Table of Contents
- 17.1 Replication Configuration
- 17.2 Replication Implementation
- 17.3 Replication Solutions
- 17.3.1 Using Replication for Backups
- 17.3.2 Using Replication with Different Master and Slave Storage Engines
- 17.3.3 Using Replication for Scale-Out
- 17.3.4 Replicating Different Databases to Different Slaves
- 17.3.5 Improving Replication Performance
- 17.3.6 Switching Masters During Failover
- 17.3.7 Setting Up Replication to Use Secure Connections
- 17.3.8 Semisynchronous Replication
- 17.4 Replication Notes and Tips
Replication enables data from one MySQL database server (the master) to be replicated to one or more MySQL database servers (the slaves). Replication is asynchronous by default, therefore slaves do not need to be connected permanently to receive updates from the master. This means that updates can occur over long-distance connections and even over temporary or intermittent connections such as a dial-up service. Depending on the configuration, you can replicate all databases, selected databases, or even selected tables within a database.
For answers to some questions often asked by those who are new to MySQL Replication, see Section A.13, “MySQL 5.5 FAQ: Replication”.
Advantages of replication in MySQL include:
Scale-out solutions - spreading the load among multiple slaves to improve performance. In this environment, all writes and updates must take place on the master server. Reads, however, may take place on one or more slaves. This model can improve the performance of writes (since the master is dedicated to updates), while dramatically increasing read speed across an increasing number of slaves.
Data security - because data is replicated to the slave, and the slave can pause the replication process, it is possible to run backup services on the slave without corrupting the corresponding master data.
Analytics - live data can be created on the master, while the analysis of the information can take place on the slave without affecting the performance of the master.
Long-distance data distribution - if a branch office would like to work with a copy of your main data, you can use replication to create a local copy of the data for their use without requiring permanent access to the master.
Replication in MySQL features support for one-way, asynchronous replication, in which one server acts as the master, while one or more other servers act as slaves. This is in contrast to the synchronous replication which is a characteristic of MySQL Cluster (see Chapter 18, MySQL Cluster NDB 7.2). In MySQL 5.5, an interface to semisynchronous replication is supported in addition to the built-in asynchronous replication. With semisynchronous replication, a commit performed on the master side blocks before returning to the session that performed the transaction until at least one slave acknowledges that it has received and logged the events for the transaction. See Section 17.3.8, “Semisynchronous Replication”
There are a number of solutions available for setting up replication between two servers, but the best method to use depends on the presence of data and the engine types you are using. For more information on the available options, see Section 17.1.1, “How to Set Up Replication”.
There are two core types of replication format, Statement Based Replication (SBR), which replicates entire SQL statements, and Row Based Replication (RBR), which replicates only the changed rows. You may also use a third variety, Mixed Based Replication (MBR). For more information on the different replication formats, see Section 17.1.2, “Replication Formats”. In MySQL 5.5, statement-based format is the default.
Replication is controlled through a number of different options and variables. These control the core operation of the replication, timeouts, and the databases and filters that can be applied on databases and tables. For more information on the available options, see Section 17.1.3, “Replication and Binary Logging Options and Variables”.
You can use replication to solve a number of different problems, including problems with performance, supporting the backup of different databases, and as part of a larger solution to alleviate system failures. For information on how to address these issues, see Section 17.3, “Replication Solutions”.
For notes and tips on how different data types and statements are treated during replication, including details of replication features, version compatibility, upgrades, and problems and their resolution, including an FAQ, see Section 17.4, “Replication Notes and Tips”.
For detailed information on the implementation of replication, how replication works, the process and contents of the binary log, background threads and the rules used to decide how statements are recorded and replication, see Section 17.2, “Replication Implementation”.
Replication between servers in MySQL is based on the binary logging mechanism. The MySQL instance operating as the master (the source of the database changes) writes updates and changes as “events” to the binary log. The information in the binary log is stored in different logging formats according to the database changes being recorded. Slaves are configured to read the binary log from the master and to execute the events in the binary log on the slave's local database.
The master is “dumb” in this scenario. Once binary logging has been enabled, all statements are recorded in the binary log. Each slave receives a copy of the entire contents of the binary log. It is the responsibility of the slave to decide which statements in the binary log should be executed; you cannot configure the master to log only certain events. If you do not specify otherwise, all events in the master binary log are executed on the slave. If required, you can configure the slave to process only events that apply to particular databases or tables.
Each slave keeps a record of the binary log coordinates: The file name and position within the file that it has read and processed from the master. This means that multiple slaves can be connected to the master and executing different parts of the same binary log. Because the slaves control this process, individual slaves can be connected and disconnected from the server without affecting the master's operation. Also, because each slave remembers the position within the binary log, it is possible for slaves to be disconnected, reconnect and then “catch up” by continuing from the recorded position.
Both the master and each slave must be configured with a unique ID
(using the server-id option). In
addition, each slave must be configured with information about the
master host name, log file name, and position within that file.
These details can be controlled from within a MySQL session using
the CHANGE MASTER TO statement on the
slave. The details are stored within the slave's
master.info file.
This section describes the setup and configuration required for a replication environment, including step-by-step instructions for creating a new replication environment. The major components of this section are:
For a guide to setting up two or more servers for replication, Section 17.1.1, “How to Set Up Replication”, deals with the configuration of the systems and provides methods for copying data between the master and slaves.
Events in the binary log are recorded using a number of formats. These are referred to as statement-based replication (SBR) or row-based replication (RBR). A third type, mixed-format replication (MIXED), uses SBR or RBR replication automatically to take advantage of the benefits of both SBR and RBR formats when appropriate. The different formats are discussed in Section 17.1.2, “Replication Formats”.
Detailed information on the different configuration options and variables that apply to replication is provided in Section 17.1.3, “Replication and Binary Logging Options and Variables”.
Once started, the replication process should require little administration or monitoring. However, for advice on common tasks that you may want to execute, see Section 17.1.4, “Common Replication Administration Tasks”.
- 17.1.1.1 Setting the Replication Master Configuration
- 17.1.1.2 Setting the Replication Slave Configuration
- 17.1.1.3 Creating a User for Replication
- 17.1.1.4 Obtaining the Replication Master Binary Log Coordinates
- 17.1.1.5 Creating a Data Snapshot Using mysqldump
- 17.1.1.6 Creating a Data Snapshot Using Raw Data Files
- 17.1.1.7 Setting Up Replication with New Master and Slaves
- 17.1.1.8 Setting Up Replication with Existing Data
- 17.1.1.9 Introducing Additional Slaves to an Existing Replication Environment
- 17.1.1.10 Setting the Master Configuration on the Slave
This section describes how to set up complete replication of a MySQL server. There are a number of different methods for setting up replication, and the exact method to use depends on how you are setting up replication, and whether you already have data within your master database.
There are some generic tasks that are common to all replication setups:
On the master, you must enable binary logging and configure a unique server ID. This might require a server restart. See Section 17.1.1.1, “Setting the Replication Master Configuration”.
On each slave that you want to connect to the master, you must configure a unique server ID. This might require a server restart. See Section 17.1.1.2, “Setting the Replication Slave Configuration”.
You may want to create a separate user that will be used by your slaves to authenticate with the master to read the binary log for replication. The step is optional. See Section 17.1.1.3, “Creating a User for Replication”.
Before creating a data snapshot or starting the replication process, you should record the position of the binary log on the master. You will need this information when configuring the slave so that the slave knows where within the binary log to start executing events. See Section 17.1.1.4, “Obtaining the Replication Master Binary Log Coordinates”.
If you already have data on your master and you want to use it to synchronize your slave, you will need to create a data snapshot. You can create a snapshot using mysqldump (see Section 17.1.1.5, “Creating a Data Snapshot Using mysqldump”) or by copying the data files directly (see Section 17.1.1.6, “Creating a Data Snapshot Using Raw Data Files”).
You will need to configure the slave with settings for connecting to the master, such as the host name, login credentials, and binary log file name and position. See Section 17.1.1.10, “Setting the Master Configuration on the Slave”.
Once you have configured the basic options, you will need to follow the instructions for your replication setup. A number of alternatives are provided:
If you are establishing a new MySQL master and one or more slaves, you need only set up the configuration, as you have no data to exchange. For guidance on setting up replication in this situation, see Section 17.1.1.7, “Setting Up Replication with New Master and Slaves”.
If you are already running a MySQL server, and therefore already have data that must be transferred to your slaves before replication starts, have not previously configured the binary log and are able to shut down your MySQL server for a short period during the process, see Section 17.1.1.8, “Setting Up Replication with Existing Data”.
If you are adding slaves to an existing replication environment, you can set up the slaves without affecting the master. See Section 17.1.1.9, “Introducing Additional Slaves to an Existing Replication Environment”.
If you will be administering MySQL replication servers, we suggest that you read this entire chapter through and try all statements mentioned in Section 13.4.1, “SQL Statements for Controlling Master Servers”, and Section 13.4.2, “SQL Statements for Controlling Slave Servers”. You should also familiarize yourself with the replication startup options described in Section 17.1.3, “Replication and Binary Logging Options and Variables”.
Note that certain steps within the setup process require the
SUPER privilege. If you do not
have this privilege, it might not be possible to enable
replication.
On a replication master, you must enable binary logging and establish a unique server ID. If this has not already been done, this part of master setup requires a server restart.
Binary logging must be enabled on the master because the binary log is the basis for sending data changes from the master to its slaves. If binary logging is not enabled, replication will not be possible.
Each server within a replication group must be configured with a unique server ID. This ID is used to identify individual servers within the group, and must be a positive integer between 1 and (232)−1. How you organize and select the numbers is entirely up to you.
To configure the binary log and server ID options, you will need
to shut down your MySQL server and edit the
my.cnf or my.ini file.
Add the following options to the configuration file within the
[mysqld] section. If these options already
exist, but are commented out, uncomment the options and alter
them according to your needs. For example, to enable binary
logging using a log file name prefix of
mysql-bin, and configure a server ID of 1,
use these lines:
[mysqld] log-bin=mysql-bin server-id=1
After making the changes, restart the server.
If you omit server-id (or set
it explicitly to its default value of 0), a master refuses
connections from all slaves.
For the greatest possible durability and consistency in a
replication setup using InnoDB with
transactions, you should use
innodb_flush_log_at_trx_commit=1 and
sync_binlog=1 in the master
my.cnf file.
Ensure that the skip-networking
option is not enabled on your replication master. If
networking has been disabled, your slave will not able to
communicate with the master and replication will fail.
On a replication slave, you must establish a unique server ID. If this has not already been done, this part of slave setup requires a server restart.
If the slave server ID is not already set, or the current value conflicts with the value that you have chosen for the master server, you should shut down your slave server and edit the configuration to specify a unique server ID. For example:
[mysqld] server-id=2
After making the changes, restart the server.
If you are setting up multiple slaves, each one must have a
unique server-id value that
differs from that of the master and from each of the other
slaves. Think of server-id values
as something similar to IP addresses: These IDs uniquely
identify each server instance in the community of replication
partners.
If you omit server-id (or set
it explicitly to its default value of 0), a slave refuses to
connect to a master.
You do not have to enable binary logging on the slave for replication to be enabled. However, if you enable binary logging on the slave, you can use the binary log for data backups and crash recovery on the slave, and also use the slave as part of a more complex replication topology (for example, where the slave acts as a master to other slaves).
Each slave must connect to the master using a MySQL user name
and password, so there must be a user account on the master that
the slave can use to connect. Any account can be used for this
operation, providing it has been granted the
REPLICATION SLAVE privilege. You
may wish to create a different account for each slave, or
connect to the master using the same account for each slave.
You need not create an account specifically for replication.
However, you should be aware that the user name and password
will be stored in plain text within the
master.info file (see
Section 17.2.2.2, “Slave Status Logs”). Therefore, you may want to
create a separate account that has privileges only for the
replication process, to minimize the possibility of compromise
to other accounts.
To create a new account, use CREATE
USER. To grant this account the privileges required
for replication, use the GRANT
statement. If you create an account solely for the purposes of
replication, that account needs only the
REPLICATION SLAVE privilege. For
example, to set up a new user, repl, that can
connect for replication from any host within the
mydomain.com domain, issue these statements
on the master:
mysql>CREATE USER 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass';mysql>GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.mydomain.com';
See Section 13.7.1, “Account Management Statements”, for more information on statements for manipulation of user accounts.
To configure replication on the slave you must determine the master's current coordinates within its binary log. You will need this information so that when the slave starts the replication process, it is able to start processing events from the binary log at the correct point.
If you have existing data on your master that you want to synchronize on your slaves before starting the replication process, you must stop processing statements on the master, and then obtain its current binary log coordinates and dump its data, before permitting the master to continue executing statements. If you do not stop the execution of statements, the data dump and the master status information that you use will not match and you will end up with inconsistent or corrupted databases on the slaves.
To obtain the master binary log coordinates, follow these steps:
Start a session on the master by connecting to it with the command-line client, and flush all tables and block write statements by executing the
FLUSH TABLES WITH READ LOCKstatement:mysql>
FLUSH TABLES WITH READ LOCK;For
InnoDBtables, note thatFLUSH TABLES WITH READ LOCKalso blocksCOMMIToperations.WarningLeave the client from which you issued the
FLUSH TABLESstatement running so that the read lock remains in effect. If you exit the client, the lock is released.In a different session on the master, use the
SHOW MASTER STATUSstatement to determine the current binary log file name and position:mysql >
SHOW MASTER STATUS;+------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000003 | 73 | test | manual,mysql | +------------------+----------+--------------+------------------+The
Filecolumn shows the name of the log file andPositionshows the position within the file. In this example, the binary log file ismysql-bin.000003and the position is 73. Record these values. You need them later when you are setting up the slave. They represent the replication coordinates at which the slave should begin processing new updates from the master.If the master has been running previously without binary logging enabled, the log file name and position values displayed by
SHOW MASTER STATUSor mysqldump --master-data will be empty. In that case, the values that you need to use later when specifying the slave's log file and position are the empty string ('') and4.
You now have the information you need to enable the slave to start reading from the binary log in the correct place to start replication.
If you have existing data that needs be to synchronized with the slave before you start replication, leave the client running so that the lock remains in place and then proceed to Section 17.1.1.5, “Creating a Data Snapshot Using mysqldump”, or Section 17.1.1.6, “Creating a Data Snapshot Using Raw Data Files”. The idea here is to prevent any further changes so that the data copied to the slaves is in synchrony with the master.
If you are setting up a brand new master and slave replication group, you can exit the first session to release the read lock.
One way to create a snapshot of the data in an existing master database is to use the mysqldump tool to create a dump of all the databases you want to replicate. Once the data dump has been completed, you then import this data into the slave before starting the replication process.
The example shown here dumps all databases to a file named
dbdump.db, and includes the
--master-data option which
automatically appends the CHANGE MASTER
TO statement required on the slave to start the
replication process:
shell> mysqldump --all-databases --master-data > dbdump.db
If you do not use
--master-data, then it is
necessary to lock all tables in a separate session manually
(using FLUSH TABLES WITH
READ LOCK) prior to running
mysqldump, then exiting or running UNLOCK
TABLES from the second session to release the locks. You must
also obtain binary log position information matching the
snapshot, using SHOW MASTER
STATUS, and use this to issue the appropriate
CHANGE MASTER TO statement when
starting the slave.
When choosing databases to include in the dump, remember that you need to filter out databases on each slave that you do not want to include in the replication process.
To import the data, either copy the dump file to the slave, or access the file from the master when connecting remotely to the slave.
If your database is large, copying the raw data files can be
more efficient than using mysqldump and
importing the file on each slave. This technique skips the
overhead of updating indexes as the INSERT
statements are replayed.
Using this method with tables in storage engines with complex caching or logging algorithms requires extra steps to produce a perfect “point in time” snapshot: the initial copy command might leave out cache information and logging updates, even if you have acquired a global read lock. How the storage engine responds to this depends on its crash recovery abilities.
This method also does not work reliably if the master and slave
have different values for
ft_stopword_file,
ft_min_word_len, or
ft_max_word_len and you are
copying tables having full-text indexes.
If you use InnoDB tables, you can
use the mysqlbackup command from the MySQL
Enterprise Backup component to produce a consistent snapshot.
This command records the log name and offset corresponding to
the snapshot to be later used on the slave. MySQL Enterprise
Backup is a commercial product that is included as part of a
MySQL Enterprise subscription. See
Section 25.2, “MySQL Enterprise Backup Overview” for detailed
information.
Otherwise, use the cold
backup technique to obtain a reliable binary snapshot of
InnoDB tables: copy all data files after
doing a slow shutdown
of the MySQL Server.
To create a raw data snapshot of MyISAM
tables, you can use standard copy tools such as
cp or copy, a remote copy
tool such as scp or rsync,
an archiving tool such as zip or
tar, or a file system snapshot tool such as
dump, providing that your MySQL data files
exist on a single file system. If you are replicating only
certain databases, copy only those files that relate to those
tables. (For InnoDB, all tables in all
databases are stored in the
system tablespace
files, unless you have the
innodb_file_per_table option
enabled.)
You might want to specifically exclude the following files from your archive:
Files relating to the
mysqldatabase.The
master.infofile.The master's binary log files.
Any relay log files.
To get the most consistent results with a raw data snapshot, shut down the master server during the process, as follows:
Acquire a read lock and get the master's status. See Section 17.1.1.4, “Obtaining the Replication Master Binary Log Coordinates”.
In a separate session, shut down the master server:
shell>
mysqladmin shutdownMake a copy of the MySQL data files. The following examples show common ways to do this. You need to choose only one of them:
shell>
tar cfshell>/tmp/db.tar./datazip -rshell>/tmp/db.zip./datarsync --recursive./data/tmp/dbdataRestart the master server.
If you are not using InnoDB tables, you can
get a snapshot of the system from a master without shutting down
the server as described in the following steps:
Acquire a read lock and get the master's status. See Section 17.1.1.4, “Obtaining the Replication Master Binary Log Coordinates”.
Make a copy of the MySQL data files. The following examples show common ways to do this. You need to choose only one of them:
shell>
tar cfshell>/tmp/db.tar./datazip -rshell>/tmp/db.zip./datarsync --recursive./data/tmp/dbdataIn the client where you acquired the read lock, release the lock:
mysql>
UNLOCK TABLES;
Once you have created the archive or copy of the database, copy the files to each slave before starting the slave replication process.
The easiest and most straightforward method for setting up replication is to use new master and slave servers.
You can also use this method if you are setting up new servers but have an existing dump of the databases from a different server that you want to load into your replication configuration. By loading the data into a new master, the data will be automatically replicated to the slaves.
To set up replication between a new master and slave:
Configure the MySQL master with the necessary configuration properties. See Section 17.1.1.1, “Setting the Replication Master Configuration”.
Start up the MySQL master.
Set up a user. See Section 17.1.1.3, “Creating a User for Replication”.
Obtain the master status information. See Section 17.1.1.4, “Obtaining the Replication Master Binary Log Coordinates”.
On the master, release the read lock:
mysql>
UNLOCK TABLES;On the slave, edit the MySQL configuration. See Section 17.1.1.2, “Setting the Replication Slave Configuration”.
Start up the MySQL slave.
Execute a
CHANGE MASTER TOstatement to set the master replication server configuration. See Section 17.1.1.10, “Setting the Master Configuration on the Slave”.
Perform the slave setup steps on each slave.
Because there is no data to load or exchange on a new server configuration you do not need to copy or import any information.
If you are setting up a new replication environment using the data from a different existing database server, you will now need to run the dump file generated from that server on the new master. The database updates will automatically be propagated to the slaves:
shell> mysql -h master < fulldb.dump
When setting up replication with existing data, you will need to decide how best to get the data from the master to the slave before starting the replication service.
The basic process for setting up replication with existing data is as follows:
With the MySQL master running, create a user to be used by the slave when connecting to the master during replication. See Section 17.1.1.3, “Creating a User for Replication”.
If you have not already configured the
server-idand enabled binary logging on the master server, you will need to shut it down to configure these options. See Section 17.1.1.1, “Setting the Replication Master Configuration”.If you have to shut down your master server, this is a good opportunity to take a snapshot of its databases. You should obtain the master status (see Section 17.1.1.4, “Obtaining the Replication Master Binary Log Coordinates”) before taking down the master, updating the configuration and taking a snapshot. For information on how to create a snapshot using raw data files, see Section 17.1.1.6, “Creating a Data Snapshot Using Raw Data Files”.
If your master server is already correctly configured, obtain its status (see Section 17.1.1.4, “Obtaining the Replication Master Binary Log Coordinates”) and then use mysqldump to take a snapshot (see Section 17.1.1.5, “Creating a Data Snapshot Using mysqldump”) or take a raw snapshot of the live server using the guide in Section 17.1.1.6, “Creating a Data Snapshot Using Raw Data Files”.
Update the configuration of the slave. See Section 17.1.1.2, “Setting the Replication Slave Configuration”.
The next step depends on how you created the snapshot of data on the master.
If you used mysqldump:
Start the slave, using the
--skip-slave-startoption so that replication does not start.Import the dump file:
shell>
mysql < fulldb.dump
If you created a snapshot using the raw data files:
Extract the data files into your slave data directory. For example:
shell>
tar xvf dbdump.tarYou may need to set permissions and ownership on the files so that the slave server can access and modify them.
Start the slave, using the
--skip-slave-startoption so that replication does not start.
Configure the slave with the replication coordinates from the master. This tells the slave the binary log file and position within the file where replication needs to start. Also, configure the slave with the login credentials and host name of the master. For more information on the
CHANGE MASTER TOstatement required, see Section 17.1.1.10, “Setting the Master Configuration on the Slave”.Start the slave threads:
mysql>
START SLAVE;
After you have performed this procedure, the slave should connect to the master and catch up on any updates that have occurred since the snapshot was taken.
If you have forgotten to set the
server-id option for the master,
slaves cannot connect to it.
If you have forgotten to set the
server-id option for the slave,
you get the following error in the slave's error log:
Warning: You should set server-id to a non-0 value if master_host is set; we will force server id to 2, but this MySQL server will not act as a slave.
You also find error messages in the slave's error log if it is not able to replicate for any other reason.
Once a slave is replicating, you can find in its data directory
one file named master.info and another
named relay-log.info. The slave uses these
two files to keep track of how much of the master's binary log
it has processed. Do not remove or edit
these files unless you know exactly what you are doing and fully
understand the implications. Even in that case, it is preferred
that you use the CHANGE MASTER TO
statement to change replication parameters. The slave will use
the values specified in the statement to update the status files
automatically.
The content of master.info overrides some
of the server options specified on the command line or in
my.cnf. See
Section 17.1.3, “Replication and Binary Logging Options and Variables”, for more details.
A single snapshot of the master suffices for multiple slaves. To set up additional slaves, use the same master snapshot and follow the slave portion of the procedure just described.
To add another slave to an existing replication configuration,
you can do so without stopping the master. Instead, set up the
new slave by making a copy of an existing slave, except that you
configure the new slave with a different
server-id value.
To duplicate an existing slave:
Shut down the existing slave:
shell>
mysqladmin shutdownCopy the data directory from the existing slave to the new slave. You can do this by creating an archive using tar or
WinZip, or by performing a direct copy using a tool such as cp or rsync. Ensure that you also copy the log files and relay log files.A common problem that is encountered when adding new replication slaves is that the new slave fails with a series of warning and error messages like these:
071118 16:44:10 [Warning] Neither --relay-log nor --relay-log-index were used; so replication may break when this MySQL server acts as a slave and has his hostname changed!! Please use '--relay-log=
new_slave_hostname-relay-bin' to avoid this problem. 071118 16:44:10 [ERROR] Failed to open the relay log './old_slave_hostname-relay-bin.003525' (relay_log_pos 22940879) 071118 16:44:10 [ERROR] Could not find target log during relay log initialization 071118 16:44:10 [ERROR] Failed to initialize the master info structureThis is due to the fact that, if the
--relay-logoption is not specified, the relay log files contain the host name as part of their file names. (This is also true of the relay log index file if the--relay-log-indexoption is not used. See Section 17.1.3, “Replication and Binary Logging Options and Variables”, for more information about these options.)To avoid this problem, use the same value for
--relay-logon the new slave that was used on the existing slave. (If this option was not set explicitly on the existing slave, useexisting_slave_hostname-relay-bin--relay-log-indexoption on the new slave to match what was used on the existing slave. (If this option was not set explicitly on the existing slave, useexisting_slave_hostname-relay-bin.indexIf you have not already done so, issue a
STOP SLAVEon the new slave.If you have already started the existing slave again, issue a
STOP SLAVEon the existing slave as well.Copy the contents of the existing slave's relay log index file into the new slave's relay log index file, making sure to overwrite any content already in the file.
Proceed with the remaining steps in this section.
Copy the
master.infoandrelay-log.infofiles from the existing slave to the new slave if they were not located in the data directory. These files hold the current log coordinates for the master's binary log and the slave's relay log.Start the existing slave.
On the new slave, edit the configuration and give the new slave a unique
server-idnot used by the master or any of the existing slaves.Start the new slave. The slave will use the information in its
master.infofile to start the replication process.
To set up the slave to communicate with the master for replication, you must tell the slave the necessary connection information. To do this, execute the following statement on the slave, replacing the option values with the actual values relevant to your system:
mysql>CHANGE MASTER TO->MASTER_HOST='->master_host_name',MASTER_USER='->replication_user_name',MASTER_PASSWORD='->replication_password',MASTER_LOG_FILE='->recorded_log_file_name',MASTER_LOG_POS=recorded_log_position;
Replication cannot use Unix socket files. You must be able to connect to the master MySQL server using TCP/IP.
The CHANGE MASTER TO statement
has other options as well. For example, it is possible to set up
secure replication using SSL. For a full list of options, and
information about the maximum permissible length for the
string-valued options, see Section 13.4.2.1, “CHANGE MASTER TO Syntax”.
Replication works because events written to the binary log are read from the master and then processed on the slave. The events are recorded within the binary log in different formats according to the type of event. The different replication formats used correspond to the binary logging format used when the events were recorded in the master's binary log. The correlation between binary logging formats and the terms used during replication are:
Replication capabilities in MySQL originally were based on propagation of SQL statements from master to slave. This is called statement-based replication (often abbreviated as SBR), which corresponds to the standard statement-based binary logging format. In older versions of MySQL (5.1.4 and earlier), binary logging and replication used this format exclusively.
Row-based binary logging logs changes in individual table rows. When used with MySQL replication, this is known as row-based replication (often abbreviated as RBR). In row-based replication, the master writes events to the binary log that indicate how individual table rows are changed.
The server can change the binary logging format in real time according to the type of event using mixed-format logging.
When the mixed format is in effect, statement-based logging is used by default, but automatically switches to row-based logging in particular cases as described later. Replication using the mixed format is often referred to as mixed-based replication or mixed-format replication. For more information, see Section 5.2.4.3, “Mixed Binary Logging Format”.
In MySQL 5.5, statement-based format is the default.
MySQL Cluster.
The default binary logging format in all MySQL Cluster NDB 7.2
releases, beginning with MySQL Cluster NDB 7.2.1, is
STATEMENT. (This is a change from previous
versions of MySQL Cluster.) You should note that MySQL Cluster
Replication always uses row-based replication, and that the
NDB storage engine is incompatible
with statement-based replication. This means that you must
manually set the format to ROW prior to
enabling MySQL Cluster Replication. See
Section 18.6.2, “General Requirements for MySQL Cluster Replication”, for more
information.
When using MIXED format, the binary logging
format is determined in part by the storage engine being used and
the statement being executed. For more information on mixed-format
logging and the rules governing the support of different logging
formats, see Section 5.2.4.3, “Mixed Binary Logging Format”.
The logging format in a running MySQL server is controlled by
setting the binlog_format server
system variable. This variable can be set with session or global
scope. The rules governing when and how the new setting takes
effect are the same as for other MySQL server system
variables—setting the variable for the current session lasts
only until the end of that session, and the change is not visible
to other sessions; setting the variable globally requires a
restart of the server to take effect. For more information, see
Section 13.7.4, “SET Syntax”.
There are conditions under which you cannot change the binary logging format at runtime or doing so causes replication to fail. See Section 5.2.4.2, “Setting The Binary Log Format”.
You must have the SUPER privilege
to set either the global or session
binlog_format value.
The statement-based and row-based replication formats have different issues and limitations. For a comparison of their relative advantages and disadvantages, see Section 17.1.2.1, “Advantages and Disadvantages of Statement-Based and Row-Based Replication”.
With statement-based replication, you may encounter issues with replicating stored routines or triggers. You can avoid these issues by using row-based replication instead. For more information, see Section 20.7, “Binary Logging of Stored Programs”.
Each binary logging format has advantages and disadvantages. For most users, the mixed replication format should provide the best combination of data integrity and performance. If, however, you want to take advantage of the features specific to the statement-based or row-based replication format when performing certain tasks, you can use the information in this section, which provides a summary of their relative advantages and disadvantages, to determine which is best for your needs.
Advantages of statement-based replication
Proven technology that has existed in MySQL since 3.23.
Less data written to log files. When updates or deletes affect many rows, this results in much less storage space required for log files. This also means that taking and restoring from backups can be accomplished more quickly.
Log files contain all statements that made any changes, so they can be used to audit the database.
Disadvantages of statement-based replication
Statements that are unsafe for SBR. Not all statements which modify data (such as
INSERTDELETE,UPDATE, andREPLACEstatements) can be replicated using statement-based replication. Any nondeterministic behavior is difficult to replicate when using statement-based replication. Examples of such DML (Data Modification Language) statements include the following:A statement that depends on a UDF or stored program that is nondeterministic, since the value returned by such a UDF or stored program or depends on factors other than the parameters supplied to it. (Row-based replication, however, simply replicates the value returned by the UDF or stored program, so its effect on table rows and data is the same on both the master and slave.) See Section 17.4.1.12, “Replication of Invoked Features”, for more information.
DELETEandUPDATEstatements that use aLIMITclause without anORDER BYare nondeterministic. See Section 17.4.1.16, “Replication and LIMIT”.Statements using any of the following functions cannot be replicated properly using statement-based replication:
SYSDATE()(unless both the master and the slave are started with the--sysdate-is-nowoption)
However, all other functions are replicated correctly using statement-based replication, including
NOW()and so forth.For more information, see Section 17.4.1.15, “Replication and System Functions”.
Statements that cannot be replicated correctly using statement-based replication are logged with a warning like the one shown here:
[Warning] Statement is not safe to log in statement format.
A similar warning is also issued to the client in such cases. The client can display it using
SHOW WARNINGS.INSERT ... SELECTrequires a greater number of row-level locks than with row-based replication.UPDATEstatements that require a table scan (because no index is used in theWHEREclause) must lock a greater number of rows than with row-based replication.For
InnoDB: AnINSERTstatement that usesAUTO_INCREMENTblocks other nonconflictingINSERTstatements.For complex statements, the statement must be evaluated and executed on the slave before the rows are updated or inserted. With row-based replication, the slave only has to modify the affected rows, not execute the full statement.
If there is an error in evaluation on the slave, particularly when executing complex statements, statement-based replication may slowly increase the margin of error across the affected rows over time. See Section 17.4.1.29, “Slave Errors During Replication”.
Stored functions execute with the same
NOW()value as the calling statement. However, this is not true of stored procedures.Deterministic UDFs must be applied on the slaves.
Table definitions must be (nearly) identical on master and slave. See Section 17.4.1.10, “Replication with Differing Table Definitions on Master and Slave”, for more information.
Advantages of row-based replication
All changes can be replicated. This is the safest form of replication.
The
mysqldatabase is not replicated. Themysqldatabase is instead seen as a node-specific database. Row-based replication is not supported on tables in this database. Instead, statements that would normally update this information—such asGRANT,REVOKEand the manipulation of triggers, stored routines (including stored procedures), and views—are all replicated to slaves using statement-based replication.For statements such as
CREATE TABLE ... SELECT, aCREATEstatement is generated from the table definition and replicated using statement-based format, while the row insertions are replicated using row-based format.The technology is the same as in most other database management systems; knowledge about other systems transfers to MySQL.
Fewer row locks are required on the master, which thus achieves higher concurrency, for the following types of statements:
Fewer row locks are required on the slave for any
INSERT,UPDATE, orDELETEstatement.
