, make sure that the cluster is properly configured for performing one. (See Section 18.5.3.3, “Configuration for MySQL Cluster Backups”.)
The START BACKUP command is used to create a
backup:
START BACKUP [backup_id] [wait_option] [snapshot_option]wait_option: WAIT {STARTED | COMPLETED} | NOWAITsnapshot_option: SNAPSHOTSTART | SNAPSHOTEND
Successive backups are automatically identified sequentially, so
the backup_id, an integer greater
than or equal to 1, is optional; if it is omitted, the next
available value is used. If an existing
backup_id value is used, the backup
fails with the error Backup failed: file already
exists. If used, the
backup_id must follow START
BACKUP immediately, before any other options are used.
The wait_option can be used to
determine when control is returned to the management client
after a START BACKUP command is issued, as
shown in the following list:
If
NOWAITis specified, the management client displays a prompt immediately, as seen here:ndb_mgm>
START BACKUP NOWAITndb_mgm>In this case, the management client can be used even while it prints progress information from the backup process.
With
WAIT STARTEDthe management client waits until the backup has started before returning control to the user, as shown here:ndb_mgm>
START BACKUP WAIT STARTEDWaiting for started, this may take several minutes Node 2: Backup 3 started from node 1 ndb_mgm>WAIT COMPLETEDcauses the management client to wait until the backup process is complete before returning control to the user.
WAIT COMPLETED is the default.
A snapshot_option can be used to
determine whether the backup matches the state of the cluster
when START BACKUP was issued, or when it was
completed. SNAPSHOTSTART causes the backup to
match the state of the cluster when the backup began;
SNAPSHOTEND causes the backup to reflect the
state of the cluster when the backup was finished.
SNAPSHOTEND is the default, and matches the
behavior found in previous MySQL Cluster releases.
If you use the SNAPSHOTSTART option with
START BACKUP, and the
CompressedBackup
parameter is enabled, only the data and control files are
compressed—the log file is not compressed.
If both a wait_option and a
snapshot_option are used, they may be
specified in either order. For example, all of the following
commands are valid, assuming that there is no existing backup
having 4 as its ID:
START BACKUP WAIT STARTED SNAPSHOTSTART START BACKUP SNAPSHOTSTART WAIT STARTED START BACKUP 4 WAIT COMPLETED SNAPSHOTSTART START BACKUP SNAPSHOTEND WAIT COMPLETED START BACKUP 4 NOWAIT SNAPSHOTSTART
The procedure for creating a backup consists of the following steps:
Start the management client (ndb_mgm), if it not running already.
Execute the
START BACKUPcommand. This produces several lines of output indicating the progress of the backup, as shown here:ndb_mgm>
START BACKUPWaiting for completed, this may take several minutes Node 2: Backup 1 started from node 1 Node 2: Backup 1 started from node 1 completed StartGCP: 177 StopGCP: 180 #Records: 7362 #LogRecords: 0 Data: 453648 bytes Log: 0 bytes ndb_mgm>When the backup has started the management client displays this message:
Backup
backup_idstarted from nodenode_idbackup_idis the unique identifier for this particular backup. This identifier is saved in the cluster log, if it has not been configured otherwise.node_idis the identifier of the management server that is coordinating the backup with the data nodes. At this point in the backup process the cluster has received and processed the backup request. It does not mean that the backup has finished. An example of this statement is shown here:Node 2: Backup 1 started from node 1
The management client indicates with a message like this one that the backup has started:
Backup
backup_idstarted from nodenode_idcompletedAs is the case for the notification that the backup has started,
backup_idis the unique identifier for this particular backup, andnode_idis the node ID of the management server that is coordinating the backup with the data nodes. This output is accompanied by additional information including relevant global checkpoints, the number of records backed up, and the size of the data, as shown here:Node 2: Backup 1 started from node 1 completed StartGCP: 177 StopGCP: 180 #Records: 7362 #LogRecords: 0 Data: 453648 bytes Log: 0 bytes
It is also possible to perform a backup from the system shell by
invoking ndb_mgm with the -e
or --execute option, as shown in
this example:
shell> ndb_mgm -e "START BACKUP 6 WAIT COMPLETED SNAPSHOTSTART"
When using START BACKUP in this way, you must
specify the backup ID.
Cluster backups are created by default in the
BACKUP subdirectory of the
DataDir on each data
node. This can be overridden for one or more data nodes
individually, or for all cluster data nodes in the
config.ini file using the
BackupDataDir
configuration parameter. The backup files created for a backup
with a given backup_id are stored in
a subdirectory named
BACKUP-
in the backup directory.
backup_id
To abort a backup that is already in progress:
Start the management client.
Execute this command:
ndb_mgm>
ABORT BACKUPbackup_idThe number
backup_idis the identifier of the backup that was included in the response of the management client when the backup was started (in the messageBackup).backup_idstarted from nodemanagement_node_idThe management client will acknowledge the abort request with
Abort of backup.backup_idorderedNoteAt this point, the management client has not yet received a response from the cluster data nodes to this request, and the backup has not yet actually been aborted.
After the backup has been aborted, the management client will report this fact in a manner similar to what is shown here:
Node 1: Backup 3 started from 5 has been aborted. Error: 1321 - Backup aborted by user request: Permanent error: User defined error Node 3: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error Node 2: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error Node 4: Backup 3 started from 5 has been aborted. Error: 1323 - 1323: Permanent error: Internal error
In this example, we have shown sample output for a cluster with 4 data nodes, where the sequence number of the backup to be aborted is
3, and the management node to which the cluster management client is connected has the node ID5. The first node to complete its part in aborting the backup reports that the reason for the abort was due to a request by the user. (The remaining nodes report that the backup was aborted due to an unspecified internal error.)NoteThere is no guarantee that the cluster nodes respond to an
ABORT BACKUPcommand in any particular order.The
Backupmessages mean that the backup has been terminated and that all files relating to this backup have been removed from the cluster file system.backup_idstarted from nodemanagement_node_idhas been aborted
It is also possible to abort a backup in progress from a system shell using this command:
shell> ndb_mgm -e "ABORT BACKUP backup_id"
If there is no backup having the ID
backup_id running when an
ABORT BACKUP is issued, the management
client makes no response, nor is it indicated in the cluster
log that an invalid abort command was sent.
Five configuration parameters are essential for backup:
The amount of memory used to buffer data before it is written to disk.
The amount of memory used to buffer log records before these are written to disk.
The total memory allocated in a data node for backups. This should be the sum of the memory allocated for the backup data buffer and the backup log buffer.
The default size of blocks written to disk. This applies for both the backup data buffer and the backup log buffer.
The maximum size of blocks written to disk. This applies for both the backup data buffer and the backup log buffer.
More detailed information about these parameters can be found in Backup Parameters.
If an error code is returned when issuing a backup request, the most likely cause is insufficient memory or disk space. You should check that there is enough memory allocated for the backup.
If you have set
BackupDataBufferSize
and
BackupLogBufferSize
and their sum is greater than 4MB, then you must also set
BackupMemory as well.
You should also make sure that there is sufficient space on the hard drive partition of the backup target.
NDB does not support repeatable
reads, which can cause problems with the restoration process.
Although the backup process is “hot”, restoring a
MySQL Cluster from backup is not a 100% “hot”
process. This is due to the fact that, for the duration of the
restore process, running transactions get nonrepeatable reads
from the restored data. This means that the state of the data is
inconsistent while the restore is in progress.
mysqld is the traditional MySQL server process.
To be used with MySQL Cluster, mysqld needs to
be built with support for the
NDBCLUSTER storage engine, as it is
in the precompiled binaries available from
http://dev.mysql.com/downloads/. If you build MySQL from
source, you must invoke configure with one of
the options to enable NDBCLUSTER
storage engine support:
(--with-ndbcluster also works to enable
NDBCLUSTER support, but is deprecated
and so produces a configure warning as of MySQL
5.1.9.)
For information about other MySQL server options and variables relevant to MySQL Cluster in addition to those discussed in this section, see Section 18.3.3.8, “MySQL Server Options and Variables for MySQL Cluster”.
If the mysqld binary has been built with
Cluster support, the NDBCLUSTER
storage engine is still disabled by default. You can use either of
two possible options to enable this engine:
Use
--ndbclusteras a startup option on the command line when starting mysqld.Insert a line containing
ndbclusterin the[mysqld]section of yourmy.cnffile.
An easy way to verify that your server is running with the
NDBCLUSTER storage engine enabled is
to issue the SHOW ENGINES statement
in the MySQL Monitor (mysql). You should see
the value YES as the Support
value in the row for NDBCLUSTER. If
you see NO in this row or if there is no such
row displayed in the output, you are not running an
NDB-enabled version of MySQL. If you
see DISABLED in this row, you need to enable it
in either one of the two ways just described.
To read cluster configuration data, the MySQL server requires at a minimum three pieces of information:
The MySQL server's own cluster node ID
The host name or IP address for the management server (MGM node)
The number of the TCP/IP port on which it can connect to the management server
Node IDs can be allocated dynamically, so it is not strictly necessary to specify them explicitly.
The mysqld parameter
ndb-connectstring is used to specify the
connection string either on the command line when starting
mysqld or in my.cnf. The
connection string contains the host name or IP address where the
management server can be found, as well as the TCP/IP port it
uses.
In the following example, ndb_mgmd.mysql.com is
the host where the management server resides, and the management
server listens for cluster messages on port 1186:
shell> mysqld --ndbcluster --ndb-connectstring=ndb_mgmd.mysql.com:1186
See Section 18.3.3.3, “MySQL Cluster Connection Strings”, for more information on connection strings.
Given this information, the MySQL server will be a full participant in the cluster. (We often refer to a mysqld process running in this manner as an SQL node.) It will be fully aware of all cluster data nodes as well as their status, and will establish connections to all data nodes. In this case, it is able to use any data node as a transaction coordinator and to read and update node data.
You can see in the mysql client whether a MySQL
server is connected to the cluster using SHOW
PROCESSLIST. If the MySQL server is connected to the
cluster, and you have the PROCESS
privilege, then the first row of the output is as shown here:
mysql> SHOW PROCESSLIST \G
*************************** 1. row ***************************
Id: 1
User: system user
Host:
db:
Command: Daemon
Time: 1
State: Waiting for event from ndbcluster
Info: NULL
To participate in a MySQL Cluster, the mysqld
process must be started with both the
options --ndbcluster and
--ndb-connectstring (or their
equivalents in my.cnf). If
mysqld is started with only the
--ndbcluster option, or if it is
unable to contact the cluster, it is not possible to work with
NDB tables, nor is it
possible to create any new tables regardless of storage
engine. The latter restriction is a safety measure
intended to prevent the creation of tables having the same names
as NDB tables while the SQL node is
not connected to the cluster. If you wish to create tables using
a different storage engine while the mysqld
process is not participating in a MySQL Cluster, you must
restart the server without the
--ndbcluster option.
This section discusses how to perform a rolling restart of a MySQL Cluster installation, so called because it involves stopping and starting (or restarting) each node in turn, so that the cluster itself remains operational. This is often done as part of a rolling upgrade or rolling downgrade, where high availability of the cluster is mandatory and no downtime of the cluster as a whole is permissible. Where we refer to upgrades, the information provided here also generally applies to downgrades as well.
There are a number of reasons why a rolling restart might be desirable. These are described in the next few paragraphs.
Configuration change. To make a change in the cluster's configuration, such as adding an SQL node to the cluster, or setting a configuration parameter to a new value.
MySQL Cluster software upgrade or downgrade. To upgrade the cluster to a newer version of the MySQL Cluster software (or to downgrade it to an older version). This is usually referred to as a “rolling upgrade” (or “rolling downgrade”, when reverting to an older version of MySQL Cluster).
Change on node host. To make changes in the hardware or operating system on which one or more MySQL Cluster node processes are running.
System reset (cluster reset). To reset the cluster because it has reached an undesirable state. In such cases it is often desirable to reload the data and metadata of one or more data nodes. This can be done in any of three ways:
Start each data node process (ndbd or possibly ndbmtd) with the
--initialoption, which forces the data node to clear its file system and to reload all MySQL Cluster data and metadata from the other data nodes.Create a backup using the ndb_mgm client
BACKUPcommand prior to performing the restart. Following the upgrade, restore the node or nodes using ndb_restore.See Section 18.5.3, “Online Backup of MySQL Cluster”, and Section 18.4.20, “ndb_restore — Restore a MySQL Cluster Backup”, for more information.
Use mysqldump to create a backup prior to the upgrade; afterward, restore the dump using
LOAD DATA INFILE.
Resource Recovery.
To free memory previously allocated to a table by successive
INSERT and
DELETE operations, for re-use by
other MySQL Cluster tables.
The process for performing a rolling restart may be generalized as follows:
Stop all cluster management nodes (ndb_mgmd processes), reconfigure them, then restart them. (See Rolling restarts with multiple management servers.)
Stop, reconfigure, then restart each cluster data node (ndbd process) in turn.
Stop, reconfigure, then restart each cluster SQL node (mysqld process) in turn.
The specifics for implementing a given rolling upgrade depend upon the changes being made. A more detailed view of the process is presented here:
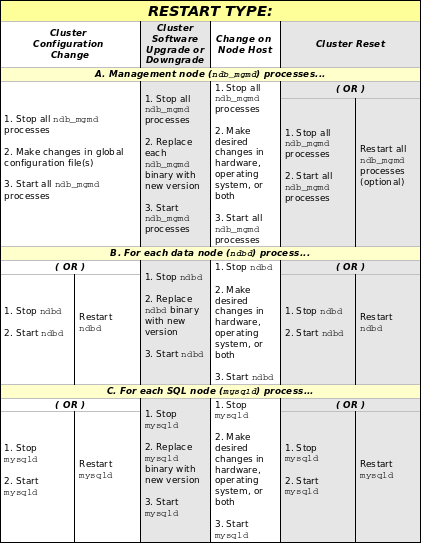
In the previous diagram, the Stop
and Start steps indicate that the
process must be stopped completely using a shell command (such as
kill on most Unix systems) or the management
client STOP command, then started again from a
system shell by invoking the ndbd or
ndb_mgmd executable as appropriate. On Windows,
you can also use the system NET START and
NET STOP commands or the Windows Service
Manager to start and stop nodes which have been installed as
Windows services (see
Section 18.2.2.4, “Installing MySQL Cluster Processes as Windows Services”).
Restart indicates that the
process may be restarted using the ndb_mgm
management client RESTART command (see
Section 18.5.2, “Commands in the MySQL Cluster Management Client”).
MySQL Cluster supports a flexible order for upgrading nodes. When upgrading a MySQL Cluster, you may upgrade API nodes (including SQL nodes) before upgrading the management nodes, data nodes, or both. In other words, you are permitted to upgrade the API and SQL nodes in any order. This is subject to the following provisions:
This functionality is intended for use as part of an online upgrade only. A mix of node binaries from different MySQL Cluster releases is neither intended nor supported for continuous, long-term use in a production setting.
All management nodes must be upgraded before any data nodes are upgraded. This remains true regardless of the order in which you upgrade the cluster's API and SQL nodes.
Features specific to the “new” version must not be used until all management nodes and data nodes have been upgraded.
This also applies to any MySQL Server version change that may apply, in addition to the NDB engine version change, so do not forget to take this into account when planning the upgrade. (This is true for online upgrades of MySQL Cluster in general.)
See also Bug #48528 and Bug #49163.
Rolling restarts with multiple management servers. When performing a rolling restart of a MySQL Cluster with multiple management nodes, you should keep in mind that ndb_mgmd checks to see if any other management node is running, and, if so, tries to use that node's configuration data. To keep this from occurring, and to force ndb_mgmd to reread its configuration file, perform the following steps:
Stop all MySQL Cluster ndb_mgmd processes.
Update all
config.inifiles.Start a single ndb_mgmd with
--reload,--initial, or both options as desired.If you started the first ndb_mgmd with the
--initialoption, you must also start any remaining ndb_mgmd processes using--initial.Regardless of any other options used when starting the first ndb_mgmd, you should not start any remaining ndb_mgmd processes after the first one using
--reload.Complete the rolling restarts of the data nodes and API nodes as normal.
When performing a rolling restart to update the cluster's
configuration, you can use the
config_generation column of the
ndbinfo.nodes table to keep
track of which data nodes have been successfully restarted with
the new configuration. See
Section 18.5.10.13, “The ndbinfo nodes Table”.
In this section, we discuss the types of event logs provided by MySQL Cluster, and the types of events that are logged.
MySQL Cluster provides two types of event log:
The cluster log, which includes events generated by all cluster nodes. The cluster log is the log recommended for most uses because it provides logging information for an entire cluster in a single location.
By default, the cluster log is saved to a file named
ndb_, (wherenode_id_cluster.lognode_idis the node ID of the management server) in the management server'sDataDir.Cluster logging information can also be sent to
stdoutor asyslogfacility in addition to or instead of being saved to a file, as determined by the values set for theDataDirandLogDestinationconfiguration parameters. See Section 18.3.3.5, “Defining a MySQL Cluster Management Server”, for more information about these parameters.Node logs are local to each node.
Output generated by node event logging is written to the file
ndb_(wherenode_id_out.lognode_idis the node's node ID) in the node'sDataDir. Node event logs are generated for both management nodes and data nodes.Node logs are intended to be used only during application development, or for debugging application code.
Both types of event logs can be set to log different subsets of events.
Each reportable event can be distinguished according to three different criteria:
Category: This can be any one of the following values:
STARTUP,SHUTDOWN,STATISTICS,CHECKPOINT,NODERESTART,CONNECTION,ERROR, orINFO.Priority: This is represented by one of the numbers from 0 to 15 inclusive, where 0 indicates “most important” and 15 “least important.”
Severity Level: This can be any one of the following values:
ALERT,CRITICAL,ERROR,WARNING,INFO, orDEBUG.
Both the cluster log and the node log can be filtered on these properties.
The format used in the cluster log is as shown here:
2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Data usage is 2%(60 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Index usage is 1%(24 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 1: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Data usage is 2%(76 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Index usage is 1%(24 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 2: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Data usage is 2%(58 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Index usage is 1%(25 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 3: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Data usage is 2%(74 32K pages of total 2560) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Index usage is 1%(25 8K pages of total 2336) 2007-01-26 19:35:55 [MgmSrvr] INFO -- Node 4: Resource 0 min: 0 max: 639 curr: 0 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 4: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 1: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 1: Node 9: API 5.5.48-ndb-7.2.24 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 2: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 2: Node 9: API 5.5.48-ndb-7.2.24 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 3: Node 9 Connected 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 3: Node 9: API 5.5.48-ndb-7.2.24 2007-01-26 19:39:42 [MgmSrvr] INFO -- Node 4: Node 9: API 5.5.48-ndb-7.2.24 2007-01-26 19:59:22 [MgmSrvr] ALERT -- Node 2: Node 7 Disconnected 2007-01-26 19:59:22 [MgmSrvr] ALERT -- Node 2: Node 7 Disconnected
Each line in the cluster log contains the following information:
A timestamp in
YYYY-MM-DDHH:MM:SSThe type of node which is performing the logging. In the cluster log, this is always
[MgmSrvr].The severity of the event.
The ID of the node reporting the event.
A description of the event. The most common types of events to appear in the log are connections and disconnections between different nodes in the cluster, and when checkpoints occur. In some cases, the description may contain status information.
ndb_mgm supports a number of management
commands related to the cluster log. In the listing that
follows, node_id denotes either a
database node ID or the keyword ALL, which
indicates that the command should be applied to all of the
cluster's data nodes.
CLUSTERLOG ONTurns the cluster log on.
CLUSTERLOG OFFTurns the cluster log off.
CLUSTERLOG INFOProvides information about cluster log settings.
node_idCLUSTERLOGcategory=thresholdLogs
categoryevents with priority less than or equal tothresholdin the cluster log.CLUSTERLOG FILTERseverity_levelToggles cluster logging of events of the specified
severity_level.
The following table describes the default setting (for all data nodes) of the cluster log category threshold. If an event has a priority with a value lower than or equal to the priority threshold, it is reported in the cluster log.
Note that events are reported per data node, and that the threshold can be set to different values on different nodes.
| Category | Default threshold (All data nodes) |
|---|---|
STARTUP | 7 |
SHUTDOWN | 7 |
STATISTICS | 7 |
CHECKPOINT | 7 |
NODERESTART | 7 |
CONNECTION | 7 |
ERROR | 15 |
INFO | 7 |
The STATISTICS category can provide a great
deal of useful data. See
Section 18.5.6.3, “Using CLUSTERLOG STATISTICS in the MySQL Cluster Management Client”, for more
information.
Thresholds are used to filter events within each category. For
example, a STARTUP event with a priority of 3
is not logged unless the threshold for
STARTUP is set to 3 or higher. Only events
with priority 3 or lower are sent if the threshold is 3.
The following table shows the event severity levels.
These correspond to Unix syslog levels,
except for LOG_EMERG and
LOG_NOTICE, which are not used or mapped.
Severity Level Value | Severity | Description |
|---|---|---|
1 |
| A condition that should be corrected immediately, such as a corrupted system database |
2 |
| Critical conditions, such as device errors or insufficient resources |
3 |
| Conditions that should be corrected, such as configuration errors |
4 | WARNING | Conditions that are not errors, but that might require special handling |
5 | INFO | Informational messages |
6 | DEBUG | Debugging messages used for NDBCLUSTER
development |
Event severity levels can be turned on or off (using
CLUSTERLOG FILTER—see above). If a
severity level is turned on, then all events with a priority
less than or equal to the category thresholds are logged. If the
severity level is turned off then no events belonging to that
severity level are logged.
Cluster log levels are set on a per
ndb_mgmd, per subscriber basis. This means
that, in a MySQL Cluster with multiple management servers,
using a CLUSTERLOG command in an instance
of ndb_mgm connected to one management
server affects only logs generated by that management server
but not by any of the others. This also means that, should one
of the management servers be restarted, only logs generated by
that management server are affected by the resetting of log
levels caused by the restart.
An event report reported in the event logs has the following format:
datetime[string]severity--message
For example:
09:19:30 2005-07-24 [NDB] INFO -- Node 4 Start phase 4 completed
This section discusses all reportable events, ordered by category and severity level within each category.
In the event descriptions, GCP and LCP mean “Global Checkpoint” and “Local Checkpoint”, respectively.
CONNECTION Events
These events are associated with connections between Cluster nodes.
| Event | Priority | Severity Level | Description |
|---|---|---|---|
Connected | 8 | INFO | Data nodes connected |
Disconnected | 8 | ALERT | Data nodes disconnected |
CommunicationClosed | 8 | INFO | SQL node or data node connection closed |
CommunicationOpened | 8 | INFO | SQL node or data node connection open |
ConnectedApiVersion | 8 | INFO | Connection using API version |
CHECKPOINT Events
The logging messages shown here are associated with checkpoints.
| Event | Priority | Severity Level | Description |
|---|---|---|---|
GlobalCheckpointStarted | 9 | INFO | Start of GCP: REDO log is written to disk |
GlobalCheckpointCompleted | 10 | INFO | GCP finished |
LocalCheckpointStarted | 7 | INFO | Start of LCP: data written to disk |
LocalCheckpointCompleted | 7 | INFO | LCP completed normally |
LCPStoppedInCalcKeepGci | 0 | ALERT | LCP stopped |
LCPFragmentCompleted | 11 | INFO | LCP on a fragment has been completed |
UndoLogBlocked | 7 | INFO | UNDO logging blocked; buffer near overflow |
RedoStatus | 7 | INFO | Redo status |
STARTUP Events
The following events are generated in response to the startup of a node or of the cluster and of its success or failure. They also provide information relating to the progress of the startup process, including information concerning logging activities.
| Event | Priority | Severity Level | Description |
|---|---|---|---|
NDBStartStarted | 1 | INFO | Data node start phases initiated (all nodes starting) |
NDBStartCompleted | 1 | INFO | Start phases completed, all data nodes |
STTORRYRecieved | 15 | INFO | Blocks received after completion of restart |
StartPhaseCompleted | 4 | INFO | Data node start phase X completed |
CM_REGCONF | 3 | INFO | Node has been successfully included into the cluster; shows the node, managing node, and dynamic ID |
CM_REGREF | 8 | INFO | Node has been refused for inclusion in the cluster; cannot be included in cluster due to misconfiguration, inability to establish communication, or other problem |
FIND_NEIGHBOURS | 8 | INFO | Shows neighboring data nodes |
NDBStopStarted | 1 | INFO | Data node shutdown initiated |
NDBStopCompleted | 1 | INFO | Data node shutdown complete |
NDBStopForced | 1 | ALERT | Forced shutdown of data node |
NDBStopAborted | 1 | INFO | Unable to shut down data node normally |
StartREDOLog | 4 | INFO | New redo log started; GCI keep X, newest
restorable GCI Y |
StartLog | 10 | INFO | New log started; log part X, start MB
Y, stop MB
Z |
UNDORecordsExecuted | 15 | INFO | Undo records executed |
StartReport | 4 | INFO | Report started |
LogFileInitStatus | 7 | INFO | Log file initialization status |
LogFileInitCompStatus | 7 | INFO | Log file completion status |
StartReadLCP | 10 | INFO | Start read for local checkpoint |
ReadLCPComplete | 10 | INFO | Read for local checkpoint completed |
RunRedo | 8 | INFO | Running the redo log |
RebuildIndex | 10 | INFO | Rebuilding indexes |
NODERESTART Events
The following events are generated when restarting a node and relate to the success or failure of the node restart process.
| Event | Priority | Severity Level | Description |
|---|---|---|---|
NR_CopyDict | 7 | INFO | Completed copying of dictionary information |
NR_CopyDistr | 7 | INFO | Completed copying distribution information |
NR_CopyFragsStarted | 7 | INFO | Starting to copy fragments |
NR_CopyFragDone | 10 | INFO | Completed copying a fragment |
NR_CopyFragsCompleted | 7 | INFO | Completed copying all fragments |
NodeFailCompleted | 8 | ALERT | Node failure phase completed |
NODE_FAILREP | 8 | ALERT | Reports that a node has failed |
ArbitState | 6 | INFO | Report whether an arbitrator is found or not; there are seven different
possible outcomes when seeking an arbitrator, listed
here:
|
ArbitResult | 2 | ALERT | Report arbitrator results; there are eight different possible results
for arbitration attempts, listed here:
|
GCP_TakeoverStarted | 7 | INFO | GCP takeover started |
GCP_TakeoverCompleted | 7 | INFO | GCP takeover complete |
LCP_TakeoverStarted | 7 | INFO | LCP takeover started |
LCP_TakeoverCompleted | 7 | INFO | LCP takeover complete (state = X) |
ConnectCheckStarted | 6 | INFO | Connection check started |
ConnectCheckCompleted | 6 | INFO | Connection check completed |
NodeFailRejected | 6 | ALERT | Node failure phase failed |
STATISTICS Events
The following events are of a statistical nature. They provide information such as numbers of transactions and other operations, amount of data sent or received by individual nodes, and memory usage.
| Event | Priority | Severity Level | Description |
|---|---|---|---|
TransReportCounters | 8 | INFO | Report transaction statistics, including numbers of transactions, commits, reads, simple reads, writes, concurrent operations, attribute information, and aborts |
OperationReportCounters | 8 | INFO | Number of operations |
TableCreated | 7 | INFO | Report number of tables created |
JobStatistic | 9 | INFO | Mean internal job scheduling statistics |
ThreadConfigLoop | 9 | INFO | Number of thread configuration loops |
SendBytesStatistic | 9 | INFO | Mean number of bytes sent to node X |
ReceiveBytesStatistic | 9 | INFO | Mean number of bytes received from node X |
MemoryUsage | 5 | INFO | Data and index memory usage (80%, 90%, and 100%) |
MTSignalStatistics | 9 | INFO | Multi-threaded signals |
SCHEMA Events
These events relate to MySQL Cluster schema operations.
| Event | Priority | Severity | Description |
|---|---|---|---|
CreateSchemaObject | 8 | INFO | Schema objected created |
AlterSchemaObject | 8 | INFO | Schema object updated |
DropSchemaObject | 8 | INFO | Schema object dropped |
ERROR Events
These events relate to Cluster errors and warnings. The presence of one or more of these generally indicates that a major malfunction or failure has occurred.
| Event | Priority | Severity | Description |
|---|---|---|---|
TransporterError | 2 | ERROR | Transporter error |
TransporterWarning | 8 | WARNING | Transporter warning |
MissedHeartbeat | 8 | WARNING | Node X missed heartbeat number
Y |
DeadDueToHeartbeat | 8 | ALERT | Node X declared “dead” due to
missed heartbeat |
WarningEvent | 2 | WARNING | General warning event |
SubscriptionStatus | 4 | WARNING | Change in subscription status |
INFO Events
These events provide general information about the state of the cluster and activities associated with Cluster maintenance, such as logging and heartbeat transmission.
| Event | Priority | Severity | Description |
|---|---|---|---|
SentHeartbeat | 12 | INFO | Sent heartbeat |
CreateLogBytes | 11 | INFO | Create log: Log part, log file, size in MB |
InfoEvent | 2 | INFO | General informational event |
EventBufferStatus | 7 | INFO | Event buffer status |
SentHeartbeat events are available only if
MySQL Cluster was compiled with VM_TRACE
enabled.
SINGLEUSER Events
These events are associated with entering and exiting single user mode.
| Event | Priority | Severity | Description |
|---|---|---|---|
SingleUser | 7 | INFO | Entering or exiting single user mode |
BACKUP Events
These events provide information about backups being created or restored.
| Event | Priority | Severity | Description |
|---|---|---|---|
BackupStarted | 7 | INFO | Backup started |
BackupStatus | 7 | INFO | Backup status |
BackupCompleted | 7 | INFO | Backup completed |
BackupFailedToStart | 7 | ALERT | Backup failed to start |
BackupAborted | 7 | ALERT | Backup aborted by user |
RestoreStarted | 7 | INFO | Started restoring from backup |
RestoreMetaData | 7 | INFO | Restoring metadata |
RestoreData | 7 | INFO | Restoring data |
RestoreLog | 7 | INFO | Restoring log files |
RestoreCompleted | 7 | INFO | Completed restoring from backup |
SavedEvent | 7 | INFO | Event saved |
The NDB management client's
CLUSTERLOG STATISTICS command can provide a
number of useful statistics in its output. Counters providing
information about the state of the cluster are updated at
5-second reporting intervals by the transaction coordinator (TC)
and the local query handler (LQH), and written to the cluster
log.
Transaction coordinator statistics. Each transaction has one transaction coordinator, which is chosen by one of the following methods:
In a round-robin fashion
By communication proximity
(Beginning with MySQL Cluster NDB 6.3.4:) By supplying a data placement hint when the transaction is started
You can determine which TC selection method is used for
transactions started from a given SQL node using the
ndb_optimized_node_selection
system variable.
All operations within the same transaction use the same transaction coordinator, which reports the following statistics:
Trans count. This is the number transactions started in the last interval using this TC as the transaction coordinator. Any of these transactions may have committed, have been aborted, or remain uncommitted at the end of the reporting interval.
NoteTransactions do not migrate between TCs.
Commit count. This is the number of transactions using this TC as the transaction coordinator that were committed in the last reporting interval. Because some transactions committed in this reporting interval may have started in a previous reporting interval, it is possible for
Commit countto be greater thanTrans count.Read count. This is the number of primary key read operations using this TC as the transaction coordinator that were started in the last reporting interval, including simple reads. This count also includes reads performed as part of unique index operations. A unique index read operation generates 2 primary key read operations—1 for the hidden unique index table, and 1 for the table on which the read takes place.
Simple read count. This is the number of simple read operations using this TC as the transaction coordinator that were started in the last reporting interval.
Write count. This is the number of primary key write operations using this TC as the transaction coordinator that were started in the last reporting interval. This includes all inserts, updates, writes and deletes, as well as writes performed as part of unique index operations.
NoteA unique index update operation can generate multiple PK read and write operations on the index table and on the base table.
AttrInfoCount. This is the number of 32-bit data words received in the last reporting interval for primary key operations using this TC as the transaction coordinator. For reads, this is proportional to the number of columns requested. For inserts and updates, this is proportional to the number of columns written, and the size of their data. For delete operations, this is usually zero.
Unique index operations generate multiple PK operations and so increase this count. However, data words sent to describe the PK operation itself, and the key information sent, are not counted here. Attribute information sent to describe columns to read for scans, or to describe ScanFilters, is also not counted in
AttrInfoCount.Concurrent Operations. This is the number of primary key or scan operations using this TC as the transaction coordinator that were started during the last reporting interval but that were not completed. Operations increment this counter when they are started and decrement it when they are completed; this occurs after the transaction commits. Dirty reads and writes—as well as failed operations—decrement this counter.
The maximum value that
Concurrent Operationscan have is the maximum number of operations that a TC block can support; currently, this is(2 * MaxNoOfConcurrentOperations) + 16 + MaxNoOfConcurrentTransactions. (For more information about these configuration parameters, see the Transaction Parameters section of Section 18.3.3.6, “Defining MySQL Cluster Data Nodes”.)Abort count. This is the number of transactions using this TC as the transaction coordinator that were aborted during the last reporting interval. Because some transactions that were aborted in the last reporting interval may have started in a previous reporting interval,
Abort countcan sometimes be greater thanTrans count.Scans. This is the number of table scans using this TC as the transaction coordinator that were started during the last reporting interval. This does not include range scans (that is, ordered index scans).
Range scans. This is the number of ordered index scans using this TC as the transaction coordinator that were started in the last reporting interval.
Local query handler statistics (Operations). There is 1 cluster event per local query handler block (that is, 1 per data node process). Operations are recorded in the LQH where the data they are operating on resides.
A single transaction may operate on data stored in multiple LQH blocks.
The Operations statistic provides the number
of local operations performed by this LQH block in the last
reporting interval, and includes all types of read and write
operations (insert, update, write, and delete operations). This
also includes operations used to replicate writes. For example,
in a 2-replica cluster, the write to the primary replica is
recorded in the primary LQH, and the write to the backup will be
recorded in the backup LQH. Unique key operations may result in
multiple local operations; however, this does
not include local operations generated as a
result of a table scan or ordered index scan, which are not
counted.
Process scheduler statistics. In addition to the statistics reported by the transaction coordinator and local query handler, each ndbd process has a scheduler which also provides useful metrics relating to the performance of a MySQL Cluster. This scheduler runs in an infinite loop; during each loop the scheduler performs the following tasks:
Read any incoming messages from sockets into a job buffer.
Check whether there are any timed messages to be executed; if so, put these into the job buffer as well.
Execute (in a loop) any messages in the job buffer.
Send any distributed messages that were generated by executing the messages in the job buffer.
Wait for any new incoming messages.
Process scheduler statistics include the following:
Mean Loop Counter. This is the number of loops executed in the third step from the preceding list. This statistic increases in size as the utilization of the TCP/IP buffer improves. You can use this to monitor changes in performance as you add new data node processes.
Mean send size and Mean receive size. These statistics enable you to gauge the efficiency of, respectively writes and reads between nodes. The values are given in bytes. Higher values mean a lower cost per byte sent or received; the maximum value is 64K.
To cause all cluster log statistics to be logged, you can use
the following command in the NDB
management client:
ndb_mgm> ALL CLUSTERLOG STATISTICS=15
Setting the threshold for STATISTICS to 15
causes the cluster log to become very verbose, and to grow
quite rapidly in size, in direct proportion to the number of
cluster nodes and the amount of activity in the MySQL Cluster.
For more information about MySQL Cluster management client commands relating to logging and reporting, see Section 18.5.6.1, “MySQL Cluster Logging Management Commands”.
This section contains information about the messages written to
the cluster log in response to different cluster log events. It
provides additional, more specific information on
NDB transporter errors.
