首页 > Python基础教程 > Python Scrapy网络爬虫
阅读:7,302
Python Scrapy爬虫项目开发过程详解
通过前面的 Scrapy shell 调试,已经演示了使用 XPath 从 HTML 文档中提取信息的方法,只要将这些调试的测试代码放在 Spider 中,即可实现真正的 Scrapy 爬虫。
基于 Scrapy 项目开发爬虫大致需要如下几个步骤:
经过上面三个步骤,基于 Scrapy 的爬虫基本开发完成。下面还需要修改 settings.py 文件进行一些简单的配置,比如增加 User-Agent 头。取消 settings.py 文件中如下代码行的注释,并将这些代码行改为如下形式:
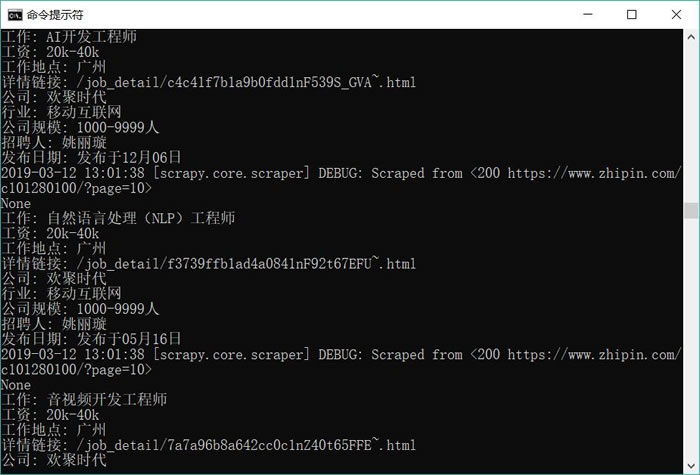
图 1 爬取第一页数据
从图 1 可以看出,该爬虫已经顺利爬取了 start_urls 列表所给出页面中的工作信息。但问题又出现了,该爬虫并未继续爬取下一页的工作信息。
爬虫可以自动爬取下一页信息吗?答案是肯定的。在提取完 response 中的所有“工作信息”之后,Spider 可以使用 XPath 找到页面中代表“下一页”的链接,然后使用 Request 发送请求即可。
通过浏览器查看源代码,可以看到 https://www.zhipin.com/c101280100/h_101280100/ 页面中包含分页信息的源代码,如图 2 所示。
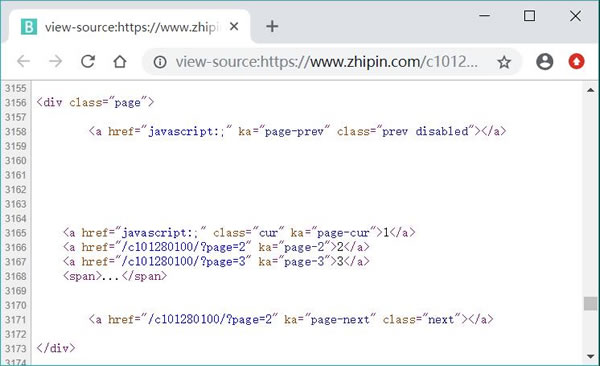
图 2 页面中包含分页信息的源代码
从图 2 可以看出,页面中“下一页”元素的 XPath 为 //div[@class='page']/a [@class='next'],因此程序需要在 JobPositionSpider 类的 parse(self, response) 方法的后面添加如下代码:
上面程序中第 2 行代码解析页面中的“下一页”链接;第 7 行代码显式使用 scrapy.Request 来发送请求,并指定使用 self.parse 方法来解析服务器响应数据。需要说明的是,这是一个递归操作,即每当 Spider 解析完页面中项目感兴趣的工作信息之后,它总会再次请求“下一页”数据,通过这种方式即可爬取广州地区所有的热门职位信息。
再次运行
基于 Scrapy 项目开发爬虫大致需要如下几个步骤:
-
定义 Item 类。该类仅仅用于定义项目需要爬取的 N 个属性。比如该项目需要爬取工作名称、工资、招聘公司等信息,则可以在 items.py 中增加如下类定义:
import scrapy class ZhipinspiderItem(scrapy.Item): # 工作名称 title = scrapy.Field() # 工资 salary = scrapy.Field() # 招聘公司 company = scrapy.Field() # 工作详细链接 url = scrapy.Field() # 工作地点 work_addr = scrapy.Field() # 行业 industry = scrapy.Field() # 公司规模 company_size = scrapy.Field() # 招聘人 recruiter = scrapy.Field() # 发布时间 publish_date = scrapy.Field()上面程序中,第 3 行代码表明所有的 Item 类都需要继承 scrapy.Item 类,接下来就为所有需要爬取的信息定义对应的属性,每个属性都是一个 scrapy.Field 对象。
该 Item 类只是一个作为数据传输对象(DTO)的类,因此定义该类非常简单。 -
编写 Spider 类。应该将该 Spider 类文件放在 spiders 目录下。这一步是爬虫开发的关键,需要使用 XPath 或 CSS 选择器来提取 HTML 页面中感兴趣的信息。
Scrapy 为创建 Spider 提供了 scrapy genspider 命令,该命令的语法格式如下:
scrapy genspider [options] <name> <domain>
在命令行窗口中进入 ZhipinSpider 目录下,然后执行如下命令即可创建一个 Spider:scrapy genspider job_position "zhipin.com"
运行上面命令,即可在 ZhipinSpider 项目的 ZhipinSpider/spider 目录下找到一个 job_position.py 文件,打开该文件可以看到如下内容:
import scrapy class JobPositionSpider(scrapy.Spider): # 定义该Spider的名字 name = 'job_position' # 定义该Spider允许爬取的域名 allowed_domains = ['zhipin.com'] # 定义该Spider爬取的首页列表 start_urls = ['https://www.zhipin.com/c101280100/h_101280100/'] # 该方法负责提取response所包含的信息 def parse(self, response): pass上面程序就是 Spider 类的模板,该类的 name 属性用于指定该 Spider 的名字;allow_domains 用于限制该 Spider 所爬取的域名;start_urls 指定该 Spider 会自动爬取的页面 URL。
Spider 需要继承 scrapy.Spider,并重写它的 parse(self, response) 方法(如上面程序所示)。从该类来看,我们看不到发送请求、获取响应的代码,这也正是 Scrapy 的魅力所在,即只要把所有需要爬取的页面 URL 定义在 start_urls 列表中,Scrapy 的下载中间件就会负责从网络上下载数据,并将所有数据传给 parse(self, response) 方法的 response 参数。
注意,如果在 Windows 上使用 genspider 命令来生成爬虫类,则容易引发 SyntaxError:(unicode error)'utf-8' codec can’t decode byte 0xb9 in position 0: invalid start byte 错误,这是由于 Windows 采用了 GBK 字符集。因此,需要手动将该 Spider 类保存为 UTF-8 字符集。
一言以蔽之,开发者只要在 start_urls 列表中列出所有需要 Spider 爬取的页面 URL,这些页面的数据就会“自动”传给 parse(self, response) 方法的 response 参数。
因此,开发者主要就是做两件事情:- 将要爬取的各页面 URL 定义在 start_urls 列表中。
- 在 parse(self, response) 方法中通过 XPath 或 CSS 选择器提取项目感兴趣的信息。
下面将 job_position.py 文件改为如下形式:
import scrapy from ZhipinSpider.items import ZhipinspiderItem class JobPositionSpider(scrapy.Spider): # 定义该Spider的名字 name = 'job_position' # 定义该Spider允许爬取的域名 allowed_domains = ['zhipin.com'] # 定义该Spider爬取的首页列表 start_urls = ['https://www.zhipin.com/c101280100/h_101280100/'] # 该方法负责提取response所包含的信息 # response代表下载器从start_urls中每个URL下载得到的响应 def parse(self, response): # 遍历页面上所有//div[@class="job-primary"]节点 for job_primary in response.xpath('//div[@class="job-primary"]'): item = ZhipinspiderItem() # 匹配//div[@class="job-primary"]节点下/div[@class="info-primary"]节点 # 也就是匹配到包含工作信息的<div.../>元素 info_primary = job_primary.xpath('./div[@class="info-primary"]') item['title'] = info_primary.xpath('./h3/a/div[@class="job-title"]/text()').extract_first() item['salary'] = info_primary.xpath('./h3/a/span[@class="red"]/text()').extract_first() item['work_addr'] = info_primary.xpath('./p/text()').extract_first() item['url'] = info_primary.xpath('./h3/a/@href').extract_first() # 匹配//div[@class="job-primary"]节点下./div[@class="info-company"]节点下 # 的/div[@class="company-text"]的节点 # 也就是匹配到包含公司信息的<div.../>元素 company_text = job_primary.xpath('./div[@class="info-company"]' + '/div[@class="company-text"]') item['company'] = company_text.xpath('./h3/a/text()').extract_first() company_info = company_text.xpath('./p/text()').extract() if company_info and len(company_info) > 0: item['industry'] = company_info[0] if company_info and len(company_info) > 2: item['company_size'] = company_info[2] # 匹配//div[@class="job-primary"]节点下./div[@class="info-publis"]节点下 # 也就是匹配到包含发布人信息的<div.../>元素 info_publis = job_primary.xpath('./div[@class="info-publis"]') item['recruiter'] = info_publis.xpath('./h3/text()').extract_first() item['publish_date'] = info_publis.xpath('./p/text()').extract_first() yield item上面程序中,第 10 行代码修改了 start_urls 列表,重新定义了该 Spider 需要爬取的首页;接下来程序重写了 Spider 的 parse(self, response) 方法。
程序第 16 行代码使用 XPath 匹配所有的 '//div[@class="job-primary"]' 节点(每个节点都包含一份招聘信息)。因此,程序使用循环遍历每个 '//div[@class="job-primary"]' 节点,为每个节点都建立一个 ZhipinspiderItem 对象,并从该节点中提取项目感兴趣的信息存入 ZhipinspiderItem 对象中。
程序最后一行代码使用 yield 语句将 item 对象返回给 Scrapy 引擎。此处不能使用 return,因为 return 会导致整个方法返回,循环不能继续执行,而 yield 将会创建一个生成器。
Spider 使用 yield 将 item 返回给 Scrapy 引擎之后,Scrapy 引擎将这些 item 收集起来传给项目的 Pipeline,因此自然就到了使用 Scrapy 开发爬虫的第二步。 -
编写 pipelines.py 文件,该文件负责将所爬取的数据写入文件或数据库中。
现在开始修改 pipelines.py 文件。为了简化开发,只在控制台打印 item 数据。下面是修改后的 pipelines.py 文件的内容。class ZhipinspiderPipeline(object): def process_item(self, item, spider): print("工作:" , item['title']) print("工资:" , item['salary']) print("工作地点:" , item['work_addr']) print("详情链接:" , item['url']) print("公司:" , item['company']) print("行业:" , item['industry']) print("公司规模:" , item['company_size']) print("招聘人:" , item['recruiter']) print("发布日期:" , item['publish_date'])从上面第 2 行代码可以看到,ZhipinspiderPipeline 主要就是实现 process_item(self, item, spider) 方法,该方法的 item、spider 参数都由 Scrapy 引擎传入,Scrapy 引擎会自动将 Spider“捕获”的所有 item 逐个传给 process_item(self, item, spider) 方法,因此该方法只需处理单个的 item 即可(不管爬虫总共爬取了多少个 item,process_item(self, item, spider) 方法只处理一个即可)。
经过上面三个步骤,基于 Scrapy 的爬虫基本开发完成。下面还需要修改 settings.py 文件进行一些简单的配置,比如增加 User-Agent 头。取消 settings.py 文件中如下代码行的注释,并将这些代码行改为如下形式:
BOT_NAME = 'ZhipinSpider'
SPIDER_MODULES = ['ZhipinSpider.spiders']
NEWSPIDER_MODULE = 'ZhipinSpider.spiders'
ROBOTSTXT_OBEY = True
# 配置默认的请求头
DEFAULT_REQUEST_HEADERS = {
"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