Disadvantages of row-based replication
RBR tends to generate more data that must be logged. To replicate a DML statement (such as an
UPDATEorDELETEstatement), statement-based replication writes only the statement to the binary log. By contrast, row-based replication writes each changed row to the binary log. If the statement changes many rows, row-based replication may write significantly more data to the binary log; this is true even for statements that are rolled back. This also means that taking and restoring from backup can require more time. In addition, the binary log is locked for a longer time to write the data, which may cause concurrency problems.Deterministic UDFs that generate large
BLOBvalues take longer to replicate with row-based replication than with statement-based replication. This is because theBLOBcolumn value is logged, rather than the statement generating the data.You cannot examine the logs to see what statements were executed, nor can you see on the slave what statements were received from the master and executed.
However, you can see what data was changed using mysqlbinlog with the options
--base64-output=DECODE-ROWSand--verbose.For tables using the
MyISAMstorage engine, a stronger lock is required on the slave forINSERTstatements when applying them as row-based events to the binary log than when applying them as statements. This means that concurrent inserts onMyISAMtables are not supported when using row-based replication.
Major changes in the replication environment and in the behavior of applications can result from using row-based logging (RBL) or row-based replication (RBR) rather than statement-based logging or replication. This section describes a number of issues known to exist when using row-based logging or replication, and discusses some best practices for taking advantage of row-based logging and replication.
For additional information, see Section 17.1.2, “Replication Formats”, and Section 17.1.2.1, “Advantages and Disadvantages of Statement-Based and Row-Based Replication”.
For information about issues specific to MySQL Cluster Replication (which depends on row-based replication), see Section 18.6.3, “Known Issues in MySQL Cluster Replication”.
RBL, RBR, and temporary tables. As noted in Section 17.4.1.24, “Replication and Temporary Tables”, temporary tables are not replicated when using row-based format. When mixed format is in effect, “safe” statements involving temporary tables are logged using statement-based format. For more information, see Section 17.1.2.1, “Advantages and Disadvantages of Statement-Based and Row-Based Replication”.
Temporary tables are not replicated when using row-based format because there is no need. In addition, because temporary tables can be read only from the thread which created them, there is seldom if ever any benefit obtained from replicating them, even when using statement-based format.
Beginning with MySQL 5.5.5, you can switch from statement-based to row-based binary logging mode even when temporary tables have been created. However, while using the row-based format, the MySQL server cannot determine the logging mode that was in effect when a given temporary table was created. For this reason, the server in such cases logs a
DROP TEMPORARY TABLE IF EXISTSstatement for each temporary table that still exists for a given client session when that session ends. (Bug #11760229, Bug #11762267) While this means that it is possible that an unnecessaryDROP TEMPORARY TABLEstatement might be logged in some cases, the statement is harmless, and does not cause an error even if the table does not exist, due to the presence of theIF EXISTSoption.RBL and synchronization of nontransactional tables. When many rows are affected, the set of changes is split into several events; when the statement commits, all of these events are written to the binary log. When executing on the slave, a table lock is taken on all tables involved, and then the rows are applied in batch mode. (This may or may not be effective, depending on the engine used for the slave's copy of the table.)
Latency and binary log size. Because RBL writes changes for each row to the binary log, its size can increase quite rapidly. In a replication environment, this can significantly increase the time required to make changes on the slave that match those on the master. You should be aware of the potential for this delay in your applications.
Reading the binary log. mysqlbinlog displays row-based events in the binary log using the
BINLOGstatement (see Section 13.7.6.1, “BINLOG Syntax”). This statement displays an event in printable form, but as a base 64-encoded string the meaning of which is not evident. When invoked with the--base64-output=DECODE-ROWSand--verboseoptions, mysqlbinlog formats the contents of the binary log in a manner that is easily human readable. This is helpful when binary log events were written in row-based format if you want to read or recover from a replication or database failure using the contents of the binary log. For more information, see Section 4.6.7.2, “mysqlbinlog Row Event Display”.Binary log execution errors and slave_exec_mode. If
slave_exec_modeisIDEMPOTENT, a failure to apply changes from RBL because the original row cannot be found does not trigger an error or cause replication to fail. This means that it is possible that updates are not applied on the slave, so that the master and slave are no longer synchronized. Latency issues and use of nontransactional tables with RBR whenslave_exec_modeisIDEMPOTENTcan cause the master and slave to diverge even further. For more information aboutslave_exec_mode, see Section 5.1.4, “Server System Variables”.Noteslave_exec_mode=IDEMPOTENTis generally useful only for circular replication or multi-master replication with MySQL Cluster, for whichIDEMPOTENTis the default value (see Section 18.6, “MySQL Cluster Replication”).For other scenarios, setting
slave_exec_modetoSTRICTis normally sufficient; this is the default value for storage engines other thanNDB.Lack of binary log checksums. RBL uses no checksums. This means that network, disk, and other errors may not be identified when processing the binary log. To ensure that data is transmitted without network corruption, you may want to consider using SSL, which adds another layer of checksumming, for replication connections. The
CHANGE MASTER TOstatement has options to enable replication over SSL. See also Section 13.4.2.1, “CHANGE MASTER TO Syntax”, for general information about setting up MySQL with SSL.Filtering based on server ID not supported. A common practice is to filter out changes on some slaves by using a
WHEREclause that includes the relation@@server_id <>clause withid_valueUPDATEandDELETEstatements, a simple example of such a clause beingWHERE @@server_id <> 1. However, this does not work correctly with row-based logging. If you must use theserver_idsystem variable for statement filtering, you must also use--binlog_format=STATEMENT.In MySQL 5.5, you can do filtering based on server ID by using the
IGNORE_SERVER_IDSoption for theCHANGE MASTER TOstatement. This option works with the statement-based and row-based logging formats.Database-level replication options. The effects of the
--replicate-do-db,--replicate-ignore-db, and--replicate-rewrite-dboptions differ considerably depending on whether row-based or statement-based logging is used. Because of this, it is recommended to avoid database-level options and instead use table-level options such as--replicate-do-tableand--replicate-ignore-table. For more information about these options and the impact that your choice of replication format has on how they operate, see Section 17.1.3, “Replication and Binary Logging Options and Variables”.RBL, nontransactional tables, and stopped slaves. When using row-based logging, if the slave server is stopped while a slave thread is updating a nontransactional table, the slave database may reaches an inconsistent state. For this reason, it is recommended that you use a transactional storage engine such as
InnoDBfor all tables replicated using the row-based format.Use of
STOP SLAVE(orSTOP SLAVE SQL_THREADin MySQL 5.5.9 and later) prior to shutting down the slave MySQL server helps prevent such issues from occurring, and is always recommended regardless of the logging format or storage engines employed.
When speaking of the “safeness” of a statement in MySQL Replication, we are referring to whether a statement and its effects can be replicated correctly using statement-based format. If this is true of the statement, we refer to the statement as safe; otherwise, we refer to it as unsafe.
In general, a statement is safe if it deterministic, and unsafe if it is not. However, certain nondeterministic functions are not considered unsafe (see Nondeterministic functions not considered unsafe, later in this section). In addition, statements using results from floating-point math functions—which are hardware-dependent—are always considered unsafe (see Section 17.4.1.13, “Replication and Floating-Point Values”).
Handling of safe and unsafe statements.
A statement is treated differently depending on whether the
statement is considered safe, and with respect to the binary
logging format (that is, the current value of
binlog_format).
No distinction is made in the treatment of safe and unsafe statements when the binary logging mode is
ROW.If the binary logging format is
MIXED, statements flagged as unsafe are logged using the row-based format; statements regarded as safe are logged using the statement-based format.If the binary logging format is
STATEMENT, statements flagged as being unsafe generate a warning to this effect. (Safe statements are logged normally.)
Each statement flagged as unsafe generates a warning. Formerly,
in cases where a great many such statements were executed on the
master, this could lead to very large error log files, sometimes
even filling up an entire disk unexpectedly. To guard against
this, MySQL 5.5.27 introduced a warning suppression mechanism,
which behaves as follows: Whenever the 50 most recent
ER_BINLOG_UNSAFE_STATEMENT
warnings have been generated more than 50 times in any 50-second
period, warning suppression is enabled. When activated, this
causes such warnings not to be written to the error log;
instead, for each 50 warnings of this type, a note The
last warning was repeated is written
to the error log. This continues as long as the 50 most recent
such warnings were issued in 50 seconds or less; once the rate
has decreased below this threshold, the warnings are once again
logged normally. Warning suppression has no effect on how the
safety of statements for statement-based logging is determined,
nor on how warnings are sent to the client (MySQL clients still
receive one warning for each such statement).
N times in
last S seconds
For more information, see Section 17.1.2, “Replication Formats”.
Statements considered unsafe. Statements having the following characteristics are considered unsafe:
Statements containing system functions that may return a different value on slave. These functions include
FOUND_ROWS(),GET_LOCK(),IS_FREE_LOCK(),IS_USED_LOCK(),LOAD_FILE(),MASTER_POS_WAIT(),RAND(),RELEASE_LOCK(),ROW_COUNT(),SESSION_USER(),SLEEP(),SYSDATE(),SYSTEM_USER(),USER(),UUID(), andUUID_SHORT().Nondeterministic functions not considered unsafe. Although these functions are not deterministic, they are treated as safe for purposes of logging and replication:
CONNECTION_ID(),CURDATE(),CURRENT_DATE(),CURRENT_TIME(),CURRENT_TIMESTAMP(),CURTIME(),LOCALTIME(),LOCALTIMESTAMP(),NOW(),UNIX_TIMESTAMP(),UTC_DATE(),UTC_TIME(),UTC_TIMESTAMP(), andLAST_INSERT_ID()For more information, see Section 17.4.1.15, “Replication and System Functions”.
References to system variables. Most system variables are not replicated correctly using the statement-based format. For exceptions, see Section 5.2.4.3, “Mixed Binary Logging Format”.
UDFs. Since we have no control over what a UDF does, we must assume that it is executing unsafe statements.
Updates a table having an AUTO_INCREMENT column. Prior to MySQL 5.5.3, all such statements were always considered unsafe because the order in which the rows are updated could differ on the master and the slave. In MySQL 5.3.3 and later, these statements are unsafe only when they are executed by a trigger or stored program (Bug #50192, Bug #11758052).
An
INSERTinto a table that has a composite primary key containing anAUTO_INCREMENTcolumn that is not the first column of this composite key is unsafe.For more information, see Section 17.4.1.1, “Replication and AUTO_INCREMENT”.
INSERT DELAYED statement. This statement is considered unsafe because the insertion of the rows may interleave with concurrently executing statements.
INSERT ... ON DUPLICATE KEY UPDATE statements on tables with multiple primary or unique keys. When executed against a table that contains more than one primary or unique key, this statement is considered unsafe, being sensitive to the order in which the storage engine checks the keys, which is not deterministic, and on which the choice of rows updated by the MySQL Server depends.
An
INSERT ... ON DUPLICATE KEY UPDATEstatement against a table having more than one unique or primary key is marked as unsafe for statement-based replication beginning with MySQL 5.5.24. (Bug #11765650, Bug #58637)Updates using LIMIT. The order in which rows are retrieved is not specified.
Accesses or references log tables. The contents of the system log table may differ between master and slave.
Nontransactional operations after transactional operations. Within a transaction, allowing any nontransactional reads or writes to execute after any transactional reads or writes is considered unsafe.
For more information, see Section 17.4.1.35, “Replication and Transactions”.
Accesses or references self-logging tables. All reads and writes to self-logging tables are considered unsafe. Within a transaction, any statement following a read or write to self-logging tables is also considered unsafe.
LOAD DATA INFILE statements. Beginning with MySQL 5.5.6,
LOAD DATA INFILEis considered unsafe, it causes a warning in statement-based mode, and a switch to row-based format when using mixed-format logging. See Section 17.4.1.17, “Replication and LOAD DATA INFILE”.
For additional information, see Section 17.4.1, “Replication Features and Issues”.
The next few sections contain information about mysqld options and server variables that are used in replication and for controlling the binary log. Options and variables for use on replication masters and replication slaves are covered separately, as are options and variables relating to binary logging. A set of quick-reference tables providing basic information about these options and variables is also included (in the next section following this one).
Of particular importance is the
--server-id option.
| Command-Line Format | --server-id=# | ||
| System Variable | Name | server_id | |
| Variable Scope | Global | ||
| Dynamic Variable | Yes | ||
| Permitted Values | Type | integer | |
| Default | 0 | ||
| Min Value | 0 | ||
| Max Value | 4294967295 | ||
This option is common to both master and slave replication servers, and is used in replication to enable master and slave servers to identify themselves uniquely. For additional information, see Section 17.1.3.2, “Replication Master Options and Variables”, and Section 17.1.3.3, “Replication Slave Options and Variables”.
On the master and each slave, you must use the
--server-id option to establish a
unique replication ID in the range from 1 to
232 − 1. “Unique”,
means that each ID must be different from every other ID in use by
any other replication master or slave. Example:
server-id=3.
If you omit --server-id, the default
ID is 0, in which case the master refuses connections from all
slaves, and slaves refuse to connect to the master. In MySQL
5.5, whether the server ID is set to 0 explicitly or
the default is allowed to be used, the server sets the
server_id system variable to 1; this is a known
issue that is fixed in MySQL 5.7.
For more information, see Section 17.1.1.2, “Setting the Replication Slave Configuration”.
The following tables list basic information about the MySQL command-line options and system variables applicable to replication and the binary log.
Table 17.1 Summary of Replication options and variables in MySQL 5.5
| Option or Variable Name | ||
|---|---|---|
| Command Line | System Variable | Status Variable |
| Option File | Scope | Dynamic |
| Notes | ||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Option used by mysql-test for debugging and testing of replication |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of CHANGE MASTER TO statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of SHOW MASTER STATUS statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of SHOW NEW MASTER statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of SHOW SLAVE HOSTS statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of SHOW SLAVE STATUS statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of START SLAVE statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of STOP SLAVE statements |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Option used by mysql-test for debugging and testing of replication |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Statements that are executed when a slave connects to a master |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Tells the slave to log the updates performed by its SQL thread to its own binary log |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Whether the slave should log the updates performed by its SQL thread to its own binary log. Read-only; set using the --log-slave-updates server option. |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Number of seconds the slave thread will sleep before retrying to connect to the master in case the master goes down or the connection is lost |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Master host name or IP address for replication |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: The location and name of the file that remembers the master and where the I/O replication thread is in the master's binary logs |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: The password the slave thread will authenticate with when connecting to master |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: The port the master is listening on |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Number of tries the slave makes to connect to the master before giving up |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Enable the slave to connect to the master using SSL |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Master SSL CA file; applies only if master-ssl is enabled |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Master SSL CA path; applies only if master-ssl is enabled |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Master SSL certificate file name; applies only if master-ssl is enabled |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Master SSL cipher; applies only if master-ssl is enabled |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Master SSL key file name; applies only if master-ssl is enabled |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: The user name the slave thread will use for authentication when connecting to master. The user must have FILE privilege. If the master user is not set, user test is assumed. The value in master.info will take precedence if it can be read |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: The location and base name to use for relay logs |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: The location and name to use for the file that keeps a list of the last relay logs |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: The location and name of the file that remembers where the SQL replication thread is in the relay logs |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Enables automatic recovery of relay log files from master at startup |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: The name of the relay log index file |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: The name of the file in which the slave records information about the relay logs |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Determines whether relay logs are purged |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Whether automatic recovery of relay log files from master at startup is enabled; must be enabled for a crash-safe slave. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Maximum space to use for all relay logs |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Tells the slave SQL thread to restrict replication to the specified database |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Tells the slave SQL thread to restrict replication to the specified table |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Tells the slave SQL thread not to replicate to the specified database |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Tells the slave SQL thread not to replicate to the specified table |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Updates to a database with a different name than the original |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: In replication, if set to 1, do not skip events having our server id |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Tells the slave thread to restrict replication to the tables that match the specified wildcard pattern |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Tells the slave thread not to replicate to the tables that match the given wildcard pattern |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Host name or IP of the slave to be reported to the master during slave registration |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: An arbitrary password that the slave server should report to the master. Not the same as the password for the MySQL replication user account. |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Port for connecting to slave reported to the master during slave registration |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: An arbitrary user name that a slave server should report to the master. Not the same as the name used with the MySQL replication user account. |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Not used; removed in later versions |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of semisynchronous slaves |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Whether semisynchronous replication is enabled on the master |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The average time the master waited for a slave reply |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The total time the master waited for slave replies |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The total number of times the master waited for slave replies |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times the master turned off semisynchronous replication |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of commits not acknowledged successfully |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Whether semisynchronous replication is operational on the master |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of times the master failed when calling time functions |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Number of milliseconds to wait for slave acknowledgment |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: The semisynchronous replication debug trace level on the master |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The average time the master waited for each transaction |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The total time the master waited for transactions |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The total number of times the master waited for transactions |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Whether master waits for timeout even with no slaves |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The total number of times the master waited for an event with binary coordinates lower than events waited for previously |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of sessions currently waiting for slave replies |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of commits acknowledged successfully |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Whether semisynchronous replication is enabled on slave |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Whether semisynchronous replication is operational on slave |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: The semisynchronous replication debug trace level on the slave |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The status of fail-safe replication (not implemented) |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Show user name and password in SHOW SLAVE HOSTS on this master |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: If set, slave is not autostarted |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: The location where the slave should put its temporary files when replicating a LOAD DATA INFILE statement |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Maximum size, in bytes, of a packet that can be sent from a replication master to a slave; overrides max_allowed_packet. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Number of seconds to wait for more data from a master/slave connection before aborting the read |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Tells the slave thread to continue replication when a query returns an error from the provided list |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Use compression on master/slave protocol |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Allows for switching the slave thread between IDEMPOTENT mode (key and some other errors suppressed) and STRICT mode; STRICT mode is the default, except for MySQL Cluster, where IDEMPOTENT is always used |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The slave's replication heartbeat interval, in seconds |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Maximum size, in bytes, of a packet that can be sent from a replication master to a slave; overrides max_allowed_packet. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of temporary tables that the slave SQL thread currently has open |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The total number of times since startup that the replication slave SQL thread has retried transactions |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: The state of this server as a replication slave (slave I/O thread status) |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Number of times the slave SQL thread will retry a transaction in case it failed with a deadlock or elapsed lock wait timeout, before giving up and stopping |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Controls type conversion mode on replication slave. Value is a list of zero or more elements from the list: ALL_LOSSY, ALL_NON_LOSSY. Set to an empty string to disallow type conversions between master and slave. |
||
| No | Yes | No |
| No | Global | Yes |
DESCRIPTION: Number of events from the master that a slave server should skip. Not compatible with GTID replication. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Synchronously flush binary log to disk after every #th event |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Synchronize master.info to disk after every #th event. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Synchronize relay log to disk after every #th event. |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Synchronize relay.info file to disk after every #th event. |
||
Section 17.1.3.2, “Replication Master Options and Variables”, provides more detailed information about options and variables relating to replication master servers. For more information about options and variables relating to replication slaves, see Section 17.1.3.3, “Replication Slave Options and Variables”.
Table 17.2 Summary of Binary Logging options and variables in MySQL 5.5
| Option or Variable Name | ||
|---|---|---|
| Command Line | System Variable | Status Variable |
| Option File | Scope | Dynamic |
| Notes | ||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Limits binary logging to specific databases |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Specifies the format of the binary log |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Tells the master that updates to the given database should not be logged to the binary log |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Binary log max event size |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions that used a temporary file instead of the binary log cache |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Size of the cache to hold the SQL statements for the binary log during a transaction |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of transactions that used the temporary binary log cache |
||
| Yes | Yes | No |
| Yes | Both | Yes |
DESCRIPTION: Causes updates using statement format to nontransactional engines to be written directly to binary log. See documentation before using. |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of nontransactional statements that used a temporary file instead of the binary log statement cache |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Size of the cache to hold nontransactional statements for the binary log during a transaction |
||
| No | No | Yes |
| No | Global | No |
DESCRIPTION: Number of statements that used the temporary binary log statement cache |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of SHOW BINLOG EVENTS statements |
||
| No | No | Yes |
| No | Both | No |
DESCRIPTION: Count of SHOW BINLOGS statements |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Use version 1 binary log row events |
||
| Yes | Yes | No |
| Yes | Global | No |
DESCRIPTION: Shows whether server is using version 1 binary log row events |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Option used by mysql-test for debugging and testing of replication |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Can be used to restrict the total size used to cache a multi-statement transaction |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Binary log will be rotated automatically when size exceeds this value |
||
| Yes | Yes | No |
| Yes | Global | Yes |
DESCRIPTION: Can be used to restrict the total size used to cache all nontransactional statements during a transaction |
||
| Yes | No | No |
| Yes | No | |
DESCRIPTION: Option used by mysql-test for debugging and testing of replication |
||
Section 17.1.3.4, “Binary Log Options and Variables”, provides more detailed information about options and variables relating to binary logging. For additional general information about the binary log, see Section 5.2.4, “The Binary Log”.
For information about the
sql_log_bin and
sql_log_off variables, see
Section 5.1.4, “Server System Variables”.
For a table showing all command-line options, system and status variables used with mysqld, see Section 5.1.1, “Server Option and Variable Reference”.
This section describes the server options and system variables
that you can use on replication master servers. You can specify
the options either on the
command line or in an
option file. You can specify
system variable values using
SET.
On the master and each slave, you must use the
server-id option to establish a
unique replication ID. For each server, you should pick a unique
positive integer in the range from 1 to
232 − 1, and each ID must be
different from every other ID in use by any other replication
master or slave. Example: server-id=3.
For options used on the master for controlling binary logging, see Section 17.1.3.4, “Binary Log Options and Variables”.
The following system variables are used in controlling replication masters:
-
System Variable Name auto_increment_incrementVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type integerDefault 1Min Value 1Max Value 65535auto_increment_incrementandauto_increment_offsetare intended for use with master-to-master replication, and can be used to control the operation ofAUTO_INCREMENTcolumns. Both variables have global and session values, and each can assume an integer value between 1 and 65,535 inclusive. Setting the value of either of these two variables to 0 causes its value to be set to 1 instead. Attempting to set the value of either of these two variables to an integer greater than 65,535 or less than 0 causes its value to be set to 65,535 instead. Attempting to set the value ofauto_increment_incrementorauto_increment_offsetto a noninteger value gives rise to an error, and the actual value of the variable remains unchanged.Noteauto_increment_incrementis also supported for use withNDBtables.These two variables affect
AUTO_INCREMENTcolumn behavior as follows:auto_increment_incrementcontrols the interval between successive column values. For example:mysql>
SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 1 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set (0.00 sec) mysql>CREATE TABLE autoinc1->(col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);Query OK, 0 rows affected (0.04 sec) mysql>SET @@auto_increment_increment=10;Query OK, 0 rows affected (0.00 sec) mysql>SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 10 | | auto_increment_offset | 1 | +--------------------------+-------+ 2 rows in set (0.01 sec) mysql>INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql>SELECT col FROM autoinc1;+-----+ | col | +-----+ | 1 | | 11 | | 21 | | 31 | +-----+ 4 rows in set (0.00 sec)auto_increment_offsetdetermines the starting point for theAUTO_INCREMENTcolumn value. Consider the following, assuming that these statements are executed during the same session as the example given in the description forauto_increment_increment:mysql>
SET @@auto_increment_offset=5;Query OK, 0 rows affected (0.00 sec) mysql>SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 10 | | auto_increment_offset | 5 | +--------------------------+-------+ 2 rows in set (0.00 sec) mysql>CREATE TABLE autoinc2->(col INT NOT NULL AUTO_INCREMENT PRIMARY KEY);Query OK, 0 rows affected (0.06 sec) mysql>INSERT INTO autoinc2 VALUES (NULL), (NULL), (NULL), (NULL);Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql>SELECT col FROM autoinc2;+-----+ | col | +-----+ | 5 | | 15 | | 25 | | 35 | +-----+ 4 rows in set (0.02 sec)If the value of
auto_increment_offsetis greater than that ofauto_increment_increment, the value ofauto_increment_offsetis ignored.
Should one or both of these variables be changed and then new rows inserted into a table containing an
AUTO_INCREMENTcolumn, the results may seem counterintuitive because the series ofAUTO_INCREMENTvalues is calculated without regard to any values already present in the column, and the next value inserted is the least value in the series that is greater than the maximum existing value in theAUTO_INCREMENTcolumn. In other words, the series is calculated like so:auto_increment_offset+N×auto_increment_incrementwhere
Nis a positive integer value in the series [1, 2, 3, ...]. For example:mysql>
SHOW VARIABLES LIKE 'auto_inc%';+--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | auto_increment_increment | 10 | | auto_increment_offset | 5 | +--------------------------+-------+ 2 rows in set (0.00 sec) mysql>SELECT col FROM autoinc1;+-----+ | col | +-----+ | 1 | | 11 | | 21 | | 31 | +-----+ 4 rows in set (0.00 sec) mysql>INSERT INTO autoinc1 VALUES (NULL), (NULL), (NULL), (NULL);Query OK, 4 rows affected (0.00 sec) Records: 4 Duplicates: 0 Warnings: 0 mysql>SELECT col FROM autoinc1;+-----+ | col | +-----+ | 1 | | 11 | | 21 | | 31 | | 35 | | 45 | | 55 | | 65 | +-----+ 8 rows in set (0.00 sec)The values shown for
auto_increment_incrementandauto_increment_offsetgenerate the series 5 +N× 10, that is, [5, 15, 25, 35, 45, ...]. The greatest value present in thecolcolumn prior to theINSERTis 31, and the next available value in theAUTO_INCREMENTseries is 35, so the inserted values forcolbegin at that point and the results are as shown for theSELECTquery.It is not possible to confine the effects of these two variables to a single table, and thus they do not take the place of the sequences offered by some other database management systems; these variables control the behavior of all
AUTO_INCREMENTcolumns in all tables on the MySQL server. If the global value of either variable is set, its effects persist until the global value is changed or overridden by setting the session value, or until mysqld is restarted. If the local value is set, the new value affectsAUTO_INCREMENTcolumns for all tables into which new rows are inserted by the current user for the duration of the session, unless the values are changed during that session.The default value of
auto_increment_incrementis 1. See Section 17.4.1.1, “Replication and AUTO_INCREMENT”. -
System Variable Name auto_increment_offsetVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type integerDefault 1Min Value 1Max Value 65535This variable has a default value of 1. For particulars, see the description for
auto_increment_increment.Noteauto_increment_offsetis also supported for use withNDBtables.
Startup Options for Replication Slaves
Obsolete Replication Slave Options
System Variables Used on Replication Slaves
This section describes the server options and system variables
that apply to slave replication servers. You can specify the
options either on the command
line or in an option
file. Many of the options can be set while the server is
running by using the CHANGE MASTER
TO statement. You can specify system variable values
using
SET.
Server ID.
On the master and each slave, you must use the
server-id option to establish a
unique replication ID in the range from 1 to
232 − 1. “Unique”
means that each ID must be different from every other ID in use
by any other replication master or slave. Example
my.cnf file:
[mysqld] server-id=3
The following list describes startup options for controlling
replication slave servers. Many of these options can be set
while the server is running by using the
CHANGE MASTER TO statement.
Others, such as the --replicate-* options, can
be set only when the slave server starts. Replication-related
system variables are discussed later in this section.
-
Command-Line Format --abort-slave-event-count=#Permitted Values Type integerDefault 0Min Value 0When this option is set to some positive integer
valueother than 0 (the default) it affects replication behavior as follows: After the slave SQL thread has started,valuelog events are permitted to be executed; after that, the slave SQL thread does not receive any more events, just as if the network connection from the master were cut. The slave thread continues to run, and the output fromSHOW SLAVE STATUSdisplaysYesin both theSlave_IO_Runningand theSlave_SQL_Runningcolumns, but no further events are read from the relay log.This option is used internally by the MySQL test suite for replication testing and debugging. It is not intended for use in a production setting.
--disconnect-slave-event-countCommand-Line Format --disconnect-slave-event-count=#Permitted Values Type integerDefault 0This option is used internally by the MySQL test suite for replication testing and debugging.
-
Command-Line Format --log-slave-updatesSystem Variable Name log_slave_updatesVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault OFFNormally, a slave does not log to its own binary log any updates that are received from a master server. This option tells the slave to log the updates performed by its SQL thread to its own binary log. For this option to have any effect, the slave must also be started with the
--log-binoption to enable binary logging. Prior to MySQL 5.5, the server would not start when using the--log-slave-updatesoption without also starting the server with the--log-binoption, and would fail with an error; in MySQL 5.5, only a warning is generated. (Bug #44663)--log-slave-updatesis used when you want to chain replication servers. For example, you might want to set up replication servers using this arrangement:A -> B -> C
Here,
Aserves as the master for the slaveB, andBserves as the master for the slaveC. For this to work,Bmust be both a master and a slave. You must start bothAandBwith--log-binto enable binary logging, andBwith the--log-slave-updatesoption so that updates received fromAare logged byBto its binary log. -
Command-Line Format --log-slow-slave-statementsPermitted Values Type booleanDefault OFFWhen the slow query log is enabled, this option enables logging for queries that have taken more than
long_query_timeseconds to execute on the slave. -
Command-Line Format --log-warnings[=#]System Variable Name log_warningsVariable Scope Global, Session Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 1Min Value 0Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 1Min Value 0Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 1Min Value 0Max Value 18446744073709551615This option causes a server to print more messages to the error log about what it is doing. With respect to replication, the server generates warnings that it succeeded in reconnecting after a network/connection failure, and informs you as to how each slave thread started. This option is enabled (1) by default; to disable it, use
--log-warnings=0. If the value is greater than 1, aborted connections are written to the error log, and access-denied errors for new connection attempts are written. See Section B.5.2.11, “Communication Errors and Aborted Connections”.Note that the effects of this option are not limited to replication. It produces warnings across a spectrum of server activities.
-
Command-Line Format --master-info-file=file_namePermitted Values Type file nameDefault master.infoThe name to use for the file in which the slave records information about the master. The default name is
master.infoin the data directory. For information about the format of this file, see Section 17.2.2.2, “Slave Status Logs”. -
Command-Line Format --master-retry-count=#Permitted Values (32-bit platforms) Type integerDefault 86400Min Value 0Max Value 4294967295Permitted Values (64-bit platforms) Type integerDefault 86400Min Value 0Max Value 18446744073709551615The number of times that the slave tries to connect to the master before giving up. Reconnects are attempted at intervals set by the
MASTER_CONNECT_RETRYoption of theCHANGE MASTER TOstatement (default 60). Reconnects are triggered when data reads by the slave time out according to the--slave-net-timeoutoption. The default value is 86400. A value of 0 means “infinite”; the slave attempts to connect forever. slave-max-allowed-packet=bytesIntroduced 5.5.26 Command-Line Format --slave-max-allowed-packet=#Permitted Values Type integerDefault 1073741824Min Value 1024Max Value 1073741824In MySQL 5.5.26 and later, this option sets the maximum packet size in bytes for the slave SQL and I/O threads, so that large updates using row-based replication do not cause replication to fail because an update exceeded
max_allowed_packet. (Bug #12400221, Bug #60926)The corresponding server variable
slave_max_allowed_packetalways has a value that is a positive integer multiple of 1024; if you set it to some value that is not such a multiple, the value is automatically rounded down to the next highest multiple of 1024. (For example, if you start the server with--slave-max-allowed-packet=10000, the value used is 9216; setting 0 as the value causes 1024 to be used.) A truncation warning is issued in such cases.The maximum (and default) value is 1073741824 (1 GB); the minimum is 1024.