The following table lists the most common
NDB cluster log messages. For
information about the cluster log, log events, and event types,
see Section 18.5.6, “Event Reports Generated in MySQL Cluster”. These log
messages also correspond to log event types in the MGM API; see
The Ndb_logevent_type Type, for related information
of interest to Cluster API developers.
| Log Message | Description | Event Name | Event Type | Priority | Severity |
|---|---|---|---|---|---|
Node | The data node having node ID node_id has
connected to the management server (node
mgm_node_id). | Connected | Connection | 8 | INFO |
Node | The data node having node ID data_node_id has
disconnected from the management server (node
mgm_node_id). | Disconnected | Connection | 8 | ALERT |
Node | The API node or SQL node having node ID
api_node_id is no longer
communicating with data node
data_node_id. | CommunicationClosed | Connection | 8 | INFO |
Node | The API node or SQL node having node ID
api_node_id is now
communicating with data node
data_node_id. | CommunicationOpened | Connection | 8 | INFO |
Node | The API node having node ID api_node_id has
connected to management node
mgm_node_id using
NDB API version
version (generally the same
as the MySQL version number). | ConnectedApiVersion | Connection | 8 | INFO |
Node | A global checkpoint with the ID gci has been
started; node node_id is the
master responsible for this global checkpoint. | GlobalCheckpointStarted | Checkpoint | 9 | INFO |
Node | The global checkpoint having the ID gci has
been completed; node node_id
was the master responsible for this global checkpoint. | GlobalCheckpointCompleted | Checkpoint | 10 | INFO |
Node | The local checkpoint having sequence ID lcp
has been started on node
node_id. The most recent GCI
that can be used has the index
current_gci, and the oldest
GCI from which the cluster can be restored has the index
old_gci. | LocalCheckpointStarted | Checkpoint | 7 | INFO |
Node | The local checkpoint having sequence ID lcp
on node node_id has been
completed. | LocalCheckpointCompleted | Checkpoint | 8 | INFO |
Node | The node was unable to determine the most recent usable GCI. | LCPStoppedInCalcKeepGci | Checkpoint | 0 | ALERT |
Node | A table fragment has been checkpointed to disk on node
node_id. The GCI in progress
has the index started_gci,
and the most recent GCI to have been completed has the
index completed_gci. | LCPFragmentCompleted | Checkpoint | 11 | INFO |
Node | Undo logging is blocked because the log buffer is close to overflowing. | UndoLogBlocked | Checkpoint | 7 | INFO |
Node | Data node node_id, running
NDB version
version, is beginning its
startup process. | NDBStartStarted | StartUp | 1 | INFO |
Node | Data node node_id, running
NDB version
version, has started
successfully. | NDBStartCompleted | StartUp | 1 | INFO |
Node | The node has received a signal indicating that a cluster restart has completed. | STTORRYRecieved | StartUp | 15 | INFO |
Node | The node has completed start phase phase of a
type start. For a listing of
start phases, see
Section 18.5.1, “Summary of MySQL Cluster Start Phases”.
(type is one of
initial, system,
node, initial
node, or <Unknown>.) | StartPhaseCompleted | StartUp | 4 | INFO |
Node | Node president_id has been selected as
“president”.
own_id and
dynamic_id should always be
the same as the ID (node_id)
of the reporting node. | CM_REGCONF | StartUp | 3 | INFO |
Node | The reporting node (ID node_id) was unable to
accept node president_id as
president. The cause of the
problem is given as one of Busy,
Election with wait = false,
Not president, Election
without selecting new candidate, or
No such cause. | CM_REGREF | StartUp | 8 | INFO |
Node | The node has discovered its neighboring nodes in the cluster (node
id_1 and node
id_2).
node_id,
own_id, and
dynamic_id should always be
the same; if they are not, this indicates a serious
misconfiguration of the cluster nodes. | FIND_NEIGHBOURS | StartUp | 8 | INFO |
Node | The node has received a shutdown signal. The
type of shutdown is either
Cluster or Node. | NDBStopStarted | StartUp | 1 | INFO |
Node [,
]
[Initiated by signal
] | The node has been shut down. This report may include an
action, which if present is
one of restarting, no
start, or initial. The
report may also include a reference to an
NDB Protocol
signal; for possible signals,
refer to
Operations and Signals. | NDBStopCompleted | StartUp | 1 | INFO |
Node [,
action]. [Occured
during startphase
]
[ Initiated by
]
[Caused by error
[(extra info
]] | The node has been forcibly shut down. The
action (one of
restarting, no
start, or initial)
subsequently being taken, if any, is also reported. If
the shutdown occurred while the node was starting, the
report includes the
start_phase during which the
node failed. If this was a result of a
signal sent to the node, this
information is also provided (see
Operations and Signals,
for more information). If the error causing the failure
is known, this is also included; for more information
about NDB error messages
and classifications, see MySQL Cluster API Errors. | NDBStopForced | StartUp | 1 | ALERT |
Node | The node shutdown process was aborted by the user. | NDBStopAborted | StartUp | 1 | INFO |
Node | This reports global checkpoints referenced during a node start. The redo
log prior to keep_pos is
dropped. last_pos is the last
global checkpoint in which data node the participated;
restore_pos is the global
checkpoint which is actually used to restore all data
nodes. | StartREDOLog | StartUp | 4 | INFO |
startup_message [Listed separately;
see below.] | There are a number of possible startup messages that can be logged under different circumstances. These are listed separately; see Section 18.5.7.2, “MySQL Cluster Log Startup Messages”. | StartReport | StartUp | 4 | INFO |
Node | Copying of data dictionary information to the restarted node has been completed. | NR_CopyDict | NodeRestart | 8 | INFO |
Node | Copying of data distribution information to the restarted node has been completed. | NR_CopyDistr | NodeRestart | 8 | INFO |
Node | Copy of fragments to starting data node
node_id has begun | NR_CopyFragsStarted | NodeRestart | 8 | INFO |
Node | Fragment fragment_id from table
table_id has been copied to
data node node_id | NR_CopyFragDone | NodeRestart | 10 | INFO |
Node | Copying of all table fragments to restarting data node
node_id has been completed | NR_CopyFragsCompleted | NodeRestart | 8 | INFO |
Node | Data node node1_id has detected the failure
of data node node2_id | NodeFailCompleted | NodeRestart | 8 | ALERT |
All nodes completed failure of Node
| All (remaining) data nodes have detected the failure of data node
node_id | NodeFailCompleted | NodeRestart | 8 | ALERT |
Node failure of
| The failure of data node node_id has been
detected in the
blockNDB
kernel block, where block is 1 of
DBTC, DBDICT,
DBDIH, or DBLQH;
for more information, see
NDB Kernel Blocks | NodeFailCompleted | NodeRestart | 8 | ALERT |
Node | A data node has failed. Its state at the time of failure is described by
an arbitration state code
state_code: possible state
code values can be found in the file
include/kernel/signaldata/ArbitSignalData.hpp. | NODE_FAILREP | NodeRestart | 8 | ALERT |
President restarts arbitration thread
[state=
or Prepare arbitrator node
or Receive arbitrator node
or Started arbitrator node
or Lost arbitrator node
or Lost arbitrator node
or Lost arbitrator node
| This is a report on the current state and progress of arbitration in the
cluster. node_id is the node
ID of the management node or SQL node selected as the
arbitrator. state_code is an
arbitration state code, as found in
include/kernel/signaldata/ArbitSignalData.hpp.
When an error has occurred, an
error_message, also defined
in ArbitSignalData.hpp, is
provided. ticket_id is a
unique identifier handed out by the arbitrator when it
is selected to all the nodes that participated in its
selection; this is used to ensure that each node
requesting arbitration was one of the nodes that took
part in the selection process. | ArbitState | NodeRestart | 6 | INFO |
Arbitration check lost - less than 1/2 nodes left or
Arbitration check won - all node groups and
more than 1/2 nodes left or
Arbitration check won - node group
majority or Arbitration check lost -
missing node group or Network
partitioning - arbitration required or
Arbitration won - positive reply from node
or
Arbitration lost - negative reply from node
or
Network partitioning - no arbitrator
available or Network partitioning -
no arbitrator configured or
Arbitration failure -
| This message reports on the result of arbitration. In the event of
arbitration failure, an
error_message and an
arbitration state_code are
provided; definitions for both of these are found in
include/kernel/signaldata/ArbitSignalData.hpp. | ArbitResult | NodeRestart | 2 | ALERT |
Node | This node is attempting to assume responsibility for the next global checkpoint (that is, it is becoming the master node) | GCP_TakeoverStarted | NodeRestart | 7 | INFO |
Node | This node has become the master, and has assumed responsibility for the next global checkpoint | GCP_TakeoverCompleted | NodeRestart | 7 | INFO |
Node | This node is attempting to assume responsibility for the next set of local checkpoints (that is, it is becoming the master node) | LCP_TakeoverStarted | NodeRestart | 7 | INFO |
Node | This node has become the master, and has assumed responsibility for the next set of local checkpoints | LCP_TakeoverCompleted | NodeRestart | 7 | INFO |
Node | This report of transaction activity is given approximately once every 10 seconds | TransReportCounters | Statistic | 8 | INFO |
Node | Number of operations performed by this node, provided approximately once every 10 seconds | OperationReportCounters | Statistic | 8 | INFO |
Node | A table having the table ID shown has been created | TableCreated | Statistic | 7 | INFO |
Node | JobStatistic | Statistic | 9 | INFO | |
Mean send size to Node = | This node is sending an average of bytes
bytes per send to node
node_id | SendBytesStatistic | Statistic | 9 | INFO |
Mean receive size to Node = | This node is receiving an average of bytes of
data each time it receives data from node
node_id | ReceiveBytesStatistic | Statistic | 9 | INFO |
Node /
Node | This report is generated when a DUMP 1000 command is
issued in the cluster management client; for more
information, see
DUMP 1000, in
MySQL Cluster Internals | MemoryUsage | Statistic | 5 | INFO |
Node | A transporter error occurred while communicating with node
node2_id; for a listing of
transporter error codes and messages, see
NDB Transporter Errors, in
MySQL Cluster Internals | TransporterError | Error | 2 | ERROR |
Node | A warning of a potential transporter problem while communicating with
node node2_id; for a listing
of transporter error codes and messages, see
NDB Transporter Errors, for more
information | TransporterWarning | Error | 8 | WARNING |
Node | This node missed a heartbeat from node
node2_id | MissedHeartbeat | Error | 8 | WARNING |
Node | This node has missed at least 3 heartbeats from node
node2_id, and so has declared
that node “dead” | DeadDueToHeartbeat | Error | 8 | ALERT |
Node | This node has sent a heartbeat to node
node2_id | SentHeartbeat | Info | 12 | INFO |
Node | This report is seen during heavy event buffer usage, for example, when many updates are being applied in a relatively short period of time; the report shows the number of bytes and the percentage of event buffer memory used, the bytes allocated and percentage still available, and the latest and latest restorable global checkpoints | EventBufferStatus | Info | 7 | INFO |
Node , Node
, Node
| These reports are written to the cluster log when entering and exiting
single user mode; API_node_id
is the node ID of the API or SQL having exclusive access
to the cluster (for more information, see
Section 18.5.8, “MySQL Cluster Single User Mode”); the
message Unknown single user report
indicates an error has taken place and should never be
seen in normal operation | SingleUser | Info | 7 | INFO |
Node | A backup has been started using the management node having
mgm_node_id; this message is
also displayed in the cluster management client when the
START BACKUP command is issued; for
more information, see
Section 18.5.3.2, “Using The MySQL Cluster Management Client to Create a Backup” | BackupStarted | Backup | 7 | INFO |
Node | The backup having the ID backup_id has been
completed; for more information, see
Section 18.5.3.2, “Using The MySQL Cluster Management Client to Create a Backup” | BackupCompleted | Backup | 7 | INFO |
Node | The backup failed to start; for error codes, see MGM API Errors | BackupFailedToStart | Backup | 7 | ALERT |
Node | The backup was terminated after starting, possibly due to user intervention | BackupAborted | Backup | 7 | ALERT |
Possible startup messages with descriptions are provided in the following list:
Initial start, waiting for %s to connect, nodes [ all: %s connected: %s no-wait: %s ]Waiting until nodes: %s connects, nodes [ all: %s connected: %s no-wait: %s ]Waiting %u sec for nodes %s to connect, nodes [ all: %s connected: %s no-wait: %s ]Waiting for non partitioned start, nodes [ all: %s connected: %s missing: %s no-wait: %s ]Waiting %u sec for non partitioned start, nodes [ all: %s connected: %s missing: %s no-wait: %s ]Initial start with nodes %s [ missing: %s no-wait: %s ]Start with all nodes %sStart with nodes %s [ missing: %s no-wait: %s ]Start potentially partitioned with nodes %s [ missing: %s no-wait: %s ]Unknown startreport: 0x%x [ %s %s %s %s ]
This section lists error codes, names, and messages that are written to the cluster log in the event of transporter errors.
| Error Code | Error Name | Error Text |
|---|---|---|
| 0x00 | TE_NO_ERROR | No error |
| 0x01 | TE_ERROR_CLOSING_SOCKET | Error found during closing of socket |
| 0x02 | TE_ERROR_IN_SELECT_BEFORE_ACCEPT | Error found before accept. The transporter will retry |
| 0x03 | TE_INVALID_MESSAGE_LENGTH | Error found in message (invalid message length) |
| 0x04 | TE_INVALID_CHECKSUM | Error found in message (checksum) |
| 0x05 | TE_COULD_NOT_CREATE_SOCKET | Error found while creating socket(can't create socket) |
| 0x06 | TE_COULD_NOT_BIND_SOCKET | Error found while binding server socket |
| 0x07 | TE_LISTEN_FAILED | Error found while listening to server socket |
| 0x08 | TE_ACCEPT_RETURN_ERROR | Error found during accept(accept return error) |
| 0x0b | TE_SHM_DISCONNECT | The remote node has disconnected |
| 0x0c | TE_SHM_IPC_STAT | Unable to check shm segment |
| 0x0d | TE_SHM_UNABLE_TO_CREATE_SEGMENT | Unable to create shm segment |
| 0x0e | TE_SHM_UNABLE_TO_ATTACH_SEGMENT | Unable to attach shm segment |
| 0x0f | TE_SHM_UNABLE_TO_REMOVE_SEGMENT | Unable to remove shm segment |
| 0x10 | TE_TOO_SMALL_SIGID | Sig ID too small |
| 0x11 | TE_TOO_LARGE_SIGID | Sig ID too large |
| 0x12 | TE_WAIT_STACK_FULL | Wait stack was full |
| 0x13 | TE_RECEIVE_BUFFER_FULL | Receive buffer was full |
| 0x14 | TE_SIGNAL_LOST_SEND_BUFFER_FULL | Send buffer was full,and trying to force send fails |
| 0x15 | TE_SIGNAL_LOST | Send failed for unknown reason(signal lost) |
| 0x16 | TE_SEND_BUFFER_FULL | The send buffer was full, but sleeping for a while solved |
| 0x0017 | TE_SCI_LINK_ERROR | There is no link from this node to the switch |
| 0x18 | TE_SCI_UNABLE_TO_START_SEQUENCE | Could not start a sequence, because system resources are exumed or no sequence has been created |
| 0x19 | TE_SCI_UNABLE_TO_REMOVE_SEQUENCE | Could not remove a sequence |
| 0x1a | TE_SCI_UNABLE_TO_CREATE_SEQUENCE | Could not create a sequence, because system resources are exempted. Must reboot |
| 0x1b | TE_SCI_UNRECOVERABLE_DATA_TFX_ERROR | Tried to send data on redundant link but failed |
| 0x1c | TE_SCI_CANNOT_INIT_LOCALSEGMENT | Cannot initialize local segment |
| 0x1d | TE_SCI_CANNOT_MAP_REMOTESEGMENT | Cannot map remote segment |
| 0x1e | TE_SCI_UNABLE_TO_UNMAP_SEGMENT | Cannot free the resources used by this segment (step 1) |
| 0x1f | TE_SCI_UNABLE_TO_REMOVE_SEGMENT | Cannot free the resources used by this segment (step 2) |
| 0x20 | TE_SCI_UNABLE_TO_DISCONNECT_SEGMENT | Cannot disconnect from a remote segment |
| 0x21 | TE_SHM_IPC_PERMANENT | Shm ipc Permanent error |
| 0x22 | TE_SCI_UNABLE_TO_CLOSE_CHANNEL | Unable to close the sci channel and the resources allocated |
Single user mode enables the database administrator to restrict access to the database system to a single API node, such as a MySQL server (SQL node) or an instance of ndb_restore. When entering single user mode, connections to all other API nodes are closed gracefully and all running transactions are aborted. No new transactions are permitted to start.
Once the cluster has entered single user mode, only the designated API node is granted access to the database.
You can use the ALL STATUS command in the
ndb_mgm client to see when the cluster has
entered single user mode. You can also check the
status column of the
ndbinfo.nodes table (see
Section 18.5.10.13, “The ndbinfo nodes Table”, for more
information).
Example:
ndb_mgm> ENTER SINGLE USER MODE 5
After this command has executed and the cluster has entered single
user mode, the API node whose node ID is 5
becomes the cluster's only permitted user.
The node specified in the preceding command must be an API node; attempting to specify any other type of node will be rejected.
When the preceding command is invoked, all transactions running on the designated node are aborted, the connection is closed, and the server must be restarted.
The command EXIT SINGLE USER MODE changes the state of the cluster's data nodes from single user mode to normal mode. API nodes—such as MySQL Servers—waiting for a connection (that is, waiting for the cluster to become ready and available), are again permitted to connect. The API node denoted as the single-user node continues to run (if still connected) during and after the state change.
Example:
ndb_mgm> EXIT SINGLE USER MODE
There are two recommended ways to handle a node failure when running in single user mode:
Method 1:
Finish all single user mode transactions
Issue the EXIT SINGLE USER MODE command
Restart the cluster's data nodes
Method 2:
Restart database nodes prior to entering single user mode.
This section discusses several SQL statements that can prove useful in managing and monitoring a MySQL server that is connected to a MySQL Cluster, and in some cases provide information about the cluster itself.
SHOW ENGINE NDB STATUS,SHOW ENGINE NDBCLUSTER STATUSThe output of this statement contains information about the server's connection to the cluster, creation and usage of MySQL Cluster objects, and binary logging for MySQL Cluster replication.
See Section 13.7.5.16, “SHOW ENGINE Syntax”, for a usage example and more detailed information.
This statement can be used to determine whether or not clustering support is enabled in the MySQL server, and if so, whether it is active.
See Section 13.7.5.17, “SHOW ENGINES Syntax”, for more detailed information.
NoteIn MySQL 5.1 and later, this statement does not support a
LIKEclause. However, you can useLIKEto filter queries against theINFORMATION_SCHEMA.ENGINEStable, as discussed in the next item.SELECT * FROM INFORMATION_SCHEMA.ENGINES [WHERE ENGINE LIKE 'NDB%']This is the equivalent of
SHOW ENGINES, but uses theENGINEStable of theINFORMATION_SCHEMAdatabase. Unlike the case with theSHOW ENGINESstatement, it is possible to filter the results using aLIKEclause, and to select specific columns to obtain information that may be of use in scripts. For example, the following query shows whether the server was built withNDBsupport and, if so, whether it is enabled:mysql>
SELECT SUPPORT FROM INFORMATION_SCHEMA.ENGINES->WHERE ENGINE LIKE 'NDB%';+---------+ | support | +---------+ | ENABLED | +---------+See Section 21.6, “The INFORMATION_SCHEMA ENGINES Table”, for more information.
This statement provides a list of most server system variables relating to the
NDBstorage engine, and their values, as shown here:mysql>
SHOW VARIABLES LIKE 'NDB%';+-------------------------------------+-------+ | Variable_name | Value | +-------------------------------------+-------+ | ndb_autoincrement_prefetch_sz | 32 | | ndb_cache_check_time | 0 | | ndb_extra_logging | 0 | | ndb_force_send | ON | | ndb_index_stat_cache_entries | 32 | | ndb_index_stat_enable | OFF | | ndb_index_stat_update_freq | 20 | | ndb_report_thresh_binlog_epoch_slip | 3 | | ndb_report_thresh_binlog_mem_usage | 10 | | ndb_use_copying_alter_table | OFF | | ndb_use_exact_count | ON | | ndb_use_transactions | ON | +-------------------------------------+-------+See Section 5.1.4, “Server System Variables”, for more information.
SELECT * FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES WHERE VARIABLE_NAME LIKE 'NDB%';This statement is the equivalent of the
SHOWcommand described in the previous item, and provides almost identical output, as shown here:mysql>
SELECT * FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES->WHERE VARIABLE_NAME LIKE 'NDB%';+-------------------------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +-------------------------------------+----------------+ | NDB_AUTOINCREMENT_PREFETCH_SZ | 32 | | NDB_CACHE_CHECK_TIME | 0 | | NDB_EXTRA_LOGGING | 0 | | NDB_FORCE_SEND | ON | | NDB_INDEX_STAT_CACHE_ENTRIES | 32 | | NDB_INDEX_STAT_ENABLE | OFF | | NDB_INDEX_STAT_UPDATE_FREQ | 20 | | NDB_REPORT_THRESH_BINLOG_EPOCH_SLIP | 3 | | NDB_REPORT_THRESH_BINLOG_MEM_USAGE | 10 | | NDB_USE_COPYING_ALTER_TABLE | OFF | | NDB_USE_EXACT_COUNT | ON | | NDB_USE_TRANSACTIONS | ON | +-------------------------------------+----------------+Unlike the case with the
SHOWcommand, it is possible to select individual columns. For example:mysql>
SELECT VARIABLE_VALUE->FROM INFORMATION_SCHEMA.GLOBAL_VARIABLES->WHERE VARIABLE_NAME = 'ndb_force_send';+----------------+ | VARIABLE_VALUE | +----------------+ | ON | +----------------+See Section 21.9, “The INFORMATION_SCHEMA GLOBAL_VARIABLES and SESSION_VARIABLES Tables”, and Section 5.1.4, “Server System Variables”, for more information.
This statement shows at a glance whether or not the MySQL server is acting as a cluster SQL node, and if so, it provides the MySQL server's cluster node ID, the host name and port for the cluster management server to which it is connected, and the number of data nodes in the cluster, as shown here:
mysql>
SHOW STATUS LIKE 'NDB%';+--------------------------+---------------+ | Variable_name | Value | +--------------------------+---------------+ | Ndb_cluster_node_id | 10 | | Ndb_config_from_host | 192.168.0.103 | | Ndb_config_from_port | 1186 | | Ndb_number_of_data_nodes | 4 | +--------------------------+---------------+If the MySQL server was built with clustering support, but it is not connected to a cluster, all rows in the output of this statement contain a zero or an empty string:
mysql>
SHOW STATUS LIKE 'NDB%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | Ndb_cluster_node_id | 0 | | Ndb_config_from_host | | | Ndb_config_from_port | 0 | | Ndb_number_of_data_nodes | 0 | +--------------------------+-------+See also Section 13.7.5.36, “SHOW STATUS Syntax”.
SELECT * FROM INFORMATION_SCHEMA.GLOBAL_STATUS WHERE VARIABLE_NAME LIKE 'NDB%';This statement provides similar output to the
SHOWcommand discussed in the previous item. However, unlike the case withSHOW STATUS, it is possible using theSELECTto extract values in SQL for use in scripts for monitoring and automation purposes.See Section 21.8, “The INFORMATION_SCHEMA GLOBAL_STATUS and SESSION_STATUS Tables”, for more information.
You can also query the tables in the
ndbinfo information database for
real-time data about many MySQL Cluster operations. See
Section 18.5.10, “The ndbinfo MySQL Cluster Information Database”.
- 18.5.10.1 The ndbinfo arbitrator_validity_detail Table
- 18.5.10.2 The ndbinfo arbitrator_validity_summary Table
- 18.5.10.3 The ndbinfo blocks Table
- 18.5.10.4 The ndbinfo cluster_operations Table
- 18.5.10.5 The ndbinfo cluster_transactions Table
- 18.5.10.6 The ndbinfo config_params Table
- 18.5.10.7 The ndbinfo counters Table
- 18.5.10.8 The ndbinfo diskpagebuffer Table
- 18.5.10.9 The ndbinfo logbuffers Table
- 18.5.10.10 The ndbinfo logspaces Table
- 18.5.10.11 The ndbinfo membership Table
- 18.5.10.12 The ndbinfo memoryusage Table
- 18.5.10.13 The ndbinfo nodes Table
- 18.5.10.14 The ndbinfo resources Table
- 18.5.10.15 The ndbinfo server_operations Table
- 18.5.10.16 The ndbinfo server_transactions Table
- 18.5.10.17 The ndbinfo threadblocks Table
- 18.5.10.18 The ndbinfo threadstat Table
- 18.5.10.19 The ndbinfo transporters Table
ndbinfo is a database storing containing
information specific to MySQL Cluster.
This database contains a number of tables, each providing a different sort of data about MySQL Cluster node status, resource usage, and operations. You can find more detailed information about each of these tables in the next several sections.
ndbinfo is included with MySQL Cluster support
in the MySQL Server; no special compilation or configuration steps
are required; the tables are created by the MySQL Server when it
connects to the cluster. You can verify that
ndbinfo support is active in a given MySQL
Server instance using SHOW PLUGINS;
if ndbinfo support is enabled, you should see a
row containing ndbinfo in the
Name column and ACTIVE in
the Status column, as shown here (emphasized
text):
mysql> SHOW PLUGINS;
+----------------------------------+--------+--------------------+---------+---------+
| Name | Status | Type | Library | License |
+----------------------------------+--------+--------------------+---------+---------+
| binlog | ACTIVE | STORAGE ENGINE | NULL | GPL |
| mysql_native_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| mysql_old_password | ACTIVE | AUTHENTICATION | NULL | GPL |
| CSV | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MEMORY | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MRG_MYISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| MyISAM | ACTIVE | STORAGE ENGINE | NULL | GPL |
| PERFORMANCE_SCHEMA | ACTIVE | STORAGE ENGINE | NULL | GPL |
| BLACKHOLE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ARCHIVE | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ndbcluster | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ndbinfo | ACTIVE | STORAGE ENGINE | NULL | GPL |
| ndb_transid_mysql_connection_map | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| InnoDB | ACTIVE | STORAGE ENGINE | NULL | GPL |
| INNODB_TRX | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCKS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_LOCK_WAITS | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMP_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| INNODB_CMPMEM_RESET | ACTIVE | INFORMATION SCHEMA | NULL | GPL |
| partition | ACTIVE | STORAGE ENGINE | NULL | GPL |
+----------------------------------+--------+--------------------+---------+---------+
22 rows in set (0.00 sec)
You can also do this by checking the output of
SHOW ENGINES for a line including
ndbinfo in the Engine column
and YES in the Support
column, as shown here (emphasized text):
mysql> SHOW ENGINES\G
*************************** 1. row ***************************
Engine: ndbcluster
Support: YES
Comment: Clustered, fault-tolerant tables
Transactions: YES
XA: NO
Savepoints: NO
*************************** 2. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 3. row ***************************
Engine: ndbinfo
Support: YES
Comment: MySQL Cluster system information storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 4. row ***************************
Engine: CSV
Support: YES
Comment: CSV storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 6. row ***************************
Engine: FEDERATED
Support: NO
Comment: Federated MySQL storage engine
Transactions: NULL
XA: NULL
Savepoints: NULL
*************************** 7. row ***************************
Engine: ARCHIVE
Support: YES
Comment: Archive storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 8. row ***************************
Engine: InnoDB
Support: YES
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES
XA: YES
Savepoints: YES
*************************** 9. row ***************************
Engine: MyISAM
Support: DEFAULT
Comment: Default engine as of MySQL 3.23 with great performance
Transactions: NO
XA: NO
Savepoints: NO
*************************** 10. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Transactions: NO
XA: NO
Savepoints: NO
10 rows in set (0.00 sec)
If ndbinfo support is enabled, then you can
access ndbinfo using SQL statements in
mysql or another MySQL client. For example, you
can see ndbinfo listed in the output of
SHOW DATABASES, as shown here:
mysql> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| ndbinfo |
| test |
+--------------------+
4 rows in set (0.00 sec)
If the mysqld process was not started with the
--ndbcluster option,
ndbinfo is not available and is not displayed
by SHOW DATABASES. If
mysqld was formerly connected to a MySQL
Cluster but the cluster becomes unavailable (due to events such as
cluster shutdown, loss of network connectivity, and so forth),
ndbinfo and its tables remain visible, but an
attempt to access any tables (other than blocks
or config_params) fails with Got
error 157 'Connection to NDB failed' from NDBINFO.
With the exception of the blocks and
config_params tables, what we refer to as
ndbinfo “tables” are actually
views generated from internal NDB
tables not normally visible to the MySQL Server.
All ndbinfo tables are read-only, and are
generated on demand when queried. Because many of them are
generated in parallel by the data nodes while other are specific
to a given SQL node, they are not guaranteed to provide a
consistent snapshot.
In addition, pushing down of joins is not supported on
ndbinfo tables; so joining large
ndbinfo tables can require transfer of a large
amount of data to the requesting API node, even when the query
makes use of a WHERE clause.
ndbinfo tables are not included in the query
cache. (Bug #59831)
You can select the ndbinfo database with a
USE statement, and then issue a
SHOW TABLES statement to obtain a
list of tables, just as for any other database, like this:
mysql>USE ndbinfo;Database changed mysql>SHOW TABLES;+-----------------------------+ | Tables_in_ndbinfo | +-----------------------------+ | arbitrator_validity_detail | | arbitrator_validity_summary | | blocks | | cluster_operations | | cluster_transactions | | config_params | | counters | | diskpagebuffer | | logbuffers | | logspaces | | membership | | memoryusage | | nodes | | resources | | server_operations | | server_transactions | | threadblocks | | threadstat | | transporters | +-----------------------------+ 19 rows in set (0.03 sec)
The cluster_operations,
cluster_transactions,
server_operations,
server_transactions,
threadblocks, and
threadstat tables were added in
MySQL Cluster NDB 7.2.2. The
arbitrator_validity_detail,
arbitrator_validity_summary, and
membership tables were added in
MySQL Cluster NDB 7.2.10.
You can execute SELECT statements
against these tables, just as you would normally expect:
mysql> SELECT * FROM memoryusage;
+---------+---------------------+--------+------------+------------+-------------+
| node_id | memory_type | used | used_pages | total | total_pages |
+---------+---------------------+--------+------------+------------+-------------+
| 5 | Data memory | 753664 | 23 | 1073741824 | 32768 |
| 5 | Index memory | 163840 | 20 | 1074003968 | 131104 |
| 5 | Long message buffer | 2304 | 9 | 67108864 | 262144 |
| 6 | Data memory | 753664 | 23 | 1073741824 | 32768 |
| 6 | Index memory | 163840 | 20 | 1074003968 | 131104 |
| 6 | Long message buffer | 2304 | 9 | 67108864 | 262144 |
+---------+---------------------+--------+------------+------------+-------------+
6 rows in set (0.02 sec)
More complex queries, such as the two following
SELECT statements using the
memoryusage table, are possible:
mysql>SELECT SUM(used) as 'Data Memory Used, All Nodes'>FROM memoryusage>WHERE memory_type = 'Data memory';+-----------------------------+ | Data Memory Used, All Nodes | +-----------------------------+ | 6460 | +-----------------------------+ 1 row in set (0.37 sec) mysql>SELECT SUM(max) as 'Total IndexMemory Available'>FROM memoryusage>WHERE memory_type = 'Index memory';+-----------------------------+ | Total IndexMemory Available | +-----------------------------+ | 25664 | +-----------------------------+ 1 row in set (0.33 sec)
ndbinfo table and column names are case
sensitive (as is the name of the ndbinfo
database itself). These identifiers are in lowercase. Trying to
use the wrong lettercase results in an error, as shown in this
example:
mysql>SELECT * FROM nodes;+---------+--------+---------+-------------+ | node_id | uptime | status | start_phase | +---------+--------+---------+-------------+ | 1 | 13602 | STARTED | 0 | | 2 | 16 | STARTED | 0 | +---------+--------+---------+-------------+ 2 rows in set (0.04 sec) mysql>SELECT * FROM Nodes;ERROR 1146 (42S02): Table 'ndbinfo.Nodes' doesn't exist
mysqldump ignores the
ndbinfo database entirely, and excludes it from
any output. This is true even when using the
--databases or
--all-databases option.
MySQL Cluster also maintains tables in the
INFORMATION_SCHEMA information database,
including the FILES table which
contains information about files used for MySQL Cluster Disk Data
storage. For more information, see
Section 21.29, “INFORMATION_SCHEMA Tables for MySQL Cluster”.
The arbitrator_validity_detail table shows
the view that each data node in the cluster of the arbitrator.
It is a subset of the
membership table.
The following table provides information about the columns in
the arbitrator_validity_detail table. For
each column, the table shows the name, data type, and a brief
description. Additional information can be found in the notes
following the table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | This node's node ID |
arbitrator | integer | Node ID of arbitrator |
arb_ticket | string | Internal identifier used to track arbitration |
arb_connected | Yes or No | Whether this node is connected to the arbitrator |
arb_state | Enumeration (see text) | Arbitration state |
The node ID is the same as that reported by ndb_mgm -e "SHOW".
All nodes should show the same arbitrator and
arb_ticket values as well as the same
arb_state value. Possible
arb_state values are
ARBIT_NULL, ARBIT_INIT,
ARBIT_FIND, ARBIT_PREP1,
ARBIT_PREP2, ARBIT_START,
ARBIT_RUN, ARBIT_CHOOSE,
ARBIT_CRASH, and UNKNOWN.
arb_connected shows whether the current node
is connected to the arbitrator.
Like the membership and
arbitrator_validity_summary
tables, this table was added in MySQL Cluster NDB 7.2.10.
The arbitrator_validity_summary table
provides a composite view of the arbitrator with regard to the
cluster's data nodes.
The following table provides information about the columns in
the arbitrator_validity_summary table. For
each column, the table shows the name, data type, and a brief
description. Additional information can be found in the notes
following the table.
| Column Name | Type | Description |
|---|---|---|
arbitrator | integer | Node ID of arbitrator |
arb_ticket | string | Internal identifier used to track arbitration |
arb_connected | Yes or No | Whether this arbitrator is connected to the cluster |
consensus_count | integer | Number of data nodes that see this node as arbitrator |
In normal operations, this table should have only 1 row for any appreciable length of time. If it has more than 1 row for longer than a few moments, then either not all nodes are connected to the arbitrator, or all nodes are connected, but do not agree on the same arbitrator.
The arbitrator column shows the
arbitrator's node ID.
arb_ticket is the internal identifier used by
this arbitrator.
arb_connected shows whether this node is
connected to the cluster as an arbitrator.
Like the membership and
arbitrator_validity_detail
tables, this table was added in MySQL Cluster NDB 7.2.10.
The blocks table is a static table which
simply contains the names and internal IDs of all NDB kernel
blocks (see NDB Kernel Blocks). It
is for use by the other
ndbinfo tables (most of which
are actually views) in mapping block numbers to block names for
producing human-readable output.
The following table provides information about the columns in
the blocks table. For each column, the table
shows the name, data type, and a brief description. Additional
information can be found in the notes following the table.
| Column Name | Type | Description |
|---|---|---|
block_number | integer | Block number |
block_name | string | Block name |
To obtain a list of all block names, simply execute
SELECT block_name FROM ndbinfo.blocks.
Although this is a static table, its content can vary between
different MySQL Cluster releases.
The cluster_operations table provides a
per-operation (stateful primary key op) view of all activity in
the MySQL Cluster from the point of view of the local data
management (LQH) blocks (see
The DBLQH Block).
The following table provides information about the columns in
the cluster_operations table. For each
column, the table shows the name, data type, and a brief
description. Additional information can be found in the notes
following the table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | Node ID of reporting LQH block |
block_instance | integer | LQH block instance |
transid | integer | Transaction ID |
operation_type | string | Operation type (see text for possible values) |
state | string | Operation state (see text for possible values) |
tableid | integer | Table ID |
fragmentid | integer | Fragment ID |
client_node_id | integer | Client node ID |
client_block_ref | integer | Client block reference |
tc_node_id | integer | Transaction coordinator node ID |
tc_block_no | integer | Transaction coordinator block number |
tc_block_instance | integer | Transaction coordinator block instance |
The transaction ID is a unique 64-bit number which can be
obtained using the NDB API's
getTransactionId()
method. (Currently, the MySQL Server does not expose the NDB API
transaction ID of an ongoing transaction.)