# 配置使用Pipeline
ITEM_PIPELINES = {
'ZhipinSpider.pipelines.ZhipinspiderPipeline': 300,
}
回顾一下上面的开发过程,使用 Scrapy 开发爬虫的核心工作就是三步:
- 定义 Item 类。由于 Item 只是一个 DTO 对象,因此定义 Item 类很简单。
- 开发 Spider 类,这一步是核心。Spider 使用 XPath 从页面中提取项目所需的信息,并用这些信息来封装 Item 对象。
- 开发 Pipeline。Pipeline 负责处理 Spider 获取的 Item 对象。
注意,所有修改过的源文件(尤其是添加了中文注释的文件)都需要手动保存为 UTF-8 字符集,否则在运行爬虫时会出现错误。
经过上面步骤,这个基于 Scrapy 的 Spider 已经开发完成。在命令行窗口中进入 ZhipinSpider 项目目录下(不是进入 ZhipinSpider/ZhipinSpider 目录下),执行如下命令来启动 Spider:scrapy crawl job_position
上面 scrapy crawl 命令中的 job_position 就是前面定义的 Spider 名称(通过 JobPositionSpider 类的 name 属性指定)。运行上面命令,可以看到如图 1 所示的输出结果。图 1 爬取第一页数据
从图 1 可以看出,该爬虫已经顺利爬取了 start_urls 列表所给出页面中的工作信息。但问题又出现了,该爬虫并未继续爬取下一页的工作信息。
爬虫可以自动爬取下一页信息吗?答案是肯定的。在提取完 response 中的所有“工作信息”之后,Spider 可以使用 XPath 找到页面中代表“下一页”的链接,然后使用 Request 发送请求即可。
通过浏览器查看源代码,可以看到 https://www.zhipin.com/c101280100/h_101280100/ 页面中包含分页信息的源代码,如图 2 所示。
图 2 页面中包含分页信息的源代码
从图 2 可以看出,页面中“下一页”元素的 XPath 为 //div[@class='page']/a [@class='next'],因此程序需要在 JobPositionSpider 类的 parse(self, response) 方法的后面添加如下代码:
# 解析下一页的链接
new_links = response.xpath('//div[@class="page"]/a[@class="next"]/@href').extract()
if new_links and len(new_links) > 0:
# 获取下一页的链接
new_link = new_links[0]
# 再次发送请求获取下一页数据
yield scrapy.Request("https://www.zhipin.com" + new_link, callback=self.parse)
应该将上面这段代码放在 parse(self, response) 方法的后面,这样可以保证 Spider 在爬取页面中所有项目感兴趣的工作信息之后,才会向下一个页面发送请求。上面程序中第 2 行代码解析页面中的“下一页”链接;第 7 行代码显式使用 scrapy.Request 来发送请求,并指定使用 self.parse 方法来解析服务器响应数据。需要说明的是,这是一个递归操作,即每当 Spider 解析完页面中项目感兴趣的工作信息之后,它总会再次请求“下一页”数据,通过这种方式即可爬取广州地区所有的热门职位信息。
再次运行
scrapy crawl job_position 命令来启动爬虫,即可看到该爬虫成功爬取了 10 页职位信息,这是因为该页面默认只提供 10 页职位信息。所有教程
- socket
- Python基础教程
- C#教程
- MySQL函数
- MySQL
- C语言入门
- C语言专题
- C语言编译器
- C语言编程实例
- GCC编译器
- 数据结构
- C语言项目案例
- C++教程
- OpenCV
- Qt教程
- Unity 3D教程
- UE4
- STL
- Redis
- Android教程
- JavaScript
- PHP
- Mybatis
- Spring Cloud
- Maven
- vi命令
- Spring Boot
- Spring MVC
- Hibernate
- Linux
- Linux命令
- Shell脚本
- Java教程
- 设计模式
- Spring
- Servlet
- Struts2
- Java Swing
- JSP教程
- CSS教程
- TensorFlow
- 区块链
- Go语言教程
- Docker
- 编程笔记
- 资源下载
- 关于我们
- 汇编语言
- 大数据
- 云计算
- VIP视频