-
Command-Line Format --max_relay_log_size=#System Variable Name max_relay_log_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type integerDefault 0Min Value 0Max Value 1073741824The size at which the server rotates relay log files automatically. If this value is nonzero, the relay log is rotated automatically when its size exceeds this value. If this value is zero (the default), the size at which relay log rotation occurs is determined by the value of
max_binlog_size. For more information, see Section 17.2.2.1, “The Slave Relay Log”. -
Command-Line Format --relay-log=file_nameSystem Variable Name relay_logVariable Scope Global Dynamic Variable No Permitted Values Type file nameThe base name for the relay log. The default base name is
host_name-relay-binDue to the manner in which MySQL parses server options, if you specify this option, you must supply a value; the default base name is used only if the option is not actually specified. If you use the
--relay-logoption without specifying a value, unexpected behavior is likely to result; this behavior depends on the other options used, the order in which they are specified, and whether they are specified on the command line or in an option file. For more information about how MySQL handles server options, see Section 4.2.3, “Specifying Program Options”.If you specify this option, the value specified is also used as the base name for the relay log index file. You can override this behavior by specifying a different relay log index file base name using the
--relay-log-indexoption.Starting with MySQL 5.5.20, when the server reads an entry from the index file, it checks whether the entry contains a relative path. If it does, the relative part of the path in replaced with the absolute path set using the
--relay-logoption. An absolute path remains unchanged; in such a case, the index must be edited manually to enable the new path or paths to be used. Prior to MySQL 5.5.20, manual intervention was required whenever relocating the binary log or relay log files. (Bug #11745230, Bug #12133)You may find the
--relay-logoption useful in performing the following tasks:Creating relay logs whose names are independent of host names.
If you need to put the relay logs in some area other than the data directory because your relay logs tend to be very large and you do not want to decrease
max_relay_log_size.To increase speed by using load-balancing between disks.
-
Command-Line Format --relay-log-index=file_nameSystem Variable Name relay_log_indexVariable Scope Global Dynamic Variable No Permitted Values Type file nameThe name to use for the relay log index file. The default name is
host_name-relay-bin.indexhost_nameis the name of the slave server.Due to the manner in which MySQL parses server options, if you specify this option, you must supply a value; the default base name is used only if the option is not actually specified. If you use the
--relay-log-indexoption without specifying a value, unexpected behavior is likely to result; this behavior depends on the other options used, the order in which they are specified, and whether they are specified on the command line or in an option file. For more information about how MySQL handles server options, see Section 4.2.3, “Specifying Program Options”.If you specify this option, the value specified is also used as the base name for the relay logs. You can override this behavior by specifying a different relay log file base name using the
--relay-logoption. --relay-log-info-file=file_nameCommand-Line Format --relay-log-info-file=file_namePermitted Values Type file nameDefault relay-log.infoThe name to use for the file in which the slave records information about the relay logs. The default name is
relay-log.infoin the data directory. For information about the format of this file, see Section 17.2.2.2, “Slave Status Logs”.-
Command-Line Format --relay_log_purgeSystem Variable Name relay_log_purgeVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault TRUEDisable or enable automatic purging of relay logs as soon as they are no longer needed. The default value is 1 (enabled). This is a global variable that can be changed dynamically with
SET GLOBAL relay_log_purge =.N -
Command-Line Format --relay-log-recoveryPermitted Values Type booleanDefault FALSEEnables automatic relay log recovery immediately following server startup, which means that the replication slave discards all unprocessed relay logs and retrieves them from the replication master. This should be used following a crash on the replication slave to ensure that no possibly corrupted relay logs are processed. The default value is 0 (disabled).
-
Command-Line Format --relay_log_space_limit=#System Variable Name relay_log_space_limitVariable Scope Global Dynamic Variable No Permitted Values (32-bit platforms) Type integerDefault 0Min Value 0Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 0Min Value 0Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 0Min Value 0Max Value 18446744073709551615This option places an upper limit on the total size in bytes of all relay logs on the slave. A value of 0 means “no limit.” This is useful for a slave server host that has limited disk space. When the limit is reached, the I/O thread stops reading binary log events from the master server until the SQL thread has caught up and deleted some unused relay logs. Note that this limit is not absolute: There are cases where the SQL thread needs more events before it can delete relay logs. In that case, the I/O thread exceeds the limit until it becomes possible for the SQL thread to delete some relay logs because not doing so would cause a deadlock. You should not set
--relay-log-space-limitto less than twice the value of--max-relay-log-size(or--max-binlog-sizeif--max-relay-log-sizeis 0). In that case, there is a chance that the I/O thread waits for free space because--relay-log-space-limitis exceeded, but the SQL thread has no relay log to purge and is unable to satisfy the I/O thread. This forces the I/O thread to ignore--relay-log-space-limittemporarily. -
Command-Line Format --replicate-do-db=namePermitted Values Type stringThe effects of this option depend on whether statement-based or row-based replication is in use.
Statement-based replication. Tell the slave SQL thread to restrict replication to statements where the default database (that is, the one selected by
USE) isdb_name. To specify more than one database, use this option multiple times, once for each database; however, doing so does not replicate cross-database statements such asUPDATEwhile a different database (or no database) is selected.some_db.some_tableSET foo='bar'WarningTo specify multiple databases you must use multiple instances of this option. Because database names can contain commas, if you supply a comma separated list then the list will be treated as the name of a single database.
An example of what does not work as you might expect when using statement-based replication: If the slave is started with
--replicate-do-db=salesand you issue the following statements on the master, theUPDATEstatement is not replicated:USE prices; UPDATE sales.january SET amount=amount+1000;
The main reason for this “check just the default database” behavior is that it is difficult from the statement alone to know whether it should be replicated (for example, if you are using multiple-table
DELETEstatements or multiple-tableUPDATEstatements that act across multiple databases). It is also faster to check only the default database rather than all databases if there is no need.Row-based replication. Tells the slave SQL thread to restrict replication to database
db_name. Only tables belonging todb_nameare changed; the current database has no effect on this. Suppose that the slave is started with--replicate-do-db=salesand row-based replication is in effect, and then the following statements are run on the master:USE prices; UPDATE sales.february SET amount=amount+100;
The
februarytable in thesalesdatabase on the slave is changed in accordance with theUPDATEstatement; this occurs whether or not theUSEstatement was issued. However, issuing the following statements on the master has no effect on the slave when using row-based replication and--replicate-do-db=sales:USE prices; UPDATE prices.march SET amount=amount-25;
Even if the statement
USE priceswere changed toUSE sales, theUPDATEstatement's effects would still not be replicated.Another important difference in how
--replicate-do-dbis handled in statement-based replication as opposed to row-based replication occurs with regard to statements that refer to multiple databases. Suppose that the slave is started with--replicate-do-db=db1, and the following statements are executed on the master:USE db1; UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
If you are using statement-based replication, then both tables are updated on the slave. However, when using row-based replication, only
table1is affected on the slave; sincetable2is in a different database,table2on the slave is not changed by theUPDATE. Now suppose that, instead of theUSE db1statement, aUSE db4statement had been used:USE db4; UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
In this case, the
UPDATEstatement would have no effect on the slave when using statement-based replication. However, if you are using row-based replication, theUPDATEwould changetable1on the slave, but nottable2—in other words, only tables in the database named by--replicate-do-dbare changed, and the choice of default database has no effect on this behavior.If you need cross-database updates to work, use
--replicate-wild-do-table=instead. See Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.db_name.%NoteThis option affects replication in the same manner that
--binlog-do-dbaffects binary logging, and the effects of the replication format on how--replicate-do-dbaffects replication behavior are the same as those of the logging format on the behavior of--binlog-do-db.This option has no effect on
BEGIN,COMMIT, orROLLBACKstatements. -
Command-Line Format --replicate-ignore-db=namePermitted Values Type stringAs with
--replicate-do-db, the effects of this option depend on whether statement-based or row-based replication is in use.Statement-based replication. Tells the slave SQL thread not to replicate any statement where the default database (that is, the one selected by
USE) isdb_name.Row-based replication. Tells the slave SQL thread not to update any tables in the database
db_name. The default database has no effect.When using statement-based replication, the following example does not work as you might expect. Suppose that the slave is started with
--replicate-ignore-db=salesand you issue the following statements on the master:USE prices; UPDATE sales.january SET amount=amount+1000;
The
UPDATEstatement is replicated in such a case because--replicate-ignore-dbapplies only to the default database (determined by theUSEstatement). Because thesalesdatabase was specified explicitly in the statement, the statement has not been filtered. However, when using row-based replication, theUPDATEstatement's effects are not propagated to the slave, and the slave's copy of thesales.januarytable is unchanged; in this instance,--replicate-ignore-db=salescauses all changes made to tables in the master's copy of thesalesdatabase to be ignored by the slave.To specify more than one database to ignore, use this option multiple times, once for each database. Because database names can contain commas, if you supply a comma separated list then the list will be treated as the name of a single database.
You should not use this option if you are using cross-database updates and you do not want these updates to be replicated. See Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.
If you need cross-database updates to work, use
--replicate-wild-ignore-table=instead. See Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.db_name.%NoteThis option affects replication in the same manner that
--binlog-ignore-dbaffects binary logging, and the effects of the replication format on how--replicate-ignore-dbaffects replication behavior are the same as those of the logging format on the behavior of--binlog-ignore-db.This option has no effect on
BEGIN,COMMIT, orROLLBACKstatements. --replicate-do-table=db_name.tbl_nameCommand-Line Format --replicate-do-table=namePermitted Values Type stringTells the slave SQL thread to restrict replication to the specified table. To specify more than one table, use this option multiple times, once for each table. This works for both cross-database updates and default database updates, in contrast to
--replicate-do-db. See Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.This option affects only statements that apply to tables. It does not affect statements that apply only to other database objects, such as stored routines. To filter statements operating on stored routines, use one or more of the
--replicate-*-dboptions.--replicate-ignore-table=db_name.tbl_nameCommand-Line Format --replicate-ignore-table=namePermitted Values Type stringTells the slave SQL thread not to replicate any statement that updates the specified table, even if any other tables might be updated by the same statement. To specify more than one table to ignore, use this option multiple times, once for each table. This works for cross-database updates, in contrast to
--replicate-ignore-db. See Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.This option affects only statements that apply to tables. It does not affect statements that apply only to other database objects, such as stored routines. To filter statements operating on stored routines, use one or more of the
--replicate-*-dboptions.--replicate-rewrite-db=from_name->to_nameCommand-Line Format --replicate-rewrite-db=old_name->new_namePermitted Values Type stringTells the slave to translate the default database (that is, the one selected by
USE) toto_nameif it wasfrom_nameon the master. Only statements involving tables are affected (not statements such asCREATE DATABASE,DROP DATABASE, andALTER DATABASE), and only iffrom_nameis the default database on the master. To specify multiple rewrites, use this option multiple times. The server uses the first one with afrom_namevalue that matches. The database name translation is done before the--replicate-*rules are tested.Statements in which table names are qualified with database names when using this option do not work with table-level replication filtering options such as
--replicate-do-table. Suppose we have a database namedaon the master, one namedbon the slave, each containing a tablet, and have started the master with--replicate-rewrite-db='a->b'. At a later point in time, we executeDELETE FROM a.t. In this case, no relevant filtering rule works, for the reasons shown here:--replicate-do-table=a.tdoes not work because the slave has tabletin databaseb.--replicate-do-table=b.tdoes not match the original statement and so is ignored.--replicate-do-table=*.tis handled identically to--replicate-do-table=a.t, and thus does not work, either.
Similarly, the
--replication-rewrite-dboption does not work with cross-database updates.If you use this option on the command line and the “
>” character is special to your command interpreter, quote the option value. For example:shell>
mysqld --replicate-rewrite-db="olddb->newdb"-
Command-Line Format --replicate-same-server-idPermitted Values Type booleanDefault FALSETo be used on slave servers. Usually you should use the default setting of 0, to prevent infinite loops caused by circular replication. If set to 1, the slave does not skip events having its own server ID. Normally, this is useful only in rare configurations. Cannot be set to 1 if
--log-slave-updatesis used. By default, the slave I/O thread does not write binary log events to the relay log if they have the slave's server ID (this optimization helps save disk usage). If you want to use--replicate-same-server-id, be sure to start the slave with this option before you make the slave read its own events that you want the slave SQL thread to execute. --replicate-wild-do-table=db_name.tbl_nameCommand-Line Format --replicate-wild-do-table=namePermitted Values Type stringTells the slave thread to restrict replication to statements where any of the updated tables match the specified database and table name patterns. Patterns can contain the “
%” and “_” wildcard characters, which have the same meaning as for theLIKEpattern-matching operator. To specify more than one table, use this option multiple times, once for each table. This works for cross-database updates. See Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.This option applies to tables, views, and triggers. It does not apply to stored procedures and functions, or events. To filter statements operating on the latter objects, use one or more of the
--replicate-*-dboptions.Example:
--replicate-wild-do-table=foo%.bar%replicates only updates that use a table where the database name starts withfooand the table name starts withbar.If the table name pattern is
%, it matches any table name and the option also applies to database-level statements (CREATE DATABASE,DROP DATABASE, andALTER DATABASE). For example, if you use--replicate-wild-do-table=foo%.%, database-level statements are replicated if the database name matches the patternfoo%.To include literal wildcard characters in the database or table name patterns, escape them with a backslash. For example, to replicate all tables of a database that is named
my_own%db, but not replicate tables from themy1ownAABCdbdatabase, you should escape the “_” and “%” characters like this:--replicate-wild-do-table=my\_own\%db. If you use the option on the command line, you might need to double the backslashes or quote the option value, depending on your command interpreter. For example, with the bash shell, you would need to type--replicate-wild-do-table=my\\_own\\%db.--replicate-wild-ignore-table=db_name.tbl_nameCommand-Line Format --replicate-wild-ignore-table=namePermitted Values Type stringTells the slave thread not to replicate a statement where any table matches the given wildcard pattern. To specify more than one table to ignore, use this option multiple times, once for each table. This works for cross-database updates. See Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.
Example:
--replicate-wild-ignore-table=foo%.bar%does not replicate updates that use a table where the database name starts withfooand the table name starts withbar.For information about how matching works, see the description of the
--replicate-wild-do-tableoption. The rules for including literal wildcard characters in the option value are the same as for--replicate-wild-ignore-tableas well.-
Command-Line Format --report-host=host_nameSystem Variable Name report_hostVariable Scope Global Dynamic Variable No Permitted Values Type stringThe host name or IP address of the slave to be reported to the master during slave registration. This value appears in the output of
SHOW SLAVE HOSTSon the master server. Leave the value unset if you do not want the slave to register itself with the master. Note that it is not sufficient for the master to simply read the IP address of the slave from the TCP/IP socket after the slave connects. Due to NAT and other routing issues, that IP may not be valid for connecting to the slave from the master or other hosts. -
Command-Line Format --report-password=nameSystem Variable Name report_passwordVariable Scope Global Dynamic Variable No Permitted Values Type stringThe account password of the slave to be reported to the master during slave registration. This value appears in the output of
SHOW SLAVE HOSTSon the master server if the--show-slave-auth-infooption is given.Although the name of this option might imply otherwise,
--report-passwordis not connected to the MySQL user privilege system and so is not necessarily (or even likely to be) the same as the password for the MySQL replication user account. -
Command-Line Format --report-port=#System Variable Name report_portVariable Scope Global Dynamic Variable No Permitted Values (<= 5.5.22) Type integerDefault 3306Min Value 0Max Value 65535Permitted Values (>= 5.5.23) Type integerDefault 0Min Value 0Max Value 65535The TCP/IP port number for connecting to the slave, to be reported to the master during slave registration. Set this only if the slave is listening on a nondefault port or if you have a special tunnel from the master or other clients to the slave. If you are not sure, do not use this option.
Prior to MySQL 5.5.23, the default value for this option was 3306. In MySQL 5.5.23 and later, the value shown is the port number actually used by the slave (Bug #13333431). This change also affects the default value displayed by
SHOW SLAVE HOSTS. -
Command-Line Format --report-user=nameSystem Variable Name report_userVariable Scope Global Dynamic Variable No Permitted Values Type stringThe account user name of the slave to be reported to the master during slave registration. This value appears in the output of
SHOW SLAVE HOSTSon the master server if the--show-slave-auth-infooption is given.Although the name of this option might imply otherwise,
--report-useris not connected to the MySQL user privilege system and so is not necessarily (or even likely to be) the same as the name of the MySQL replication user account. -
Command-Line Format --show-slave-auth-infoPermitted Values Type booleanDefault FALSEDisplay slave user names and passwords in the output of
SHOW SLAVE HOSTSon the master server for slaves started with the--report-userand--report-passwordoptions. -
Command-Line Format --skip-slave-startPermitted Values Type booleanDefault FALSETells the slave server not to start the slave threads when the server starts. To start the threads later, use a
START SLAVEstatement. --slave_compressed_protocol={0|1}Command-Line Format --slave_compressed_protocolSystem Variable Name slave_compressed_protocolVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFIf this option is set to 1, use compression for the slave/master protocol if both the slave and the master support it. The default is 0 (no compression).
-
Command-Line Format --slave-load-tmpdir=dir_nameSystem Variable Name slave_load_tmpdirVariable Scope Global Dynamic Variable No Permitted Values Type directory nameDefault /tmpThe name of the directory where the slave creates temporary files. This option is by default equal to the value of the
tmpdirsystem variable. When the slave SQL thread replicates aLOAD DATA INFILEstatement, it extracts the file to be loaded from the relay log into temporary files, and then loads these into the table. If the file loaded on the master is huge, the temporary files on the slave are huge, too. Therefore, it might be advisable to use this option to tell the slave to put temporary files in a directory located in some file system that has a lot of available space. In that case, the relay logs are huge as well, so you might also want to use the--relay-logoption to place the relay logs in that file system.The directory specified by this option should be located in a disk-based file system (not a memory-based file system) because the temporary files used to replicate
LOAD DATA INFILEmust survive machine restarts. The directory also should not be one that is cleared by the operating system during the system startup process. -
Command-Line Format --slave-net-timeout=#System Variable Name slave_net_timeoutVariable Scope Global Dynamic Variable Yes Permitted Values Type integerDefault 3600Min Value 1The number of seconds to wait for more data from the master before the slave considers the connection broken, aborts the read, and tries to reconnect. The first retry occurs immediately after the timeout. The interval between retries is controlled by the
MASTER_CONNECT_RETRYoption for theCHANGE MASTER TOstatement, and the number of reconnection attempts is limited by the--master-retry-countoption. The default is 3600 seconds (one hour). --slave-skip-errors=[err_code1,err_code2,...|all](MySQL Cluster NDB 7.2.6 and later:)
--slave-skip-errors=[err_code1,err_code2,...|all|ddl_exist_errors]Command-Line Format --slave-skip-errors=nameSystem Variable Name slave_skip_errorsVariable Scope Global Dynamic Variable No Permitted Values Type stringDefault OFFValid Values OFF[list of error codes]allPermitted Values Type stringDefault OFFValid Values OFF[list of error codes]allddl_exist_errorsPermitted Values (>= 5.5.22-ndb-7.2.6) Type stringDefault OFFValid Values OFF[list of error codes]allddl_exist_errorsNormally, replication stops when an error occurs on the slave. This gives you the opportunity to resolve the inconsistency in the data manually. This option tells the slave SQL thread to continue replication when a statement returns any of the errors listed in the option value.
Do not use this option unless you fully understand why you are getting errors. If there are no bugs in your replication setup and client programs, and no bugs in MySQL itself, an error that stops replication should never occur. Indiscriminate use of this option results in slaves becoming hopelessly out of synchrony with the master, with you having no idea why this has occurred.
For error codes, you should use the numbers provided by the error message in your slave error log and in the output of
SHOW SLAVE STATUS. Appendix B, Errors, Error Codes, and Common Problems, lists server error codes.You can also (but should not) use the very nonrecommended value of
allto cause the slave to ignore all error messages and keeps going regardless of what happens. Needless to say, if you useall, there are no guarantees regarding the integrity of your data. Please do not complain (or file bug reports) in this case if the slave's data is not anywhere close to what it is on the master. You have been warned.MySQL Cluster NDB 7.2.6 and later support an additional shorthand value
ddl_exist_errorsfor use with the enhanced failover mechanism which is implemented beginning with that version of MySQL Cluster. This value is equivalent to the error code list1007,1008,1050,1051,1054,1060,1061,1068,1094,1146. This value is not supported by the mysqld binary included with the MySQL Server 5.5 distribution. (Bug #11762277, Bug #54854) For more information, see Section 18.6.8, “Implementing Failover with MySQL Cluster Replication”.Examples:
--slave-skip-errors=1062,1053 --slave-skip-errors=all --slave-skip-errors=ddl_exist_errors
The following options are removed in MySQL
5.5. If you attempt to start
mysqld with any of these options in MySQL
5.5, the server aborts with an unknown
variable error. To set the replication
parameters formerly associated with these options, you must use
the CHANGE MASTER TO ... statement (see
Section 13.4.2.1, “CHANGE MASTER TO Syntax”).
The options affected are shown in this list:
The following list describes system variables for controlling
replication slave servers. They can be set at server startup and
some of them can be changed at runtime using
SET.
Server options used with replication slaves are listed earlier
in this section.
-
Command-Line Format --init-slave=nameSystem Variable Name init_slaveVariable Scope Global Dynamic Variable Yes Permitted Values Type stringThis variable is similar to
init_connect, but is a string to be executed by a slave server each time the SQL thread starts. The format of the string is the same as for theinit_connectvariable.NoteThe SQL thread sends an acknowledgment to the client before it executes
init_slave. Therefore, it is not guaranteed thatinit_slavehas been executed whenSTART SLAVEreturns. See Section 13.4.2.5, “START SLAVE Syntax”, for more information. -
Command-Line Format --relay-log=file_nameSystem Variable Name relay_logVariable Scope Global Dynamic Variable No Permitted Values Type file nameThe name of the relay log file.
-
Command-Line Format --relay-log-indexSystem Variable Name relay_log_indexVariable Scope Global Dynamic Variable No Permitted Values Type file nameDefault *host_name*-relay-bin.indexThe name of the relay log index file. The default name is
host_name-relay-bin.indexhost_nameis the name of the slave server. -
Command-Line Format --relay-log-info-file=file_nameSystem Variable Name relay_log_info_fileVariable Scope Global Dynamic Variable No Permitted Values Type file nameDefault relay-log.infoThe name of the file in which the slave records information about the relay logs. The default name is
relay-log.infoin the data directory. -
Command-Line Format --relay-log-recoverySystem Variable Name relay_log_recoveryVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault FALSEEnables automatic relay log recovery immediately following server startup, which means that the replication slave discards all unprocessed relay logs and retrieves them from the replication master. This should be used following a crash on the replication slave to ensure that no possibly corrupted relay logs are processed. The default value is 0 (disabled). This global variable can be changed dynamically, or by starting the slave with the
--relay-log-recoveryoption. This variable is unused, and is removed in MySQL 5.6.
-
Command-Line Format --slave_compressed_protocolSystem Variable Name slave_compressed_protocolVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault OFFWhether to use compression of the slave/master protocol if both the slave and the master support it.
-
Command-Line Format --slave-exec-mode=modeSystem Variable Name slave_exec_modeVariable Scope Global Dynamic Variable Yes Permitted Values Type enumerationDefault STRICT(ALL)Default IDEMPOTENT(NDB)Valid Values IDEMPOTENTSTRICTControls how a slave thread resolves conflicts and errors during replication.
IDEMPOTENTmode causes suppression of duplicate-key and no-key-found errors. This mode should be employed in multi-master replication, circular replication, and some other special replication scenarios.STRICTmode is the default, and is suitable for most other cases.This mode is needed for multi-master replication, circular replication, and some other special replication scenarios for MySQL Cluster Replication. (See Section 18.6.10, “MySQL Cluster Replication: Multi-Master and Circular Replication”, and Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”, for more information.) The mysqld supplied with MySQL Cluster ignores any value explicitly set for
slave_exec_mode, and always treats it asIDEMPOTENT.In MySQL Server 5.5,
STRICTmode is the default value. This should not be changed; currently,IDEMPOTENTmode is supported only byNDB. -
Command-Line Format --slave-load-tmpdir=dir_nameSystem Variable Name slave_load_tmpdirVariable Scope Global Dynamic Variable No Permitted Values Type directory nameDefault /tmpThe name of the directory where the slave creates temporary files for replicating
LOAD DATA INFILEstatements. -
Introduced 5.5.26 System Variable Name slave_max_allowed_packetVariable Scope Global Dynamic Variable Yes Permitted Values Type integerDefault 1073741824Min Value 1024Max Value 1073741824In MySQL 5.5.26 and later, this variable sets the maximum packet size for the slave SQL and I/O threads, so that large updates using row-based replication do not cause replication to fail because an update exceeded
max_allowed_packet.This global variable always has a value that is a positive integer multiple of 1024; if you set it to some value that is not, the value is rounded down to the next highest multiple of 1024 for it is stored or used; setting
slave_max_allowed_packetto 0 causes 1024 to be used. (A truncation warning is issued in all such cases.) The default and maximum value is 1073741824 (1 GB); the minimum is 1024.slave_max_allowed_packetcan also be set at startup, using the--slave-max-allowed-packetoption. -
Command-Line Format --slave-net-timeout=#System Variable Name slave_net_timeoutVariable Scope Global Dynamic Variable Yes Permitted Values Type integerDefault 3600Min Value 1The number of seconds to wait for more data from a master/slave connection before aborting the read.
-
Command-Line Format --slave-skip-errors=nameSystem Variable Name slave_skip_errorsVariable Scope Global Dynamic Variable No Permitted Values Type stringDefault OFFValid Values OFF[list of error codes]allPermitted Values Type stringDefault OFFValid Values OFF[list of error codes]allddl_exist_errorsPermitted Values (>= 5.5.22-ndb-7.2.6) Type stringDefault OFFValid Values OFF[list of error codes]allddl_exist_errorsNormally, replication stops when an error occurs on the slave. This gives you the opportunity to resolve the inconsistency in the data manually. This variable tells the slave SQL thread to continue replication when a statement returns any of the errors listed in the variable value.
-
Command-Line Format --slave_transaction_retries=#System Variable Name slave_transaction_retriesVariable Scope Global Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 10Min Value 0Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 10Min Value 0Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 10Min Value 0Max Value 18446744073709551615If a replication slave SQL thread fails to execute a transaction because of an
InnoDBdeadlock or because the transaction's execution time exceededInnoDB'sinnodb_lock_wait_timeoutorNDBCLUSTER'sTransactionDeadlockDetectionTimeoutorTransactionInactiveTimeout, it automatically retriesslave_transaction_retriestimes before stopping with an error. The default value is 10. -
Introduced 5.5.3 Command-Line Format --slave_type_conversions=setSystem Variable Name slave_type_conversionsVariable Scope Global Dynamic Variable No Permitted Values Type setDefault Valid Values ALL_LOSSYALL_NON_LOSSYControls the type conversion mode in effect on the slave when using row-based replication, including MySQL Cluster Replication. Its value is a comma-delimited set of zero or more elements from the list:
ALL_LOSSY,ALL_NON_LOSSY. Set this variable to an empty string to disallow type conversions between the master and the slave. Changes require a restart of the slave to take effect.For additional information on type conversion modes applicable to attribute promotion and demotion in row-based replication, see Row-based replication: attribute promotion and demotion.
This variable was added in MySQL 5.5.3.
-
System Variable Name sql_slave_skip_counterVariable Scope Global Dynamic Variable Yes Permitted Values Type integerThe number of events from the master that a slave server should skip.
ImportantIf skipping the number of events specified by setting this variable would cause the slave to begin in the middle of an event group, the slave continues to skip until it finds the beginning of the next event group and begins from that point. For more information, see Section 13.4.2.4, “SET GLOBAL sql_slave_skip_counter Syntax”.
-
Command-Line Format --sync-master-info=#System Variable Name sync_master_infoVariable Scope Global Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 0Min Value 0Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 0Min Value 0Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 0Min Value 0Max Value 18446744073709551615If the value of this variable is greater than 0, a replication slave synchronizes its
master.infofile to disk (usingfdatasync()) after everysync_master_infoevents. The default value is 0 (recommended in most situations), which does not force any synchronization to disk by the MySQL server; in this case, the server relies on the operating system to flush themaster.infofile's contents from time to time as for any other file. -
Command-Line Format --sync-relay-log=#System Variable Name sync_relay_logVariable Scope Global Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 0Min Value 0Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 0Min Value 0Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 0Min Value 0Max Value 18446744073709551615If the value of this variable is greater than 0, the MySQL server synchronizes its relay log to disk (using
fdatasync()) after everysync_relay_logevents are written to the relay log.The default value of
sync_relay_logis 0, which does no synchronizing to disk; in this case, the server relies on the operating system to flush the relay log's contents from time to time as for any other file.A value of 1 is the safest choice because in the event of a crash you lose at most one event from the relay log. However, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast).
-
Command-Line Format --sync-relay-log-info=#System Variable Name sync_relay_log_infoVariable Scope Global Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 0Min Value 0Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 0Min Value 0Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 0Min Value 0Max Value 18446744073709551615If the value of this variable is greater than 0, a replication slave synchronizes its
relay-log.infofile to disk (usingfdatasync()) after everysync_relay_log_infotransactions. A value of 1 is the generally the best choice. The default value ofsync_relay_log_infois 0, which does not force any synchronization to disk by the MySQL server—in this case, the server relies on the operating system to flush therelay-log.infofile's contents from time to time as for any other file.
Startup Options Used with Binary Logging
System Variables Used with Binary Logging
You can use the mysqld options and system variables that are described in this section to affect the operation of the binary log as well as to control which statements are written to the binary log. For additional information about the binary log, see Section 5.2.4, “The Binary Log”. For additional information about using MySQL server options and system variables, see Section 5.1.3, “Server Command Options”, and Section 5.1.4, “Server System Variables”.
The following list describes startup options for enabling and configuring the binary log. System variables used with binary logging are discussed later in this section.
-
Command-Line Format --binlog-row-event-max-size=#Permitted Values (32-bit platforms) Type integerDefault 1024Min Value 256Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 1024Min Value 256Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 1024Min Value 256Max Value 18446744073709551615Specify the maximum size of a row-based binary log event, in bytes. Rows are grouped into events smaller than this size if possible. The value should be a multiple of 256. The default is 1024. See Section 17.1.2, “Replication Formats”.
-
Command-Line Format --log-binSystem Variable Name log_binVariable Scope Global Dynamic Variable No Permitted Values Type file nameEnable binary logging. The server logs all statements that change data to the binary log, which is used for backup and replication. See Section 5.2.4, “The Binary Log”.
The option value, if given, is the base name for the log sequence. The server creates binary log files in sequence by adding a numeric suffix to the base name. It is recommended that you specify a base name (see Section B.5.7, “Known Issues in MySQL”, for the reason). Otherwise, MySQL uses
host_name-binIn MySQL 5.5.20 and later, when the server reads an entry from the index file, it checks whether the entry contains a relative path, and if it does, the relative part of the path is replaced with the absolute path set using the
--log-binoption. An absolute path remains unchanged; in such a case, the index must be edited manually to enable the new path or paths to be used. Previous to MySQL 5.5.20, manual intervention was required whenever relocating the binary log or relay log files. (Bug #11745230, Bug #12133)Setting this option causes the
log_binsystem variable to be set toON(or1), and not to the base name. This is a known issue; see Bug #19614 for more information. -
Command-Line Format --log-bin-index=file_namePermitted Values Type file nameThe index file for binary log file names. See Section 5.2.4, “The Binary Log”. If you omit the file name, and if you did not specify one with
--log-bin, MySQL useshost_name-bin.index --log-bin-trust-function-creators[={0|1}]Command-Line Format --log-bin-trust-function-creatorsSystem Variable Name log_bin_trust_function_creatorsVariable Scope Global Dynamic Variable Yes Permitted Values Type booleanDefault FALSEThis option sets the corresponding
log_bin_trust_function_creatorssystem variable. If no argument is given, the option sets the variable to 1.log_bin_trust_function_creatorsaffects how MySQL enforces restrictions on stored function and trigger creation. See Section 20.7, “Binary Logging of Stored Programs”.--log-bin-use-v1-row-events[={0|1}]Introduced 5.5.15-ndb-7.2.1 Command-Line Format --log-bin-use-v1-row-events[={0|1}]System Variable Name log_bin_use_v1_row_eventsVariable Scope Global Dynamic Variable No Permitted Values (>= 5.5.15-ndb-7.2.1) Type booleanDefault 0Version 2 binary log row events are used by default beginning with MySQL Cluster NDB 7.2.1; however, Version 2 events cannot be read by previous MySQL Cluster releases. Setting
--log-bin-use-v1-row-eventsto 1 causes mysqld to write the binary log using Version 1 logging events, which is the only version of binary log events used in previous releases, and thus produce binary logs that can be read by older slaves.The value used for this option can be obtained from the read-only
log_bin_use_v1_row_eventssystem variable.--log-bin-use-v1-row-eventsis chiefly of interest when setting up replication conflict detection and resolution usingNDB$EPOCH_TRANS()as the conflict detection function, which requires Version 2 binary log row events. Thus, this option and--ndb-log-transaction-idare not compatible.NoteVersion 2 binary log row events are also available in MySQL Cluster NDB 7.0.27 and MySQL Cluster NDB 7.1.6 and later MySQL Cluster NDB 7.0 and 7.1 releases. However, prior to MySQL Cluster NDB 7.2.1, Version 1 events are the default (and so the default value for this option is 1 in those versions). You should keep this mind when planning upgrades for setups using MySQL Cluster Replication.