The operation_type column can take any one of
the values READ, READ-SH,
READ-EX, INSERT,
UPDATE, DELETE,
WRITE, UNLOCK,
REFRESH, SCAN,
SCAN-SH, SCAN-EX, or
<unknown>.
The state column can have any one of the
values ABORT_QUEUED,
ABORT_STOPPED, COMMITTED,
COMMIT_QUEUED,
COMMIT_STOPPED,
COPY_CLOSE_STOPPED,
COPY_FIRST_STOPPED,
COPY_STOPPED, COPY_TUPKEY,
IDLE, LOG_ABORT_QUEUED,
LOG_COMMIT_QUEUED,
LOG_COMMIT_QUEUED_WAIT_SIGNAL,
LOG_COMMIT_WRITTEN,
LOG_COMMIT_WRITTEN_WAIT_SIGNAL,
LOG_QUEUED, PREPARED,
PREPARED_RECEIVED_COMMIT,
SCAN_CHECK_STOPPED,
SCAN_CLOSE_STOPPED,
SCAN_FIRST_STOPPED,
SCAN_RELEASE_STOPPED,
SCAN_STATE_USED,
SCAN_STOPPED, SCAN_TUPKEY,
STOPPED, TC_NOT_CONNECTED,
WAIT_ACC, WAIT_ACC_ABORT,
WAIT_AI_AFTER_ABORT,
WAIT_ATTR, WAIT_SCAN_AI,
WAIT_TUP, WAIT_TUPKEYINFO,
WAIT_TUP_COMMIT, or
WAIT_TUP_TO_ABORT. (If the MySQL Server is
running with
ndbinfo_show_hidden enabled,
you can view this list of states by selecting from the
ndb$dblqh_tcconnect_state table, which is
normally hidden.)
You can obtain the name of an NDB table from
its table ID by checking the output of
ndb_show_tables.
The fragid is the same as the partition
number seen in the output of ndb_desc
--extra-partition-info (short
form -p).
In client_node_id and
client_block_ref, client
refers to a MySQL Cluster API or SQL node (that is, an NDB API
client or a MySQL Server attached to the cluster).
This table was added in MySQL Cluster NDB 7.2.2.
The cluster_transactions table shows
information about all ongoing transactions in a MySQL Cluster.
The following table provides information about the columns in
the cluster_transactions table. For each
column, the table shows the name, data type, and a brief
description. Additional information can be found in the notes
following the table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | Node ID of transaction coordinator |
block_instance | integer | TC block instance |
transid | integer | Transaction ID |
state | string | Operation state (see text for possible values) |
count_operations | integer | Number of stateful primary key operations in transaction (includes reads with locks, as well as DML operations) |
outstanding_operations | integer | Operations still being executed in local data management blocks |
inactive_seconds | integer | Time spent waiting for API |
client_node_id | integer | Client node ID |
client_block_ref | integer | Client block reference |
The transaction ID is a unique 64-bit number which can be
obtained using the NDB API's
getTransactionId()
method. (Currently, the MySQL Server does not expose the NDB API
transaction ID of an ongoing transaction.)
The state column can have any one of the
values CS_ABORTING,
CS_COMMITTING,
CS_COMMIT_SENT,
CS_COMPLETE_SENT,
CS_COMPLETING,
CS_CONNECTED,
CS_DISCONNECTED,
CS_FAIL_ABORTED,
CS_FAIL_ABORTING,
CS_FAIL_COMMITTED,
CS_FAIL_COMMITTING,
CS_FAIL_COMPLETED,
CS_FAIL_PREPARED,
CS_PREPARE_TO_COMMIT,
CS_RECEIVING,
CS_REC_COMMITTING,
CS_RESTART,
CS_SEND_FIRE_TRIG_REQ,
CS_STARTED,
CS_START_COMMITTING,
CS_START_SCAN,
CS_WAIT_ABORT_CONF,
CS_WAIT_COMMIT_CONF,
CS_WAIT_COMPLETE_CONF,
CS_WAIT_FIRE_TRIG_REQ. (If the MySQL Server
is running with
ndbinfo_show_hidden enabled,
you can view this list of states by selecting from the
ndb$dbtc_apiconnect_state table, which is
normally hidden.)
In client_node_id and
client_block_ref, client
refers to a MySQL Cluster API or SQL node (that is, an NDB API
client or a MySQL Server attached to the cluster).
This table was added in MySQL Cluster NDB 7.2.2.
The config_params table is a static table
which provides the names and internal ID numbers of all MySQL
Cluster configuration parameters.
The following table provides information about the columns in
the config_params table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
param_number | integer | The parameter's internal ID number |
param_name | string | The name of the parameter |
Although this is a static table, its content can vary between MySQL Cluster installations, since supported parameters can vary due to differences between software releases, cluster hardware configurations, and other factors.
The counters table provides running totals of
events such as reads and writes for specific kernel blocks and
data nodes. Counts are kept from the most recent node start or
restart; a node start or restart resets all counters on that
node. Not all kernel blocks have all types of counters.
The following table provides information about the columns in
the counters table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | The data node ID |
block_name | string | Name of the associated NDB kernel block (see NDB Kernel Blocks). |
block_instance | integer | Block instance |
counter_id | integer | The counter's internal ID number; normally an integer between 1 and 10, inclusive. |
counter_name | string | The name of the counter. See text for names of individual counters and the NDB kernel block with which each counter is associated. |
val | integer | The counter's value |
Each counter is associated with a particular
NDB kernel block. Prior to MySQL Cluster NDB
7.2.0, this was limited to either the DBLQH
kernel block or the DBTC kernel block. In
MySQL Cluster NDB 7.2.0 and later, a number of counters relating
to the DBSPJ kernel block are also available;
these counters are described later in this section.
The OPERATIONS counter is associated with the
DBLQH (local query handler) kernel block (see
The DBLQH Block). A
primary-key read counts as one operation, as does a primary-key
update. For reads, there is one operation in
DBLQH per operation in
DBTC. For writes, there is one operation
counted per replica.
The ATTRINFO,
TRANSACTIONS, COMMITS,
READS, LOCAL_READS,
SIMPLE_READS, WRITES,
LOCAL_WRITES, ABORTS,
TABLE_SCANS, and
RANGE_SCANS counters are associated with the
DBTC (transaction co-ordinator) kernel block (see
The DBTC Block).
LOCAL_WRITES and
LOCAL_READS are primary-key operations using
a transaction coordinator in a node that also holds the primary
replica of the record.
The READS counter includes all reads.
LOCAL_READS includes only those reads of the
primary replica on the same node as this transaction
coordinator. SIMPLE_READS includes only those
reads in which the read operation is the beginning and ending
operation for a given transaction. Simple reads do not hold
locks but are part of a transaction, in that they observe
uncommitted changes made by the transaction containing them but
not of any other uncommitted transactions. Such reads are
“simple” from the point of view of the TC block;
since they hold no locks they are not durable, and once
DBTC has routed them to the relevant LQH
block, it holds no state for them.
ATTRINFO keeps a count of the number of times
an interpreted program is sent to the data node. See
NDB Protocol Messages, for more
information about ATTRINFO messages in the
NDB kernel.
MySQL Cluster NDB 7.2.0, as part of its implementation of
distributed pushed-down joins, adds the
LOCAL_TABLE_SCANS_SENT,
READS_RECEIVED,
PRUNED_RANGE_SCANS_RECEIVED,
RANGE_SCANS_RECEIVED,
LOCAL_READS_SENT,
CONST_PRUNED_RANGE_SCANS_RECEIVED,
LOCAL_RANGE_SCANS_SENT,
REMOTE_READS_SENT,
REMOTE_RANGE_SCANS_SENT,
READS_NOT_FOUND,
SCAN_BATCHES_RETURNED,
TABLE_SCANS_RECEIVED, and
SCAN_ROWS_RETURNED counters. These counters
are associated with the DBSPJ (select
push-down join) kernel block (see
The DBSPJ Block).
A number of counters increasing the visibility of transporter overload and send buffer sizing when troubleshooting such issues were added in MySQL Cluster NDB 7.2.10. (Bug #15935206) For each LQH instance, there is one instance of each counter in the following list:
LQHKEY_OVERLOAD: Number of primary key requests rejected at the LQH block instance due to transporter overloadLQHKEY_OVERLOAD_TC: Count of instances ofLQHKEY_OVERLOADwhere the TC node transporter was overloadedLQHKEY_OVERLOAD_READER: Count of instances ofLQHKEY_OVERLOADwhere the API reader (reads only) node was overloaded.LQHKEY_OVERLOAD_NODE_PEER: Count of instances ofLQHKEY_OVERLOADwhere the next backup data node (writes only) was overloadedLQHKEY_OVERLOAD_SUBSCRIBER: Count of instances ofLQHKEY_OVERLOADwhere a event subscriber (writes only) was overloaded.LQHSCAN_SLOWDOWNS: Count of instances where a fragment scan batch size was reduced due to scanning API transporter overload.
The diskpagebuffer table provides statistics
about disk page buffer usage by MySQL Cluster Disk Data tables.
The following table provides information about the columns in
the diskpagebuffer table. For each column,
the table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | The data node ID |
block_instance | integer | Block instance |
pages_written | integer | Number of pages written to disk. |
pages_written_lcp | integer | Number of pages written by local checkpoints. |
pages_read | integer | Number of pages read from disk |
log_waits | integer | Number of page writes waiting for log to be written to disk |
page_requests_direct_return | integer | Number of requests for pages that were available in buffer |
page_requests_wait_queue | integer | Number of requests that had to wait for pages to become available in buffer |
page_requests_wait_io | integer | Number of requests that had to be read from pages on disk (pages were unavailable in buffer) |
You can use this table with MySQL Cluster Disk Data tables to
determine whether
DiskPageBufferMemory is
sufficiently large to allow data to be read from the buffer
rather from disk; minimizing disk seeks can help improve
performance of such tables.
You can determine the proportion of reads from
DiskPageBufferMemory to
the total number of reads using a query such as this one, which
obtains this ratio as a percentage:
SELECT
node_id,
100 * page_requests_direct_return /
(page_requests_direct_return + page_requests_wait_io)
AS hit_ratio
FROM ndbinfo.diskpagebuffer;
The result from this query should be similar to what is shown here, with one row for each data node in the cluster (in this example, the cluster has 4 data nodes):
+---------+-----------+ | node_id | hit_ratio | +---------+-----------+ | 5 | 97.6744 | | 6 | 97.6879 | | 7 | 98.1776 | | 8 | 98.1343 | +---------+-----------+ 4 rows in set (0.00 sec)
hit_ratio values approaching 100% indicate
that only a very small number of reads are being made from disk
rather than from the buffer, which means that Disk Data read
performance is approaching an optimum level. If any of these
values are less than 95%, this is a strong indicator that the
setting for
DiskPageBufferMemory
needs to be increased in the config.ini
file.
A change in
DiskPageBufferMemory
requires a rolling restart of all of the cluster's data
nodes before it takes effect.
The logbuffer table provides information on
MySQL Cluster log buffer usage.
The following table provides information about the columns in
the logbuffers table. For each column, the
table shows the name, data type, and a brief description.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | The ID of this data node. |
log_type | string | Type of log; one of: REDO or
DD-UNDO. |
log_id | integer | The log ID. |
log_part | integer | The log part number. |
total | integer | Total space available for this log. |
used | integer | Space used by this log. |
This table provides information about MySQL Cluster log space usage.
The following table provides information about the columns in
the logspaces table. For each column, the
table shows the name, data type, and a brief description.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | The ID of this data node. |
log_type | string | Type of log; one of: REDO or
DD-UNDO. |
log_id | integer | The log ID. |
log_part | integer | The log part number. |
total | integer | Total space available for this log. |
used | integer | Space used by this log. |
The membership table describes the view that
each data node has of all the others in the cluster, including
node group membership, president node, arbitrator, arbitrator
successor, arbitrator connection states, and other information.
The following table provides information about the columns in
the membership table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | This node's node ID |
group_id | integer | Node group to which this node belongs |
left node | integer | Node ID of the previous node |
right_node | integer | Node ID of the next node |
president | integer | President's node ID |
successor | integer | Node ID of successor to president |
succession_order | integer | Order in which this node succeeds to presidency |
Conf_HB_order | integer | - |
arbitrator | integer | Node ID of arbitrator |
arb_ticket | string | Internal identifier used to track arbitration |
arb_state | Enumeration (see text) | Arbitration state |
arb_connected | Yes or No | Whether this node is connected to the arbitrator |
connected_rank1_arbs | List of node IDs | Connected arbitrators of rank 1 |
connected_rank2_arbs | List of node IDs | Connected arbitrators of rank 1 |
The node ID and node group ID are the same as reported by ndb_mgm -e "SHOW".
left_node and right_node
are defined in terms of a model that connects all data nodes in
a circle, in order of their node IDs, similar to the ordering of
the numbers on a clock dial, as shown here:
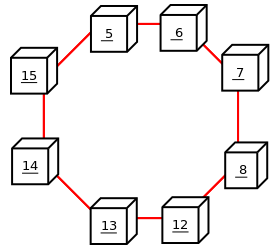
In this example, we have 8 data nodes, numbered 5, 6, 7, 8, 12, 13, 14, and 15, ordered clockwise in a circle. We determine “left” and “right” from the interior of the circle. The node to the left of node 5 is node 15, and the node to the right of node 5 is node 6. You can see all these relationships by running the following query and observing the output:
mysql>SELECT node_id,left_node,right_node->FROM ndbinfo.membership;+---------+-----------+------------+ | node_id | left_node | right_node | +---------+-----------+------------+ | 5 | 15 | 6 | | 6 | 5 | 7 | | 7 | 6 | 8 | | 8 | 7 | 12 | | 12 | 8 | 13 | | 13 | 12 | 14 | | 14 | 13 | 15 | | 15 | 14 | 5 | +---------+-----------+------------+ 8 rows in set (0.00 sec)
The designations “left” and “right” are used in the event log in the same way.
The president node is the node viewed by the
current node as responsible for setting an arbitrator (see
MySQL Cluster Start Phases). If the president
fails or becomes disconnected, the current node expects the node
whose ID is shown in the successor column to
become the new president. The
succession_order column shows the place in
the succession queue that the current node views itself as
having.
In a normal MySQL Cluster, all data nodes should see the same
node as president, and the same node (other
than the president) as its successor. In
addition, the current president should see itself as
1 in the order of succession, the
successor node should see itself as
2, and so on.
All nodes should show the same arb_ticket
values as well as the same arb_state values.
Possible arb_state values are
ARBIT_NULL, ARBIT_INIT,
ARBIT_FIND, ARBIT_PREP1,
ARBIT_PREP2, ARBIT_START,
ARBIT_RUN, ARBIT_CHOOSE,
ARBIT_CRASH, and UNKNOWN.
arb_connected shows whether this node is
connected to the node shown as this node's
arbitrator.
The connected_rank1_arbs and
connected_rank2_arbs columns each display a
list of 0 or more arbitrators having an
ArbitrationRank equal to
1, or to 2, respectively.
Both management nodes and API nodes are eligible to become arbitrators.
Like the
arbitrator_validity_detail and
arbitrator_validity_summary
tables, this table was added in MySQL Cluster NDB 7.2.10.
Querying this table provides information similar to that
provided by the ALL REPORT MemoryUsage
command in the ndb_mgm client, or logged by
ALL DUMP 1000.
The following table provides information about the columns in
the memoryusage table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | The node ID of this data node. |
memory_type | string | One of Data memory or Index
memory, or (MySQL Cluster NDB 7.2.16
and later) Long message
buffer. |
used | integer | Number of bytes currently used for data memory or index memory by this data node. |
used_pages | integer | Number of pages currently used for data memory or index memory by this data node; see text. |
total | integer | Total number of bytes of data memory or index memory available for this data node; see text. |
total_pages | integer | Total number of memory pages available for data memory or index memory on this data node; see text. |
The total column represents the total amount
of memory in bytes available for the given resource (data memory
or index memory) on a particular data node. This number should
be approximately equal to the setting of the corresponding
configuration parameter in the config.ini
file.
Suppose that the cluster has 2 data nodes having node IDs
5 and 6, and the
config.ini file contains the following:
[ndbd default] DataMemory = 1G IndexMemory = 1G
Suppose also that the value of the
LongMessageBuffer
configuration parameter is allowed to assume its default (64 MB
in MySQL Cluster NDB 7.2.16 and later).
The following query shows approximately the same values:
mysql> SELECT node_id, memory_type, total
> FROM ndbinfo.memoryusage;
+---------+---------------------+------------+
| node_id | memory_type | total |
+---------+---------------------+------------+
| 5 | Data memory | 1073741824 |
| 5 | Index memory | 1074003968 |
| 5 | Long message buffer | 67108864 |
| 6 | Data memory | 1073741824 |
| 6 | Index memory | 1074003968 |
| 6 | Long message buffer | 67108864 |
+---------+---------------------+------------+
6 rows in set (0.00 sec)
In this case, the total column values for
index memory are slightly higher than the value set of
IndexMemory due to
internal rounding.
For the used_pages and
total_pages columns, resources are measured
in pages, which are 32K in size for
DataMemory and 8K for
IndexMemory. For long
message buffer memory, the page size is 256 bytes.
Long message buffer information can be found in this table beginning with MySQL Cluster NDB 7.2.16; in earlier versions of MySQL Cluster NDB 7.2, only data memory and index memory were included.
This table contains information on the status of data nodes. For each data node that is running in the cluster, a corresponding row in this table provides the node's node ID, status, and uptime. For nodes that are starting, it also shows the current start phase.
The following table provides information about the columns in
the nodes table. For each column, the table
shows the name, data type, and a brief description. Additional
information can be found in the notes following the table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | The data node's unique node ID in the cluster. |
uptime | integer | Time since the node was last started, in seconds. |
status | string | Current status of the data node; see text for possible values. |
start_phase | integer | If the data node is starting, the current start phase. |
config_generation | integer | The version of the cluster configuration file in use on this data node. |
The uptime column shows the time in seconds
that this node has been running since it was last started or
restarted. This is a BIGINT
value. This figure includes the time actually needed to start
the node; in other words, this counter starts running the moment
that ndbd or ndbmtd is
first invoked; thus, even for a node that has not yet finished
starting, uptime may show a non-zero value.
The status column shows the node's
current status. This is one of: NOTHING,
CMVMI, STARTING,
STARTED, SINGLEUSER,
STOPPING_1, STOPPING_2,
STOPPING_3, or STOPPING_4.
When the status is STARTING, you can see the
current start phase in the start_phase column
(see later in this section). SINGLEUSER is
displayed in the status column for all data
nodes when the cluster is in single user mode (see
Section 18.5.8, “MySQL Cluster Single User Mode”). Seeing one of
the STOPPING states does not necessarily mean
that the node is shutting down but can mean rather that it is
entering a new state; for example, if you put the cluster in
single user mode, you can sometimes see data nodes report their
state briefly as STOPPING_2 before the status
changes to SINGLEUSER.
The start_phase column uses the same range of
values as those used in the output of the
ndb_mgm client
node_id STATUS0. For a listing of MySQL Cluster start
phases with descriptions, see
Section 18.5.1, “Summary of MySQL Cluster Start Phases”.
The config_generation column shows which
version of the cluster configuration is in effect on each data
node. This can be useful when performing a rolling restart of
the cluster in order to make changes in configuration
parameters. For example, from the output of the following
SELECT statement, you can see
that node 3 is not yet using the latest version of the cluster
configuration (6) although nodes 1, 2, and 4
are doing so:
mysql>USE ndbinfo;Database changed mysql>SELECT * FROM nodes;+---------+--------+---------+-------------+-------------------+ | node_id | uptime | status | start_phase | config_generation | +---------+--------+---------+-------------+-------------------+ | 1 | 10462 | STARTED | 0 | 6 | | 2 | 10460 | STARTED | 0 | 6 | | 3 | 10457 | STARTED | 0 | 5 | | 4 | 10455 | STARTED | 0 | 6 | +---------+--------+---------+-------------+-------------------+ 2 rows in set (0.04 sec)
Therefore, for the case just shown, you should restart node 3 to complete the rolling restart of the cluster.
Nodes that are stopped are not accounted for in this table. Suppose that you have a MySQL Cluster with 4 data nodes (node IDs 1, 2, 3 and 4), and all nodes are running normally, then this table contains 4 rows, 1 for each data node:
mysql>USE ndbinfo;Database changed mysql>SELECT * FROM nodes;+---------+--------+---------+-------------+-------------------+ | node_id | uptime | status | start_phase | config_generation | +---------+--------+---------+-------------+-------------------+ | 1 | 11776 | STARTED | 0 | 6 | | 2 | 11774 | STARTED | 0 | 6 | | 3 | 11771 | STARTED | 0 | 6 | | 4 | 11769 | STARTED | 0 | 6 | +---------+--------+---------+-------------+-------------------+ 4 rows in set (0.04 sec)
If you shut down one of the nodes, only the nodes that are still
running are represented in the output of this
SELECT statement, as shown here:
ndb_mgm> 2 STOP
Node 2: Node shutdown initiated
Node 2: Node shutdown completed.
Node 2 has shutdown.
mysql> SELECT * FROM nodes;
+---------+--------+---------+-------------+-------------------+
| node_id | uptime | status | start_phase | config_generation |
+---------+--------+---------+-------------+-------------------+
| 1 | 11807 | STARTED | 0 | 6 |
| 3 | 11802 | STARTED | 0 | 6 |
| 4 | 11800 | STARTED | 0 | 6 |
+---------+--------+---------+-------------+-------------------+
3 rows in set (0.02 sec)
This table provides information about data node resource availability and usage.
These resources are sometimes known as super-pools.
The following table provides information about the columns in
the resources table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | The unique node ID of this data node. |
resource_name | string | Name of the resource; see text. |
reserved | integer | The amount reserved for this resource. |
used | integer | The amount actually used by this resource. |
max | integer | The maximum amount of this resource used, since the node was last started. |
The resource_name can be one of the names
shown in the following table:
| Resource name | Description |
|---|---|
RESERVED | Reserved by the system; cannot be overridden. |
DISK_OPERATIONS | If a log file group is allocated, the size of the undo log buffer is
used to set the size of this resource. This resource is
used only to allocate the undo log buffer for an undo
log file group; there can only be one such group.
Overallocation occurs as needed by
CREATE LOGFILE GROUP. |
DISK_RECORDS | Records allocated for Disk Data operations. |
DATA_MEMORY | Used for main memory tuples, indexes, and hash indexes. Sum of DataMemory and IndexMemory, plus 8 pages of 32 KB each if IndexMemory has been set. Cannot be overallocated. |
JOBBUFFER | Used for allocating job buffers by the NDB scheduler; cannot be overallocated. This is approximately 2 MB per thread plus a 1 MB buffer in both directions for all threads that can communicate. For large configurations this consume several GB. |
FILE_BUFFERS | Used by the redo log handler in the DBLQH kernel
block; cannot be overallocated. Size is
NoOfFragmentLogParts
* RedoBuffer,
plus 1 MB per log file part. |
TRANSPORTER_BUFFERS | Used for send buffers by ndbmtd; the sum of
TotalSendBufferMemory
and
ExtraSendBufferMemory.
This resource that can be overallocated by up to 25
percent. TotalSendBufferMemory is
calculated by summing the send buffer memory per node,
the default value of which is 2 MB. Thus, in a system
having four data nodes and eight API nodes, the data
nodes have 12 * 2 MB send buffer memory.
ExtraSendBufferMemory is used by
ndbmtd and amounts to 2 MB extra
memory per thread. Thus, with 4 LDM threads, 2 TC
threads, 1 main thread, 1 replication thread, and 2
receive threads,
ExtraSendBufferMemory is 10 * 2 MB.
Overallocation of this resource can be performed by
setting the
SharedGlobalMemory
data node configuration parameter. |
DISK_PAGE_BUFFER | Used for the disk page buffer; determined by the
DiskPageBufferMemory
configuration parameter. Cannot be overallocated. |
QUERY_MEMORY | Used by the DBSPJ kernel block. |
SCHEMA_TRANS_MEMORY | Minimum is 2 MB; can be overallocated to use any remaining available memory. |
The server_operations table contains entries
for all ongoing NDB operations that
the current SQL node (MySQL Server) is currently involved in. It
effectively is a subset of the
cluster_operations table, in
which operations for other SQL and API nodes are not shown.
The following table provides information about the columns in
the server_operations table. For each column,
the table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
mysql_connection_id | integer | MySQL Server connection ID |
node_id | integer | Node ID |
block_instance | integer | Block instance |
transid | integer | Transaction ID |
operation_type | string | Operation type (see text for possible values) |
state | string | Operation state (see text for possible values) |
tableid | integer | Table ID |
fragmentid | integer | Fragment ID |
client_node_id | integer | Client node ID |
client_block_ref | integer | Client block reference |
tc_node_id | integer | Transaction coordinator node ID |
tc_block_no | integer | Transaction coordinator block number |
tc_block_instance | integer | Transaction coordinator block instance |
The mysql_connection_id is the same as the
connection or session ID shown in the output of
SHOW PROCESSLIST. It is obtained
from the INFORMATION_SCHEMA table
NDB_TRANSID_MYSQL_CONNECTION_MAP.
The transaction ID is a unique 64-bit number which can be
obtained using the NDB API's
getTransactionId()
method. (Currently, the MySQL Server does not expose the NDB API
transaction ID of an ongoing transaction.)
The operation_type column can take any one of
the values READ, READ-SH,
READ-EX, INSERT,
UPDATE, DELETE,
WRITE, UNLOCK,
REFRESH, SCAN,
SCAN-SH, SCAN-EX, or
<unknown>.
The state column can have any one of the
values ABORT_QUEUED,
ABORT_STOPPED, COMMITTED,
COMMIT_QUEUED,
COMMIT_STOPPED,
COPY_CLOSE_STOPPED,
COPY_FIRST_STOPPED,
COPY_STOPPED, COPY_TUPKEY,
IDLE, LOG_ABORT_QUEUED,
LOG_COMMIT_QUEUED,
LOG_COMMIT_QUEUED_WAIT_SIGNAL,
LOG_COMMIT_WRITTEN,
LOG_COMMIT_WRITTEN_WAIT_SIGNAL,
LOG_QUEUED, PREPARED,
PREPARED_RECEIVED_COMMIT,
SCAN_CHECK_STOPPED,
SCAN_CLOSE_STOPPED,
SCAN_FIRST_STOPPED,
SCAN_RELEASE_STOPPED,
SCAN_STATE_USED,
SCAN_STOPPED, SCAN_TUPKEY,
STOPPED, TC_NOT_CONNECTED,
WAIT_ACC, WAIT_ACC_ABORT,
WAIT_AI_AFTER_ABORT,
WAIT_ATTR, WAIT_SCAN_AI,
WAIT_TUP, WAIT_TUPKEYINFO,
WAIT_TUP_COMMIT, or
WAIT_TUP_TO_ABORT. (If the MySQL Server is
running with
ndbinfo_show_hidden enabled,
you can view this list of states by selecting from the
ndb$dblqh_tcconnect_state table, which is
normally hidden.)
You can obtain the name of an NDB table from
its table ID by checking the output of
ndb_show_tables.
The fragid is the same as the partition
number seen in the output of ndb_desc
--extra-partition-info (short
form -p).
In client_node_id and
client_block_ref, client
refers to a MySQL Cluster API or SQL node (that is, an NDB API
client or a MySQL Server attached to the cluster).
This table was added in MySQL Cluster NDB 7.2.2.
The server_transactions table is subset of
the cluster_transactions
table, but includes only those transactions in which the current
SQL node (MySQL Server) is a participant, while including the
relevant connection IDs.
The following table provides information about the columns in
the server_transactions table. For each
column, the table shows the name, data type, and a brief
description. Additional information can be found in the notes
following the table.
| Column Name | Type | Description |
|---|---|---|
mysql_connection_id | integer | MySQL Server connection ID |
node_id | integer | Transaction coordinator node ID |
block_instance | integer | Transaction coordinator block instance |
transid | integer | Transaction ID |
state | string | Operation state (see text for possible values) |
count_operations | integer | Number of stateful operations in the transaction |
outstanding_operations | integer | Operations still being executed by local data management layer (LQH blocks) |
inactive_seconds | integer | Time spent waiting for API |
client_node_id | integer | Client node ID |
client_block_ref | integer | Client block reference |
The mysql_connection_id is the same as the
connection or session ID shown in the output of
SHOW PROCESSLIST. It is obtained
from the INFORMATION_SCHEMA table
NDB_TRANSID_MYSQL_CONNECTION_MAP.
The transaction ID is a unique 64-bit number which can be
obtained using the NDB API's
getTransactionId()
method. (Currently, the MySQL Server does not expose the NDB API
transaction ID of an ongoing transaction.)
The state column can have any one of the
values CS_ABORTING,
CS_COMMITTING,
CS_COMMIT_SENT,
CS_COMPLETE_SENT,
CS_COMPLETING,
CS_CONNECTED,
CS_DISCONNECTED,
CS_FAIL_ABORTED,
CS_FAIL_ABORTING,
CS_FAIL_COMMITTED,
CS_FAIL_COMMITTING,
CS_FAIL_COMPLETED,
CS_FAIL_PREPARED,
CS_PREPARE_TO_COMMIT,
CS_RECEIVING,
CS_REC_COMMITTING,
CS_RESTART,
CS_SEND_FIRE_TRIG_REQ,
CS_STARTED,
CS_START_COMMITTING,
CS_START_SCAN,
CS_WAIT_ABORT_CONF,
CS_WAIT_COMMIT_CONF,
CS_WAIT_COMPLETE_CONF,
CS_WAIT_FIRE_TRIG_REQ. (If the MySQL Server
is running with
ndbinfo_show_hidden enabled,
you can view this list of states by selecting from the
ndb$dbtc_apiconnect_state table, which is
normally hidden.)
In client_node_id and
client_block_ref, client
refers to a MySQL Cluster API or SQL node (that is, an NDB API
client or a MySQL Server attached to the cluster).
This table was added in MySQL Cluster NDB 7.2.2.
The threadblocks table associates data nodes,
threads, and instances of NDB kernel blocks.
The following table provides information about the columns in
the threadblocks table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | Node ID |
thr_no | integer | Thread ID |
block_name | string | Block name |
block_instance | integer | Block instance number |
The block_name is one of the values found in
the block_name column when selecting from the
ndbinfo.blocks table. Although
the list of possible values is static for a given MySQL Cluster
release, the list may vary between releases.
This table was added in MySQL Cluster NDB 7.2.2.
The threadstat table provides a rough
snapshot of statistics for threads running in the
NDB kernel.
The following table provides information about the columns in
the threadstat table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | Node ID |
thr_no | integer | Thread ID |
thr_nm | string | Thread name |
c_loop | string | Number of loops in main loop |
c_exec | string | Number of signals executed |
c_wait | string | Number of times waiting for additional input |
c_l_sent_prioa | integer | Number of priority A signals sent to own node |
c_l_sent_priob | integer | Number of priority B signals sent to own node |
c_r_sent_prioa | integer | Number of priority A signals sent to remote node |
c_r_sent_priob | integer | Number of priority B signals sent to remote node |
os_tid | integer | OS thread ID |
os_now | integer | OS time (ms) |
os_ru_utime | integer | OS user CPU time (µs) |
os_ru_stime | integer | OS system CPU time (µs) |
os_ru_minflt | integer | OS page reclaims (soft page faults) |
os_ru_majflt | integer | OS page faults (hard page faults) |
os_ru_nvcsw | integer | OS voluntary context switches |
os_ru_nivcsw | integer | OS involuntary context switches |
os_time uses the system
gettimeofday() call.
The values of the os_ru_utime,
os_ru_stime, os_ru_minflt,
os_ru_majflt, os_ru_nvcsw,
and os_ru_nivcsw columns are obtained using
the system getrusage() call, or the
equivalent.
Since this table contains counts taken at a given point in time, for best results it is necessary to query this table periodically and store the results in an intermediate table or tables. The MySQL Server's Event Scheduler can be employed to automate such monitoring. For more information, see Section 20.4, “Using the Event Scheduler”.
This table was added in MySQL Cluster NDB 7.2.2.
This table contains information about NDB transporters.
The following table provides information about the columns in
the transporters table. For each column, the
table shows the name, data type, and a brief description.
Additional information can be found in the notes following the
table.
| Column Name | Type | Description |
|---|---|---|
node_id | integer | This data node's unique node ID in the cluster. |
remote_node_id | integer | The remote data node's node ID. |
status | string | Status of the connection. |
remote_address | string | Name or IP address of the remote host |
bytes_sent | integer | Number of bytes sent using this connection |
bytes_received | Number of bytes received using this connection | |
connect_count | Number of times connection established on this transporter | |
overloaded | 1 if this transporter is currently overloaded, otherwise 0 | |
overload_count | Number of times this transporter has entered overload state since connecting | |
slowdown | 1 if this transporter is in scan slowdown state, otherwise 0 | |
slowdown_count | Number of times this transporter has entered scan slowdown state since connecting |
For each running data node in the cluster, the
transporters table displays a row showing the
status of each of that node's connections with all nodes in
the cluster, including itself. This
information is shown in the table's
status column, which can have any one of
the following values: CONNECTING,
CONNECTED, DISCONNECTING,
or DISCONNECTED.
Connections to API and management nodes which are configured but
not currently connected to the cluster are shown with status
DISCONNECTED. Rows where the
node_id is that of a data nodes which is not
currently connected are not shown in this table. (This is
similar omission of disconnected nodes in the
ndbinfo.nodes table.
The remote_address,
bytes_sent, and
bytes_received columns were added in MySQL
Cluster NDB 7.2.9. The remote_address is the
host name or address for the node whose ID is shown in the
remote_node_id column. The
bytes_sent from this node and
bytes_received by this node are the numbers,
respectively, of bytes sent and received by the node using this
connection since it was established; for nodes whose status is
CONNECTING or
DISCONNECTED, these columns always display
0.
The connect_count,
overloaded, overload_count
,slowdown, and
slowdown_count columns were added in MySQL
Cluster NDB 7.2.10. These counters are reset on connection, and
retain their values after the remote node disconnects. Also
beginning with MySQL Cluster NDB 7.2.10, the
bytes_send and
bytes_received counters are reset on
connection as well, and so retain their values following
disconnection. (Previously, the values in these columns were
reset on disconnection.) (Bug #15935206)
Assume you have a 5-node cluster consisting of 2 data nodes, 2
SQL nodes, and 1 management node, as shown in the output of the
SHOW command in the
ndb_mgm client:
ndb_mgm> SHOW
Connected to Management Server at: localhost:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=1 @10.100.10.1 (5.5.48-ndb-7.2.24, Nodegroup: 0, *)
id=2 @10.100.10.2 (5.5.48-ndb-7.2.24, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=10 @10.100.10.10 (5.5.48-ndb-7.2.24)
[mysqld(API)] 2 node(s)
id=20 @10.100.10.20 (5.5.48-ndb-7.2.24)
id=21 @10.100.10.21 (5.5.48-ndb-7.2.24)
There are 10 rows in the transporters
table—5 for the first data node, and 5 for the
second—assuming that all data nodes are running, as shown
here:
mysql>SELECT node_id, remote_node_id, status->FROM ndbinfo.transporters;+---------+----------------+---------------+ | node_id | remote_node_id | status | +---------+----------------+---------------+ | 1 | 1 | DISCONNECTED | | 1 | 2 | CONNECTED | | 1 | 10 | CONNECTED | | 1 | 20 | CONNECTED | | 1 | 21 | CONNECTED | | 2 | 1 | CONNECTED | | 2 | 2 | DISCONNECTED | | 2 | 10 | CONNECTED | | 2 | 20 | CONNECTED | | 2 | 21 | CONNECTED | +---------+----------------+---------------+ 10 rows in set (0.04 sec)
If you shut down one of the data nodes in this cluster using the
command 2 STOP in the
ndb_mgm client, then repeat the previous
query (again using the mysql client), this
table now shows only 5 rows—1 row for each connection from
the remaining management node to another node, including both
itself and the data node that is currently offline—and
displays CONNECTING for the status of each
remaining connection to the data node that is currently offline,
as shown here:
mysql>SELECT node_id, remote_node_id, status->FROM ndbinfo.transporters;+---------+----------------+---------------+ | node_id | remote_node_id | status | +---------+----------------+---------------+ | 1 | 1 | DISCONNECTED | | 1 | 2 | CONNECTING | | 1 | 10 | CONNECTED | | 1 | 20 | CONNECTED | | 1 | 21 | CONNECTED | +---------+----------------+---------------+ 5 rows in set (0.02 sec)
This section discusses security considerations to take into account when setting up and running MySQL Cluster.
