首页 > Python基础教程 > Python Scrapy网络爬虫
阅读:6,696
Python Scrapy shell调试工具及用法(含爬虫案例)
本节示例将会爬取 BOSS 直聘网上广州地区的热门职位进行分析。首先使用浏览器访问 https://www.zhipin.com/c101280100/h_101280100/ 页面,即可看到广州地区的热门职位。
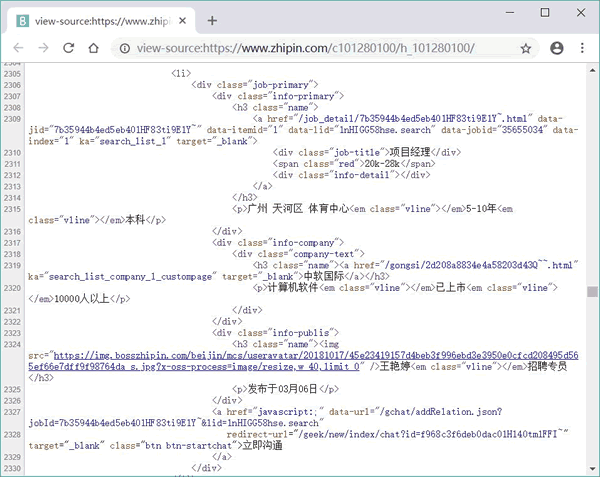
这里我们要使用爬虫来爬取该页面中的信息,因此需要查看该页面的源代码。可以看到,该页面中包含工作信息的源代码如图 1 所示。
下面将会使用 Scrapy 提供的 shell 调试工具来抓取该页面中的信息。使用如下命令来开启 shell 调试:
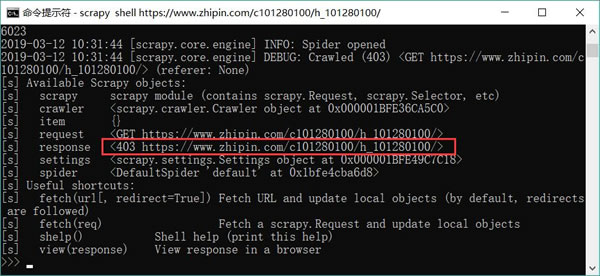
图 2 使用 shell 调试工具抓取页面信息时出现 403 错误
为了让 Scrapy 伪装成浏览器,需要在发送请求时设置 User-Agent 头,将 User-Agent 的值设置为真实浏览器发送请求的 User-Agent。
查看浏览器的 User-Agent,可按如下步骤进行操作(以 Firefox 为例):
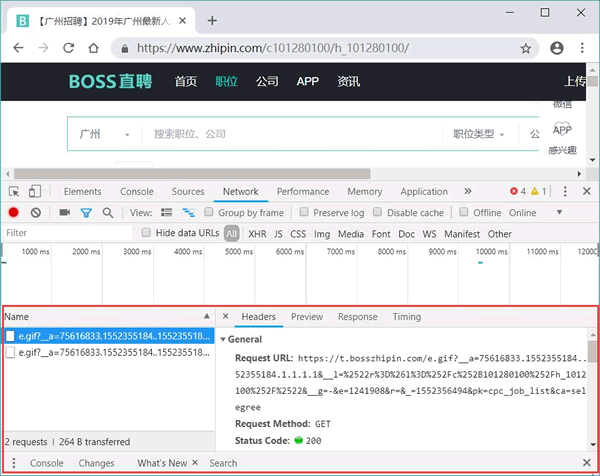
图 3 查看Firefox 发送请求的请求头
因此,可以使用如下命令让 Scrapy 伪装成 Firefox 来开启 shell 调试。
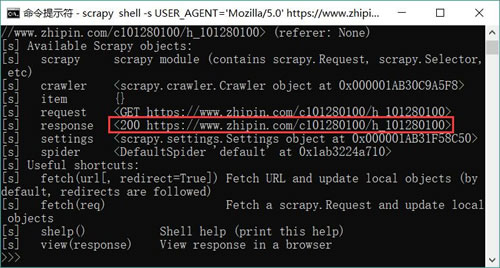
图 4 使用 shell 调试工具成功抓取页面的提示信息
接下来就可以使用 XPath 或 css 选择器来提取我们感兴趣的信息了。
为了让读者能看懂后面的代码,这里简单补充一点 XPath 的必要知识。表 5 中列出了 XPath 最实用的简化写法。
典型的,比如可以使用 //div 来匹配页面中任意位置处的 <div.../> 元素,也可以使用 //div/span 来匹配页面中任意位置处的 <div....> 元素内的 <span.../> 子元素。
XPath 还支持“谓词”,就是在节点后增加一个方括号,在方括号内放一个限制表达式对该节点进行限制。
典型的,我们可以使用 //div[@class]来匹配页面中任意位置处、有 class 属性的 <div.../> 元素,也可以使用 //div/span[1] 来匹配页面中任意位置处的 <div.../> 元素内的第一个 <span.../> 子元素;使用 //div/span[last()] 来匹配页面中任意位置处的 <div.../> 元素内的最后一个 <span.../> 子元素;使用 //div/span[last()-1] 来匹配页面中任意位置处的 <div.../> 元素内的倒数第二个 <span.../> 子元素……
例如,想获取上面页面中的第一条工作信息的工作名称,从图 1 中可以看到,所有工作信息都位于 <div class="job-primary"> 元素内,因此该 XPath 的开始应该写成:
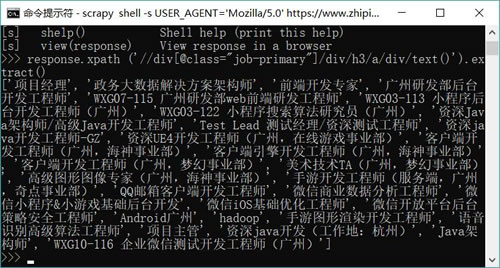
图 6 使用 css 选择器抓取感兴趣的信息
相比之下,XPath 比 css 选择器的匹配能力更强,因此本章的项目会使用 XPath 来匹配、抓取感兴趣的信息。
这里我们要使用爬虫来爬取该页面中的信息,因此需要查看该页面的源代码。可以看到,该页面中包含工作信息的源代码如图 1 所示。
下面将会使用 Scrapy 提供的 shell 调试工具来抓取该页面中的信息。使用如下命令来开启 shell 调试:
scrapy shell https://www.zhipin.com/c101280100/h_101280100/
运行上面命令,将会看到 Scrapy 并未抓取到页面数据,页面返回了 403 错误(如图 2 所示),这表明目标网站开启了“防爬虫”,不允许使用 Scrapy“爬取”数据。为了解决这个问题,我们需要让 Scrapy 伪装成浏览器。图 2 使用 shell 调试工具抓取页面信息时出现 403 错误
为了让 Scrapy 伪装成浏览器,需要在发送请求时设置 User-Agent 头,将 User-Agent 的值设置为真实浏览器发送请求的 User-Agent。