--log-bin-use-v1-row-eventsis not supported in mainline MySQL Server 5.5 releases.For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
Statement selection options. The options in the following list affect which statements are written to the binary log, and thus sent by a replication master server to its slaves. There are also options for slave servers that control which statements received from the master should be executed or ignored. For details, see Section 17.1.3.3, “Replication Slave Options and Variables”.
-
Command-Line Format --binlog-do-db=namePermitted Values Type stringThis option affects binary logging in a manner similar to the way that
--replicate-do-dbaffects replication.The effects of this option depend on whether the statement-based or row-based logging format is in use, in the same way that the effects of
--replicate-do-dbdepend on whether statement-based or row-based replication is in use. You should keep in mind that the format used to log a given statement may not necessarily be the same as that indicated by the value ofbinlog_format. For example, DDL statements such asCREATE TABLEandALTER TABLEare always logged as statements, without regard to the logging format in effect, so the following statement-based rules for--binlog-do-dbalways apply in determining whether or not the statement is logged.Statement-based logging. Only those statements are written to the binary log where the default database (that is, the one selected by
USE) isdb_name. To specify more than one database, use this option multiple times, once for each database; however, doing so does not cause cross-database statements such asUPDATEto be logged while a different database (or no database) is selected.some_db.some_tableSET foo='bar'WarningTo specify multiple databases you must use multiple instances of this option. Because database names can contain commas, the list will be treated as the name of a single database if you supply a comma-separated list.
An example of what does not work as you might expect when using statement-based logging: If the server is started with
--binlog-do-db=salesand you issue the following statements, theUPDATEstatement is not logged:USE prices; UPDATE sales.january SET amount=amount+1000;
The main reason for this “just check the default database” behavior is that it is difficult from the statement alone to know whether it should be replicated (for example, if you are using multiple-table
DELETEstatements or multiple-tableUPDATEstatements that act across multiple databases). It is also faster to check only the default database rather than all databases if there is no need.Another case which may not be self-evident occurs when a given database is replicated even though it was not specified when setting the option. If the server is started with
--binlog-do-db=sales, the followingUPDATEstatement is logged even thoughpriceswas not included when setting--binlog-do-db:USE sales; UPDATE prices.discounts SET percentage = percentage + 10;
Because
salesis the default database when theUPDATEstatement is issued, theUPDATEis logged.Row-based logging. Logging is restricted to database
db_name. Only changes to tables belonging todb_nameare logged; the default database has no effect on this. Suppose that the server is started with--binlog-do-db=salesand row-based logging is in effect, and then the following statements are executed:USE prices; UPDATE sales.february SET amount=amount+100;
The changes to the
februarytable in thesalesdatabase are logged in accordance with theUPDATEstatement; this occurs whether or not theUSEstatement was issued. However, when using the row-based logging format and--binlog-do-db=sales, changes made by the followingUPDATEare not logged:USE prices; UPDATE prices.march SET amount=amount-25;
Even if the
USE pricesstatement were changed toUSE sales, theUPDATEstatement's effects would still not be written to the binary log.Another important difference in
--binlog-do-dbhandling for statement-based logging as opposed to the row-based logging occurs with regard to statements that refer to multiple databases. Suppose that the server is started with--binlog-do-db=db1, and the following statements are executed:USE db1; UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
If you are using statement-based logging, the updates to both tables are written to the binary log. However, when using the row-based format, only the changes to
table1are logged;table2is in a different database, so it is not changed by theUPDATE. Now suppose that, instead of theUSE db1statement, aUSE db4statement had been used:USE db4; UPDATE db1.table1 SET col1 = 10, db2.table2 SET col2 = 20;
In this case, the
UPDATEstatement is not written to the binary log when using statement-based logging. However, when using row-based logging, the change totable1is logged, but not that totable2—in other words, only changes to tables in the database named by--binlog-do-dbare logged, and the choice of default database has no effect on this behavior. -
Command-Line Format --binlog-ignore-db=namePermitted Values Type stringThis option affects binary logging in a manner similar to the way that
--replicate-ignore-dbaffects replication.The effects of this option depend on whether the statement-based or row-based logging format is in use, in the same way that the effects of
--replicate-ignore-dbdepend on whether statement-based or row-based replication is in use. You should keep in mind that the format used to log a given statement may not necessarily be the same as that indicated by the value ofbinlog_format. For example, DDL statements such asCREATE TABLEandALTER TABLEare always logged as statements, without regard to the logging format in effect, so the following statement-based rules for--binlog-ignore-dbalways apply in determining whether or not the statement is logged.Statement-based logging. Tells the server to not log any statement where the default database (that is, the one selected by
USE) isdb_name.Prior to MySQL 5.5.32, this option caused any statements containing fully qualified table names not to be logged if there was no default database specified (that is, when
SELECTDATABASE()returnedNULL). In MySQL 5.5.32 and later, when there is no default database, no--binlog-ignore-dboptions are applied, and such statements are always logged. (Bug #11829838, Bug #60188)Row-based format. Tells the server not to log updates to any tables in the database
db_name. The current database has no effect.When using statement-based logging, the following example does not work as you might expect. Suppose that the server is started with
--binlog-ignore-db=salesand you issue the following statements:USE prices; UPDATE sales.january SET amount=amount+1000;
The
UPDATEstatement is logged in such a case because--binlog-ignore-dbapplies only to the default database (determined by theUSEstatement). Because thesalesdatabase was specified explicitly in the statement, the statement has not been filtered. However, when using row-based logging, theUPDATEstatement's effects are not written to the binary log, which means that no changes to thesales.januarytable are logged; in this instance,--binlog-ignore-db=salescauses all changes made to tables in the master's copy of thesalesdatabase to be ignored for purposes of binary logging.To specify more than one database to ignore, use this option multiple times, once for each database. Because database names can contain commas, the list will be treated as the name of a single database if you supply a comma-separated list.
You should not use this option if you are using cross-database updates and you do not want these updates to be logged.
Testing and debugging options. The following binary log options are used in replication testing and debugging. They are not intended for use in normal operations.
-
Command-Line Format --max-binlog-dump-events=#Permitted Values Type integerDefault 0This option is used internally by the MySQL test suite for replication testing and debugging.
-
Command-Line Format --sporadic-binlog-dump-failPermitted Values Type booleanDefault FALSEThis option is used internally by the MySQL test suite for replication testing and debugging.
The following list describes system variables for controlling
binary logging. They can be set at server startup and some of
them can be changed at runtime using
SET.
Server options used to control binary logging are listed earlier
in this section. For information about the
sql_log_bin and
sql_log_off variables, see
Section 5.1.4, “Server System Variables”.
-
Command-Line Format --binlog_cache_size=#System Variable Name binlog_cache_sizeVariable Scope Global Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 32768Min Value 4096Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 32768Min Value 4096Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 32768Min Value 4096Max Value 18446744073709551615The size of the cache to hold changes to the binary log during a transaction. A binary log cache is allocated for each client if the server supports any transactional storage engines and if the server has the binary log enabled (
--log-binoption). If you often use large transactions, you can increase this cache size to get better performance. TheBinlog_cache_useandBinlog_cache_disk_usestatus variables can be useful for tuning the size of this variable. See Section 5.2.4, “The Binary Log”.In MySQL 5.5.3, a separate binary log cache (the binary log statement cache) was introduced for nontransactional statements and in MySQL 5.5.3 through 5.5.8, this variable sets.the size for both caches. This means that, in these MySQL versions, the total memory used for these caches is double the value set for
binlog_cache_size.Beginning with MySQL 5.5.9,
binlog_cache_sizesets the size for the transaction cache only, and the size of the statement cache is governed by thebinlog_stmt_cache_sizesystem variable. binlog_direct_non_transactional_updatesIntroduced 5.5.2 Command-Line Format --binlog_direct_non_transactional_updates[=value]System Variable Name binlog_direct_non_transactional_updatesVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type booleanDefault OFFDue to concurrency issues, a slave can become inconsistent when a transaction contains updates to both transactional and nontransactional tables. MySQL tries to preserve causality among these statements by writing nontransactional statements to the transaction cache, which is flushed upon commit. However, problems arise when modifications done to nontransactional tables on behalf of a transaction become immediately visible to other connections because these changes may not be written immediately into the binary log.
Beginning with MySQL 5.5.2, the
binlog_direct_non_transactional_updatesvariable offers one possible workaround to this issue. By default, this variable is disabled. Enablingbinlog_direct_non_transactional_updatescauses updates to nontransactional tables to be written directly to the binary log, rather than to the transaction cache.binlog_direct_non_transactional_updatesworks only for statements that are replicated using the statement-based binary logging format; that is, it works only when the value ofbinlog_formatisSTATEMENT, or whenbinlog_formatisMIXEDand a given statement is being replicated using the statement-based format. This variable has no effect when the binary log format isROW, or whenbinlog_formatis set toMIXEDand a given statement is replicated using the row-based format.ImportantBefore enabling this variable, you must make certain that there are no dependencies between transactional and nontransactional tables; an example of such a dependency would be the statement
INSERT INTO. Otherwise, such statements are likely to cause the slave to diverge from the master.myisam_tableSELECT * FROMinnodb_tableBeginning with MySQL 5.5.5, this variable has no effect when the binary log format is
ROWorMIXED. (Bug #51291)-
Command-Line Format --binlog-format=formatSystem Variable Name binlog_formatVariable Scope Global, Session Dynamic Variable Yes Permitted Values Type enumerationDefault STATEMENTValid Values ROWSTATEMENTMIXEDPermitted Values (>= 5.5.15-ndb-7.2.1, <= 5.5.30-ndb-7.2.12) Type enumerationDefault STATEMENTValid Values ROWSTATEMENTMIXEDPermitted Values (>= 5.5.31-ndb-7.2.13) Type enumerationDefault MIXEDValid Values ROWSTATEMENTMIXEDThis variable sets the binary logging format, and can be any one of
STATEMENT,ROW, orMIXED. See Section 17.1.2, “Replication Formats”.binlog_formatis set by the--binlog-formatoption at startup, or by thebinlog_formatsystem variable at runtime.NoteWhile you can change the logging format at runtime, it is not recommended that you change it while replication is ongoing. This is due in part to the fact that slaves do not honor the master's
binlog_formatsetting; a given MySQL Server can change only its own logging format.In MySQL 5.5, the default format is
STATEMENT.Exception. In MySQL Cluster NDB 7.2.1 through MySQL Cluster NDB 7.2.12, the default for this variable is
STATEMENT. In MySQL Cluster NDB 7.2.13 and later, when theNDBstorage engine is enabled, the default isMIXED. (Bug #16417224) See also Section 18.6.6, “Starting MySQL Cluster Replication (Single Replication Channel)”, and Section 18.6.7, “Using Two Replication Channels for MySQL Cluster Replication”.You must have the
SUPERprivilege to set either the global or sessionbinlog_formatvalue.The rules governing when changes to this variable take effect and how long the effect lasts are the same as for other MySQL server system variables. See Section 13.7.4, “SET Syntax”, for more information.
When
MIXEDis specified, statement-based replication is used, except for cases where only row-based replication is guaranteed to lead to proper results. For example, this happens when statements contain user-defined functions (UDF) or theUUID()function. An exception to this rule is thatMIXEDalways uses statement-based replication for stored functions and triggers.There are exceptions when you cannot switch the replication format at runtime:
From within a stored function or a trigger.
If the session is currently in row-based replication mode and has open temporary tables.
Beginning with MySQL 5.5.3, within a transaction. (Bug #47863)
Trying to switch the format in those cases results in an error.
NotePrior to MySQL Cluster NDB 7.2.1, it was also not possible to change the binary logging format at runtime when the
NDBCLUSTERstorage engine was enabled. In MySQL Cluster NDB 7.2.1 and later, this restriction is removed.The binary log format affects the behavior of the following server options:
These effects are discussed in detail in the descriptions of the individual options.
-
Introduced 5.5.9 Command-Line Format --binlog_stmt_cache_size=#System Variable Name binlog_stmt_cache_sizeVariable Scope Global Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 32768Min Value 4096Max Value 4294967295Permitted Values (64-bit platforms) Type integerDefault 32768Min Value 4096Max Value 18446744073709551615Beginning with MySQL 5.5.9, this variable determines the size of the cache for the binary log to hold nontransactional statements issued during a transaction. In MySQL 5.5.3 and later, separate binary log transaction and statement caches are allocated for each client if the server supports any transactional storage engines and if the server has the binary log enabled (
--log-binoption). If you often use large nontransactional statements during transactions, you can increase this cache size to get more performance. TheBinlog_stmt_cache_useandBinlog_stmt_cache_disk_usestatus variables can be useful for tuning the size of this variable. See Section 5.2.4, “The Binary Log”.In MySQL 5.5.3 through 5.5.8, the size for both caches is set using
binlog_cache_size. This means that, in these MySQL versions, the total memory used for these caches is double the value set forbinlog_cache_size. Beginning with MySQL 5.5.9,binlog_cache_sizesets the size for the transaction cache only. -
System Variable Name log_binVariable Scope Global Dynamic Variable No Whether the binary log is enabled. If the
--log-binoption is used, then the value of this variable isON; otherwise it isOFF. This variable reports only on the status of binary logging (enabled or disabled); it does not actually report the value to which--log-binis set. -
Introduced 5.5.15-ndb-7.2.1 Command-Line Format --log-bin-use-v1-row-events[={0|1}]System Variable Name log_bin_use_v1_row_eventsVariable Scope Global Dynamic Variable No Permitted Values (>= 5.5.15-ndb-7.2.1) Type booleanDefault 0Shows whether Version 2 binary logging, available beginning with MySQL Cluster NDB 7.2.1, is in use. A value of 1 shows that the server is writing the binary log using Version 1 logging events (the only version of binary log events used in previous releases), and thus producing a binary log that can be read by older slaves. 0 indicates that Version 2 binary log events are in use.
This variable is read-only. To switch between Version 1 and Version 2 binary event binary logging, it is necessary to restart mysqld with the
--log-bin-use-v1-row-eventsoption.Other than when performing upgrades of MySQL Cluster Replication,
--log-bin-use-v1-eventsis chiefly of interest when setting up replication conflict detection and resolution usingNDB$EPOCH_TRANS(), which requires Version 2 binary row event logging. Thus, this option and--ndb-log-transaction-idare not compatible.NoteMySQL Cluster NDB 7.2.1 and later use Version 2 binary log row events by default (and so the default value for this variable changes to 0 in those versions). You should keep this mind when planning upgrades for setups using MySQL Cluster Replication.
This variable is not supported in mainline MySQL Server 5.5.
For more information, see Section 18.6.11, “MySQL Cluster Replication Conflict Resolution”.
-
Command-Line Format --log-slave-updatesSystem Variable Name log_slave_updatesVariable Scope Global Dynamic Variable No Permitted Values Type booleanDefault FALSEWhether updates received by a slave server from a master server should be logged to the slave's own binary log. Binary logging must be enabled on the slave for this variable to have any effect. See Section 17.1.3, “Replication and Binary Logging Options and Variables”.
-
Command-Line Format --max_binlog_cache_size=#System Variable Name max_binlog_cache_sizeVariable Scope Global Dynamic Variable Yes Permitted Values (<= 5.5.2) Type integerDefault 18446744073709547520Min Value 4096Max Value 18446744073709547520Permitted Values (>= 5.5.3) Type integerDefault 18446744073709551615Min Value 4096Max Value 18446744073709551615If a transaction requires more than this many bytes of memory, the server generates a Multi-statement transaction required more than 'max_binlog_cache_size' bytes of storage error. The minimum value is 4096. The maximum possible value is 16EB (exabytes). The maximum recommended value is 4GB; this is due to the fact that MySQL currently cannot work with binary log positions greater than 4GB.
NotePrior to MySQL 5.5.28, 64-bit Windows platforms truncated the stored value for this variable to 4G, even when it was set to a greater value (Bug #13961678).
In MySQL 5.5.3, a separate binary log cache (the binary log statement cache) was introduced for nontransactional statements and in MySQL 5.5.3 through 5.5.8, this variable sets.the upper limit for both caches. This means that, in these MySQL versions, the effective maximum for these caches is double the value set for
max_binlog_cache_size.Beginning with MySQL 5.5.9,
max_binlog_cache_sizesets the size for the transaction cache only, and the upper limit for the statement cache is governed by themax_binlog_stmt_cache_sizesystem variable.Also beginning with MySQL 5.5.9, the session visibility of the
max_binlog_cache_sizesystem variable matches that of thebinlog_cache_sizesystem variable: In MySQL 5.5.8 and earlier releases, a change inmax_binlog_cache_sizetook immediate effect; in MySQL 5.5.9 and later, a change inmax_binlog_cache_sizetakes effect only for new sessions that started after the value is changed. -
Command-Line Format --max_binlog_size=#System Variable Name max_binlog_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type integerDefault 1073741824Min Value 4096Max Value 1073741824If a write to the binary log causes the current log file size to exceed the value of this variable, the server rotates the binary logs (closes the current file and opens the next one). The minimum value is 4096 bytes. The maximum and default value is 1GB.
A transaction is written in one chunk to the binary log, so it is never split between several binary logs. Therefore, if you have big transactions, you might see binary log files larger than
max_binlog_size.If
max_relay_log_sizeis 0, the value ofmax_binlog_sizeapplies to relay logs as well. -
Introduced 5.5.9 Command-Line Format --max_binlog_stmt_cache_size=#System Variable Name max_binlog_stmt_cache_sizeVariable Scope Global Dynamic Variable Yes Permitted Values Type integerDefault 18446744073709547520Min Value 4096Max Value 18446744073709547520If nontransactional statements within a transaction require more than this many bytes of memory, the server generates an error. The minimum value is 4096. The maximum and default values are 4GB on 32-bit platforms and 16EB (exabytes) on 64-bit platforms.
NotePrior to MySQL 5.5.28, 64-bit Windows platforms truncated the stored value for this variable to 4G, even when it was set to a greater value (Bug #13961678).
In MySQL 5.5.3, a separate binary log cache (the binary log statement cache) was introduced for nontransactional statements and in MySQL 5.5.3 through 5.5.8, this variable sets.the upper limit for both caches. This means that, in these MySQL versions, the effective maximum for these caches is double the value set for
max_binlog_cache_size.Beginning with MySQL 5.5.9,
max_binlog_stmt_cache_sizesets the size for the statement cache only, and the upper limit for the transaction cache is governed exclusively by themax_binlog_cache_sizesystem variable. -
Command-Line Format --sync-binlog=#System Variable Name sync_binlogVariable Scope Global Dynamic Variable Yes Permitted Values (32-bit platforms) Type integerDefault 0Min Value 0Max Value 4294967295Permitted Values (64-bit platforms, <= 5.5.2) Type integerDefault 0Min Value 0Max Value 18446744073709547520Permitted Values (64-bit platforms, >= 5.5.3) Type integerDefault 0Min Value 0Max Value 4294967295If the value of this variable is greater than 0, the MySQL server synchronizes its binary log to disk (using
fdatasync()) after everysync_binlogwrites to the binary log. There is one write to the binary log per statement if autocommit is enabled, and one write per transaction otherwise. The default value ofsync_binlogis 0, which does no synchronizing to disk—in this case, the server relies on the operating system to flush the binary log's contents from time to time as for any other file. A value of 1 is the safest choice because in the event of a crash you lose at most one statement or transaction from the binary log. However, it is also the slowest choice (unless the disk has a battery-backed cache, which makes synchronization very fast).
Once replication has been started it should execute without requiring much regular administration. Depending on your replication environment, you will want to check the replication status of each slave periodically, daily, or even more frequently.
The most common task when managing a replication process is to
ensure that replication is taking place and that there have been
no errors between the slave and the master. The primary
statement for this is SHOW SLAVE
STATUS, which you must execute on each slave:
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: master1
Master_User: root
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 931
Relay_Log_File: slave1-relay-bin.000056
Relay_Log_Pos: 950
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 931
Relay_Log_Space: 1365
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids: 0
The key fields from the status report to examine are:
Slave_IO_State: The current status of the slave. See Section 8.14.6, “Replication Slave I/O Thread States”, and Section 8.14.7, “Replication Slave SQL Thread States”, for more information.Slave_IO_Running: Whether the I/O thread for reading the master's binary log is running. Normally, you want this to beYesunless you have not yet started replication or have explicitly stopped it withSTOP SLAVE.Slave_SQL_Running: Whether the SQL thread for executing events in the relay log is running. As with the I/O thread, this should normally beYes.Last_IO_Error,Last_SQL_Error: The last errors registered by the I/O and SQL threads when processing the relay log. Ideally these should be blank, indicating no errors.Seconds_Behind_Master: The number of seconds that the slave SQL thread is behind processing the master binary log. A high number (or an increasing one) can indicate that the slave is unable to handle events from the master in a timely fashion.A value of 0 for
Seconds_Behind_Mastercan usually be interpreted as meaning that the slave has caught up with the master, but there are some cases where this is not strictly true. For example, this can occur if the network connection between master and slave is broken but the slave I/O thread has not yet noticed this—that is,slave_net_timeouthas not yet elapsed.It is also possible that transient values for
Seconds_Behind_Mastermay not reflect the situation accurately. When the slave SQL thread has caught up on I/O,Seconds_Behind_Masterdisplays 0; but when the slave I/O thread is still queuing up a new event,Seconds_Behind_Mastermay show a large value until the SQL thread finishes executing the new event. This is especially likely when the events have old timestamps; in such cases, if you executeSHOW SLAVE STATUSseveral times in a relatively short period, you may see this value change back and forth repeatedly between 0 and a relatively large value.
Several pairs of fields provide information about the progress of the slave in reading events from the master binary log and processing them in the relay log:
(
Master_Log_file,Read_Master_Log_Pos): Coordinates in the master binary log indicating how far the slave I/O thread has read events from that log.(
Relay_Master_Log_File,Exec_Master_Log_Pos): Coordinates in the master binary log indicating how far the slave SQL thread has executed events received from that log.(
Relay_Log_File,Relay_Log_Pos): Coordinates in the slave relay log indicating how far the slave SQL thread has executed the relay log. These correspond to the preceding coordinates, but are expressed in slave relay log coordinates rather than master binary log coordinates.
On the master, you can check the status of connected slaves
using SHOW PROCESSLIST to examine
the list of running processes. Slave connections have
Binlog Dump in the Command
field:
mysql> SHOW PROCESSLIST \G;
*************************** 4. row ***************************
Id: 10
User: root
Host: slave1:58371
db: NULL
Command: Binlog Dump
Time: 777
State: Has sent all binlog to slave; waiting for binlog to be updated
Info: NULL
Because it is the slave that drives the replication process, very little information is available in this report.
For slaves that were started with the
--report-host option and are
connected to the master, the SHOW SLAVE
HOSTS statement on the master shows basic information
about the slaves. The output includes the ID of the slave
server, the value of the
--report-host option, the
connecting port, and master ID:
mysql> SHOW SLAVE HOSTS;
+-----------+--------+------+-------------------+-----------+
| Server_id | Host | Port | Rpl_recovery_rank | Master_id |
+-----------+--------+------+-------------------+-----------+
| 10 | slave1 | 3306 | 0 | 1 |
+-----------+--------+------+-------------------+-----------+
1 row in set (0.00 sec)
You can stop and start the replication of statements on the
slave using the STOP SLAVE and
START SLAVE statements.
To stop processing of the binary log from the master, use
STOP SLAVE:
mysql> STOP SLAVE;
When replication is stopped, the slave I/O thread stops reading events from the master binary log and writing them to the relay log, and the SQL thread stops reading events from the relay log and executing them. You can pause the I/O or SQL thread individually by specifying the thread type:
mysql>STOP SLAVE IO_THREAD;mysql>STOP SLAVE SQL_THREAD;
To start execution again, use the START
SLAVE statement:
mysql> START SLAVE;
To start a particular thread, specify the thread type:
mysql>START SLAVE IO_THREAD;mysql>START SLAVE SQL_THREAD;
For a slave that performs updates only by processing events from the master, stopping only the SQL thread can be useful if you want to perform a backup or other task. The I/O thread will continue to read events from the master but they are not executed. This makes it easier for the slave to catch up when you restart the SQL thread.
Stopping only the I/O thread enables the events in the relay log to be executed by the SQL thread up to the point where the relay log ends. This can be useful when you want to pause execution to catch up with events already received from the master, when you want to perform administration on the slave but also ensure that it has processed all updates to a specific point. This method can also be used to pause event receipt on the slave while you conduct administration on the master. Stopping the I/O thread but permitting the SQL thread to run helps ensure that there is not a massive backlog of events to be executed when replication is started again.
Replication is based on the master server keeping track of all
changes to its databases (updates, deletes, and so on) in its binary
log. The binary log serves as a written record of all events that
modify database structure or content (data) from the moment the
server was started. Typically, SELECT
statements are not recorded because they modify neither database
structure nor content.
Each slave that connects to the master requests a copy of the binary log. That is, it pulls the data from the master, rather than the master pushing the data to the slave. The slave also executes the events from the binary log that it receives. This has the effect of repeating the original changes just as they were made on the master. Tables are created or their structure modified, and data is inserted, deleted, and updated according to the changes that were originally made on the master.
Because each slave is independent, the replaying of the changes from the master's binary log occurs independently on each slave that is connected to the master. In addition, because each slave receives a copy of the binary log only by requesting it from the master, the slave is able to read and update the copy of the database at its own pace and can start and stop the replication process at will without affecting the ability to update to the latest database status on either the master or slave side.
For more information on the specifics of the replication implementation, see Section 17.2.1, “Replication Implementation Details”.
Masters and slaves report their status in respect of the replication process regularly so that you can monitor them. See Section 8.14, “Examining Thread Information”, for descriptions of all replicated-related states.
The master binary log is written to a local relay log on the slave before it is processed. The slave also records information about the current position with the master's binary log and the local relay log. See Section 17.2.2, “Replication Relay and Status Logs”.
Database changes are filtered on the slave according to a set of rules that are applied according to the various configuration options and variables that control event evaluation. For details on how these rules are applied, see Section 17.2.3, “How Servers Evaluate Replication Filtering Rules”.
MySQL replication capabilities are implemented using three threads, one on the master server and two on the slave:
Binlog dump thread. The master creates a thread to send the binary log contents to a slave when the slave connects. This thread can be identified in the output of
SHOW PROCESSLISTon the master as theBinlog Dumpthread.The binary log dump thread acquires a lock on the master's binary log for reading each event that is to be sent to the slave. As soon as the event has been read, the lock is released, even before the event is sent to the slave.
Slave I/O thread. When a
START SLAVEstatement is issued on a slave server, the slave creates an I/O thread, which connects to the master and asks it to send the updates recorded in its binary logs.The slave I/O thread reads the updates that the master's
Binlog Dumpthread sends (see previous item) and copies them to local files that comprise the slave's relay log.The state of this thread is shown as
Slave_IO_runningin the output ofSHOW SLAVE STATUSor asSlave_runningin the output ofSHOW STATUS.Slave SQL thread. The slave creates an SQL thread to read the relay log that is written by the slave I/O thread and execute the events contained therein.
In the preceding description, there are three threads per master/slave connection. A master that has multiple slaves creates one binary log dump thread for each currently connected slave, and each slave has its own I/O and SQL threads.
A slave uses two threads to separate reading updates from the master and executing them into independent tasks. Thus, the task of reading statements is not slowed down if statement execution is slow. For example, if the slave server has not been running for a while, its I/O thread can quickly fetch all the binary log contents from the master when the slave starts, even if the SQL thread lags far behind. If the slave stops before the SQL thread has executed all the fetched statements, the I/O thread has at least fetched everything so that a safe copy of the statements is stored locally in the slave's relay logs, ready for execution the next time that the slave starts. This enables the master server to purge its binary logs sooner because it no longer needs to wait for the slave to fetch their contents.
The SHOW PROCESSLIST statement
provides information that tells you what is happening on the
master and on the slave regarding replication. For information on
master states, see Section 8.14.5, “Replication Master Thread States”. For
slave states, see Section 8.14.6, “Replication Slave I/O Thread States”, and
Section 8.14.7, “Replication Slave SQL Thread States”.
The following example illustrates how the three threads show up in
the output from SHOW PROCESSLIST.
On the master server, the output from SHOW
PROCESSLIST looks like this:
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 2
User: root
Host: localhost:32931
db: NULL
Command: Binlog Dump
Time: 94
State: Has sent all binlog to slave; waiting for binlog to
be updated
Info: NULL
Here, thread 2 is a Binlog Dump replication
thread that services a connected slave. The
State information indicates that all
outstanding updates have been sent to the slave and that the
master is waiting for more updates to occur. If you see no
Binlog Dump threads on a master server, this
means that replication is not running; that is, no slaves are
currently connected.
On a slave server, the output from SHOW
PROCESSLIST looks like this:
mysql> SHOW PROCESSLIST\G
*************************** 1. row ***************************
Id: 10
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Waiting for master to send event
Info: NULL
*************************** 2. row ***************************
Id: 11
User: system user
Host:
db: NULL
Command: Connect
Time: 11
State: Has read all relay log; waiting for the slave I/O
thread to update it
Info: NULL
The State information indicates that thread 10
is the I/O thread that is communicating with the master server,
and thread 11 is the SQL thread that is processing the updates
stored in the relay logs. At the time that
SHOW PROCESSLIST was run, both
threads were idle, waiting for further updates.
The value in the Time column can show how late
the slave is compared to the master. See
Section A.13, “MySQL 5.5 FAQ: Replication”. If sufficient time elapses on
the master side without activity on the Binlog
Dump thread, the master determines that the slave is no
longer connected. As for any other client connection, the timeouts
for this depend on the values of
net_write_timeout and
net_retry_count; for more information about
these, see Section 5.1.4, “Server System Variables”.
The SHOW SLAVE STATUS statement
provides additional information about replication processing on a
slave server. See
Section 17.1.4.1, “Checking Replication Status”.
During replication, a slave server creates several logs that hold the binary log events relayed from the master to the slave, and to record information about the current status and location within the relay log. There are three types of logs used in the process, listed here:
The relay log consists of the events read from the binary log of the master and written by the slave I/O thread. Events in the relay log are executed on the slave as part of the SQL thread.
The master info log contains status and current configuration information for the slave's connection to the master. This log holds information on the master host name, login credentials, and coordinates indicating how far the slave has read from the master's binary log.
The relay log info log holds status information about the execution point within the slave's relay log.
The relay log, like the binary log, consists of a set of numbered files containing events that describe database changes, and an index file that contains the names of all used relay log files.
The term “relay log file” generally denotes an individual numbered file containing database events. The term “relay log” collectively denotes the set of numbered relay log files plus the index file.
Relay log files have the same format as binary log files and can be read using mysqlbinlog (see Section 4.6.7, “mysqlbinlog — Utility for Processing Binary Log Files”).
By default, relay log file names have the form
host_name-relay-bin.nnnnnnhost_name is the name of the slave
server host and nnnnnn is a sequence
number. Successive relay log files are created using successive
sequence numbers, beginning with 000001. The
slave uses an index file to track the relay log files currently
in use. The default relay log index file name is
host_name-relay-bin.index
The default relay log file and relay log index file names can be
overridden with, respectively, the
--relay-log and
--relay-log-index server options
(see Section 17.1.3, “Replication and Binary Logging Options and Variables”).