Topics covered in this section include the following:
MySQL Cluster and network security issues
Configuration issues relating to running MySQL Cluster securely
MySQL Cluster and the MySQL privilege system
MySQL standard security procedures as applicable to MySQL Cluster
In this section, we discuss basic network security issues as they relate to MySQL Cluster. It is extremely important to remember that MySQL Cluster “out of the box” is not secure; you or your network administrator must take the proper steps to ensure that your cluster cannot be compromised over the network.
Cluster communication protocols are inherently insecure, and no encryption or similar security measures are used in communications between nodes in the cluster. Because network speed and latency have a direct impact on the cluster's efficiency, it is also not advisable to employ SSL or other encryption to network connections between nodes, as such schemes will effectively slow communications.
It is also true that no authentication is used for controlling API node access to a MySQL Cluster. As with encryption, the overhead of imposing authentication requirements would have an adverse impact on Cluster performance.
In addition, there is no checking of the source IP address for either of the following when accessing the cluster:
SQL or API nodes using “free slots” created by empty
[mysqld]or[api]sections in theconfig.inifileThis means that, if there are any empty
[mysqld]or[api]sections in theconfig.inifile, then any API nodes (including SQL nodes) that know the management server's host name (or IP address) and port can connect to the cluster and access its data without restriction. (See Section 18.5.11.2, “MySQL Cluster and MySQL Privileges”, for more information about this and related issues.)NoteYou can exercise some control over SQL and API node access to the cluster by specifying a
HostNameparameter for all[mysqld]and[api]sections in theconfig.inifile. However, this also means that, should you wish to connect an API node to the cluster from a previously unused host, you need to add an[api]section containing its host name to theconfig.inifile.More information is available elsewhere in this chapter about the
HostNameparameter. Also see Section 18.3.1, “Quick Test Setup of MySQL Cluster”, for configuration examples usingHostNamewith API nodes.Any ndb_mgm client
This means that any cluster management client that is given the management server's host name (or IP address) and port (if not the standard port) can connect to the cluster and execute any management client command. This includes commands such as
ALL STOPandSHUTDOWN.
For these reasons, it is necessary to protect the cluster on the network level. The safest network configuration for Cluster is one which isolates connections between Cluster nodes from any other network communications. This can be accomplished by any of the following methods:
Keeping Cluster nodes on a network that is physically separate from any public networks. This option is the most dependable; however, it is the most expensive to implement.
We show an example of a MySQL Cluster setup using such a physically segregated network here:
This setup has two networks, one private (solid box) for the Cluster management servers and data nodes, and one public (dotted box) where the SQL nodes reside. (We show the management and data nodes connected using a gigabit switch since this provides the best performance.) Both networks are protected from the outside by a hardware firewall, sometimes also known as a network-based firewall.
This network setup is safest because no packets can reach the cluster's management or data nodes from outside the network—and none of the cluster's internal communications can reach the outside—without going through the SQL nodes, as long as the SQL nodes do not permit any packets to be forwarded. This means, of course, that all SQL nodes must be secured against hacking attempts.
ImportantWith regard to potential security vulnerabilities, an SQL node is no different from any other MySQL server. See Section 6.1.3, “Making MySQL Secure Against Attackers”, for a description of techniques you can use to secure MySQL servers.
Using one or more software firewalls (also known as host-based firewalls) to control which packets pass through to the cluster from portions of the network that do not require access to it. In this type of setup, a software firewall must be installed on every host in the cluster which might otherwise be accessible from outside the local network.
The host-based option is the least expensive to implement, but relies purely on software to provide protection and so is the most difficult to keep secure.
This type of network setup for MySQL Cluster is illustrated here:
Using this type of network setup means that there are two zones of MySQL Cluster hosts. Each cluster host must be able to communicate with all of the other machines in the cluster, but only those hosting SQL nodes (dotted box) can be permitted to have any contact with the outside, while those in the zone containing the data nodes and management nodes (solid box) must be isolated from any machines that are not part of the cluster. Applications using the cluster and user of those applications must not be permitted to have direct access to the management and data node hosts.
To accomplish this, you must set up software firewalls that limit the traffic to the type or types shown in the following table, according to the type of node that is running on each cluster host computer:
Type of Node to be Accessed Traffic to Permit SQL or API node It originates from the IP address of a management or data node (using any TCP or UDP port).
It originates from within the network in which the cluster resides and is on the port that your application is using.
Data node or Management node It originates from the IP address of a management or data node (using any TCP or UDP port).
It originates from the IP address of an SQL or API node.
Any traffic other than that shown in the table for a given node type should be denied.
The specifics of configuring a firewall vary from firewall application to firewall application, and are beyond the scope of this Manual. iptables is a very common and reliable firewall application, which is often used with APF as a front end to make configuration easier. You can (and should) consult the documentation for the software firewall that you employ, should you choose to implement a MySQL Cluster network setup of this type, or of a “mixed” type as discussed under the next item.
It is also possible to employ a combination of the first two methods, using both hardware and software to secure the cluster—that is, using both network-based and host-based firewalls. This is between the first two schemes in terms of both security level and cost. This type of network setup keeps the cluster behind the hardware firewall, but permits incoming packets to travel beyond the router connecting all cluster hosts to reach the SQL nodes.
One possible network deployment of a MySQL Cluster using hardware and software firewalls in combination is shown here:
In this case, you can set the rules in the hardware firewall to deny any external traffic except to SQL nodes and API nodes, and then permit traffic to them only on the ports required by your application.
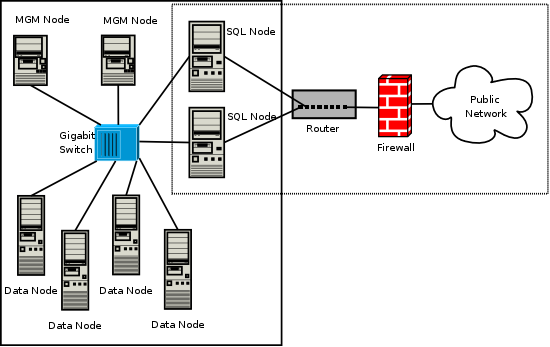
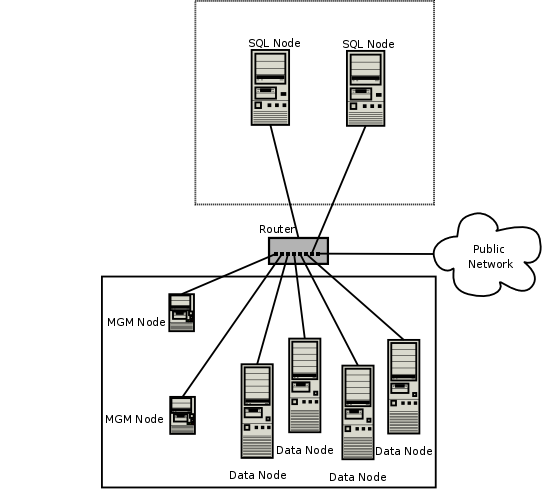
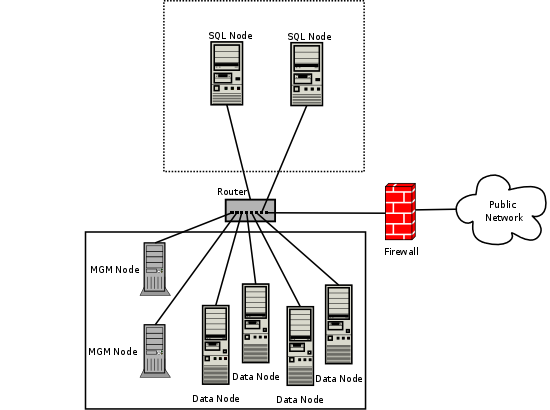
Whatever network configuration you use, remember that your objective from the viewpoint of keeping the cluster secure remains the same—to prevent any unessential traffic from reaching the cluster while ensuring the most efficient communication between the nodes in the cluster.
Because MySQL Cluster requires large numbers of ports to be open for communications between nodes, the recommended option is to use a segregated network. This represents the simplest way to prevent unwanted traffic from reaching the cluster.
If you wish to administer a MySQL Cluster remotely (that is, from outside the local network), the recommended way to do this is to use ssh or another secure login shell to access an SQL node host. From this host, you can then run the management client to access the management server safely, from within the Cluster's own local network.
Even though it is possible to do so in theory, it is not recommended to use ndb_mgm to manage a Cluster directly from outside the local network on which the Cluster is running. Since neither authentication nor encryption takes place between the management client and the management server, this represents an extremely insecure means of managing the cluster, and is almost certain to be compromised sooner or later.
In this section, we discuss how the MySQL privilege system works in relation to MySQL Cluster and the implications of this for keeping a MySQL Cluster secure.
Standard MySQL privileges apply to MySQL Cluster tables. This
includes all MySQL privilege types
(SELECT privilege,
UPDATE privilege,
DELETE privilege, and so on)
granted on the database, table, and column level. As with any
other MySQL Server, user and privilege information is stored in
the mysql system database. The SQL statements
used to grant and revoke privileges on
NDB tables, databases containing
such tables, and columns within such tables are identical in all
respects with the GRANT and
REVOKE statements used in
connection with database objects involving any (other) MySQL
storage engine. The same thing is true with respect to the
CREATE USER and
DROP USER statements.
It is important to keep in mind that, by default, the MySQL
grant tables use the MyISAM storage
engine. Because of this, those tables are not normally
duplicated or shared among MySQL servers acting as SQL nodes in
a MySQL Cluster. In other words, changes in users and their
privileges do not automatically propagate between SQL nodes by
default. In MySQL Cluster NDB 7.2 (and later), you can enable
automatic distribution of MySQL users and privileges across
MySQL Cluster SQL nodes; see
Section 18.5.14, “Distributed MySQL Privileges for MySQL Cluster”, for
details.
Conversely, because there is no way in MySQL to deny privileges
(privileges can either be revoked or not granted in the first
place, but not denied as such), there is no special protection
for NDB tables on one SQL node from
users that have privileges on another SQL node; (This is true
even if you are not using automatic distribution of user
privileges. The definitive example of this is the MySQL
root account, which can perform any action on
any database object. In combination with empty
[mysqld] or [api] sections
of the config.ini file, this account can be
especially dangerous. To understand why, consider the following
scenario:
The
config.inifile contains at least one empty[mysqld]or[api]section. This means that the MySQL Cluster management server performs no checking of the host from which a MySQL Server (or other API node) accesses the MySQL Cluster.There is no firewall, or the firewall fails to protect against access to the MySQL Cluster from hosts external to the network.
The host name or IP address of the MySQL Cluster's management server is known or can be determined from outside the network.
If these conditions are true, then anyone, anywhere can start a
MySQL Server with --ndbcluster
--ndb-connectstring=
and access this MySQL Cluster. Using the MySQL
management_hostroot account, this person can then perform
the following actions:
Execute metadata statements such as
SHOW DATABASESstatement (to obtain a list of allNDBdatabases on the server) orSHOW TABLES FROMstatement to obtain a list of allsome_ndb_databaseNDBtables in a given databaseRun any legal MySQL statements on any of the discovered tables, such as:
SELECT * FROMto read all the data from any tablesome_tableDELETE FROMto delete all the data from a tablesome_tableDESCRIBEorsome_tableSHOW CREATE TABLEto determine the table schemasome_tableUPDATEto fill a table column with “garbage” data; this could actually cause much greater damage than simply deleting all the datasome_tableSETcolumn1=some_valueMore insidious variations might include statements like these:
UPDATE
some_tableSETan_int_column=an_int_column+ 1or
UPDATE
some_tableSETa_varchar_column= REVERSE(a_varchar_column)Such malicious statements are limited only by the imagination of the attacker.
The only tables that would be safe from this sort of mayhem would be those tables that were created using storage engines other than
NDB, and so not visible to a “rogue” SQL node.A user who can log in as
rootcan also access theINFORMATION_SCHEMAdatabase and its tables, and so obtain information about databases, tables, stored routines, scheduled events, and any other database objects for which metadata is stored inINFORMATION_SCHEMA.It is also a very good idea to use different passwords for the
rootaccounts on different MySQL Cluster SQL nodes unless you are using distributed privileges.
In sum, you cannot have a safe MySQL Cluster if it is directly accessible from outside your local network.
Never leave the MySQL root account password empty. This is just as true when running MySQL as a MySQL Cluster SQL node as it is when running it as a standalone (non-Cluster) MySQL Server, and should be done as part of the MySQL installation process before configuring the MySQL Server as an SQL node in a MySQL Cluster.
Prior to MySQL Cluster NDB 7.2, you should never convert the
system tables in the mysql database to use
the NDB storage engine. There are a
number of reasons why you should not do this, but the most
important reason is this: Many of the SQL statements
that affect mysql tables storing information
about user privileges, stored routines, scheduled events, and
other database objects cease to function if these tables are
changed to use any storage engine other than
MyISAM. This is a consequence of
various MySQL Server internals. Beginning with MySQL Cluster NDB
7.2, you can use a stored procedure provided for this purpose
(see Section 18.5.14, “Distributed MySQL Privileges for MySQL Cluster”),
but you are strongly advised not to attempt convert the system
tables manually.
Otherwise, if you need to synchronize mysql
system tables between SQL nodes, you can use standard MySQL
replication to do so, or employ a script to copy table entries
between the MySQL servers.
Summary. The most important points to remember regarding the MySQL privilege system with regard to MySQL Cluster are listed here:
Users and privileges established on one SQL node do not automatically exist or take effect on other SQL nodes in the cluster. Conversely, removing a user or privilege on one SQL node in the cluster does not remove the user or privilege from any other SQL nodes.
You can distribute MySQL users and privileges among SQL nodes using the SQL script, and the stored procedures it contains, that are supplied for this purpose in the MySQL Cluster distribution.
Once a MySQL user is granted privileges on an
NDBtable from one SQL node in a MySQL Cluster, that user can “see” any data in that table regardless of the SQL node from which the data originated, even if you are not using privilege distribution.
In this section, we discuss MySQL standard security procedures as they apply to running MySQL Cluster.
In general, any standard procedure for running MySQL securely
also applies to running a MySQL Server as part of a MySQL
Cluster. First and foremost, you should always run a MySQL
Server as the mysql system user; this is no
different from running MySQL in a standard (non-Cluster)
environment. The mysql system account should
be uniquely and clearly defined. Fortunately, this is the
default behavior for a new MySQL installation. You can verify
that the mysqld process is running as the
system user mysql by using the system command
such as the one shown here:
shell> ps aux | grep mysql
root 10467 0.0 0.1 3616 1380 pts/3 S 11:53 0:00 \
/bin/sh ./mysqld_safe --ndbcluster --ndb-connectstring=localhost:1186
mysql 10512 0.2 2.5 58528 26636 pts/3 Sl 11:53 0:00 \
/usr/local/mysql/libexec/mysqld --basedir=/usr/local/mysql \
--datadir=/usr/local/mysql/var --user=mysql --ndbcluster \
--ndb-connectstring=localhost:1186 --pid-file=/usr/local/mysql/var/mothra.pid \
--log-error=/usr/local/mysql/var/mothra.err
jon 10579 0.0 0.0 2736 688 pts/0 S+ 11:54 0:00 grep mysql
If the mysqld process is running as any other
user than mysql, you should immediately shut
it down and restart it as the mysql user. If
this user does not exist on the system, the
mysql user account should be created, and
this user should be part of the mysql user
group; in this case, you should also make sure that the MySQL
data directory on this system (as set using the
--datadir option for
mysqld) is owned by the
mysql user, and that the SQL node's
my.cnf file includes
user=mysql in the [mysqld]
section. Alternatively, you can start the MySQL server process
with --user=mysql on the command
line, but it is preferable to use the
my.cnf option, since you might forget to
use the command-line option and so have
mysqld running as another user
unintentionally. The mysqld_safe startup
script forces MySQL to run as the mysql user.
Never run mysqld as the system root user. Doing so means that potentially any file on the system can be read by MySQL, and thus—should MySQL be compromised—by an attacker.
As mentioned in the previous section (see Section 18.5.11.2, “MySQL Cluster and MySQL Privileges”), you should always set a root password for the MySQL Server as soon as you have it running. You should also delete the anonymous user account that is installed by default. You can accomplish these tasks using the following statements:
shell>mysql -u rootmysql>UPDATE mysql.user->SET Password=PASSWORD('->secure_password')WHERE User='root';mysql>DELETE FROM mysql.user->WHERE User='';mysql>FLUSH PRIVILEGES;
Be very careful when executing the
DELETE statement not to omit the
WHERE clause, or you risk deleting
all MySQL users. Be sure to run the
FLUSH
PRIVILEGES statement as soon as you have modified the
mysql.user table, so that the changes take
immediate effect. Without
FLUSH
PRIVILEGES, the changes do not take effect until the
next time that the server is restarted.
Many of the MySQL Cluster utilities such as
ndb_show_tables,
ndb_desc, and
ndb_select_all also work without
authentication and can reveal table names, schemas, and data.
By default these are installed on Unix-style systems with the
permissions wxr-xr-x (755), which means
they can be executed by any user that can access the
mysql/bin directory.
See Section 18.4, “MySQL Cluster Programs”, for more information about these utilities.
It is possible to store the nonindexed columns of
NDB tables on disk, rather than in
RAM.
As part of implementing MySQL Cluster Disk Data work, a number of improvements were made in MySQL Cluster for the efficient handling of very large amounts (terabytes) of data during node recovery and restart. These include a “no-steal” algorithm for synchronizing a starting node with very large data sets. For more information, see the paper Recovery Principles of MySQL Cluster 5.1, by MySQL Cluster developers Mikael Ronström and Jonas Oreland.
MySQL Cluster Disk Data performance can be influenced by a number of configuration parameters. For information about these parameters and their effects, see MySQL Cluster Disk Data configuration parameters and MySQL Cluster Disk Data storage and GCP Stop errors
The performance of a MySQL Cluster that uses Disk Data storage can also be greatly improved by separating data node file systems from undo log files and tablespace data files, which can be done using symbolic links. For more information, see Section 18.5.12.2, “Using Symbolic Links with Disk Data Objects”.
MySQL Cluster Disk Data storage is implemented using a number of Disk Data objects. These include the following:
Tablespaces act as containers for other Disk Data objects.
Undo log files undo information required for rolling back transactions.
One or more undo log files are assigned to a log file group, which is then assigned to a tablespace.
Data files store Disk Data table data. A data file is assigned directly to a tablespace.
Undo log files and data files are actual files in the file
system of each data node; by default they are placed in
ndb_ in
the node_id_fsDataDir specified in the MySQL
Cluster config.ini file, and where
node_id is the data node's node
ID. It is possible to place these elsewhere by specifying either
an absolute or relative path as part of the filename when
creating the undo log or data file. Statements that create these
files are shown later in this section.
MySQL Cluster tablespaces and log file groups are not implemented as files.
Although not all Disk Data objects are implemented as files,
they all share the same namespace. This means that
each Disk Data object must be uniquely
named (and not merely each Disk Data object of a given type).
For example, you cannot have a tablespace and a log file group
both named dd1.
Assuming that you have already set up a MySQL Cluster with all nodes (including management and SQL nodes), the basic steps for creating a MySQL Cluster table on disk are as follows:
Create a log file group, and assign one or more undo log files to it (an undo log file is also sometimes referred to as an undofile).
NoteUndo log files are necessary only for Disk Data tables; they are not used for
NDBCLUSTERtables that are stored only in memory.Create a tablespace; assign the log file group, as well as one or more data files, to the tablespace.
Create a Disk Data table that uses this tablespace for data storage.
Each of these tasks can be accomplished using SQL statements in the mysql client or other MySQL client application, as shown in the example that follows.
We create a log file group named
lg_1usingCREATE LOGFILE GROUP. This log file group is to be made up of two undo log files, which we nameundo_1.logandundo_2.log, whose initial sizes are 16 MB and 12 MB, respectively. (The default initial size for an undo log file is 128 MB.) Optionally, you can also specify a size for the log file group's undo buffer, or permit it to assume the default value of 8 MB. In this example, we set the UNDO buffer's size at 2 MB. A log file group must be created with an undo log file; so we addundo_1.logtolg_1in thisCREATE LOGFILE GROUPstatement:CREATE LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_1.log' INITIAL_SIZE 16M UNDO_BUFFER_SIZE 2M ENGINE NDBCLUSTER;To add
undo_2.logto the log file group, use the followingALTER LOGFILE GROUPstatement:ALTER LOGFILE GROUP lg_1 ADD UNDOFILE 'undo_2.log' INITIAL_SIZE 12M ENGINE NDBCLUSTER;Some items of note:
The
.logfile extension used here is not required. We use it merely to make the log files easily recognisable.Every
CREATE LOGFILE GROUPandALTER LOGFILE GROUPstatement must include anENGINEclause. In MySQL Cluster NDB 7.2, the only permitted values for this clause areNDBCLUSTERandNDB.ImportantThere can exist at most one log file group in the same MySQL Cluster at any given time.
When you add an undo log file to a log file group using
ADD UNDOFILE ', a file with the namefilename'filenameis created in thendb_directory within thenode_id_fsDataDirof each data node in the cluster, wherenode_idis the node ID of the data node. Each undo log file is of the size specified in the SQL statement. For example, if a MySQL Cluster has 4 data nodes, then theALTER LOGFILE GROUPstatement just shown creates 4 undo log files, 1 each on in the data directory of each of the 4 data nodes; each of these files is namedundo_2.logand each file is 12 MB in size.UNDO_BUFFER_SIZEis limited by the amount of system memory available.For more information about the
CREATE LOGFILE GROUPstatement, see Section 13.1.14, “CREATE LOGFILE GROUP Syntax”. For more information aboutALTER LOGFILE GROUP, see Section 13.1.3, “ALTER LOGFILE GROUP Syntax”.
Now we can create a tablespace, which contains files to be used by MySQL Cluster Disk Data tables for storing their data. A tablespace is also associated with a particular log file group. When creating a new tablespace, you must specify the log file group which it is to use for undo logging; you must also specify a data file. You can add more data files to the tablespace after the tablespace is created; it is also possible to drop data files from a tablespace (an example of dropping data files is provided later in this section).
Assume that we wish to create a tablespace named
ts_1which useslg_1as its log file group. This tablespace is to contain two data files nameddata_1.datanddata_2.dat, whose initial sizes are 32 MB and 48 MB, respectively. (The default value forINITIAL_SIZEis 128 MB.) We can do this using two SQL statements, as shown here:CREATE TABLESPACE ts_1 ADD DATAFILE 'data_1.dat' USE LOGFILE GROUP lg_1 INITIAL_SIZE 32M ENGINE NDBCLUSTER; ALTER TABLESPACE ts_1 ADD DATAFILE 'data_2.dat' INITIAL_SIZE 48M ENGINE NDBCLUSTER;The
CREATE TABLESPACEstatement creates a tablespacets_1with the data filedata_1.dat, and associatests_1with log file grouplg_1. TheALTER TABLESPACEadds the second data file (data_2.dat).Some items of note:
As is the case with the
.logfile extension used in this example for undo log files, there is no special significance for the.datfile extension; it is used merely for easy recognition of data files.When you add a data file to a tablespace using
ADD DATAFILE ', a file with the namefilename'filenameis created in thendb_directory within thenode_id_fsDataDirof each data node in the cluster, wherenode_idis the node ID of the data node. Each data file is of the size specified in the SQL statement. For example, if a MySQL Cluster has 4 data nodes, then theALTER TABLESPACEstatement just shown creates 4 data files, 1 each in the data directory of each of the 4 data nodes; each of these files is nameddata_2.datand each file is 48 MB in size.All
CREATE TABLESPACEandALTER TABLESPACEstatements must contain anENGINEclause; only tables using the same storage engine as the tablespace can be created in the tablespace. In MySQL MySQL Cluster NDB 7.2, the only permitted values for this clause areNDBCLUSTERandNDB.For more information about the
CREATE TABLESPACEandALTER TABLESPACEstatements, see Section 13.1.18, “CREATE TABLESPACE Syntax”, and Section 13.1.8, “ALTER TABLESPACE Syntax”.
Now it is possible to create a table whose nonindexed columns are stored on disk in the tablespace
ts_1:CREATE TABLE dt_1 ( member_id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, last_name VARCHAR(50) NOT NULL, first_name VARCHAR(50) NOT NULL, dob DATE NOT NULL, joined DATE NOT NULL, INDEX(last_name, first_name) ) TABLESPACE ts_1 STORAGE DISK ENGINE NDBCLUSTER;The
TABLESPACE ... STORAGE DISKoption tells theNDBCLUSTERstorage engine to use tablespacets_1for disk data storage.NoteIt is also possible to specify whether an individual column is stored on disk or in memory by using a
STORAGEclause as part of the column's definition in aCREATE TABLEorALTER TABLEstatement.STORAGE DISKcauses the column to be stored on disk, andSTORAGE MEMORYcauses in-memory storage to be used. See Section 13.1.17, “CREATE TABLE Syntax”, for more information.Once table
ts_1has been created as shown, you can performINSERT,SELECT,UPDATE, andDELETEstatements on it just as you would with any other MySQL table.For table
dt_1as it has been defined here, only thedobandjoinedcolumns are stored on disk. This is because there are indexes on theid,last_name, andfirst_namecolumns, and so data belonging to these columns is stored in RAM. In MySQL Cluster NDB 7.2, only nonindexed columns can be held on disk; indexes and indexed column data continue to be stored in memory. This tradeoff between the use of indexes and conservation of RAM is something you must keep in mind as you design Disk Data tables.
Performance note. The performance of a cluster using Disk Data storage is greatly improved if Disk Data files are kept on a separate physical disk from the data node file system. This must be done for each data node in the cluster to derive any noticeable benefit.
You may use absolute and relative file system paths with
ADD UNDOFILE and ADD
DATAFILE. Relative paths are calculated relative to
the data node's data directory. You may also use symbolic links;
see Section 18.5.12.2, “Using Symbolic Links with Disk Data Objects”, for more
information and examples.
A log file group, a tablespace, and any Disk Data tables using these must be created in a particular order. The same is true for dropping any of these objects:
A log file group cannot be dropped as long as any tablespaces are using it.
A tablespace cannot be dropped as long as it contains any data files.
You cannot drop any data files from a tablespace as long as there remain any tables which are using the tablespace.
It is not possible to drop files created in association with a different tablespace than the one with which the files were created. (Bug #20053)
For example, to drop all the objects created so far in this section, you would use the following statements:
mysql>DROP TABLE dt_1;mysql>ALTER TABLESPACE ts_1->DROP DATAFILE 'data_2.dat'->ENGINE NDBCLUSTER;mysql>ALTER TABLESPACE ts_1->DROP DATAFILE 'data_1.dat'->ENGINE NDBCLUSTER;mysql>DROP TABLESPACE ts_1->ENGINE NDBCLUSTER;mysql>DROP LOGFILE GROUP lg_1->ENGINE NDBCLUSTER;
These statements must be performed in the order shown, except
that the two ALTER TABLESPACE ... DROP
DATAFILE statements may be executed in either order.
You can obtain information about data files used by Disk Data
tables by querying the FILES table
in the INFORMATION_SCHEMA database. An extra
“NULL row” provides additional
information about undo log files. For more information and
examples, see Section 21.29.1, “The INFORMATION_SCHEMA FILES Table”.
It is also possible to view information about allocated and free disk space for each Disk Data table or table partition using the ndb_desc utility. For more information, see Section 18.4.10, “ndb_desc — Describe NDB Tables”.
The performance of a MySQL Cluster that uses Disk Data storage
can be greatly improved by separating data node file systems
from undo log files and tablespace data files and placing these
on different disks. In early versions of MySQL Cluster, there
was no direct support for this in MySQL Cluster, but it was
possible to achieve this separation using symbolic links as
described in this section. MySQL Cluster NDB 7.2 supports the
data node configuration parameters
FileSystemPathDD,
FileSystemPathDataFiles,
and
FileSystemPathUndoFiles,
which make the use of symbolic links for this purpose
unnecessary. For more information about these parameters, see
Disk Data file system parameters.
Each data node in the cluster creates a file system in the
directory named
ndb_
under the data node's
node_id_fsDataDir as defined in
the config.ini file. In this example, we
assume that each data node host has 3 disks, aliased as
/data0, /data1, and
/data2, and that the cluster's
config.ini includes the following:
[ndbd default] DataDir= /data0
Our objective is to place all Disk Data log files in
/data1, and all Disk Data data files in
/data2, on each data node host.
In this example, we assume that the cluster's data node hosts are all using Linux operating systems. For other platforms, you may need to substitute you operating system's commands for those shown here.
To accomplish this, perform the following steps:
Under the data node file system create symbolic links pointing to the other drives:
shell>
cd /data0/ndb_2_fsshell>lsD1 D10 D11 D2 D8 D9 LCP shell>ln -s /data0 dnlogsshell>ln -s /data1 dndataYou should now have two symbolic links:
shell>
ls -l --hide=D*lrwxrwxrwx 1 user group 30 2007-03-19 13:58 dndata -> /data1 lrwxrwxrwx 1 user group 30 2007-03-19 13:59 dnlogs -> /data2We show this only for the data node with node ID 2; however, you must do this for each data node.
Now, in the mysql client, create a log file group and tablespace using the symbolic links, as shown here:
mysql>
CREATE LOGFILE GROUP lg1->ADD UNDOFILE 'dnlogs/undo1.log'->INITIAL_SIZE 150M->UNDO_BUFFER_SIZE = 1M->ENGINE=NDBCLUSTER;mysql>CREATE TABLESPACE ts1->ADD DATAFILE 'dndata/data1.log'->USE LOGFILE GROUP lg1->INITIAL_SIZE 1G->ENGINE=NDBCLUSTER;Verify that the files were created and placed correctly as shown here:
shell>
cd /data1shell>ls -ltotal 2099304 -rw-rw-r-- 1 user group 157286400 2007-03-19 14:02 undo1.dat shell>cd /data2shell>ls -ltotal 2099304 -rw-rw-r-- 1 user group 1073741824 2007-03-19 14:02 data1.datIf you are running multiple data nodes on one host, you must take care to avoid having them try to use the same space for Disk Data files. You can make this easier by creating a symbolic link in each data node file system. Suppose you are using
/data0for both data node file systems, but you wish to have the Disk Data files for both nodes on/data1. In this case, you can do something similar to what is shown here:shell>
cd /data0shell>ln -s /data1/dn2 ndb_2_fs/ddshell>ln -s /data1/dn3 ndb_3_fs/ddshell>ls -l --hide=D* ndb_2_fslrwxrwxrwx 1 user group 30 2007-03-19 14:22 dd -> /data1/dn2 shell>ls -l --hide=D* ndb_3_fslrwxrwxrwx 1 user group 30 2007-03-19 14:22 dd -> /data1/dn3Now you can create a logfile group and tablespace using the symbolic link, like this:
mysql>
CREATE LOGFILE GROUP lg1->ADD UNDOFILE 'dd/undo1.log'->INITIAL_SIZE 150M->UNDO_BUFFER_SIZE = 1M->ENGINE=NDBCLUSTER;mysql>CREATE TABLESPACE ts1->ADD DATAFILE 'dd/data1.log'->USE LOGFILE GROUP lg1->INITIAL_SIZE 1G->ENGINE=NDBCLUSTER;Verify that the files were created and placed correctly as shown here:
shell>
cd /data1shell>lsdn2 dn3 shell>ls dn2undo1.log data1.log shell>ls dn3undo1.log data1.log
The following items apply to Disk Data storage requirements:
Variable-length columns of Disk Data tables take up a fixed amount of space. For each row, this is equal to the space required to store the largest possible value for that column.
For general information about calculating these values, see Section 11.7, “Data Type Storage Requirements”.
You can obtain an estimate the amount of space available in data files and undo log files by querying the
INFORMATION_SCHEMA.FILEStable. For more information and examples, see Section 21.29.1, “The INFORMATION_SCHEMA FILES Table”.NoteThe
OPTIMIZE TABLEstatement does not have any effect on Disk Data tables.In a Disk Data table, the first 256 bytes of a
TEXTorBLOBcolumn are stored in memory; only the remainder is stored on disk.Each row in a Disk Data table uses 8 bytes in memory to point to the data stored on disk. This means that, in some cases, converting an in-memory column to the disk-based format can actually result in greater memory usage. For example, converting a
CHAR(4)column from memory-based to disk-based format increases the amount ofDataMemoryused per row from 4 to 8 bytes.
Starting the cluster with the --initial
option does not remove Disk Data files.
You must remove these manually prior to performing an initial
restart of the cluster.
Performance of Disk Data tables can be improved by minimizing
the number of disk seeks by making sure that
DiskPageBufferMemory is
of sufficient size. You can query the
diskpagebuffer table to help
determine whether the value for this parameter needs to be
increased.
This section describes how to add MySQL Cluster data nodes “online”—that is, without needing to shut down the cluster completely and restart it as part of the process.
Currently, you must add new data nodes to a MySQL Cluster as part of a new node group. In addition, it is not possible to change the number of replicas (or the number of nodes per node group) online.
This section provides general information about the behavior of and current limitations in adding MySQL Cluster nodes online.
Redistribution of Data.
The ability to add new nodes online includes a means to
reorganize NDBCLUSTER table data
and indexes so that they are distributed across all data
nodes, including the new ones, by means of the
ALTER
ONLINE TABLE ... REORGANIZE PARTITION statement.
Table reorganization of both in-memory and Disk Data tables is
supported. This redistribution does not currently include
unique indexes (only ordered indexes are redistributed). Prior
to MySQL Cluster NDB 7.2.14, BLOB table
data is also not redistributed using this method (Bug
#13714148).
The redistribution for NDBCLUSTER
tables already existing before the new data nodes were added is
not automatic, but can be accomplished using simple SQL
statements in mysql or another MySQL client
application. However, all data and indexes added to tables
created after a new node group has been added are distributed
automatically among all cluster data nodes, including those
added as part of the new node group.
Partial starts. It is possible to add a new node group without all of the new data nodes being started. It is also possible to add a new node group to a degraded cluster—that is, a cluster that is only partially started, or where one or more data nodes are not running. In the latter case, the cluster must have enough nodes running to be viable before the new node group can be added.
Effects on ongoing operations.
Normal DML operations using MySQL Cluster data are not
prevented by the creation or addition of a new node group, or
by table reorganization. However, it is not possible to
perform DDL concurrently with table reorganization—that
is, no other DDL statements can be issued while an
ALTER TABLE ...
REORGANIZE PARTITION statement is executing. In
addition, during the execution of ALTER TABLE ...
REORGANIZE PARTITION (or the execution of any other
DDL statement), it is not possible to restart cluster data
nodes.
Failure handling. Failures of data nodes during node group creation and table reorganization are handled as hown in the following table:
| Failure occurs during: | Failure occurs in: | ||
|---|---|---|---|
| “Old” data nodes | “New” data nodes | System | |
| Node group creation |
|
|
|
| Table reorganization |
|
|
|
Dropping node groups.
The ndb_mgm client supports a DROP
NODEGROUP command, but it is possible to drop a node
group only when no data nodes in the node group contain any
data. Since there is currently no way to “empty”
a specific data node or node group, this command works only
the following two cases:
After issuing
CREATE NODEGROUPin the ndb_mgm client, but before issuing anyALTER ONLINE TABLE ... REORGANIZE PARTITIONstatements in the mysql client.After dropping all
NDBCLUSTERtables usingDROP TABLE.TRUNCATE TABLEdoes not work for this purpose because the data nodes continue to store the table definitions.