查看浏览器的 User-Agent,可按如下步骤进行操作(以 Firefox 为例):
- 启动Firefox 浏览器,然后按下“Ctrl+Shift+I”快捷键打开浏览器的调试控制台,选择“网络”Tab页。
- 通过该浏览器可以正常浏览任意页面。
- 在浏览器下方的调试控制台中,将会显示浏览器向哪些资源发送了请求。
- 在调试控制台中选择浏览器所请求的任意一个资源,即可在右边看到浏览器发送请求的各种请求头,如图 3 所示。
图 3 查看Firefox 发送请求的请求头
因此,可以使用如下命令让 Scrapy 伪装成 Firefox 来开启 shell 调试。
scrapy shell -s USER_AGENT='Mozilla/5.0' https://www.zhipin.com/c101280100/h_101280100
执行上面命令,将可以看到使用 shell 调试工具成功抓取页面的提示信息,如图 4 所示。图 4 使用 shell 调试工具成功抓取页面的提示信息
接下来就可以使用 XPath 或 css 选择器来提取我们感兴趣的信息了。
为了让读者能看懂后面的代码,这里简单补充一点 XPath 的必要知识。表 5 中列出了 XPath 最实用的简化写法。
| 表达式 | 作用 |
|---|---|
| nodename | 匹配此节点的所有内容 |
| / | 匹配根节点 |
| // | 匹配任意位置的节点 |
| . | 匹配当前节点 |
| .. | 匹配父节点 |
| @ | 匹配属性 |
典型的,比如可以使用 //div 来匹配页面中任意位置处的 <div.../> 元素,也可以使用 //div/span 来匹配页面中任意位置处的 <div....> 元素内的 <span.../> 子元素。
XPath 还支持“谓词”,就是在节点后增加一个方括号,在方括号内放一个限制表达式对该节点进行限制。
典型的,我们可以使用 //div[@class]来匹配页面中任意位置处、有 class 属性的 <div.../> 元素,也可以使用 //div/span[1] 来匹配页面中任意位置处的 <div.../> 元素内的第一个 <span.../> 子元素;使用 //div/span[last()] 来匹配页面中任意位置处的 <div.../> 元素内的最后一个 <span.../> 子元素;使用 //div/span[last()-1] 来匹配页面中任意位置处的 <div.../> 元素内的倒数第二个 <span.../> 子元素……
例如,想获取上面页面中的第一条工作信息的工作名称,从图 1 中可以看到,所有工作信息都位于 <div class="job-primary"> 元素内,因此该 XPath 的开始应该写成:
//div[@class="job-primary"]
接下来可以看到工作信息还处于 <div class="info-primary"> 元素内,因此该 XPath 应该写成(此处不加谓词也可以)://div[@class="job-primary"]/div
接下来可以看到工作信息还处于 <h3 class="name"> 元素内,因此该 XPath 应该写成(此处不加谓词也可以)://div [@class = "job-primary"]/div/h3
依此类推,可以看到工作名称对应的 XPath 写成://div[@class = "job-primary"]/div/h3/a/div/text()
在掌握了 XPath 的写法之后,即可在 Scrapy 的 shell 控制台调用 response 的 xpath() 方法来获取 XPath 匹配的节点。执行如下命令:response.xpath ('//div[@class="job-primary"]/div/h3/a/div/text()').extract()
上面的 extract() 方法用于提取节点的内容。运行上面命令,可以看到如图 6 所示的输出信息。图 6 使用 css 选择器抓取感兴趣的信息
相比之下,XPath 比 css 选择器的匹配能力更强,因此本章的项目会使用 XPath 来匹配、抓取感兴趣的信息。
所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频