If a slave uses the default host-based relay log file names,
changing a slave's host name after replication has been set up
can cause replication to fail with the errors Failed
to open the relay log and Could not find
target log during relay log initialization. This is
a known issue (see Bug #2122). If you anticipate that a slave's
host name might change in the future (for example, if networking
is set up on the slave such that its host name can be modified
using DHCP), you can avoid this issue entirely by using the
--relay-log and
--relay-log-index options to
specify relay log file names explicitly when you initially set
up the slave. This will make the names independent of server
host name changes.
If you encounter the issue after replication has already begun, one way to work around it is to stop the slave server, prepend the contents of the old relay log index file to the new one, and then restart the slave. On a Unix system, this can be done as shown here:
shell>catshell>new_relay_log_name.index >>old_relay_log_name.indexmvold_relay_log_name.indexnew_relay_log_name.index
A slave server creates a new relay log file under the following conditions:
Each time the I/O thread starts.
When the logs are flushed; for example, with
FLUSH LOGSor mysqladmin flush-logs.When the size of the current relay log file becomes “too large,” determined as follows:
If the value of
max_relay_log_sizeis greater than 0, that is the maximum relay log file size.If the value of
max_relay_log_sizeis 0,max_binlog_sizedetermines the maximum relay log file size.
The SQL thread automatically deletes each relay log file as soon
as it has executed all events in the file and no longer needs
it. There is no explicit mechanism for deleting relay logs
because the SQL thread takes care of doing so. However,
FLUSH LOGS
rotates relay logs, which influences when the SQL thread deletes
them.
A replication slave server creates two logs. By default, these
logs are files named master.info and
relay-log.info and created in the data
directory. The names and locations of these files can be changed
by using the --master-info-file
and --relay-log-info-file
options, respectively. See
Section 17.1.3, “Replication and Binary Logging Options and Variables”.
The two status logs contain information like that shown in the
output of the SHOW SLAVE STATUS
statement, which is discussed in
Section 13.4.2, “SQL Statements for Controlling Slave Servers”. Because the status logs
are stored on disk, they survive a slave server's shutdown.
The next time the slave starts up, it reads the two logs to
determine how far it has proceeded in reading binary logs from
the master and in processing its own relay logs.
The master info log should be protected because it contains the password for connecting to the master. See Section 6.1.2.3, “Passwords and Logging”.
The slave I/O thread updates the master info log. The following
table shows the correspondence between the lines in the
master.info file and the columns displayed
by SHOW SLAVE STATUS.
Line in master.info | SHOW SLAVE STATUS Column | Description |
|---|---|---|
| 1 | Number of lines in the file | |
| 2 | Master_Log_File | The name of the master binary log currently being read from the master |
| 3 | Read_Master_Log_Pos | The current position within the master binary log that have been read from the master |
| 4 | Master_Host | The host name of the master |
| 5 | Master_User | The user name used to connect to the master |
| 6 | Password (not shown by SHOW SLAVE STATUS) | The password used to connect to the master |
| 7 | Master_Port | The network port used to connect to the master |
| 8 | Connect_Retry | The period (in seconds) that the slave will wait before trying to reconnect to the master |
| 9 | Master_SSL_Allowed | Indicates whether the server supports SSL connections |
| 10 | Master_SSL_CA_File | The file used for the Certificate Authority (CA) certificate |
| 11 | Master_SSL_CA_Path | The path to the Certificate Authority (CA) certificates |
| 12 | Master_SSL_Cert | The name of the SSL certificate file |
| 13 | Master_SSL_Cipher | The list of possible ciphers used in the handshake for the SSL connection |
| 14 | Master_SSL_Key | The name of the SSL key file |
| 15 | Master_SSL_Verify_Server_Cert | Whether to verify the server certificate |
| 17 | Replicate_Ignore_Server_Ids | The number of server IDs to be ignored, followed by the actual server IDs |
The slave SQL thread updates the relay log info log. The
following table shows the correspondence between the lines in
the relay-log.info file and the columns
displayed by SHOW SLAVE STATUS.
Line in relay-log.info | SHOW SLAVE STATUS Column | Description |
|---|---|---|
| 1 | Relay_Log_File | The name of the current relay log file |
| 2 | Relay_Log_Pos | The current position within the relay log file; events up to this position have been executed on the slave database |
| 3 | Relay_Master_Log_File | The name of the master binary log file from which the events in the relay log file were read |
| 4 | Exec_Master_Log_Pos | The equivalent position within the master's binary log file of events that have already been executed |
The contents of the relay-log.info file and
the states shown by the SHOW SLAVE
STATUS statement might not match if the
relay-log.info file has not been flushed to
disk. Ideally, you should only view
relay-log.info on a slave that is offline
(that is, mysqld is not running). For a
running system, SHOW SLAVE STATUS
should be used.
When you back up the slave's data, you should back up these
two status logs, along with the relay log files. The status logs
are needed to resume replication after you restore the data from
the slave. If you lose the relay logs but still have the relay
log info log, you can check it to determine how far the SQL
thread has executed in the master binary logs. Then you can use
CHANGE MASTER TO with the
MASTER_LOG_FILE and
MASTER_LOG_POS options to tell the slave to
re-read the binary logs from that point. Of course, this
requires that the binary logs still exist on the master.
If a master server does not write a statement to its binary log, the statement is not replicated. If the server does log the statement, the statement is sent to all slaves and each slave determines whether to execute it or ignore it.
On the master, you can control which databases to log changes for
by using the --binlog-do-db and
--binlog-ignore-db options to
control binary logging. For a description of the rules that
servers use in evaluating these options, see
Section 17.2.3.1, “Evaluation of Database-Level Replication and Binary Logging Options”. You should not use
these options to control which databases and tables are
replicated. Instead, use filtering on the slave to control the
events that are executed on the slave.
On the slave side, decisions about whether to execute or ignore
statements received from the master are made according to the
--replicate-* options that the slave was started
with. (See Section 17.1.3, “Replication and Binary Logging Options and Variables”.)
In the simplest case, when there are no
--replicate-* options, the slave executes all
statements that it receives from the master. Otherwise, the result
depends on the particular options given.
Database-level options
(--replicate-do-db,
--replicate-ignore-db) are checked
first; see Section 17.2.3.1, “Evaluation of Database-Level Replication and Binary Logging Options”, for a
description of this process. If no database-level options are
used, option checking proceeds to any table-level options that may
be in use (see Section 17.2.3.2, “Evaluation of Table-Level Replication Options”,
for a discussion of these). If one or more database-level options
are used but none are matched, the statement is not replicated.
To make it easier to determine what effect an option set will
have, it is recommended that you avoid mixing “do”
and “ignore” options, or wildcard and nonwildcard
options. An example of the latter that may have unintended effects
is the use of --replicate-do-db and
--replicate-wild-do-table together,
where --replicate-wild-do-table
uses a pattern for the database name that matches the name given
for --replicate-do-db. Suppose a
replication slave is started with
--replicate-do-db=dbx
--replicate-wild-do-table=db%.t1.
Then, suppose that on the master, you issue the statement
CREATE DATABASE
dbx. Although you might expect it, this statement is not
replicated because it does not reference a table named
t1.
If any --replicate-rewrite-db
options were specified, they are applied before the
--replicate-* filtering rules are tested.
Database-level filtering options are case-sensitive on platforms
supporting case sensitivity in filenames, whereas table-level
filtering options are not (regardless of platform). This is true
regardless of the value of the
lower_case_table_names system
variable.
When evaluating replication options, the slave begins by
checking to see whether there are any
--replicate-do-db or
--replicate-ignore-db options
that apply. When using
--binlog-do-db or
--binlog-ignore-db, the process
is similar, but the options are checked on the master.
With statement-based replication, the default database is checked for a match. With row-based replication, the database where data is to be changed is the database that is checked. Regardless of the binary logging format, checking of database-level options proceeds as shown in the following diagram.
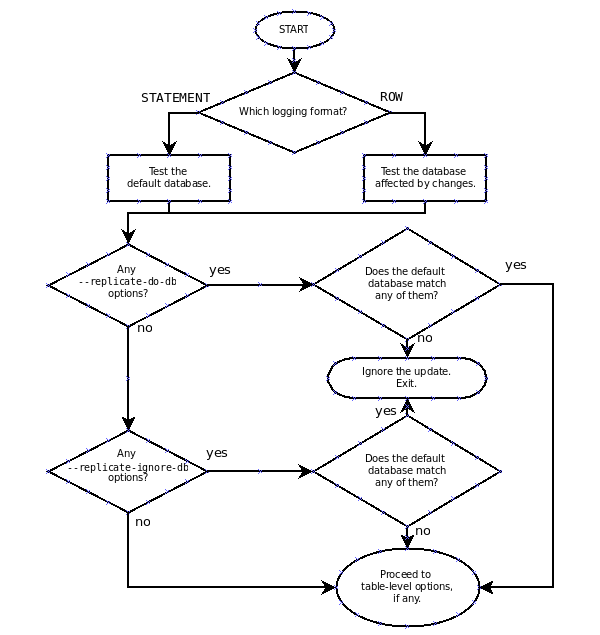
The steps involved are listed here:
Are there any
--replicate-do-dboptions?Yes. Do any of them match the database?
Yes. Execute the statement and exit.
No. Ignore the statement and exit.
No. Continue to step 2.
Are there any
--replicate-ignore-dboptions?Yes. Do any of them match the database?
Yes. Ignore the statement and exit.
No. Continue to step 3.
No. Continue to step 3.
Proceed to checking the table-level replication options, if there are any. For a description of how these options are checked, see Section 17.2.3.2, “Evaluation of Table-Level Replication Options”.
ImportantA statement that is still permitted at this stage is not yet actually executed. The statement is not executed until all table-level options (if any) have also been checked, and the outcome of that process permits execution of the statement.
For binary logging, the steps involved are listed here:
Are there any
--binlog-do-dbor--binlog-ignore-dboptions?Yes. Continue to step 2.
No. Log the statement and exit.
Is there a default database (has any database been selected by
USE)?Yes. Continue to step 3.
No. Ignore the statement and exit.
There is a default database. Are there any
--binlog-do-dboptions?Yes. Do any of them match the database?
Yes. Log the statement and exit.
No. Ignore the statement and exit.
No. Continue to step 4.
Do any of the
--binlog-ignore-dboptions match the database?Yes. Ignore the statement and exit.
No. Log the statement and exit.
For statement-based logging, an exception is made in the rules
just given for the CREATE
DATABASE, ALTER
DATABASE, and DROP
DATABASE statements. In those cases, the database
being created, altered, or dropped
replaces the default database when determining whether to log
or ignore updates.
--binlog-do-db can sometimes mean
“ignore other databases”. For example, when using
statement-based logging, a server running with only
--binlog-do-db=sales does not
write to the binary log statements for which the default
database differs from sales. When using
row-based logging with the same option, the server logs only
those updates that change data in sales.
The slave checks for and evaluates table options only if either of the following two conditions is true:
No matching database options were found.
One or more database options were found, and were evaluated to arrive at an “execute” condition according to the rules described in the previous section (see Section 17.2.3.1, “Evaluation of Database-Level Replication and Binary Logging Options”).
First, as a preliminary condition, the slave checks whether statement-based replication is enabled. If so, and the statement occurs within a stored function, the slave executes the statement and exits. If row-based replication is enabled, the slave does not know whether a statement occurred within a stored function on the master, so this condition does not apply.
For statement-based replication, replication events represent
statements (all changes making up a given event are associated
with a single SQL statement); for row-based replication, each
event represents a change in a single table row (thus a single
statement such as UPDATE mytable SET mycol =
1 may yield many row-based events). When viewed in
terms of events, the process of checking table options is the
same for both row-based and statement-based replication.
Having reached this point, if there are no table options, the
slave simply executes all events. If there are any
--replicate-do-table or
--replicate-wild-do-table
options, the event must match one of these if it is to be
executed; otherwise, it is ignored. If there are any
--replicate-ignore-table or
--replicate-wild-ignore-table
options, all events are executed except those that match any of
these options. This process is illustrated in the following
diagram.
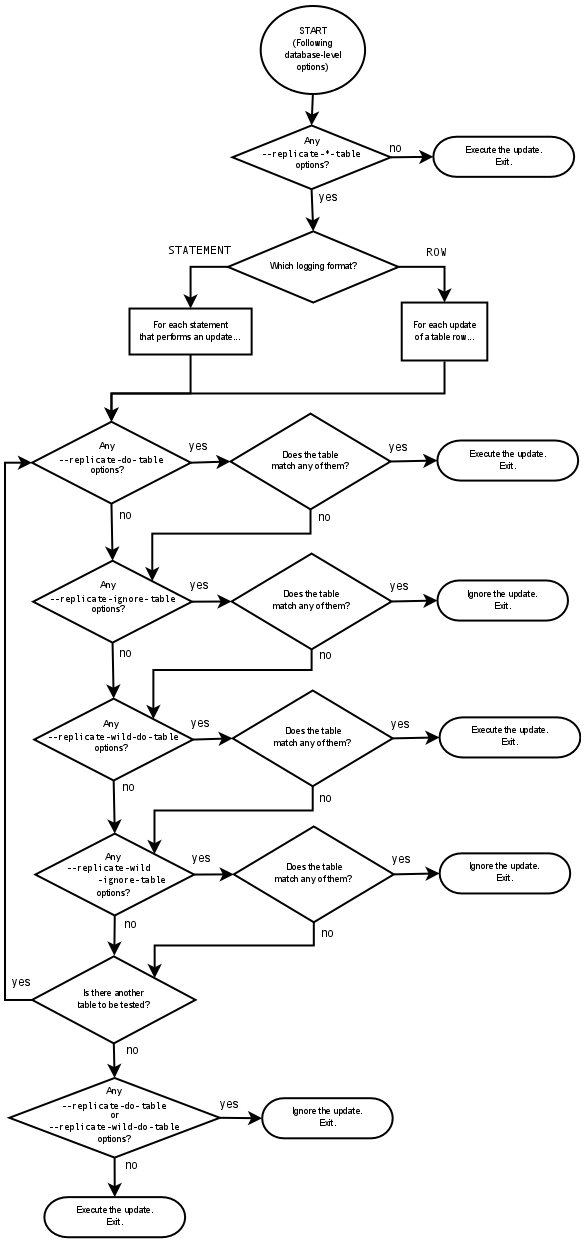
The following steps describe this evaluation in more detail:
Are there any table options?
Yes. Continue to step 2.
No. Execute the event and exit.
Are there any
--replicate-do-tableoptions?Yes. Does the table match any of them?
Yes. Execute the event and exit.
No. Continue to step 3.
No. Continue to step 3.
Are there any
--replicate-ignore-tableoptions?Yes. Does the table match any of them?
Yes. Ignore the event and exit.
No. Continue to step 4.
No. Continue to step 4.
Are there any
--replicate-wild-do-tableoptions?Yes. Does the table match any of them?
Yes. Execute the event and exit.
No. Continue to step 5.
No. Continue to step 5.
Are there any
--replicate-wild-ignore-tableoptions?Yes. Does the table match any of them?
Yes. Ignore the event and exit.
No. Continue to step 6.
No. Continue to step 6.
Are there any
--replicate-do-tableor--replicate-wild-do-tableoptions?Yes. Ignore the event and exit.
No. Execute the event and exit.
This section provides additional explanation and examples of usage for different combinations of replication filtering options.
Some typical combinations of replication filter rule types are given in the following table:
| Condition (Types of Options) | Outcome |
|---|---|
No --replicate-* options at all: | The slave executes all events that it receives from the master. |
--replicate-*-db options, but no table options: | The slave accepts or ignores events using the database options. It executes all events permitted by those options because there are no table restrictions. |
--replicate-*-table options, but no database options: | All events are accepted at the database-checking stage because there are no database conditions. The slave executes or ignores events based solely on the table options. |
| A combination of database and table options: | The slave accepts or ignores events using the database options. Then it evaluates all events permitted by those options according to the table options. This can sometimes lead to results that seem counterintuitive, and that may be different depending on whether you are using statement-based or row-based replication; see the text for an example. |
A more complex example follows, in which we examine the outcomes for both statement-based and row-based settings.
Suppose that we have two tables mytbl1 in
database db1 and mytbl2 in
database db2 on the master, and the slave is
running with the following options (and no other replication
filtering options):
replicate-ignore-db = db1 replicate-do-table = db2.tbl2
Now we execute the following statements on the master:
USE db1; INSERT INTO db2.tbl2 VALUES (1);
The results on the slave vary considerably depending on the binary log format, and may not match initial expectations in either case.
Statement-based replication.
The USE statement causes
db1 to be the default database. Thus the
--replicate-ignore-db option
matches, and the
INSERT statement is
ignored. The table options are not checked.
Row-based replication.
The default database has no effect on how the slave reads
database options when using row-based replication. Thus, the
USE statement makes no
difference in how the
--replicate-ignore-db option is
handled: the database specified by this option does not match
the database where the INSERT
statement changes data, so the slave proceeds to check the
table options. The table specified by
--replicate-do-table matches
the table to be updated, and the row is
inserted.
- 17.3.1 Using Replication for Backups
- 17.3.2 Using Replication with Different Master and Slave Storage Engines
- 17.3.3 Using Replication for Scale-Out
- 17.3.4 Replicating Different Databases to Different Slaves
- 17.3.5 Improving Replication Performance
- 17.3.6 Switching Masters During Failover
- 17.3.7 Setting Up Replication to Use Secure Connections
- 17.3.8 Semisynchronous Replication
Replication can be used in many different environments for a range of purposes. This section provides general notes and advice on using replication for specific solution types.
For information on using replication in a backup environment, including notes on the setup, backup procedure, and files to back up, see Section 17.3.1, “Using Replication for Backups”.
For advice and tips on using different storage engines on the master and slaves, see Section 17.3.2, “Using Replication with Different Master and Slave Storage Engines”.
Using replication as a scale-out solution requires some changes in the logic and operation of applications that use the solution. See Section 17.3.3, “Using Replication for Scale-Out”.
For performance or data distribution reasons, you may want to replicate different databases to different replication slaves. See Section 17.3.4, “Replicating Different Databases to Different Slaves”
As the number of replication slaves increases, the load on the master can increase and lead to reduced performance (because of the need to replicate the binary log to each slave). For tips on improving your replication performance, including using a single secondary server as a replication master, see Section 17.3.5, “Improving Replication Performance”.
For guidance on switching masters, or converting slaves into masters as part of an emergency failover solution, see Section 17.3.6, “Switching Masters During Failover”.
To secure your replication communication, you can encrypt the communication channel. For step-by-step instructions, see Section 17.3.7, “Setting Up Replication to Use Secure Connections”.
To use replication as a backup solution, replicate data from the master to a slave, and then back up the data slave. The slave can be paused and shut down without affecting the running operation of the master, so you can produce an effective snapshot of “live” data that would otherwise require the master to be shut down.
How you back up a database depends on its size and whether you are backing up only the data, or the data and the replication slave state so that you can rebuild the slave in the event of failure. There are therefore two choices:
If you are using replication as a solution to enable you to back up the data on the master, and the size of your database is not too large, the mysqldump tool may be suitable. See Section 17.3.1.1, “Backing Up a Slave Using mysqldump”.
For larger databases, where mysqldump would be impractical or inefficient, you can back up the raw data files instead. Using the raw data files option also means that you can back up the binary and relay logs that will enable you to recreate the slave in the event of a slave failure. For more information, see Section 17.3.1.2, “Backing Up Raw Data from a Slave”.
Another backup strategy, which can be used for either master or slave servers, is to put the server in a read-only state. The backup is performed against the read-only server, which then is changed back to its usual read/write operational status. See Section 17.3.1.3, “Backing Up a Master or Slave by Making It Read Only”.
Using mysqldump to create a copy of a database enables you to capture all of the data in the database in a format that enables the information to be imported into another instance of MySQL Server (see Section 4.5.4, “mysqldump — A Database Backup Program”). Because the format of the information is SQL statements, the file can easily be distributed and applied to running servers in the event that you need access to the data in an emergency. However, if the size of your data set is very large, mysqldump may be impractical.
When using mysqldump, you should stop replication on the slave before starting the dump process to ensure that the dump contains a consistent set of data:
Stop the slave from processing requests. You can stop replication completely on the slave using mysqladmin:
shell>
mysqladmin stop-slaveAlternatively, you can stop only the slave SQL thread to pause event execution:
shell>
mysql -e 'STOP SLAVE SQL_THREAD;'This enables the slave to continue to receive data change events from the master's binary log and store them in the relay logs using the I/O thread, but prevents the slave from executing these events and changing its data. Within busy replication environments, permitting the I/O thread to run during backup may speed up the catch-up process when you restart the slave SQL thread.
Run mysqldump to dump your databases. You may either dump all databases or select databases to be dumped. For example, to dump all databases:
shell>
mysqldump --all-databases > fulldb.dumpOnce the dump has completed, start slave operations again:
shell>
mysqladmin start-slave
In the preceding example, you may want to add login credentials (user name, password) to the commands, and bundle the process up into a script that you can run automatically each day.
If you use this approach, make sure you monitor the slave replication process to ensure that the time taken to run the backup does not affect the slave's ability to keep up with events from the master. See Section 17.1.4.1, “Checking Replication Status”. If the slave is unable to keep up, you may want to add another slave and distribute the backup process. For an example of how to configure this scenario, see Section 17.3.4, “Replicating Different Databases to Different Slaves”.
To guarantee the integrity of the files that are copied, backing
up the raw data files on your MySQL replication slave should
take place while your slave server is shut down. If the MySQL
server is still running, background tasks may still be updating
the database files, particularly those involving storage engines
with background processes such as InnoDB.
With InnoDB, these problems should be
resolved during crash recovery, but since the slave server can
be shut down during the backup process without affecting the
execution of the master it makes sense to take advantage of this
capability.
To shut down the server and back up the files:
Shut down the slave MySQL server:
shell>
mysqladmin shutdownCopy the data files. You can use any suitable copying or archive utility, including cp, tar or WinZip. For example, assuming that the data directory is located under the current directory, you can archive the entire directory as follows:
shell>
tar cf /tmp/dbbackup.tar ./dataStart the MySQL server again. Under Unix:
shell>
mysqld_safe &Under Windows:
C:\>
"C:\Program Files\MySQL\MySQL Server 5.5\bin\mysqld"
Normally you should back up the entire data directory for the
slave MySQL server. If you want to be able to restore the data
and operate as a slave (for example, in the event of failure of
the slave), then in addition to the slave's data, you should
also back up the slave status files,
master.info and
relay-log.info, along with the relay log
files. These files are needed to resume replication after you
restore the slave's data.
If you lose the relay logs but still have the
relay-log.info file, you can check it to
determine how far the SQL thread has executed in the master
binary logs. Then you can use CHANGE MASTER
TO with the MASTER_LOG_FILE and
MASTER_LOG_POS options to tell the slave to
re-read the binary logs from that point. This requires that the
binary logs still exist on the master server.
If your slave is replicating
LOAD DATA
INFILE statements, you should also back up any
SQL_LOAD-* files that exist in the
directory that the slave uses for this purpose. The slave needs
these files to resume replication of any interrupted
LOAD DATA
INFILE operations. The location of this directory is
the value of the
--slave-load-tmpdir option. If
the server was not started with that option, the directory
location is the value of the
tmpdir system variable.
It is possible to back up either master or slave servers in a
replication setup by acquiring a global read lock and
manipulating the read_only
system variable to change the read-only state of the server to
be backed up:
Make the server read-only, so that it processes only retrievals and blocks updates.
Perform the backup.
Change the server back to its normal read/write state.
The instructions in this section place the server to be backed up in a state that is safe for backup methods that get the data from the server, such as mysqldump (see Section 4.5.4, “mysqldump — A Database Backup Program”). You should not attempt to use these instructions to make a binary backup by copying files directly because the server may still have modified data cached in memory and not flushed to disk.
The following instructions describe how to do this for a master server and for a slave server. For both scenarios discussed here, suppose that you have the following replication setup:
A master server M1
A slave server S1 that has M1 as its master
A client C1 connected to M1
A client C2 connected to S1
In either scenario, the statements to acquire the global read
lock and manipulate the
read_only variable are
performed on the server to be backed up and do not propagate to
any slaves of that server.
Scenario 1: Backup with a Read-Only Master
Put the master M1 in a read-only state by executing these statements on it:
mysql>FLUSH TABLES WITH READ LOCK;mysql>SET GLOBAL read_only = ON;
While M1 is in a read-only state, the following properties are true:
Requests for updates sent by C1 to M1 will block because the server is in read-only mode.
Requests for query results sent by C1 to M1 will succeed.
Making a backup on M1 is safe.
Making a backup on S1 is not safe. This server is still running, and might be processing the binary log or update requests coming from client C2
While M1 is read only, perform the backup. For example, you can use mysqldump.
After the backup operation on M1 completes, restore M1 to its normal operational state by executing these statements:
mysql>SET GLOBAL read_only = OFF;mysql>UNLOCK TABLES;
Although performing the backup on M1 is safe (as far as the backup is concerned), it is not optimal for performance because clients of M1 are blocked from executing updates.
This strategy applies to backing up a master server in a replication setup, but can also be used for a single server in a nonreplication setting.
Scenario 2: Backup with a Read-Only Slave
Put the slave S1 in a read-only state by executing these statements on it:
mysql>FLUSH TABLES WITH READ LOCK;mysql>SET GLOBAL read_only = ON;
While S1 is in a read-only state, the following properties are true:
The master M1 will continue to operate, so making a backup on the master is not safe.
The slave S1 is stopped, so making a backup on the slave S1 is safe.
These properties provide the basis for a popular backup scenario: Having one slave busy performing a backup for a while is not a problem because it does not affect the entire network, and the system is still running during the backup. In particular, clients can still perform updates on the master server, which remains unaffected by backup activity on the slave.
While S1 is read only, perform the backup. For example, you can use mysqldump.
After the backup operation on S1 completes, restore S1 to its normal operational state by executing these statements:
mysql>SET GLOBAL read_only = OFF;mysql>UNLOCK TABLES;
After the slave is restored to normal operation, it again synchronizes to the master by catching up with any outstanding updates from the binary log of the master.
It does not matter for the replication process whether the source
table on the master and the replicated table on the slave use
different engine types. In fact, the
default_storage_engine and
storage_engine system variables
are not replicated.
This provides a number of benefits in the replication process in
that you can take advantage of different engine types for
different replication scenarios. For example, in a typical
scale-out scenario (see
Section 17.3.3, “Using Replication for Scale-Out”), you want to use
InnoDB tables on the master to take advantage
of the transactional functionality, but use
MyISAM on the slaves where transaction support
is not required because the data is only read. When using
replication in a data-logging environment you may want to use the
Archive storage engine on the slave.
Configuring different engines on the master and slave depends on how you set up the initial replication process:
If you used mysqldump to create the database snapshot on your master, you could edit the dump file text to change the engine type used on each table.
Another alternative for mysqldump is to disable engine types that you do not want to use on the slave before using the dump to build the data on the slave. For example, you can add the
--skip-innodboption on your slave to disable theInnoDBengine. If a specific engine does not exist for a table to be created, MySQL will use the default engine type, usuallyMyISAM. (This requires that theNO_ENGINE_SUBSTITUTIONSQL mode is not enabled.) If you want to disable additional engines in this way, you may want to consider building a special binary to be used on the slave that only supports the engines you want.If you are using raw data files (a binary backup) to set up the slave, you will be unable to change the initial table format. Instead, use
ALTER TABLEto change the table types after the slave has been started.For new master/slave replication setups where there are currently no tables on the master, avoid specifying the engine type when creating new tables.
If you are already running a replication solution and want to convert your existing tables to another engine type, follow these steps:
Stop the slave from running replication updates:
mysql>
STOP SLAVE;This will enable you to change engine types without interruptions.
Execute an
ALTER TABLE ... ENGINE='for each table to be changed.engine_type'Start the slave replication process again:
mysql>
START SLAVE;
Although the
default_storage_engine variable
is not replicated, be aware that CREATE
TABLE and ALTER TABLE
statements that include the engine specification will be correctly
replicated to the slave. For example, if you have a CSV table and
you execute:
mysql> ALTER TABLE csvtable Engine='MyISAM';
The above statement will be replicated to the slave and the engine
type on the slave will be converted to MyISAM,
even if you have previously changed the table type on the slave to
an engine other than CSV. If you want to retain engine differences
on the master and slave, you should be careful to use the
default_storage_engine variable
on the master when creating a new table. For example, instead of:
mysql> CREATE TABLE tablea (columna int) Engine=MyISAM;
Use this format:
mysql>SET default_storage_engine=MyISAM;mysql>CREATE TABLE tablea (columna int);
When replicated, the
default_storage_engine variable
will be ignored, and the CREATE
TABLE statement will execute on the slave using the
slave's default engine.
You can use replication as a scale-out solution; that is, where you want to split up the load of database queries across multiple database servers, within some reasonable limitations.
Because replication works from the distribution of one master to one or more slaves, using replication for scale-out works best in an environment where you have a high number of reads and low number of writes/updates. Most Web sites fit into this category, where users are browsing the Web site, reading articles, posts, or viewing products. Updates only occur during session management, or when making a purchase or adding a comment/message to a forum.
Replication in this situation enables you to distribute the reads over the replication slaves, while still enabling your web servers to communicate with the replication master when a write is required. You can see a sample replication layout for this scenario in Figure 17.1, “Using Replication to Improve Performance During Scale-Out”.
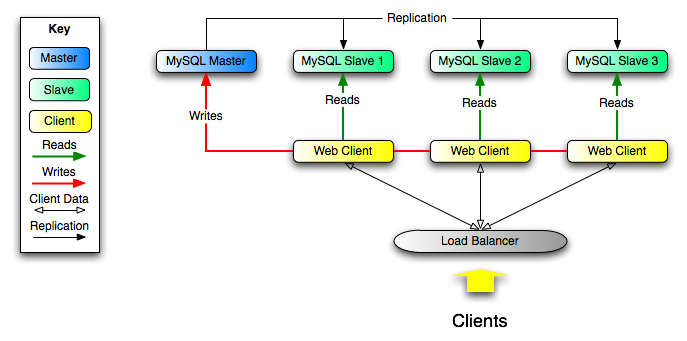
If the part of your code that is responsible for database access has been properly abstracted/modularized, converting it to run with a replicated setup should be very smooth and easy. Change the implementation of your database access to send all writes to the master, and to send reads to either the master or a slave. If your code does not have this level of abstraction, setting up a replicated system gives you the opportunity and motivation to clean it up. Start by creating a wrapper library or module that implements the following functions:
safe_writer_connect()safe_reader_connect()safe_reader_statement()safe_writer_statement()
safe_ in each function name means that the
function takes care of handling all error conditions. You can use
different names for the functions. The important thing is to have
a unified interface for connecting for reads, connecting for
writes, doing a read, and doing a write.
Then convert your client code to use the wrapper library. This may be a painful and scary process at first, but it pays off in the long run. All applications that use the approach just described are able to take advantage of a master/slave configuration, even one involving multiple slaves. The code is much easier to maintain, and adding troubleshooting options is trivial. You need modify only one or two functions; for example, to log how long each statement took, or which statement among those issued gave you an error.
If you have written a lot of code, you may want to automate the conversion task by using the replace utility that comes with standard MySQL distributions, or write your own conversion script. Ideally, your code uses consistent programming style conventions. If not, then you are probably better off rewriting it anyway, or at least going through and manually regularizing it to use a consistent style.
There may be situations where you have a single master and want to replicate different databases to different slaves. For example, you may want to distribute different sales data to different departments to help spread the load during data analysis. A sample of this layout is shown in Figure 17.2, “Using Replication to Replicate Databases to Separate Replication Slaves”.
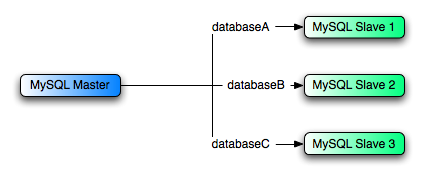
You can achieve this separation by configuring the master and
slaves as normal, and then limiting the binary log statements that
each slave processes by using the
--replicate-wild-do-table
configuration option on each slave.
You should not use
--replicate-do-db for this
purpose when using statement-based replication, since
statement-based replication causes this option's affects to
vary according to the database that is currently selected. This
applies to mixed-format replication as well, since this enables
some updates to be replicated using the statement-based format.