In this section, we list the basic steps required to add new data nodes to a MySQL Cluster. This procedure applies whether you are using ndbd or ndbmtd binaries for the data node processes. For a more detailed example, see Section 18.5.13.3, “Adding MySQL Cluster Data Nodes Online: Detailed Example”.
Assuming that you already have a running MySQL Cluster, adding data nodes online requires the following steps:
Edit the cluster configuration
config.inifile, adding new[ndbd]sections corresponding to the nodes to be added. In the case where the cluster uses multiple management servers, these changes need to be made to allconfig.inifiles used by the management servers.You must be careful that node IDs for any new data nodes added in the
config.inifile do not overlap node IDs used by existing nodes. In the event that you have API nodes using dynamically allocated node IDs and these IDs match node IDs that you want to use for new data nodes, it is possible to force any such API nodes to “migrate”, as described later in this procedure.Perform a rolling restart of all MySQL Cluster management servers.
Perform a rolling restart of all existing MySQL Cluster data nodes. It is not necessary (or usually even desirable) to use
--initialwhen restarting the existing data nodes.If you are using API nodes with dynamically allocated IDs matching any node IDs that you wish to assign to new data nodes, you must restart all API nodes (including SQL nodes) before restarting any of the data nodes processes in this step. This causes any API nodes with node IDs that were previously not explicitly assigned to relinquish those node IDs and acquire new ones.
Perform a rolling restart of any SQL or API nodes connected to the MySQL Cluster.
Start the new data nodes.
The new data nodes may be started in any order. They can also be started concurrently, as long as they are started after the rolling restarts of all existing data nodes have been completed, and before proceeding to the next step.
Execute one or more
CREATE NODEGROUPcommands in the MySQL Cluster management client to create the new node group or node groups to which the new data nodes will belong.Redistribute the cluster's data among all data nodes, including the new ones. Normally this is done by issuing an
ALTER ONLINE TABLE ... REORGANIZE PARTITIONstatement in the mysql client for eachNDBCLUSTERtable. Exception: For tables created using theMAX_ROWSoption, this statement does not work; instead, useALTER ONLINE TABLE ... MAX_ROWS=...to reorganize such tables.NoteThis needs to be done only for tables already existing at the time the new node group is added. Data in tables created after the new node group is added is distributed automatically; however, data added to any given table
tblthat existed before the new nodes were added is not distributed using the new nodes until that table has been reorganized.Reclaim the space freed on the “old” nodes by issuing, for each
NDBCLUSTERtable, anOPTIMIZE TABLEstatement in the mysql client.
You can add all the nodes desired, then issue several
CREATE NODEGROUP commands in succession to
add the new node groups to the cluster.
In this section we provide a detailed example illustrating how to add new MySQL Cluster data nodes online, starting with a MySQL Cluster having 2 data nodes in a single node group and concluding with a cluster having 4 data nodes in 2 node groups.
Starting configuration.
For purposes of illustration, we assume a minimal
configuration, and that the cluster uses a
config.ini file containing only the
following information:
[ndbd default] DataMemory = 100M IndexMemory = 100M NoOfReplicas = 2 DataDir = /usr/local/mysql/var/mysql-cluster [ndbd] Id = 1 HostName = 192.168.0.1 [ndbd] Id = 2 HostName = 192.168.0.2 [mgm] HostName = 192.168.0.10 Id = 10 [api] Id=20 HostName = 192.168.0.20 [api] Id=21 HostName = 192.168.0.21
We have left a gap in the sequence between data node IDs and other nodes. This make it easier later to assign node IDs that are not already in use to data nodes which are newly added.
We also assume that you have already started the cluster using
the appropriate command line or my.cnf
options, and that running
SHOW in the management
client produces output similar to what is shown here:
-- NDB Cluster -- Management Client --
ndb_mgm> SHOW
Connected to Management Server at: 192.168.0.10:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=1 @192.168.0.1 (5.5.48-ndb-7.2.24, Nodegroup: 0, *)
id=2 @192.168.0.2 (5.5.48-ndb-7.2.24, Nodegroup: 0)
[ndb_mgmd(MGM)] 1 node(s)
id=10 @192.168.0.10 (5.5.48-ndb-7.2.24)
[mysqld(API)] 2 node(s)
id=20 @192.168.0.20 (5.5.48-ndb-7.2.24)
id=21 @192.168.0.21 (5.5.48-ndb-7.2.24)
Finally, we assume that the cluster contains a single
NDBCLUSTER table created as shown
here:
USE n;
CREATE TABLE ips (
id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY,
country_code CHAR(2) NOT NULL,
type CHAR(4) NOT NULL,
ip_address varchar(15) NOT NULL,
addresses BIGINT UNSIGNED DEFAULT NULL,
date BIGINT UNSIGNED DEFAULT NULL
) ENGINE NDBCLUSTER;
The memory usage and related information shown later in this section was generated after inserting approximately 50000 rows into this table.
In this example, we show the single-threaded ndbd being used for the data node processes. However—beginning with MySQL Cluster NDB 7.0.4—you can also apply this example, if you are using the multi-threaded ndbmtd by substituting ndbmtd for ndbd wherever it appears in the steps that follow. (Bug #43108)
Step 1: Update configuration file.
Open the cluster global configuration file in a text editor
and add [ndbd] sections corresponding to
the 2 new data nodes. (We give these data nodes IDs 3 and 4,
and assume that they are to be run on host machines at
addresses 192.168.0.3 and 192.168.0.4, respectively.) After
you have added the new sections, the contents of the
config.ini file should look like what is
shown here, where the additions to the file are shown in bold
type:
[ndbd default]
DataMemory = 100M
IndexMemory = 100M
NoOfReplicas = 2
DataDir = /usr/local/mysql/var/mysql-cluster
[ndbd]
Id = 1
HostName = 192.168.0.1
[ndbd]
Id = 2
HostName = 192.168.0.2
[ndbd]
Id = 3
HostName = 192.168.0.3
[ndbd]
Id = 4
HostName = 192.168.0.4
[mgm]
HostName = 192.168.0.10
Id = 10
[api]
Id=20
HostName = 192.168.0.20
[api]
Id=21
HostName = 192.168.0.21
Once you have made the necessary changes, save the file.
Step 2: Restart the management server. Restarting the cluster management server requires that you issue separate commands to stop the management server and then to start it again, as follows:
Stop the management server using the management client
STOPcommand, as shown here:ndb_mgm>
10 STOPNode 10 has shut down. Disconnecting to allow Management Server to shutdown shell>Because shutting down the management server causes the management client to terminate, you must start the management server from the system shell. For simplicity, we assume that
config.iniis in the same directory as the management server binary, but in practice, you must supply the correct path to the configuration file. You must also supply the--reloador--initialoption so that the management server reads the new configuration from the file rather than its configuration cache. If your shell's current directory is also the same as the directory where the management server binary is located, then you can invoke the management server as shown here:shell>
ndb_mgmd -f config.ini --reload2008-12-08 17:29:23 [MgmSrvr] INFO -- NDB Cluster Management Server. 5.5.48-ndb-7.2.24 2008-12-08 17:29:23 [MgmSrvr] INFO -- Reading cluster configuration from 'config.ini'
If you check the output of
SHOW in the management
client after restarting the ndb_mgm process,
you should now see something like this:
-- NDB Cluster -- Management Client --
ndb_mgm> SHOW
Connected to Management Server at: 192.168.0.10:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=1 @192.168.0.1 (5.5.48-ndb-7.2.24, Nodegroup: 0, *)
id=2 @192.168.0.2 (5.5.48-ndb-7.2.24, Nodegroup: 0)
id=3 (not connected, accepting connect from 192.168.0.3)
id=4 (not connected, accepting connect from 192.168.0.4)
[ndb_mgmd(MGM)] 1 node(s)
id=10 @192.168.0.10 (5.5.48-ndb-7.2.24)
[mysqld(API)] 2 node(s)
id=20 @192.168.0.20 (5.5.48-ndb-7.2.24)
id=21 @192.168.0.21 (5.5.48-ndb-7.2.24)
Step 3: Perform a rolling restart of the existing data nodes.
This step can be accomplished entirely within the cluster
management client using the RESTART
command, as shown here:
ndb_mgm>1 RESTARTNode 1: Node shutdown initiated Node 1: Node shutdown completed, restarting, no start. Node 1 is being restarted ndb_mgm> Node 1: Start initiated (version 7.2.24) Node 1: Started (version 7.1.37) ndb_mgm>2 RESTARTNode 2: Node shutdown initiated Node 2: Node shutdown completed, restarting, no start. Node 2 is being restarted ndb_mgm> Node 2: Start initiated (version 7.2.24) ndb_mgm> Node 2: Started (version 7.2.24)
After issuing each X
RESTARTNode before proceeding
any further.
X: Started
(version ...)
You can verify that all existing data nodes were restarted using
the updated configuration by checking the
ndbinfo.nodes table in the
mysql client.
Step 4: Perform a rolling restart of all cluster API nodes.
Shut down and restart each MySQL server acting as an SQL node
in the cluster using mysqladmin shutdown
followed by mysqld_safe (or another startup
script). This should be similar to what is shown here, where
password is the MySQL
root password for a given MySQL server
instance:
shell>mysqladmin -uroot -p081208 20:19:56 mysqld_safe mysqld from pid file /usr/local/mysql/var/tonfisk.pid ended shell>passwordshutdownmysqld_safe --ndbcluster --ndb-connectstring=192.168.0.10 &081208 20:20:06 mysqld_safe Logging to '/usr/local/mysql/var/tonfisk.err'. 081208 20:20:06 mysqld_safe Starting mysqld daemon with databases from /usr/local/mysql/var
Of course, the exact input and output depend on how and where
MySQL is installed on the system, as well as which options you
choose to start it (and whether or not some or all of these
options are specified in a my.cnf file).
Step 5: Perform an initial start of the new data nodes.
From a system shell on each of the hosts for the new data
nodes, start the data nodes as shown here, using the
--initial option:
shell> ndbd -c 192.168.0.10 --initial
Unlike the case with restarting the existing data nodes, you can start the new data nodes concurrently; you do not need to wait for one to finish starting before starting the other.
Wait until both of the new data nodes have started
before proceeding with the next step. Once the new
data nodes have started, you can see in the output of the
management client SHOW
command that they do not yet belong to any node group (as
indicated with bold type here):
ndb_mgm> SHOW
Connected to Management Server at: 192.168.0.10:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=1 @192.168.0.1 (5.5.48-ndb-7.2.24, Nodegroup: 0, *)
id=2 @192.168.0.2 (5.5.48-ndb-7.2.24, Nodegroup: 0)
id=3 @192.168.0.3 (5.5.48-ndb-7.2.24, no nodegroup)
id=4 @192.168.0.4 (5.5.48-ndb-7.2.24, no nodegroup)
[ndb_mgmd(MGM)] 1 node(s)
id=10 @192.168.0.10 (5.5.48-ndb-7.2.24)
[mysqld(API)] 2 node(s)
id=20 @192.168.0.20 (5.5.48-ndb-7.2.24)
id=21 @192.168.0.21 (5.5.48-ndb-7.2.24)
Step 6: Create a new node group.
You can do this by issuing a CREATE
NODEGROUP command in the cluster management client.
This command takes as its argument a comma-separated list of
the node IDs of the data nodes to be included in the new node
group, as shown here:
ndb_mgm> CREATE NODEGROUP 3,4
Nodegroup 1 created
By issuing SHOW again, you
can verify that data nodes 3 and 4 have joined the new node
group (again indicated in bold type):
ndb_mgm> SHOW
Connected to Management Server at: 192.168.0.10:1186
Cluster Configuration
---------------------
[ndbd(NDB)] 2 node(s)
id=1 @192.168.0.1 (5.5.48-ndb-7.2.24, Nodegroup: 0, *)
id=2 @192.168.0.2 (5.5.48-ndb-7.2.24, Nodegroup: 0)
id=3 @192.168.0.3 (5.5.48-ndb-7.2.24, Nodegroup: 1)
id=4 @192.168.0.4 (5.5.48-ndb-7.2.24, Nodegroup: 1)
[ndb_mgmd(MGM)] 1 node(s)
id=10 @192.168.0.10 (5.5.48-ndb-7.2.24)
[mysqld(API)] 2 node(s)
id=20 @192.168.0.20 (5.5.48-ndb-7.2.24)
id=21 @192.168.0.21 (5.5.48-ndb-7.2.24)
Step 7: Redistribute cluster data.
When a node group is created, existing data and indexes are
not automatically distributed to the new node group's
data nodes, as you can see by issuing the appropriate
REPORT command in the management client:
ndb_mgm> ALL REPORT MEMORY
Node 1: Data usage is 5%(177 32K pages of total 3200)
Node 1: Index usage is 0%(108 8K pages of total 12832)
Node 2: Data usage is 5%(177 32K pages of total 3200)
Node 2: Index usage is 0%(108 8K pages of total 12832)
Node 3: Data usage is 0%(0 32K pages of total 3200)
Node 3: Index usage is 0%(0 8K pages of total 12832)
Node 4: Data usage is 0%(0 32K pages of total 3200)
Node 4: Index usage is 0%(0 8K pages of total 12832)
By using ndb_desc with the
-p option, which causes the output to include
partitioning information, you can see that the table still uses
only 2 partitions (in the Per partition info
section of the output, shown here in bold text):
shell> ndb_desc -c 192.168.0.10 -d n ips -p
-- ips --
Version: 1
Fragment type: 9
K Value: 6
Min load factor: 78
Max load factor: 80
Temporary table: no
Number of attributes: 6
Number of primary keys: 1
Length of frm data: 340
Row Checksum: 1
Row GCI: 1
SingleUserMode: 0
ForceVarPart: 1
FragmentCount: 2
TableStatus: Retrieved
-- Attributes --
id Bigint PRIMARY KEY DISTRIBUTION KEY AT=FIXED ST=MEMORY AUTO_INCR
country_code Char(2;latin1_swedish_ci) NOT NULL AT=FIXED ST=MEMORY
type Char(4;latin1_swedish_ci) NOT NULL AT=FIXED ST=MEMORY
ip_address Varchar(15;latin1_swedish_ci) NOT NULL AT=SHORT_VAR ST=MEMORY
addresses Bigunsigned NULL AT=FIXED ST=MEMORY
date Bigunsigned NULL AT=FIXED ST=MEMORY
-- Indexes --
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
-- Per partition info --
Partition Row count Commit count Frag fixed memory Frag varsized memory
0 26086 26086 1572864 557056
1 26329 26329 1605632 557056
NDBT_ProgramExit: 0 - OK
You can cause the data to be redistributed among all of the data
nodes by performing, for each NDB
table, an ALTER
ONLINE TABLE ... REORGANIZE PARTITION statement in the
mysql client.
ALTER ONLINE TABLE ... REORGANIZE PARTITION
does not work on tables that were created with the
MAX_ROWS option. Instead, use
ALTER ONLINE TABLE ... MAX_ROWS=... to
reorganize such tables.
After issuing the statement ALTER ONLINE TABLE ips
REORGANIZE PARTITION, you can see using
ndb_desc that the data for this table is now
stored using 4 partitions, as shown here (with the relevant
portions of the output in bold type):
shell> ndb_desc -c 192.168.0.10 -d n ips -p
-- ips --
Version: 16777217
Fragment type: 9
K Value: 6
Min load factor: 78
Max load factor: 80
Temporary table: no
Number of attributes: 6
Number of primary keys: 1
Length of frm data: 341
Row Checksum: 1
Row GCI: 1
SingleUserMode: 0
ForceVarPart: 1
FragmentCount: 4
TableStatus: Retrieved
-- Attributes --
id Bigint PRIMARY KEY DISTRIBUTION KEY AT=FIXED ST=MEMORY AUTO_INCR
country_code Char(2;latin1_swedish_ci) NOT NULL AT=FIXED ST=MEMORY
type Char(4;latin1_swedish_ci) NOT NULL AT=FIXED ST=MEMORY
ip_address Varchar(15;latin1_swedish_ci) NOT NULL AT=SHORT_VAR ST=MEMORY
addresses Bigunsigned NULL AT=FIXED ST=MEMORY
date Bigunsigned NULL AT=FIXED ST=MEMORY
-- Indexes --
PRIMARY KEY(id) - UniqueHashIndex
PRIMARY(id) - OrderedIndex
-- Per partition info --
Partition Row count Commit count Frag fixed memory Frag varsized memory
0 12981 52296 1572864 557056
1 13236 52515 1605632 557056
2 13105 13105 819200 294912
3 13093 13093 819200 294912
NDBT_ProgramExit: 0 - OK
Normally, ALTER
[ONLINE] TABLE is used with a list of
partition identifiers and a set of partition definitions to
create a new partitioning scheme for a table that has already
been explicitly partitioned. Its use here to redistribute data
onto a new MySQL Cluster node group is an exception in this
regard; when used in this way, only the name of the table is
used following the table_name
REORGANIZE PARTITIONTABLE keyword, and no
other keywords or identifiers follow REORGANIZE
PARTITION.
For more information, see Section 13.1.7, “ALTER TABLE Syntax”.
In addition, for each table, the
ALTER ONLINE
TABLE statement should be followed by an
OPTIMIZE TABLE to reclaim wasted
space. You can obtain a list of all
NDBCLUSTER tables using the
following query against the
INFORMATION_SCHEMA.TABLES table:
SELECT TABLE_SCHEMA, TABLE_NAME
FROM INFORMATION_SCHEMA.TABLES
WHERE ENGINE = 'NDBCLUSTER';
The INFORMATION_SCHEMA.TABLES.ENGINE value
for a MySQL Cluster table is always
NDBCLUSTER, regardless of whether
the CREATE TABLE statement used to create
the table (or ALTER TABLE
statement used to convert an existing table from a different
storage engine) used NDB or
NDBCLUSTER in its
ENGINE option.
You can see after performing these statements in the output of
ALL REPORT MEMORY that the data and indexes
are now redistributed between all cluster data nodes, as shown
here:
ndb_mgm> ALL REPORT MEMORY
Node 1: Data usage is 5%(176 32K pages of total 3200)
Node 1: Index usage is 0%(76 8K pages of total 12832)
Node 2: Data usage is 5%(176 32K pages of total 3200)
Node 2: Index usage is 0%(76 8K pages of total 12832)
Node 3: Data usage is 2%(80 32K pages of total 3200)
Node 3: Index usage is 0%(51 8K pages of total 12832)
Node 4: Data usage is 2%(80 32K pages of total 3200)
Node 4: Index usage is 0%(50 8K pages of total 12832)
Since only one DDL operation on
NDBCLUSTER tables can be executed
at a time, you must wait for each
ALTER ONLINE
TABLE ... REORGANIZE PARTITION statement to finish
before issuing the next one.
It is not necessary to issue
ALTER ONLINE TABLE
... REORGANIZE PARTITION statements for
NDBCLUSTER tables created
after the new data nodes have been added;
data added to such tables is distributed among all data nodes
automatically. However, in
NDBCLUSTER tables that existed
prior to the addition of the new nodes,
neither existing nor new data is distributed using the new nodes
until these tables have been reorganized using
ALTER ONLINE TABLE
... REORGANIZE PARTITION.
Alternative procedure, without rolling restart. It is possible to avoid the need for a rolling restart by configuring the extra data nodes, but not starting them, when first starting the cluster. We assume, as before, that you wish to start with two data nodes—nodes 1 and 2—in one node group and later to expand the cluster to four data nodes, by adding a second node group consisting of nodes 3 and 4:
[ndbd default] DataMemory = 100M IndexMemory = 100M NoOfReplicas = 2 DataDir = /usr/local/mysql/var/mysql-cluster [ndbd] Id = 1 HostName = 192.168.0.1 [ndbd] Id = 2 HostName = 192.168.0.2 [ndbd] Id = 3 HostName = 192.168.0.3 Nodegroup = 65536 [ndbd] Id = 4 HostName = 192.168.0.4 Nodegroup = 65536 [mgm] HostName = 192.168.0.10 Id = 10 [api] Id=20 HostName = 192.168.0.20 [api] Id=21 HostName = 192.168.0.21
In MySQL Cluster NDB 7.2, it is no longer necessary to perform
the initial start of the cluster using
--nowait-nodes option with
ndbd or ndbmtd as it was
in some earlier versions of MySQL Cluster.
The data nodes to be brought online at a later time (nodes 3 and
4) can be configured with
NodeGroup = 65536, in
which case nodes 1 and 2 can each be started as shown here:
shell> ndbd -c 192.168.0.10 --initial
The data nodes configured with
NodeGroup = 65536 are
treated by the management server as though you had started nodes
1 and 2 using --nowait-nodes=3,4
after waiting for a period of time determined by the setting for
the
StartNoNodeGroupTimeout
data node configuration parameter. By default, this is 15
seconds (15000 milliseconds).
StartNoNodegroupTimeout
must be the same for all data nodes in the cluster; for this
reason, you should always set it in the [ndbd
default] section of the
config.ini file, rather than for
individual data nodes.
When you are ready to add the second node group, you need only perform the following additional steps:
Start data nodes 3 and 4, invoking the data node process once for each new node:
shell>
ndbd -c 192.168.0.10 --initialIssue the appropriate
CREATE NODEGROUPcommand in the management client:ndb_mgm>
CREATE NODEGROUP 3,4In the mysql client, issue
ALTER ONLINE TABLE ... REORGANIZE PARTITIONandOPTIMIZE TABLEstatements for each existingNDBCLUSTERtable. (As noted elsewhere in this section, existing MySQL Cluster tables cannot use the new nodes for data distribution until this has been done.)
MySQL Cluster NDB 7.2 introduces support for distributing MySQL users and privileges across all SQL nodes in a MySQL Cluster. This support is not enabled by default; you should follow the procedure outlined in this section in order to do so.
Normally, each MySQL server's user privilege tables in the
mysql database must use the
MyISAM storage engine, which means
that a user account and its associated privileges created on one
SQL node are not available on the cluster's other SQL nodes.
In MySQL Cluster NDB 7.2 and later, an SQL file
ndb_dist_priv.sql is provided with the MySQL
Cluster distribution. This file can be found in the
share directory in the MySQL installation
directory.
The first step in enabling distributed privileges is to load this
script into a MySQL Server that functions as an SQL node (which we
refer to after this as the
target SQL node or MySQL
Server). You can do this by executing the following command from
the system shell on the target SQL node after changing to its
MySQL installation directory (where
options stands for any additional
options needed to connect to this SQL node):
shell> mysql options -uroot < share/ndb_dist_priv.sql
Importing ndb_dist_priv.sql creates a number
of stored routines (six stored procedures and one stored function)
in the mysql database on the target SQL node.
After connecting to the SQL node in the mysql
client (as the MySQL root user), you can verify
that these were created as shown here:
mysql>SELECT ROUTINE_NAME, ROUTINE_SCHEMA, ROUTINE_TYPE->FROM INFORMATION_SCHEMA.ROUTINES->WHERE ROUTINE_NAME LIKE 'mysql_cluster%'->ORDER BY ROUTINE_TYPE; +---------------------------------------------+----------------+--------------+ | ROUTINE_NAME | ROUTINE_SCHEMA | ROUTINE_TYPE | +---------------------------------------------+----------------+--------------+ | mysql_cluster_privileges_are_distributed | mysql | FUNCTION | | mysql_cluster_backup_privileges | mysql | PROCEDURE | | mysql_cluster_move_grant_tables | mysql | PROCEDURE | | mysql_cluster_move_privileges | mysql | PROCEDURE | | mysql_cluster_restore_local_privileges | mysql | PROCEDURE | | mysql_cluster_restore_privileges | mysql | PROCEDURE | | mysql_cluster_restore_privileges_from_local | mysql | PROCEDURE | +---------------------------------------------+----------------+--------------+ 7 rows in set (0.01 sec)
The stored procedure named
mysql_cluster_move_privileges creates backup
copies of the existing privilege tables, then converts them to
NDB.
mysql_cluster_move_privileges performs the
backup and conversion in two steps. The first step is to call
mysql_cluster_backup_privileges, which creates
two sets of copies in the mysql database:
A set of local copies that use the
MyISAMstorage engine. Their names are generated by adding the suffix_backupto the original privilege table names.A set of distributed copies that use the
NDBCLUSTERstorage engine. These tables are named by prefixingndb_and appending_backupto the names of the original tables.
After the copies are created,
mysql_cluster_move_privileges invokes
mysql_cluster_move_grant_tables, which contains
the ALTER TABLE ...
ENGINE = NDB statements that convert the mysql system
tables to NDB.
Normally, you should not invoke either
mysql_cluster_backup_privileges or
mysql_cluster_move_grant_tables manually; these
stored procedures are intended only for use by
mysql_cluster_move_privileges.
Although the original privilege tables are backed up automatically, it is always a good idea to create backups manually of the existing privilege tables on all affected SQL nodes before proceeding. You can do this using mysqldump in a manner similar to what is shown here:
shell> mysqldumpoptions-uroot \ mysql host user db tables_priv columns_priv procs_priv proxies_priv >backup_file
To perform the conversion, you must be connected to the target SQL
node using the mysql client (again, as the
MySQL root user). Invoke the stored procedure
like this:
mysql> CALL mysql.mysql_cluster_move_privileges();
Query OK, 0 rows affected (22.32 sec)
Depending on the number of rows in the privilege tables, this
procedure may take some time to execute. If some of the privilege
tables are empty, you may see one or more No data -
zero rows fetched, selected, or processed warnings
when mysql_cluster_move_privileges returns. In
such cases, the warnings may be safely ignored. To verify that the
conversion was successful, you can use the stored function
mysql_cluster_privileges_are_distributed as
shown here:
mysql>SELECT CONCAT(->'Conversion ',->IF(mysql.mysql_cluster_privileges_are_distributed(), 'succeeded', 'failed'),->'.')->AS Result;+-----------------------+ | Result | +-----------------------+ | Conversion succeeded. | +-----------------------+ 1 row in set (0.00 sec)
mysql_cluster_privileges_are_distributed checks
for the existence of the distributed privilege tables and returns
1 if all of the privilege tables are
distributed; otherwise, it returns 0.
You can verify that the backups have been created using a query such as this one:
mysql>SELECT TABLE_NAME, ENGINE FROM INFORMATION_SCHEMA.TABLES->WHERE TABLE_SCHEMA = 'mysql' AND TABLE_NAME LIKE '%backup'->ORDER BY ENGINE;+-------------------------+------------+ | TABLE_NAME | ENGINE | +-------------------------+------------+ | host_backup | MyISAM | | db_backup | MyISAM | | columns_priv_backup | MyISAM | | user_backup | MyISAM | | tables_priv_backup | MyISAM | | proxies_priv_backup | MyISAM | | procs_priv_backup | MyISAM | | ndb_user_backup | ndbcluster | | ndb_tables_priv_backup | ndbcluster | | ndb_proxies_priv_backup | ndbcluster | | ndb_procs_priv_backup | ndbcluster | | ndb_host_backup | ndbcluster | | ndb_db_backup | ndbcluster | | ndb_columns_priv_backup | ndbcluster | +-------------------------+------------+ 14 rows in set (0.00 sec)
Once the conversion to distributed privileges has been made, any time a MySQL user account is created, dropped, or has its privileges updated on any SQL node, the changes take effect immediately on all other MySQL servers attached to the cluster. Once privileges are distributed, any new MySQL Servers that connect to the cluster automatically participate in the distribution.
For clients connected to SQL nodes at the time that
mysql_cluster_move_privileges is executed,
you may need to execute
FLUSH
PRIVILEGES on those SQL nodes, or to disconnect and
then reconnect the clients, in order for those clients to be
able to see the changes in privileges.
All MySQL user privileges are distributed across all connected MySQL Servers. This includes any privileges associated with views and stored routines, even though distribution of views and stored routines themselves is not currently supported.
In the event that an SQL node becomes disconnected from the
cluster while mysql_cluster_move_privileges is
running, you must drop its privilege tables after reconnecting to
the cluster, using a statement such as
DROP TABLE IF EXISTS
mysql.user mysql.db mysql.tables_priv mysql.columns_priv
mysql.procs_priv. This causes the SQL node to use the
shared privilege tables rather than its own local versions of
them. This is not needed when connecting a new SQL node to the
cluster for the first time.
In the event of an initial restart of the entire cluster (all data
nodes shut down, then started again with
--initial), the shared privilege
tables are lost. If this happens, you can restore them using the
original target SQL node either from the backups made by
mysql_cluster_move_privileges or from a dump
file created with mysqldump. If you need to use
a new MySQL Server to perform the restoration, you should start it
with --skip-grant-tables when
connecting to the cluster for the first time; after this, you can
restore the privilege tables locally, then distribute them again
using mysql_cluster_move_privileges. After
restoring and distributing the tables, you should restart this
MySQL Server without the
--skip-grant-tables option.
You can also restore the distributed tables using
ndb_restore
--restore-privilege-tables
from a backup made using START BACKUP in the
ndb_mgm client. (The
MyISAM tables created by
mysql_cluster_move_privileges are not backed up
by the START BACKUP command.)
ndb_restore does not restore the privilege
tables by default; the
--restore-privilege-tables
option causes it to do so.
You can restore the SQL node's local privileges using either
of two procedures.
mysql_cluster_restore_privileges works as
follows:
If copies of the
mysql.ndb_*_backuptables are available, attempt to restore the system tables from these.Otherwise, attempt to restore the system tables from the local backups named
*_backup(without thendb_prefix).
The other procedure, named
mysql_cluster_restore_local_privileges,
restores the system tables from the local backups only, without
checking the ndb_* backups.
The system tables re-created by
mysql_cluster_restore_privileges or
mysql_cluster_restore_local_privileges use the
MySQL server default storage engine; they are not shared or
distributed in any way, and do not use MySQL Cluster's
NDB storage engine.
The additional stored procedure
mysql_cluster_restore_privileges_from_local is
intended for the use of
mysql_cluster_restore_privileges and
mysql_cluster_restore_local_privileges. It
should not be invoked directly.
Applications that access MySQL Cluster data directly, including
NDB API and ClusterJ applications, are not subject to the MySQL
privilege system. This means that, once you have distributed the
grant tables, they can be freely accessed by such applications,
just as they can any other NDB
tables. In particular, you should keep in mind that
NDB API and ClusterJ applications can read and write
user names, host names, password hashes, and any other contents
of the distributed grant tables without any
restrictions.
A number of types of statistical counters relating to actions
performed by or affecting Ndb
objects are available. Such actions include starting and closing
(or aborting) transactions; primary key and unique key operations;
table, range, and pruned scans; threads blocked while waiting for
the completion of various operations; and data and events sent and
received by NDBCLUSTER. The counters are
incremented inside the NDB kernel whenever NDB API calls are made
or data is sent to or received by the data nodes.
mysqld exposes these counters as system status
variables; their values can be read in the output of
SHOW STATUS, or by querying the
INFORMATION_SCHEMA.SESSION_STATUS
or
INFORMATION_SCHEMA.GLOBAL_STATUS
table. By comparing the values before and after statements
operating on NDB tables, you can
observe the corresponding actions taken on the API level, and thus
the cost of performing the statement.
You can list all of these status variables using the following
SHOW STATUS statement:
mysql> SHOW STATUS LIKE 'ndb_api%';
+--------------------------------------------+----------+
| Variable_name | Value |
+--------------------------------------------+----------+
| Ndb_api_wait_exec_complete_count_session | 0 |
| Ndb_api_wait_scan_result_count_session | 0 |
| Ndb_api_wait_meta_request_count_session | 0 |
| Ndb_api_wait_nanos_count_session | 0 |
| Ndb_api_bytes_sent_count_session | 0 |
| Ndb_api_bytes_received_count_session | 0 |
| Ndb_api_trans_start_count_session | 0 |
| Ndb_api_trans_commit_count_session | 0 |
| Ndb_api_trans_abort_count_session | 0 |
| Ndb_api_trans_close_count_session | 0 |
| Ndb_api_pk_op_count_session | 0 |
| Ndb_api_uk_op_count_session | 0 |
| Ndb_api_table_scan_count_session | 0 |
| Ndb_api_range_scan_count_session | 0 |
| Ndb_api_pruned_scan_count_session | 0 |
| Ndb_api_scan_batch_count_session | 0 |
| Ndb_api_read_row_count_session | 0 |
| Ndb_api_trans_local_read_row_count_session | 0 |
| Ndb_api_event_data_count_injector | 0 |
| Ndb_api_event_nondata_count_injector | 0 |
| Ndb_api_event_bytes_count_injector | 0 |
| Ndb_api_wait_exec_complete_count_slave | 0 |
| Ndb_api_wait_scan_result_count_slave | 0 |
| Ndb_api_wait_meta_request_count_slave | 0 |
| Ndb_api_wait_nanos_count_slave | 0 |
| Ndb_api_bytes_sent_count_slave | 0 |
| Ndb_api_bytes_received_count_slave | 0 |
| Ndb_api_trans_start_count_slave | 0 |
| Ndb_api_trans_commit_count_slave | 0 |
| Ndb_api_trans_abort_count_slave | 0 |
| Ndb_api_trans_close_count_slave | 0 |
| Ndb_api_pk_op_count_slave | 0 |
| Ndb_api_uk_op_count_slave | 0 |
| Ndb_api_table_scan_count_slave | 0 |
| Ndb_api_range_scan_count_slave | 0 |
| Ndb_api_pruned_scan_count_slave | 0 |
| Ndb_api_scan_batch_count_slave | 0 |
| Ndb_api_read_row_count_slave | 0 |
| Ndb_api_trans_local_read_row_count_slave | 0 |
| Ndb_api_wait_exec_complete_count | 2 |
| Ndb_api_wait_scan_result_count | 3 |
| Ndb_api_wait_meta_request_count | 27 |
| Ndb_api_wait_nanos_count | 45612023 |
| Ndb_api_bytes_sent_count | 992 |
| Ndb_api_bytes_received_count | 9640 |
| Ndb_api_trans_start_count | 2 |
| Ndb_api_trans_commit_count | 1 |
| Ndb_api_trans_abort_count | 0 |
| Ndb_api_trans_close_count | 2 |
| Ndb_api_pk_op_count | 1 |
| Ndb_api_uk_op_count | 0 |
| Ndb_api_table_scan_count | 1 |
| Ndb_api_range_scan_count | 0 |
| Ndb_api_pruned_scan_count | 0 |
| Ndb_api_scan_batch_count | 0 |
| Ndb_api_read_row_count | 1 |
| Ndb_api_trans_local_read_row_count | 1 |
| Ndb_api_event_data_count | 0 |
| Ndb_api_event_nondata_count | 0 |
| Ndb_api_event_bytes_count | 0 |
+--------------------------------------------+----------+
60 rows in set (0.02 sec)
These status variables are also available from the
SESSION_STATUS and
GLOBAL_STATUS
tables of the INFORMATION_SCHEMA database, as
shown here:
mysql>SELECT * FROM INFORMATION_SCHEMA.SESSION_STATUS->WHERE VARIABLE_NAME LIKE 'ndb_api%';+--------------------------------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +--------------------------------------------+----------------+ | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SESSION | 2 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SESSION | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SESSION | 1 | | NDB_API_WAIT_NANOS_COUNT_SESSION | 8144375 | | NDB_API_BYTES_SENT_COUNT_SESSION | 68 | | NDB_API_BYTES_RECEIVED_COUNT_SESSION | 84 | | NDB_API_TRANS_START_COUNT_SESSION | 1 | | NDB_API_TRANS_COMMIT_COUNT_SESSION | 1 | | NDB_API_TRANS_ABORT_COUNT_SESSION | 0 | | NDB_API_TRANS_CLOSE_COUNT_SESSION | 1 | | NDB_API_PK_OP_COUNT_SESSION | 1 | | NDB_API_UK_OP_COUNT_SESSION | 0 | | NDB_API_TABLE_SCAN_COUNT_SESSION | 0 | | NDB_API_RANGE_SCAN_COUNT_SESSION | 0 | | NDB_API_PRUNED_SCAN_COUNT_SESSION | 0 | | NDB_API_SCAN_BATCH_COUNT_SESSION | 0 | | NDB_API_READ_ROW_COUNT_SESSION | 1 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SESSION | 1 | | NDB_API_EVENT_DATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_NONDATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_BYTES_COUNT_INJECTOR | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SLAVE | 0 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SLAVE | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SLAVE | 0 | | NDB_API_WAIT_NANOS_COUNT_SLAVE | 0 | | NDB_API_BYTES_SENT_COUNT_SLAVE | 0 | | NDB_API_BYTES_RECEIVED_COUNT_SLAVE | 0 | | NDB_API_TRANS_START_COUNT_SLAVE | 0 | | NDB_API_TRANS_COMMIT_COUNT_SLAVE | 0 | | NDB_API_TRANS_ABORT_COUNT_SLAVE | 0 | | NDB_API_TRANS_CLOSE_COUNT_SLAVE | 0 | | NDB_API_PK_OP_COUNT_SLAVE | 0 | | NDB_API_UK_OP_COUNT_SLAVE | 0 | | NDB_API_TABLE_SCAN_COUNT_SLAVE | 0 | | NDB_API_RANGE_SCAN_COUNT_SLAVE | 0 | | NDB_API_PRUNED_SCAN_COUNT_SLAVE | 0 | | NDB_API_SCAN_BATCH_COUNT_SLAVE | 0 | | NDB_API_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT | 4 | | NDB_API_WAIT_SCAN_RESULT_COUNT | 3 | | NDB_API_WAIT_META_REQUEST_COUNT | 28 | | NDB_API_WAIT_NANOS_COUNT | 53756398 | | NDB_API_BYTES_SENT_COUNT | 1060 | | NDB_API_BYTES_RECEIVED_COUNT | 9724 | | NDB_API_TRANS_START_COUNT | 3 | | NDB_API_TRANS_COMMIT_COUNT | 2 | | NDB_API_TRANS_ABORT_COUNT | 0 | | NDB_API_TRANS_CLOSE_COUNT | 3 | | NDB_API_PK_OP_COUNT | 2 | | NDB_API_UK_OP_COUNT | 0 | | NDB_API_TABLE_SCAN_COUNT | 1 | | NDB_API_RANGE_SCAN_COUNT | 0 | | NDB_API_PRUNED_SCAN_COUNT | 0 | | NDB_API_SCAN_BATCH_COUNT | 0 | | NDB_API_READ_ROW_COUNT | 2 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT | 2 | | NDB_API_EVENT_DATA_COUNT | 0 | | NDB_API_EVENT_NONDATA_COUNT | 0 | | NDB_API_EVENT_BYTES_COUNT | 0 | +--------------------------------------------+----------------+ 60 rows in set (0.00 sec) mysql>SELECT * FROM INFORMATION_SCHEMA.GLOBAL_STATUS->WHERE VARIABLE_NAME LIKE 'ndb_api%';+--------------------------------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +--------------------------------------------+----------------+ | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SESSION | 2 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SESSION | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SESSION | 1 | | NDB_API_WAIT_NANOS_COUNT_SESSION | 8144375 | | NDB_API_BYTES_SENT_COUNT_SESSION | 68 | | NDB_API_BYTES_RECEIVED_COUNT_SESSION | 84 | | NDB_API_TRANS_START_COUNT_SESSION | 1 | | NDB_API_TRANS_COMMIT_COUNT_SESSION | 1 | | NDB_API_TRANS_ABORT_COUNT_SESSION | 0 | | NDB_API_TRANS_CLOSE_COUNT_SESSION | 1 | | NDB_API_PK_OP_COUNT_SESSION | 1 | | NDB_API_UK_OP_COUNT_SESSION | 0 | | NDB_API_TABLE_SCAN_COUNT_SESSION | 0 | | NDB_API_RANGE_SCAN_COUNT_SESSION | 0 | | NDB_API_PRUNED_SCAN_COUNT_SESSION | 0 | | NDB_API_SCAN_BATCH_COUNT_SESSION | 0 | | NDB_API_READ_ROW_COUNT_SESSION | 1 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SESSION | 1 | | NDB_API_EVENT_DATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_NONDATA_COUNT_INJECTOR | 0 | | NDB_API_EVENT_BYTES_COUNT_INJECTOR | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT_SLAVE | 0 | | NDB_API_WAIT_SCAN_RESULT_COUNT_SLAVE | 0 | | NDB_API_WAIT_META_REQUEST_COUNT_SLAVE | 0 | | NDB_API_WAIT_NANOS_COUNT_SLAVE | 0 | | NDB_API_BYTES_SENT_COUNT_SLAVE | 0 | | NDB_API_BYTES_RECEIVED_COUNT_SLAVE | 0 | | NDB_API_TRANS_START_COUNT_SLAVE | 0 | | NDB_API_TRANS_COMMIT_COUNT_SLAVE | 0 | | NDB_API_TRANS_ABORT_COUNT_SLAVE | 0 | | NDB_API_TRANS_CLOSE_COUNT_SLAVE | 0 | | NDB_API_PK_OP_COUNT_SLAVE | 0 | | NDB_API_UK_OP_COUNT_SLAVE | 0 | | NDB_API_TABLE_SCAN_COUNT_SLAVE | 0 | | NDB_API_RANGE_SCAN_COUNT_SLAVE | 0 | | NDB_API_PRUNED_SCAN_COUNT_SLAVE | 0 | | NDB_API_SCAN_BATCH_COUNT_SLAVE | 0 | | NDB_API_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT_SLAVE | 0 | | NDB_API_WAIT_EXEC_COMPLETE_COUNT | 4 | | NDB_API_WAIT_SCAN_RESULT_COUNT | 3 | | NDB_API_WAIT_META_REQUEST_COUNT | 28 | | NDB_API_WAIT_NANOS_COUNT | 53756398 | | NDB_API_BYTES_SENT_COUNT | 1060 | | NDB_API_BYTES_RECEIVED_COUNT | 9724 | | NDB_API_TRANS_START_COUNT | 3 | | NDB_API_TRANS_COMMIT_COUNT | 2 | | NDB_API_TRANS_ABORT_COUNT | 0 | | NDB_API_TRANS_CLOSE_COUNT | 3 | | NDB_API_PK_OP_COUNT | 2 | | NDB_API_UK_OP_COUNT | 0 | | NDB_API_TABLE_SCAN_COUNT | 1 | | NDB_API_RANGE_SCAN_COUNT | 0 | | NDB_API_PRUNED_SCAN_COUNT | 0 | | NDB_API_SCAN_BATCH_COUNT | 0 | | NDB_API_READ_ROW_COUNT | 2 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT | 2 | | NDB_API_EVENT_DATA_COUNT | 0 | | NDB_API_EVENT_NONDATA_COUNT | 0 | | NDB_API_EVENT_BYTES_COUNT | 0 | +--------------------------------------------+----------------+ 60 rows in set (0.00 sec)
Each Ndb object has its own
counters. NDB API applications can read the values of the counters
for use in optimization or monitoring. For multi-threaded clients
which use more than one Ndb
object concurrently, it is also possible to obtain a summed view
of counters from all Ndb objects
belonging to a given
Ndb_cluster_connection.
Four sets of these counters are exposed. One set applies to the
current session only; the other 3 are global. This is in
spite of the fact that their values can be obtained as either
session or global status variables in the mysql
client. This means that specifying the
SESSION or GLOBAL keyword
with SHOW STATUS has no effect on
the values reported for NDB API statistics status variables, and
the value for each of these variables is the same whether the
value is obtained from the equivalent column of the
SESSION_STATUS or
the GLOBAL_STATUS
table.
Session counters (session specific)
Session counters relate to the
Ndbobjects in use by (only) the current session. Use of such objects by other MySQL clients does not influence these counts.In order to minimize confusion with standard MySQL session variables, we refer to the variables that correspond to these NDB API session counters as “
_sessionvariables”, with a leading underscore.Slave counters (global)
This set of counters relates to the
Ndbobjects used by the replication slave SQL thread, if any. If this mysqld does not act as a replication slave, or does not useNDBtables, then all of these counts are 0.We refer to the related status variables as “
_slavevariables” (with a leading underscore).Injector counters (global)
Injector counters relate to the
Ndbobject used to listen to cluster events by the binary log injector thread. Even when not writing a binary log, mysqld processes attached to a MySQL Cluster continue to listen for some events, such as schema changes.We refer to the status variables that correspond to NDB API injector counters as “
_injectorvariables” (with a leading underscore).Server (Global) counters (global)
This set of counters relates to all
Ndbobjects currently used by this mysqld. This includes all MySQL client applications, the slave SQL thread (if any), the binlog injector, and theNDButility thread.We refer to the status variables that correspond to these counters as “global variables” or “mysqld-level variables”.
You can obtain values for a particular set of variables by
additionally filtering for the substring
session, slave, or
injector in the variable name (along with the
common prefix Ndb_api). For
_session variables, this can be done as shown
here:
mysql> SHOW STATUS LIKE 'ndb_api%session';
+--------------------------------------------+---------+
| Variable_name | Value |
+--------------------------------------------+---------+
| Ndb_api_wait_exec_complete_count_session | 2 |
| Ndb_api_wait_scan_result_count_session | 0 |
| Ndb_api_wait_meta_request_count_session | 1 |
| Ndb_api_wait_nanos_count_session | 8144375 |
| Ndb_api_bytes_sent_count_session | 68 |
| Ndb_api_bytes_received_count_session | 84 |
| Ndb_api_trans_start_count_session | 1 |
| Ndb_api_trans_commit_count_session | 1 |
| Ndb_api_trans_abort_count_session | 0 |
| Ndb_api_trans_close_count_session | 1 |
| Ndb_api_pk_op_count_session | 1 |
| Ndb_api_uk_op_count_session | 0 |
| Ndb_api_table_scan_count_session | 0 |
| Ndb_api_range_scan_count_session | 0 |
| Ndb_api_pruned_scan_count_session | 0 |
| Ndb_api_scan_batch_count_session | 0 |
| Ndb_api_read_row_count_session | 1 |
| Ndb_api_trans_local_read_row_count_session | 1 |
+--------------------------------------------+---------+
18 rows in set (0.50 sec)
To obtain a listing of the NDB API mysqld-level
status variables, filter for variable names beginning with
ndb_api and ending in
_count, like this:
mysql>SELECT * FROM INFORMATION_SCHEMA.SESSION_STATUS->WHERE VARIABLE_NAME LIKE 'ndb_api%count';+------------------------------------+----------------+ | VARIABLE_NAME | VARIABLE_VALUE | +------------------------------------+----------------+ | NDB_API_WAIT_EXEC_COMPLETE_COUNT | 4 | | NDB_API_WAIT_SCAN_RESULT_COUNT | 3 | | NDB_API_WAIT_META_REQUEST_COUNT | 28 | | NDB_API_WAIT_NANOS_COUNT | 53756398 | | NDB_API_BYTES_SENT_COUNT | 1060 | | NDB_API_BYTES_RECEIVED_COUNT | 9724 | | NDB_API_TRANS_START_COUNT | 3 | | NDB_API_TRANS_COMMIT_COUNT | 2 | | NDB_API_TRANS_ABORT_COUNT | 0 | | NDB_API_TRANS_CLOSE_COUNT | 3 | | NDB_API_PK_OP_COUNT | 2 | | NDB_API_UK_OP_COUNT | 0 | | NDB_API_TABLE_SCAN_COUNT | 1 | | NDB_API_RANGE_SCAN_COUNT | 0 | | NDB_API_PRUNED_SCAN_COUNT | 0 | | NDB_API_SCAN_BATCH_COUNT | 0 | | NDB_API_READ_ROW_COUNT | 2 | | NDB_API_TRANS_LOCAL_READ_ROW_COUNT | 2 | | NDB_API_EVENT_DATA_COUNT | 0 | | NDB_API_EVENT_NONDATA_COUNT | 0 | | NDB_API_EVENT_BYTES_COUNT | 0 | +------------------------------------+----------------+ 21 rows in set (0.09 sec)
Not all counters are reflected in all 4 sets of status variables.
For the event counters DataEventsRecvdCount,
NondataEventsRecvdCount, and
EventBytesRecvdCount, only
_injector and mysqld-level
NDB API status variables are available:
mysql> SHOW STATUS LIKE 'ndb_api%event%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| Ndb_api_event_data_count_injector | 0 |
| Ndb_api_event_nondata_count_injector | 0 |
| Ndb_api_event_bytes_count_injector | 0 |
| Ndb_api_event_data_count | 0 |
| Ndb_api_event_nondata_count | 0 |
| Ndb_api_event_bytes_count | 0 |
+--------------------------------------+-------+
6 rows in set (0.00 sec)
_injector status variables are not implemented
for any other NDB API counters, as shown here:
mysql> SHOW STATUS LIKE 'ndb_api%injector%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| Ndb_api_event_data_count_injector | 0 |
| Ndb_api_event_nondata_count_injector | 0 |
| Ndb_api_event_bytes_count_injector | 0 |
+--------------------------------------+-------+
3 rows in set (0.00 sec)
The names of the status variables can easily be associated with the names of the corresponding counters. Each NDB API statistics counter is listed in the following table with a description as well as the names of any MySQL server status variables corresponding to this counter.
| Counter Name | Description |
|---|---|
Status Variables (by statistic type):
| |
WaitExecCompleteCount | Number of times thread has been blocked while waiting for execution of
an operation to complete. Includes all
execute()
calls as well as implicit executes for blob operations and
auto-increment not visible to clients. |
WaitScanResultCount | Number of times thread has been blocked while waiting for a scan-based signal, such waiting for additional results, or for a scan to close. |
WaitMetaRequestCount | Number of times thread has been blocked waiting for a metadata-based signal; this can occur when waiting for a DDL operation or for an epoch to be started (or ended). |
WaitNanosCount | Total time (in nanoseconds) spent waiting for some type of signal from the data nodes. |
BytesSentCount | Amount of data (in bytes) sent to the data nodes |
BytesRecvdCount | Amount of data (in bytes) received from the data nodes |
TransStartCount | Number of transactions started. |
TransCommitCount | Number of transactions committed. |
TransAbortCount | Number of transactions aborted. |
TransCloseCount | Number of transactions aborted. (This value may be greater than the sum
of TransCommitCount and
TransAbortCount.) |
PkOpCount | Number of operations based on or using primary keys. This count includes blob-part table operations, implicit unlocking operations, and auto-increment operations, as well as primary key operations normally visible to MySQL clients. |
UkOpCount | Number of operations based on or using unique keys. |
TableScanCount | Number of table scans that have been started. This includes scans of internal tables. |
RangeScanCount | Number of range scans that have been started. |
PrunedScanCount | Number of scans that have been pruned to a single partition. |
ScanBatchCount | Number of batches of rows received. (A batch in this context is a set of scan results from a single fragment.) |
ReadRowCount | Total number of rows that have been read. Includes rows read using primary key, unique key, and scan operations. |
TransLocalReadRowCount | Number of rows read from the data same node on which the transaction was being run. |
DataEventsRecvdCount | Number of row change events received. |
| |
NondataEventsRecvdCount | Number of events received, other than row change events. |
EventBytesRecvdCount | Number of bytes of events received. |
|
To see all counts of committed transactions—that is, all
TransCommitCount counter status
variables—you can filter the results of
SHOW STATUS for the substring
trans_commit_count, like this:
mysql> SHOW STATUS LIKE '%trans_commit_count%';
+------------------------------------+-------+
| Variable_name | Value |
+------------------------------------+-------+
| Ndb_api_trans_commit_count_session | 1 |
| Ndb_api_trans_commit_count_slave | 0 |
| Ndb_api_trans_commit_count | 2 |
+------------------------------------+-------+
3 rows in set (0.00 sec)
From this you can determine that 1 transaction has been committed in the current mysql client session, and 2 transactions have been committed on this mysqld since it was last restarted.
You can see how various NDB API counters are incremented by a
given SQL statement by comparing the values of the corresponding
_session status variables immediately before
and after performing the statement. In this example, after getting
the initial values from SHOW
STATUS, we create in the test
database an NDB table, named
t, that has a single column:
mysql>SHOW STATUS LIKE 'ndb_api%session%';+--------------------------------------------+--------+ | Variable_name | Value | +--------------------------------------------+--------+ | Ndb_api_wait_exec_complete_count_session | 2 | | Ndb_api_wait_scan_result_count_session | 0 | | Ndb_api_wait_meta_request_count_session | 3 | | Ndb_api_wait_nanos_count_session | 820705 | | Ndb_api_bytes_sent_count_session | 132 | | Ndb_api_bytes_received_count_session | 372 | | Ndb_api_trans_start_count_session | 1 | | Ndb_api_trans_commit_count_session | 1 | | Ndb_api_trans_abort_count_session | 0 | | Ndb_api_trans_close_count_session | 1 | | Ndb_api_pk_op_count_session | 1 | | Ndb_api_uk_op_count_session | 0 | | Ndb_api_table_scan_count_session | 0 | | Ndb_api_range_scan_count_session | 0 | | Ndb_api_pruned_scan_count_session | 0 | | Ndb_api_scan_batch_count_session | 0 | | Ndb_api_read_row_count_session | 1 | | Ndb_api_trans_local_read_row_count_session | 1 | +--------------------------------------------+--------+ 18 rows in set (0.00 sec) mysql>USE test;Database changed mysql>CREATE TABLE t (c INT) ENGINE NDBCLUSTER;Query OK, 0 rows affected (0.85 sec)
Now you can execute a new SHOW
STATUS statement and observe the changes, as shown here
(with the changed rows highlighted in the output):
mysql> SHOW STATUS LIKE 'ndb_api%session%'; +--------------------------------------------+-----------+ | Variable_name | Value | +--------------------------------------------+-----------+ | Ndb_api_wait_exec_complete_count_session | 8 | | Ndb_api_wait_scan_result_count_session | 0 | | Ndb_api_wait_meta_request_count_session | 17 | | Ndb_api_wait_nanos_count_session | 706871709 | | Ndb_api_bytes_sent_count_session | 2376 | | Ndb_api_bytes_received_count_session | 3844 | | Ndb_api_trans_start_count_session | 4 | | Ndb_api_trans_commit_count_session | 4 | | Ndb_api_trans_abort_count_session | 0 | | Ndb_api_trans_close_count_session | 4 | | Ndb_api_pk_op_count_session | 6 | | Ndb_api_uk_op_count_session | 0 | | Ndb_api_table_scan_count_session | 0 | | Ndb_api_range_scan_count_session | 0 | | Ndb_api_pruned_scan_count_session | 0 | | Ndb_api_scan_batch_count_session | 0 | | Ndb_api_read_row_count_session | 2 | | Ndb_api_trans_local_read_row_count_session | 1 | +--------------------------------------------+-----------+ 18 rows in set (0.00 sec)
Similarly, you can see the changes in the NDB API statistics
counters caused by inserting a row into t:
Insert the row, then run the same SHOW
STATUS statement used in the previous example, as shown
here:
mysql>INSERT INTO t VALUES (100);Query OK, 1 row affected (0.00 sec) mysql>SHOW STATUS LIKE 'ndb_api%session%';+--------------------------------------------+-----------+ | Variable_name | Value | +--------------------------------------------+-----------+ | Ndb_api_wait_exec_complete_count_session | 11 | | Ndb_api_wait_scan_result_count_session | 6 | | Ndb_api_wait_meta_request_count_session | 20 | | Ndb_api_wait_nanos_count_session | 707370418 | | Ndb_api_bytes_sent_count_session | 2724 | | Ndb_api_bytes_received_count_session | 4116 | | Ndb_api_trans_start_count_session | 7 | | Ndb_api_trans_commit_count_session | 6 | | Ndb_api_trans_abort_count_session | 0 | | Ndb_api_trans_close_count_session | 7 | | Ndb_api_pk_op_count_session | 8 | | Ndb_api_uk_op_count_session | 0 | | Ndb_api_table_scan_count_session | 1 | | Ndb_api_range_scan_count_session | 0 | | Ndb_api_pruned_scan_count_session | 0 | | Ndb_api_scan_batch_count_session | 0 | | Ndb_api_read_row_count_session | 3 | | Ndb_api_trans_local_read_row_count_session | 2 | +--------------------------------------------+-----------+ 18 rows in set (0.00 sec)
We can make a number of observations from these results:
Although we created
twith no explicit primary key, 5 primary key operations were performed in doing so (the difference in the “before” and “after” values ofNdb_api_pk_op_count_session, or 6 minus 1). This reflects the creation of the hidden primary key that is a feature of all tables using theNDBstorage engine.By comparing successive values for
Ndb_api_wait_nanos_count_session, we can see that the NDB API operations implementing theCREATE TABLEstatement waited much longer (706871709 - 820705 = 706051004 nanoseconds, or approximately 0.7 second) for responses from the data nodes than those executed by theINSERT(707370418 - 706871709 = 498709 ns or roughly .0005 second). The execution times reported for these statements in the mysql client correlate roughly with these figures.On platforms with without sufficient (nanosecond) time resolution, small changes in the value of the
WaitNanosCountNDB API counter due to SQL statements that execute very quickly may not always be visible in the values ofNdb_api_wait_nanos_count_session,Ndb_api_wait_nanos_count_slave, orNdb_api_wait_nanos_count.The
INSERTstatement incremented both theReadRowCountandTransLocalReadRowCountNDB API statistics counters, as reflected by the increased values ofNdb_api_read_row_count_sessionandNdb_api_trans_local_read_row_count_session.
- 18.6.1 MySQL Cluster Replication: Abbreviations and Symbols
- 18.6.2 General Requirements for MySQL Cluster Replication
- 18.6.3 Known Issues in MySQL Cluster Replication
- 18.6.4 MySQL Cluster Replication Schema and Tables
- 18.6.5 Preparing the MySQL Cluster for Replication
- 18.6.6 Starting MySQL Cluster Replication (Single Replication Channel)
- 18.6.7 Using Two Replication Channels for MySQL Cluster Replication
- 18.6.8 Implementing Failover with MySQL Cluster Replication
- 18.6.9 MySQL Cluster Backups With MySQL Cluster Replication
- 18.6.10 MySQL Cluster Replication: Multi-Master and Circular Replication
- 18.6.11 MySQL Cluster Replication Conflict Resolution
MySQL Cluster supports asynchronous replication, more usually referred to simply as “replication”. This section explains how to set up and manage a configuration in which one group of computers operating as a MySQL Cluster replicates to a second computer or group of computers. We assume some familiarity on the part of the reader with standard MySQL replication as discussed elsewhere in this Manual. (See Chapter 17, Replication).
Normal (non-clustered) replication involves a “master”
server and a “slave” server, the master being the
source of the operations and data to be replicated and the slave
being the recipient of these. In MySQL Cluster, replication is
conceptually very similar but can be more complex in practice, as it
may be extended to cover a number of different configurations
including replicating between two complete clusters. Although a
MySQL Cluster itself depends on the NDB
storage engine for clustering functionality, it is not necessary to
use NDB as the storage engine for the
slave's copies of the replicated tables (see
Replication from NDB to other storage engines).
However, for maximum availability, it is possible (and preferable)
to replicate from one MySQL Cluster to another, and it is this
scenario that we discuss, as shown in the following figure:
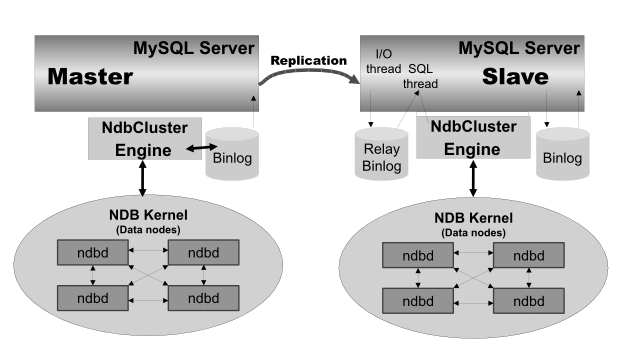
In this scenario, the replication process is one in which successive
states of a master cluster are logged and saved to a slave cluster.
This process is accomplished by a special thread known as the NDB
binary log injector thread, which runs on each MySQL server and
produces a binary log (binlog). This thread
ensures that all changes in the cluster producing the binary
log—and not just those changes that are effected through the
MySQL Server—are inserted into the binary log with the correct
serialization order. We refer to the MySQL replication master and
replication slave servers as replication servers or replication
nodes, and the data flow or line of communication between them as a
replication channel.
For information about performing point-in-time recovery with MySQL Cluster and MySQL Cluster Replication, see Section 18.6.9.2, “Point-In-Time Recovery Using MySQL Cluster Replication”.
NDB API _slave status variables.
NDB API counters can provide enhanced monitoring capabilities on
MySQL Cluster replication slaves. These are implemented as NDB
statistics _slave status variables, as seen in
the output of SHOW STATUS, or in
the results of queries against the
SESSION_STATUS or
GLOBAL_STATUS
table in a mysql client session connected to a
MySQL Server that is acting as a slave in MySQL Cluster
Replication. By comparing the values of these status variables
before and after the execution of statements affecting replicated
NDB tables, you can observe the
corresponding actions taken on the NDB API level by the slave,
which can be useful when monitoring or troubleshooting MySQL
Cluster Replication.
Section 18.5.15, “NDB API Statistics Counters and Variables”, provides
additional information.
Replication from NDB to non-NDB tables.
It is possible to replicate NDB
tables from a MySQL Cluster acting as the master to tables using
other MySQL storage engines such as
InnoDB or
MyISAM on a slave
mysqld. This is subject to a number of
conditions; see
Replication from NDB to other storage engines, and
Replication from NDB to a nontransactional storage engine,
for more information.
Throughout this section, we use the following abbreviations or symbols for referring to the master and slave clusters, and to processes and commands run on the clusters or cluster nodes:
| Symbol or Abbreviation | Description (Refers to...) |
|---|---|
M | The cluster serving as the (primary) replication master |
S | The cluster acting as the (primary) replication slave |
shell | Shell command to be issued on the master cluster |
mysql | MySQL client command issued on a single MySQL server running as an SQL node on the master cluster |
mysql | MySQL client command to be issued on all SQL nodes participating in the replication master cluster |
shell | Shell command to be issued on the slave cluster |
mysql | MySQL client command issued on a single MySQL server running as an SQL node on the slave cluster |
mysql | MySQL client command to be issued on all SQL nodes participating in the replication slave cluster |
C | Primary replication channel |
C' | Secondary replication channel |
M' | Secondary replication master |
S' | Secondary replication slave |
A replication channel requires two MySQL servers acting as replication servers (one each for the master and slave). For example, this means that in the case of a replication setup with two replication channels (to provide an extra channel for redundancy), there will be a total of four replication nodes, two per cluster.
Replication of a MySQL Cluster as described in this section and
those following is dependent on row-based replication. This means
that the replication master MySQL server must be running with
--binlog-format=ROW or
--binlog-format=MIXED, as described
in Section 18.6.6, “Starting MySQL Cluster Replication (Single Replication Channel)”. For
general information about row-based replication, see
Section 17.1.2, “Replication Formats”.
If you attempt to use MySQL Cluster Replication with
--binlog-format=STATEMENT,
replication fails to work properly because the
ndb_binlog_index table on the master and the
epoch column of the
ndb_apply_status table on the slave are not
updated (see
Section 18.6.4, “MySQL Cluster Replication Schema and Tables”). Instead,
only updates on the MySQL server acting as the replication
master propagate to the slave, and no updates from any other SQL
nodes on the master cluster are replicated.
Beginning with MySQL Cluster NDB 7.2.13, the default value for
the --binlog-format option is
MIXED. (Bug #16417224)
In MySQL Cluster NDB 7.2.12 and earlier MySQL Cluster NDB 7.2
releases, the default for
--binlog-format was
STATEMENT; this meant that you were required
to change the binary logging format to ROW
(or MIXED) manually on all MySQL Servers on
the master MySQL Cluster, prior to starting MySQL Cluster
replication. If necessary, you can do this on startup using the
--binlog-format option, or at
runtime by setting the global
binlog_format system variable.
Using the startup option is preferred in such cases.
Each MySQL server used for replication in either cluster must be
uniquely identified among all the MySQL replication servers
participating in either cluster (you cannot have replication
servers on both the master and slave clusters sharing the same
ID). This can be done by starting each SQL node using the
--server-id= option,
where idid is a unique integer. Although
it is not strictly necessary, we will assume for purposes of this
discussion that all MySQL Cluster binaries are of the same release
version.
It is generally true in MySQL Replication that both MySQL servers (mysqld processes) involved must be compatible with one another with respect to both the version of the replication protocol used and the SQL feature sets which they support (see Section 17.4.2, “Replication Compatibility Between MySQL Versions”). It is due to such differences between the binaries in the MySQL Cluster and MySQL Server 5.5 distributions that MySQL Cluster Replication has the additional requirement that both mysqld binaries come from a MySQL Cluster distribution. The simplest and easiest way to assure that the mysqld servers are compatible is to use the same MySQL Cluster distribution for all master and slave mysqld binaries.
We assume that the slave server or cluster is dedicated to replication of the master, and that no other data is being stored on it.
All NDB tables being replicated must be created
using a MySQL server and client. Tables and other database objects
created using the NDB API (with, for example,
Dictionary::createTable()) are
not visible to a MySQL server and so are not replicated. Updates
by NDB API applications to existing tables that were created using
a MySQL server can be replicated.
It is possible to replicate a MySQL Cluster using statement-based replication. However, in this case, the following restrictions apply:
All updates to data rows on the cluster acting as the master must be directed to a single MySQL server.
It is not possible to replicate a cluster using multiple simultaneous MySQL replication processes.
Only changes made at the SQL level are replicated.
These are in addition to the other limitations of statement-based replication as opposed to row-based replication; see Section 17.1.2.1, “Advantages and Disadvantages of Statement-Based and Row-Based Replication”, for more specific information concerning the differences between the two replication formats.
This section discusses known problems or issues when using replication with MySQL Cluster NDB 7.2.
Loss of master-slave connection.
A loss of connection can occur either between the replication
master SQL node and the replication slave SQL node, or between
the replication master SQL node and the data nodes in the master
cluster. In the latter case, this can occur not only as a result
of loss of physical connection (for example, a broken network
cable), but due to the overflow of data node event buffers; if
the SQL node is too slow to respond, it may be dropped by the
cluster (this is controllable to some degree by adjusting the
MaxBufferedEpochs and
TimeBetweenEpochs
configuration parameters). If this occurs, it is
entirely possible for new data to be inserted into the master
cluster without being recorded in the replication master's
binary log. For this reason, to guarantee high
availability, it is extremely important to maintain a backup
replication channel, to monitor the primary channel, and to fail
over to the secondary replication channel when necessary to keep
the slave cluster synchronized with the master. MySQL Cluster is
not designed to perform such monitoring on its own; for this, an
external application is required.
The replication master issues a “gap” event when
connecting or reconnecting to the master cluster. (A gap event is
a type of “incident event,” which indicates an
incident that occurs that affects the contents of the database but
that cannot easily be represented as a set of changes. Examples of
incidents are server crashes, database resynchronization, (some)
software updates, and (some) hardware changes.) When the slave
encounters a gap in the replication log, it stops with an error
message. This message is available in the output of
SHOW SLAVE STATUS, and indicates
that the SQL thread has stopped due to an incident registered in
the replication stream, and that manual intervention is required.
See Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”, for more
information about what to do in such circumstances.
Because MySQL Cluster is not designed on its own to monitor replication status or provide failover, if high availability is a requirement for the slave server or cluster, then you must set up multiple replication lines, monitor the master mysqld on the primary replication line, and be prepared fail over to a secondary line if and as necessary. This must be done manually, or possibly by means of a third-party application. For information about implementing this type of setup, see Section 18.6.7, “Using Two Replication Channels for MySQL Cluster Replication”, and Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”.
However, if you are replicating from a standalone MySQL server to a MySQL Cluster, one channel is usually sufficient.
Circular replication. MySQL Cluster Replication supports circular replication, as shown in the next example. The replication setup involves three MySQL Clusters numbered 1, 2, and 3, in which Cluster 1 acts as the replication master for Cluster 2, Cluster 2 acts as the master for Cluster 3, and Cluster 3 acts as the master for Cluster 1, thus completing the circle. Each MySQL Cluster has two SQL nodes, with SQL nodes A and B belonging to Cluster 1, SQL nodes C and D belonging to Cluster 2, and SQL nodes E and F belonging to Cluster 3.
Circular replication using these clusters is supported as long as the following conditions are met:
The SQL nodes on all masters and slaves are the same
All SQL nodes acting as replication masters and slaves are started using the
--log-slave-updatesoption
This type of circular replication setup is shown in the following diagram:
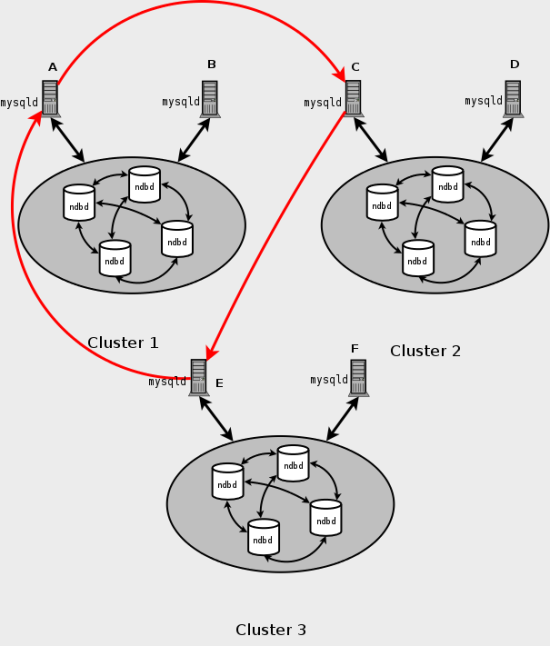
In this scenario, SQL node A in Cluster 1 replicates to SQL node C in Cluster 2; SQL node C replicates to SQL node E in Cluster 3; SQL node E replicates to SQL node A. In other words, the replication line (indicated by the red arrows in the diagram) directly connects all SQL nodes used as replication masters and slaves.
It should also be possible to set up circular replication in which not all master SQL nodes are also slaves, as shown here:
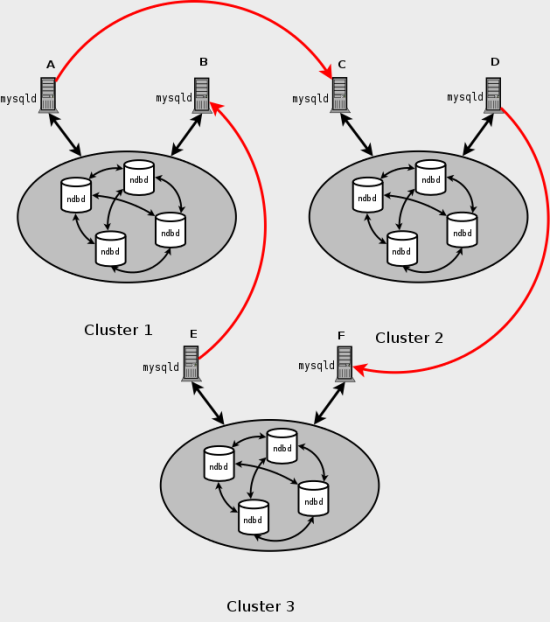
In this case, different SQL nodes in each cluster are used as
replication masters and slaves. However, you must
not start any of the SQL nodes using
--log-slave-updates. This type of
circular replication scheme for MySQL Cluster, in which the line
of replication (again indicated by the red arrows in the diagram)
is discontinuous, should be possible, but it should be noted that
it has not yet been thoroughly tested and must therefore still be
considered experimental.
The NDB storage engine uses
idempotent execution mode,
which suppresses duplicate-key and other errors that otherwise
break circular replication of MySQL Cluster. This is equivalent
to setting the global
slave_exec_mode system variable
to IDEMPOTENT, although this is not necessary
in MySQL Cluster replication, since MySQL Cluster sets this
variable automatically and ignores any attempts to set it
explicitly.
MySQL Cluster replication and primary keys.
In the event of a node failure, errors in replication of
NDB tables without primary keys can
still occur, due to the possibility of duplicate rows being
inserted in such cases. For this reason, it is highly
recommended that all NDB tables
being replicated have primary keys.
MySQL Cluster Replication and Unique Keys.