However, it should be safe to use
--replicate-do-db for this
purpose if you are using row-based replication only, since in
this case the currently selected database has no effect on the
option's operation.
For example, to support the separation as shown in
Figure 17.2, “Using Replication to Replicate Databases to Separate Replication Slaves”, you should
configure each replication slave as follows, before executing
START SLAVE:
Replication slave 1 should use
--replicate-wild-do-table=databaseA.%.Replication slave 2 should use
--replicate-wild-do-table=databaseB.%.Replication slave 3 should use
--replicate-wild-do-table=databaseC.%.
Each slave in this configuration receives the entire binary log
from the master, but executes only those events from the binary
log that apply to the databases and tables included by the
--replicate-wild-do-table option in
effect on that slave.
If you have data that must be synchronized to the slaves before replication starts, you have a number of choices:
Synchronize all the data to each slave, and delete the databases, tables, or both that you do not want to keep.
Use mysqldump to create a separate dump file for each database and load the appropriate dump file on each slave.
Use a raw data file dump and include only the specific files and databases that you need for each slave.
NoteThis does not work with
InnoDBdatabases unless you useinnodb_file_per_table.
As the number of slaves connecting to a master increases, the load, although minimal, also increases, as each slave uses a client connection to the master. Also, as each slave must receive a full copy of the master binary log, the network load on the master may also increase and create a bottleneck.
If you are using a large number of slaves connected to one master, and that master is also busy processing requests (for example, as part of a scale-out solution), then you may want to improve the performance of the replication process.
One way to improve the performance of the replication process is to create a deeper replication structure that enables the master to replicate to only one slave, and for the remaining slaves to connect to this primary slave for their individual replication requirements. A sample of this structure is shown in Figure 17.3, “Using an Additional Replication Host to Improve Performance”.
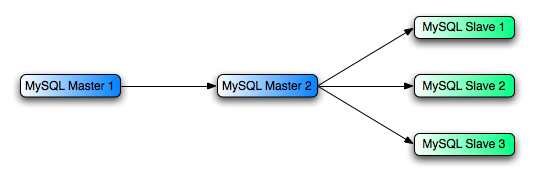
For this to work, you must configure the MySQL instances as follows:
Master 1 is the primary master where all changes and updates are written to the database. Binary logging should be enabled on this machine.
Master 2 is the slave to the Master 1 that provides the replication functionality to the remainder of the slaves in the replication structure. Master 2 is the only machine permitted to connect to Master 1. Master 2 also has binary logging enabled, and the
--log-slave-updatesoption so that replication instructions from Master 1 are also written to Master 2's binary log so that they can then be replicated to the true slaves.Slave 1, Slave 2, and Slave 3 act as slaves to Master 2, and replicate the information from Master 2, which actually consists of the upgrades logged on Master 1.
The above solution reduces the client load and the network interface load on the primary master, which should improve the overall performance of the primary master when used as a direct database solution.
If your slaves are having trouble keeping up with the replication process on the master, there are a number of options available:
If possible, put the relay logs and the data files on different physical drives. To do this, use the
--relay-logoption to specify the location of the relay log.If the slaves are significantly slower than the master, you may want to divide up the responsibility for replicating different databases to different slaves. See Section 17.3.4, “Replicating Different Databases to Different Slaves”.
If your master makes use of transactions and you are not concerned about transaction support on your slaves, use
MyISAMor another nontransactional engine on the slaves. See Section 17.3.2, “Using Replication with Different Master and Slave Storage Engines”.If your slaves are not acting as masters, and you have a potential solution in place to ensure that you can bring up a master in the event of failure, then you can switch off
--log-slave-updates. This prevents “dumb” slaves from also logging events they have executed into their own binary log.
There is in MySQL 5.5 no official solution for providing failover between master and slaves in the event of a failure. Instead, you must set up a master and one or more slaves; then, you need to write an application or script that monitors the master to check whether it is up, and instructs the slaves and applications to change master in case of failure. This section discusses some of the issues encountered when setting up failover in this fashion.
The MySQL Utilities include a mysqlfailover tool that provides failover capability using GTIDs, support for which requires MySQL 5.6 or later. For more information, see mysqlfailover — Automatic replication health monitoring and failover, and Replication with Global Transaction Identifiers.
You can tell a slave to change to a new master using the
CHANGE MASTER TO statement. The
slave does not check whether the databases on the master are
compatible with those on the slave; it simply begins reading and
executing events from the specified coordinates in the new
master's binary log. In a failover situation, all the servers
in the group are typically executing the same events from the same
binary log file, so changing the source of the events should not
affect the structure or integrity of the database, provided that
you exercise care in making the change.
Slaves should be run with the
--log-bin option and without
--log-slave-updates. In this way,
the slave is ready to become a master without restarting the slave
mysqld. Assume that you have the structure
shown in Figure 17.4, “Redundancy Using Replication, Initial Structure”.
Remember that you can tell a slave to change its master at any
time, using the CHANGE MASTER TO
statement. The slave will not check whether the databases on the
master are compatible with the slave, it will just start reading
and executing events from the specified binary log coordinates on
the new master. In a failover situation, all the servers in the
group are typically executing the same events from the same binary
log file, so changing the source of the events should not affect
the database structure or integrity providing you are careful.
Run your slaves with the --log-bin
option and without
--log-slave-updates. In this way,
the slave is ready to become a master as soon as you issue
STOP SLAVE;
RESET MASTER, and
CHANGE MASTER TO statement on the
other slaves. For example, assume that you have the structure
shown in Figure 17.4, “Redundancy Using Replication, Initial Structure”.
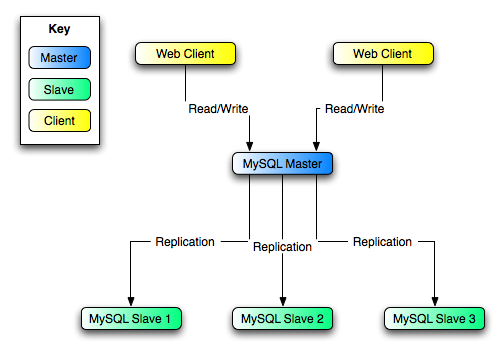
In this diagram, the MySQL Master holds the
master database, the MySQL Slave hosts are
replication slaves, and the Web Client machines
are issuing database reads and writes. Web clients that issue only
reads (and would normally be connected to the slaves) are not
shown, as they do not need to switch to a new server in the event
of failure. For a more detailed example of a read/write scale-out
replication structure, see
Section 17.3.3, “Using Replication for Scale-Out”.
Each MySQL Slave (Slave 1, Slave
2, and Slave 3) is a slave running
with --log-bin and without
--log-slave-updates. Because
updates received by a slave from the master are not logged in the
binary log unless
--log-slave-updates is specified,
the binary log on each slave is empty initially. If for some
reason MySQL Master becomes unavailable, you
can pick one of the slaves to become the new master. For example,
if you pick Slave 1, all Web
Clients should be redirected to Slave
1, which writes the updates to its binary log.
Slave 2 and Slave 3 should
then replicate from Slave 1.
The reason for running the slave without
--log-slave-updates is to prevent
slaves from receiving updates twice in case you cause one of the
slaves to become the new master. If Slave 1 has
--log-slave-updates enabled, it
writes any updates that it receives from Master
in its own binary log. This means that, when Slave
2 changes from Master to
Slave 1 as its master, it may receive updates
from Slave 1 that it has already received from
Master.
Make sure that all slaves have processed any statements in their
relay log. On each slave, issue STOP SLAVE
IO_THREAD, then check the output of
SHOW PROCESSLIST until you see
Has read all relay log. When this is true for
all slaves, they can be reconfigured to the new setup. On the
slave Slave 1 being promoted to become the
master, issue STOP SLAVE and
RESET MASTER.
On the other slaves Slave 2 and Slave
3, use STOP SLAVE and
CHANGE MASTER TO MASTER_HOST='Slave1' (where
'Slave1' represents the real host name of
Slave 1). To use CHANGE MASTER
TO, add all information about how to connect to
Slave 1 from Slave 2 or
Slave 3 (user,
password,
port). When issuing the CHANGE
MASTER TO statement in this, there is no need to specify
the name of the Slave 1 binary log file or log
position to read from, since the first binary log file and
position 4, are the defaults. Finally, execute
START SLAVE on Slave
2 and Slave 3.
Once the new replication setup is in place, you need to tell each
Web Client to direct its statements to
Slave 1. From that point on, all updates
statements sent by Web Client to Slave
1 are written to the binary log of Slave
1, which then contains every update statement sent to
Slave 1 since Master died.
The resulting server structure is shown in Figure 17.5, “Redundancy Using Replication, After Master Failure”.
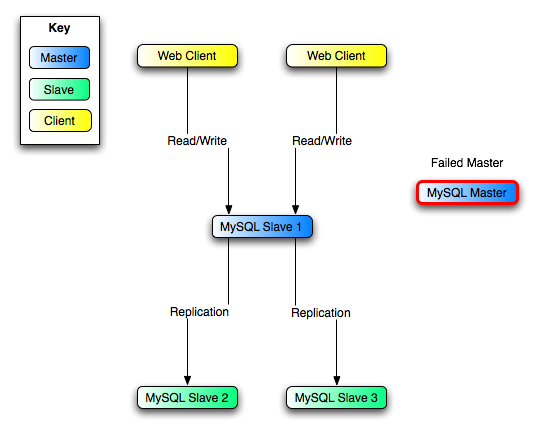
When Master becomes available again, you should
make it a slave of Slave 1. To do this, issue
on Master the same CHANGE
MASTER TO statement as that issued on Slave
2 and Slave 3 previously.
Master then becomes a slave of S1ave
1 and picks up the Web Client writes
that it missed while it was offline.
To make Master a master again, use the
preceding procedure as if Slave 1 was
unavailable and Master was to be the new
master. During this procedure, do not forget to run
RESET MASTER on
Master before making Slave
1, Slave 2, and Slave
3 slaves of Master. If you fail to do
this, the slaves may pick up stale writes from the Web
Client applications dating from before the point at
which Master became unavailable.
You should be aware that there is no synchronization between slaves, even when they share the same master, and thus some slaves might be considerably ahead of others. This means that in some cases the procedure outlined in the previous example might not work as expected. In practice, however, relay logs on all slaves should be relatively close together.
One way to keep applications informed about the location of the
master is to have a dynamic DNS entry for the master. With
bind you can use nsupdate
to update the DNS dynamically.
To use a secure connection for encrypting the transfer of the binary log required during replication, both the master and the slave servers must support encrypted network connections. If either server does not support secure connections (because it has not been compiled or configured for them), replication through an encrypted connection is not possible.
Setting up secure connections for replication is similar to doing so for client/server connections. You must obtain (or create) a suitable security certificate that you can use on the master, and a similar certificate (from the same certificate authority) on each slave. You must also obtain suitable key files.
For more information on setting up a server and client for secure connections, see Section 6.3.8.4, “Configuring MySQL to Use Secure Connections”.
To enable secure connections on the master, you must create or
obtain suitable certificate and key files, and then add the
following configuration options to the master's configuration
within the [mysqld] section of the master's
my.cnf file, changing the file names as
necessary:
[mysqld] ssl-ca=cacert.pem ssl-cert=server-cert.pem ssl-key=server-key.pem
The paths to the files may be relative or absolute; we recommend that you always use complete paths for this purpose.
The options are as follows:
On the slave, there are two ways to specify the information
required for connecting securely to the master. You can either
name the slave certificate and key files in the
[client] section of the slave's
my.cnf file, or you can explicitly specify
that information using the CHANGE MASTER
TO statement:
To name the slave certificate and key files using an option file, add the following lines to the
[client]section of the slave'smy.cnffile, changing the file names as necessary:[client] ssl-ca=cacert.pem ssl-cert=client-cert.pem ssl-key=client-key.pem
Restart the slave server, using the
--skip-slave-startoption to prevent the slave from connecting to the master. UseCHANGE MASTER TOto specify the master configuration, using theMASTER_SSLoption to connect securely:mysql>
CHANGE MASTER TO->MASTER_HOST='master_hostname',->MASTER_USER='replicate',->MASTER_PASSWORD='password',->MASTER_SSL=1;To specify the certificate and key names using the
CHANGE MASTER TOstatement, append the appropriateMASTER_SSL_options:xxxmysql>
CHANGE MASTER TO->MASTER_HOST='master_hostname',->MASTER_USER='replicate',->MASTER_PASSWORD='password',->MASTER_SSL=1,->MASTER_SSL_CA = 'ca_file_name',->MASTER_SSL_CAPATH = 'ca_directory_name',->MASTER_SSL_CERT = 'cert_file_name',->MASTER_SSL_KEY = 'key_file_name';
After the master information has been updated, start the slave replication process:
mysql> START SLAVE;
You can use the SHOW SLAVE STATUS
statement to confirm that a secure connection was established
successfully.
For more information on the CHANGE MASTER
TO statement, see Section 13.4.2.1, “CHANGE MASTER TO Syntax”.
If you want to enforce the use of secure connections during
replication, then create a user with the
REPLICATION SLAVE privilege and use
the REQUIRE SSL option for that user. For
example:
mysql>CREATE USER 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass';mysql>GRANT REPLICATION SLAVE ON *.*->TO 'repl'@'%.mydomain.com' REQUIRE SSL;
If the account already exists, you can add REQUIRE
SSL to it with this statement:
mysql>GRANT USAGE ON *.*->TO 'repl'@'%.mydomain.com' REQUIRE SSL;
In addition to the built-in asynchronous replication, MySQL 5.5 supports an interface to semisynchronous replication that is implemented by plugins. This section discusses what semisynchronous replication is and how it works. The following sections cover the administrative interface to semisynchronous replication and how to install, configure, and monitor it.
MySQL replication by default is asynchronous. The master writes events to its binary log but does not know whether or when a slave has retrieved and processed them. With asynchronous replication, if the master crashes, transactions that it has committed might not have been transmitted to any slave. Consequently, failover from master to slave in this case may result in failover to a server that is missing transactions relative to the master.
Semisynchronous replication can be used as an alternative to asynchronous replication:
A slave indicates whether it is semisynchronous-capable when it connects to the master.
If semisynchronous replication is enabled on the master side and there is at least one semisynchronous slave, a thread that performs a transaction commit on the master blocks after the commit is done and waits until at least one semisynchronous slave acknowledges that it has received all events for the transaction, or until a timeout occurs.
The slave acknowledges receipt of a transaction's events only after the events have been written to its relay log and flushed to disk.
If a timeout occurs without any slave having acknowledged the transaction, the master reverts to asynchronous replication. When at least one semisynchronous slave catches up, the master returns to semisynchronous replication.
Semisynchronous replication must be enabled on both the master and slave sides. If semisynchronous replication is disabled on the master, or enabled on the master but on no slaves, the master uses asynchronous replication.
While the master is blocking (waiting for acknowledgment from a slave after having performed a commit), it does not return to the session that performed the transaction. When the block ends, the master returns to the session, which then can proceed to execute other statements. At this point, the transaction has committed on the master side, and receipt of its events has been acknowledged by at least one slave.
Blocking also occurs after rollbacks that are written to the binary log, which occurs when a transaction that modifies nontransactional tables is rolled back. The rolled-back transaction is logged even though it has no effect for transactional tables because the modifications to the nontransactional tables cannot be rolled back and must be sent to slaves.
For statements that do not occur in transactional context (that
is, when no transaction has been started with
START
TRANSACTION or
SET autocommit =
0), autocommit is enabled and each statement commits
implicitly. With semisynchronous replication, the master blocks
after committing each such statement, just as it does for explicit
transaction commits.
To understand what the “semi” in “semisynchronous replication” means, compare it with asynchronous and fully synchronous replication:
With asynchronous replication, the master writes events to its binary log and slaves request them when they are ready. There is no guarantee that any event will ever reach any slave.
With fully synchronous replication, when a master commits a transaction, all slaves also will have committed the transaction before the master returns to the session that performed the transaction. The drawback of this is that there might be a lot of delay to complete a transaction.
Semisynchronous replication falls between asynchronous and fully synchronous replication. The master waits after commit only until at least one slave has received and logged the events. It does not wait for all slaves to acknowledge receipt, and it requires only receipt, not that the events have been fully executed and committed on the slave side.
Compared to asynchronous replication, semisynchronous replication provides improved data integrity. When a commit returns successfully, it is known that the data exists in at least two places (on the master and at least one slave). If the master commits but a crash occurs while the master is waiting for acknowledgment from a slave, it is possible that the transaction may not have reached any slave.
Semisynchronous replication also places a rate limit on busy sessions by constraining the speed at which binary log events can be sent from master to slave. When one user is too busy, this will slow it down, which is useful in some deployment situations.
Semisynchronous replication does have some performance impact because commits are slower due to the need to wait for slaves. This is the tradeoff for increased data integrity. The amount of slowdown is at least the TCP/IP roundtrip time to send the commit to the slave and wait for the acknowledgment of receipt by the slave. This means that semisynchronous replication works best for close servers communicating over fast networks, and worst for distant servers communicating over slow networks.
The administrative interface to semisynchronous replication has several components:
Two plugins implement semisynchronous capability. There is one plugin for the master side and one for the slave side.
System variables control plugin behavior. Some examples:
Controls whether semisynchronous replication is enabled on the master. To enable or disable the plugin, set this variable to 1 or 0, respectively. The default is 0 (off).
A value in milliseconds that controls how long the master waits on a commit for acknowledgment from a slave before timing out and reverting to asynchronous replication. The default value is 10000 (10 seconds).
Similar to
rpl_semi_sync_master_enabled, but controls the slave plugin.
All
rpl_semi_sync_system variables are described at Section 5.1.4, “Server System Variables”.xxxStatus variables enable semisynchronous replication monitoring. Some examples:
The number of semisynchronous slaves.
Whether semisynchronous replication currently is operational on the master. The value is 1 if the plugin has been enabled and a commit acknowledgment has occurred. It is 0 if the plugin is not enabled or the master has fallen back to asynchronous replication due to commit acknowledgment timeout.
The number of commits that were not acknowledged successfully by a slave.
The number of commits that were acknowledged successfully by a slave.
Whether semisynchronous replication currently is operational on the slave. This is 1 if the plugin has been enabled and the slave I/O thread is running, 0 otherwise.
All
Rpl_semi_sync_status variables are described at Section 5.1.6, “Server Status Variables”.xxx
The system and status variables are available only if the
appropriate master or slave plugin has been installed with
INSTALL PLUGIN.
Semisynchronous replication is implemented using plugins, so the plugins must be installed into the server to make them available. After a plugin has been installed, you control it by means of the system variables associated with it. These system variables are unavailable until the associated plugin has been installed.
To use semisynchronous replication, the following requirements must be satisfied:
MySQL 5.5 or higher must be installed.
The capability of installing plugins requires a MySQL server that supports dynamic loading. To verify this, check that the value of the
have_dynamic_loadingsystem variable isYES. Binary distributions should support dynamic loading.Replication must already be working. For information on creating a master/slave relationship, see Section 17.1.1, “How to Set Up Replication”.
To set up semisynchronous replication, use the following
instructions. The INSTALL PLUGIN,
SET
GLOBAL, STOP SLAVE, and
START SLAVE statements mentioned
here require the SUPER privilege.
The semisynchronous replication plugins are included with MySQL distributions.
Unpack the component distribution, which contains files for the master side and the slave side.
Install the component files in the plugin directory of the
appropriate server. Install the
semisync_master* files in the plugin
directory of the master server. Install the
semisync_slave* files in the plugin
directory of each slave server. The location of the plugin
directory is available as the value of the server's
plugin_dir system variable.
To load the plugins, use the INSTALL
PLUGIN statement on the master and on each slave that
is to be semisynchronous.
On the master:
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
On each slave:
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
The preceding commands use a plugin file name suffix of
.so. A different suffix might apply on your
system. If you are not sure about the plugin file name, look for
the plugins in the server's plugin directory.
If an attempt to install a plugin results in an error on Linux
similar to that shown here, you will need to install
libimf:
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
ERROR 1126 (HY000): Can't open shared library
'/usr/local/mysql/lib/plugin/semisync_master.so' (errno: 22 libimf.so: cannot open
shared object file: No such file or directory)
You can obtain libimf from
http://dev.mysql.com/downloads/os-linux.html.
To see which plugins are installed, use the
SHOW PLUGINS statement, or query
the INFORMATION_SCHEMA.PLUGINS
table.
After a semisynchronous replication plugin has been installed, it is disabled by default. The plugins must be enabled both on the master side and the slave side to enable semisynchronous replication. If only one side is enabled, replication will be asynchronous.
To control whether an installed plugin is enabled, set the
appropriate system variables. You can set these variables at
runtime using SET
GLOBAL, or at server startup on the command line or in
an option file.
At runtime, these master-side system variables are available:
mysql>SET GLOBAL rpl_semi_sync_master_enabled = {0|1};mysql>SET GLOBAL rpl_semi_sync_master_timeout =N;
On the slave side, this system variable is available:
mysql> SET GLOBAL rpl_semi_sync_slave_enabled = {0|1};
For
rpl_semi_sync_master_enabled or
rpl_semi_sync_slave_enabled,
the value should be 1 to enable semisynchronous replication or 0
to disable it. By default, these variables are set to 0.
For
rpl_semi_sync_master_timeout,
the value N is given in milliseconds.
The default value is 10000 (10 seconds).
If you enable semisynchronous replication on a slave at runtime, you must also start the slave I/O thread (stopping it first if it is already running) to cause the slave to connect to the master and register as a semisynchronous slave:
mysql> STOP SLAVE IO_THREAD; START SLAVE IO_THREAD;
If the I/O thread is already running and you do not restart it, the slave continues to use asynchronous replication.
At server startup, the variables that control semisynchronous
replication can be set as command-line options or in an option
file. A setting listed in an option file takes effect each time
the server starts. For example, you can set the variables in
my.cnf files on the master and slave sides
as follows.
On the master:
[mysqld] rpl_semi_sync_master_enabled=1 rpl_semi_sync_master_timeout=1000 # 1 second
On each slave:
[mysqld] rpl_semi_sync_slave_enabled=1
The plugins for the semisynchronous replication capability expose several system and status variables that you can examine to determine its configuration and operational state.
The system variable reflect how semisynchronous replication is
configured. To check their values, use SHOW
VARIABLES:
mysql> SHOW VARIABLES LIKE 'rpl_semi_sync%';
The status variables enable you to monitor the operation of
semisynchronous replication. To check their values, use
SHOW STATUS:
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
When the master switches between asynchronous or semisynchronous
replication due to commit-blocking timeout or a slave catching
up, it sets the value of the
Rpl_semi_sync_master_status
status variable appropriately. Automatic fallback from
semisynchronous to asynchronous replication on the master means
that it is possible for the
rpl_semi_sync_master_enabled
system variable to have a value of 1 on the master side even
when semisynchronous replication is in fact not operational at
the moment. You can monitor the
Rpl_semi_sync_master_status
status variable to determine whether the master currently is
using asynchronous or semisynchronous replication.
To see how many semisynchronous slaves are connected, check
Rpl_semi_sync_master_clients.
The number of commits that have been acknowledged successfully
or unsuccessfully by slaves are indicated by the
Rpl_semi_sync_master_yes_tx
and Rpl_semi_sync_master_no_tx
variables.
On the slave side,
Rpl_semi_sync_slave_status
indicates whether semisynchronous replication currently is
operational.
- 17.4.1.1 Replication and AUTO_INCREMENT
- 17.4.1.2 Replication and BLACKHOLE Tables
- 17.4.1.3 Replication and Character Sets
- 17.4.1.4 Replication and CHECKSUM TABLE
- 17.4.1.5 Replication of CREATE ... IF NOT EXISTS Statements
- 17.4.1.6 Replication of CREATE TABLE ... SELECT Statements
- 17.4.1.7 Replication of CREATE SERVER, ALTER SERVER, and DROP SERVER
- 17.4.1.8 Replication of CURRENT_USER()
- 17.4.1.9 Replication of DROP ... IF EXISTS Statements
- 17.4.1.10 Replication with Differing Table Definitions on Master and Slave
- 17.4.1.11 Replication and DIRECTORY Table Options
- 17.4.1.12 Replication of Invoked Features
- 17.4.1.13 Replication and Floating-Point Values
- 17.4.1.14 Replication and FLUSH
- 17.4.1.15 Replication and System Functions
- 17.4.1.16 Replication and LIMIT
- 17.4.1.17 Replication and LOAD DATA INFILE
- 17.4.1.18 Replication and the Slow Query Log
- 17.4.1.19 Replication and Partitioning
- 17.4.1.20 Replication and REPAIR TABLE
- 17.4.1.21 Replication and Master or Slave Shutdowns
- 17.4.1.22 Replication and max_allowed_packet
- 17.4.1.23 Replication and MEMORY Tables
- 17.4.1.24 Replication and Temporary Tables
- 17.4.1.25 Replication of the mysql System Database
- 17.4.1.26 Replication and the Query Optimizer
- 17.4.1.27 Replication and Reserved Words
- 17.4.1.28 SET PASSWORD and Row-Based Replication
- 17.4.1.29 Slave Errors During Replication
- 17.4.1.30 Replication of Server-Side Help Tables
- 17.4.1.31 Replication and Server SQL Mode
- 17.4.1.32 Replication Retries and Timeouts
- 17.4.1.33 Replication and TIMESTAMP
- 17.4.1.34 Replication and Time Zones
- 17.4.1.35 Replication and Transactions
- 17.4.1.36 Replication and Triggers
- 17.4.1.37 Replication and TRUNCATE TABLE
- 17.4.1.38 Replication and Variables
- 17.4.1.39 Replication and Views
The following sections provide information about what is supported and what is not in MySQL replication, and about specific issues and situations that may occur when replicating certain statements.
Statement-based replication depends on compatibility at the SQL level between the master and slave. In others, successful SBR requires that any SQL features used be supported by both the master and the slave servers. For example, if you use a feature on the master server that is available only in MySQL 5.5 (or later), you cannot replicate to a slave that uses MySQL 5.1 (or earlier).
Such incompatibilities also can occur within a release series when
using pre-production releases of MySQL. For example, the
SLEEP() function is available
beginning with MySQL 5.0.12. If you use this function on the
master, you cannot replicate to a slave that uses MySQL 5.0.11 or
earlier.
For this reason, use Generally Available (GA) releases of MySQL for statement-based replication in a production setting, since we do not introduce new SQL statements or change their behavior within a given release series once that series reaches GA release status.
If you are planning to use statement-based replication between MySQL 5.5 and a previous MySQL release series, it is also a good idea to consult the edition of the MySQL Reference Manual corresponding to the earlier release series for information regarding the replication characteristics of that series.
With MySQL's statement-based replication, there may be issues with replicating stored routines or triggers. You can avoid these issues by using MySQL's row-based replication instead. For a detailed list of issues, see Section 20.7, “Binary Logging of Stored Programs”. For more information about row-based logging and row-based replication, see Section 5.2.4.1, “Binary Logging Formats”, and Section 17.1.2, “Replication Formats”.
For additional information specific to replication and
InnoDB, see
Section 14.20, “InnoDB and MySQL Replication”. For information
relating to replication with MySQL Cluster, see
Section 18.6, “MySQL Cluster Replication”.
Statement-based replication of
AUTO_INCREMENT,
LAST_INSERT_ID(), and
TIMESTAMP values is done
correctly, subject to the following exceptions:
When using statement-based replication prior to MySQL 5.5.30,
AUTO_INCREMENTcolumns in tables on the slave must match the same columns on the master; that is,AUTO_INCREMENTcolumns must be replicated toAUTO_INCREMENTcolumns. (Bug #12669186)A statement invoking a trigger or function that causes an update to an
AUTO_INCREMENTcolumn is not replicated correctly using statement-based replication. In MySQL 5.5, such statements are marked as unsafe. (Bug #45677)An
INSERTinto a table that has a composite primary key that includes anAUTO_INCREMENTcolumn that is not the first column of this composite key is not safe for statement-based logging or replication. Beginning with MySQL 5.5.25, such statements are marked as unsafe. (Bug #11754117, Bug #45670)This issue does not affect tables using the
InnoDBstorage engine, since anInnoDBtable with an AUTO_INCREMENT column requires at least one key where the auto-increment column is the only or leftmost column.Adding an
AUTO_INCREMENTcolumn to a table withALTER TABLEmight not produce the same ordering of the rows on the slave and the master. This occurs because the order in which the rows are numbered depends on the specific storage engine used for the table and the order in which the rows were inserted. If it is important to have the same order on the master and slave, the rows must be ordered before assigning anAUTO_INCREMENTnumber. Assuming that you want to add anAUTO_INCREMENTcolumn to a tablet1that has columnscol1andcol2, the following statements produce a new tablet2identical tot1but with anAUTO_INCREMENTcolumn:CREATE TABLE t2 LIKE t1; ALTER TABLE t2 ADD id INT AUTO_INCREMENT PRIMARY KEY; INSERT INTO t2 SELECT * FROM t1 ORDER BY col1, col2;
ImportantTo guarantee the same ordering on both master and slave, the
ORDER BYclause must name all columns oft1.The instructions just given are subject to the limitations of
CREATE TABLE ... LIKE: Foreign key definitions are ignored, as are theDATA DIRECTORYandINDEX DIRECTORYtable options. If a table definition includes any of those characteristics, createt2using aCREATE TABLEstatement that is identical to the one used to createt1, but with the addition of theAUTO_INCREMENTcolumn.Regardless of the method used to create and populate the copy having the
AUTO_INCREMENTcolumn, the final step is to drop the original table and then rename the copy:DROP t1; ALTER TABLE t2 RENAME t1;
The BLACKHOLE storage engine
accepts data but discards it and does not store it. When
performing binary logging, all inserts to such tables are always
logged, regardless of the logging format in use. Updates and
deletes are handled differently depending on whether statement
based or row based logging is in use. With the statement based
logging format, all statements affecting
BLACKHOLE tables are logged, but their
effects ignored. When using row-based logging, updates and
deletes to such tables are simply skipped—they are not
written to the binary log. In MySQL 5.5.32 and later, a warning
is logged whenever this occurs (Bug #13004581)
For this reason we recommend when you replicate to tables using
the BLACKHOLE storage engine that
you have the binlog_format
server variable set to STATEMENT, and not to
either ROW or MIXED.
The following applies to replication between MySQL servers that use different character sets:
If the master has databases with a character set different from the global
character_set_servervalue, you should design yourCREATE TABLEstatements so that they do not implicitly rely on the database default character set. A good workaround is to state the character set and collation explicitly inCREATE TABLEstatements.
CHECKSUM TABLE returns a checksum
that is calculated row by row, using a method that depends on
the table row storage format, which is not guaranteed to remain
the same between MySQL release series. For example, the storage
format for temporal types such as
TIME,
DATETIME, and
TIMESTAMP changes in MySQL 5.6
prior to MySQL 5.6.5, so if a 5.5 table is upgraded to MySQL
5.6, the checksum value may change.
MySQL applies these rules when various CREATE ... IF
NOT EXISTS statements are replicated:
Every
CREATE DATABASE IF NOT EXISTSstatement is replicated, whether or not the database already exists on the master.Similarly, every
CREATE TABLE IF NOT EXISTSstatement without aSELECTis replicated, whether or not the table already exists on the master. This includesCREATE TABLE IF NOT EXISTS ... LIKE. Replication ofCREATE TABLE IF NOT EXISTS ... SELECTfollows somewhat different rules; see Section 17.4.1.6, “Replication of CREATE TABLE ... SELECT Statements”, for more information.CREATE EVENT IF NOT EXISTSis always replicated in MySQL 5.5, whether or not the event named in the statement already exists on the master.
See also Bug #45574.
This section discusses how MySQL replicates
CREATE
TABLE ... SELECT statements.
These behaviors are not dependent on MySQL version:
CREATE TABLE ... SELECTalways performs an implicit commit (Section 13.3.3, “Statements That Cause an Implicit Commit”).If destination table does not exist, logging occurs as follows. It does not matter whether
IF NOT EXISTSis present.STATEMENTorMIXEDformat: The statement is logged as written.ROWformat: The statement is logged as aCREATE TABLEstatement followed by a series of insert-row events.