In older versions of MySQL Cluster, operations that updated
values of unique key columns of NDB
tables could result in duplicate-key errors when replicated.
This issue is solved for replication between
NDB tables by deferring unique key
checks until after all table row updates have been performed.
Deferring constraints in this way is currently supported only by
NDB. Thus, updates of unique keys
when replicating from NDB to a
different storage engine such as
MyISAM or
InnoDB are still not supported.
The problem encountered when replicating without deferred checking
of unique key updates can be illustrated using
NDB table such as
t, is created and populated on the master (and
replicated to a slave that does not support deferred unique key
updates) as shown here:
CREATE TABLE t (
p INT PRIMARY KEY,
c INT,
UNIQUE KEY u (c)
) ENGINE NDB;
INSERT INTO t
VALUES (1,1), (2,2), (3,3), (4,4), (5,5);
The following UPDATE statement on
t succeeded on the master, since the rows
affected are processed in the order determined by the
ORDER BY option, performed over the entire
table:
UPDATE t SET c = c - 1 ORDER BY p;
However, the same statement failed with a duplicate key error or other constraint violation on the slave, because the ordering of the row updates was done for one partition at a time, rather than for the table as a whole.
Every NDB table is implicitly
partitioned by key when it is created. See
Section 19.2.5, “KEY Partitioning”, for more information.
Restarting with --initial.
Restarting the cluster with the
--initial option causes the
sequence of GCI and epoch numbers to start over from
0. (This is generally true of MySQL Cluster
and not limited to replication scenarios involving Cluster.) The
MySQL servers involved in replication should in this case be
restarted. After this, you should use the
RESET MASTER and
RESET SLAVE statements to clear
the invalid ndb_binlog_index and
ndb_apply_status tables, respectively.
Replication from NDB to other storage engines.
It is possible to replicate an NDB
table on the master to a table using a different storage engine
on the slave, taking into account the restrictions listed here:
Multi-master and circular replication are not supported (tables on both the master and the slave must use the
NDBstorage engine for this to work).Using a storage engine which does not perform binary logging for slave tables requires special handling.
Use of a nontransactional storage engine for slave tables also requires special handling.
The master mysqld must be started with
--ndb-log-update-as-write=0or--ndb-log-update-as-write=OFF.
The next few paragraphs provide additional information about each of the issues just described.
Multiple masters not supported when replicating NDB to other storage
engines.
For replication from NDB to a
different storage engine, the relationship between the two
databases must be a simple master-slave one. This means that
circular or master-master replication is not supported between
MySQL Cluster and other storage engines.
In addition, it is not possible to configure more than one
replication channel when replicating between
NDB and a different storage engine.
(However, a MySQL Cluster database can
simultaneously replicate to multiple slave MySQL Cluster
databases.) If the master uses NDB
tables, it is still possible to have more than one MySQL Server
maintain a binary log of all changes; however, for the slave to
change masters (fail over), the new master-slave relationship must
be explicitly defined on the slave.
Replicating NDB to a slave storage engine that does not perform binary logging. If you attempt to replicate from a MySQL Cluster to a slave that uses a storage engine that does not handle its own binary logging, the replication process aborts with the error Binary logging not possible ... Statement cannot be written atomically since more than one engine involved and at least one engine is self-logging (Error 1595). It is possible to work around this issue in one of the following ways:
Turn off binary logging on the slave. This can be accomplished by setting
sql_log_bin = 0.Change the storage engine used for the mysql.ndb_apply_status table. Causing this table to use an engine that does not handle its own binary logging can also eliminate the conflict. This can be done by issuing a statement such as
ALTER TABLE mysql.ndb_apply_status ENGINE=MyISAMon the slave. It is safe to do this when using a non-NDBstorage engine on the slave, since you do not then need to worry about keeping multiple slave SQL nodes synchronized.Filter out changes to the mysql.ndb_apply_status table on the slave. This can be done by starting the slave SQL node with
--replicate-ignore-table=mysql.ndb_apply_status. If you need for other tables to be ignored by replication, you might wish to use an appropriate--replicate-wild-ignore-tableoption instead.
You should not disable replication or
binary logging of mysql.ndb_apply_status or
change the storage engine used for this table when replicating
from one MySQL Cluster to another. See
Replication and binary log filtering rules with replication between
MySQL Clusters,
for details.
Replication from NDB to a nontransactional storage engine.
When replicating from NDB to a
nontransactional storage engine such as
MyISAM, you may encounter
unnecessary duplicate key errors when replicating
INSERT ...
ON DUPLICATE KEY UPDATE statements. You can suppress
these by using
--ndb-log-update-as-write=0,
which forces updates to be logged as writes (rather than as
updates).
In addition, when replicating from
NDB to a storage engine that does not
implement transactions, if the slave fails to apply any row
changes from a given transaction, it does not roll back the rest
of the transaction. (This is true when replicating tables using
any transactional storage engine—not only
NDB—to a nontransactional
storage engine.) Because of this, it cannot be guaranteed that
transactional consistency will be maintained on the slave in such
cases.
Replication and binary log filtering rules with replication between
MySQL Clusters.
If you are using any of the options
--replicate-do-*,
--replicate-ignore-*,
--binlog-do-db, or
--binlog-ignore-db to filter
databases or tables being replicated, care must be taken not to
block replication or binary logging of the
mysql.ndb_apply_status, which is required for
replication between MySQL Clusters to operate properly. In
particular, you must keep in mind the following:
Using
--replicate-do-db=(and no otherdb_name--replicate-do-*or--replicate-ignore-*options) means that only tables in databasedb_nameare replicated. In this case, you should also use--replicate-do-db=mysql,--binlog-do-db=mysql, or--replicate-do-table=mysql.ndb_apply_statusto ensure thatmysql.ndb_apply_statusis populated on slaves.Using
--binlog-do-db=(and no otherdb_name--binlog-do-dboptions) means that changes only to tables in databasedb_nameare written to the binary log. In this case, you should also use--replicate-do-db=mysql,--binlog-do-db=mysql, or--replicate-do-table=mysql.ndb_apply_statusto ensure thatmysql.ndb_apply_statusis populated on slaves.Using
--replicate-ignore-db=mysqlmeans that no tables in themysqldatabase are replicated. In this case, you should also use--replicate-do-table=mysql.ndb_apply_statusto ensure thatmysql.ndb_apply_statusis replicated.Using
--binlog-ignore-db=mysqlmeans that no changes to tables in themysqldatabase are written to the binary log. In this case, you should also use--replicate-do-table=mysql.ndb_apply_statusto ensure thatmysql.ndb_apply_statusis replicated.
You should also remember that each replication rule requires the following:
Its own
--replicate-do-*or--replicate-ignore-*option, and that multiple rules cannot be expressed in a single replication filtering option. For information about these rules, see Section 17.1.3, “Replication and Binary Logging Options and Variables”.Its own
--binlog-do-dbor--binlog-ignore-dboption, and that multiple rules cannot be expressed in a single binary log filtering option. For information about these rules, see Section 5.2.4, “The Binary Log”.
If you are replicating a MySQL Cluster to a slave that uses a
storage engine other than NDB, the
considerations just given previously may not apply, as discussed
elsewhere in this section.
MySQL Cluster Replication and IPv6. Currently, the NDB API and MGM API do not support IPv6. However, MySQL Servers—including those acting as SQL nodes in a MySQL Cluster—can use IPv6 to contact other MySQL Servers. This means that you can replicate between MySQL Clusters using IPv6 to connect the master and slave SQL nodes as shown by the dotted arrow in the following diagram:
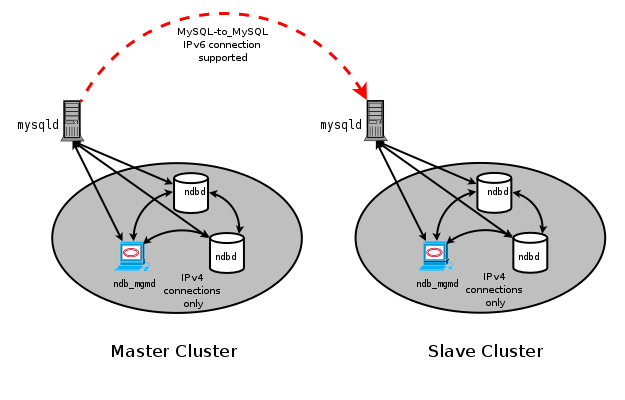
However, all connections originating within the MySQL Cluster—represented in the preceding diagram by solid arrows—must use IPv4. In other words, all MySQL Cluster data nodes, management servers, and management clients must be accessible from one another using IPv4. In addition, SQL nodes must use IPv4 to communicate with the cluster.
Since there is currently no support in the NDB and MGM APIs for IPv6, any applications written using these APIs must also make all connections using IPv4.
Attribute promotion and demotion.
MySQL Cluster Replication includes support for attribute
promotion and demotion. The implementation of the latter
distinguishes between lossy and non-lossy type conversions, and
their use on the slave can be controlled by setting the
slave_type_conversions global
server system variable.
For more information about attribute promotion and demotion in MySQL Cluster, see Row-based replication: attribute promotion and demotion.
Replication in MySQL Cluster makes use of a number of dedicated
tables in the mysql database on each MySQL
Server instance acting as an SQL node in both the cluster being
replicated and the replication slave (whether the slave is a
single server or a cluster). These tables are created during the
MySQL installation process by the
mysql_install_db script, and include a table
for storing the binary log's indexing data. Since the
ndb_binlog_index table is local to each MySQL
server and does not participate in clustering, it uses the
MyISAM storage engine. This means that it must
be created separately on each mysqld
participating in the master cluster. (However, the binary log
itself contains updates from all MySQL servers in the cluster to
be replicated.) This table is defined as follows:
CREATE TABLE `ndb_binlog_index` (
`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` INT(10) UNSIGNED NOT NULL,
`updates` INT(10) UNSIGNED NOT NULL,
`deletes` INT(10) UNSIGNED NOT NULL,
`schemaops` INT(10) UNSIGNED NOT NULL,
`orig_server_id` INT(10) UNSIGNED NOT NULL,
`orig_epoch` BIGINT(20) UNSIGNED NOT NULL,
`gci` INT(10) UNSIGNED NOT NULL,
`next_position` bigint(20) unsigned NOT NULL,
`next_file` varchar(255) NOT NULL,
PRIMARY KEY (`epoch`,`orig_server_id`,`orig_epoch`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
The size of this table is dependent on the number of epochs per
binary log file and the number of binary log files. The number of
epochs per binary log file normally depends on the amount of
binary log generated per epoch and the size of the binary log
file, with smaller epochs resulting in more epochs per file. It
should be noted that empty epochs produce result in inserts to the
ndb_binlog_index table, even when the
--ndb-log-empty-epochs option is
OFF, meaning that the number of entries per
file depends on the length of time that the file is in use; that
is,
[number of epochs per file] = [time spent per file] / TimeBetweenEpochs
A busy MySQL Cluster writes to the binary log regularly and
presumably rotates binary log files more quickly than a quiet one.
This means that a “quiet” MySQL Cluster with
--ndb-log-empty-epochs=ON can
actually have a much higher number of
ndb_binlog_index rows per file than one with a
great deal of activity.
When mysqld is started with the
--ndb-log-orig option, the
orig_server_id and
orig_epoch columns store, respectively, the ID
of the server on which the event originated and the epoch in which
the event took place on the originating server, which is useful in
MySQL Cluster replication setups employing multiple masters. The
SELECT statement used to find the
closest binary log position to the highest applied epoch on the
slave in a multi-master setup (see
Section 18.6.10, “MySQL Cluster Replication: Multi-Master and Circular Replication”) employs
these two columns, which are not indexed. This can lead to
performance issues when trying to fail over, since the query must
perform a table scan, especially when the master has been running
with --ndb-log-empty-epochs=ON. You
can improve multi-master failover times by adding an index to
these columns, as shown here:
ALTER TABLE mysql.ndb_binlog_index
ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);
Adding this index provides no benefit when replicating from a
single master to a single slave, since the query used to get the
binary log position in such cases makes no use of
orig_server_id or
orig_epoch.
The next_position and
next_file columns were added in MySQL Cluster
NDB 7.2.6; see
Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”, for more
information about using these columns.
The following figure shows the relationship of the MySQL Cluster
replication master server, its binary log injector thread, and the
mysql.ndb_binlog_index table.
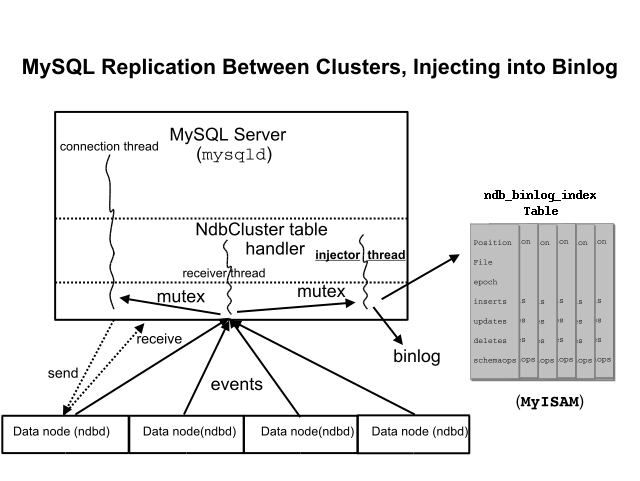
An additional table, named ndb_apply_status, is
used to keep a record of the operations that have been replicated
from the master to the slave. Unlike the case with
ndb_binlog_index, the data in this table is not
specific to any one SQL node in the (slave) cluster, and so
ndb_apply_status can use the
NDBCLUSTER storage engine, as shown here:
CREATE TABLE `ndb_apply_status` (
`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`log_name` VARCHAR(255) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
`start_pos` BIGINT(20) UNSIGNED NOT NULL,
`end_pos` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`server_id`) USING HASH
) ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
The ndb_apply_status table is populated only on
slaves, which means that, on the master, this table never contains
any rows; thus, there is no need to allow for
DataMemory or
IndexMemory to be allotted
to ndb_apply_status there.
Because this table is populated from data originating on the
master, it should be allowed to replicate; any replication
filtering or binary log filtering rules that inadvertently prevent
the slave from updating ndb_apply_status or the
master from writing into the binary log may prevent replication
between clusters from operating properly. For more information
about potential problems arising from such filtering rules, see
Replication and binary log filtering rules with replication between
MySQL Clusters.
The ndb_binlog_index and
ndb_apply_status tables are created in the
mysql database because they should not be
explicitly replicated by the user. User intervention is normally
not required to create or maintain either of these tables, since
both ndb_binlog_index and the
ndb_apply_status are maintained by the
NDB binary log (binlog) injector
thread. This keeps the master mysqld process
updated to changes performed by the
NDB storage engine. The
NDB binlog
injector thread receives events directly from the
NDB storage engine. The
NDB injector is responsible for
capturing all the data events within the cluster, and ensures that
all events which change, insert, or delete data are recorded in
the ndb_binlog_index table. The slave I/O
thread transfers the events from the master's binary log to the
slave's relay log.
However, it is advisable to check for the existence and integrity
of these tables as an initial step in preparing a MySQL Cluster
for replication. It is possible to view event data recorded in the
binary log by querying the
mysql.ndb_binlog_index table directly on the
master. This can be also be accomplished using the
SHOW BINLOG EVENTS statement on
either the replication master or slave MySQL servers. (See
Section 13.7.5.3, “SHOW BINLOG EVENTS Syntax”.)
You can also obtain useful information from the output of
SHOW ENGINE NDB
STATUS.
The ndb_schema table is used to track schema
changes made to NDB tables. It is
defined as shown here:
CREATE TABLE ndb_schema (
`db` VARBINARY(63) NOT NULL,
`name` VARBINARY(63) NOT NULL,
`slock` BINARY(32) NOT NULL,
`query` BLOB NOT NULL,
`node_id` INT UNSIGNED NOT NULL,
`epoch` BIGINT UNSIGNED NOT NULL,
`id` INT UNSIGNED NOT NULL,
`version` INT UNSIGNED NOT NULL,
`type` INT UNSIGNED NOT NULL,
PRIMARY KEY USING HASH (db,name)
) ENGINE=NDB DEFAULT CHARSET=latin1;
Unlike the two tables previously mentioned in this section, the
ndb_schema table is not visible either to MySQL
SHOW statements, or in any
INFORMATION_SCHEMA tables; however, it can be
seen in the output of ndb_show_tables, as shown
here:
shell> ndb_show_tables -t 2
id type state logging database schema name
4 UserTable Online Yes mysql def ndb_apply_status
5 UserTable Online Yes ndbworld def City
6 UserTable Online Yes ndbworld def Country
3 UserTable Online Yes mysql def NDB$BLOB_2_3
7 UserTable Online Yes ndbworld def CountryLanguage
2 UserTable Online Yes mysql def ndb_schema
NDBT_ProgramExit: 0 - OK
It is also possible to SELECT from
this table in mysql and other MySQL client
applications, as shown here:
mysql> SELECT * FROM mysql.ndb_schema WHERE name='City' \G
*************************** 1. row ***************************
db: ndbworld
name: City
slock:
query: alter table City engine=ndb
node_id: 4
epoch: 0
id: 0
version: 0
type: 7
1 row in set (0.00 sec)
This can sometimes be useful when debugging applications.
When performing schema changes on
NDB tables, applications should
wait until the ALTER TABLE
statement has returned in the MySQL client connection that
issued the statement before attempting to use the updated
definition of the table.
If the ndb_apply_status table or the
ndb_schema table does not exist on the slave,
ndb_restore re-creates the missing table or
tables (Bug #14612).
Conflict resolution for MySQL Cluster Replication requires the
presence of an additional mysql.ndb_replication
table. Currently, this table must be created manually. For
information about how to do this, see
Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Preparing the MySQL Cluster for replication consists of the following steps:
Check all MySQL servers for version compatibility (see Section 18.6.2, “General Requirements for MySQL Cluster Replication”).
Create a slave account on the master Cluster with the appropriate privileges:
mysql
M>GRANT REPLICATION SLAVE->ON *.* TO '->slave_user'@'slave_host'IDENTIFIED BY 'slave_password';In the previous statement,
slave_useris the slave account user name,slave_hostis the host name or IP address of the replication slave, andslave_passwordis the password to assign to this account.For example, to create a slave user account with the name “
myslave,” logging in from the host named “rep-slave,” and using the password “53cr37,” use the followingGRANTstatement:mysql
M>GRANT REPLICATION SLAVE->ON *.* TO 'myslave'@'rep-slave'->IDENTIFIED BY '53cr37';For security reasons, it is preferable to use a unique user account—not employed for any other purpose—for the replication slave account.
Configure the slave to use the master. Using the MySQL Monitor, this can be accomplished with the
CHANGE MASTER TOstatement:mysql
S>CHANGE MASTER TO->MASTER_HOST='->master_host',MASTER_PORT=->master_port,MASTER_USER='->slave_user',MASTER_PASSWORD='slave_password';In the previous statement,
master_hostis the host name or IP address of the replication master,master_portis the port for the slave to use for connecting to the master,slave_useris the user name set up for the slave on the master, andslave_passwordis the password set for that user account in the previous step.For example, to tell the slave to replicate from the MySQL server whose host name is “
rep-master,” using the replication slave account created in the previous step, use the following statement:mysql
S>CHANGE MASTER TO->MASTER_HOST='rep-master',->MASTER_PORT=3306,->MASTER_USER='myslave',->MASTER_PASSWORD='53cr37';For a complete list of options that can be used with this statement, see Section 13.4.2.1, “CHANGE MASTER TO Syntax”.
To provide replication backup capability, you also need to add an
--ndb-connectstringoption to the slave'smy.cnffile prior to starting the replication process. See Section 18.6.9, “MySQL Cluster Backups With MySQL Cluster Replication”, for details.For additional options that can be set in
my.cnffor replication slaves, see Section 17.1.3, “Replication and Binary Logging Options and Variables”.If the master cluster is already in use, you can create a backup of the master and load this onto the slave to cut down on the amount of time required for the slave to synchronize itself with the master. If the slave is also running MySQL Cluster, this can be accomplished using the backup and restore procedure described in Section 18.6.9, “MySQL Cluster Backups With MySQL Cluster Replication”.
ndb-connectstring=
management_host[:port]In the event that you are not using MySQL Cluster on the replication slave, you can create a backup with this command on the replication master:
shell
M>mysqldump --master-data=1Then import the resulting data dump onto the slave by copying the dump file over to the slave. After this, you can use the mysql client to import the data from the dumpfile into the slave database as shown here, where
dump_fileis the name of the file that was generated using mysqldump on the master, anddb_nameis the name of the database to be replicated:shell
S>mysql -u root -pdb_name<dump_fileFor a complete list of options to use with mysqldump, see Section 4.5.4, “mysqldump — A Database Backup Program”.
NoteIf you copy the data to the slave in this fashion, you should make sure that the slave is started with the
--skip-slave-startoption on the command line, or else includeskip-slave-startin the slave'smy.cnffile to keep it from trying to connect to the master to begin replicating before all the data has been loaded. Once the data loading has completed, follow the additional steps outlined in the next two sections.Ensure that each MySQL server acting as a replication master is configured with a unique server ID, and with binary logging enabled, using the row format. (See Section 17.1.2, “Replication Formats”.) These options can be set either in the master server's
my.cnffile, or on the command line when starting the master mysqld process. See Section 18.6.6, “Starting MySQL Cluster Replication (Single Replication Channel)”, for information regarding the latter option.
This section outlines the procedure for starting MySQL Cluster replication using a single replication channel.
Start the MySQL replication master server by issuing this command:
shell
M>mysqld --ndbcluster --server-id=id\--log-bin &If the master is running MySQL Cluster NDB 7.2.12 or earlier, it must also be started with
--binlog-format=ROW(orMIXED). (Bug #16417224)In the previous statement,
idis this server's unique ID (see Section 18.6.2, “General Requirements for MySQL Cluster Replication”). This starts the server's mysqld process with binary logging enabled using the proper logging format.NoteYou can also start the master with
--binlog-format=MIXED, in which case row-based replication is used automatically when replicating between clusters.STATEMENTbased binary logging is not supported for MySQL Cluster Replication (see Section 18.6.2, “General Requirements for MySQL Cluster Replication”).Start the MySQL replication slave server as shown here:
shell
S>mysqld --ndbcluster --server-id=id&In the command just shown,
idis the slave server's unique ID. It is not necessary to enable logging on the replication slave.NoteYou should use the
--skip-slave-startoption with this command or else you should includeskip-slave-startin the slave server'smy.cnffile, unless you want replication to begin immediately. With the use of this option, the start of replication is delayed until the appropriateSTART SLAVEstatement has been issued, as explained in Step 4 below.It is necessary to synchronize the slave server with the master server's replication binary log. If binary logging has not previously been running on the master, run the following statement on the slave:
mysql
S>CHANGE MASTER TO->MASTER_LOG_FILE='',->MASTER_LOG_POS=4;This instructs the slave to begin reading the master's binary log from the log's starting point. Otherwise—that is, if you are loading data from the master using a backup—see Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”, for information on how to obtain the correct values to use for
MASTER_LOG_FILEandMASTER_LOG_POSin such cases.Finally, you must instruct the slave to begin applying replication by issuing this command from the mysql client on the replication slave:
mysql
S>START SLAVE;This also initiates the transmission of replication data from the master to the slave.
It is also possible to use two replication channels, in a manner similar to the procedure described in the next section; the differences between this and using a single replication channel are covered in Section 18.6.7, “Using Two Replication Channels for MySQL Cluster Replication”.
It is also possible to improve cluster replication performance by
enabling batched updates.
This can be accomplished by setting the
slave_allow_batching system
variable on the slave mysqld processes.
Normally, updates are applied as soon as they are received.
However, the use of batching causes updates to be applied in 32 KB
batches, which can result in higher throughput and less CPU usage,
particularly where individual updates are relatively small.
Slave batching works on a per-epoch basis; updates belonging to more than one transaction can be sent as part of the same batch.
All outstanding updates are applied when the end of an epoch is reached, even if the updates total less than 32 KB.
Batching can be turned on and off at runtime. To activate it at runtime, you can use either of these two statements:
SET GLOBAL slave_allow_batching = 1; SET GLOBAL slave_allow_batching = ON;
If a particular batch causes problems (such as a statement whose effects do not appear to be replicated correctly), slave batching can be deactivated using either of the following statements:
SET GLOBAL slave_allow_batching = 0; SET GLOBAL slave_allow_batching = OFF;
You can check whether slave batching is currently being used by
means of an appropriate SHOW
VARIABLES statement, like this one:
mysql> SHOW VARIABLES LIKE 'slave%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| slave_allow_batching | ON |
| slave_compressed_protocol | OFF |
| slave_load_tmpdir | /tmp |
| slave_net_timeout | 3600 |
| slave_skip_errors | OFF |
| slave_transaction_retries | 10 |
+---------------------------+-------+
6 rows in set (0.00 sec)
In a more complete example scenario, we envision two replication channels to provide redundancy and thereby guard against possible failure of a single replication channel. This requires a total of four replication servers, two masters for the master cluster and two slave servers for the slave cluster. For purposes of the discussion that follows, we assume that unique identifiers are assigned as shown here:
| Server ID | Description |
|---|---|
| 1 | Master - primary replication channel (M) |
| 2 | Master - secondary replication channel (M') |
| 3 | Slave - primary replication channel (S) |
| 4 | Slave - secondary replication channel (S') |
Setting up replication with two channels is not radically
different from setting up a single replication channel. First, the
mysqld processes for the primary and secondary
replication masters must be started, followed by those for the
primary and secondary slaves. Then the replication processes may
be initiated by issuing the START
SLAVE statement on each of the slaves. The commands and
the order in which they need to be issued are shown here:
Start the primary replication master:
shell
M>mysqld --ndbcluster --server-id=1 \--log-bin &For MySQL Cluster NDB 7.2.12 and earlier, you should use the following (Bug #16417224):
shell
M>mysqld --ndbcluster --server-id=1 \--log-bin --binlog-format=ROW &Start the secondary replication master:
shell
M'>mysqld --ndbcluster --server-id=2 \--log-bin &For MySQL Cluster NDB 7.2.12 and earlier, you should use this instead (Bug #16417224):
shell
M'>mysqld --ndbcluster --server-id=2 \--log-bin --binlog-format=ROW &Start the primary replication slave server:
shell
S>mysqld --ndbcluster --server-id=3 \--skip-slave-start &Start the secondary replication slave:
shell
S'>mysqld --ndbcluster --server-id=4 \--skip-slave-start &Finally, initiate replication on the primary channel by executing the
START SLAVEstatement on the primary slave as shown here:mysql
S>START SLAVE;WarningOnly the primary channel is to be started at this point. The secondary replication channel is to be started only in the event that the primary replication channel fails, as described in Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”. Running multiple replication channels simultaneously can result in unwanted duplicate records being created on the replication slaves.
As mentioned previously, it is not necessary to enable binary logging on replication slaves.
In the event that the primary Cluster replication process fails, it is possible to switch over to the secondary replication channel. The following procedure describes the steps required to accomplish this.
Obtain the time of the most recent global checkpoint (GCP). That is, you need to determine the most recent epoch from the
ndb_apply_statustable on the slave cluster, which can be found using the following query:mysql
S'>SELECT @latest:=MAX(epoch)->FROM mysql.ndb_apply_status;In a circular replication topology, with a master and a slave running on each host, when you are using
ndb_log_apply_status=1, MySQL Cluster epochs are written in the slave binary logs. This means that thendb_apply_statustable contains information for the slave on this host as well as for any other host which acts as a slave of the master running on this host.In this case, you need to determine the latest epoch on this slave to the exclusion of any epochs from any other slaves in this slave's binary log that were not listed in the
IGNORE_SERVER_IDSoptions of theCHANGE MASTER TOstatement used to set up this slave. The reason for excluding such epochs is that rows in themysql.ndb_apply_statustable whose server IDs have a match in theIGNORE_SERVER_IDSlist used with the CHANGE MASTER TO statement used to prepare this slave's master are also considered to be from local servers, in addition to those having the slave's own server ID. You can retrieve this list asReplicate_Ignore_Server_Idsfrom the output ofSHOW SLAVE STATUS. We assume that you have obtained this list and are substituting it forignore_server_idsin the query shown here, which like the previous version of the query, selects the greatest epoch into a variable named@latest:mysql
S'>SELECT @latest:=MAX(epoch)->FROM mysql.ndb_apply_status->WHERE server_id NOT IN (ignore_server_ids);In some cases, it may be simpler or more efficient (or both) to use a list of the server IDs to be included and
server_id INin theserver_id_listWHEREcondition of the preceding query.Using the information obtained from the query shown in Step 1, obtain the corresponding records from the
ndb_binlog_indextable on the master cluster.Prior to MySQL Cluster NDB 7.2.6, you should use the following query to accomplish this task:
mysql
M'>SELECT->@file:=SUBSTRING_INDEX(File, '/', -1),->@pos:=Position->FROM mysql.ndb_binlog_index->WHERE epoch > @latest->ORDER BY epoch ASC LIMIT 1;Beginning with MySQL Cluster NDB 7.2.6, you can take advantage of the improved binary logging of DDL statements implemented in those and later versions by using the following query to obtain the needed records from the master's
ndb_binlog_indextable:mysql
M'>SELECT->@file:=SUBSTRING_INDEX(next_file, '/', -1),->@pos:=next_position->FROM mysql.ndb_binlog_index->WHERE epoch = @latest->ORDER BY epoch ASC LIMIT 1;In either case, these are the records saved on the master since the failure of the primary replication channel. We have employed a user variable
@latesthere to represent the value obtained in Step 1. Of course, it is not possible for one mysqld instance to access user variables set on another server instance directly. These values must be “plugged in” to the second query manually or in application code.ImportantIf (and only if) you use the second of the two queries just shown against
ndb_binlog_index(that is, the query that employs thenext_positionandnext_filecolumns), you must ensure that the slave mysqld is started with--slave-skip-errors=ddl_exist_errorsbefore executingSTART SLAVE. Otherwise, replication may stop with duplicate DDL errors.Now it is possible to synchronize the secondary channel by running the following query on the secondary slave server:
mysql
S'>CHANGE MASTER TO->MASTER_LOG_FILE='@file',->MASTER_LOG_POS=@pos;Again we have employed user variables (in this case
@fileand@pos) to represent the values obtained in Step 2 and applied in Step 3; in practice these values must be inserted manually or using application code that can access both of the servers involved.Note@fileis a string value such as'/var/log/mysql/replication-master-bin.00001', and so must be quoted when used in SQL or application code. However, the value represented by@posmust not be quoted. Although MySQL normally attempts to convert strings to numbers, this case is an exception.You can now initiate replication on the secondary channel by issuing the appropriate command on the secondary slave mysqld:
mysql
S'>START SLAVE;
Once the secondary replication channel is active, you can investigate the failure of the primary and effect repairs. The precise actions required to do this will depend upon the reasons for which the primary channel failed.
The secondary replication channel is to be started only if and when the primary replication channel has failed. Running multiple replication channels simultaneously can result in unwanted duplicate records being created on the replication slaves.
If the failure is limited to a single server, it should (in
theory) be possible to replicate from M
to S', or from
M' to S;
however, this has not yet been tested.
This section discusses making backups and restoring from them using MySQL Cluster replication. We assume that the replication servers have already been configured as covered previously (see Section 18.6.5, “Preparing the MySQL Cluster for Replication”, and the sections immediately following). This having been done, the procedure for making a backup and then restoring from it is as follows:
There are two different methods by which the backup may be started.
Method A. This method requires that the cluster backup process was previously enabled on the master server, prior to starting the replication process. This can be done by including the following line in a
[mysql_cluster]section in themy.cnf file, wheremanagement_hostis the IP address or host name of theNDBmanagement server for the master cluster, andportis the management server's port number:ndb-connectstring=
management_host[:port]NoteThe port number needs to be specified only if the default port (1186) is not being used. See Section 18.2.3, “Initial Configuration of MySQL Cluster”, for more information about ports and port allocation in MySQL Cluster.
In this case, the backup can be started by executing this statement on the replication master:
shell
M>ndb_mgm -e "START BACKUP"Method B. If the
my.cnffile does not specify where to find the management host, you can start the backup process by passing this information to theNDBmanagement client as part of theSTART BACKUPcommand. This can be done as shown here, wheremanagement_hostandportare the host name and port number of the management server:shell
M>ndb_mgmmanagement_host:port-e "START BACKUP"In our scenario as outlined earlier (see Section 18.6.5, “Preparing the MySQL Cluster for Replication”), this would be executed as follows:
shell
M>ndb_mgm rep-master:1186 -e "START BACKUP"
Copy the cluster backup files to the slave that is being brought on line. Each system running an ndbd process for the master cluster will have cluster backup files located on it, and all of these files must be copied to the slave to ensure a successful restore. The backup files can be copied into any directory on the computer where the slave management host resides, so long as the MySQL and NDB binaries have read permissions in that directory. In this case, we will assume that these files have been copied into the directory
/var/BACKUPS/BACKUP-1.It is not necessary that the slave cluster have the same number of ndbd processes (data nodes) as the master; however, it is highly recommended this number be the same. It is necessary that the slave be started with the
--skip-slave-startoption, to prevent premature startup of the replication process.Create any databases on the slave cluster that are present on the master cluster that are to be replicated to the slave.
ImportantA
CREATE DATABASE(orCREATE SCHEMA) statement corresponding to each database to be replicated must be executed on each SQL node in the slave cluster.Reset the slave cluster using this statement in the MySQL Monitor:
mysql
S>RESET SLAVE;You can now start the cluster restoration process on the replication slave using the ndb_restore command for each backup file in turn. For the first of these, it is necessary to include the
-moption to restore the cluster metadata:shell
S>ndb_restore -cslave_host:port-nnode-id\-bbackup-id-m -rdirdiris the path to the directory where the backup files have been placed on the replication slave. For the ndb_restore commands corresponding to the remaining backup files, the-moption should not be used.For restoring from a master cluster with four data nodes (as shown in the figure in Section 18.6, “MySQL Cluster Replication”) where the backup files have been copied to the directory
/var/BACKUPS/BACKUP-1, the proper sequence of commands to be executed on the slave might look like this:shell
S>ndb_restore -c rep-slave:1186 -n 2 -b 1 -m \-r ./var/BACKUPS/BACKUP-1shellS>ndb_restore -c rep-slave:1186 -n 3 -b 1 \-r ./var/BACKUPS/BACKUP-1shellS>ndb_restore -c rep-slave:1186 -n 4 -b 1 \-r ./var/BACKUPS/BACKUP-1shellS>ndb_restore -c rep-slave:1186 -n 5 -b 1 -e \-r ./var/BACKUPS/BACKUP-1ImportantThe
-e(or--restore_epoch) option in the final invocation of ndb_restore in this example is required in order that the epoch is written to the slavemysql.ndb_apply_status. Without this information, the slave will not be able to synchronize properly with the master. (See Section 18.4.20, “ndb_restore — Restore a MySQL Cluster Backup”.)Now you need to obtain the most recent epoch from the
ndb_apply_statustable on the slave (as discussed in Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”):mysql
S>SELECT @latest:=MAX(epoch)FROM mysql.ndb_apply_status;Using
@latestas the epoch value obtained in the previous step, you can obtain the correct starting position@posin the correct binary log file@filefrom the master'smysql.ndb_binlog_indextable using the query shown here:mysql
M>SELECT->@file:=SUBSTRING_INDEX(File, '/', -1),->@pos:=Position->FROM mysql.ndb_binlog_index->WHERE epoch > @latest->ORDER BY epoch ASC LIMIT 1;In the event that there is currently no replication traffic, you can get this information by running
SHOW MASTER STATUSon the master and using the value in thePositioncolumn for the file whose name has the suffix with the greatest value for all files shown in theFilecolumn. However, in this case, you must determine this and supply it in the next step manually or by parsing the output with a script.Using the values obtained in the previous step, you can now issue the appropriate
CHANGE MASTER TOstatement in the slave's mysql client:mysql
S>CHANGE MASTER TO->MASTER_LOG_FILE='@file',->MASTER_LOG_POS=@pos;Now that the slave “knows” from what point in which binary log file to start reading data from the master, you can cause the slave to begin replicating with this standard MySQL statement:
mysql
S>START SLAVE;
To perform a backup and restore on a second replication channel, it is necessary only to repeat these steps, substituting the host names and IDs of the secondary master and slave for those of the primary master and slave replication servers where appropriate, and running the preceding statements on them.