If the statement fails, nothing is logged. This includes the case that the destination table exists and
IF NOT EXISTSis not given.
When the destination table exists and IF NOT
EXISTS is given, MySQL handles the statement in a
version-dependent way.
In MySQL 5.1 before 5.1.51 and in MySQL 5.5 before 5.5.6 (this is the original behavior):
STATEMENTorMIXEDformat: The statement is logged as written.ROWformat: The statement is logged as aCREATE TABLEstatement followed by a series of insert-row events.
In MySQL 5.1 as of 5.1.51:
STATEMENTorMIXEDformat: The statement is logged as the equivalent pair ofCREATE TABLEandINSERT INTO ... SELECTstatements.ROWformat: The statement is logged as aCREATE TABLEstatement followed by a series of insert-row events.
In MySQL 5.5 as of 5.5.6:
Nothing is inserted or logged.
These version dependencies arise due to a change in MySQL 5.5.6
in handling of
CREATE
TABLE ... SELECT not to insert rows if the destination
table already exists, and a change made in MySQL 5.1.51 to
preserve forward compatibility in replication of such statements
from a 5.1 master to a 5.5 slave. For details, see
Section 13.1.17.2, “CREATE TABLE ... SELECT Syntax”.
When using statement-based replication between a MySQL 5.6 or
later slave and a master running a previous version of MySQL, a
CREATE
TABLE ... SELECT statement causing changes in other
tables on the master fails on the slave, causing replication to
stop. This is due to the fact that MySQL 5.6 does not allow a
CREATE
TABLE ... SELECT statement to make any changes in
tables other than the table that is created by the
statement—a change in behavior from previous versions of
MySQL, which permitted these statements to do so. To keep this
from happening, you should use row-based replication, rewrite
the offending statement before running it on the master, or
upgrade the master to MySQL 5.6 (or later). (If you choose to
upgrade the master, keep in mind that such a
CREATE
TABLE ... SELECT statement will fail there as well,
following the upgrade, unless the statement is rewritten to
remove any side effects on other tables.) This is not an issue
when using row-based replication, because the statement is
logged as a CREATE TABLE
statement with any changes to table data logged as row-insert
events (or possibly row-update events), rather than as the
entire
CREATE
TABLE ... SELECT statement.
In MySQL 5.5, the statements
CREATE SERVER,
ALTER SERVER, and
DROP SERVER are not written to
the binary log, regardless of the binary logging format that is
in use.
The following statements support use of the
CURRENT_USER() function to take
the place of the name of (and, possibly, the host for) an
affected user or a definer; in such cases,
CURRENT_USER() is expanded where
and as needed:
When CURRENT_USER() or
CURRENT_USER is used as the
definer in any of the statements CREATE
FUNCTION, CREATE
PROCEDURE, CREATE
TRIGGER, CREATE EVENT,
CREATE VIEW, or
ALTER VIEW when binary logging is
enabled, the function reference is expanded before it is written
to the binary log, so that the statement refers to the same user
on both the master and the slave when the statement is
replicated. CURRENT_USER() or
CURRENT_USER is also expanded
prior to being written to the binary log when used in
DROP USER,
RENAME USER,
GRANT,
REVOKE, or
ALTER EVENT.
The DROP DATABASE
IF EXISTS,
DROP TABLE IF
EXISTS, and
DROP VIEW IF
EXISTS statements are always replicated, even if the
database, table, or view to be dropped does not exist on the
master. This is to ensure that the object to be dropped no
longer exists on either the master or the slave, once the slave
has caught up with the master.
DROP ... IF EXISTS statements for stored
programs (stored procedures and functions, triggers, and events)
are also replicated, even if the stored program to be dropped
does not exist on the master.
Source and target tables for replication do not have to be identical. A table on the master can have more or fewer columns than the slave's copy of the table. In addition, corresponding table columns on the master and the slave can use different data types, subject to certain conditions.
Replication between tables which are partitioned differently from one another is not supported. See Section 17.4.1.19, “Replication and Partitioning”.
In all cases where the source and target tables do not have identical definitions, the database and table names must be the same on both the master and the slave. Additional conditions are discussed, with examples, in the following two sections.
You can replicate a table from the master to the slave such that the master and slave copies of the table have differing numbers of columns, subject to the following conditions:
Columns common to both versions of the table must be defined in the same order on the master and the slave.
(This is true even if both tables have the same number of columns.)
Columns common to both versions of the table must be defined before any additional columns.
This means that executing an
ALTER TABLEstatement on the slave where a new column is inserted into the table within the range of columns common to both tables causes replication to fail, as shown in the following example:Suppose that a table
t, existing on the master and the slave, is defined by the followingCREATE TABLEstatement:CREATE TABLE t ( c1 INT, c2 INT, c3 INT );Suppose that the
ALTER TABLEstatement shown here is executed on the slave:ALTER TABLE t ADD COLUMN cnew1 INT AFTER c3;
The previous
ALTER TABLEis permitted on the slave because the columnsc1,c2, andc3that are common to both versions of tabletremain grouped together in both versions of the table, before any columns that differ.However, the following
ALTER TABLEstatement cannot be executed on the slave without causing replication to break:ALTER TABLE t ADD COLUMN cnew2 INT AFTER c2;
Replication fails after execution on the slave of the
ALTER TABLEstatement just shown, because the new columncnew2comes between columns common to both versions oft.Each “extra” column in the version of the table having more columns must have a default value.
NoteA column's default value is determined by a number of factors, including its type, whether it is defined with a
DEFAULToption, whether it is declared asNULL, and the server SQL mode in effect at the time of its creation; for more information, see Section 11.6, “Data Type Default Values”).
In addition, when the slave's copy of the table has more columns than the master's copy, each column common to the tables must use the same data type in both tables.
Examples. The following examples illustrate some valid and invalid table definitions:
More columns on the master. The following table definitions are valid and replicate correctly:
master>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);slave>CREATE TABLE t1 (c1 INT, c2 INT);
The following table definitions would raise an error because the definitions of the columns common to both versions of the table are in a different order on the slave than they are on the master:
master>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);slave>CREATE TABLE t1 (c2 INT, c1 INT);
The following table definitions would also raise an error because the definition of the extra column on the master appears before the definitions of the columns common to both versions of the table:
master>CREATE TABLE t1 (c3 INT, c1 INT, c2 INT);slave>CREATE TABLE t1 (c1 INT, c2 INT);
More columns on the slave. The following table definitions are valid and replicate correctly:
master>CREATE TABLE t1 (c1 INT, c2 INT);slave>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);
The following definitions raise an error because the columns common to both versions of the table are not defined in the same order on both the master and the slave:
master>CREATE TABLE t1 (c1 INT, c2 INT);slave>CREATE TABLE t1 (c2 INT, c1 INT, c3 INT);
The following table definitions also raise an error because the definition for the extra column in the slave's version of the table appears before the definitions for the columns which are common to both versions of the table:
master>CREATE TABLE t1 (c1 INT, c2 INT);slave>CREATE TABLE t1 (c3 INT, c1 INT, c2 INT);
The following table definitions fail because the slave's
version of the table has additional columns compared to the
master's version, and the two versions of the table use
different data types for the common column
c2:
master>CREATE TABLE t1 (c1 INT, c2 BIGINT);slave>CREATE TABLE t1 (c1 INT, c2 INT, c3 INT);
Corresponding columns on the master's and the slave's copies of the same table ideally should have the same data type. However, beginning with MySQL 5.1.21, this is not always strictly enforced, as long as certain conditions are met.
All other things being equal, it is always possible to
replicate from a column of a given data type to another column
of the same type and same size or width, where applicable, or
larger. For example, you can replicate from a
CHAR(10) column to another
CHAR(10), or from a
CHAR(10) column to a
CHAR(25) column without any problems. In
certain cases, it also possible to replicate from a column
having one data type (on the master) to a column having a
different data type (on the slave); when the data type of the
master's version of the column is promoted to a type that
is the same size or larger on the slave, this is known as
attribute promotion.
Attribute promotion can be used with both statement-based and row-based replication, and is not dependent on the storage engine used by either the master or the slave. However, the choice of logging format does have an effect on the type conversions that are permitted; the particulars are discussed later in this section.
Whether you use statement-based or row-based replication, the slave's copy of the table cannot contain more columns than the master's copy if you wish to employ attribute promotion.
Statement-based replication.
When using statement-based replication, a simple rule of
thumb to follow is, “If the statement run on the
master would also execute successfully on the slave, it
should also replicate successfully”. In other words,
if the statement uses a value that is compatible with the
type of a given column on the slave, the statement can be
replicated. For example, you can insert any value that fits
in a TINYINT column into a
BIGINT column as well; it follows that,
even if you change the type of a TINYINT
column in the slave's copy of a table to
BIGINT, any insert into that column on
the master that succeeds should also succeed on the slave,
since it is impossible to have a legal
TINYINT value that is large enough to
exceed a BIGINT column.
Prior to MySQL 5.5.30, when using statement-based replication,
AUTO_INCREMENT columns were required to be
the same on both the master and the slave; otherwise, updates
could be applied to the wrong table on the slave. (Bug
#12669186)
Row-based replication: attribute promotion and demotion.
Formerly, due to the fact that in row-based replication
changes rather than statements are replicated, and that
these changes are transmitted using formats that do not
always map directly to MySQL server column data types, you
could not replicate between different subtypes of the same
general type (for example, from TINYINT
to BIGINT, both INT
subtypes). However, beginning with MySQL 5.5.3, MySQL
Replication supports attribute promotion and demotion
between smaller data types and larger types. It is also
possible to specify whether or not to permit lossy
(truncated) or non-lossy conversions of demoted column
values, as explained later in this section.
Lossy and non-lossy conversions. In the event that the target type cannot represent the value being inserted, a decision must be made on how to handle the conversion. If we permit the conversion but truncate (or otherwise modify) the source value to achieve a “fit” in the target column, we make what is known as a lossy conversion. A conversion which does not require truncation or similar modifications to fit the source column value in the target column is a non-lossy conversion.
Type conversion modes (slave_type_conversions variable).
The setting of the slave_type_conversions
global server variable controls the type conversion mode
used on the slave. This variable takes a set of values from
the following table, which shows the effects of each mode on
the slave's type-conversion behavior:
| Mode | Effect |
|---|---|
ALL_LOSSY | In this mode, type conversions that would mean loss of information are permitted.
This does not imply that non-lossy conversions are
permitted, merely that only cases requiring either
lossy conversions or no conversion at all are
permitted; for example, enabling
only this mode permits an
|
ALL_NON_LOSSY | This mode permits conversions that do not require truncation or other special handling of the source value; that is, it permits conversions where the target type has a wider range than the source type.
Setting this mode has no bearing on whether lossy
conversions are permitted; this is controlled with
the |
ALL_LOSSY,ALL_NON_LOSSY | When this mode is set, all supported type conversions are permitted, whether or not they are lossy conversions. |
| [empty] |
When This mode is the default. |
Changing the type conversion mode requires restarting the
slave with the new slave_type_conversions
setting.
Supported conversions. Supported conversions between different but similar data types are shown in the following list:
Between any of the integer types
TINYINT,SMALLINT,MEDIUMINT,INT, andBIGINT.This includes conversions between the signed and unsigned versions of these types.
Lossy conversions are made by truncating the source value to the maximum (or minimum) permitted by the target column. For insuring non-lossy conversions when going from unsigned to signed types, the target column must be large enough to accommodate the range of values in the source column. For example, you can demote
TINYINT UNSIGNEDnon-lossily toSMALLINT, but not toTINYINT.Between any of the decimal types
DECIMAL,FLOAT,DOUBLE, andNUMERIC.FLOATtoDOUBLEis a non-lossy conversion;DOUBLEtoFLOATcan only be handled lossily. A conversion fromDECIMAL(toM,D)DECIMAL(whereM',D')D'>=D(-M'-D') >= (MD) are non-lossy; for any case whereM'<MD'<DFor any of the decimal types, if a value to be stored cannot be fit in the target type, the value is rounded down according to the rounding rules defined for the server elsewhere in the documentation. See Section 12.18.4, “Rounding Behavior”, for information about how this is done for decimal types.
Between any of the string types
CHAR,VARCHAR, andTEXT, including conversions between different widths.Conversion of a
CHAR,VARCHAR, orTEXTto aCHAR,VARCHAR, orTEXTcolumn the same size or larger is never lossy. Lossy conversion is handled by inserting only the firstNcharacters of the string on the slave, whereNis the width of the target column.ImportantReplication between columns using different character sets is not supported.
Between any of the binary data types
BINARY,VARBINARY, andBLOB, including conversions between different widths.Conversion of a
BINARY,VARBINARY, orBLOBto aBINARY,VARBINARY, orBLOBcolumn the same size or larger is never lossy. Lossy conversion is handled by inserting only the firstNbytes of the string on the slave, whereNis the width of the target column.Between any 2
BITcolumns of any 2 sizes.When inserting a value from a
BIT(column into aM)BIT(column, whereM')M'>MBIT(columns are cleared (set to zero) and theM')Mbits of theBIT(value are set as the least significant bits of theM)BIT(column.M')When inserting a value from a source
BIT(column into a targetM)BIT(column, whereM')M'<MBIT(column is assigned; in other words, an “all-set” value is assigned to the target column.M')
Conversions between types not in the previous list are not permitted.
Replication type conversions in MySQL 5.5.3 and earlier.
Prior to MySQL 5.5.3, with row-based binary logging, you
could not replicate between different INT
subtypes, such as from TINYINT to
BIGINT, because changes to columns of
these types were represented differently from one another in
the binary log when using row-based logging. (However, you
could replicate from BLOB to
TEXT using row-based replication because
changes to BLOB and
TEXT columns were represented using the
same format in the binary log.)
Supported conversions for attribute promotion when using row-based replication prior to MySQL 5.5.3 are shown in the following table:
| From (Master) | To (Slave) |
|---|---|
BINARY | CHAR |
BLOB | TEXT |
CHAR | BINARY |
DECIMAL | NUMERIC |
NUMERIC | DECIMAL |
TEXT | BLOB |
VARBINARY | VARCHAR |
VARCHAR | VARBINARY |
In all cases, the size or width of the column on the slave
must be equal to or greater than that of the column on the
master. For example, you could replicate from a
CHAR(10) column on the master to a column
that used BINARY(10) or
BINARY(25) on the slave, but you could
not replicate from a CHAR(10) column on
the master to BINARY(5) column on the
slave.
Any unique index (including primary keys) having a prefix must use a prefix of the same length on both master and slave; in such cases, differing prefix lengths are disallowed. It is possible to use a nonunique index whose prefix length differs between master and slave, but this can cause serious performance issues, particularly when the prefix used on the master is longer. This is due to the fact that 2 unique prefixes of a given length may no longer be unique at a shorter length; for example, the words catalogue and catamount have the 5-character prefixes catal and catam, respectively, but share the same 4-character prefix (cata). This can lead to queries that use such indexes executing less efficiently on the slave, when a shorter prefix is employed in the slave' definition of the same index than on the master.
For DECIMAL and
NUMERIC columns, both the
mantissa (M) and the number of decimals
(D) must be the same size or larger on
the slave as compared with the master. For example,
replication from a NUMERIC(5,4) to a
DECIMAL(6,4) worked, but not from a
NUMERIC(5,4) to a
DECIMAL(5,3).
Prior to MySQL 5.5.3, MySQL replication did not support attribute promotion of any of the following data types to or from any other data type when using row-based replication:
If a DATA DIRECTORY or INDEX
DIRECTORY table option is used in a
CREATE TABLE statement on the
master server, the table option is also used on the slave. This
can cause problems if no corresponding directory exists in the
slave host file system or if it exists but is not accessible to
the slave server. This can be overridden by using the
NO_DIR_IN_CREATE server SQL
mode on the slave, which causes the slave to ignore the
DATA DIRECTORY and INDEX
DIRECTORY table options when replicating
CREATE TABLE statements. The
result is that MyISAM data and index files
are created in the table's database directory.
For more information, see Section 5.1.7, “Server SQL Modes”.
Replication of invoked features such as user-defined functions (UDFs) and stored programs (stored procedures and functions, triggers, and events) provides the following characteristics:
The effects of the feature are always replicated.
The following statements are replicated using statement-based replication:
However, the effects of features created, modified, or dropped using these statements are replicated using row-based replication.
NoteAttempting to replicate invoked features using statement-based replication produces the warning Statement is not safe to log in statement format. For example, trying to replicate a UDF with statement-based replication generates this warning because it currently cannot be determined by the MySQL server whether the UDF is deterministic. If you are absolutely certain that the invoked feature's effects are deterministic, you can safely disregard such warnings.
In the case of
CREATE EVENTandALTER EVENT:The status of the event is set to
SLAVESIDE_DISABLEDon the slave regardless of the state specified (this does not apply toDROP EVENT).The master on which the event was created is identified on the slave by its server ID. The
ORIGINATORcolumn inINFORMATION_SCHEMA.EVENTSand theoriginatorcolumn inmysql.eventstore this information. See Section 21.7, “The INFORMATION_SCHEMA EVENTS Table”, and Section 13.7.5.19, “SHOW EVENTS Syntax”, for more information.
The feature implementation resides on the slave in a renewable state so that if the master fails, the slave can be used as the master without loss of event processing.
To determine whether there are any scheduled events on a MySQL
server that were created on a different server (that was acting
as a replication master), query the
INFORMATION_SCHEMA.EVENTS table in
a manner similar to what is shown here:
SELECT EVENT_SCHEMA, EVENT_NAME
FROM INFORMATION_SCHEMA.EVENTS
WHERE STATUS = 'SLAVESIDE_DISABLED';
Alternatively, you can use the SHOW
EVENTS statement, like this:
SHOW EVENTS
WHERE STATUS = 'SLAVESIDE_DISABLED';
When promoting a replication slave having such events to a
replication master, you must enable each event using
ALTER EVENT
, where
event_name ENABLEDevent_name is the name of the event.
If more than one master was involved in creating events on this
slave, and you wish to identify events that were created only on
a given master having the server ID
master_id, modify the previous query
on the EVENTS table to include the
ORIGINATOR column, as shown here:
SELECT EVENT_SCHEMA, EVENT_NAME, ORIGINATOR
FROM INFORMATION_SCHEMA.EVENTS
WHERE STATUS = 'SLAVESIDE_DISABLED'
AND ORIGINATOR = 'master_id'
You can employ ORIGINATOR with the
SHOW EVENTS statement in a
similar fashion:
SHOW EVENTS
WHERE STATUS = 'SLAVESIDE_DISABLED'
AND ORIGINATOR = 'master_id'
Before enabling events that were replicated from the master, you
should disable the MySQL Event Scheduler on the slave (using a
statement such as SET GLOBAL event_scheduler =
OFF;), run any necessary ALTER
EVENT statements, restart the server, then re-enable
the Event Scheduler on the slave afterward (using a statement
such as SET GLOBAL event_scheduler = ON;)-
If you later demote the new master back to being a replication
slave, you must disable manually all events enabled by the
ALTER EVENT statements. You can
do this by storing in a separate table the event names from the
SELECT statement shown
previously, or using ALTER EVENT
statements to rename the events with a common prefix such as
replicated_ to identify them.
If you rename the events, then when demoting this server back to
being a replication slave, you can identify the events by
querying the EVENTS table, as shown
here:
SELECT CONCAT(EVENT_SCHEMA, '.', EVENT_NAME) AS 'Db.Event'
FROM INFORMATION_SCHEMA.EVENTS
WHERE INSTR(EVENT_NAME, 'replicated_') = 1;
With statement-based replication, values are converted from decimal to binary. Because conversions between decimal and binary representations of them may be approximate, comparisons involving floating-point values are inexact. This is true for operations that use floating-point values explicitly, or that use values that are converted to floating-point implicitly. Comparisons of floating-point values might yield different results on master and slave servers due to differences in computer architecture, the compiler used to build MySQL, and so forth. See Section 12.2, “Type Conversion in Expression Evaluation”, and Section B.5.4.8, “Problems with Floating-Point Values”.
Some forms of the FLUSH statement
are not logged because they could cause problems if replicated
to a slave: FLUSH
LOGS, FLUSH
MASTER, FLUSH
SLAVE, and
FLUSH TABLES WITH READ
LOCK. For a syntax example, see
Section 13.7.6.3, “FLUSH Syntax”. The
FLUSH TABLES,
ANALYZE TABLE,
OPTIMIZE TABLE, and
REPAIR TABLE statements are
written to the binary log and thus replicated to slaves. This is
not normally a problem because these statements do not modify
table data.
However, this behavior can cause difficulties under certain
circumstances. If you replicate the privilege tables in the
mysql database and update those tables
directly without using GRANT, you
must issue a FLUSH
PRIVILEGES on the slaves to put the new privileges
into effect. In addition, if you use
FLUSH TABLES
when renaming a MyISAM table that is part of
a MERGE table, you must issue
FLUSH TABLES
manually on the slaves. These statements are written to the
binary log unless you specify
NO_WRITE_TO_BINLOG or its alias
LOCAL.
Certain functions do not replicate well under some conditions:
The
USER(),CURRENT_USER()(orCURRENT_USER),UUID(),VERSION(), andLOAD_FILE()functions are replicated without change and thus do not work reliably on the slave unless row-based replication is enabled. (See Section 17.1.2, “Replication Formats”.)USER()andCURRENT_USER()are automatically replicated using row-based replication when usingMIXEDmode, and generate a warning inSTATEMENTmode. (Bug #28086) (See also Section 17.4.1.8, “Replication of CURRENT_USER()”.)Beginning with MySQL 5.5.1,
VERSION()is also automatically replicated using row-based replication when usingMIXEDmode, and generates a warning inSTATEMENTmode. (Bug #47995) Beginning with MySQL 5.5.2, this is also true with regard to theRAND()function. (Bug #49222)For
NOW(), the binary log includes the timestamp. This means that the value as returned by the call to this function on the master is replicated to the slave. This can lead to a possibly unexpected result when replicating between MySQL servers in different time zones. Suppose that the master is located in New York, the slave is located in Stockholm, and both servers are using local time. Suppose further that, on the master, you create a tablemytable, perform anINSERTstatement on this table, and then select from the table, as shown here:mysql>
CREATE TABLE mytable (mycol TEXT);Query OK, 0 rows affected (0.06 sec) mysql>INSERT INTO mytable VALUES ( NOW() );Query OK, 1 row affected (0.00 sec) mysql>SELECT * FROM mytable;+---------------------+ | mycol | +---------------------+ | 2009-09-01 12:00:00 | +---------------------+ 1 row in set (0.00 sec)Local time in Stockholm is 6 hours later than in New York; so, if you issue
SELECT NOW()on the slave at that exact same instant, the value2009-09-01 18:00:00is returned. For this reason, if you select from the slave's copy ofmytableafter theCREATE TABLEandINSERTstatements just shown have been replicated, you might expectmycolto contain the value2009-09-01 18:00:00. However, this is not the case; when you select from the slave's copy ofmytable, you obtain exactly the same result as on the master:mysql>
SELECT * FROM mytable;+---------------------+ | mycol | +---------------------+ | 2009-09-01 12:00:00 | +---------------------+ 1 row in set (0.00 sec)Unlike
NOW(), theSYSDATE()function is not replication-safe because it is not affected bySET TIMESTAMPstatements in the binary log and is nondeterministic if statement-based logging is used. This is not a problem if row-based logging is used.An alternative is to use the
--sysdate-is-nowoption to causeSYSDATE()to be an alias forNOW(). This must be done on the master and the slave to work correctly. In such cases, a warning is still issued by this function, but can safely be ignored as long as--sysdate-is-nowis used on both the master and the slave.Beginning with MySQL 5.5.1,
SYSDATE()is automatically replicated using row-based replication when usingMIXEDmode, and generates a warning inSTATEMENTmode. (Bug #47995)The following restriction applies to statement-based replication only, not to row-based replication. The
GET_LOCK(),RELEASE_LOCK(),IS_FREE_LOCK(), andIS_USED_LOCK()functions that handle user-level locks are replicated without the slave knowing the concurrency context on the master. Therefore, these functions should not be used to insert into a master table because the content on the slave would differ. For example, do not issue a statement such asINSERT INTO mytable VALUES(GET_LOCK(...)).Beginning with MySQL 5.5.1, these functions are automatically replicated using row-based replication when using
MIXEDmode, and generate a warning inSTATEMENTmode. (Bug #47995)
As a workaround for the preceding limitations when
statement-based replication is in effect, you can use the
strategy of saving the problematic function result in a user
variable and referring to the variable in a later statement. For
example, the following single-row
INSERT is problematic due to the
reference to the UUID() function:
INSERT INTO t VALUES(UUID());
To work around the problem, do this instead:
SET @my_uuid = UUID(); INSERT INTO t VALUES(@my_uuid);
That sequence of statements replicates because the value of
@my_uuid is stored in the binary log as a
user-variable event prior to the
INSERT statement and is available
for use in the INSERT.
The same idea applies to multiple-row inserts, but is more cumbersome to use. For a two-row insert, you can do this:
SET @my_uuid1 = UUID(); @my_uuid2 = UUID(); INSERT INTO t VALUES(@my_uuid1),(@my_uuid2);
However, if the number of rows is large or unknown, the workaround is difficult or impracticable. For example, you cannot convert the following statement to one in which a given individual user variable is associated with each row:
INSERT INTO t2 SELECT UUID(), * FROM t1;
Within a stored function, RAND()
replicates correctly as long as it is invoked only once during
the execution of the function. (You can consider the function
execution timestamp and random number seed as implicit inputs
that are identical on the master and slave.)
The FOUND_ROWS() and
ROW_COUNT() functions are not
replicated reliably using statement-based replication. A
workaround is to store the result of the function call in a user
variable, and then use that in the
INSERT statement. For example, if
you wish to store the result in a table named
mytable, you might normally do so like this:
SELECT SQL_CALC_FOUND_ROWS FROM mytable LIMIT 1; INSERT INTO mytable VALUES( FOUND_ROWS() );
However, if you are replicating mytable, you
should use SELECT
... INTO, and then store the variable in the table,
like this:
SELECT SQL_CALC_FOUND_ROWS INTO @found_rows FROM mytable LIMIT 1; INSERT INTO mytable VALUES(@found_rows);
In this way, the user variable is replicated as part of the context, and applied on the slave correctly.
These functions are automatically replicated using row-based
replication when using MIXED mode, and
generate a warning in STATEMENT mode. (Bug
#12092, Bug #30244)
Prior to MySQL 5.5.35, the value of
LAST_INSERT_ID() was not
replicated correctly if any filtering options such as
--replicate-ignore-db and
--replicate-do-table were enabled
on the slave. (Bug #17234370, BUG# 69861)
Statement-based replication of LIMIT clauses
in DELETE,
UPDATE, and
INSERT ...
SELECT statements is unsafe since the order of the
rows affected is not defined. (Such statements can be replicated
correctly with statement-based replication only if they also
contain an ORDER BY clause.) When such a
statement is encountered:
When using
STATEMENTmode, a warning that the statement is not safe for statement-based replication is now issued.When using
STATEMENTmode, warnings are issued for DML statements containingLIMITeven when they also have anORDER BYclause (and so are made deterministic). This is a known issue. (Bug #42851)When using
MIXEDmode, the statement is now automatically replicated using row-based mode.
In MySQL 5.5.6 and later,
LOAD DATA
INFILE is considered unsafe (see
Section 17.1.2.3, “Determination of Safe and Unsafe Statements in Binary Logging”). It causes a
warning when using statement-based logging format, and is logged
using row-based format when using mixed-format logging.
In older versions of MySQL, replication slaves did not write replicated queries to the slow query log, even if the same queries were written to the slow query log on the master. This is no longer an issue in MySQL 5.5. (Bug #23300)
Replication is supported between partitioned tables as long as they use the same partitioning scheme and otherwise have the same structure except where an exception is specifically allowed (see Section 17.4.1.10, “Replication with Differing Table Definitions on Master and Slave”).
Replication between tables having different partitioning is
generally not supported. This because statements (such as
ALTER
TABLE ... DROP PARTITION) acting directly on
partitions in such cases may produce different results on master
and slave. In the case where a table is partitioned on the
master but not on the slave, any statements operating on
partitions on the master's copy of the slave fail on the
slave. When the slave's copy of the table is partitioned
but the master's copy is not, statements acting on
partitions cannot be run on the master without causing errors
there.
Due to these dangers of causing replication to fail entirely (on account of failed statements) and of inconsistencies (when the result of a partition-level SQL statement produces different results on master and slave), we recommend that insure that the partitioning of any tables to be replicated from the master is matched by the slave's versions of these tables.
When used on a corrupted or otherwise damaged table, it is
possible for the REPAIR TABLE
statement to delete rows that cannot be recovered. However, any
such modifications of table data performed by this statement are
not replicated, which can cause master and slave to lose
synchronization. For this reason, in the event that a table on
the master becomes damaged and you use
REPAIR TABLE to repair it, you
should first stop replication (if it is still running) before
using REPAIR TABLE, then
afterward compare the master's and slave's copies of
the table and be prepared to correct any discrepancies manually,
before restarting replication.
It is safe to shut down a master server and restart it later.
When a slave loses its connection to the master, the slave tries
to reconnect immediately and retries periodically if that fails.
The default is to retry every 60 seconds. This may be changed
with the CHANGE MASTER TO
statement. A slave also is able to deal with network
connectivity outages. However, the slave notices the network
outage only after receiving no data from the master for
slave_net_timeout seconds. If
your outages are short, you may want to decrease
slave_net_timeout. See
Section 5.1.4, “Server System Variables”.
An unclean shutdown (for example, a crash) on the master side
can result in the master binary log having a final position less
than the most recent position read by the slave, due to the
master binary log file not being flushed. This can cause the
slave not to be able to replicate when the master comes back up.
Setting sync_binlog=1 in the
master my.cnf file helps to minimize this
problem because it causes the master to flush its binary log
more frequently.
Shutting down a slave cleanly is safe because it keeps track of where it left off. However, be careful that the slave does not have temporary tables open; see Section 17.4.1.24, “Replication and Temporary Tables”. Unclean shutdowns might produce problems, especially if the disk cache was not flushed to disk before the problem occurred:
For transactions, the slave commits and then updates
relay-log.info. If a crash occurs between these two operations, relay log processing will have proceeded further than the information file indicates and the slave will re-execute the events from the last transaction in the relay log after it has been restarted.A similar problem can occur if the slave updates
relay-log.infobut the server host crashes before the write has been flushed to disk. To minimize the chance of this occurring, setsync_relay_log_info=1in the slavemy.cnffile. The default value ofsync_relay_log_infois 0, which does not cause writes to be forced to disk; the server relies on the operating system to flush the file from time to time.
The fault tolerance of your system for these types of problems is greatly increased if you have a good uninterruptible power supply.
max_allowed_packet sets an
upper limit on the size of any single message between the MySQL
server and clients, including replication slaves. If you are
replicating large column values (such as might be found in
TEXT or
BLOB columns) and
max_allowed_packet is too small
on the master, the master fails with an error, and the slave
shuts down the I/O thread. If
max_allowed_packet is too small
on the slave, this also causes the slave to stop the I/O thread.
Row-based replication currently sends all columns and column
values for updated rows from the master to the slave, including
values of columns that were not actually changed by the update.
This means that, when you are replicating large column values
using row-based replication, you must take care to set
max_allowed_packet large enough
to accommodate the largest row in any table to be replicated,
even if you are replicating updates only, or you are inserting
only relatively small values.
When a master server shuts down and restarts, its
MEMORY tables become empty. To
replicate this effect to slaves, the first time that the master
uses a given MEMORY table after
startup, it logs an event that notifies slaves that the table
must to be emptied by writing a
DELETE statement for that table
to the binary log.
When a slave server shuts down and restarts, its
MEMORY tables become empty. This
causes the slave to be out of synchrony with the master and may
lead to other failures or cause the slave to stop:
Row-format updates and deletes received from the master may fail with
Can't find record in '.memory_table'Statements such as
INSERT INTO ... SELECT FROMmay insert a different set of rows on the master and slave.memory_table
The safe way to restart a slave that is replicating
MEMORY tables is to first drop or
delete all rows from the MEMORY
tables on the master and wait until those changes have
replicated to the slave. Then it is safe to restart the slave.
An alternative restart method may apply in some cases. When
binlog_format=ROW, you can
prevent the slave from stopping if you set
slave_exec_mode=IDEMPOTENT
before you start the slave again. This allows the slave to
continue to replicate, but its
MEMORY tables will still be
different from those on the master. This can be okay if the
application logic is such that the contents of
MEMORY tables can be safely lost
(for example, if the MEMORY tables
are used for caching).
slave_exec_mode=IDEMPOTENT
applies globally to all tables, so it may hide other replication
errors in non-MEMORY tables.
(The method just described is not applicable in MySQL Cluster,
where slave_exec_mode is always
IDEMPOTENT, and cannot be changed.)
The size of MEMORY tables is
limited by the value of the
max_heap_table_size system
variable, which is not replicated (see
Section 17.4.1.38, “Replication and Variables”). A change in
max_heap_table_size takes effect for
MEMORY tables that are created or updated
using ALTER TABLE
... ENGINE = MEMORY or TRUNCATE
TABLE following the change, or for all
MEMORY tables following a server
restart. If you increase the value of this variable on the
master without doing so on the slave, it becomes possible for a
table on the master to grow larger than its counterpart on the
slave, leading to inserts that succeed on the master but fail on
the slave with Table is full errors. This
is a known issue (Bug #48666). In such cases, you must set the
global value of
max_heap_table_size on the
slave as well as on the master, then restart replication. It is
also recommended that you restart both the master and slave
MySQL servers, to insure that the new value takes complete
(global) effect on each of them.
See Section 15.4, “The MEMORY Storage Engine”, for more
information about MEMORY tables.
The discussion in the following paragraphs does not apply when
binlog_format=ROW because, in
that case, temporary tables are not replicated; this means that
there are never any temporary tables on the slave to be lost in
the event of an unplanned shutdown by the slave. The remainder
of this section applies only when using statement-based or
mixed-format replication. Loss of replicated temporary tables on
the slave can be an issue, whenever
binlog_format is
STATEMENT or MIXED, for
statements involving temporary tables that can be logged safely
using statement-based format. For more information about
row-based replication and temporary tables, see
RBL, RBR, and temporary tables.
Safe slave shutdown when using temporary tables. Temporary tables are replicated except in the case where you stop the slave server (not just the slave threads) and you have replicated temporary tables that are open for use in updates that have not yet been executed on the slave. If you stop the slave server, the temporary tables needed by those updates are no longer available when the slave is restarted. To avoid this problem, do not shut down the slave while it has temporary tables open. Instead, use the following procedure:
Issue a
STOP SLAVE SQL_THREADstatement.Use
SHOW STATUSto check the value of theSlave_open_temp_tablesvariable.If the value is not 0, restart the slave SQL thread with
START SLAVE SQL_THREADand repeat the procedure later.When the value is 0, issue a mysqladmin shutdown command to stop the slave.
Temporary tables and replication options.
By default, all temporary tables are replicated; this happens
whether or not there are any matching
--replicate-do-db,
--replicate-do-table, or
--replicate-wild-do-table
options in effect. However, the
--replicate-ignore-table and
--replicate-wild-ignore-table
options are honored for temporary tables.
A recommended practice when using statement-based or
mixed-format replication is to designate a prefix for exclusive
use in naming temporary tables that you do not want replicated,
then employ a
--replicate-wild-ignore-table
option to match that prefix. For example, you might give all
such tables names beginning with norep (such
as norepmytable,
norepyourtable, and so on), then use
--replicate-wild-ignore-table=norep%
to prevent them from being replicated.
Data modification statements made to tables in the
mysql database are replicated according to
the value of binlog_format; if
this value is MIXED, these statements are
replicated using row-based format. However, statements that
would normally update this information indirectly—such
GRANT,
REVOKE, and statements
manipulating triggers, stored routines, and views—are
replicated to slaves using statement-based replication.
It is possible for the data on the master and slave to become
different if a statement is written in such a way that the data
modification is nondeterministic; that is, left up the query
optimizer. (In general, this is not a good practice, even
outside of replication.) Examples of nondeterministic statements
include DELETE or
UPDATE statements that use
LIMIT with no ORDER BY
clause; see Section 17.4.1.16, “Replication and LIMIT”, for a
detailed discussion of these.
You can encounter problems when you attempt to replicate from an
older master to a newer slave and you make use of identifiers on
the master that are reserved words in the newer MySQL version
running on the slave. An example of this is using a table column
named range on a 5.0 master that is
replicating to a 5.1 or higher slave because
RANGE is a reserved word beginning in MySQL
5.1. Replication can fail in such cases with Error 1064
You have an error in your SQL syntax...,
even if a database or table named using the reserved
word or a table having a column named using the reserved word is
excluded from replication. This is due to the fact
that each SQL event must be parsed by the slave prior to
execution, so that the slave knows which database object or
objects would be affected; only after the event is parsed can
the slave apply any filtering rules defined by
--replicate-do-db,
--replicate-do-table,
--replicate-ignore-db, and
--replicate-ignore-table.
To work around the problem of database, table, or column names on the master which would be regarded as reserved words by the slave, do one of the following:
Use one or more
ALTER TABLEstatements on the master to change the names of any database objects where these names would be considered reserved words on the slave, and change any SQL statements that use the old names to use the new names instead.In any SQL statements using these database object names, write the names as quoted identifiers using backtick characters (
`).
For listings of reserved words by MySQL version, see Reserved Words, in the MySQL Server Version Reference. For identifier quoting rules, see Section 9.2, “Schema Object Names”.
Row-based replication of SET
PASSWORD statements from a MySQL 5.1 master to a MySQL
5.5 slave did not work correctly prior to MySQL 5.1.53 on the
master and MySQL 5.5.7 on the slave (see Bug #57098, Bug
#57357).
If a statement produces the same error (identical error code) on both the master and the slave, the error is logged, but replication continues.
If a statement produces different errors on the master and the
slave, the slave SQL thread terminates, and the slave writes a
message to its error log and waits for the database
administrator to decide what to do about the error. This
includes the case that a statement produces an error on the
master or the slave, but not both. To address the issue, connect
to the slave manually and determine the cause of the problem.
SHOW SLAVE STATUS is useful for
this. Then fix the problem and run START
SLAVE. For example, you might need to create a
nonexistent table before you can start the slave again.
If this error code validation behavior is not desirable, some or
all errors can be masked out (ignored) with the
--slave-skip-errors option.
For nontransactional storage engines such as
MyISAM, it is possible to have a statement
that only partially updates a table and returns an error code.
This can happen, for example, on a multiple-row insert that has
one row violating a key constraint, or if a long update
statement is killed after updating some of the rows. If that
happens on the master, the slave expects execution of the
statement to result in the same error code. If it does not, the
slave SQL thread stops as described previously.
If you are replicating between tables that use different storage
engines on the master and slave, keep in mind that the same
statement might produce a different error when run against one
version of the table, but not the other, or might cause an error
for one version of the table, but not the other. For example,
since MyISAM ignores foreign key constraints,
an INSERT or
UPDATE statement accessing an
InnoDB table on the master might cause a
foreign key violation but the same statement performed on a
MyISAM version of the same table on the slave
would produce no such error, causing replication to stop.
The server maintains tables in the mysql
database that store information for the
HELP statement (see
Section 13.8.3, “HELP Syntax”. These tables can be loaded manually as
described at Section 5.1.10, “Server-Side Help”.
Help table content is derived from the MySQL Reference Manual. There are versions of the manual specific to each MySQL release series, so help content is specific to each series as well. Normally, you load a version of help content that matches the server version. This has implications for replication. For example, you would load MySQL 5.5 help content into a MySQL 5.5 master server, but not necessarily replicate that content to a MySQL 5.6 slave server for which 5.6 help content is more appropriate.
This section describes how to manage help table content upgrades when your servers participate in replication. Server versions are one factor in this task. Another is that help table structure may differ between the master and the slave.
Assume that help content is stored in a file named
fill_help_tables.sql. In MySQL
distributions, this file is located under the
share or share/mysql
directory, and the most recent version is always available for
download from http://dev.mysql.com/doc/index-other.html.
To upgrade help tables, using the following procedure.
Connection parameters are not shown for the
mysql commands discussed here; in all cases,
connect to the server using an account such as
root that has privileges for modifying tables
in the mysql database.
Upgrade your servers by running mysql_upgrade, first on the slaves and then on the master. This is the usual principle of upgrading slaves first.
Decide whether you want to replicate help table content from the master to its slaves. If not, load the content on the master and each slave individually. Otherwise, check for and resolve any incompatibilities between help table structure on the master and its slaves, then load the content into the master and let it replicate to the slaves.
More detail about these two methods of loading help table content follows.
Loading Help Table Content Without Replication to Slaves
To load help table content without replication, run this command
on the master and each slave individually, using a
fill_help_tables.sql file containing
content appropriate to the server version (enter the command on
one line):
mysql --init-command="SET sql_log_bin=0" mysql < fill_help_tables.sql
Use the --init-command option on
each server, including the slaves, in case a slave also acts as
a master to other slaves in your replication topology. The
SET statement suppresses binary logging.
After the command has been run on each server to be upgraded,
you are done.
Loading Help Table Content With Replication to Slaves
If you do want to replicate help table content, check for help
table incompatibilities between your master and its slaves. The
url column in the
help_category and
help_topic tables was originally
CHAR(128), but is TEXT in
newer MySQL versions to accommodate longer URLs. To check help
table structure, use this statement:
SELECT TABLE_NAME, COLUMN_NAME, COLUMN_TYPE FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA = 'mysql' AND COLUMN_NAME = 'url';
For tables with the old structure, the statement produces this result:
+---------------+-------------+-------------+ | TABLE_NAME | COLUMN_NAME | COLUMN_TYPE | +---------------+-------------+-------------+ | help_category | url | char(128) | | help_topic | url | char(128) | +---------------+-------------+-------------+
For tables with the new structure, the statement produces this result:
+---------------+-------------+-------------+ | TABLE_NAME | COLUMN_NAME | COLUMN_TYPE | +---------------+-------------+-------------+ | help_category | url | text | | help_topic | url | text | +---------------+-------------+-------------+
If the master and slave both have the old structure or both have the new structure, they are compatible and you can replicate help table content by executing this command on the master:
mysql mysql < fill_help_tables.sql
The table content will load into the master, then replicate to the slaves.
If the master and slave have incompatible help tables (one server has the old structure and the other has the new), you have a choice between not replicating help table content after all, or making the table structures compatible so that you can replicate the content.
If you decide not to replicate the content after all, upgrade the master and slaves individually using mysql with the
--init-commandoption, as described previously.If instead you decide to make the table structures compatible, upgrade the tables on the server that has the old structure. Suppose that your master server has the old table structure. Upgrade its tables to the new structure manually by executing these statements (binary logging is disabled here to prevent replication of the changes to the slaves, which already have the new structure):
SET sql_log_bin=0; ALTER TABLE mysql.help_category ALTER COLUMN url TEXT; ALTER TABLE mysql.help_topic ALTER COLUMN url TEXT;
Then run this command on the master:
mysql mysql < fill_help_tables.sql
The table content will load into the master, then replicate to the slaves.
Using different server SQL mode settings on the master and the
slave may cause the same INSERT
statements to be handled differently on the master and the
slave, leading the master and slave to diverge. For best
results, you should always use the same server SQL mode on the
master and on the slave. This advice applies whether you are
using statement-based or row-based replication.
If you are replicating partitioned tables, using different SQL modes on the master and the slave is likely to cause issues. At a minimum, this is likely to cause the distribution of data among partitions to be different in the master's and slave's copies of a given table. It may also cause inserts into partitioned tables that succeed on the master to fail on the slave.
For more information, see Section 5.1.7, “Server SQL Modes”.
The global system variable
slave_transaction_retries
affects replication as follows: If the slave SQL thread fails to
execute a transaction because of an InnoDB
deadlock or because it exceeded the InnoDB
innodb_lock_wait_timeout value,
or the NDBCLUSTER
TransactionDeadlockDetectionTimeout or
TransactionInactiveTimeout value, the slave
automatically retries the transaction
slave_transaction_retries times
before stopping with an error. The default value is 10. The
total retry count can be seen in the output of
SHOW STATUS; see
Section 5.1.6, “Server Status Variables”.
Older versions of MySQL (prior to 4.1) differed significantly in
several ways in their handling of the
TIMESTAMP data type from what is
supported in MySQL versions 5.5 and newer; these
include syntax extensions which are deprecated in MySQL 5.1, and
that no longer supported in MySQL 5.5. This can cause problems
(including replication failures) when replicating between MySQL
Server versions, if you are using columns that are defined using
the old TIMESTAMP(N) syntax. See
Section 2.11.1.1, “Changes Affecting Upgrades to 5.5”, for more
information about the differences, how they can impact MySQL
replication, and what you can do if you encounter such problems.
The same system time zone should be set for both master and
slave. Otherwise, statements depending on the local time on the
master are not replicated properly, such as statements that use
the NOW() or
FROM_UNIXTIME() functions. You
can set the time zone in which MySQL server runs by using the
--timezone=
option of the timezone_namemysqld_safe script or by
setting the TZ environment variable. See also
Section 17.4.1.15, “Replication and System Functions”.
Mixing transactional and nontransactional statements within the same transaction. In general, you should avoid transactions that update both transactional and nontransactional tables in a replication environment. You should also avoid using any statement that accesses both transactional (or temporary) and nontransactional tables and writes to any of them.
As of MySQL 5.5.2, the server uses these rules for binary logging:
If the initial statements in a transaction are nontransactional, they are written to the binary log immediately. The remaining statements in the transaction are cached and not written to the binary log until the transaction is committed. (If the transaction is rolled back, the cached statements are written to the binary log only if they make nontransactional changes that cannot be rolled back. Otherwise, they are discarded.)
For statement-based logging, logging of nontransactional statements is affected by the
binlog_direct_non_transactional_updatessystem variable. When this variable isOFF(the default), logging is as just described. When this variable isON, logging occurs immediately for nontransactional statements occurring anywhere in the transaction (not just initial nontransactional statements). Other statements are kept in the transaction cache and logged when the transaction commits.binlog_direct_non_transactional_updateshas no effect for row-format or mixed-format binary logging.
Transactional, nontransactional, and mixed statements. To apply those rules, the server considers a statement nontransactional if it changes only nontransactional tables, and transactional if it changes only transactional tables. Prior to MySQL 5.5.6, a statement that changed both nontransactional and transactional tables was considered “mixed”. Beginning with MySQL 5.5.6, a statement that references both nontransactional and transactional tables and updates any of the tables involved, is considered a mixed statement. Mixed statements, like transactional statements, are cached and logged when the transaction commits.
Beginning with MySQL 5.5.6, a mixed statement that updates a transactional table is considered unsafe if the statement also performs either of the following actions:
Updates or reads a transactional table
Reads a nontransactional table and the transaction isolation level is less than REPEATABLE_READ
Also beginning with MySQL 5.5.6, any mixed statement following the update of a transactional table within a transaction is considered unsafe if it performs either of the following actions:
Updates any table and reads from any temporary table
Updates a nontransactional table and binlog_direct_non_trans_update is OFF
For more information, see Section 17.1.2.3, “Determination of Safe and Unsafe Statements in Binary Logging”.
A mixed statement is unrelated to mixed binary logging format.
Before MySQL 5.5.2, the rules for binary logging are similar to
those just described, except that there is no
binlog_direct_non_transactional_updates
system variable to affect logging of transactional statements.
Thus, the server immediately logs only the initial
nontransactional statements in a transaction and caches the rest
until commit time.
In situations where transactions mix updates to transactional
and nontransactional tables, the order of statements in the
binary log is correct, and all needed statements are written to
the binary log even in case of a
ROLLBACK.
However, when a second connection updates the nontransactional
table before the first connection transaction is complete,
statements can be logged out of order because the second
connection update is written immediately after it is performed,
regardless of the state of the transaction being performed by
the first connection.
Using different storage engines on master and slave.
It is possible to replicate transactional tables on the master
using nontransactional tables on the slave. For example, you
can replicate an InnoDB master table as a
MyISAM slave table. However, if you do
this, there are problems if the slave is stopped in the middle
of a BEGIN
... COMMIT block because the
slave restarts at the beginning of the
BEGIN block.
Beginning with MySQL 5.5.0, it is also safe to replicate
transactions from MyISAM tables on
the master to transactional tables—such as tables that use
the InnoDB storage engine—on
the slave. In such cases (beginning with MySQL 5.5.0), an
AUTOCOMMIT=1
statement issued on the master is replicated, thus enforcing
AUTOCOMMIT mode on the slave.
When the storage engine type of the slave is nontransactional, transactions on the master that mix updates of transactional and nontransactional tables should be avoided because they can cause inconsistency of the data between the master transactional table and the slave nontransactional table. That is, such transactions can lead to master storage engine-specific behavior with the possible effect of replication going out of synchrony. MySQL does not issue a warning about this currently, so extra care should be taken when replicating transactional tables from the master to nontransactional tables on the slaves.
Changing the binary logging format within transactions.
Beginning with MySQL 5.5.3, the
binlog_format system variable
is read-only as long as a transaction is in progress. (Bug
#47863)
Every transaction (including
autocommit transactions) is
recorded in the binary log as though it starts with a
BEGIN
statement, and ends with either a
COMMIT or a
ROLLBACK
statement. In MySQL 5.5, this true is even for
statements affecting tables that use a nontransactional storage
engine (such as MyISAM).
With statement-based replication, triggers executed on the master also execute on the slave. With row-based replication, triggers executed on the master do not execute on the slave. Instead, the row changes on the master resulting from trigger execution are replicated and applied on the slave.
This behavior is by design. If under row-based replication the slave applied the triggers as well as the row changes caused by them, the changes would in effect be applied twice on the slave, leading to different data on the master and the slave.
If you want triggers to execute on both the master and the slave—perhaps because you have different triggers on the master and slave—you must use statement-based replication. However, to enable slave-side triggers, it is not necessary to use statement-based replication exclusively. It is sufficient to switch to statement-based replication only for those statements where you want this effect, and to use row-based replication the rest of the time.
A statement invoking a trigger (or function) that causes an
update to an AUTO_INCREMENT column is not
replicated correctly using statement-based replication. MySQL
5.5 marks such statements as unsafe. (Bug #45677)
TRUNCATE TABLE is normally
regarded as a DML statement, and so would be expected to be
logged and replicated using row-based format when the binary
logging mode is ROW or
MIXED. However this caused issues when
logging or replicating, in STATEMENT or
MIXED mode, tables that used transactional
storage engines such as InnoDB when
the transaction isolation level was READ
COMMITTED or READ UNCOMMITTED,
which precludes statement-based logging.
TRUNCATE TABLE is treated for
purposes of logging and replication as DDL rather than DML so
that it can be logged and replicated as a statement. However,
the effects of the statement as applicable to
InnoDB and other transactional
tables on replication slaves still follow the rules described in
Section 13.1.33, “TRUNCATE TABLE Syntax” governing such tables. (Bug
#36763)
System variables are not replicated correctly when using
STATEMENT mode, except for the following
variables when they are used with session scope:
When MIXED mode is used, the variables in the
preceding list, when used with session scope, cause a switch
from statement-based to row-based logging. See
Section 5.2.4.3, “Mixed Binary Logging Format”.
sql_mode is also replicated
except for the
NO_DIR_IN_CREATE mode; the
slave always preserves its own value for
NO_DIR_IN_CREATE, regardless
of changes to it on the master. This is true for all replication
formats.
However, when mysqlbinlog parses a
SET @@sql_mode =
statement, the full
modemode value, including
NO_DIR_IN_CREATE, is passed to
the receiving server. For this reason, replication of such a
statement may not be safe when STATEMENT mode
is in use.
The default_storage_engine and
storage_engine system variables
are not replicated, regardless of the logging mode; this is
intended to facilitate replication between different storage
engines.
The read_only system variable
is not replicated. In addition, the enabling this variable has
different effects with regard to temporary tables, table
locking, and the SET PASSWORD
statement in different MySQL versions.
The max_heap_table_size system
variable is not replicated. Increasing the value of this
variable on the master without doing so on the slave can lead
eventually to Table is full errors on the
slave when trying to execute
INSERT statements on a
MEMORY table on the master that is
thus permitted to grow larger than its counterpart on the slave.
For more information, see
Section 17.4.1.23, “Replication and MEMORY Tables”.
In statement-based replication, session variables are not replicated properly when used in statements that update tables. For example, the following sequence of statements will not insert the same data on the master and the slave:
SET max_join_size=1000; INSERT INTO mytable VALUES(@@max_join_size);
This does not apply to the common sequence:
SET time_zone=...; INSERT INTO mytable VALUES(CONVERT_TZ(..., ..., @@time_zone));
Replication of session variables is not a problem when row-based replication is being used, in which case, session variables are always replicated safely. See Section 17.1.2, “Replication Formats”.
In MySQL 5.5, the following session variables are written to the binary log and honored by the replication slave when parsing the binary log, regardless of the logging format:
Even though session variables relating to character sets and collations are written to the binary log, replication between different character sets is not supported.
It is strongly recommended that you always use the same setting
for the lower_case_table_names
system variable on both master and slave. In particular, when a
case-sensitive file system is used, setting this variable to 1
on the slave, but to a different value on the master, can cause
two types of problems: Names of databases are not converted to
lowercase; in addition, when using row-based replication names
of tables are also not converted. Either of these problems can
cause replication to fail. This is a known issue, which is fixed
in MySQL 5.6.
Views are always replicated to slaves. Views are filtered by
their own name, not by the tables they refer to. This means that
a view can be replicated to the slave even if the view contains
a table that would normally be filtered out by
replication-ignore-table rules. Care should
therefore be taken to ensure that views do not replicate table
data that would normally be filtered for security reasons.
Replication from a table to a samed-named view is supported using statement-based logging, but not when using row-based logging. In MySQL 5.5.31 and later, trying to do so when row-based logging is in effect causes an error. (Bug #11752707, Bug #43975)
MySQL supports replication from one release series to the next higher release series. For example, you can replicate from a master running MySQL 5.1 to a slave running MySQL 5.5, from a master running MySQL 5.5 to a slave running MySQL 5.6, and so on.
However, one may encounter difficulties when replicating from an
older master to a newer slave if the master uses statements or
relies on behavior no longer supported in the version of MySQL
used on the slave. For example, in MySQL 5.5,
CREATE TABLE
... SELECT statements are permitted to change tables
other than the one being created, but are no longer allowed to do
so in MySQL 5.6 (see
Section 17.4.1.6, “Replication of CREATE TABLE ... SELECT Statements”).
The use of more than two MySQL Server versions is not supported in replication setups involving multiple masters, regardless of the number of master or slave MySQL servers. This restriction applies not only to release series, but to version numbers within the same release series as well. For example, if you are using a chained or circular replication setup, you cannot use MySQL 5.5.1, MySQL 5.5.2, and MySQL 5.5.4 concurrently, although you could use any two of these releases together.
It is strongly recommended to use the most recent release available within a given MySQL release series because replication (and other) capabilities are continually being improved. It is also recommended to upgrade masters and slaves that use early releases of a release series of MySQL to GA (production) releases when the latter become available for that release series.
Replication from newer masters to older slaves may be possible, but is generally not supported. This is due to a number of factors:
Binary log format changes. The binary log format can change between major releases. While we attempt to maintain backward compatibility, this is not always possible. For example, the binary log format implemented in MySQL 5.0 changed considerably from that used in previous versions, especially with regard to handling of character sets,
LOAD DATA INFILE, and time zones. This means that replication from a MySQL 5.0 (or later) master to a MySQL 4.1 (or earlier) slave is generally not supported.This also has significant implications for upgrading replication servers; see Section 17.4.3, “Upgrading a Replication Setup”, for more information.
Use of row-based replication. Row-based replication was implemented in MySQL 5.1.5, so you cannot replicate using row-based replication from any MySQL 5.5 or later master to a slave older than MySQL 5.1.5.
For more information about row-based replication, see Section 17.1.2, “Replication Formats”.
SQL incompatibilities. You cannot replicate from a newer master to an older slave using statement-based replication if the statements to be replicated use SQL features available on the master but not on the slave.
However, if both the master and the slave support row-based replication, and there are no data definition statements to be replicated that depend on SQL features found on the master but not on the slave, you can use row-based replication to replicate the effects of data modification statements even if the DDL run on the master is not supported on the slave.
For more information on potential replication issues, see Section 17.4.1, “Replication Features and Issues”.
When you upgrade servers that participate in a replication setup, the procedure for upgrading depends on the current server versions and the version to which you are upgrading. This section provides information about how upgrading affects replication. For general information about upgrading MySQL, see Section 2.11.1, “Upgrading MySQL”
When you upgrade a master to 5.5 from an earlier MySQL release series, you should first ensure that all the slaves of this master are using the same 5.5.x release. If this is not the case, you should first upgrade the slaves. To upgrade each slave, shut it down, upgrade it to the appropriate 5.5.x version, restart it, and restart replication. The 5.5 slave is able to read the old relay logs written prior to the upgrade and to execute the statements they contain. Relay logs created by the slave after the upgrade are in 5.5 format.
After the slaves have been upgraded, shut down the master, upgrade it to the same 5.5.x release as the slaves, and restart it. The 5.5 master is able to read the old binary logs written prior to the upgrade and to send them to the 5.5 slaves. The slaves recognize the old format and handle it properly. Binary logs created by the master subsequent to the upgrade are in 5.5 format. These too are recognized by the 5.5 slaves.
In other words, when upgrading to MySQL 5.5, the slaves must be MySQL 5.5 before you can upgrade the master to 5.5. Note that downgrading from 5.5 to older versions does not work so simply: You must ensure that any 5.5 binary log or relay log has been fully processed, so that you can remove it before proceeding with the downgrade.
Downgrading a replication setup to a previous version cannot be done once you have switched from statement-based to row-based replication, and after the first row-based statement has been written to the binary log. See Section 17.1.2, “Replication Formats”.
Some upgrades may require that you drop and re-create database objects when you move from one MySQL series to the next. For example, collation changes might require that table indexes be rebuilt. Such operations, if necessary, are detailed at Section 2.11.1.1, “Changes Affecting Upgrades to 5.5”. It is safest to perform these operations separately on the slaves and the master, and to disable replication of these operations from the master to the slave. To achieve this, use the following procedure:
Stop all the slaves and upgrade them. Restart them with the
--skip-slave-startoption so that they do not connect to the master. Perform any table repair or rebuilding operations needed to re-create database objects, such as use ofREPAIR TABLEorALTER TABLE, or dumping and reloading tables or triggers.Disable the binary log on the master. To do this without restarting the master, execute a
SET sql_log_bin = 0statement. Alternatively, stop the master and restart it without the--log-binoption. If you restart the master, you might also want to disallow client connections. For example, if all clients connect using TCP/IP, use the--skip-networkingoption when you restart the master.With the binary log disabled, perform any table repair or rebuilding operations needed to re-create database objects. The binary log must be disabled during this step to prevent these operations from being logged and sent to the slaves later.
Re-enable the binary log on the master. If you set
sql_log_binto 0 earlier, execute aSET sql_log_bin = 1statement. If you restarted the master to disable the binary log, restart it with--log-bin, and without--skip-networkingso that clients and slaves can connect.Restart the slaves, this time without the
--skip-slave-startoption.
If you have followed the instructions but your replication setup is not working, the first thing to do is check the error log for messages. Many users have lost time by not doing this soon enough after encountering problems.
If you cannot tell from the error log what the problem was, try the following techniques:
Verify that the master has binary logging enabled by issuing a
SHOW MASTER STATUSstatement. If logging is enabled,Positionis nonzero. If binary logging is not enabled, verify that you are running the master with the--log-binoption.Verify that the master and slave both were started with the
--server-idoption and that the ID value is unique on each server.Verify that the slave is running. Use
SHOW SLAVE STATUSto check whether theSlave_IO_RunningandSlave_SQL_Runningvalues are bothYes. If not, verify the options that were used when starting the slave server. For example,--skip-slave-startprevents the slave threads from starting until you issue aSTART SLAVEstatement.If the slave is running, check whether it established a connection to the master. Use
SHOW PROCESSLIST, find the I/O and SQL threads and check theirStatecolumn to see what they display. See Section 17.2.1, “Replication Implementation Details”. If the I/O thread state saysConnecting to master, check the following:Verify the privileges for the user being used for replication on the master.
Check that the host name of the master is correct and that you are using the correct port to connect to the master. The port used for replication is the same as used for client network communication (the default is
3306). For the host name, ensure that the name resolves to the correct IP address.Check that networking has not been disabled on the master or slave. Look for the
skip-networkingoption in the configuration file. If present, comment it out or remove it.If the master has a firewall or IP filtering configuration, ensure that the network port being used for MySQL is not being filtered.
Check that you can reach the master by using
pingortraceroute/tracertto reach the host.
If the slave was running previously but has stopped, the reason usually is that some statement that succeeded on the master failed on the slave. This should never happen if you have taken a proper snapshot of the master, and never modified the data on the slave outside of the slave thread. If the slave stops unexpectedly, it is a bug or you have encountered one of the known replication limitations described in Section 17.4.1, “Replication Features and Issues”. If it is a bug, see Section 17.4.5, “How to Report Replication Bugs or Problems”, for instructions on how to report it.
If a statement that succeeded on the master refuses to run on the slave, try the following procedure if it is not feasible to do a full database resynchronization by deleting the slave's databases and copying a new snapshot from the master:
Determine whether the affected table on the slave is different from the master table. Try to understand how this happened. Then make the slave's table identical to the master's and run
START SLAVE.If the preceding step does not work or does not apply, try to understand whether it would be safe to make the update manually (if needed) and then ignore the next statement from the master.
If you decide that the slave can skip the next statement from the master, issue the following statements:
mysql>
SET GLOBAL sql_slave_skip_counter =mysql>N;START SLAVE;The value of
Nshould be 1 if the next statement from the master does not useAUTO_INCREMENTorLAST_INSERT_ID(). Otherwise, the value should be 2. The reason for using a value of 2 for statements that useAUTO_INCREMENTorLAST_INSERT_ID()is that they take two events in the binary log of the master.See also Section 13.4.2.4, “SET GLOBAL sql_slave_skip_counter Syntax”.
If you are sure that the slave started out perfectly synchronized with the master, and that no one has updated the tables involved outside of the slave thread, then presumably the discrepancy is the result of a bug. If you are running the most recent version of MySQL, please report the problem. If you are running an older version, try upgrading to the latest production release to determine whether the problem persists.
When you have determined that there is no user error involved, and replication still either does not work at all or is unstable, it is time to send us a bug report. We need to obtain as much information as possible from you to be able to track down the bug. Please spend some time and effort in preparing a good bug report.
If you have a repeatable test case that demonstrates the bug, please enter it into our bugs database using the instructions given in Section 1.6, “How to Report Bugs or Problems”. If you have a “phantom” problem (one that you cannot duplicate at will), use the following procedure:
Verify that no user error is involved. For example, if you update the slave outside of the slave thread, the data goes out of synchrony, and you can have unique key violations on updates. In this case, the slave thread stops and waits for you to clean up the tables manually to bring them into synchrony. This is not a replication problem. It is a problem of outside interference causing replication to fail.
Run the slave with the
--log-slave-updatesand--log-binoptions. These options cause the slave to log the updates that it receives from the master into its own binary logs.Save all evidence before resetting the replication state. If we have no information or only sketchy information, it becomes difficult or impossible for us to track down the problem. The evidence you should collect is:
All binary log files from the master
All binary log files from the slave
The output of
SHOW MASTER STATUSfrom the master at the time you discovered the problemThe output of
SHOW SLAVE STATUSfrom the slave at the time you discovered the problemError logs from the master and the slave
Use mysqlbinlog to examine the binary logs. The following should be helpful to find the problem statement.
log_fileandlog_posare theMaster_Log_FileandRead_Master_Log_Posvalues fromSHOW SLAVE STATUS.shell>
mysqlbinlog --start-position=log_poslog_file| head
After you have collected the evidence for the problem, try to isolate it as a separate test case first. Then enter the problem with as much information as possible into our bugs database using the instructions at Section 1.6, “How to Report Bugs or Problems”.