For additional information on performing Cluster backups and restoring Cluster from backups, see Section 18.5.3, “Online Backup of MySQL Cluster”.
It is possible to automate much of the process described in the
previous section (see
Section 18.6.9, “MySQL Cluster Backups With MySQL Cluster Replication”). The
following Perl script reset-slave.pl serves
as an example of how you can do this.
#!/user/bin/perl -w
# file: reset-slave.pl
# Copyright ©2005 MySQL AB
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
# You should have received a copy of the GNU General Public License
# along with this program; if not, write to:
# Free Software Foundation, Inc.
# 59 Temple Place, Suite 330
# Boston, MA 02111-1307 USA
#
# Version 1.1
######################## Includes ###############################
use DBI;
######################## Globals ################################
my $m_host='';
my $m_port='';
my $m_user='';
my $m_pass='';
my $s_host='';
my $s_port='';
my $s_user='';
my $s_pass='';
my $dbhM='';
my $dbhS='';
####################### Sub Prototypes ##########################
sub CollectCommandPromptInfo;
sub ConnectToDatabases;
sub DisconnectFromDatabases;
sub GetSlaveEpoch;
sub GetMasterInfo;
sub UpdateSlave;
######################## Program Main ###########################
CollectCommandPromptInfo;
ConnectToDatabases;
GetSlaveEpoch;
GetMasterInfo;
UpdateSlave;
DisconnectFromDatabases;
################## Collect Command Prompt Info ##################
sub CollectCommandPromptInfo
{
### Check that user has supplied correct number of command line args
die "Usage:\n
reset-slave >master MySQL host< >master MySQL port< \n
>master user< >master pass< >slave MySQL host< \n
>slave MySQL port< >slave user< >slave pass< \n
All 8 arguments must be passed. Use BLANK for NULL passwords\n"
unless @ARGV == 8;
$m_host = $ARGV[0];
$m_port = $ARGV[1];
$m_user = $ARGV[2];
$m_pass = $ARGV[3];
$s_host = $ARGV[4];
$s_port = $ARGV[5];
$s_user = $ARGV[6];
$s_pass = $ARGV[7];
if ($m_pass eq "BLANK") { $m_pass = '';}
if ($s_pass eq "BLANK") { $s_pass = '';}
}
############### Make connections to both databases #############
sub ConnectToDatabases
{
### Connect to both master and slave cluster databases
### Connect to master
$dbhM
= DBI->connect(
"dbi:mysql:database=mysql;host=$m_host;port=$m_port",
"$m_user", "$m_pass")
or die "Can't connect to Master Cluster MySQL process!
Error: $DBI::errstr\n";
### Connect to slave
$dbhS
= DBI->connect(
"dbi:mysql:database=mysql;host=$s_host",
"$s_user", "$s_pass")
or die "Can't connect to Slave Cluster MySQL process!
Error: $DBI::errstr\n";
}
################ Disconnect from both databases ################
sub DisconnectFromDatabases
{
### Disconnect from master
$dbhM->disconnect
or warn " Disconnection failed: $DBI::errstr\n";
### Disconnect from slave
$dbhS->disconnect
or warn " Disconnection failed: $DBI::errstr\n";
}
###################### Find the last good GCI ##################
sub GetSlaveEpoch
{
$sth = $dbhS->prepare("SELECT MAX(epoch)
FROM mysql.ndb_apply_status;")
or die "Error while preparing to select epoch from slave: ",
$dbhS->errstr;
$sth->execute
or die "Selecting epoch from slave error: ", $sth->errstr;
$sth->bind_col (1, \$epoch);
$sth->fetch;
print "\tSlave Epoch = $epoch\n";
$sth->finish;
}
####### Find the position of the last GCI in the binary log ########
sub GetMasterInfo
{
$sth = $dbhM->prepare("SELECT
SUBSTRING_INDEX(File, '/', -1), Position
FROM mysql.ndb_binlog_index
WHERE epoch > $epoch
ORDER BY epoch ASC LIMIT 1;")
or die "Prepare to select from master error: ", $dbhM->errstr;
$sth->execute
or die "Selecting from master error: ", $sth->errstr;
$sth->bind_col (1, \$binlog);
$sth->bind_col (2, \$binpos);
$sth->fetch;
print "\tMaster binary log = $binlog\n";
print "\tMaster binary log position = $binpos\n";
$sth->finish;
}
########## Set the slave to process from that location #########
sub UpdateSlave
{
$sth = $dbhS->prepare("CHANGE MASTER TO
MASTER_LOG_FILE='$binlog',
MASTER_LOG_POS=$binpos;")
or die "Prepare to CHANGE MASTER error: ", $dbhS->errstr;
$sth->execute
or die "CHANGE MASTER on slave error: ", $sth->errstr;
$sth->finish;
print "\tSlave has been updated. You may now start the slave.\n";
}
# end reset-slave.pl
Point-in-time
recovery—that is, recovery of data changes made since a
given point in time—is performed after restoring a full
backup that returns the server to its state when the backup was
made. Performing point-in-time recovery of MySQL Cluster tables
with MySQL Cluster and MySQL Cluster Replication can be
accomplished using a native NDB
data backup (taken by issuing CREATE BACKUP
in the ndb_mgm client) and restoring the
ndb_binlog_index table (from a dump made
using mysqldump).
To perform point-in-time recovery of MySQL Cluster, it is necessary to follow the steps shown here:
Back up all
NDBdatabases in the cluster, using theSTART BACKUPcommand in the ndb_mgm client (see Section 18.5.3, “Online Backup of MySQL Cluster”).At some later point, prior to restoring the cluster, make a backup of the
mysql.ndb_binlog_indextable. It is probably simplest to use mysqldump for this task. Also back up the binary log files at this time.This backup should be updated regularly—perhaps even hourly—depending on your needs.
(Catastrophic failure or error occurs.)
Locate the last known good backup.
Clear the data node file systems (using ndbd
--initialor ndbmtd--initial).NoteMySQL Cluster Disk Data tablespace and log files are not removed by
--initial. You must delete these manually.Use
DROP TABLEorTRUNCATE TABLEwith themysql.ndb_binlog_indextable.Execute ndb_restore, restoring all data. You must include the
--restore_epochoption when you run ndb_restore, so that thendb_apply_statustable is populated correctly. (See Section 18.4.20, “ndb_restore — Restore a MySQL Cluster Backup”, for more information.)Restore the
ndb_binlog_indextable from the output of mysqldump and restore the binary log files from backup, if necessary.Find the epoch applied most recently—that is, the maximum
epochcolumn value in thendb_apply_statustable—as the user variable@LATEST_EPOCH(emphasized):SELECT @LATEST_EPOCH:=MAX(epoch) FROM mysql.ndb_apply_status;Find the latest binary log file (
@FIRST_FILE) and position (Positioncolumn value) within this file that correspond to@LATEST_EPOCHin thendb_binlog_indextable:SELECT Position, @FIRST_FILE:=File FROM mysql.ndb_binlog_index WHERE epoch > @LATEST_EPOCH ORDER BY epoch ASC LIMIT 1;
Using mysqlbinlog, replay the binary log events from the given file and position up to the point of the failure. (See Section 4.6.7, “mysqlbinlog — Utility for Processing Binary Log Files”.)
See also Section 7.5, “Point-in-Time (Incremental) Recovery Using the Binary Log”, for more information about the binary log, replication, and incremental recovery.
It is possible to use MySQL Cluster in multi-master replication, including circular replication between a number of MySQL Clusters.
Circular replication example. In the next few paragraphs we consider the example of a replication setup involving three MySQL Clusters numbered 1, 2, and 3, in which Cluster 1 acts as the replication master for Cluster 2, Cluster 2 acts as the master for Cluster 3, and Cluster 3 acts as the master for Cluster 1. Each cluster has two SQL nodes, with SQL nodes A and B belonging to Cluster 1, SQL nodes C and D belonging to Cluster 2, and SQL nodes E and F belonging to Cluster 3.
Circular replication using these clusters is supported as long as the following conditions are met:
The SQL nodes on all masters and slaves are the same
All SQL nodes acting as replication masters and slaves are started using the
--log-slave-updatesoption
This type of circular replication setup is shown in the following diagram:
In this scenario, SQL node A in Cluster 1 replicates to SQL node C in Cluster 2; SQL node C replicates to SQL node E in Cluster 3; SQL node E replicates to SQL node A. In other words, the replication line (indicated by the red arrows in the diagram) directly connects all SQL nodes used as replication masters and slaves.
It is also possible to set up circular replication in such a way that not all master SQL nodes are also slaves, as shown here:
In this case, different SQL nodes in each cluster are used as
replication masters and slaves. However, you must
not start any of the SQL nodes using
--log-slave-updates. This type of
circular replication scheme for MySQL Cluster, in which the line
of replication (again indicated by the red arrows in the diagram)
is discontinuous, should be possible, but it should be noted that
it has not yet been thoroughly tested and must therefore still be
considered experimental.
Using NDB-native backup and restore to initialize a slave MySQL Cluster.
When setting up circular replication, it is possible to
initialize the slave cluster by using the management client
BACKUP command on one MySQL Cluster to create
a backup and then applying this backup on another MySQL Cluster
using ndb_restore. However, this does not
automatically create binary logs on the second MySQL
Cluster's SQL node acting as the replication slave. In
order to cause the binary logs to be created, you must issue a
SHOW TABLES statement on that SQL
node; this should be done prior to running
START SLAVE.
This is a known issue which we intend to address in a future release.
Multi-master failover example. In this section, we discuss failover in a multi-master MySQL Cluster replication setup with three MySQL Clusters having server IDs 1, 2, and 3. In this scenario, Cluster 1 replicates to Clusters 2 and 3; Cluster 2 also replicates to Cluster 3. This relationship is shown here:
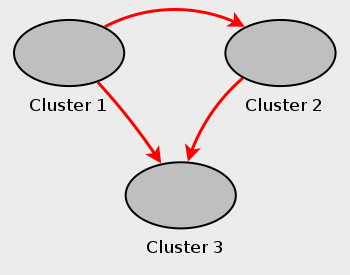
In other words, data replicates from Cluster 1 to Cluster 3 through 2 different routes: directly, and by way of Cluster 2.
Not all MySQL servers taking part in multi-master replication must act as both master and slave, and a given MySQL Cluster might use different SQL nodes for different replication channels. Such a case is shown here:
MySQL servers acting as replication slaves must be run with the
--log-slave-updates option. Which
mysqld processes require this option is also
shown in the preceding diagram.
Using the --log-slave-updates
option has no effect on servers not being run as replication
slaves.
The need for failover arises when one of the replicating clusters goes down. In this example, we consider the case where Cluster 1 is lost to service, and so Cluster 3 loses 2 sources of updates from Cluster 1. Because replication between MySQL Clusters is asynchronous, there is no guarantee that Cluster 3's updates originating directly from Cluster 1 are more recent than those received through Cluster 2. You can handle this by ensuring that Cluster 3 catches up to Cluster 2 with regard to updates from Cluster 1. In terms of MySQL servers, this means that you need to replicate any outstanding updates from MySQL server C to server F.
On server C, perform the following queries:
mysqlC> SELECT @latest:=MAX(epoch)
-> FROM mysql.ndb_apply_status
-> WHERE server_id=1;
mysqlC> SELECT
-> @file:=SUBSTRING_INDEX(File, '/', -1),
-> @pos:=Position
-> FROM mysql.ndb_binlog_index
-> WHERE orig_epoch >= @latest
-> AND orig_server_id = 1
-> ORDER BY epoch ASC LIMIT 1;
You can improve the performance of this query, and thus likely
speed up failover times significantly, by adding the appropriate
index to the ndb_binlog_index table. See
Section 18.6.4, “MySQL Cluster Replication Schema and Tables”, for more
information.
Copy over the values for @file and
@pos manually from server C to server F
(or have your application perform the equivalent). Then, on server
F, execute the following CHANGE MASTER
TO statement:
mysqlF> CHANGE MASTER TO
-> MASTER_HOST = 'serverC'
-> MASTER_LOG_FILE='@file',
-> MASTER_LOG_POS=@pos;
Once this has been done, you can issue a
START SLAVE statement on MySQL
server F, and any missing updates originating from server B will
be replicated to server F.
The CHANGE MASTER TO statement also
supports an IGNORE_SERVER_IDS option which
takes a comma-separated list of server IDs and causes events
originating from the corresponding servers to be ignored. For more
information, see Section 13.4.2.1, “CHANGE MASTER TO Syntax”, and
Section 13.7.5.35, “SHOW SLAVE STATUS Syntax”. For information about how
this option intereacts with the
ndb_log_apply_status variable,
see Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”.
When using a replication setup involving multiple masters (including circular replication), it is possible that different masters may try to update the same row on the slave with different data. Conflict resolution in MySQL Cluster Replication provides a means of resolving such conflicts by permitting a user-defined resolution column to be used to determine whether or not an update on a given master should be applied on the slave.
Some types of conflict resolution supported by MySQL Cluster
(NDB$OLD(), NDB$MAX(),
NDB$MAX_DELETE_WIN()) implement this
user-defined column as a “timestamp” column (although
its type cannot be TIMESTAMP, as
explained later in this section). These types of conflict
resolution are always applied a row-by-row basis rather than a
transactional basis. The epoch-based conflict resolution functions
introduced in MySQL Cluster NDB 7.2.1
(NDB$EPOCH() and
NDB$EPOCH_TRANS()) compare the order in which
epochs are replicated (and thus these functions are
transactional). Different methods can be used to compare
resolution column values on the slave when conflicts occur, as
explained later in this section; the method used can be set on a
per-table basis.
You should also keep in mind that it is the application's responsibility to ensure that the resolution column is correctly populated with relevant values, so that the resolution function can make the appropriate choice when determining whether to apply an update.
Requirements. Preparations for conflict resolution must be made on both the master and the slave. These tasks are described in the following list:
On the master writing the binary logs, you must determine which columns are sent (all columns or only those that have been updated). This is done for the MySQL Server as a whole by applying the mysqld startup option
--ndb-log-updated-only(described later in this section) or on a per-table basis by entries in themysql.ndb_replicationtable (see The ndb_replication system table).NoteIf you are replicating tables with very large columns (such as
TEXTorBLOBcolumns),--ndb-log-updated-onlycan also be useful for reducing the size of the master and slave binary logs and avoiding possible replication failures due to exceedingmax_allowed_packet.See Section 17.4.1.22, “Replication and max_allowed_packet”, for more information about this issue.
On the slave, you must determine which type of conflict resolution to apply (“latest timestamp wins”, “same timestamp wins”, “primary wins”, “primary wins, complete transaction”, or none). This is done using the
mysql.ndb_replicationsystem table, on a per-table basis (see The ndb_replication system table).Prior to MySQL Cluster NDB 7.2.5, conflict detection and resolution did not always work properly unless set up for
NDBtables created on the same server only (Bug #13578660).
When using the functions NDB$OLD(),
NDB$MAX(), and
NDB$MAX_DELETE_WIN() for timestamp-based
conflict resolution, we often refer to the column used for
determining updates as a “timestamp” column. However,
the data type of this column is never
TIMESTAMP; instead, its data type
should be INT
(INTEGER) or
BIGINT. The
“timestamp” column should also be
UNSIGNED and NOT NULL.
The NDB$EPOCH() and
NDB$EPOCH_TRANS() functions discussed later in
this section work by comparing the relative order of replication
epochs applied on a primary and secondary MySQL Cluster, and do
not make use of timestamps.
Master column control.
We can see update operations in terms of “before”
and “after” images—that is, the states of the
table before and after the update is applied. Normally, when
updating a table with a primary key, the “before”
image is not of great interest; however, when we need to
determine on a per-update basis whether or not to use the
updated values on a replication slave, we need to make sure that
both images are written to the master's binary log. This is
done with the
--ndb-log-update-as-write option
for mysqld, as described later in this
section.
Whether logging of complete rows or of updated columns only is done is decided when the MySQL server is started, and cannot be changed online; you must either restart mysqld, or start a new mysqld instance with different logging options.
Logging Full or Partial Rows (--ndb-log-updated-only Option)
| Command-Line Format | --ndb-log-updated-only | ||
| System Variable | Name | ndb_log_updated_only | |
| Variable Scope | Global | ||
| Dynamic Variable | Yes | ||
| Permitted Values | Type | boolean | |
| Default | ON | ||
For purposes of conflict resolution, there are two basic methods
of logging rows, as determined by the setting of the
--ndb-log-updated-only option for
mysqld:
Log complete rows
Log only column data that has been updated—that is, column data whose value has been set, regardless of whether or not this value was actually changed. This is the default behavior.
It is usually sufficient—and more efficient—to log
updated columns only; however, if you need to log full rows, you
can do so by setting
--ndb-log-updated-only to
0 or OFF.
--ndb-log-update-as-write Option: Logging Changed Data as Updates
| Command-Line Format | --ndb-log-update-as-write | ||
| System Variable | Name | ndb_log_update_as_write | |
| Variable Scope | Global | ||
| Dynamic Variable | Yes | ||
| Permitted Values | Type | boolean | |
| Default | ON | ||
The setting of the MySQL Server's
--ndb-log-update-as-write option
determines whether logging is performed with or without the
“before” image. Because conflict resolution is done
in the MySQL Server's update handler, it is necessary to
control logging on the master such that updates are updates and
not writes; that is, such that updates are treated as changes in
existing rows rather than the writing of new rows (even though
these replace existing rows). This option is turned on by default;
in other words, updates are treated as writes. (That is, updates
are by default written as write_row events in
the binary log, rather than as update_row
events.)
To turn off the option, start the master mysqld
with --ndb-log-update-as-write=0 or
--ndb-log-update-as-write=OFF. You must do this
when replicating from NDB tables to tables using a different
storage engine; see
Replication from NDB to other storage engines.
Conflict resolution control.
Conflict resolution is usually enabled on the server where
conflicts can occur. Like logging method selection, it is
enabled by entries in the
mysql.ndb_replication table.
The ndb_replication system table.
To enable conflict resolution, it is necessary to create an
ndb_replication table in the
mysql system database on the master, the
slave, or both, depending on the conflict resolution type and
method to be employed. This table is used to control logging and
conflict resolution functions on a per-table basis, and has one
row per table involved in replication.
ndb_replication is created and filled with
control information on the server where the conflict is to be
resolved. In a simple master-slave setup where data can also be
changed locally on the slave this will typically be the slave.
In a more complex master-master (2-way) replication schema this
will usually be all of the masters involved. Each row in
mysql.ndb_replication corresponds to a table
being replicated, and specifies how to log and resolve conflicts
(that is, which conflict resolution function, if any, to use)
for that table. The definition of the
mysql.ndb_replication table is shown here:
CREATE TABLE mysql.ndb_replication (
db VARBINARY(63),
table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
conflict_fn VARBINARY(128),
PRIMARY KEY USING HASH (db, table_name, server_id)
) ENGINE=NDB
PARTITION BY KEY(db,table_name);
The columns in this table are described in the next few paragraphs.
db. The name of the database containing the table to be replicated.
Beginning with MySQL Cluster NDB 7.2.5, you may employ either or
both of the wildcards _ and
% as part of the database name. Matching is
similar to what is implemented for the
LIKE operator.
table_name. The name of the table to be replicated.
Beginning with MySQL Cluster NDB 7.2.5, the table name may include
either or both of the wildcards _ and
%. Matching is similar to what is implemented
for the LIKE operator.
server_id. The unique server ID of the MySQL instance (SQL node) where the table resides.
binlog_type. The type of binary logging to be employed. This is determined as shown in the following table:
| Value | Internal Value | Description |
|---|---|---|
| 0 | NBT_DEFAULT | Use server default |
| 1 | NBT_NO_LOGGING | Do not log this table in the binary log |
| 2 | NBT_UPDATED_ONLY | Only updated attributes are logged |
| 3 | NBT_FULL | Log full row, even if not updated (MySQL server default behavior) |
| 4 | NBT_USE_UPDATE | (For generating NBT_UPDATED_ONLY_USE_UPDATE and
NBT_FULL_USE_UPDATE values
only—not intended for separate use) |
| 5 | [Not used] | --- |
| 6 | NBT_UPDATED_ONLY_USE_UPDATE (equal to
NBT_UPDATED_ONLY | NBT_USE_UPDATE) | Use updated attributes, even if values are unchanged |
| 7 | NBT_FULL_USE_UPDATE (equal to NBT_FULL |
NBT_USE_UPDATE) | Use full row, even if values are unchanged |
conflict_fn. The conflict resolution function to be applied. This function must be specified as one of those shown in the following list:
NDB$EPOCH() and NDB$EPOCH_TRANS() (MySQL Cluster NDB 7.2.1 and later)
NDB$EPOCH_TRANS() (MySQL Cluster NDB 7.2.1 and later)
NULL: Indicates that conflict resolution is not to be used for the corresponding table.
These functions are described in the next few paragraphs.
NDB$OLD(column_name).
If the value of column_name is the
same on both the master and the slave, then the update is
applied; otherwise, the update is not applied on the slave and
an exception is written to the log. This is illustrated by the
following pseudocode:
if (master_old_column_value==slave_current_column_value) apply_update(); else log_exception();
This function can be used for “same value wins” conflict resolution. This type of conflict resolution ensures that updates are not applied on the slave from the wrong master.
The column value from the master's “before” image is used by this function.
NDB$MAX(column_name). If the “timestamp” column value for a given row coming from the master is higher than that on the slave, it is applied; otherwise it is not applied on the slave. This is illustrated by the following pseudocode:
if (master_new_column_value>slave_current_column_value) apply_update();
This function can be used for “greatest timestamp wins” conflict resolution. This type of conflict resolution ensures that, in the event of a conflict, the version of the row that was most recently updated is the version that persists.
The column value from the master's “after” image is used by this function.
NDB$MAX_DELETE_WIN().
This is a variation on NDB$MAX(). Due to the
fact that no timestamp is available for a delete operation, a
delete using NDB$MAX() is in fact processed
as NDB$OLD. However, for some use cases, this
is not optimal. For NDB$MAX_DELETE_WIN(), if
the “timestamp” column value for a given row adding
or updating an existing row coming from the master is higher
than that on the slave, it is applied. However, delete
operations are treated as always having the higher value. This
is illustrated in the following pseudocode:
if ( (master_new_column_value>slave_current_column_value) ||operation.type== "delete") apply_update();
This function can be used for “greatest timestamp, delete wins” conflict resolution. This type of conflict resolution ensures that, in the event of a conflict, the version of the row that was deleted or (otherwise) most recently updated is the version that persists.
As with NDB$MAX(), the column value from the
master's “after” image is the value used by
this function.
NDB$EPOCH() and NDB$EPOCH_TRANS().
The NDB$EPOCH() function, available beginning
with MySQL Cluster NDB 7.2.1, tracks the order in which
replicated epochs are applied on a slave MySQL Cluster relative
to changes originating on the slave. This relative ordering is
used to determine whether changes originating on the slave are
concurrent with any changes that originate locally, and are
therefore potentially in conflict.
Most of what follows in the description of
NDB$EPOCH() also applies to
NDB$EPOCH_TRANS(). Any exceptions are noted in
the text.
NDB$EPOCH() is asymmetric, operating on one
MySQL Cluster in a two-cluster circular replication configuration
(sometimes referred to as “active-active”
replication). We refer here to cluster on which it operates as the
primary, and the other as the secondary. The slave on the primary
is responsible for detecting and handling conflicts, while the
slave on the secondary is not involved in any conflict detection
or handling.
When the slave on the primary detects conflicts, it injects events into its own binary log to compensate for these; this ensures that the secondary MySQL Cluster eventually realigns itself with the primary and so keeps the primary and secondary from diverging. This compensation and realignment mechanism requires that the primary MySQL Cluster always wins any conflicts with the secondary—that is, that the primary's changes are always used rather than those from the secondary in event of a conflict. This “primary always wins” rule has the following implications:
Operations that change data, once committed on the primary, are fully persistent and will not be undone or rolled back by conflict detection and resolution.
Data read from the primary is fully consistent. Any changes committed on the Primary (locally or from the slave) will not be reverted later.
Operations that change data on the secondary may later be reverted if the primary determines that they are in conflict.
Individual rows read on the secondary are self-consistent at all times, each row always reflecting either a state committed by the secondary, or one committed by the primary.
Sets of rows read on the secondary may not necessarily be consistent at a given single point in time. For
NDB$EPOCH_TRANS(), this is a transient state; forNDB$EPOCH(), it can be a persistent state.Assuming a period of sufficient length without any conflicts, all data on the secondary MySQL Cluster (eventually) becomes consistent with the primary's data.
NDB$EPOCH() and
NDB$EPOCH_TRANS() do not require any user
schema modifications, or application changes to provide conflict
detection. However, careful thought must be given to the schema
used, and the access patterns used, to verify that the complete
system behaves within specified limits.
Each of the NDB$EPOCH() and
NDB$EPOCH_TRANS() functions can take an
optional parameter; this is the number of bits to use to represent
the lower 32 bits of the epoch, and should be set to no less than
CEIL( LOG2(TimeBetweenGlobalCheckpoints/TimeBetweenEpochs), 1)
For the default values of these configuration parameters (2000 and
100 milliseconds, respectively), this gives a value of 5 bits, so
the default value (6) should be sufficient, unless other values
are used for
TimeBetweenGlobalCheckpoints,
TimeBetweenEpochs, or
both. A value that is too small can result in false positives,
while one that is too large could lead to excessive wasted space
in the database.
Both NDB$EPOCH() and
NDB$EPOCH_TRANS() insert entries for
conflicting rows into the relevant exceptions tables, provided
that these tables have been defined according to the same
exceptions table schema rules as described elsewhere in this
section (see NDB$OLD(column_name)).
You need to create any exceptions table before creating the table
with which it is to be used.
As with the other conflict detection functions discussed in this
section, NDB$EPOCH() and
NDB$EPOCH_TRANS() are activated by including
relevant entries in the mysql.ndb_replication
table (see The ndb_replication system table).
The roles of the primary and secondary MySQL Clusters in this
scenario are fully determined by
mysql.ndb_replication table entries.
Because the conflict detection algorithms employed by
NDB$EPOCH() and
NDB$EPOCH_TRANS() are asymmetric, you must use
different values for the primary slave's and secondary
slave's server_id entries.
Prior to MySQL Cluster NDB 7.2.17, conflict between
DELETE operations were handled like those for
UPDATE operations, and within the same epoch
were considered in conflict. In MySQL Cluster NDB 7.2.17 and
later, a conflict between DELETE operations
alone is not sufficient to trigger a conflict using
NDB$EPOCH() or
NDB$EPOCH_TRANS(), and the relative placement
within epochs does not matter. (Bug "18454499)
Conflict detection status variables.
MySQL Cluster NDB 7.2.1 introduces several status variables that
can be used to monitor NDB$EPOCH() and
NDB$EPOCH_TRANS() conflict detection. You can
see how many rows have been found in conflict by
NDB$EPOCH() since this slave was last
restarted from the current value of the
Ndb_conflict_fn_epoch system
status variable.
Ndb_conflict_fn_epoch_trans
provides the number of rows that have been found directly in
conflict by NDB$EPOCH_TRANS(); the number of
rows actually realigned, including those affected due to their
membership in or dependency on the same transactions as other
conflicting rows, is given by
Ndb_conflict_trans_row_reject_count.
For more information, see Section 18.3.3.8.3, “MySQL Cluster Status Variables”.
Limitations on NDB$EPOCH().
The following limitations currently apply when using
NDB$EPOCH() to perform conflict detection:
Conflicts are detected using MySQL Cluster epoch boundaries, with granularity proportional to
TimeBetweenEpochs(default: 100 milliseconds). The minimum conflict window is the minimum time during which concurrent updates to the same data on both clusters always report a conflict. This is always a nonzero length of time, and is roughly proportional to2 * (latency + queueing + TimeBetweenEpochs). This implies that—assuming the default forTimeBetweenEpochsand ignoring any latency between clusters (as well as any queuing delays)—the minimum conflict window size is approximately 200 milliseconds. This minimum window should be considered when looking at expected application “race” patterns.Additional storage is required for tables using the
NDB$EPOCH()andNDB$EPOCH_TRANS()functions; from 1 to 32 bits extra space per row is required, depending on the value passed to the function.Conflicts between delete operations may result in divergence between the primary and secondary. When a row is deleted on both clusters concurrently, the conflict can be detected, but is not recorded, since the row is deleted. This means that further conflicts during the propagation of any subsequent realignment operations will not be detected, which can lead to divergence.
Deletes should be externally serialized, or routed to one cluster only. Alternatively, a separate row should be updated transactionally with such deletes and any inserts that follow them, so that conflicts can be tracked across row deletes. This may require changes in applications.
Only two MySQL Clusters in a circular “active-active” configuration are currently supported when using
NDB$EPOCH()orNDB$EPOCH_TRANS()for conflict detection.Tables having
BLOBorTEXTcolumns are not currently supported withNDB$EPOCH()orNDB$EPOCH_TRANS().
NDB$EPOCH_TRANS().
NDB$EPOCH_TRANS() extends the
NDB$EPOCH() function, and, like
NDB$EPOCH(), is available beginning with
MySQL Cluster NDB 7.2.1. Conflicts are detected and handled in
the same way using the “primary wins all” rule (see
NDB$EPOCH() and NDB$EPOCH_TRANS()) but with
the extra condition that any other rows updated in the same
transaction in which the conflict occurred are also regarded as
being in conflict. In other words, where
NDB$EPOCH() realigns individual conflicting
rows on the secondary, NDB$EPOCH_TRANS()
realigns conflicting transactions.
In addition, any transactions which are detectably dependent on a conflicting transaction are also regarded as being in conflict, these dependencies being determined by the contents of the secondary cluster's binary log. Since the binary log contains only data modification operations (inserts, updates, and deletes), only overlapping data modifications are used to determine dependencies between transactions.
NDB$EPOCH_TRANS() is subject to the same
conditions and limitations as NDB$EPOCH(), and
in addition requires that Version 2 binary log row events are used
(--log-bin-use-v1-row-events equal
to 0), which adds a storage overhead of 2 bytes per event in the
binary log. In addition, all transaction IDs must be recorded in
the secondary's binary log
(--ndb-log-transaction-id option),
which adds a further variable overhead (up to 13 bytes per row).
See NDB$EPOCH() and NDB$EPOCH_TRANS().
Status information.
A server status variable
Ndb_conflict_fn_max provides a
count of the number of times that a row was not applied on the
current SQL node due to “greatest timestamp wins”
conflict resolution since the last time that
mysqld was started.
The number of times that a row was not applied as the result of
“same timestamp wins” conflict resolution on a given
mysqld since the last time it was restarted is
given by the global status variable
Ndb_conflict_fn_old. In addition
to incrementing
Ndb_conflict_fn_old, the primary
key of the row that was not used is inserted into an
exceptions table, as
explained later in this section.
Conflict resolution exceptions table.
To use the NDB$OLD() conflict resolution
function, it is also necessary to create an exceptions table
corresponding to each NDB table for
which this type of conflict resolution is to be employed. This
is also true when using NDB$EPOCH() or
NDB$EPOCH_TRANS() in MySQL Cluster NDB 7.2.1
and later. The name of this table is that of the table for which
conflict resolution is to be applied, with the string
$EX appended. (For example, if the name of
the original table is mytable, the name of
the corresponding exceptions table name should be
mytable$EX.) This table is created as
follows:
CREATE TABLEoriginal_table$EX ( server_id INT UNSIGNED, master_server_id INT UNSIGNED, master_epoch BIGINT UNSIGNED, count INT UNSIGNED,original_table_pk_columns, [additional_columns,] PRIMARY KEY(server_id, master_server_id, master_epoch, count) ) ENGINE=NDB;
The first four columns are required. The names of the first four
columns and the columns matching the original table's primary
key columns are not critical; however, we suggest for reasons of
clarity and consistency, that you use the names shown here for the
server_id, master_server_id,
master_epoch, and count
columns, and that you use the same names as in the original table
for the columns matching those in the original table's
primary key.
Following these columns, the columns making up the original table's primary key should be copied in the order in which they are used to define the primary key of the original table. The data types for the columns duplicating the primary key columns of the original table should be the same as (or larger than) those of the original columns.
Additional columns may optionally be defined following the copied
primary key columns, but not before any of them; any such extra
columns cannot be NOT NULL. The exceptions
table's primary key must be defined as shown.
The exceptions table must use the NDB
storage engine. An example that uses NDB$OLD()
with an exceptions table is shown later in this section.
The mysql.ndb_replication table is read when
a data table is set up for replication, so the row corresponding
to a table to be replicated must be inserted into
mysql.ndb_replication
before the table to be replicated is
created.
Examples
The following examples assume that you have already a working MySQL Cluster replication setup, as described in Section 18.6.5, “Preparing the MySQL Cluster for Replication”, and Section 18.6.6, “Starting MySQL Cluster Replication (Single Replication Channel)”.
NDB$MAX() example.
Suppose you wish to enable “greatest timestamp
wins” conflict resolution on table
test.t1, using column
mycol as the “timestamp”. This
can be done using the following steps:
Make sure that you have started the master mysqld with
--ndb-log-update-as-write=OFF.On the master, perform this
INSERTstatement:INSERT INTO mysql.ndb_replication VALUES ('test', 't1', 0, NULL, 'NDB$MAX(mycol)');Inserting a 0 into the
server_idindicates that all SQL nodes accessing this table should use conflict resolution. If you want to use conflict resolution on a specific mysqld only, use the actual server ID.Inserting
NULLinto thebinlog_typecolumn has the same effect as inserting 0 (NBT_DEFAULT); the server default is used.Create the
test.t1table:CREATE TABLE test.t1 (columnsmycol INT UNSIGNED,columns) ENGINE=NDB;Now, when updates are done on this table, conflict resolution is applied, and the version of the row having the greatest value for
mycolis written to the slave.
Other binlog_type options—such as
NBT_UPDATED_ONLY_USE_UPDATE should be used to
control logging on the master using the
ndb_replication table rather than by using
command-line options.
NDB$OLD() example.
Suppose an NDB table such as the
one defined here is being replicated, and you wish to enable
“same timestamp wins” conflict resolution for
updates to this table:
CREATE TABLE test.t2 (
a INT UNSIGNED NOT NULL,
b CHAR(25) NOT NULL,
columns,
mycol INT UNSIGNED NOT NULL,
columns,
PRIMARY KEY pk (a, b)
) ENGINE=NDB;
The following steps are required, in the order shown:
First—and prior to creating
test.t2—you must insert a row into themysql.ndb_replicationtable, as shown here:INSERT INTO mysql.ndb_replication VALUES ('test', 't2', 0, NULL, 'NDB$OLD(mycol)');Possible values for the
binlog_typecolumn are shown earlier in this section. The value'NDB$OLD(mycol)'should be inserted into theconflict_fncolumn.Create an appropriate exceptions table for
test.t2. The table creation statement shown here includes all required columns; any additional columns must be declared following these columns, and before the definition of the table's primary key.CREATE TABLE test.t2$EX ( server_id SMALLINT UNSIGNED, master_server_id INT UNSIGNED, master_epoch BIGINT UNSIGNED, count BIGINT UNSIGNED, a INT UNSIGNED NOT NULL, b CHAR(25) NOT NULL, [additional_columns,] PRIMARY KEY(server_id, master_server_id, master_epoch, count) ) ENGINE=NDB;Create the table
test.t2as shown previously.
These steps must be followed for every table for which you wish to
perform conflict resolution using NDB$OLD().
For each such table, there must be a corresponding row in
mysql.ndb_replication, and there must be an
exceptions table in the same database as the table being
replicated.
MySQL Cluster release notes are no longer published in the MySQL Reference Manual.
Release notes for the changes in each release of MySQL Cluster are located at MySQL Cluster 7.2 Release Notes.